Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Ihre Kompetenzen in der Google Cloud Console anwenden
Prüfpunkte
Enable the Document AI API
Fortschritt prüfen
/ 10
Create a processor
Fortschritt prüfen
/ 20
Authenticate API requests
Fortschritt prüfen
/ 30
Make a batch processing request
Fortschritt prüfen
/ 20
Make a batch processing request for a directory
Fortschritt prüfen
/ 20
Anleitung und Anforderungen für Lab-Einrichtung
Schützen Sie Ihr Konto und Ihren Fortschritt. Verwenden Sie immer den privaten Modus und Lab-Anmeldedaten, um dieses Lab auszuführen.
Optische Zeichenerkennung (OCR) mit Document AI (Python)
Dieser Inhalt ist noch nicht für Mobilgeräte optimiert.
Die Lernumgebung funktioniert am besten, wenn Sie auf einem Computer über einen per E‑Mail gesendeten Link darauf zugreifen.
GSP1138
Übersicht
Document AI ist eine Lösung zur Dokumentverarbeitung, die unstrukturierte Daten (z. B. Dokumente, E‑Mails, Rechnungen, Formulare usw.) leichter verständlich, analysierbar und nutzbar macht. Über die API stehen Funktionen wie Inhaltsklassifizierung, Entitätsextraktion, erweiterte Suche und weitere Optionen zur Verfügung.
In diesem Lab führen Sie die optische Zeichenerkennung (Optical Character Recognition, OCR) in PDF-Dokumenten mit Document AI und Python durch. Sie lernen, wie Sie sowohl Online- (synchron) als auch Batchverarbeitungsanfragen (asynchron) stellen.
Wir verwenden eine PDF-Datei des Klassikers „Winnie the Pooh“ von A. A. Milne (auf Englisch), der seit Kurzem in den Vereinigten Staaten frei von Urheberrechten ist. Diese Datei wurde von Google Books gescannt und digitalisiert.
Ziele
Aufgaben in diesem Lab:
Document AI API aktivieren
API-Anfragen authentifizieren
Clientbibliothek für Python installieren
APIs für Online- und Batchverarbeitung verwenden
Text aus einer PDF-Datei parsen
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
Schaltfläche „Google Cloud Console öffnen“
Restzeit
Temporäre Anmeldedaten für das Lab
Ggf. weitere Informationen für dieses Lab
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
Klicken Sie auf Weiter.
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
Klicken Sie sich durch die nachfolgenden Seiten:
Akzeptieren Sie die Nutzungsbedingungen.
Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.
Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
Klicken Sie sich durch die folgenden Fenster:
Fahren Sie mit dem Informationsfenster zu Cloud Shell fort.
Autorisieren Sie Cloud Shell, Ihre Anmeldedaten für Google Cloud API-Aufrufe zu verwenden.
Wenn eine Verbindung besteht, sind Sie bereits authentifiziert und das Projekt ist auf Project_ID, eingestellt. Die Ausgabe enthält eine Zeile, in der die Project_ID für diese Sitzung angegeben ist:
Ihr Cloud-Projekt in dieser Sitzung ist festgelegt als {{{project_0.project_id | "PROJECT_ID"}}}
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
(Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
Klicken Sie auf Autorisieren.
