Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Terapkan keterampilan Anda di Konsol Google Cloud
Checkpoint
Enable the Document AI API
Periksa progres saya
/ 10
Create a processor
Periksa progres saya
/ 20
Authenticate API requests
Periksa progres saya
/ 30
Make a batch processing request
Periksa progres saya
/ 20
Make a batch processing request for a directory
Periksa progres saya
/ 20
Petunjuk dan persyaratan penyiapan lab
Lindungi akun dan progres Anda. Selalu gunakan jendela browser pribadi dan kredensial lab untuk menjalankan lab ini.
Pengenalan Karakter Optik (OCR) dengan Document AI (Python)
Lab
25 menit
universal_currency_alt
5 Kredit
show_chart
Menengah
info
Lab ini mungkin menggabungkan alat AI untuk mendukung pembelajaran Anda.
Konten ini belum dioptimalkan untuk perangkat seluler.
Untuk pengalaman terbaik, kunjungi kami dengan komputer desktop menggunakan link yang dikirim melalui email.
GSP1138
Ringkasan
Document AI adalah solusi pemahaman dokumen yang memproses data tidak terstruktur (misalnya dokumen, email, invoice, formulir, dll.) dan membuat data tersebut lebih mudah dipahami, dianalisis, dan digunakan. API-nya memberikan struktur melalui klasifikasi konten, ekstraksi entity, penelusuran lanjutan, dan lainnya.
Dalam lab ini, Anda akan melakukan Pengenalan Karakter Optik (OCR) terhadap dokumen PDF menggunakan Document AI dan Python. Anda akan mempelajari cara membuat permintaan proses Online (Sinkron) dan Batch (Asinkron).
Kita akan menggunakan file PDF dari novel klasik "Winnie the Pooh" karya A.A. Milne, yang baru-baru ini menjadi bagian Domain Publik di Amerika Serikat. File ini dipindai dan didigitalkan oleh Google Buku.
Tujuan
Di lab ini, Anda akan mempelajari cara melakukan tugas berikut:
Mengaktifkan Document AI API
Melakukan Autentikasi permintaan API
Menginstal library klien untuk Python
Menggunakan API batch processing dan pemrosesan online
Mengurai teks dari file PDF
Penyiapan dan persyaratan
Sebelum mengklik tombol Start Lab
Baca petunjuk ini. Lab memiliki timer dan Anda tidak dapat menjedanya. Timer yang dimulai saat Anda mengklik Start Lab akan menampilkan durasi ketersediaan resource Google Cloud untuk Anda.
Lab interaktif ini dapat Anda gunakan untuk melakukan aktivitas lab di lingkungan cloud sungguhan, bukan di lingkungan demo atau simulasi. Untuk mengakses lab ini, Anda akan diberi kredensial baru yang bersifat sementara dan dapat digunakan untuk login serta mengakses Google Cloud selama durasi lab.
Untuk menyelesaikan lab ini, Anda memerlukan:
Akses ke browser internet standar (disarankan browser Chrome).
Catatan: Gunakan jendela Samaran (direkomendasikan) atau browser pribadi untuk menjalankan lab ini. Hal ini akan mencegah konflik antara akun pribadi Anda dan akun siswa yang dapat menyebabkan tagihan ekstra pada akun pribadi Anda.
Waktu untuk menyelesaikan lab. Ingat, setelah dimulai, lab tidak dapat dijeda.
Catatan: Hanya gunakan akun siswa untuk lab ini. Jika Anda menggunakan akun Google Cloud yang berbeda, Anda mungkin akan dikenai tagihan ke akun tersebut.
Cara memulai lab dan login ke Google Cloud Console
Klik tombol Start Lab. Jika Anda perlu membayar lab, dialog akan terbuka untuk memilih metode pembayaran.
