Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
No BigQuery, você organiza os dados em conjuntos de dados e define o esquema (ou estrutura) de cada tabela usando nomes de colunas e tipos de dados. O esquema de uma tabela pode afetar o desempenho e o custo das consultas no BigQuery, pois determina o nível de rapidez e a eficiência com que o BigQuery vai acessar e processar os dados em uma tabela. O BigQuery é compatível com esquemas flexíveis, e é possível fazer mudanças sem precisar reescrever os dados.
Neste laboratório, oferecemos aos profissionais do Redshift o conhecimento e as habilidades de que precisam para começar a projetar e implementar esquemas de tabelas do BigQuery. Os objetivos de aprendizagem são entender melhor como criar, otimizar e consultar esquemas de tabelas do BigQuery.
Neste laboratório, você vai criar conjuntos de dados e tabelas do BigQuery para armazenar dados, criar campos aninhados e repetidos para manter relacionamentos em dados desnormalizados e criar tabelas particionadas e em cluster para otimizar o desempenho das consultas.
Criar e consultar campos aninhados e repetidos no BigQuery.
Criar e consultar tabelas particionadas no BigQuery.
Criar e consultar tabelas em cluster no BigQuery.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Como começar o laboratório e fazer login no console
Clique no botão Começar o laboratório. Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Um painel aparece à esquerda contendo as credenciais temporárias que você precisa usar no laboratório.
Copie o nome de usuário e clique em Abrir console do Google.
O laboratório ativa os recursos e depois abre a página Escolha uma conta em outra guia.
Observação: abra as guias em janelas separadas, lado a lado.
Na página "Escolha uma conta", clique em Usar outra conta. A página de login abre.
Cole o nome de usuário que foi copiado do painel "Detalhes da conexão". Em seguida, copie e cole a senha.
Observação: é necessário usar as credenciais do painel "Detalhes da conexão". Não use suas credenciais do Google Skills. Caso tenha sua própria conta do Google Cloud, não a use para este laboratório (isso evita cobranças).
Acesse as próximas páginas:
Aceite os Termos e Condições.
Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
Não se inscreva em testes sem custo financeiro.
Depois de alguns instantes, o console do Cloud abre nesta guia.
Observação: para acessar a lista dos produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo.
Tarefa 1: criar conjuntos de dados e tabelas no BigQuery
No BigQuery, você pode usar a linguagem de definição de dados (DDL) para criar conjuntos de dados e tabelas. Você também pode usar a instrução SQL LOAD DATA para carregar dados de um ou mais arquivos em uma tabela.
Nesta tarefa, você vai usar DDL para criar conjuntos de dados e tabelas no BigQuery e, em seguida, carregar dados nas tabelas novas com a instrução LOAD DATA.
No Menu de navegação () do console do Google Cloud, em "Analytics", clique em BigQuery.
A caixa de mensagem "Olá! Este é o BigQuery no console do Cloud" vai aparecer. Esta caixa de mensagem fornece um link para o guia de início rápido e para as notas da versão.
Clique em Concluído.
Na barra do espaço de trabalho SQL, clique no ícone Editor para abrir o editor de consultas SQL.
