GSP1139

概览
Document AI 是一种接受非结构化数据(例如文档、邮件、账单、表单等)的文档理解解决方案,可使数据更易于理解、分析和使用。Document AI API 通过内容分类、实体提取和高级搜索等功能实现对数据的结构化处理。
在本实验中,您将学习如何使用 Document AI 表单解析器来通过 Python 解析手写表单。您将使用简单的医疗信息采集表单作为示例,但所采用的操作程序将适用于 DocAI 支持的任何通用表单。
目标
在本实验中,您将学习如何执行以下任务:
- 使用 Document AI 表单解析器从扫描的表单中提取数据
- 使用 Document AI 表单解析器从表单中提取键值对
- 使用 Document AI 表单解析器从表单中提取和导出 CSV 数据
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式(推荐)或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:请仅使用学生账号完成本实验。如果您使用其他 Google Cloud 账号,则可能会向该账号收取费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。右侧是实验设置和访问权限面板,其中包含以下内容:
-
打开 Google Cloud 控制台按钮
- 您在本实验中必须使用的临时凭证(用户名和密码)
- 帮助您逐步完成该实验所需的其他信息(如果需要)
请注意,实验计时器位于页面顶部附近,将显示剩余时间。
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:可以将这些标签页分别放在不同的窗口中,并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在实验设置和访问权限面板中找到“用户名”。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在实验设置和访问权限面板中找到“密码”。
-
点击下一步。
重要提示:您必须使用实验提供的凭证。请勿使用您的 Google Cloud 账号凭证。
注意:在本实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
依次点击进入后续页面:
- 接受条款及条件。
- 由于这是临时账号,请勿添加账号恢复选项或双重身份验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需访问 Google Cloud 产品和服务,请点击导航菜单,或在搜索字段中输入服务或产品的名称。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
-
点击 Google Cloud 控制台顶部的激活 Cloud Shell  。
。
-
在弹出的窗口中执行以下操作:
- 继续完成 Cloud Shell 信息窗口中的设置。
- 授权 Cloud Shell 使用您的凭据进行 Google Cloud API 调用。
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID 。输出内容中有一行说明了此会话的 Project_ID:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
gcloud auth list
- 点击授权。
输出:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (可选)您可以通过此命令列出项目 ID:
gcloud config list project
输出:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注意:如需查看在 Google Cloud 中使用 gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
任务 1. 启用 Document AI API
您必须先启用 Document AI API,然后才能开始使用 Document AI。
-
点击控制台顶部的激活 Cloud Shell 按钮,打开 Cloud Shell。
-
在 Cloud Shell 中运行以下命令,以启用 Document AI API。
gcloud services enable documentai.googleapis.com
您应会看到类似如下所示的内容:
Operation "operations/..." finished successfully.
您还需要安装 Pandas,这是一个适用于 Python 的开源数据分析库。
- 运行以下命令以安装 Pandas。
pip3 install --upgrade pandas
- 运行以下命令,安装 Document AI 的 Python 客户端库。
pip3 install --upgrade google-cloud-documentai
您应会看到类似如下所示的内容:
...
Installing collected packages: google-cloud-documentai
Successfully installed google-cloud-documentai-2.15.0
现在,您可以使用 Document AI API 了!