Ausgabe:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Um das aktive Konto festzulegen, führen Sie diesen Befehl aus:
$ gcloud config set account `ACCOUNT`
(Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Hinweis: Die vollständige Dokumentation für gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
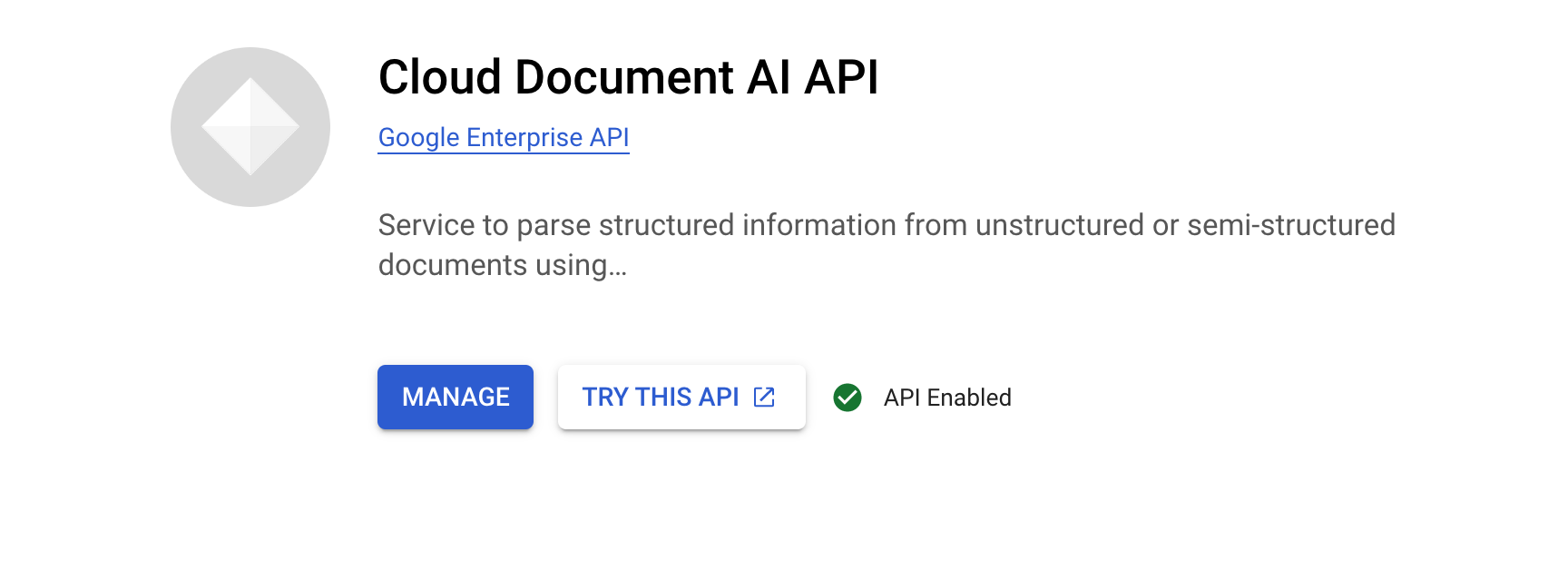
Aufgabe 1: Document AI API aktivieren
Bevor Sie mit Document AI arbeiten können, müssen Sie die API aktivieren.
Suchen Sie über die Suchleiste oben in der Console nach „Document AI API“ und klicken Sie dann auf Aktivieren, um die API in Ihrem Google Cloud-Projekt zu verwenden.
Suchen Sie in der Suchleiste nach „Cloud Storage API“ und klicken Sie auf Aktivieren, falls diese API noch nicht aktiviert ist.
Alternativ können die APIs mit den folgenden Befehlen von gcloud aktiviert werden:
Auf dem Bildschirm sollte Folgendes zu sehen sein:
Operation "operations/..." finished successfully.
Jetzt können Sie Document AI verwenden.
Klicken Sie auf Fortschritt prüfen.
Document AI API aktivieren
Aufgabe 2: Prozessor erstellen und testen
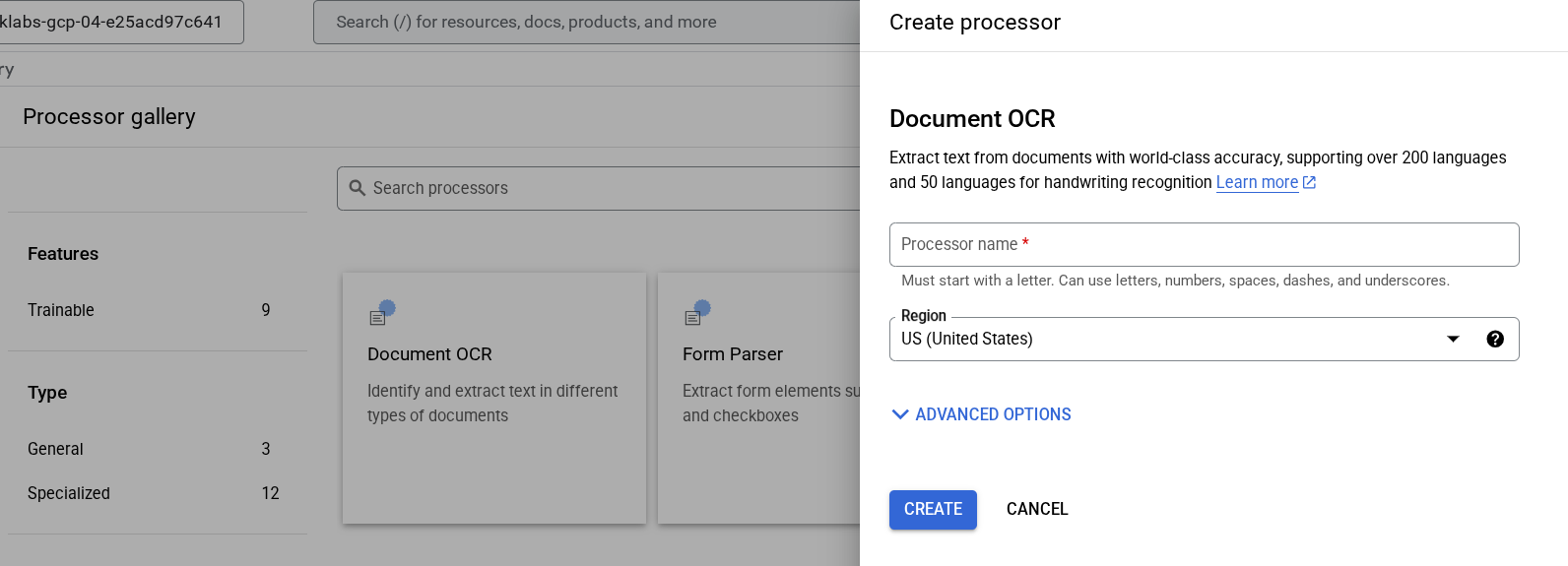
Sie müssen zuerst eine Instanz des Dokument-OCR-Prozessors erstellen, mit dem die Extraktion durchgeführt wird. Dies kann über die Cloud Console oder die Processor Management API erfolgen.
Klicken Sie im Navigationsmenü auf Alle Produkte ansehen. Wählen Sie unter Künstliche Intelligenz die Option Document AI aus.
Klicken Sie auf Prozessoren ansehen und dann auf Dokument-OCR.