Di sebelah kiri ada panel Lab Details yang berisi hal-hal berikut:
Tombol Open Google Cloud console
Waktu tersisa
Kredensial sementara yang harus Anda gunakan untuk lab ini
Informasi lain, jika diperlukan, untuk menyelesaikan lab ini
Klik Open Google Cloud console (atau klik kanan dan pilih Open Link in Incognito Window jika Anda menjalankan browser Chrome).
Lab akan menjalankan resource, lalu membuka tab lain yang menampilkan halaman Sign in.
Tips: Atur tab di jendela terpisah secara berdampingan.
Catatan: Jika Anda melihat dialog Choose an account, klik Use Another Account.
Jika perlu, salin Username di bawah dan tempel ke dialog Sign in.
{{{user_0.username | "Username"}}}
Anda juga dapat menemukan Username di panel Lab Details.
Klik Next.
Salin Password di bawah dan tempel ke dialog Welcome.
{{{user_0.password | "Password"}}}
Anda juga dapat menemukan Password di panel Lab Details.
Klik Next.
Penting: Anda harus menggunakan kredensial yang diberikan lab. Jangan menggunakan kredensial akun Google Cloud Anda.
Catatan: Menggunakan akun Google Cloud sendiri untuk lab ini dapat dikenai biaya tambahan.
Klik halaman berikutnya:
Setujui persyaratan dan ketentuan.
Jangan tambahkan opsi pemulihan atau autentikasi 2 langkah (karena ini akun sementara).
Jangan mendaftar uji coba gratis.
Setelah beberapa saat, Konsol Google Cloud akan terbuka di tab ini.
Catatan: Untuk mengakses produk dan layanan Google Cloud, klik Navigation menu atau ketik nama layanan atau produk di kolom Search.
Mengaktifkan Cloud Shell
Cloud Shell adalah mesin virtual yang dilengkapi dengan berbagai alat pengembangan. Mesin virtual ini menawarkan direktori beranda persisten berkapasitas 5 GB dan berjalan di Google Cloud. Cloud Shell menyediakan akses command-line untuk resource Google Cloud Anda.
Klik Activate Cloud Shell di bagian atas Konsol Google Cloud.
Klik jendela berikut:
Lanjutkan melalui jendela informasi Cloud Shell.
Beri otorisasi ke Cloud Shell untuk menggunakan kredensial Anda guna melakukan panggilan Google Cloud API.
Setelah terhubung, Anda sudah diautentikasi, dan project ditetapkan ke Project_ID, . Output berisi baris yang mendeklarasikan Project_ID untuk sesi ini:
Project Cloud Platform Anda dalam sesi ini disetel ke {{{project_0.project_id | "PROJECT_ID"}}}
gcloud adalah alat command line untuk Google Cloud. Alat ini sudah terinstal di Cloud Shell dan mendukung pelengkapan command line.
(Opsional) Anda dapat menampilkan daftar nama akun yang aktif dengan perintah ini:
gcloud auth list
Klik Authorize.
Output:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Untuk menetapkan akun aktif, jalankan:
$ gcloud config set account `ACCOUNT`
(Opsional) Anda dapat menampilkan daftar ID project dengan perintah ini:
gcloud config list project
Output:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Catatan: Untuk mendapatkan dokumentasi gcloud yang lengkap di Google Cloud, baca panduan ringkasan gcloud CLI.
Tugas 1. Mengaktifkan Document AI API
Sebelum dapat mulai menggunakan Document AI, Anda harus mengaktifkan API.
Dengan menggunakan Kotak Penelusuran di bagian atas konsol, cari "Document AI API", lalu klik Enable untuk menggunakan API di project Google Cloud Anda.
Gunakan kotak penelusuran untuk menelusuri "Cloud Storage API", jika belum diaktifkan, klik Enable.
Atau, API dapat diaktifkan menggunakan perintah gcloud berikut.
Klik Check my progress untuk memverifikasi tujuan.
Mengaktifkan Document AI API
Tugas 2. Membuat dan menguji pemroses
Pertama-tama, Anda harus membuat instance pemroses pOCR Dokumen yang akan melakukan ekstraksi. Hal ini dapat dilakukan menggunakan Konsol Cloud atau Processor Management API.