点击检查我的进度以验证是否完成了以下目标:
启用 Document AI API。
任务 2. 创建表单解析器处理器
在本教程中,您必须先创建一个表单解析器处理器实例,以便在 Document AI Platform 中使用。
- 在 Cloud 控制台中,打开导航菜单 (
 ),然后依次点击查看所有产品 > 人工智能 > Document AI。
),然后依次点击查看所有产品 > 人工智能 > Document AI。
- 点击探索处理器,然后在常规中点击表单解析器,以打开创建处理器页面。
-
将处理器命名为 lab-form-parser,并从列表中选择距离最近的区域。
-
点击创建以创建处理器
-
复制处理器 ID。您稍后必须在代码中使用此 ID。
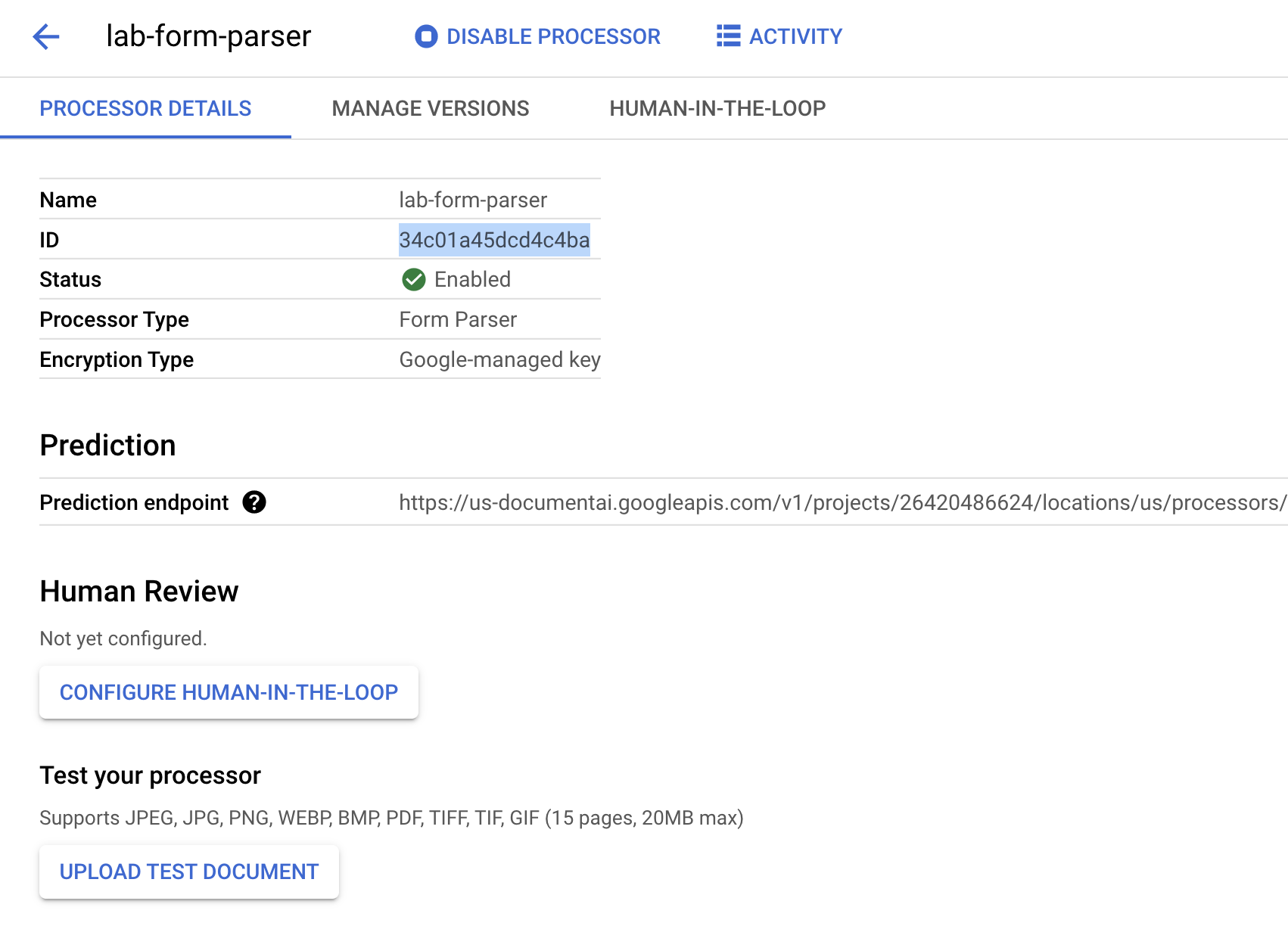
点击检查我的进度以验证是否完成了以下目标:
创建处理器
在 Cloud 控制台中测试处理器
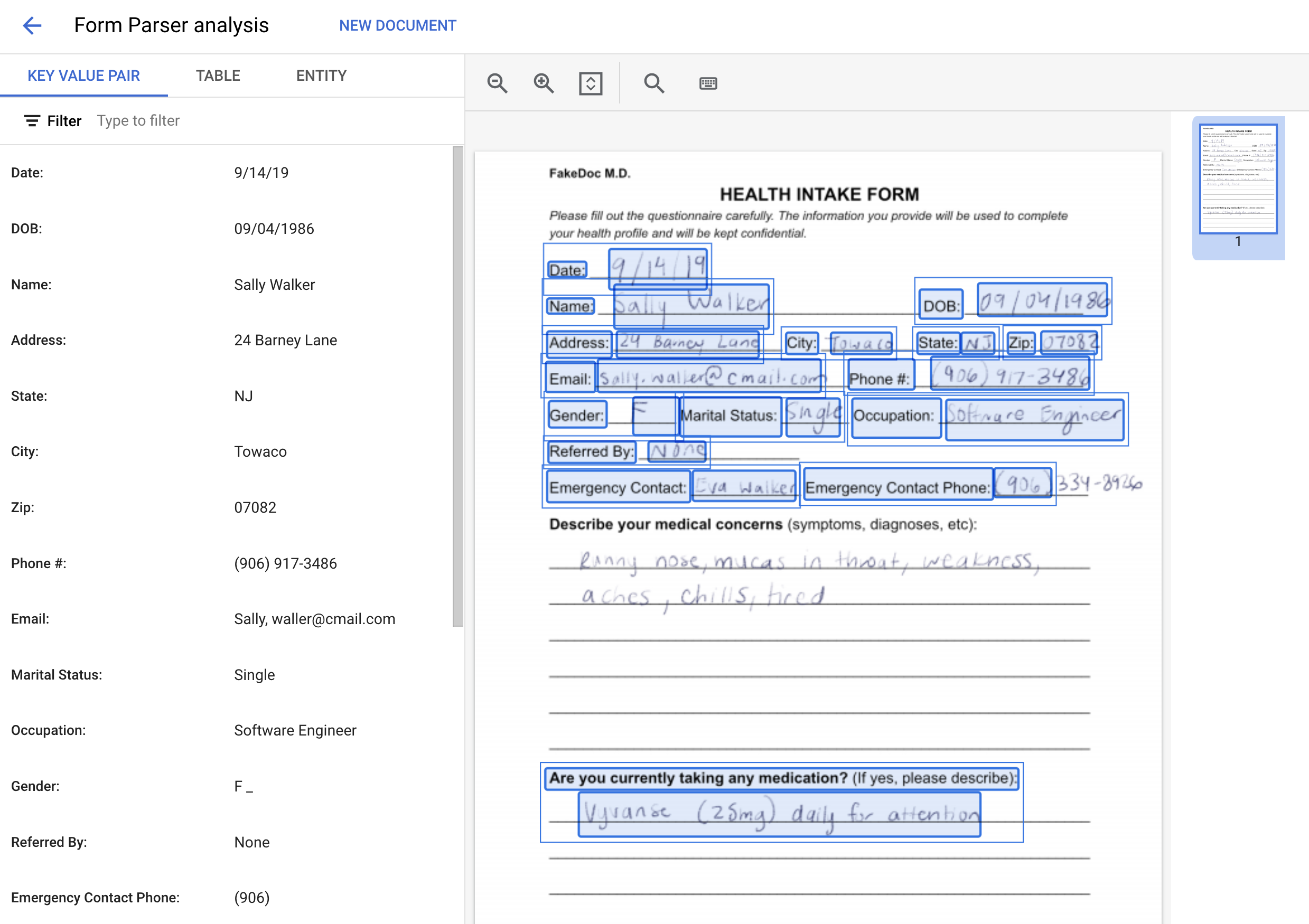
您可以在控制台中上传文档来测试所创建的处理器。
- 右键点击下方的图片,然后选择图片另存为,以下载示例表单。

- 在处理器详情页面上,点击上传测试文档。选择您刚刚下载的表单。
您创建的表单解析器处理器将处理该文档,并返回解析后的表单数据。输出应如下所示:
任务 3. 下载示例表单
在本部分,您将下载一份示例文档,其中包含简单的医疗信息采集表单。
- 运行以下命令,将示例表单下载到 Cloud Shell。
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/form-parser/intake-form.pdf .
