Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Aplique suas habilidades no console do Google Cloud
Checkpoints
Enable the Document AI API
Verificar meu progresso
/ 10
Create a processor
Verificar meu progresso
/ 20
Authenticate API requests
Verificar meu progresso
/ 30
Make a batch processing request
Verificar meu progresso
/ 20
Make a batch processing request for a directory
Verificar meu progresso
/ 20
Instruções e requisitos de configuração do laboratório
Proteja sua conta e seu progresso. Sempre use uma janela anônima do navegador e suas credenciais para realizar este laboratório.
Reconhecimento óptico de caracteres (OCR) com a Document AI (Python)
Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
GSP1138
Visão geral
A API Document AI é uma solução para compreensão de dados não estruturados, como documentos, e-mails, faturas, formulários etc., que facilita o entendimento, a análise e o uso desses dados. Essa API fornece uma estrutura por meio de classificação de conteúdo, extração de entidades, da pesquisa avançada e muito mais.
Neste laboratório, você vai realizar o reconhecimento óptico de caracteres (OCR) de documentos PDF usando Document AI e Python. Você vai aprender a fazer solicitações de processo on-line (síncronas) e em lote (assíncronas).
Vamos usar um arquivo PDF do romance clássico "O Ursinho Pooh" (Winnie the Pooh, no título original) de A.A. Milne, que recentemente entrou em domínio público nos Estados Unidos. Este arquivo foi verificado e digitalizado pelo Google Livros.
Objetivos
Neste laboratório, você vai aprender a fazer o seguinte:
ativar a API Document AI
autenticar as solicitações de API
Instalar a biblioteca de cliente para Python
Usar as APIs de processamento on-line e em lote
Analisar texto de um arquivo PDF