Dari Menu Navigasi, klik View All Products. Di bagian Artificial Intelligence, pilih Document AI.
Klik Explore Processors, lalu klik Document OCR.
Beri nama lab-ocr dan pilih region terdekat di daftar.
Klik Create untuk membuat pemroses
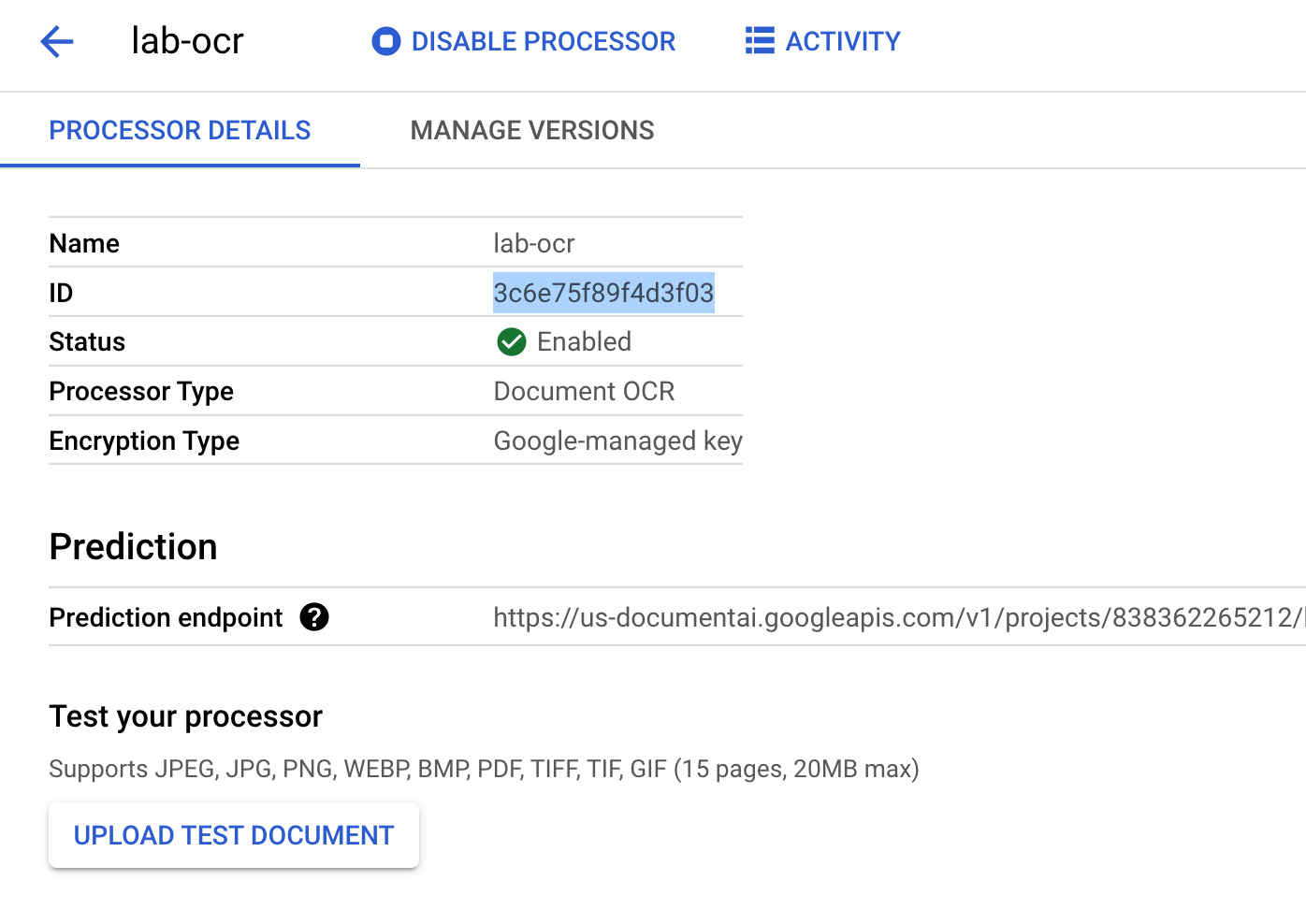
Salin ID Pemroses Anda. Anda harus menggunakan ini dalam kode nanti.