- 使用以下命令,确认已将文件下载到 Cloud Shell:
ls intake-form.pdf
任务 4. 提取表单键值对
在本部分,您将使用在线处理 API 调用之前创建的表单解析器处理器。然后,您将提取文档中的键值对。
在线处理功能用于发送单个文档并等待响应。如果需要发送多个文件,或者文件大小超过在线处理功能支持的最大页数,您还可以使用批处理功能。
除了处理器 ID 之外,所有处理器类型用于发出处理请求的代码都是相同的。Document 响应对象包含输入文档中的一系列页面。每个 page 对象都包含一系列表单字段及其在文本中的位置。
以下代码会遍历每个页面,并提取每个键、值和置信度分数。这种结构化数据可以更轻松地存储到数据库中或用于其他应用。
- 在 Cloud Shell 中,创建一个名为
form_parser.py 的文件,并将以下代码粘贴到该文件中:
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
使用 Document AI 在线处理 API 处理文档。
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# 实例化客户端
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# 处理器的完整资源名称,例如:
# projects/project-id/locations/location/processor/processor-id
# 您必须先在 Cloud 控制台中创建新处理器
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# 将文件读入内存
with open(file_path, "rb") as image:
image_content = image.read()
# 将二进制数据加载到 Document AI RawDocument 对象中
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# 配置处理请求
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# 使用 Document AI 客户端处理示例表单
result = documentai_client.process_document(request=request)
return result.document
def trim_text(text: str):
"""
移除文本中多余的空格字符(空格、换行符、制表符等)
"""
return text.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 格式为“us”或“eu”
PROCESSOR_ID = "FORM_PARSER_ID" # 在 Cloud 控制台中创建处理器
# 当前工作目录中的本地文件
FILE_PATH = "form.pdf"
# 请参阅 https://cloud.google.com/document-ai/docs/processors-list,
# 了解支持的文件类型
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
names = []
name_confidence = []
values = []
value_confidence = []
for page in document.pages:
for field in page.form_fields:
# 获取提取的字段名称
names.append(trim_text(field.field_name.text_anchor.content))
# 置信度 - 模型对文本正确性的“确定”程度
name_confidence.append(field.field_name.confidence)
values.append(trim_text(field.field_value.text_anchor.content))
value_confidence.append(field.field_value.confidence)
# 创建 Pandas Dataframe,以表格格式输出相应值。
df = pd.DataFrame(
{
"Field Name": names,
"Field Name Confidence": name_confidence,
"Field Value": values,
"Field Value Confidence": value_confidence,
}
)
print(df)
- 根据您的环境,将
YOUR_PROJECT_ID、YOUR_PROJECT_LOCATION、YOUR_PROCESSOR_ID 和 FILE_PATH 替换为相应值。
请注意,FILE_PATH 是您在上一步中下载到 Cloud Shell 的文件的名称。如果您未重命名该文件,则文件名应为 intake-form.pdf,您需要将该名称更新到代码中。
- 运行以下命令以执行相应脚本:
python3 form_parser.py
您应该会看到以下输出内容:
Field Name Field Name Confidence Field Value Field Value Confidence
0 Phone #: 0.999982 (906) 917-3486 0.999982
1 Emergency Contact: 0.999972 Eva Walker 0.999972
2 Marital Status: 0.999951 Single 0.999951
3 Gender: 0.999933 F 0.999933
4 Occupation: 0.999914 Software Engineer 0.999914
5 Referred By: 0.999862 None 0.999862
6 Date: 0.999858 9/14/19 0.999858
7 DOB: 0.999716 09/04/1986 0.999716
8 Address: 0.999147 24 Barney Lane 0.999147
9 City: 0.997718 Towaco 0.997718
10 Name: 0.997345 Sally Walker 0.997345
11 State: 0.996944 NJ 0.996944
...
任务 5. 解析表格
表单解析器还能够从文档内的表格中提取数据。在本部分,您将下载一个新的示例文档并从表格中提取数据。由于您要将数据加载到 Pandas 中,因此只需进行一次方法调用,即可将这些数据输出为 CSV 文件和多种其他格式。
下载包含表格的示例表单
我们提供了一个示例文档,其中包含一个示例表单和一个表格。
- 运行以下命令,将示例表单下载到 Cloud Shell。
gcloud storage cp gs://cloud-samples-data/documentai/codelabs/form-parser/form_with_tables.pdf .