No editor de consultas, copie e cole a consulta abaixo, depois clique em Executar:
CREATE SCHEMA IF NOT EXISTS
ticket_sales OPTIONS(
location="us");
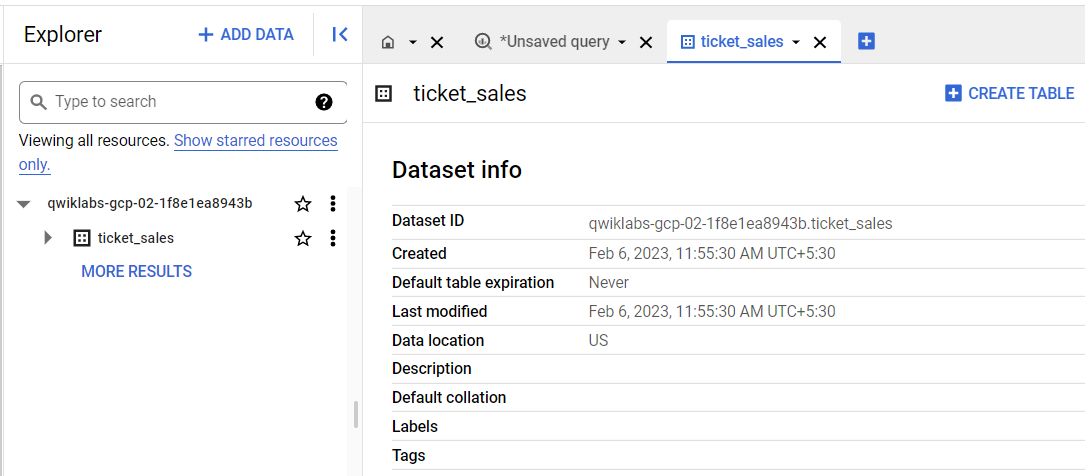
Essa consulta cria um conjunto de dados no BigQuery chamado ticket_sales. A instrução DDL usa o termo SCHEMA para se referir a uma coleção lógica de tabelas, visualizações e outros recursos. No BigQuery, trata-se de um conjunto de dados.
Expanda o painel "Explorer" no lado esquerdo, que lista o conjunto de dados, e clique no nome do conjunto de dados ticket_sales para confirmar se ele foi criado.
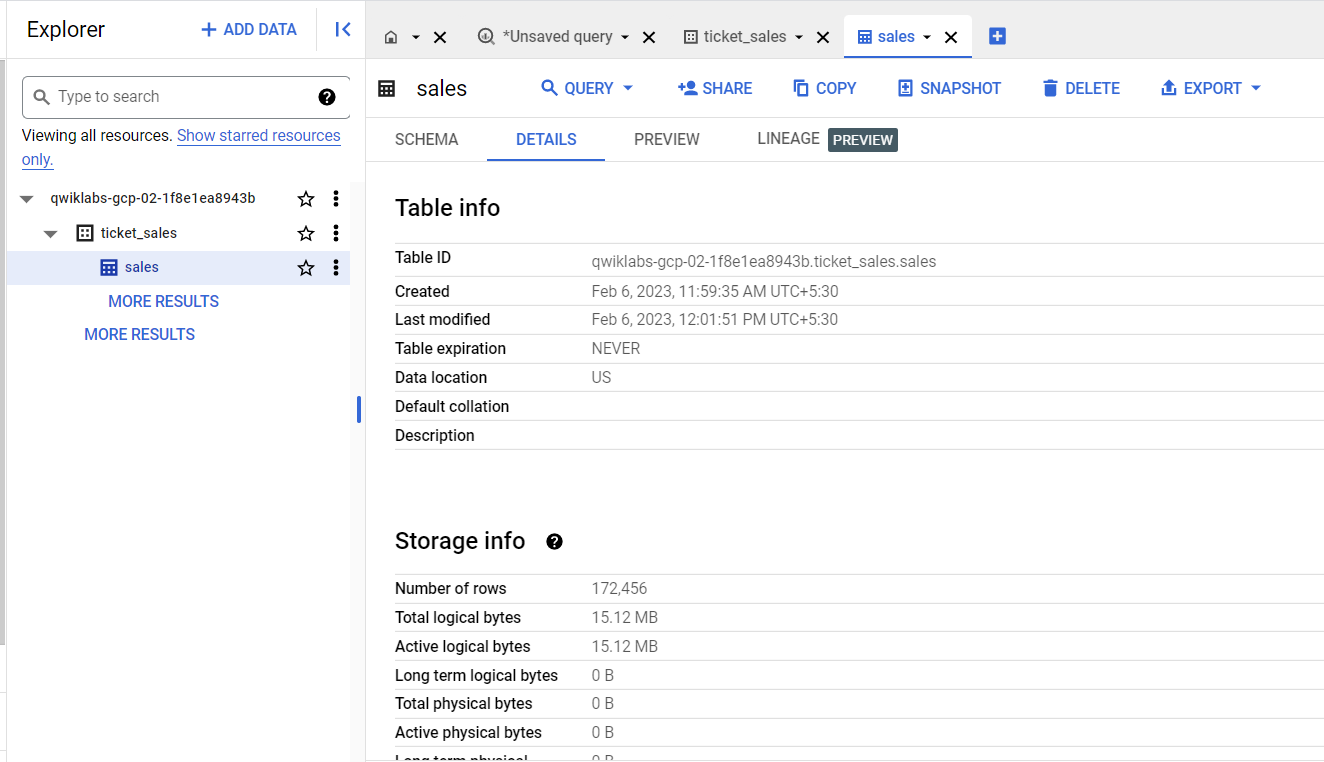
Essa consulta usa uma definição explícita de esquema de tabelas para carregar, na tabela sales, dados de um arquivo CSV no Cloud Storage.
