
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a discovery scan configuration for BigQuery in paused mode
/ 20
Create a sensitivity level tag in IAM
/ 20
Grant role to service account for discovery scan
/ 20
Update the paused discovery scan with automated tagging and start scan
/ 20
Explore conditional access for BigQuery using tags
/ 20
Create a discovery scan configuration for BigQuery in paused mode
/ 20
Create a sensitivity level tag in IAM
/ 20
Grant role to service account for discovery scan
/ 20
Update the paused discovery scan with automated tagging and start scan
/ 20
Explore conditional access for BigQuery using tags
/ 20

Sensitive Data Protection は、機密情報を検出、分類、保護できるようにするためのフルマネージド サービスです。主なオプションには、機密データを継続的にプロファイリングする機密データの検出、秘匿化を含む機密データの匿名化、カスタム ワークロードやアプリケーションに検出、検査、匿名化を組み込むことができる Cloud Data Loss Prevention(DLP)API などがあります。
Google Cloud の Identity and Access Management(IAM)とともに Sensitive Data Protection を活用することで、検出スキャン中に機密データに自動でタグ付けし、組織内のユーザーに BigQuery データへの条件付きアクセス権を付与できます。これにより、BigQuery の機密データを保護できます。
このラボでは、まず一時停止モードで BigQuery の検出スキャン構成を作成します。次に、BigQuery で機密データをフラグ付けするためのタグを作成し、作成したタグを自動スキャンに使用するよう検出スキャン構成を更新します。最後に、作成したタグを使用して、追加のユーザーに BigQuery データへの条件付きアクセス権を付与します。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Sensitive Data Protection の検出サービスを使用すると、組織全体で機密データやリスクの高いデータが存在する場所を特定できます。検出スキャン構成を作成すると、Sensitive Data Protection によって、レビュー対象として選択したリソースがスキャンされ、データ プロファイルが生成されます。データ プロファイルは、特定された infoType(機密データのタイプ)に関する分析情報と、データリスクおよび機密性レベルに関するメタデータのセットです。
このタスクでは、BigQuery のデータを自動的にプロファイリングするための検出スキャンを作成します。完全な検出結果が生成されるまでには時間がかかるため、このラボの最後のタスクで、主な結果のハイライトと概要が提供されます。
Google Cloud コンソールで、ナビゲーション メニュー(
[データ保護] で [Sensitive Data Protection] をクリックします。
[検出] というタブをクリックします。
[BigQuery] で [有効にする] をクリックします。
[検出タイプの選択] で、[BigQuery] のオプションを有効にしたまま、[続行] をクリックします。
[スコープの選択] で、[選択したプロジェクトをスキャン] のオプションを有効にしたまま、[続行] をクリックします。
[スケジュールの管理] はデフォルトのままにして、[続行] をクリックします。
このラボでは作成直後に検出スキャンを実行するようスケジュールを設定しますが、定期的に(毎日または毎週など)実行する、特定のイベント(検査テンプレートが更新されたときなど)の後に実行するなど、スキャンのスケジュール オプションは多数用意されています。
[検査テンプレートの選択] で、[新しい検査テンプレートを作成] オプションを有効にしたままにします。
その他はすべてデフォルトのままにして、[続行] をクリックします。
デフォルトでは、新しい検査テンプレートには既存のすべての infoType が含まれます。