- 使用以下命令,确认已将文件下载到 Cloud Shell:
ls form_with_tables.pdf
提取表格数据
提取表格数据的处理请求与提取键值对的处理请求完全相同。区别在于,系统会在响应时从哪些字段中提取数据。表格数据存储在 pages[].tables[] 字段中。
在此示例中,您要从每个页面上每个表格的表格标题行和正文行中提取相关信息,然后输出表格并将其另存为 CSV 文件。
- 创建一个名为
table_parsing.py 的文件,并将以下代码粘贴到该文件中:
# type: ignore[1]
"""
使用 Document AI 在线处理功能来调用表单解析器处理器
提取文档中的表格和数据。
"""
from os.path import splitext
from typing import List, Sequence
import pandas as pd
from google.cloud import documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
使用 Document AI 在线处理 API 处理文档。
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# 实例化客户端
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# 处理器的完整资源名称,例如:
# projects/project-id/locations/location/processor/processor-id
# 您必须先在 Cloud 控制台中创建新处理器
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# 将文件读入内存
with open(file_path, "rb") as image:
image_content = image.read()
# 将二进制数据加载到 Document AI RawDocument 对象中
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# 配置处理请求
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# 使用 Document AI 客户端处理示例表单
result = documentai_client.process_document(request=request)
return result.document
def get_table_data(
rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> List[List[str]]:
"""
从表格行中获取文本数据
"""
all_values: List[List[str]] = []
for row in rows:
current_row_values: List[str] = []
for cell in row.cells:
current_row_values.append(
text_anchor_to_text(cell.layout.text_anchor, text)
)
all_values.append(current_row_values)
return all_values
def text_anchor_to_text(text_anchor: documentai.Document.TextAnchor, text: str) -> str:
"""
Document AI 通过表格数据在整个文档文本中的偏移量来识别表格数据。
此函数将偏移量转换为字符串。
"""
response = ""
# 如果一个文本段有几行,则会将其
# 存储为不同的文本段。
for segment in text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # 格式为“us”或“eu”
PROCESSOR_ID = "FORM_PARSER_ID" # 在运行示例之前创建处理器
# 当前工作目录中的本地文件
FILE_PATH = "form_with_tables.pdf"
# 请参阅 https://cloud.google.com/document-ai/docs/file-types,
# 了解支持的文件类型
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
header_row_values: List[List[str]] = []
body_row_values: List[List[str]] = []
# 输入文件名(不带扩展名)
output_file_prefix = splitext(FILE_PATH)[0]
for page in document.pages:
for index, table in enumerate(page.tables):
header_row_values = get_table_data(table.header_rows, document.text)
body_row_values = get_table_data(table.body_rows, document.text)
# 创建 Pandas DataFrame,以表格格式输出相应值。
df = pd.DataFrame(
data=body_row_values,
columns=pd.MultiIndex.from_arrays(header_row_values),
)
print(f"Page {page.page_number} - Table {index}")
print(df)
# 将各个表格另存为 CSV 文件
output_filename = f"{output_file_prefix}_pg{page.page_number}_tb{index}.csv"
df.to_csv(output_filename, index=False)
- 根据您的环境,将
YOUR_PROJECT_ID、YOUR_PROJECT_LOCATION、YOUR_PROCESSOR_ID 和 FILE_PATH 替换为相应值。
请注意,FILE_PATH 是您在上一步中下载到 Cloud Shell 的文件的名称。如果您未重命名该文件,则文件名应为 form_with_tables.pdf;该名称是默认值,无需更改。
- 运行以下命令以执行相应脚本:
python3 table_parsing.py
您应该会看到以下输出内容:
Page 1 - Table 0
Item Description
0 Item 1 Description 1
1 Item 2 Description 2
2 Item 3 Description 3
此外,您还应该会在运行代码的目录中获得一个新的 CSV 文件。
- 运行以下命令,列出当前工作目录中的各个文件:
ls
您应该会看到以下输出内容:
form_with_tables_pg1_tb0.csv
恭喜!
恭喜您完成本实验!您已成功使用 Document AI API 从一份手写表单中提取数据。您还了解了如何使用 Document AI Python 客户端库从表单中提取键值对,以及如何从包含表格的表单中提取表格数据。
后续步骤/了解详情
请查看以下资源,详细了解 Document AI 和 Python 客户端库:
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
本手册的最后更新时间:2025 年 7 月 21 日
本实验的最后测试时间:2025 年 7 月 21 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。





