GSP811

Visão geral
Neste laboratório, você vai aprender a usar o plug-in da Proteção de Dados Sensíveis para o Cloud Fusion com o objetivo de encobrir dados sensíveis.
Considere o cenário a seguir, em que algumas informações sensíveis do cliente precisam ser ocultadas.
Cenário: sua equipe de suporte documenta os detalhes de cada caso processado em um tíquete de suporte. Todas as informações nos tíquetes são extraídas para um arquivo CSV. Os técnicos de suporte não devem documentar informações de clientes consideradas sensíveis, mas às vezes fazem isso por engano. Você percebe que os números de telefone de alguns clientes estão aparecendo no arquivo CSV.
Seu objetivo agora é analisar o arquivo CSV e encobrir todos os números de telefone. Para isso, você cria um pipeline do Cloud Data Fusion que encobre os dados sensíveis dos clientes usando o plug-in da Proteção de Dados Sensíveis.
Você vai criar um pipeline que faz o seguinte:
- Encobre os números de telefone e e-mails dos clientes mascarando-os com o caractere #.
- Armazena os dados sensíveis mascarados e os dados não sensíveis no Cloud Storage.
Objetivos
Neste laboratório, você vai aprender a:
- conectar o Cloud Data Fusion a uma origem do Cloud Storage;
- implantar o plug-in da Proteção de Dados Sensíveis;
- criar um modelo personalizado da Proteção de Dados Sensíveis;
- usar o plug-in de transformação Redact para mascarar dados confidenciais de clientes;
- gravar os dados de saída no Cloud Storage.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Faça login no Google Skills usando uma janela anônima.
-
Verifique o tempo de acesso do laboratório (por exemplo, 02:00:00) para conseguir finalizar todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
-
Quando tudo estiver pronto, clique em Começar o laboratório.
Observação: depois de clicar em Começar o laboratório, o tempo para provisionar os recursos necessários e criar uma instância do Data Fusion é de 15 a 20 minutos.
Enquanto isso, você pode conferir as etapas abaixo para conhecer as metas do laboratório.
Quando as credenciais do laboratório (nome de usuário e senha) aparecem no painel esquerdo, isso significa que a instância foi criada, e você pode continuar o login no console.
-
Anote as credenciais (nome de usuário e senha). É com elas que você vai fazer login no console do Google Cloud.
-
Clique em Abrir console do Google.
-
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Aceite os termos e pule a página de recursos de recuperação.
Observação: não clique em Terminar o laboratório a menos que você tenha concluído as atividades ou queira refazer tudo. Essa opção limpa as ações que você realizou e remove o projeto.
Fazer login no console do Google Cloud
- Na guia ou janela do navegador desta sessão de laboratório, copie o Nome de usuário do painel Detalhes da conexão e clique no botão Abrir console do Google.
Observação: se precisar escolher uma conta, clique em Usar outra conta.
- Cole o nome de usuário e a senha quando solicitado.
- Clique em Próxima.
- Aceite os Termos e Condições.
Como a conta é temporária, ela só dura até o final deste laboratório:
- não adicione opções de recuperação.
- não se inscreva em testes.
- Assim que o console abrir, clique no menu de navegação (
 ) no canto superior esquerdo para acessar a lista de serviços.
) no canto superior esquerdo para acessar a lista de serviços.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
-
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ( ).
).
-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:

Exemplo de comandos
gcloud auth list
(Saída)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemplo de saída)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Saída)
[core]
project = <project_ID>
(Exemplo de saída)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
-
No Console do Google Cloud, acesse o menu de navegação () e clique em IAM e administrador > IAM.
-
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.

Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
-
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
-
No card Informações do projeto, copie o Número do projeto.
-
No Menu de navegação, clique em IAM e administrador > IAM.
-
Na parte superior da página IAM, clique em Adicionar.
-
Para Novos principais, digite:
{project-number}-compute@developer.gserviceaccount.com
Substitua {project-number} pelo número do seu projeto.
-
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
-
Clique em Salvar.
Tarefa 1: configurar o bucket do Cloud Storage
Você vai criar um bucket do Cloud Storage no seu projeto para que o pipeline possa armazenar os dados de saída.
O nome do bucket criado é o mesmo do seu ID do projeto.
Clique em Verificar meu progresso para conferir o objetivo.
Configurar o bucket do Cloud Storage
Tarefa 2: adicionar as permissões necessárias para a instância do Cloud Data Fusion
- Na barra de título do console do Google Cloud, digite Data Fusion no campo Pesquisar e clique em Data Fusion nos resultados da pesquisa. Você verá uma instância do Cloud Data Fusion já configurada e pronta para uso.
Observação: a criação da instância leva cerca de 20 minutos. Aguarde até que ela fique pronta.
Em seguida, conceda permissões à conta de serviço associada à instância seguindo estas etapas:
-
No console do Google Cloud, acesse IAM e admin > IAM.
-
Confirme se a conta de serviço padrão do Compute Engine {project-number}-compute@developer.gserviceaccount.com está presente. Copie a conta de serviço para a área de transferência.
-
Na página de permissões do IAM, clique em +Conceder acesso.
-
No campo "Novos principais", cole a conta de serviço.
-
Clique no campo Selecionar um papel, digite Agente de serviço da API Cloud Data Fusion e selecione essa opção.
-
Clique em Salvar.
Clique em Verificar meu progresso para conferir o objetivo.
Adicionar um papel de agente de serviço da API Cloud Data Fusion à conta de serviço
Conceder permissão do usuário para a conta de serviço
-
No console, acesse o Menu de navegação e clique em IAM e admin > IAM.
-
Marque a caixa de seleção Incluir concessões do papel fornecidas pelo Google.
-
Role a lista para baixo até encontrar a conta de serviço do Cloud Data Fusion gerenciada pelo Google com esta estrutura: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com e copie o nome da conta de serviço para a área de transferência.

-
Em seguida, acesse IAM e admin > Contas de serviço.
-
Clique na conta padrão do Compute Engine com esta estrutura: {project-number}-compute@developer.gserviceaccount.com. Depois disso, selecione a guia Principais com acesso na parte de cima do menu de navegação.
-
Clique no botão Permitir acesso.
-
No campo Novos principais, cole a conta de serviço que você copiou mais cedo.