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
O botão Abrir Console do Google Cloud
O tempo restante
As credenciais temporárias que você vai usar neste laboratório
Outras informações, se forem necessárias
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
Clique em Próxima.
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
Acesse as próximas páginas:
Aceite os Termos e Condições.
Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
Clique nas seguintes janelas:
Continue na janela de informações do Cloud Shell.
Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
(Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
(Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Tarefa 1: ativar a API Document AI
Antes de começar a usar a Document AI, você precisa ativar a API.
Pesquise "API Document AI" na barra de pesquisa na parte de cima do console e clique em Ativar para usar a API no projeto do Google Cloud.
Use a barra de pesquisa para procurar "API Cloud Storage". Se ela ainda não estiver ativada, clique em Ativar.
Como alternativa, é possível ativar as APIs pelos comandos gcloud a seguir.
Clique em Verificar meu progresso para conferir o objetivo.
Ativar a API Document AI
Tarefa 2: criar e testar um processador
Primeiro, crie uma instância do processador de OCR de documentos que vai fazer a extração. É possível fazer isso com o Cloud Console ou a API de gerenciamento do processador.
No Menu de navegação, clique em Ver todos os produtos. Em Inteligência artificial, selecione Document AI.
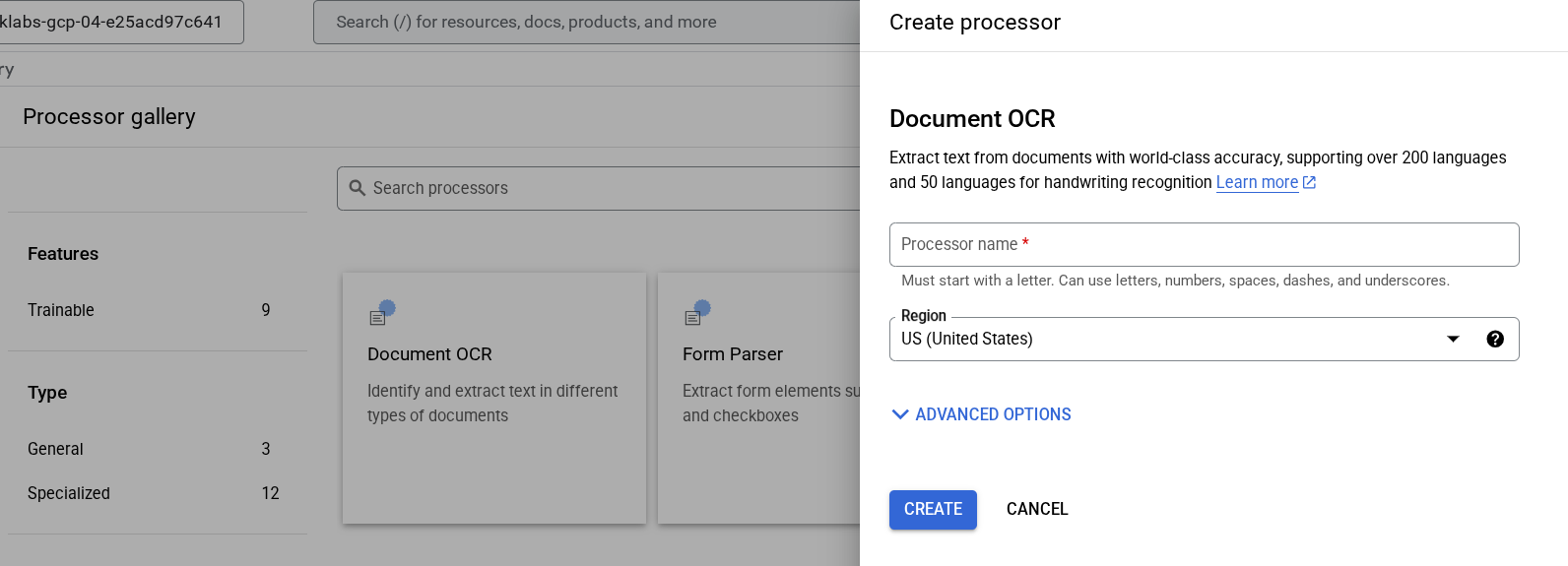
Clique em Acessar os processadores e em OCR de documentos.
Atribua o nome lab-ocr e selecione a região mais próxima na lista.
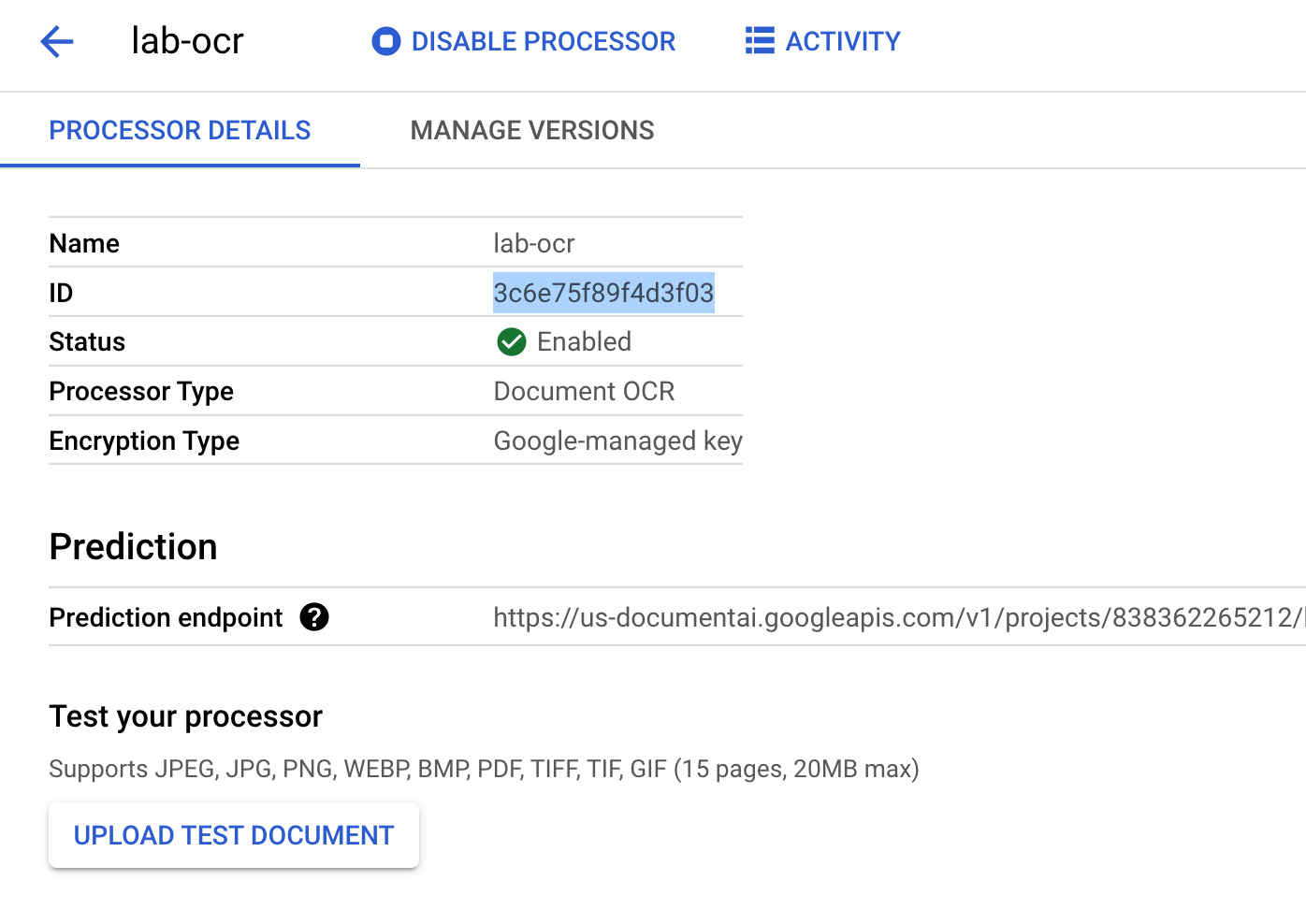
Clique em Criar para criar seu processador.