Geben Sie dem Prozessor den Namen lab-ocr und wählen Sie die nächstgelegene Region aus der Liste aus.
Klicken Sie auf Erstellen, um den Prozessor zu erstellen.
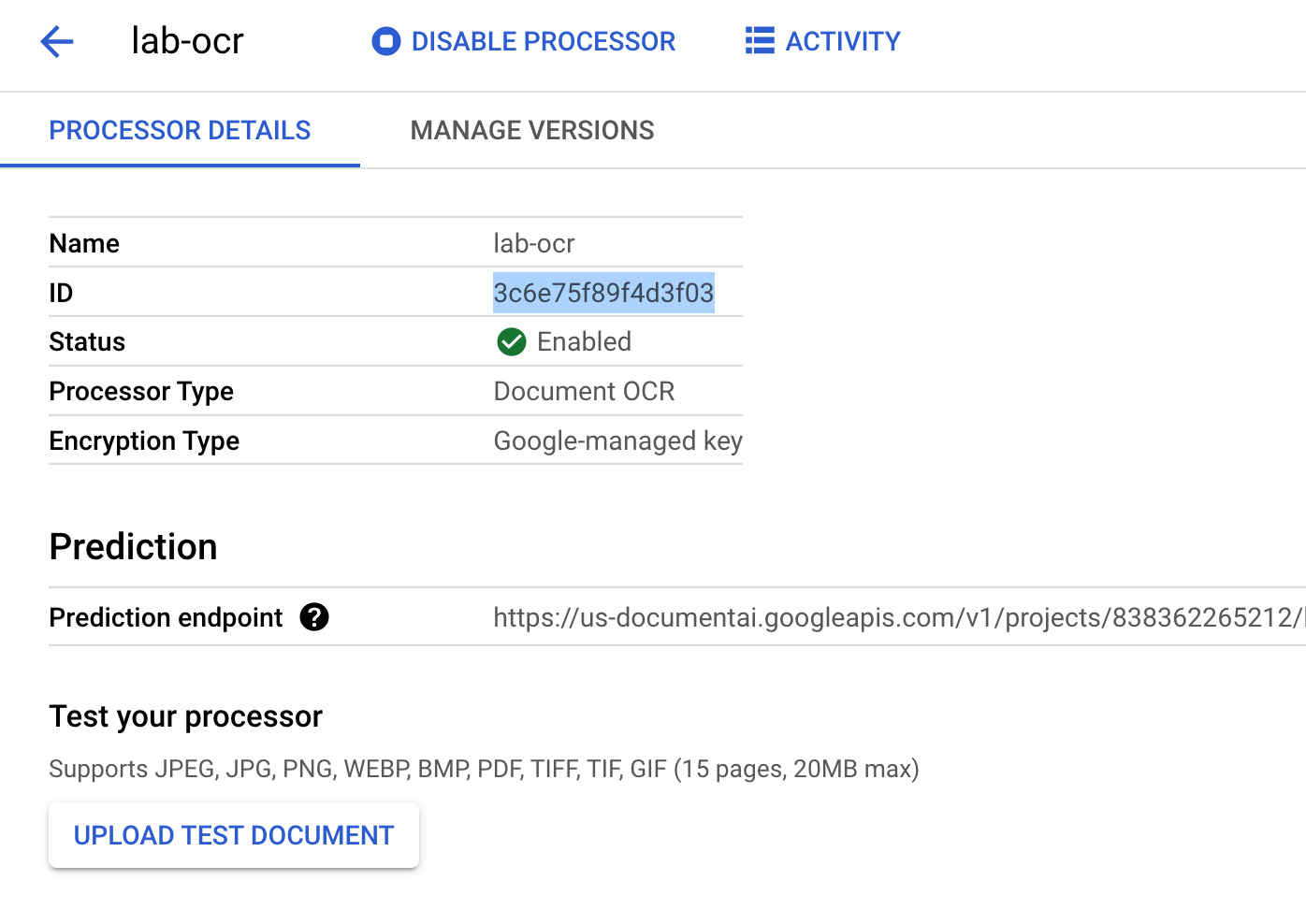
Kopieren Sie Ihre Prozessor-ID. Sie müssen sie später in Ihrem Code verwenden.
Laden Sie die PDF-Datei unten mit den ersten drei Seiten des Romans „Winnie the Pooh“ von A. A. Milne herunter.
Sie können Ihren Prozessor jetzt in der Console testen, indem Sie ein Dokument hochladen.
Klicken Sie auf Testdokument hochladen und wählen Sie die PDF-Datei aus, die Sie heruntergeladen haben.
Die Ausgabe sollte so aussehen:
Klicken Sie auf Fortschritt prüfen.
Prozessor erstellen und testen
Aufgabe 3: API-Anfragen authentifizieren
Für Anfragen an die Document AI API müssen Sie ein Dienstkonto verwenden. Das Dienstkonto gehört zu Ihrem Projekt und wird von der Python-Clientbibliothek zum Ausführen von API-Anfragen verwendet. Wie jedes andere Nutzerkonto wird auch ein Dienstkonto durch eine E‑Mail-Adresse dargestellt. In diesem Abschnitt verwenden Sie das Cloud SDK, um ein Dienstkonto zu erstellen. Anschließend erstellen Sie die Anmeldedaten, die Sie für die Authentifizierung als Dienstkonto benötigen.
Öffnen Sie zuerst ein neues Cloud Shell-Fenster und legen Sie mit dem folgenden Befehl eine Umgebungsvariable mit Ihrer Projekt-ID fest:
Erstellen Sie Anmeldedaten, die der Python-Code verwendet, um sich mit dem neuen Dienstkonto anzumelden. Durch den folgenden Befehl werden die Anmeldedaten erstellt und als JSON-Datei ~/key.json gespeichert:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-docai-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Richten Sie die Umgebungsvariable GOOGLE_APPLICATION_CREDENTIALS ein. Sie wird von der Bibliothek verwendet, um die Anmeldedaten zu finden. Die Umgebungsvariable sollte auf den vollständigen Pfad der von Ihnen erstellten JSON-Datei mit den Anmeldedaten festgelegt werden:
In diesem Schritt verarbeiten Sie die ersten drei Seiten des Romans mit der API für die Onlineverarbeitung (synchron). Diese Methode eignet sich am besten für kleinere Dokumente, die lokal gespeichert sind. In der vollständigen Liste der Prozessoren finden Sie die maximale Anzahl von Seiten und die maximale Dateigröße für jeden Prozessortyp.
Erstellen Sie in der Cloud Shell eine Datei mit dem Namen online_processing.py und fügen Sie den folgenden Code ein:
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "Winnie_the_Pooh_3_Pages.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Read the file into memory
with open(FILE_PATH, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=image_content, mime_type=MIME_TYPE)
# Configure the process request
request = documentai.ProcessRequest(name=RESOURCE_NAME, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = docai_client.process_document(request=request)
document_object = result.document
print("Document processing complete.")
print(f"Text: {document_object.text}")
Ersetzen Sie YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID und FILE_PATH durch die entsprechenden Werte für Ihre Umgebung.