-
No menu suspenso Papel, selecione Usuário da conta de serviço.
-
Clique em Salvar.
Tarefa 3: receber permissões da Proteção de Dados Sensíveis
-
No console do Cloud, acesse o Menu de navegação > IAM.
-
No canto superior direito da tabela "Permissões", procure a caixa de seleção Incluir concessões de papéis fornecidos pelo Google e clique nela.

- Na tabela de permissões, na coluna Principal, encontre a conta de serviço que corresponde ao formato
service-project-number@gcp-sa-datafusion.iam.gserviceaccount.com.

-
Clique no botão Editar à direita da conta de serviço.
-
Clique em Adicionar outro papel.
-
Clique no menu suspenso exibido.
-
Use a barra de pesquisa para encontrar e selecionar a opção Administrador do DLP.
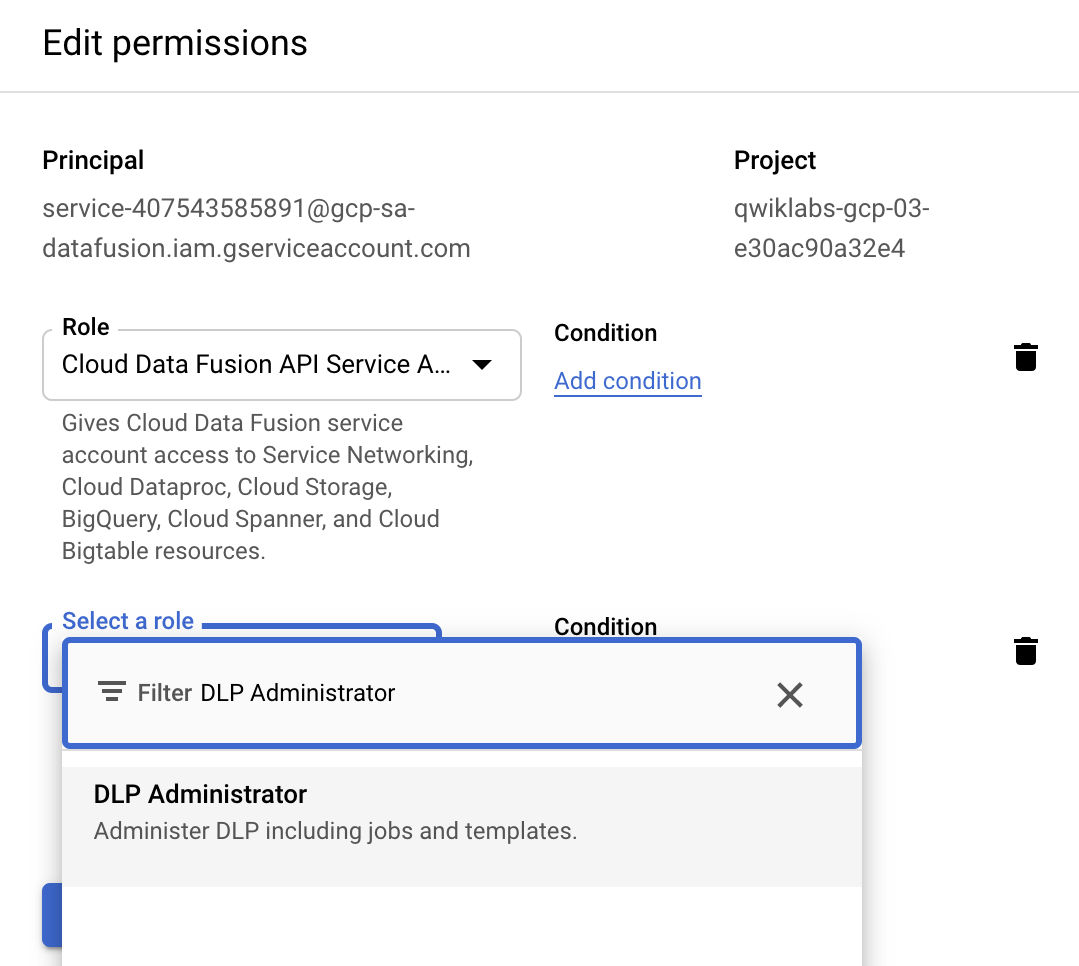
-
Clique em Salvar.
-
Verifique se o Administrador do DLP aparece na coluna Papel.

Clique em Verificar meu progresso para conferir o objetivo.
Receber permissões da Proteção de Dados Sensíveis
Tarefa 4: navegar até a interface do Cloud Data Fusion
-
Acesse o Data Fusion, clique em Instâncias e depois no link Ver instância ao lado da sua instância do Data Fusion. Se necessário, selecione suas credenciais do laboratório para fazer login. Caso o serviço ofereça um tour, clique em Agora não. Agora você está usando a interface do Cloud Data Fusion.
-
Na interface, clique no Menu de navegação no canto superior esquerdo e navegue até a página Studio.
Em seguida, você vai criar um pipeline.
Tarefa 5: criar o pipeline
O pipeline que você vai criar faz o seguinte:
* Lê os dados de entrada usando o plug-in de origem do Cloud Storage.
* Implanta o plug-in da Proteção de Dados Sensíveis do Hub e aplica o plug-in de transformação Redact.
* Grava os dados de saída usando um plug-in de coletor do Cloud Storage.
- No painel esquerdo da página do Studio, no menu Origem, clique no plug-in Google Cloud Storage (GCS).
-
Mantenha o ponteiro sobre o nó do GCS exibido e clique em Propriedades.
-
Em Nome de referência, insira um nome.
-
Este laboratório usa o conjunto de dados de entrada SampleRecords.csv, fornecido em um bucket do Cloud Storage disponível publicamente. Em Caminho, insira gs://cloud-training/OCBL167/SampleRecords.csv
-
Em Formato, selecione CSV.