Copie o ID do processador. Você vai usá-lo no código mais tarde.
Baixe arquivo PDF abaixo, que contém as três primeiras páginas do romance "O Ursinho Pooh", de AA Milne.
Agora é possível fazer upload de um documento para testar o processador no console.
Clique em Fazer upload do documento de teste e selecione o arquivo PDF que você baixou.
A resposta será parecida com esta:
Clique em Verificar meu progresso para conferir o objetivo.
Crie e teste um processador
Tarefa 3: autenticar as solicitações de API
Para fazer solicitações à API Document AI, você precisa usar uma conta de serviço. Uma conta de serviço pertence ao seu projeto. Ela é usada pela biblioteca de cliente Python para fazer solicitações de API. Como qualquer outra conta de usuário, uma conta de serviço é representada por um endereço de e-mail. Nesta seção, você vai usar o SDK Cloud para criar uma conta de serviço e, em seguida, criar as credenciais necessárias para realizar a autenticação.
Primeiro, abra uma nova janela do Cloud Shell e defina uma variável de ambiente com o ID do projeto executando o seguinte comando:
Crie credenciais que o código Python usa para fazer login como a nova conta de serviço. Crie e salve essas credenciais como um arquivo JSON ~/key.json ao usar o seguinte comando:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Por fim, defina a variável de ambiente GOOGLE_APPLICATION_CREDENTIALS, que a biblioteca usa para encontrar suas credenciais. A variável de ambiente deve ser definida para o caminho completo do arquivo JSON de credenciais que você criou. Para isso, use:
Tarefa 5: fazer uma solicitação de processamento on-line
Nesta etapa, você vai processar as primeiras 3 páginas do romance usando a API de processamento on-line (síncrona). Esse método é mais adequado para documentos menores armazenados localmente. Confira a lista completa de processadores para saber o máximo de páginas e de tamanho de arquivo para cada tipo de processador.
No Cloud Shell, crie um arquivo chamado online_processing.py e cole o seguinte código nele:
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Read the file into memory
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# Configure the process request
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
Substitua YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID e FILE_PATH pelos valores adequados para seu ambiente.
Observação: FILE_PATH é o nome do arquivo que você enviou para o Cloud Shell na etapa anterior. Se você não renomeou o arquivo, ele deve ser Winnie_the_Pooh_3_Pages.pdf, que é o valor padrão e não precisa ser alterado.
Execute o código que vai extrair e imprimir o texto no console.
python3 online_processing.py
Você verá esta resposta:
Document processing complete.