Hinweis:FILE_PATH ist der Name der Datei, die Sie im vorherigen Schritt in die Cloud Shell hochgeladen haben. Wenn Sie die Datei nicht umbenannt haben, sollte ihr Name Winnie_the_Pooh_3_Pages.pdf lauten. Das ist der Standardwert und muss nicht geändert werden.
Führen Sie den Code aus. Der Text wird extrahiert und in der Console ausgegeben.
python3 online_processing.py
Es sollte folgende Ausgabe angezeigt werden:
Document processing complete.
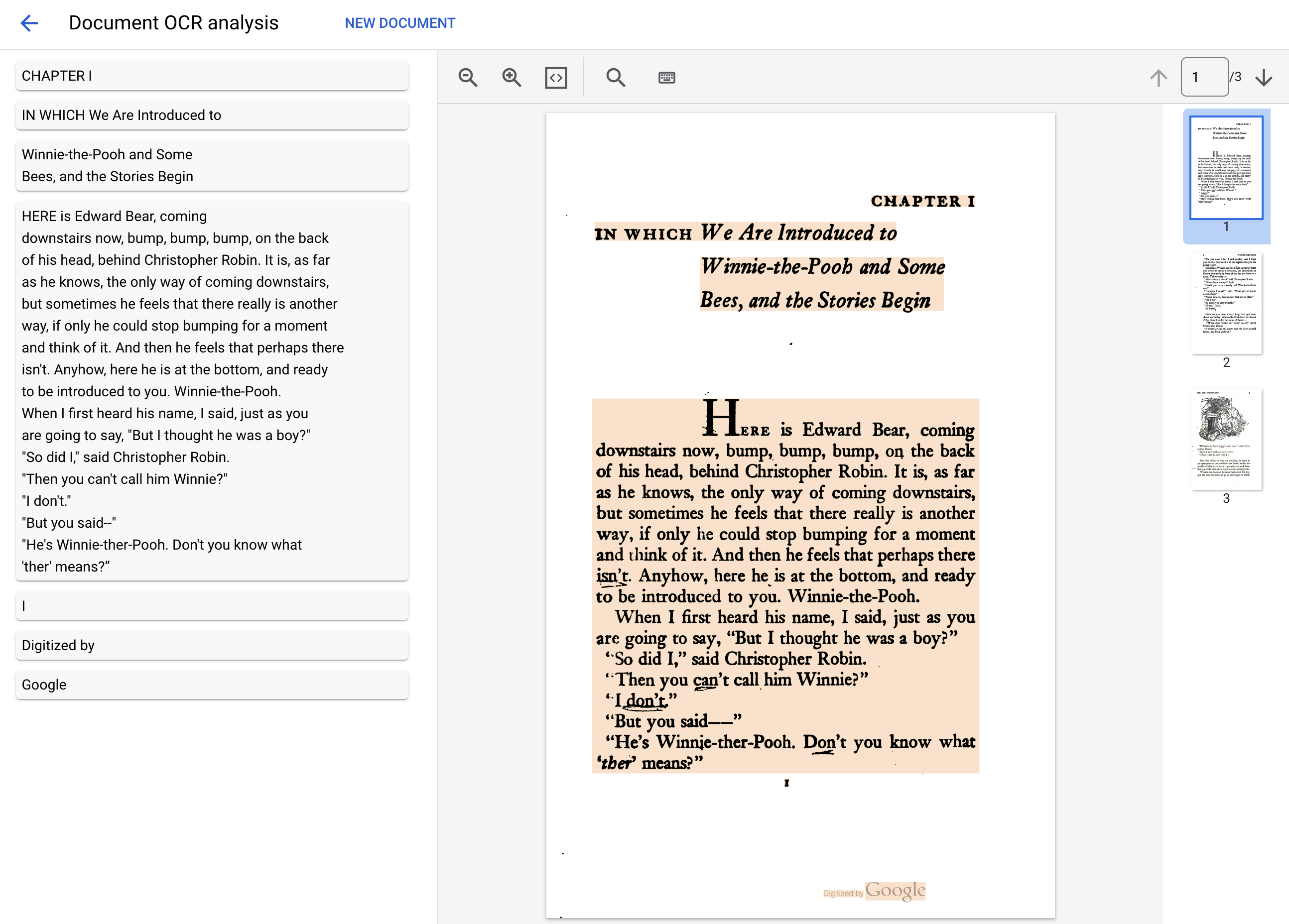
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
...