[信頼度のしきい値] の [最小の可能性] のデフォルトは [可能性あり] です。つまり、[可能性あり]、[高い]、[かなり高い] と評価された結果のみが得られます。
後のタスクで、この検査テンプレートを変更して、infoType と信頼度のしきい値の他のオプションを試します。
[アクションを追加] で、[Security Command Center に公開] を有効にします。
[アクションを追加] で、[データ プロファイルのコピーを BigQuery に保存する] も有効にして、BigQuery に結果を保存するデータセットとテーブル(このラボで事前に作成済み)を指定します。
| プロパティ | 値 |
|---|---|
| プロジェクト ID |
|
| データセット ID | bq_discovery |
| テーブル ID | data_profiles |
リソースにタグを付けるアクションの下に表示されるメッセージに注意してください。自動タグ付けを行うには、サービス エージェントに特定のロールが必要であることが示されています。
次のタスクでは、検出スキャン中に自動でタグ付けを行うために、タグを作成し、必要なロールをサービス アカウントに付与します。
その他はすべてデフォルトのままにして、[続行] をクリックします。
[構成の保存ロケーションを設定する] で、[US(米国の複数のリージョン)] のオプションを有効にしたまま、[続行] をクリックします。
この構成の表示名を「BigQuery 検出」に指定します。
[一時停止モードでスキャンを作成する] を有効にします。
これにより、検出スキャン構成が作成されますが、スキャンはまだ開始されません。これは、検出スキャンのためにタグを作成し、サービス エージェント ID に適切な IAM ロールを付与できるようにするためです。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
IAM 内で機密レベルタグを作成できます。機密レベルタグを使用して、検出スキャン中にリソースに自動でタグ付けし、タグ付けされた特定のリソースへのアクセスを許可または拒否できます。
このタスクでは、4 つの機密レベル(低、中、高、不明)を表すタグ値を持つ機密レベルタグを IAM で作成します。
Google Cloud コンソールで、ナビゲーション メニュー(
[+ 作成] をクリックします。
[タグキー]