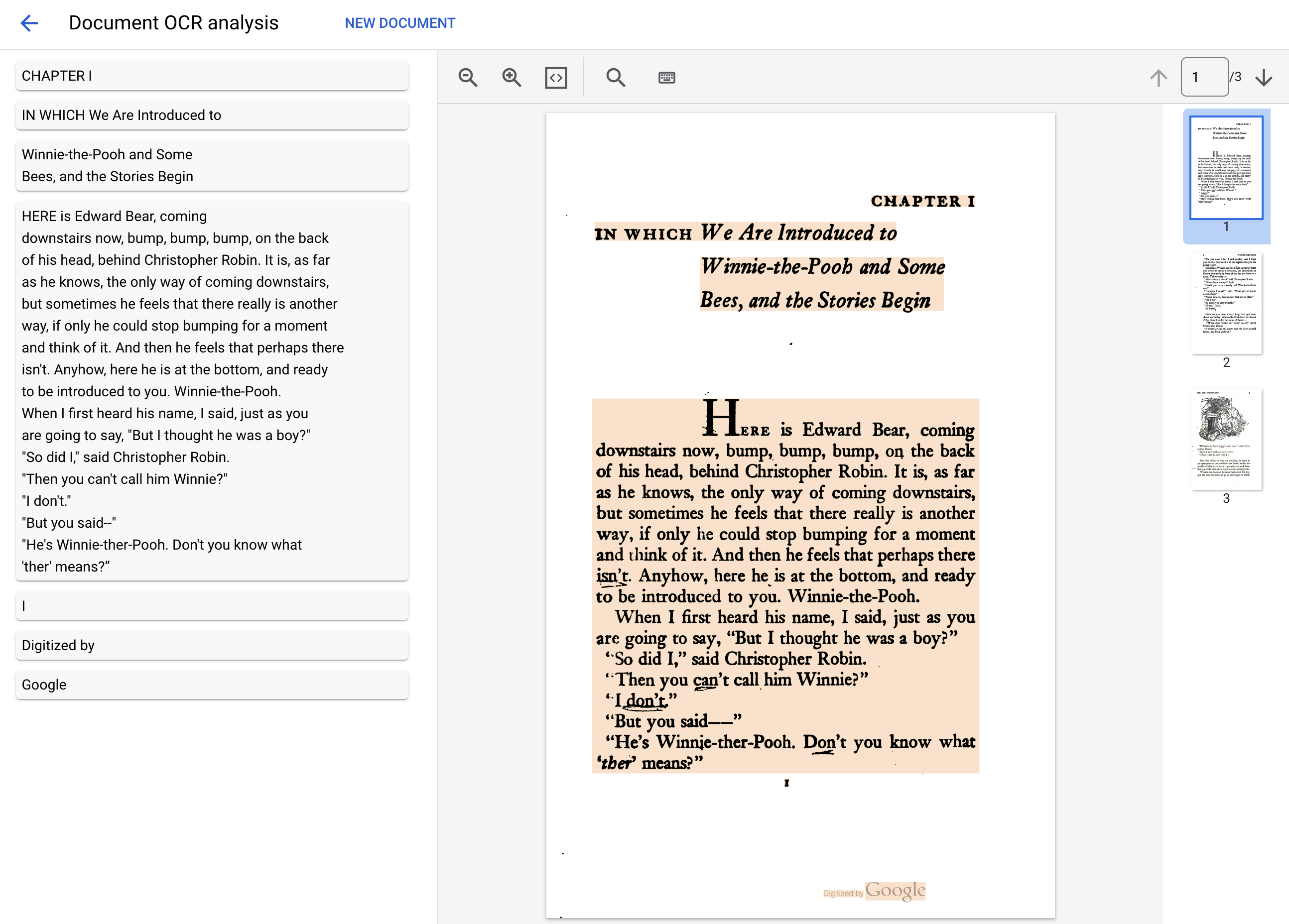
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
Tarefa 6: fazer uma solicitação de processamento em lote
Agora suponha que você queira ler o texto inteiro do romance.
O processamento on-line tem limites de número de páginas e de tamanho do arquivo para envio e permite apenas um arquivo de documento por chamada de API.
O processamento em lote permite o processamento de arquivos maiores/múltiplos em um método assíncrono.
Nesta seção, você vai processar todo o romance "O Ursinho Pooh" com a API de processamento em lote da Document AI e enviar o texto para um bucket do Google Cloud Storage.
O processamento em lote usa operações de longa duração para gerenciar solicitações de maneira assíncrona. Sendo assim, é preciso fazer a solicitação e recuperar a saída de uma maneira diferente do processamento on-line.
No entanto, a saída vai ter o mesmo formato de objeto Document, seja usando processamento on-line ou em lote.
Confira nesta seção como fornecer documentos específicos para a Document AI processar. Confira na seção posterior como processar um diretório inteiro de documentos.
Fazer upload do PDF no Cloud Storage
No momento, o método batch_process_documents() aceita arquivos do Google Cloud Storage. Consulte documentai_v1.types.BatchProcessRequest para mais informações sobre a estrutura do objeto.