-
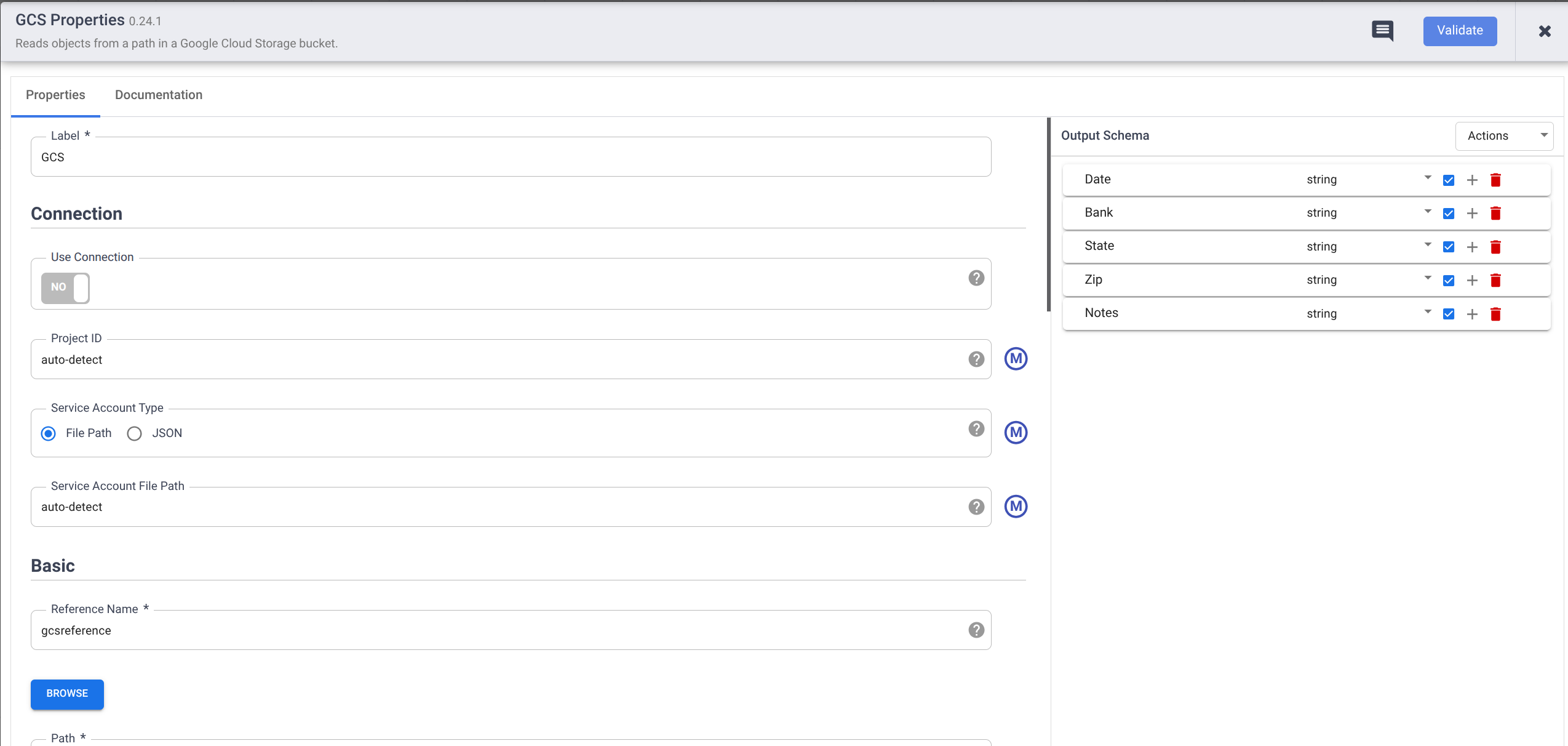
Em Nome do campo na opção Esquema de saída, digite o seguinte clicando no botão + para cada tipo de dado (remova todos os tipos de dados já inseridos, se houver).
- Data
- Banco
- Estado
- CEP
- Observações
-
Verifique se todos os tipos de dados são do tipo string. Para mudar isso, clique em Tipo e selecione String no menu suspenso.
-
Marque a caixa de seleção para cada tipo de dado. Isso garante que o pipeline não falhe quando encontrar um valor nulo (vazio).
-
Clique em Validar para verificar se há erros.
-
Clique no botão X no canto superior direito da caixa de diálogo.
Tarefa 6: encobrir dados sensíveis
O plug-in de transformação Redact identifica registros sensíveis no fluxo de entrada de dados e aplica transformações criadas por você a esses registros. Um registro de dados é considerado sensível se corresponder a filtros predefinidos da Proteção de Dados Sensíveis ou a um modelo personalizado definido por você.
Neste tutorial, você quer encobrir os números de telefone dos clientes que alguns técnicos de suporte da sua equipe anotaram acidentalmente. Eles inseriram as informações sensíveis na seção Observações dos tíquetes de suporte, que aparece como a coluna Observações no arquivo CSV. Crie um modelo de inspeção personalizado da Proteção de Dados Sensíveis e forneça o ID do modelo no menu de propriedades do plug-in de transformação Redact.
Tarefa 7: implantar o plug-in da Proteção de Dados Sensíveis
-
Na interface do Cloud Data Fusion, clique em Hub no canto superior direito.
-
Clique no plug-in Prevenção Contra Perda de Dados.
-
Clique em Implantar.
-
Clique em Concluir.
-
Clique no botão X no canto superior direito da caixa de diálogo Prevenção Contra Perda de Dados | Implantar.
-
Clique no botão X para sair do Hub.
Tarefa 8: criar um modelo personalizado
-
Na barra de título do console do Google Cloud, digite Segurança no campo Pesquisar e clique em Segurança nos resultados da pesquisa. Selecione Proteção de Dados Sensíveis.
-
Clique na guia Configuração e depois em Criar modelo.
-
Em Definir modelo, no campo ID do modelo, insira um ID. Você vai precisar do ID do modelo mais tarde no tutorial.
-
Clique em Continuar.
-
Em Configurar detecção, clique em Gerenciar infoTypes.
-
Na guia Integrado, use o filtro para pesquisar phone number.