Download file PDF di bawah ini, yang berisi 3 halaman pertama novel "Winnie the Pooh" karya A.A. Milne.
Kini Anda dapat menguji pemroses di konsol dengan mengupload dokumen.
Klik Upload Test Document dan pilih file PDF yang Anda download.
Output Anda akan terlihat seperti ini:
Klik Check my progress untuk memverifikasi tujuan.
Membuat dan menguji pemroses
Tugas 3. Melakukan Autentikasi permintaan API
Untuk membuat permintaan ke Document AI API, Anda harus menggunakan Akun Layanan. Akun Layanan merupakan milik project Anda dan digunakan oleh library Klien Python untuk membuat permintaan API. Seperti akun pengguna lainnya, akun layanan diwakili oleh alamat email. Di bagian ini, Anda akan menggunakan Cloud SDK untuk membuat akun layanan, lalu membuat kredensial yang diperlukan untuk melakukan autentikasi sebagai akun layanan.
Pertama, buka jendela Cloud Shell baru dan tetapkan variabel lingkungan dengan Project ID Anda dengan menjalankan perintah berikut:
Buat kredensial yang digunakan kode Python Anda untuk login sebagai akun layanan baru. Buat kredensial ini dan simpan sebagai file JSON ~/key.json menggunakan perintah berikut:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Terakhir, tetapkan variabel lingkungan GOOGLE_APPLICATION_CREDENTIALS, yang digunakan oleh library untuk menemukan kredensial Anda. Variabel lingkungan harus ditetapkan ke jalur lengkap file JSON kredensial yang Anda buat menggunakan:
Pada langkah ini, Anda akan memproses 3 halaman pertama novel menggunakan API pemrosesan online (sinkron). Metode ini paling cocok untuk dokumen kecil yang disimpan secara lokal. Lihat daftar lengkap pemroses untuk mengetahui halaman maksimum dan ukuran file untuk setiap jenis pemroses.
Di Cloud Shell, buat file bernama online_processing.py dan tempelkan kode berikut ke dalamnya:
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Read the file into memory
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# Configure the process request
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
Ganti YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, dan FILE_PATH dengan nilai yang sesuai untuk lingkungan Anda.
Catatan:FILE_PATH adalah nama file yang Anda upload ke Cloud Shell pada langkah sebelumnya. Jika Anda tidak mengganti nama file, file tersebut akan menjadi Winnie_the_Pooh_3_Pages.pdf yang merupakan nilai default dan tidak perlu diubah.
Jalankan kode, yang akan mengekstrak teks dan mencetaknya ke konsol.