Crie um bucket do Google Cloud Storage executando o comando a seguir para armazenar o arquivo PDF e fazer upload dele no bucket:
Crie um arquivo chamado batch_processing.py e cole o seguinte código:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory/file.pdf'
GCS_INPUT_URI = "gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf"
INPUT_MIME_TYPE = "application/pdf"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Document
input_document = documentai.GcsDocument(
gcs_uri=GCS_INPUT_URI, mime_type=INPUT_MIME_TYPE
)
# Load GCS Input URI into a List of document files
input_config = documentai.BatchDocumentsInputConfig(
gcs_documents=documentai.GcsDocuments(documents=[input_document])
)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Substitua YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, GCS_INPUT_URI e GCS_OUTPUT_URI pelos valores adequados para seu ambiente.
Em GCS_INPUT_URI, use o URI do arquivo que você enviou para o bucket na etapa anterior, ou seja, gs:///Winnie_the_Pooh.pdf.
Em GCS_OUTPUT_URI, use o URI do bucket criado na etapa anterior, ou seja, gs://.
Execute o código para exibir o texto completo do romance extraído e impresso no console.
python3 batch_processing.py
Observação: isso pode levar algum tempo para ser concluído, porque o arquivo é muito maior que o exemplo anterior. No entanto, com a API de processamento em lote, você recebe um ID de operação que pode ser usado para extrair a saída do Cloud Storage assim que a tarefa é concluída.
A saída será parecida com esta:
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
Ótimo! Você extraiu texto de um arquivo PDF usando a API Batch Processing da Document AI.
Clique em Verificar meu progresso para conferir o objetivo.
Faça uma solicitação de processamento em lote
Tarefa 7: fazer uma solicitação de processamento em lote para um diretório
Talvez você queira processar um diretório inteiro de documentos, sem listar cada documento individualmente. O método batch_process_documents() aceita a entrada de uma lista de documentos específicos ou um caminho de diretório.
Nesta seção, você vai aprender a processar um diretório completo de arquivos de documentos. A maior parte do código é igual à etapa anterior, a única diferença é o URI do GCS enviado com o BatchProcessRequest.
Execute o comando a seguir para copiar o diretório de amostra (que contém várias páginas do romance em arquivos separados) para seu bucket do Cloud Storage.
Leia os arquivos diretamente ou copie-os para o bucket do Cloud Storage.
Crie um arquivo chamado batch_processing_directory.py e cole o seguinte código:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory'
GCS_INPUT_PREFIX = "gs://cloud-samples-data/documentai/codelabs/ocr/multi-document"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Directory
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=GCS_INPUT_PREFIX)
# Load GCS Input URI into Batch Input Config
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Substitua PROJECT_ID, LOCATION, PROCESSOR_ID, GCS_INPUT_PREFIX e GCS_OUTPUT_URI pelos valores adequados para seu ambiente.
Em GCS_INPUT_PREFIX, use o URI do diretório que você enviou para o bucket na seção anterior, ou seja, gs:///multi-document.
Em GCS_OUTPUT_URI, use o URI do bucket criado na seção anterior, ou seja, gs://.
Use o comando a seguir para executar o código e exibir o texto extraído de todos os arquivos de documentos do diretório do Cloud Storage.
python3 batch_processing_directory.py
A saída será parecida com esta:
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
Ótimo! Você usou corretamente a biblioteca de cliente Python da Document AI para processar um diretório de documentos usando um processador da Document AI e gerar os resultados no Cloud Storage.
Clique em Verificar meu progresso para conferir o objetivo.
Faça uma solicitação de processamento em lote para um diretório
Parabéns!
Parabéns! Neste laboratório, você aprendeu a usar a biblioteca de cliente Python da Document AI para processar um diretório de documentos usando um processador da Document AI e gerar os resultados no Cloud Storage. Você também aprendeu a autenticar solicitações de API usando um arquivo de chave de conta de serviço, instalar a biblioteca de cliente Python da Document AI e usar as APIs on-line (síncronas) e em lote (assíncronas) para processar solicitações.
Próximas etapas/Saiba mais
Confira os recursos a seguir para saber mais sobre a Document AI e a biblioteca de cliente Python:
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 13 de junho de 2024
Laboratório testado em 13 de junho de 2024
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender a realizar o reconhecimento óptico de caracteres usando a API Document AI com Python.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 25 minutos



 na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.