Aufgabe 6: Batchverarbeitungsanfrage stellen
Angenommen, Sie möchten den Text des gesamten Romans einlesen.
Für die Onlineverarbeitung gelten Beschränkungen hinsichtlich der Anzahl der Seiten, die gesendet werden können, und der Dateigröße. Außerdem ist nur eine Dokumentdatei pro API-Aufruf zulässig.
Die Batchverarbeitung ermöglicht die Verarbeitung größerer oder mehrerer Dateien mit einer asynchronen Methode.
In diesem Abschnitt verarbeiten Sie den gesamten Roman „Winnie the Pooh“ mit der Document AI Batch Processing API und geben den Text in einen Google Cloud Storage-Bucket aus.
Bei der Batchverarbeitung werden Vorgänge mit langer Ausführungszeit verwendet, um Anfragen asynchron zu verwalten. Daher müssen wir die Anfrage anders stellen und die Ausgabe auf andere Weise abrufen als bei der Onlineverarbeitung.
Die Ausgabe erfolgt jedoch unabhängig davon, ob Sie die Online- oder Batchverarbeitung verwenden, im selben Objektformat Document.
In diesem Abschnitt wird beschrieben, wie Sie bestimmte Dokumente für die Verarbeitung durch Document AI bereitstellen. In einem späteren Abschnitt wird gezeigt, wie Sie ein ganzes Verzeichnis mit Dokumenten verarbeiten.
PDF in Cloud Storage hochladen
Die Methode batch_process_documents() akzeptiert derzeit Dateien aus Google Cloud Storage. Informationen zur Objektstruktur finden Sie in der Referenz documentai_v1.types.BatchProcessRequest.
Führen Sie den folgenden Befehl aus, um einen Google Cloud Storage-Bucket zum Speichern der PDF-Datei zu erstellen und die Datei in den Bucket hochzuladen:
Erstellen Sie eine Datei mit dem Namen batch_processing.py und fügen Sie den folgenden Code ein:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory/file.pdf'
GCS_INPUT_URI = "gs://cloud-samples-data/documentai/codelabs/ocr/Winnie_the_Pooh.pdf"
INPUT_MIME_TYPE = "application/pdf"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Document
input_document = documentai.GcsDocument(
gcs_uri=GCS_INPUT_URI, mime_type=INPUT_MIME_TYPE
)
# Load GCS Input URI into a List of document files
input_config = documentai.BatchDocumentsInputConfig(
gcs_documents=documentai.GcsDocuments(documents=[input_document])
)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Ersetzen Sie YOUR_PROJECT_ID, YOUR_PROJECT_LOCATION, YOUR_PROCESSOR_ID, GCS_INPUT_URI und GCS_OUTPUT_URI durch die entsprechenden Werte für Ihre Umgebung.
Verwenden Sie für GCS_INPUT_URI den URI der Datei, die Sie im vorherigen Schritt in Ihren Bucket hochgeladen haben, also gs:///Winnie_the_Pooh.pdf.
Verwenden Sie für GCS_OUTPUT_URI den URI des Buckets, den Sie im vorherigen Schritt erstellt haben, also gs://.
Führen Sie den Code aus. Der vollständige Romantext sollte extrahiert und in der Console ausgegeben werden.
python3 batch_processing.py
Hinweis: Da die Datei viel größer als im vorherigen Beispiel ist, kann es einige Zeit dauern, bis der Vorgang abgeschlossen ist. Bei Verwendung der Batch Processing API erhalten Sie eine Vorgangs-ID, mit der Sie die Ausgabe aus Cloud Storage abrufen können, sobald die Aufgabe abgeschlossen ist.
Die Ausgabe sollte in etwa so aussehen:
Document processing complete.
Fetching 16218185426403815298/0/Winnie_the_Pooh-0.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-1.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-10.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-11.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-12.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-13.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-14.json
Fetching 16218185426403815298/0/Winnie_the_Pooh-15.json
..
This is a reproduction of a library book that was digitized
by Google as part of an ongoing effort t
0
TAM MTAA
Digitized by
Google
Introduction
(I₂
F YOU happen to have read another
book about Christo
84
Eeyore took down his right hoof from his right
ear, turned round, and with great difficulty put u
94
..
Sehr gut! Sie haben mit der Document AI Batch Processing API Text aus einer PDF-Datei extrahiert.