python3 online_processing.py
Anda akan melihat output berikut:
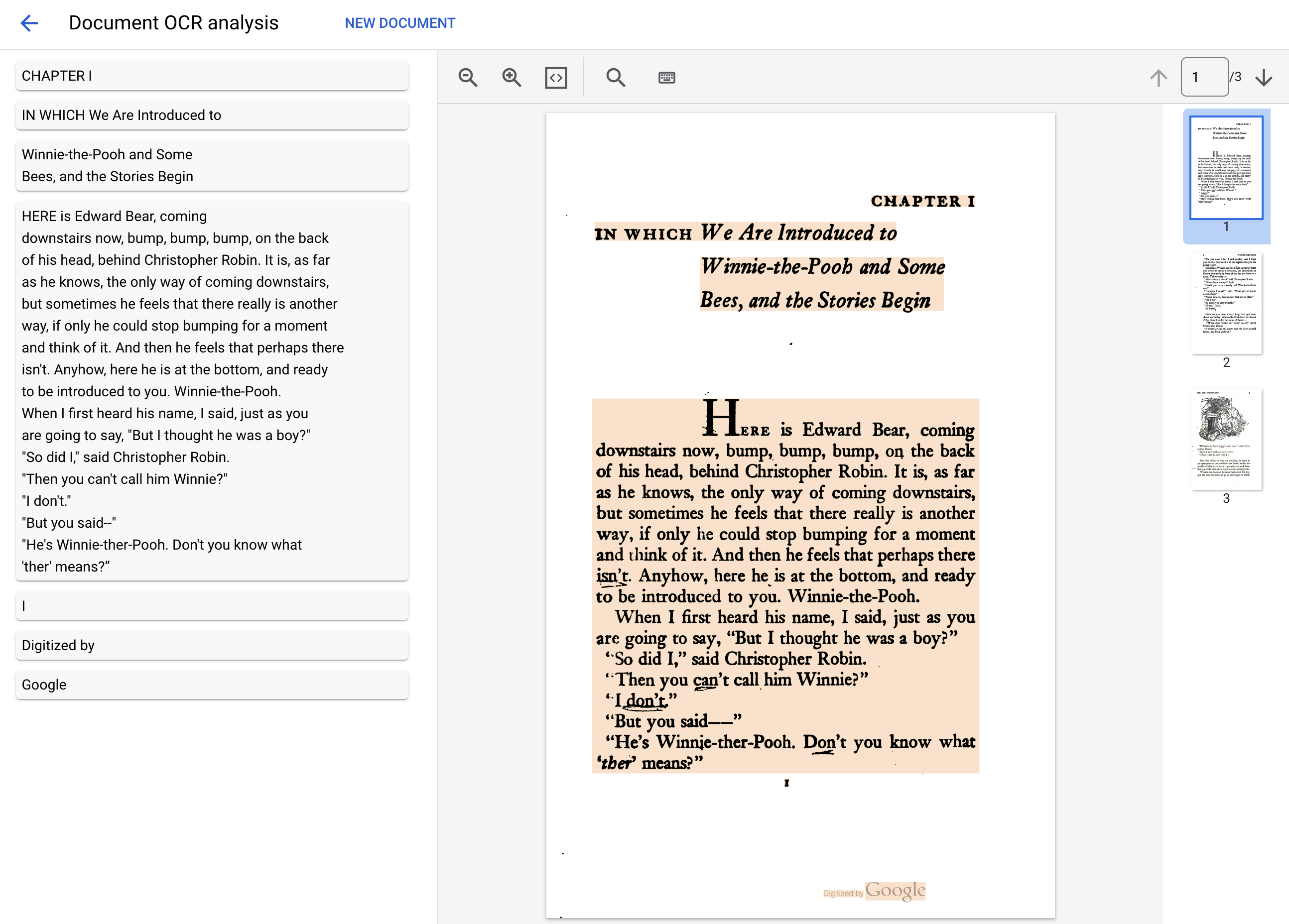
Document processing complete.
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
Tugas 6. Membuat permintaan batch processing
Sekarang, misalkan Anda ingin membaca teks dari seluruh novel.
Pemrosesan Online memiliki batasan jumlah halaman dan ukuran file yang dapat dikirim dan hanya mengizinkan satu file dokumen per panggilan API.
Batch Processing dapat dilakukan untuk melakukan pemrosesan file yang lebih besar/banyak dalam metode asinkron.
Pada bagian ini, Anda akan memproses seluruh novel "Winnie the Pooh" dengan Document AI Batch Processing API dan menampilkan teks ke dalam Bucket Google Cloud Storage.
Batch processing menggunakan Operasi yang Berjalan Lama untuk mengelola permintaan secara asinkron. Jadi, kita harus membuat permintaan dan mengambil output dengan cara yang berbeda dari pemrosesan online.
Namun, outputnya akan memiliki format objek Document yang sama, baik menggunakan pemrosesan online atau batch processing.