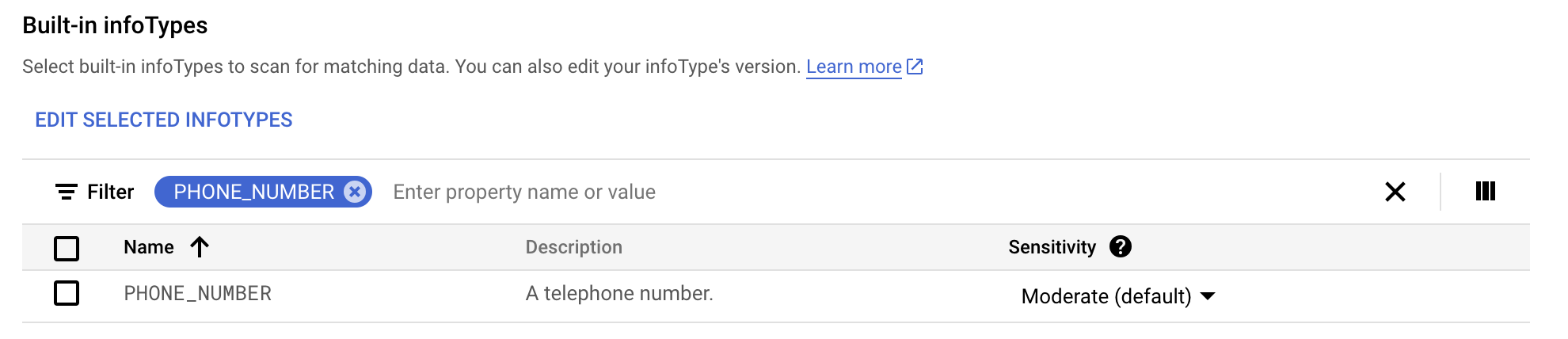
-
Selecione PHONE_NUMBER.
-
Clique em Concluído.
-
Clique em Criar.
Clique em Verificar meu progresso para conferir o objetivo.
Criar um modelo personalizado
Tarefa 9: aplicar o plug-in de transformação Redact
-
De volta à interface do Cloud Data Fusion, na página Studio, clique para expandir o menu Transformação.
-
Clique no plug-in de transformação Google DLP Redact.
- Arraste uma seta de conexão do nó GCS para o nó Google DLP Redact.
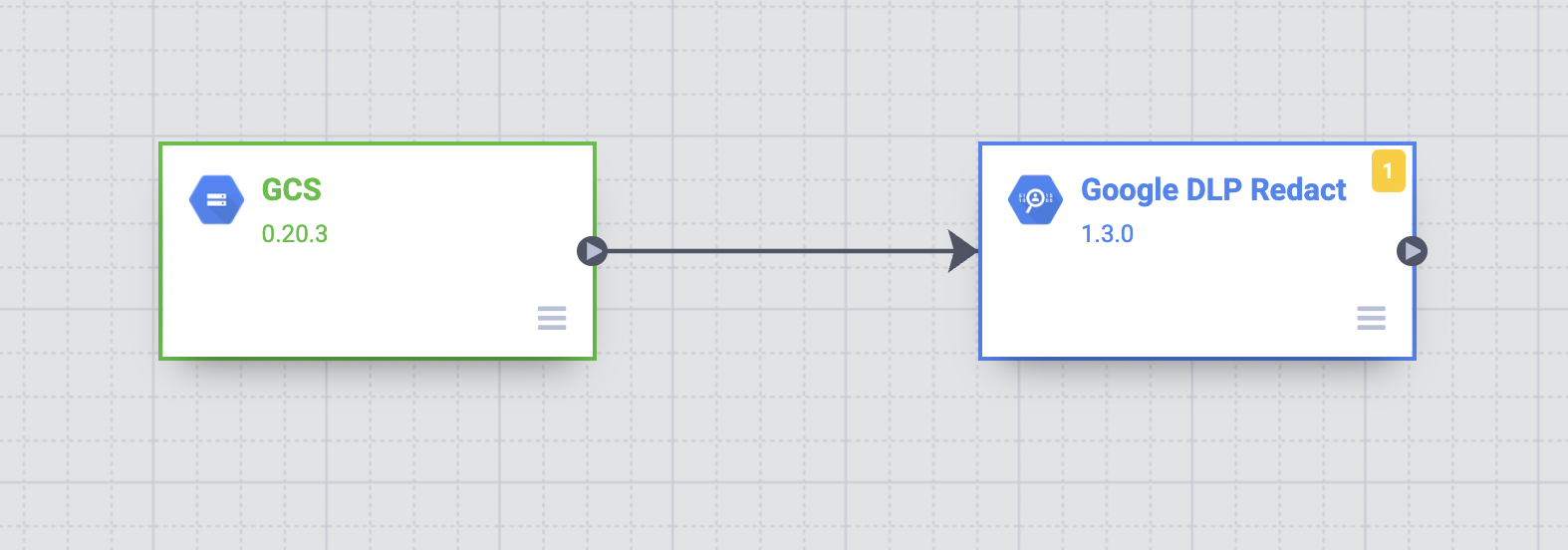
- Mantenha o ponteiro sobre o nó Google DLP Redact e clique em Propriedades.