Klicken Sie auf Fortschritt prüfen.
Batchverarbeitungsanfrage stellen
Aufgabe 7: Batchverarbeitungsanfrage für ein Verzeichnis stellen
Vielleicht möchten Sie ein ganzes Verzeichnis mit Dokumenten verarbeiten, ohne jedes Dokument einzeln aufzulisten. Die Methode batch_process_documents() unterstützt die Eingabe einer Liste bestimmter Dokumente oder eines Verzeichnispfads.
In diesem Abschnitt erfahren Sie, wie Sie ein vollständiges Verzeichnis von Dokumentdateien verarbeiten. Der Großteil des Codes ist derselbe wie im vorherigen Schritt. Der einzige Unterschied ist der GCS-URI, der mit BatchProcessRequest gesendet wird.
Führen Sie den folgenden Befehl aus, um das Beispielverzeichnis, das mehrere Seiten des Romans in separaten Dateien enthält, in den Cloud Storage-Bucket zu kopieren:
Sie können die Dateien direkt lesen oder in Ihren eigenen Cloud Storage-Bucket kopieren.
Erstellen Sie eine Datei mit dem Namen batch_processing_directory.py und fügen Sie den folgenden Code ein:
import re
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import documentai_v1 as documentai
from google.cloud import storage
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "YOUR_PROCESSOR_ID" # Create processor in Cloud Console
# Format 'gs://input_bucket/directory'
GCS_INPUT_PREFIX = "gs://cloud-samples-data/documentai/codelabs/ocr/multi-document"
# Format 'gs://output_bucket/directory'
GCS_OUTPUT_URI = "YOUR_OUTPUT_BUCKET_URI"
# Instantiates a client
docai_client = documentai.DocumentProcessorServiceClient(
client_options=ClientOptions(api_endpoint=f"{LOCATION}-documentai.googleapis.com")
)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
RESOURCE_NAME = docai_client.processor_path(PROJECT_ID, LOCATION, PROCESSOR_ID)
# Cloud Storage URI for the Input Directory
gcs_prefix = documentai.GcsPrefix(gcs_uri_prefix=GCS_INPUT_PREFIX)
# Load GCS Input URI into Batch Input Config
input_config = documentai.BatchDocumentsInputConfig(gcs_prefix=gcs_prefix)
# Cloud Storage URI for Output directory
gcs_output_config = documentai.DocumentOutputConfig.GcsOutputConfig(
gcs_uri=GCS_OUTPUT_URI
)
# Load GCS Output URI into OutputConfig object
output_config = documentai.DocumentOutputConfig(gcs_output_config=gcs_output_config)
# Configure Process Request
request = documentai.BatchProcessRequest(
name=RESOURCE_NAME,
input_documents=input_config,
document_output_config=output_config,
)
# Batch Process returns a Long Running Operation (LRO)
operation = docai_client.batch_process_documents(request)
# Continually polls the operation until it is complete.
# This could take some time for larger files
# Format: projects/PROJECT_NUMBER/locations/LOCATION/operations/OPERATION_ID
print(f"Waiting for operation {operation.operation.name} to complete...")
operation.result()
# NOTE: Can also use callbacks for asynchronous processing
#
# def my_callback(future):
# result = future.result()
#
# operation.add_done_callback(my_callback)
print("Document processing complete.")
# Once the operation is complete,
# get output document information from operation metadata
metadata = documentai.BatchProcessMetadata(operation.metadata)
if metadata.state != documentai.BatchProcessMetadata.State.SUCCEEDED:
raise ValueError(f"Batch Process Failed: {metadata.state_message}")
documents: List[documentai.Document] = []
# Storage Client to retrieve the output files from GCS
storage_client = storage.Client()
# One process per Input Document
for process in metadata.individual_process_statuses:
# output_gcs_destination format: gs://BUCKET/PREFIX/OPERATION_NUMBER/0
# The GCS API requires the bucket name and URI prefix separately
output_bucket, output_prefix = re.match(
r"gs://(.*?)/(.*)", process.output_gcs_destination
).groups()
# Get List of Document Objects from the Output Bucket
output_blobs = storage_client.list_blobs(output_bucket, prefix=output_prefix)
# DocAI may output multiple JSON files per source file
for blob in output_blobs:
# Document AI should only output JSON files to GCS
if ".json" not in blob.name:
print(f"Skipping non-supported file type {blob.name}")
continue
print(f"Fetching {blob.name}")
# Download JSON File and Convert to Document Object
document = documentai.Document.from_json(
blob.download_as_bytes(), ignore_unknown_fields=True
)
documents.append(document)
# Print Text from all documents
# Truncated at 100 characters for brevity
for document in documents:
print(document.text[:100])
Ersetzen Sie PROJECT_ID, LOCATION, PROCESSOR_ID, GCS_INPUT_PREFIX und GCS_OUTPUT_URI durch die entsprechenden Werte für Ihre Umgebung.