Bagian ini menunjukkan cara menyediakan dokumen khusus untuk diproses oleh Document AI. Bagian berikutnya akan menunjukkan cara memproses seluruh direktori dokumen.
Mengupload PDF ke Cloud Storage
Metode batch_process_documents() saat ini menerima file dari Google Cloud Storage. Anda dapat merujuk documentai_v1.types.BatchProcessRequest untuk mengetahui informasi selengkapnya tentang struktur objek.
Jalankan perintah berikut untuk membuat Bucket Google Cloud Storage guna menyimpan file PDF dan mengupload file PDF ke bucket:
Buat file bernama batch_processing.py dan tempelkan kode berikut:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory/file.pdf'
GCS_INPUT_URI = "gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf"
INPUT_MIME_TYPE = "application/pdf"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Document
input_document = documentai.GcsDocument(
gcs_uri=GCS_INPUT_URI, mime_type=INPUT_MIME_TYPE
)
# Load GCS Input URI into a List of document files
input_config = documentai.BatchDocumentsInputConfig(
gcs_documents=documentai.GcsDocuments(documents=[input_document])
)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Ganti YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, GCS_INPUT_URI, dan GCS_OUTPUT_URI dengan nilai yang sesuai untuk lingkungan Anda.
Untuk GCS_INPUT_URI, gunakan URI file yang Anda upload ke bucket pada langkah sebelumnya, yaitu gs:///Winnie_the_Pooh.pdf.
Untuk GCS_OUTPUT_URI, gunakan URI bucket yang Anda buat pada langkah sebelumnya, yaitu gs://.
Jalankan kodenya, dan Anda akan melihat teks lengkap novel diekstraksi dan dicetak di konsol Anda.
python3 batch_processing.py
Catatan: Proses ini mungkin memerlukan waktu beberapa saat untuk diselesaikan karena file ini jauh lebih besar daripada contoh sebelumnya. Namun, dengan Batch Processing API, Anda akan menerima ID Operasi yang dapat digunakan untuk mendapatkan output dari Cloud Storage setelah tugas selesai.
Output Anda akan terlihat seperti ini:
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
Bagus! Anda kini telah berhasil mengekstrak teks dari file PDF menggunakan Document AI Batch Processing API.
Klik Check my progress untuk memverifikasi tujuan.
Membuat permintaan batch processing
Tugas 7. Membuat permintaan batch processing untuk sebuah direktori
Terkadang, Anda mungkin ingin memproses seluruh direktori dokumen, tanpa mencantumkan setiap dokumen satu per satu. Metode batch_process_documents() mendukung input berupa daftar dokumen tertentu atau jalur direktori.
Di bagian ini, Anda akan mempelajari cara memproses direktori lengkap file dokumen. Sebagian besar kodenya sama dengan yang ada di langkah sebelumnya. Satu-satunya perbedaan adalah URI GCS yang dikirim dengan BatchProcessRequest.
Jalankan perintah berikut untuk menyalin direktori contoh (yang berisi beberapa halaman novel dalam file terpisah) ke bucket Cloud Storage Anda.
Anda dapat membaca file secara langsung atau menyalinnya ke dalam bucket Cloud Storage Anda sendiri.
Buat file bernama batch_processing_directory.py lalu tempelkan kode berikut:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory'
GCS_INPUT_PREFIX = "gs://cloud-samples-data/documentai/codelabs/ocr/multi-document"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Directory
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=GCS_INPUT_PREFIX)
# Load GCS Input URI into Batch Input Config
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Ganti PROJECT_ID, LOCATION, PROCESSOR_ID, GCS_INPUT_PREFIX, dan GCS_OUTPUT_URI dengan nilai yang sesuai untuk lingkungan Anda.
Untuk GCS_INPUT_PREFIX, gunakan URI direktori yang Anda upload ke bucket di bagian sebelumnya, yaitu gs:///multi-document.