に、タグの表示名として「sensitivity-level」と入力します。
[タグの説明] に、このタグの説明として「Sensitivity level tagged as low, moderate, high, and unknown」と入力します。
[+ 値を追加] をクリックします。
[タグ値]
に、最初のタグ値の表示名として「low」と入力します。
[タグ値の説明] に、このタグ値の説明として「Tag value to attach to low-sensitivity data」と入力します。
手順 5~7 を繰り返して、さらに 3 つのタグ値を作成します。
| タグ値 | タグの説明 |
|---|---|
moderate |
Tag value to attach to moderate-sensitivity data
|
high |
Tag value to attach to high-sensitivity data
|
unknown |
Tag value to attach to resources with an unknown sensitivity
level
|
タグキーが作成されるまで 1 分ほどかかることがあります。
タグキーには、タグキーのパス(high、low、moderate、unknown
があります。
タグキーのパスとタグ値を組み合わせることで、タグ値のパスが得られます。これは次のタスクで使用します。例:
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
リソースに自動的にタグを付けるには、サービス エージェントに
resourcemanager.tagUser ロールが必要です。このセクションでは、データの機密性に基づいて IAM アクセスを制御するというドキュメントに記載されている手順に沿って、このロールを付与します。
 をクリックします。
をクリックします。
プロンプトが表示されたら、[続行] をクリックします。
プロンプトが表示されたら、[承認] をクリックします。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
自動タグ付けに必要なロールをサービス アカウントに付与したので、検出スキャンでリソースにタグ付けするオプションを有効にできます。
Sensitive Data Protection の概要ページに戻ります。
[検出] > [スキャン構成] タブで、「BigQuery 検出」という名前の行を見つけます。該当する行の [アクションを表示] アイコン(縦に 3 つ並んだ点)をクリックし、[編集] を選択します。
[アクションを追加] で、[リソースにタグを付ける] と、次の関連オプションを有効にします。
| プロパティ | 値 |
|---|---|
| 機密性が高いリソースにタグを付ける |
タグを有効にして、タグ値
|
| 機密性が中程度のリソースにタグを付ける |
タグを有効にして、タグ値
|
| 機密性が低いリソースにタグを付ける |
タグを有効にして、タグ値
|
| 機密性が不明なリソースにタグを付ける |
タグを有効にして、タグ値
|
また、次の 2 つのオプションを有効にします。
[保存] をクリックし、[編集を確定] をクリックします。
最後に、[スキャンを再開] をクリックして検出スキャンを開始します。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
注: 構成スキャンの開始後、完全な結果が利用可能になるまでには時間がかかる場合があります。
以下の画像は、このラボ環境で BigQuery の検出を有効にした場合に得られる主な結果を示しています。結果では、このラボ環境に含まれる BigQuery データには、非常に機密性の高いデータである米国社会保障番号など、複数の infoType が存在する可能性があることが示されています。
BigQuery では、3 つのプロファイルが特定されました。機密性の低いプロファイルが 2 つ(1 つは検出結果のデータセット、もう 1 つは損傷した車の画像メタデータのデータセット)、機密性の高いプロファイルが 1 つ(車の購入者に関する詳細を含むデータセット)です。
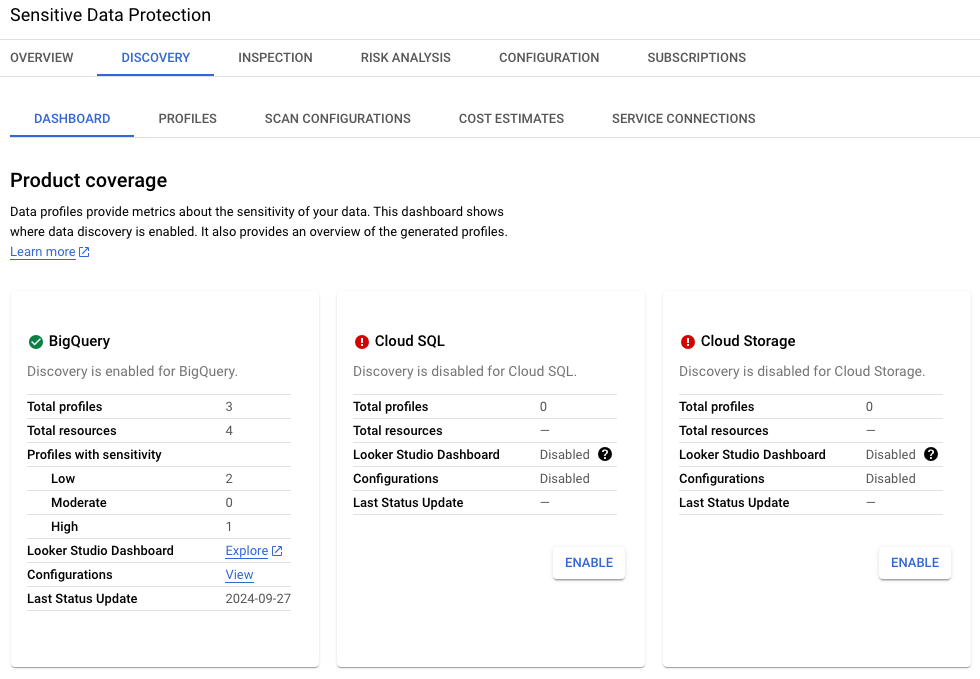
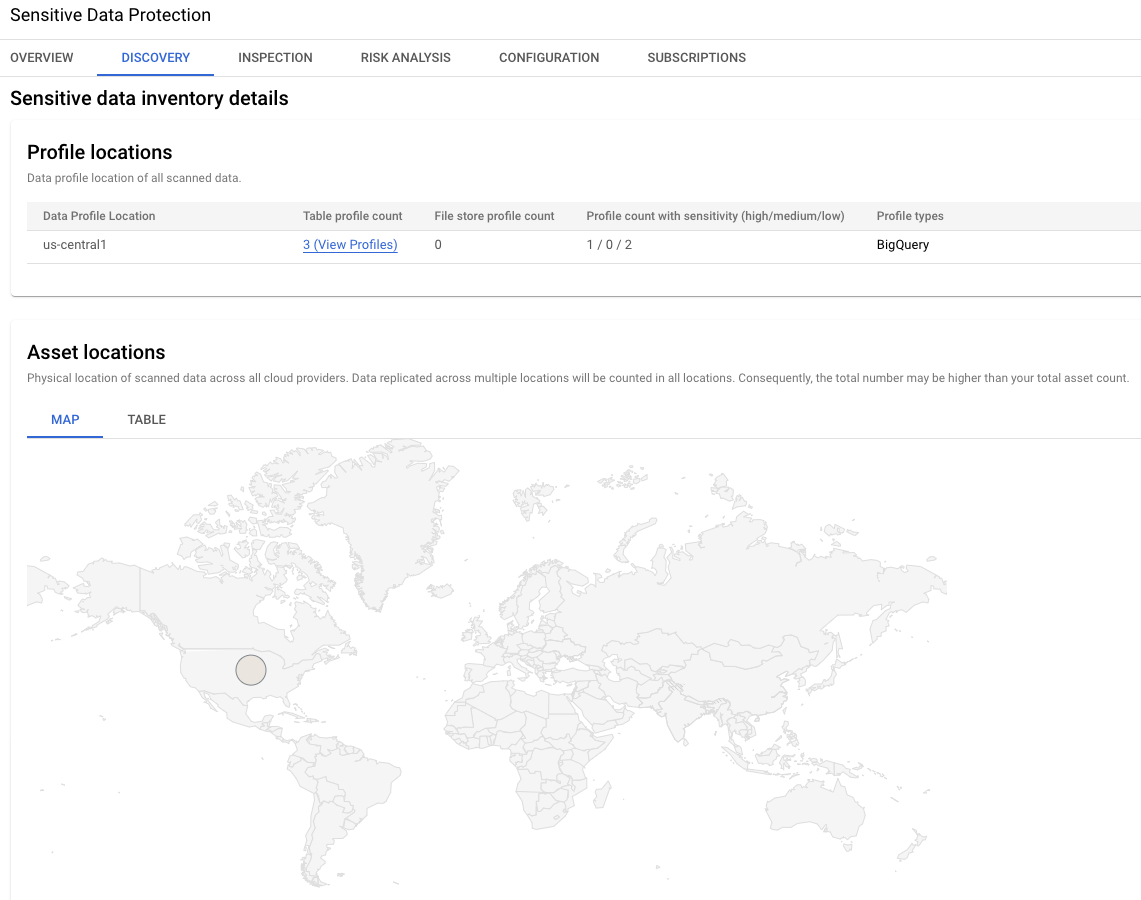
結果のこのセクションには、3 つのデータ プロファイルのグローバル
ロケーションが示されています。この例では、どれも
us-central1 リージョンにあります。
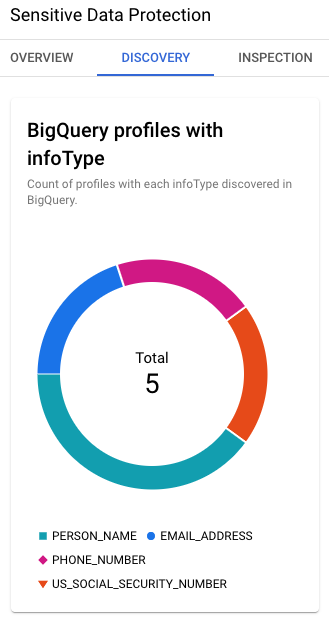
検出結果には、BigQuery で特定された主要な infoType(米国社会保障番号、メールアドレス、名前など)も含まれています。
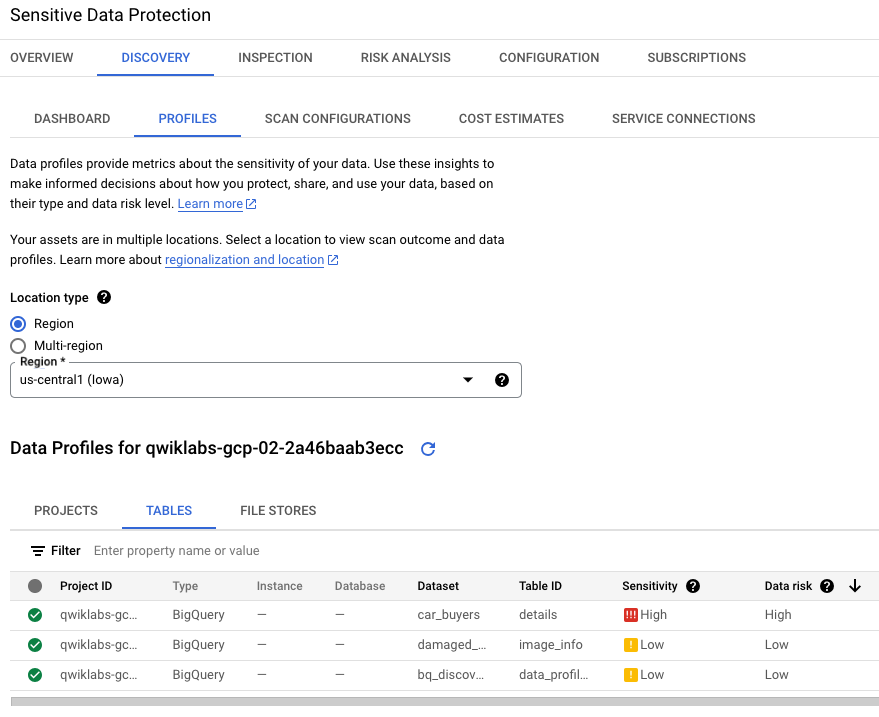