Verwenden Sie für GCS_INPUT_PREFIX den URI des Verzeichnisses, das Sie im vorherigen Abschnitt in den Bucket hochgeladen haben, also gs:///multi-document.
Verwenden Sie für GCS_OUTPUT_URI den URI des Buckets, den Sie im vorherigen Abschnitt erstellt haben, also gs://.
Führen Sie mit dem folgenden Befehl den Code aus. Sie sollten den extrahierten Text aus allen Dokumentdateien im Cloud Storage-Verzeichnis sehen.
python3 batch_processing_directory.py
Die Ausgabe sollte in etwa so aussehen:
Document processing complete.
Fetching 16354972755137859334/0/Winnie_the_Pooh_Page_0-0.json
Fetching 16354972755137859334/1/Winnie_the_Pooh_Page_1-0.json
Fetching 16354972755137859334/2/Winnie_the_Pooh_Page_10-0.json
..
Introduction
(I₂
F YOU happen to have read another
book about Christopher Robin, you may remember
th
IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is
..
Sehr gut! Sie haben die Python-Clientbibliothek für Document AI verwendet, um ein Verzeichnis mit Dokumenten mit einem Document AI-Prozessor zu verarbeiten und die Ergebnisse in Cloud Storage auszugeben.
Klicken Sie auf Fortschritt prüfen.
Batchverarbeitungsanfrage für ein Verzeichnis stellen
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Das wars! Sie haben das Lab erfolgreich abgeschlossen. In diesem Lab haben Sie gelernt, wie Sie mit der Python-Clientbibliothek für Document AI ein Verzeichnis mit Dokumenten mithilfe eines Document AI-Prozessors verarbeiten und die Ergebnisse in Cloud Storage ausgeben. Außerdem haben Sie gelernt, wie Sie API-Anfragen mit einer Dienstkontoschlüsseldatei authentifizieren, die Python-Clientbibliothek für Document AI installieren und die APIs für die Online- (synchron) und Batchverarbeitung (asynchron) zum Verarbeiten von Anfragen verwenden.
Weitere Informationen
Weitere Informationen zu Document AI und der Python-Clientbibliothek finden Sie in den folgenden Ressourcen:
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Labs erstellen ein Google Cloud-Projekt und Ressourcen für einen bestimmten Zeitraum
Labs haben ein Zeitlimit und keine Pausenfunktion. Wenn Sie das Lab beenden, müssen Sie von vorne beginnen.
Klicken Sie links oben auf dem Bildschirm auf Lab starten, um zu beginnen
Privates Surfen verwenden
Kopieren Sie den bereitgestellten Nutzernamen und das Passwort für das Lab
Klicken Sie im privaten Modus auf Konsole öffnen
In der Konsole anmelden
Melden Sie sich mit Ihren Lab-Anmeldedaten an. Wenn Sie andere Anmeldedaten verwenden, kann dies zu Fehlern führen oder es fallen Kosten an.
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen
Klicken Sie erst auf Lab beenden, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten. Andernfalls werden Ihre bisherige Arbeit und das Projekt gelöscht.
Diese Inhalte sind derzeit nicht verfügbar
Bei Verfügbarkeit des Labs benachrichtigen wir Sie per E-Mail
Sehr gut!
Bei Verfügbarkeit kontaktieren wir Sie per E-Mail
Es ist immer nur ein Lab möglich
Bestätigen Sie, dass Sie alle vorhandenen Labs beenden und dieses Lab starten möchten
Privates Surfen für das Lab verwenden
Am besten führen Sie dieses Lab in einem Inkognito- oder privaten Browserfenster aus. So vermeiden Sie Konflikte zwischen Ihrem privaten Konto und dem Teilnehmerkonto, die zusätzliche Kosten für Ihr privates Konto verursachen könnten.
In diesem Lab erfahren Sie, wie Sie mit der Document AI API und Python die optische Zeichenerkennung durchführen.



 .
.