

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Enable the pgaudit extension
/ 40
Create a read pool instance
/ 30
Create a backup
/ 30

AlloyDB for PostgreSQL は、特に要求の厳しいエンタープライズ データベース ワークロード向けに構築された PostgreSQL 互換のフルマネージド データベース サービスです。AlloyDB は、Google の強みと、特に人気のオープンソース データベース エンジンの一つである PostgreSQL を組み合わせて、優れたパフォーマンス、スケーリング、可用性を実現しています。
このラボでは、AlloyDB for PostgreSQL データベースを最適な形で使用するために不可欠な管理タスクを行います。
このラボでは、次のタスクの実行方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン 
ウィンドウで次の操作を行います。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
ラボの開始時に、AlloyDB クラスタとインスタンスがプロビジョニングされています。Cloud コンソールのナビゲーション メニュー(
クラスタの名前は lab-cluster、インスタンスの名前は lab-instance です。
インスタンスが完全に作成され、初期化されるまでにはしばらく時間がかかります。[ステータス] が [準備完了] になるまで待ってから、次の手順に進んでください。
インスタンス セクションのプライベート IP アドレスを確認します。後のステップで値を貼り付けられるよう、このプライベート IP アドレスをテキスト ファイルにコピーしておきます。
インスタンスは、enable_pgaudit データベース フラグがすでに設定された状態で構成されています。pgaudit は、標準のロギング メカニズムを使用して詳細なセッション監査ロギングとオブジェクト監査ロギングを提供する、PostgreSQL の一般的な機能です。pgaudit を完全に有効にするには、対応するデータベース拡張機能も有効にする必要があります。これについては、次のセクションで説明します。
[クラスタ内のインスタンス] セクションで、[lab-instance] を選択し、[プライマリを編集] をクリックします。
インスタンスにデータベース フラグを追加するには、[高度な構成のオプション] を開いて [データベース フラグを追加] をクリックします。
[フラグを選択] 内の利用可能なフラグのリストを参照して、サポートされているオプションを確認します。このラボでは、フラグは追加しません。
[キャンセル] を 2 回クリックして、[プライマリを編集] インスタンス画面を終了します。
前の手順に続いて、データベース拡張機能を設定して、AlloyDB クラスタの pgaudit 機能を完全に有効にします。
フラグの構成とは異なり、データベース拡張機能を有効にするには、psql クライアントを介してインスタンスに接続する必要があります。
ナビゲーション メニュー(
alloydb-client という名前のインスタンスの [接続] 列で、[SSH] をクリックしてターミナル ウィンドウを開きます。
次の環境変数を設定します。ALLOYDB_ADDRESS は、AlloyDB インスタンスのプライベート IP アドレスに置き換えます。
「\q」と入力して psql クライアントを終了します。
「exit」と入力して、ターミナル ウィンドウを閉じます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
読み取りプール インスタンスは、クラスタに必須ではありませんが、プライマリ インスタンスよりも適切にデータ分析ワークロードをサポートします。そのため、データ分析のニーズに最良の選択肢です。
読み取りプール インスタンスを追加するには、クラスタの [概要] ページの [クラスタ内のインスタンス] セクションで、[読み取りプールを追加] または [読み取りプール インスタンスを追加] をクリックします。
[読み取りプール インスタンス ID] に「lab-instance-rp1」と入力します。[ノード数] を [2] に設定します。
マシンタイプとして [2 vCPU、16 GB] を選択します。
[読み取りプールを作成] をクリックします。
読み取りプール インスタンスの作成には約 8~11 分かかります。
読み取りプール インスタンスが [概要] ページに表示されます。プライベート IP は、プライマリ インスタンスと同じアドレスプールにあります。直接 IP アドレスを使用すると、読み取り専用のクエリを読み取りプールに転送できるため、クラスタ全体のパフォーマンスが向上します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