[プロファイル] タブでは、BigQuery データセット名ごとに機密レベルとリスクレベルが特定されます。機密性が低いものが 1 つ(ジョブからの出力を受け取る空のバケット)、機密性が高いものが 1 つ(米国社会保障番号を含む元データが格納されたバケット)です。
このラボ環境では、プロファイルを表示するために、[ロケーション タイプ] で [リージョン] > [
IAM では、条件付きロール バインディングを使用して、特定のリソースにアタッチされた機密レベルタグに基づき、ユーザーにロールを付与できます。たとえば、機密性が低いとタグ付けされた BigQuery データのみへのアクセス権をユーザーに付与できます。ユーザーは、タグなしの BigQuery を含め、タグがアタッチされていない BigQuery にはアクセスできなくなります。
このタスクでは、まず、このラボ環境でユーザー名 2 に付与されている既存の BigQuery アクセス権を確認します。次に、ユーザー名 2 のアクセス権を、機密性が低いデータのタグに基づく条件付きに更新し、そのタグを BigQuery データセットの 1 つに手動で割り当てます。最後に、ユーザー名 2 の更新された BigQuery アクセス権をテストして、条件付きアクセス権を確認します。
このセクションでは、まずユーザー名 2(
完全なソリューション(開くとすべての手順が確認できます)
ユーザー名 2 として、次の手順に沿って、ユーザー名 2 に付与されている既存の BigQuery アクセス権を確認します。
Google Cloud コンソールで、ナビゲーション メニュー(
[エクスプローラ] パネルで、プロジェクト ID(
次の 4 つの BigQuery データセットが表示されます。
このセクションでは、まずユーザー名 1(
完全なソリューション(開くとすべての手順が確認できます)
Google Cloud コンソールで、ナビゲーション メニュー(
ユーザー名 2(
「閲覧者」という名前のロールの行を見つけ、[ロールを削除](ゴミ箱アイコン)をクリックします。
[別のロールを追加] をクリックします。
[ロールを選択] で、[基本] > [ブラウザ] を選択します。
「BigQuery データ閲覧者」という名前のロールの行を見つけ、[IAM の条件を追加] をクリックします。
[タイトル] に「Low Sensitivity Data Access Only」と入力します。
[条件作成ツール] で、[条件タイプ 1] に [タグ] を選択し、[演算子] に [値がある] を選択します。
[値のパス] に、タスク 3 で使用した機密性が低いリソースのタグ値を指定します。
タグ値を忘れた場合は、ヒントを開いて確認してください。
このセクションでは、ユーザー名 1(
検出スキャンが完全に完了するまでには時間がかかるため、まだ機密レベルタグが付けされた BigQuery データセットはありません。
条件付きアクセスをテストするために、機密データを含まない damaged_car_image_info という名前の BigQuery データセットに、手動で機密性「低」のタグを割り当てます。
Google Cloud コンソールで、ナビゲーション メニュー(
[エクスプローラ] パネルで、プロジェクト ID(
「damaged_car_image_info」をクリックしてデータセット情報のタブを開き、[詳細を編集](鉛筆アイコン)をクリックします。
[タグ] で [スコープを選択] > [現在のプロジェクトを選択] をクリックします。
次の詳細を選択します。
| プロパティ | 値 |
|---|---|
| キー 1 | sensitivity-level |
| 値 1 | low |
このセクションでは、最後にもう一度ユーザー名 2(
完全なソリューション(開くとすべての手順が確認できます)
ユーザー名 2 として、次の手順に沿ってユーザー名 2 に付与されている BigQuery への条件付きアクセス権を確認します。
ナビゲーション メニュー(
[データ エクスプローラ] パネルで、プロジェクト ID(
IAM ロールが適切な条件で更新されると、次の BigQuery データセットが 1 つだけ表示されます。これは、機密性「低」のタグが付いているデータセットがこの 1 つのみであるためです。
[進行状況を確認]
をクリックして、目標に沿って進んでいることを確認します。
注: 前述のように、構成スキャンの開始後、完全な結果が利用可能になるまでには時間がかかる場合があります。
別のユーザーに条件付きアクセスを付与し、テストしている間に時間が経過したため、検出スキャンによって生成された Looker ダッシュボードに結果の一部が表示されます。
このセクションでは、まずユーザー名 1(
新しいユーザーへの切り替えについては、以下のヒントを開いてください。
完全なソリューション(開くとすべての手順が確認できます)