O painel Resultados indica que a instrução LOAD foi executada.
No painel "Explorer", clique nas guias Detalhes e Visualização para confirmar se os dados foram carregados na tabela sales.
Clique em Atualizar no canto superior direito para atualizar os dados na guia Visualização.
Clique em Verificar meu progresso para conferir o objetivo.
Criar conjunto de dados e tabelas no BigQuery
Você usou instruções SQL no BigQuery para criar um conjunto de dados e uma tabela e carregar dados nela. Crie outra tabela e carregue dados sobre informações de eventos para praticar o que aprendeu.
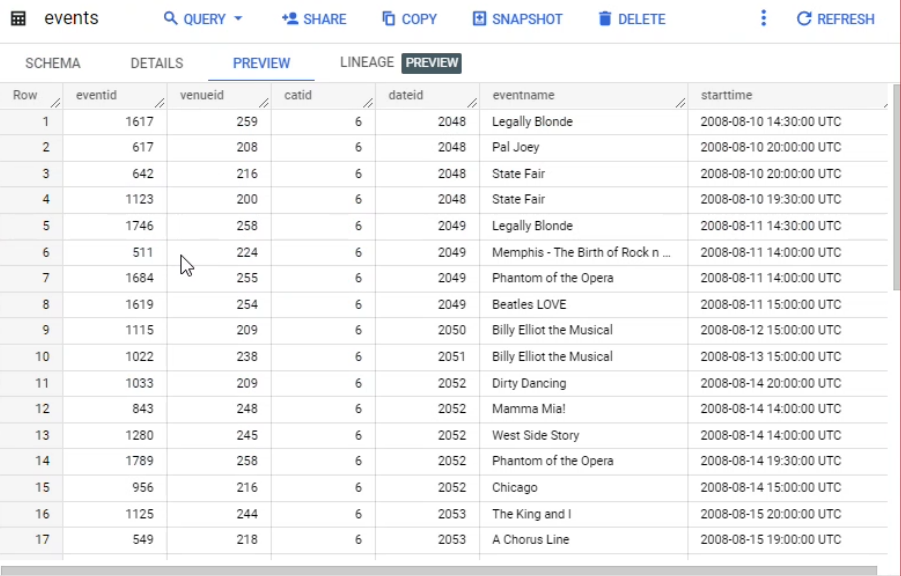
No editor, execute a seguinte consulta para criar a tabela events:
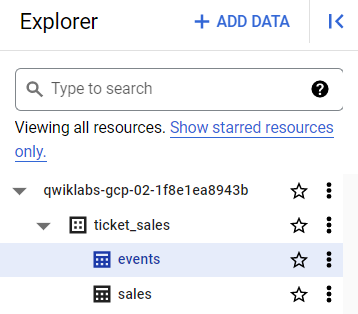
No painel Explorer, confira se há duas tabelas: sales e events.
No editor, execute a seguinte consulta para carregar dados na tabela events:
LOAD DATA INTO ticket_sales.events
FROM FILES (
skip_leading_rows=1,
format = 'CSV',
field_delimiter = ',',
max_bad_records = 10,
uris =['gs://tcd_repo/data/entertainment_media/ticket-sales/events.csv']);
Essa consulta usa a detecção automática de esquemas para carregar, na tabela events, os dados de um arquivo CSV no Cloud Storage.
O painel Resultados indica que a instrução LOAD foi executada.
Clique nas guias Detalhes e Visualização para conferir se os dados foram carregados na tabela events.
Clique em Atualizar no canto superior direito para atualizar os dados na guia Visualização.