すべての AlloyDB クラスタが作成されると、自動バックアップがデフォルトで構成されます。ただし、ワークロードの要件によっては、必要に応じてオンデマンドでバックアップを作成し、追加の復元オプションを用意することもできます。
Cloud コンソールのナビゲーション メニュー(
インスタンスが作成されてから間もないため、自動バックアップはありません。オンデマンド バックアップの作成に進みます。[バックアップを作成] をクリックします。
バックアップのソースとして lab-cluster が選択されていることを確認します。
バックアップの一意の ID を入力します。この場合は「lab-backup」と入力します。
[作成] をクリックします。
AlloyDB は、ソースクラスタが準備完了状態であることを確認してから、バックアップを実行する長時間実行オペレーションを開始します。[バックアップ] ページには、オペレーションが完了するまで、バックアップが進行中のステータスで表示されます。かかる時間はインスタンスのサイズによって異なりますが、ラボ環境ではバックアップは短時間(1 分以内)で作成されるはずです。
バックアップの復元は非常に簡単です。バックアップの行の最後にある [復元] リンクをクリックします。バックアップと提案された復元ターゲットの情報を確認します。このラボでは、作成したばかりのバックアップを復元しません。[キャンセル] をクリックしてウィザードを閉じます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
AlloyDB Monitoring ダッシュボードには、クラスタとインスタンスの使用状況、サイズ、パフォーマンスに関する多くの情報が含まれています。使用しているリソースの指標が表示され、傾向をモニタリングできます。
[クラスタの概要] で、ページの左側にある [モニタリング] リンクを選択します。
lab-instance でのアクティビティがほとんど発生していないため、現時点で表示されている指標からはあまり情報を得られません。そこで、Postgres ツール pgbench を使用して人工的なデータセットを生成し、シミュレートされたワークロードを実行して、lab-instance に一般的な負荷をかけます。
ナビゲーション メニュー(
alloydb-client という名前のインスタンスの [接続] 列で、[SSH] をクリックしてターミナル ウィンドウを開きます。
次のコマンドを実行して、ALLOYDB 環境変数を設定します。
最大のテーブル pgbench_accounts には 500 万行が読み込まれます。この操作は非常に短時間で完了します。
「\q」と入力して psql クライアントを終了します。
次の pgbench オペレーションを実行して、lab-instance に対するワークロードをシミュレートします。このオペレーションは、2 つのスレッドで 50 個のクライアントを 3 分間にわたって 30 秒ごとにポーリングする負荷に対応しています。postgres ユーザーのパスワード(Change3Me)を入力するよう求められます。
AlloyDB モニタリング ダッシュボードに戻り、期間を [1 時間] に設定します。下のタイルには、平均 CPU 使用率、最小使用可能メモリ、接続、1 秒あたりのトランザクション数、クラスタ ストレージ、最大レプリケーション ラグ、アクティブ ノードの詳細が表示されます。
左側の [Query Insights] リンクをクリックして、pgbench オペレーションがインスタンスに対して発行したクエリの詳細を確認します。
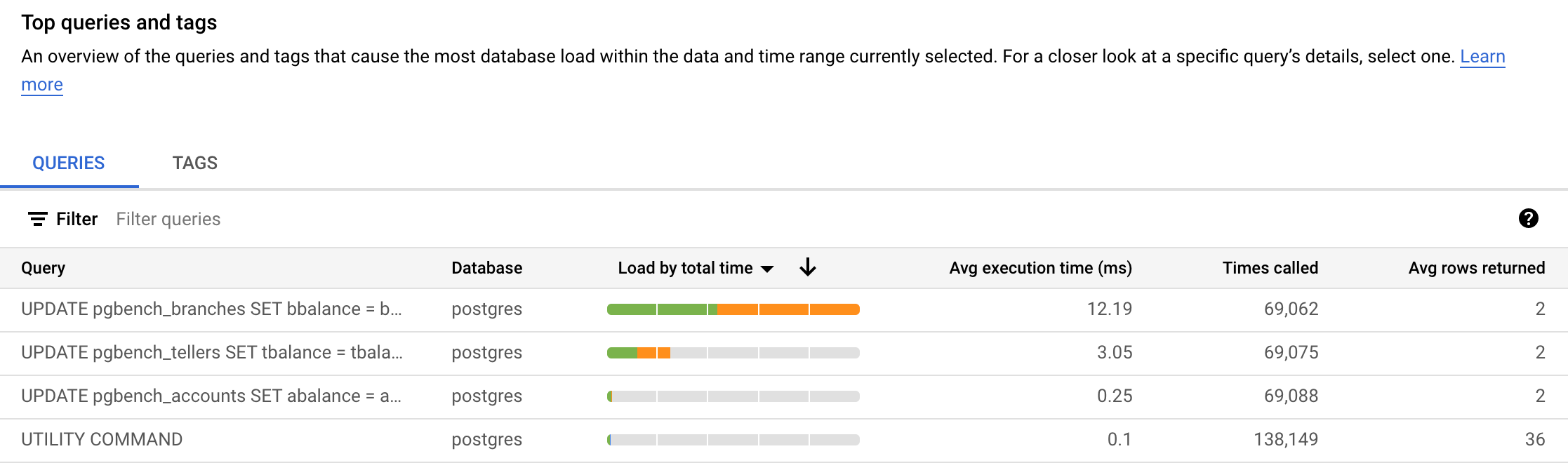
[上位のクエリとタグ] に、クエリの順序が表示されます。下の図では、クエリ UPDATE pgbench_branches SET ... が [負荷(合計実行時間別)] で上位のクエリになっています。実際の結果とは異なる場合があります。
[負荷(合計実行時間別)] 列にはセレクタ オプションがあります。負荷(CPU 別)、負荷(IO 待機別)、負荷(ロック待機別)でクエリを表示することもできます。
[上位のクエリとタグ] セクションの [クエリ] 列の値、またはダッシュボードの他の領域のリンクをクリックすると、クエリの詳細を確認できます。
これで、AlloyDB for PostgreSQL データベースを最適な形で使用するために不可欠な管理タスクが完了しました。
マニュアルの最終更新日: 2024 年 8 月 28 日
ラボの最終テスト日: 2024 年 8 月 24 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください