GSP1086

Présentation
AlloyDB pour PostgreSQL est un service de base de données entièrement géré compatible avec PostgreSQL pour les charges de travail d'entreprise les plus exigeantes. AlloyDB associe le meilleur de Google à l'un des moteurs de base de données Open Source les plus utilisés, PostgreSQL, pour des performances, une évolutivité et une disponibilité optimales.
Dans cet atelier, vous allez effectuer des tâches administratives essentielles pour exploiter efficacement une base de données AlloyDB pour PostgreSQL.
Objectifs de l'atelier
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Examiner un flag de base de données
- Configurer une extension de base de données
- Créer une instance de pool de lecture pour un cluster existant
- Configurer des sauvegardes
- Examiner la surveillance dans la console AlloyDB
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
-
Cliquez sur Activer Cloud Shell  en haut de la console Google Cloud.
en haut de la console Google Cloud.
-
Passez les fenêtres suivantes :
- Accédez à la fenêtre d'informations de Cloud Shell.
- Autorisez Cloud Shell à utiliser vos identifiants pour effectuer des appels d'API Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET : . Le résultat contient une ligne qui déclare l'ID_PROJET pour cette session :
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
- Cliquez sur Autoriser.
Résultat :
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Remarque : Pour consulter la documentation complète sur gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Examiner un flag de base de données
-
Un cluster et une instance AlloyDB ont été provisionnés au début de l'atelier. Dans le menu de navigation de la console Cloud ( ), cliquez sur AFFICHER TOUS LES PRODUITS. Dans la section Bases de données, cliquez sur AlloyDB, puis sur Clusters pour examiner les détails du cluster.
), cliquez sur AFFICHER TOUS LES PRODUITS. Dans la section Bases de données, cliquez sur AlloyDB, puis sur Clusters pour examiner les détails du cluster.
-
Le cluster s'appelle lab-cluster et l'instance lab-instance.
-
La création et l'initialisation complètes de l'instance prennent un certain temps. Veuillez attendre que l'état indique Prêt avant de continuer.
-
Notez l'adresse IP privée dans la section "Instances". Copiez l'adresse IP privée dans un fichier texte. Vous pourrez ainsi coller la valeur à une étape ultérieure.
-
L'instance a également été configurée avec le flag de base de données enable_pgaudit déjà défini. Pgaudit est une fonctionnalité populaire de PostgreSQL qui fournit une journalisation détaillée des sessions et des objets en utilisant le système de journalisation standard. Pour activer complètement pgaudit, vous devez aussi activer l'extension de base de données correspondante, ce que vous ferez dans la section suivante.
-
Dans la section Instances dans votre cluster, sélectionnez lab-instance, puis cliquez sur Modifier l'instance principale.
-
Pour ajouter un flag de base de données à votre instance, développez Options de configuration avancées, puis cliquez sur Ajouter un flag de base de données.
-
Parcourez la liste des flags disponibles (dans Sélectionner un indicateur) pour avoir une idée des options proposées. Vous n'ajouterez pas de flag supplémentaire dans cet atelier.
-
Cliquez deux fois sur Annuler pour quitter l'écran Modifier l'instance principale.
Tâche 2 : Configurer une extension de base de données
-
Vous allez maintenant configurer une extension de base de données afin d'activer complètement la fonctionnalité pgaudit pour votre cluster AlloyDB.
-
Contrairement à la configuration d'un flag, vous devez vous connecter à votre instance en utilisant le client psql pour activer une extension de base de données.
-
Dans le menu de navigation (), sous Compute Engine, cliquez sur Instances de VM.
-
Pour l'instance nommée alloydb-client, dans la colonne Connecter, cliquez sur SSH pour ouvrir une fenêtre de terminal.
-
Définissez la variable d'environnement suivante en remplaçant ALLOYDB_ADDRESS par l'adresse IP privée de l'instance AlloyDB.
export ALLOYDB=ALLOYDB_ADDRESS
- Exécutez la commande suivante pour stocker l'adresse IP privée de l'instance AlloyDB sur la VM cliente AlloyDB afin qu'elle soit conservée tout au long de l'atelier.
echo $ALLOYDB > alloydbip.txt
- Utilisez la commande suivante pour lancer le client PostgreSQL (psql). Vous serez invité à fournir le mot de passe de l'utilisateur postgres (Change3Me) que vous avez saisi lors de la création du cluster.
psql -h $ALLOYDB -U postgres
- L'invite de terminal psql s'affiche, comme illustré ci-dessous.
psql (14.5 (Debian 14.5-1.pgdg110+1), server 14.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=>
- Saisissez et exécutez les commandes SQL suivantes séparément pour activer l'extension.
\c postgres
CREATE EXTENSION IF NOT EXISTS PGAUDIT;
- Exécutez la requête système suivante pour afficher les détails de l'extension pgaudit.
select extname, extversion from pg_extension where extname = 'pgaudit';
extname | extversion
---------+------------
pgaudit | 1.6.1
(1 row)
-
Saisissez \q pour quitter le client psql.
-
Saisissez exit pour fermer la fenêtre de terminal.
-
Cliquez sur Vérifier ma progression pour valider l'objectif.
Activer l'extension pgaudit
Tâche 3 : Créer une instance de pool de lecture pour un cluster existant
- L'une des principales fonctionnalités d'AlloyDB pour PostgreSQL est l'implémentation d'instances de pool de lecture. Une instance de pool de lecture augmente la capacité de lecture de votre cluster en agrégeant les nœuds, que vous pouvez faire évoluer afin d'assurer une disponibilité élevée en lecture.
Il n'est pas obligatoire d'avoir des instances de pool de lecture dans un cluster, mais elles gèrent mieux les charges de travail d'analyse de données que les instances principales. C'est donc le meilleur choix pour vos besoins en analyse de données.
-
Pour ajouter une instance de pool de lecture, cliquez sur Ajouter un pool de lecture ou Ajouter une instance de pool de lecture dans la section Instances dans votre cluster de la page Présentation de votre cluster.
-
Pour l'ID de l'instance de pool de lecture, saisissez lab-instance-rp1. Définissez le nombre de nœuds sur 2.
-
Sélectionnez 2 vCPU, 16 Go comme type de machine.
-
Cliquez sur Créer un pool de lecture.
-
La création de l'instance de pool de lecture prend environ 8 à 11 minutes.
-
Votre instance de pool de lecture s'affiche désormais sur la page Présentation. Notez que l'adresse IP privée se trouve dans le même pool d'adresses IP que l'instance principale. L'adresse IP directe vous permet d'acheminer les requêtes de lecture vers le pool de lecture, améliorant ainsi les performances globales du cluster.
-
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une instance de pool de lecture
Tâche 4 : Configurer des sauvegardes
-
Les sauvegardes automatiques sont configurées par défaut lors de la création de chaque cluster AlloyDB. Toutefois, vous pouvez créer des sauvegardes à la demande, selon vos besoins, pour bénéficier d'options de récupération supplémentaires en fonction des exigences de la charge de travail.
-
Dans le menu de navigation de la console Cloud (), cliquez sur AFFICHER TOUS LES PRODUITS. Ensuite, sous Bases de données, cliquez sur AlloyDB, puis sur Sauvegardes pour ouvrir la page "Sauvegardes".
-
Votre instance a été créée trop récemment pour disposer de sauvegardes automatiques. Vous allez donc créer une sauvegarde à la demande. Cliquez sur Créer une sauvegarde.
-
Assurez-vous que lab-cluster est sélectionné comme source de la sauvegarde.
-
Saisissez un identifiant unique pour la sauvegarde. Ici, saisissez lab-backup.
-
Cliquez sur Créer.
AlloyDB vérifie que le cluster source est à l'état Prêt, puis lance une opération de longue durée pour effectuer la sauvegarde. La page Sauvegardes affiche la sauvegarde avec l'état En cours jusqu'à la fin de l'opération. La vitesse de sauvegarde varie en fonction de la taille de l'instance, mais dans l'environnement de l'atelier, elle devrait être créée rapidement (en moins d'une minute).
- Dans Cloud Shell, exécutez la commande ci-dessous pour afficher plus de détails sur votre sauvegarde.
gcloud beta alloydb backups list
-
La récupération d'une sauvegarde est très simple. Cliquez sur le lien Restaurer à la fin de la ligne de sauvegarde. Examinez les informations de la sauvegarde et la cible proposée pour la récupération. Pour cet atelier, vous n'allez pas restaurer la sauvegarde que vous venez de créer. Cliquez sur Annuler pour fermer l'assistant.
-
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une sauvegarde
Tâche 5 : Examiner la surveillance dans la console AlloyDB
-
Le tableau de bord de surveillance AlloyDB contient de nombreuses informations sur l'utilisation, la taille et les performances des clusters et des instances. Il affiche les métriques des ressources que vous utilisez et vous permet de surveiller les tendances qui en résultent.
-
Dans Aperçu du cluster, sélectionnez le lien Surveillance sur la gauche de la page.
-
Très peu d'activité a eu lieu sur lab-instance. Les métriques affichées pour le moment ne vous seront donc pas très utiles. À l'aide de l'outil Postgres pgbench, vous allez générer un ensemble de données synthétiques et exécuter une charge de travail simulée pour placer lab-instance sous une charge représentative.
-
Dans le menu de navigation (), sous Compute Engine, cliquez sur Instances de VM.
-
Pour l'instance nommée alloydb-client, dans la colonne Connecter, cliquez sur SSH pour ouvrir une fenêtre de terminal.
-
Définissez la variable d'environnement ALLOYDB en exécutant la commande suivante.
export ALLOYDB=$(cat alloydbip.txt)
- Pour utiliser pgbench, vous devez d'abord créer et remplir les exemples de tables. Exécutez la commande suivante pour créer un ensemble de quatre tables. Vous serez invité à saisir le mot de passe de l'utilisateur postgres, qui est Change3Me.
La plus grande table, pgbench_accounts, contiendra 5 millions de lignes. L'opération devrait être très rapide.
pgbench -h $ALLOYDB -U postgres -i -s 50 -F 90 -n postgres
pgbench create
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 9.49 s, remaining 0.00 s)
creating primary keys...
done in 13.71 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 9.98 s, primary keys 3.72 s).
- Connectez-vous au client psql et exécutez la requête suivante pour vérifier le nombre de lignes dans la table pgbench_accounts. Vous serez invité à saisir le mot de passe de l'utilisateur postgres, qui est Change3Me.
psql -h $ALLOYDB -U postgres
select count (*) from pgbench_accounts;
count
---------
5000000
(1 row)
-
Saisissez \q pour quitter le client psql.
-
Exécutez l'opération pgbench suivante pour simuler une charge de travail sur lab-instance. L'opération correspond à une charge de cinquante (50) clients, répartis sur deux (2) threads, interrogeant toutes les trente (30) secondes, pendant trois (3) minutes. Vous serez invité à saisir le mot de passe de l'utilisateur postgres, qui est Change3Me.
pgbench -h $ALLOYDB -U postgres -c 50 -j 2 -P 30 -T 180 postgres
- L'opération de charge de travail se termine et génère des statistiques pour l'exécution. Les détails sont semblables à ce qui suit :
pgbench (14.5 (Debian 14.5-1.pgdg110+1), server 14.4)
starting vacuum...end.
progress: 30.0 s, 1412.2 tps, lat 34.433 ms stddev 25.836
progress: 60.0 s, 1426.6 tps, lat 35.040 ms stddev 25.459
progress: 90.0 s, 1393.2 tps, lat 35.863 ms stddev 33.101
progress: 120.0 s, 1429.8 tps, lat 34.968 ms stddev 31.735
progress: 150.0 s, 1335.4 tps, lat 37.406 ms stddev 30.922
progress: 180.0 s, 1424.8 tps, lat 35.118 ms stddev 28.440
transaction type:
scaling factor: 50
query mode: simple
number of clients: 50
number of threads: 2
duration: 180 s
number of transactions actually processed: 252710
latency average = 35.458 ms
latency stddev = 29.391 ms
initial connection time = 801.012 ms
tps = 1409.393040 (without initial connection time)
-
Revenez au tableau de bord de surveillance AlloyDB et définissez l'horizon temporel sur 1 heure. Dans les blocs ci-dessous, vous trouverez des informations sur l'utilisation moyenne du processeur, la mémoire minimale disponible, les connexions, les transactions par seconde, l'espace de stockage du cluster, le délai maximal de réplication et les nœuds actifs.
-
Cliquez sur le lien Insights sur les requêtes à gauche pour obtenir des informations sur les requêtes que l'opération pgbench a émises sur l'instance.
-
Sous Requêtes et tags les plus fréquents, vous verrez une liste de requêtes. Dans l'image ci-dessous, la requête UPDATE pgbench_branches SET ... était la requête la plus fréquente en termes de charge par temps total. Vos résultats peuvent différer.
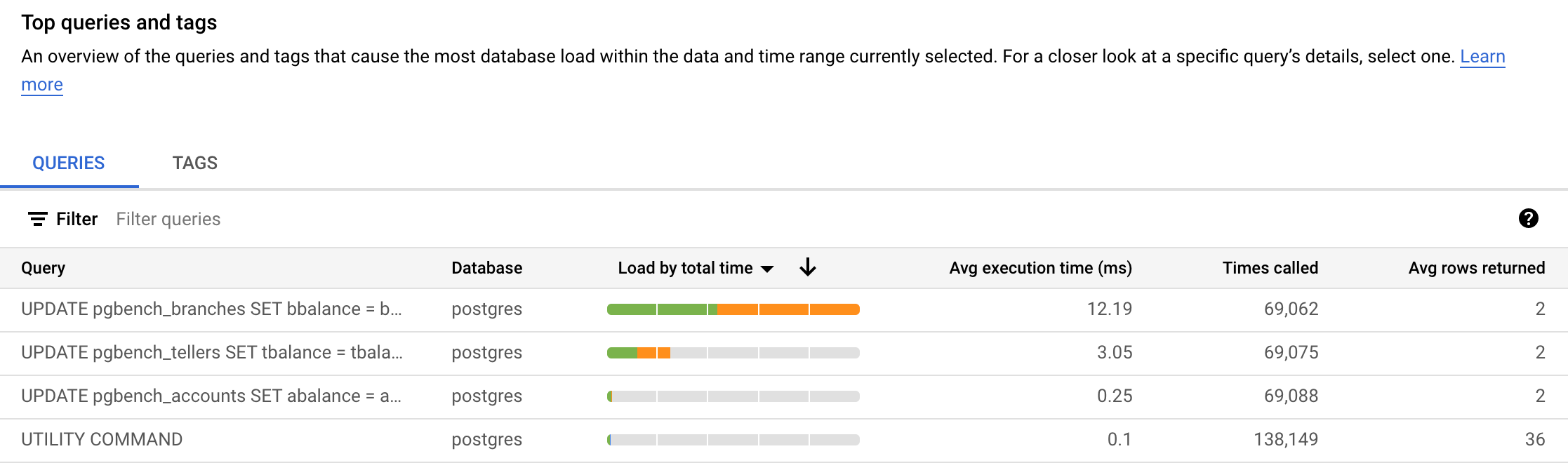
-
La colonne Charge par temps total comporte une option de sélection. Vous pouvez également afficher les requêtes par charge par processeur, charge par attente E/S et charge par attente de verrouillage.
-
Vous pouvez explorer les requêtes en détail en cliquant sur l'une des valeurs de la colonne Requête dans la section Requêtes et tags les plus fréquents ou sur les liens dans d'autres sections du tableau de bord.
Félicitations !
Vous avez effectué des tâches administratives essentielles pour exploiter efficacement une base de données AlloyDB pour PostgreSQL.
Dernière mise à jour du manuel : 28 août 2024
Dernier test de l'atelier : 28 août 2024
Copyright 2025 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.