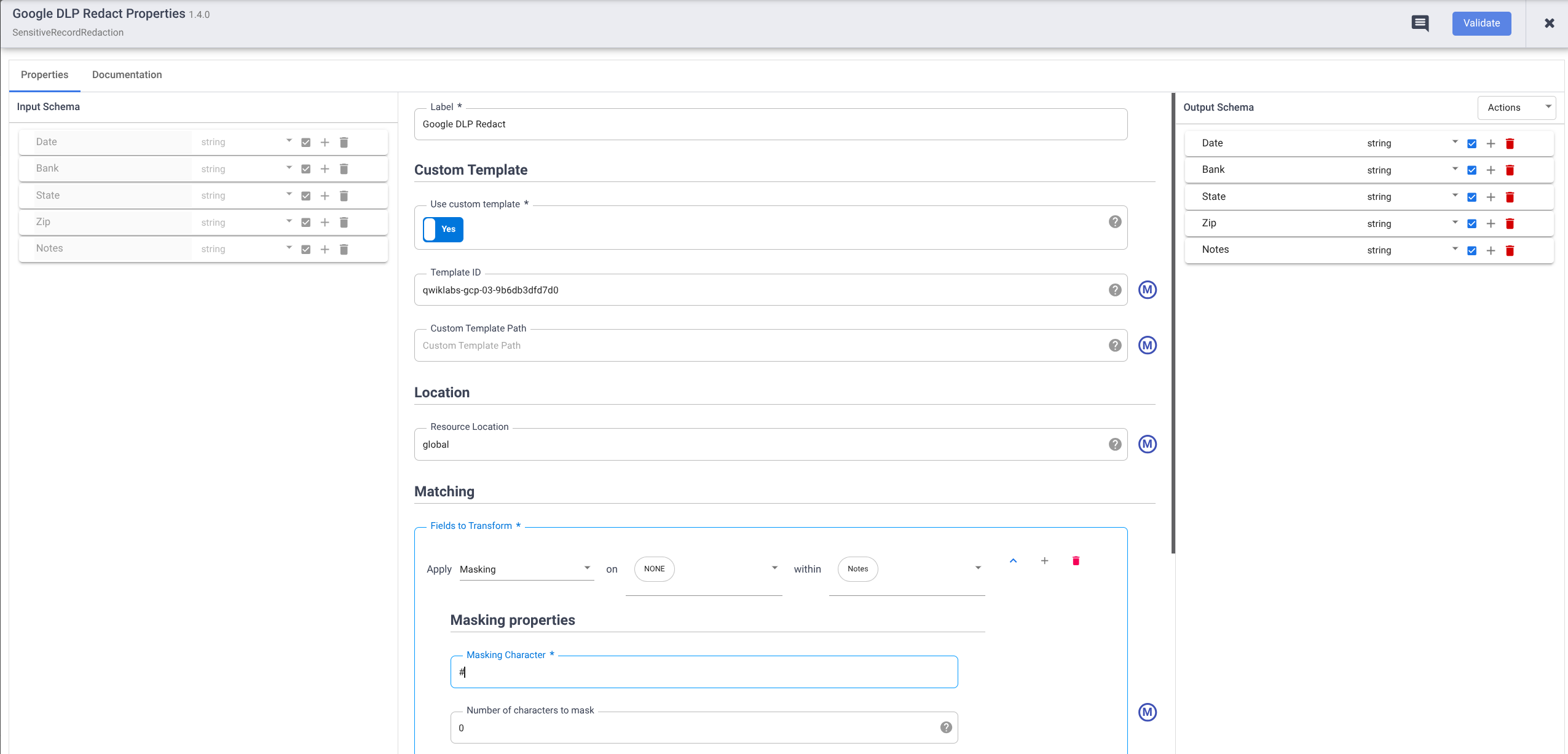
- Defina Usar modelo personalizado como Sim.
- Em ID do modelo, insira o ID do modelo personalizado que você criou.
- Em Correspondência, acesse Observações > Modelo personalizado e aplique Mascaramento.
Observação: além de mascarar, há outras transformações disponíveis com o plug-in da Proteção de Dados Sensíveis. Para saber mais, consulte a guia "Documentação" no menu de propriedades do plug-in Redact.
- Em Caractere de mascaramento, digite
#.
-
Clique em Validar para verificar se há erros.
-
Clique no botão X no canto superior direito da caixa de diálogo.
Tarefa 10: armazenar os dados de saída
Armazene os resultados do pipeline em um arquivo do Cloud Storage.
-
Na interface do Cloud Data Fusion, na página Studio, clique para expandir o menu Coletor.
-
Clique em GCS.
-
Arraste uma seta de conexão do nó Google DLP Redact para o nó GCS2.
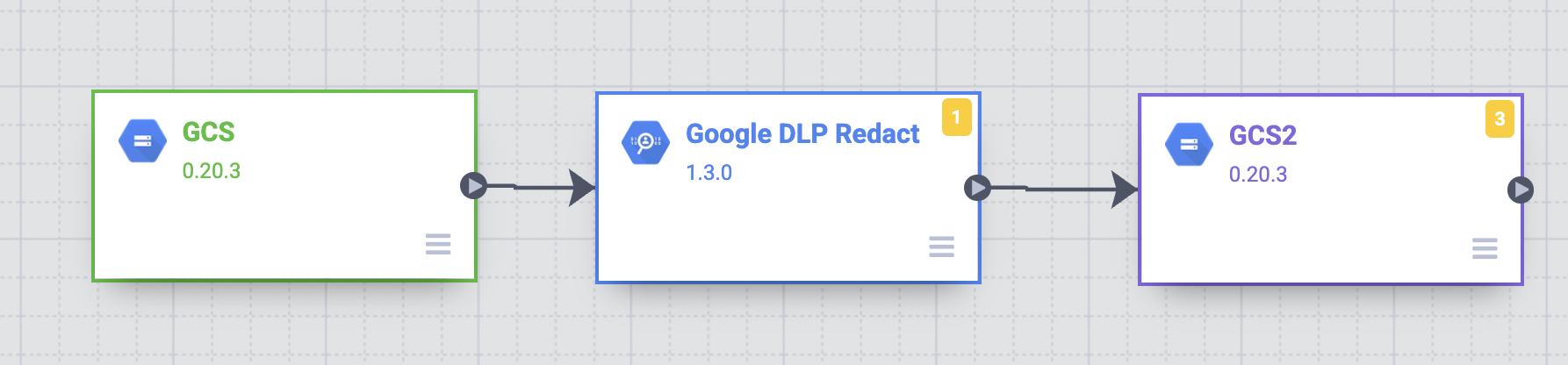
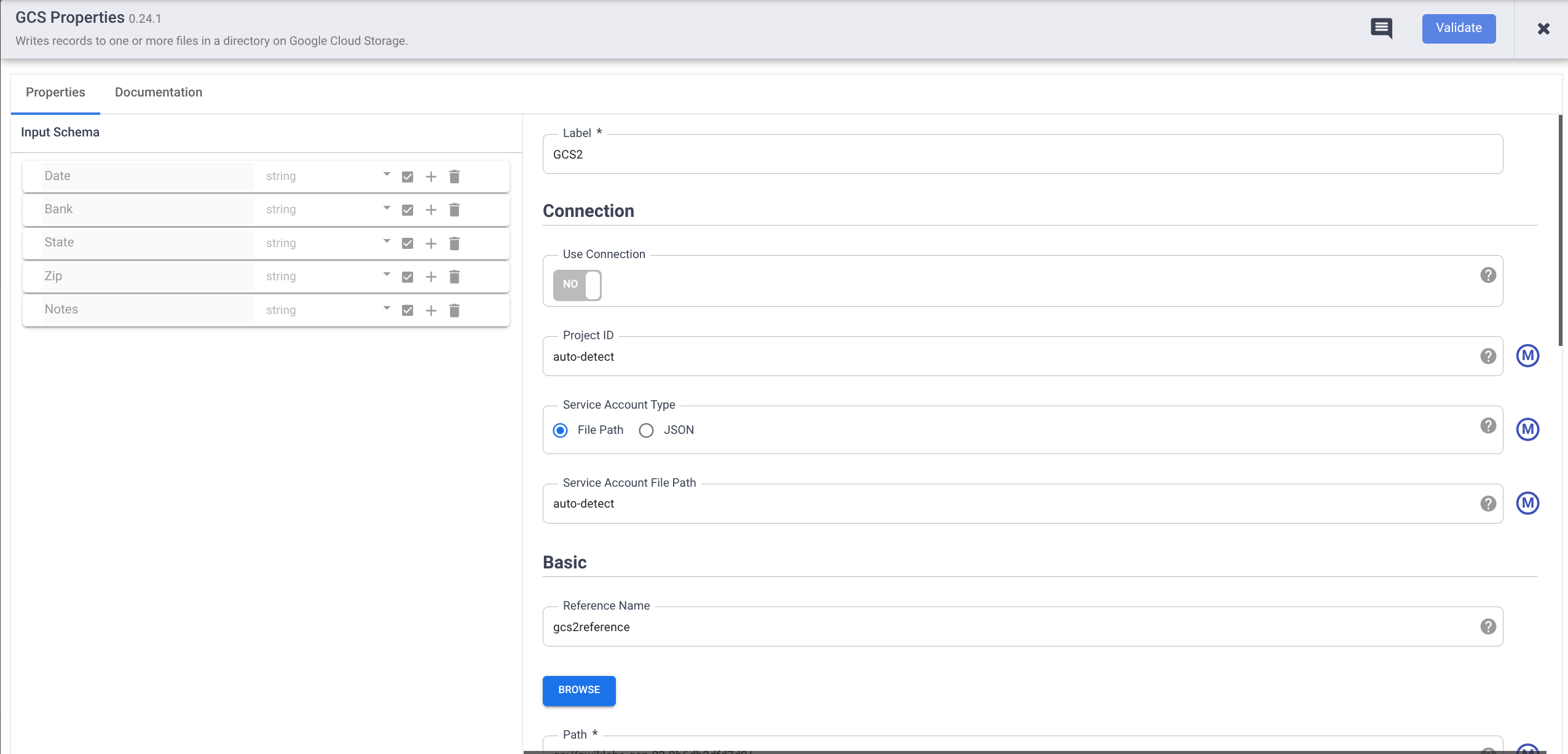
- Mantenha o ponteiro sobre o nó GCS2 e clique em Propriedades.
- Em Nome de referência, insira um nome.
- Em Caminho, insira o caminho do bucket do Cloud Storage que você criou no início deste laboratório.
- Em Formato, selecione CSV.
-
Clique em Validar para verificar se há erros.
-
Clique no botão X no canto superior direito da caixa de diálogo.