Sensitive Data Protection の概要ページに戻ります。
[検出] > [スキャン構成] タブで、「BigQuery 検出」という名前の行を見つけます。[Data Studio] で、該当する行の [Looker] をクリックします。
[承認のリクエスト] で [承認] をクリックします。
[qwiklabs.net のアカウントを選択] ダイアログ
ウィンドウで、
[概要] を確認します。
データリスク、データの機密性、アセットタイプなどの主要な情報を要約したデータタイルが表示されます。
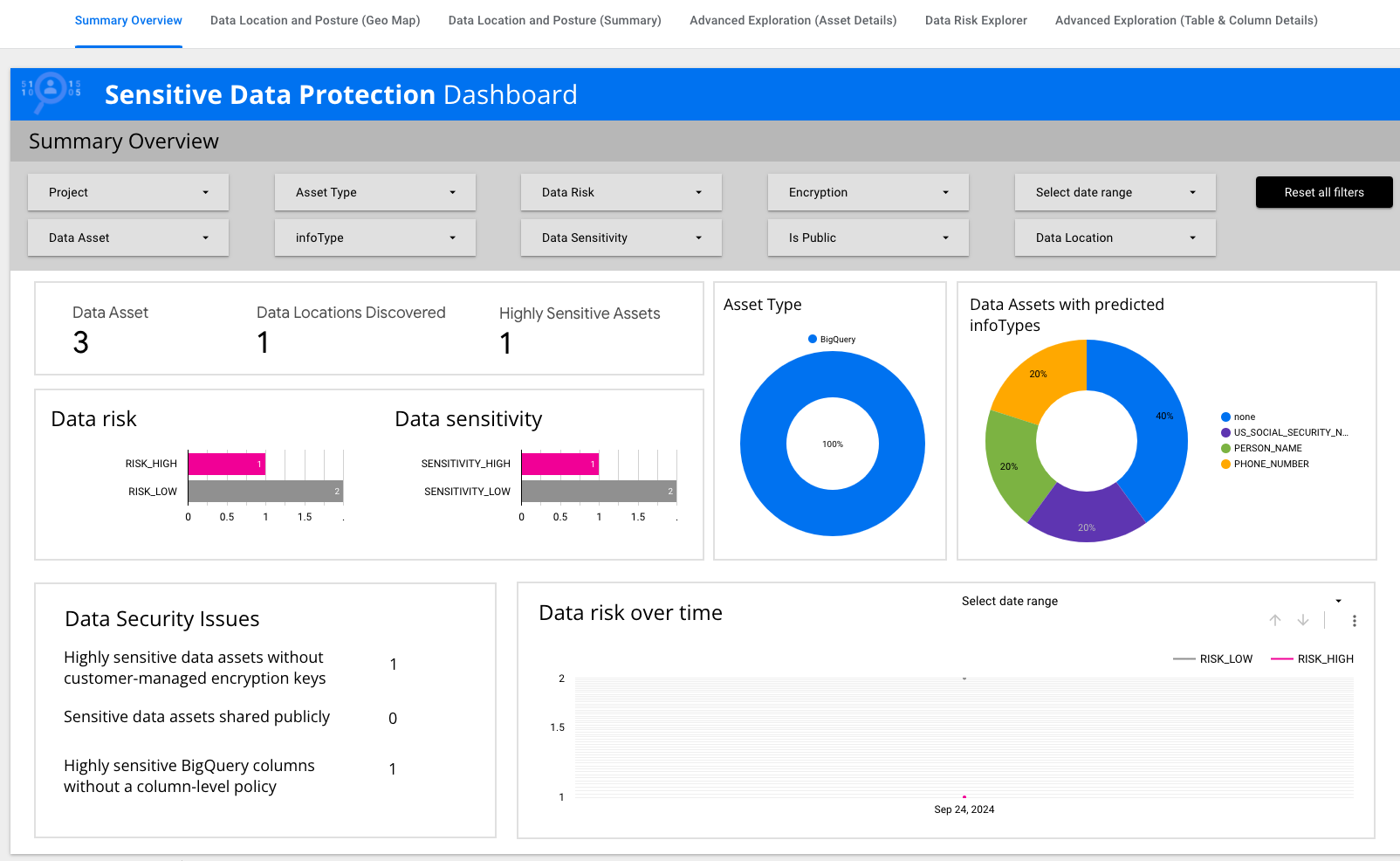
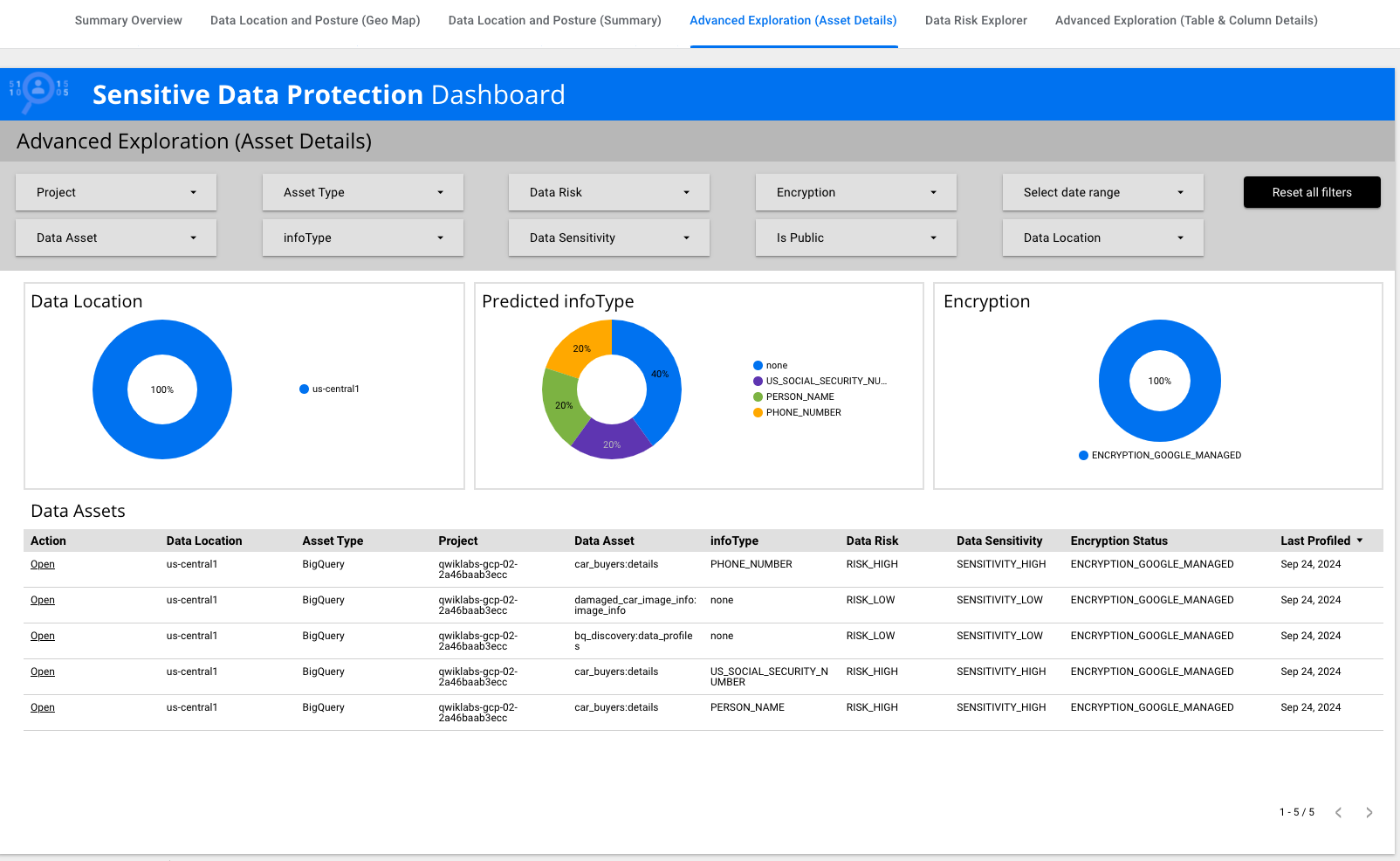
[高度な探索(アセットの詳細)] をクリックします。
infoType が
US_SOCIAL_SECURITY_NUMBER の行を見つけます。[アクション]
で、該当する行の [開く] をクリックします。
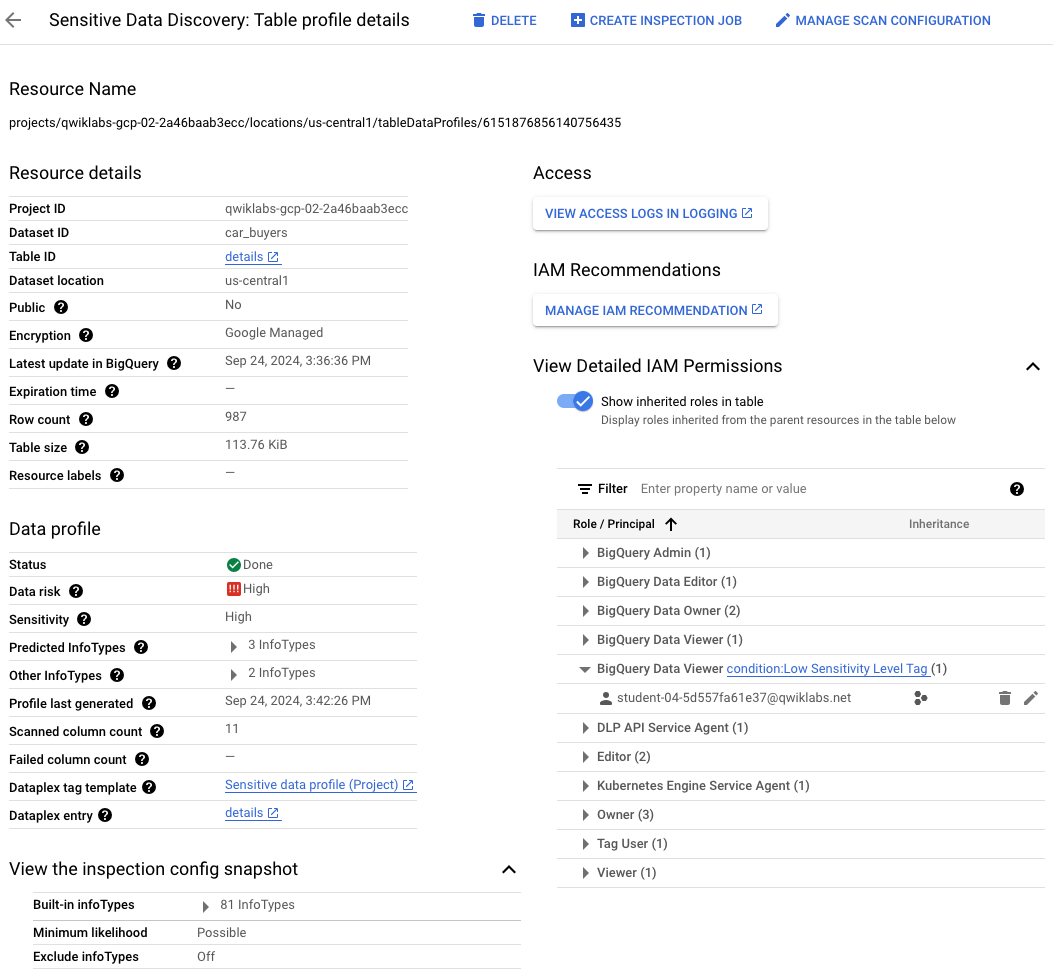
開いた [機密データの検出: Filestore のプロファイルの詳細] ページを確認します。
IAM 権限など、スキャンされたリソースに関する多くの詳細情報が表示されます。
[詳細な IAM 権限を表示] の横にある矢印を開きます。
[BigQuery 閲覧者] の横にある矢印を開きます。
別のユーザー(
このラボでは、一時停止モードで BigQuery の検出スキャン構成を作成しました。その後、BigQuery で機密データをフラグ付けするためのタグを作成し、作成したタグを自動スキャンに使用するよう検出スキャン構成を更新しました。最後に、作成したタグを使用して、追加のユーザーに BigQuery データへの条件付きアクセス権を付与しました。
BigQuery の Sensitive Data Protection について詳しくは、次のリソースをご覧ください。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 11 月 18 日
ラボの最終テスト日: 2024 年 11 月 18 日
Copyright 2026 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください
ラボを開始するには、この簡単な手順を完了してください。