Untuk GCS_OUTPUT_URI, gunakan URI bucket yang Anda buat di bagian sebelumnya, yaitu gs://.
Gunakan perintah berikut untuk menjalankan kode, dan Anda akan melihat teks yang diekstrak dari semua file dokumen di direktori Cloud Storage.
python3 batch_processing_directory.py
Output Anda akan terlihat seperti ini:
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
Bagus! Anda telah berhasil menggunakan Library Klien Python Document AI untuk memproses direktori dokumen menggunakan Pemroses Document AI, dan menampilkan output ke Cloud Storage.
Klik Check my progress untuk memverifikasi tujuan.
Membuat permintaan batch processing untuk sebuah direktori
Selamat!
Selamat! Di lab ini, Anda telah mempelajari cara menggunakan Library Klien Python Document AI untuk memproses direktori dokumen menggunakan Pemroses Document AI, dan menampilkan hasilnya ke Cloud Storage. Anda juga mempelajari cara mengautentikasi permintaan API menggunakan file kunci akun layanan, menginstal Library Klien Python Document AI, dan menggunakan API Online (Sinkron) dan Batch (Asinkron) untuk memproses permintaan.
Langkah berikutnya/Pelajari lebih lanjut
Lihat referensi berikut untuk mempelajari Document AI dan Library Klien Python lebih lanjut:
...membantu Anda mengoptimalkan teknologi Google Cloud. Kelas kami mencakup keterampilan teknis dan praktik terbaik untuk membantu Anda memahami dengan cepat dan melanjutkan proses pembelajaran. Kami menawarkan pelatihan tingkat dasar hingga lanjutan dengan opsi on demand, live, dan virtual untuk menyesuaikan dengan jadwal Anda yang sibuk. Sertifikasi membantu Anda memvalidasi dan membuktikan keterampilan serta keahlian Anda dalam teknologi Google Cloud.
Manual Terakhir Diperbarui pada 13 Juni 2024
Lab Terakhir Diuji pada 13 Juni 2024
Hak cipta 2026 Google LLC. Semua hak dilindungi undang-undang. Google dan logo Google adalah merek dagang dari Google LLC. Semua nama perusahaan dan produk lain mungkin adalah merek dagang masing-masing perusahaan yang bersangkutan.
Lab membuat project dan resource Google Cloud untuk jangka waktu tertentu
Lab memiliki batas waktu dan tidak memiliki fitur jeda. Jika lab diakhiri, Anda harus memulainya lagi dari awal.
Di kiri atas layar, klik Start lab untuk memulai
Gunakan penjelajahan rahasia
Salin Nama Pengguna dan Sandi yang diberikan untuk lab tersebut
Klik Open console dalam mode pribadi
Login ke Konsol
Login menggunakan kredensial lab Anda. Menggunakan kredensial lain mungkin menyebabkan error atau dikenai biaya.
Setujui persyaratan, dan lewati halaman resource pemulihan
Jangan klik End lab kecuali jika Anda sudah menyelesaikan lab atau ingin mengulanginya, karena tindakan ini akan menghapus pekerjaan Anda dan menghapus project
Konten ini tidak tersedia untuk saat ini
Kami akan memberi tahu Anda melalui email saat konten tersedia
Bagus!
Kami akan menghubungi Anda melalui email saat konten tersedia
Satu lab dalam satu waktu
Konfirmasi untuk mengakhiri semua lab yang ada dan memulai lab ini
Gunakan penjelajahan rahasia untuk menjalankan lab
Menggunakan jendela Samaran atau browser pribadi adalah cara terbaik untuk menjalankan lab ini. Langkah ini akan mencegah konflik antara akun pribadi Anda dan akun Siswa, yang dapat menyebabkan tagihan ekstra pada akun pribadi Anda.
Di lab ini, Anda akan mempelajari cara melakukan Pengenalan Karakter Optik menggunakan Document AI API dengan Python.



 di bagian atas Konsol Google Cloud.
di bagian atas Konsol Google Cloud.