Tarefa 11: executar o pipeline no modo de visualização
Em seguida, execute o pipeline no modo de visualização antes de implantá-lo.
- Clique em Visualizar e em Executar.

O botão Executar mostra o status do pipeline, que começa com Iniciando, depois muda para Interromper e depois para Executar.
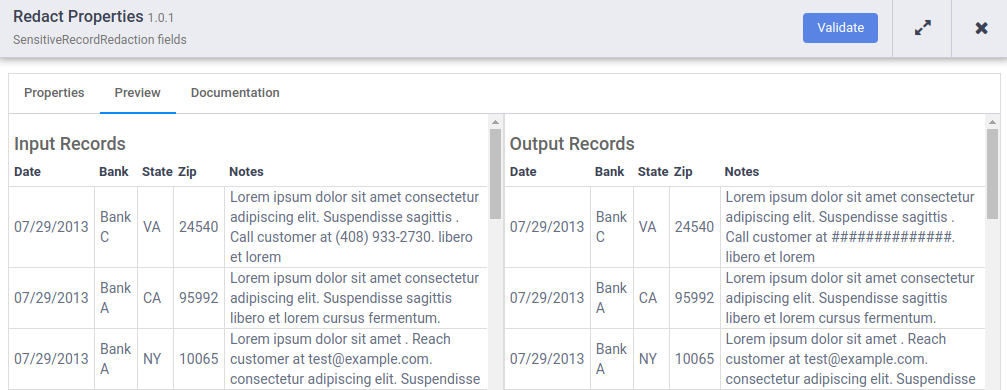
- Quando a execução da visualização for concluída, no nó Google DLP Redact, clique em Visualizar dados para ver uma comparação lado a lado dos dados de entrada e saída. Verifique se os números de telefone foram mascarados com o caractere #.
 3. Clique no botão X para fechar a guia Visualizar dados.
3. Clique no botão X para fechar a guia Visualizar dados.
Observação: se você não conseguir ver os números de telefone na coluna Observações, passe o cursor sobre as entradas para verificar o resultado.
Tarefa 12: encobrir outro tipo de dado
Ao examinar os resultados da execução da visualização, você percebe que outras informações sensíveis aparecem na coluna Observações: endereços de e-mail. Volte e edite o modelo de inspeção da Proteção de Dados Sensíveis para encobrir também os endereços de e-mail.
-
Acesse Segurança > Proteção de Dados Sensíveis .
-
Na guia Configuração, selecione seu modelo.
-
Clique em Editar.
-
Clique em Gerenciar InfoTypes.
-
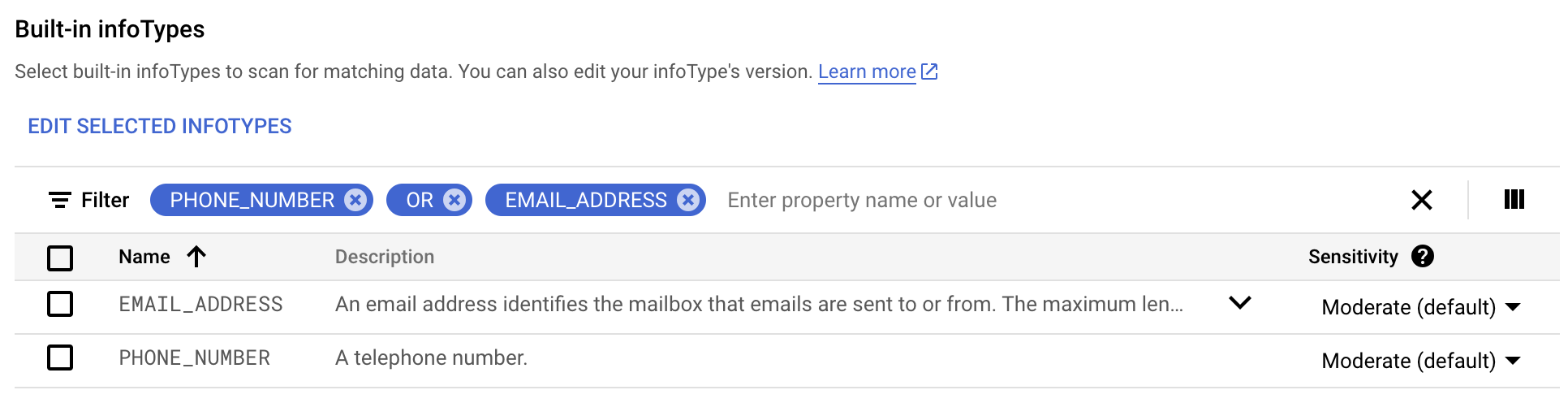
Na guia Integrado, use o filtro para pesquisar phone number OU email address.
-
Selecione tudo e clique em Concluído.
-
Clique em Salvar.
-
No pop-up, clique em Confirmo que quero salvar.
-
Mais uma vez, execute o pipeline no modo de visualização. O Cloud Data Fusion usará automaticamente o modelo atualizado da Proteção de Dados Sensíveis.
-
Verifique se os números de telefone e os endereços de e-mail foram mascarados com o caractere #.
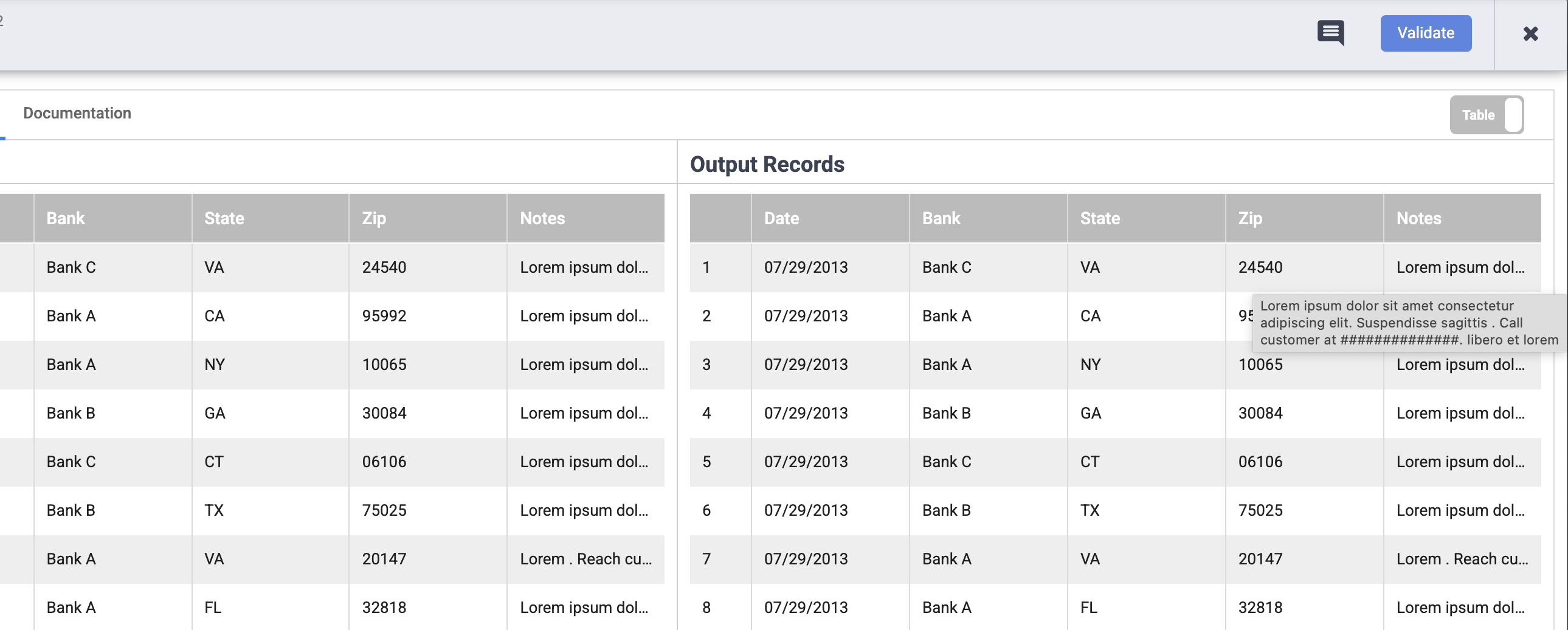
Observação: se você não conseguir ver os números de telefone e endereços de e-mail na coluna Observações, passe o cursor sobre as entradas para verificar o resultado.
Clique em Verificar meu progresso para conferir o objetivo.
Encobrir outro tipo de dado
Tarefa 13: implantar e executar o pipeline
-
Verifique se o modo Visualizar está desmarcado.
-
Clique em Salvar. Ao clicar em Salvar, será solicitado que você nomeie o pipeline. Dê um nome ao pipeline e clique em Salvar.
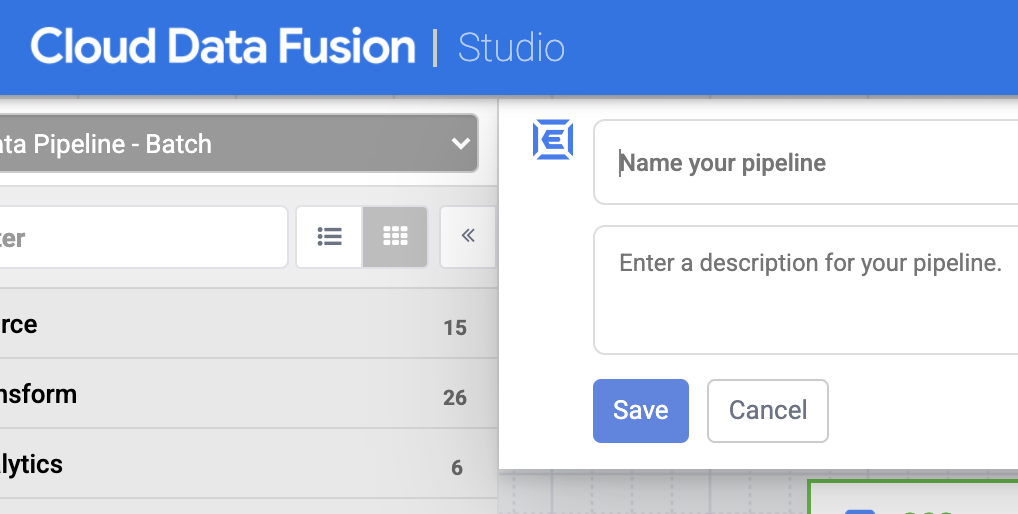
-
Clique em Implantar.
-
Quando a implantação for concluída, clique em Executar. A execução do pipeline pode levar alguns minutos. Enquanto espera, observe o Status do pipeline mudar de Provisionando > Iniciando > Em execução > Concluído.
Observação: se o pipeline falhar, execute-o novamente.
Clique em Verificar meu progresso para conferir o objetivo.
Implantar e executar o pipeline
Tarefa 14: ver os resultados
-
No Console do Cloud, acesse Cloud Storage.
-
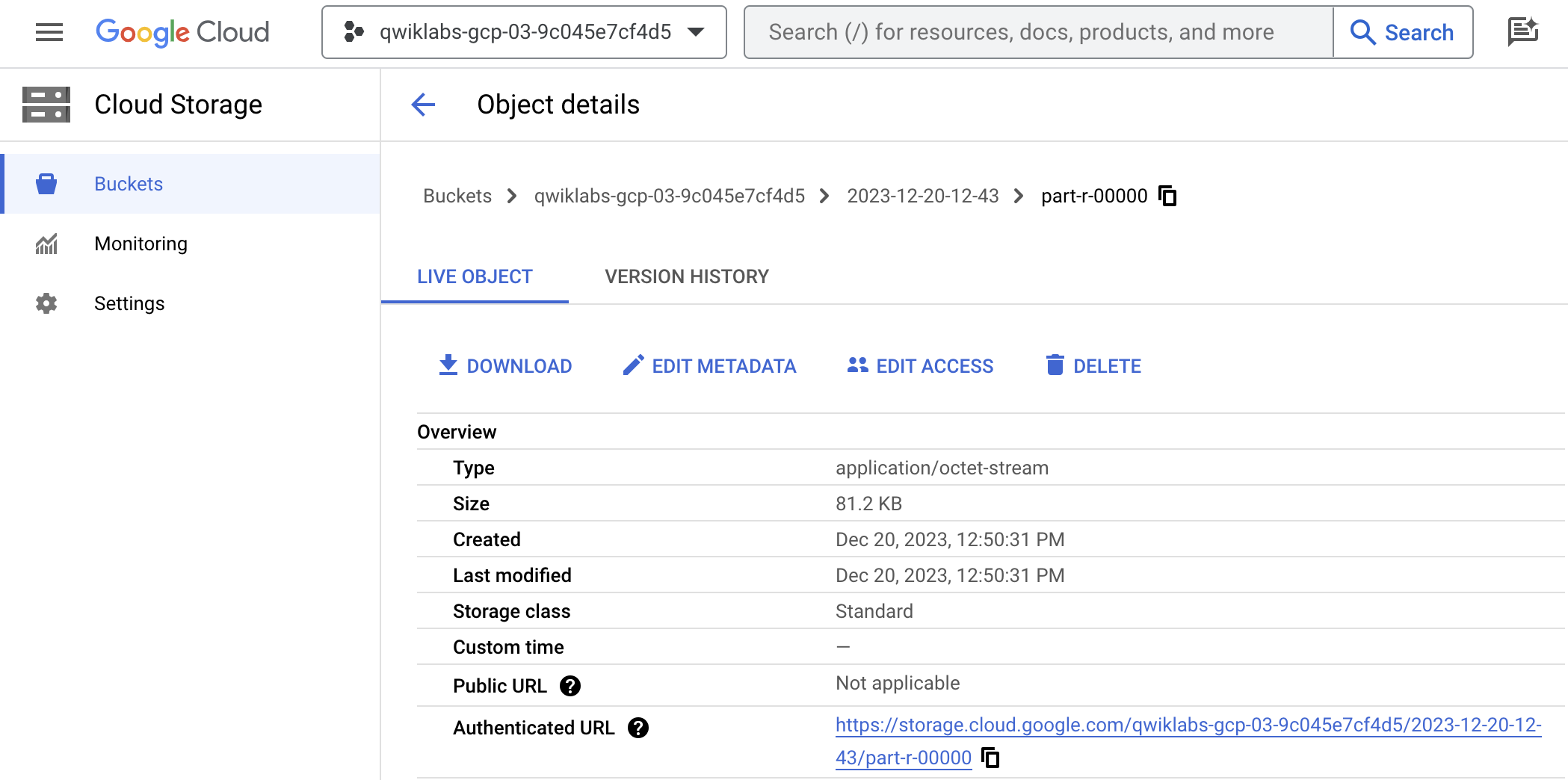
No navegador do Storage, acesse o bucket do Cloud Storage especificado nas propriedades do plug-in do Cloud Storage do coletor.
-
Em URL autenticado, copie o link e cole em uma nova guia do navegador para fazer o download do arquivo CSV com os resultados. Confirme se os números de telefone e endereços de e-mail foram mascarados com o caractere #.
Parabéns!
Neste laboratório, você aprendeu a usar a Proteção de Dados Sensíveis para mascarar certas partes dos seus dados que passam pelo pipeline do Data Fusion. Isso ajuda quando você precisa remover/mascarar informações de PII incorporadas nos seus dados antes de compartilhá-los com o público.
Saiba como criar modelos da Proteção de Dados Sensíveis na documentação.
Manual atualizado em 9 de dezembro de 2025
Laboratório testado em 9 de dezembro de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.