Clique em Verificar meu progresso para conferir o objetivo.
Carregar dados na tabela de eventos
Tarefa 2: criar e consultar campos aninhados e repetidos
A desnormalização é uma estratégia conhecida para melhorar o desempenho de leitura em conjuntos de dados relacionais que já foram normalizados. No BigQuery, a recomendação para desnormalizar dados é usar campos aninhados e repetidos. Use esses campos para manter relacionamentos em dados desnormalizados, em vez de simplificar por completo os dados comuns.
Nesta tarefa, você vai aprender a criar e consultar campos aninhados e repetidos no BigQuery.
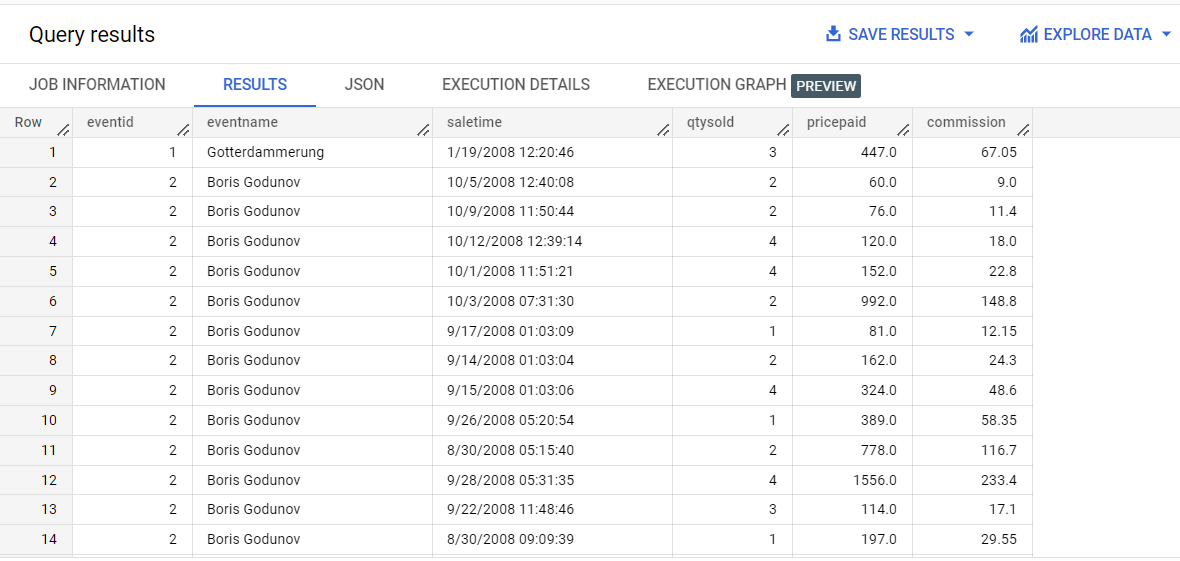
No editor, execute esta consulta:
SELECT
e.eventid,
e.eventname,
s.saletime,
s.qtysold,
s.pricepaid,
s.commission
FROM
ticket_sales.events e
JOIN
ticket_sales.sales s
ON
e.eventid = s.eventid
ORDER BY
eventid, eventname;
Observação: há uma relação de um para muitos entre as tabelas de eventos e de vendas. Quando executar essa consulta, uma repetição no lado "um" da relação de um para muitos vai aparecer. Para cada venda, o evento se repete. Para remover a repetição, agregue os dados de vendas em uma matriz.
No editor, execute esta consulta:
SELECT
e.eventid,
e.eventname,
ARRAY_AGG(STRUCT(
s.saletime,
s.qtysold,
s.pricepaid,
s.commission)) as sales
FROM
ticket_sales.events e
JOIN
ticket_sales.sales s
ON
e.eventid = s.eventid
GROUP BY
eventid, eventname
ORDER BY
eventid, eventname;
Embora o SQL da etapa 2 seja semelhante ao SQL da etapa 1, foram adicionadas as funções ARRAY_AGG, STRUCT e GROUP BY.
Revise os resultados da consulta.
Em vez de repetir os dados no lado "um" da relação de um para muitos, os dados no lado "muitos" agora ficam em uma matriz de structs.
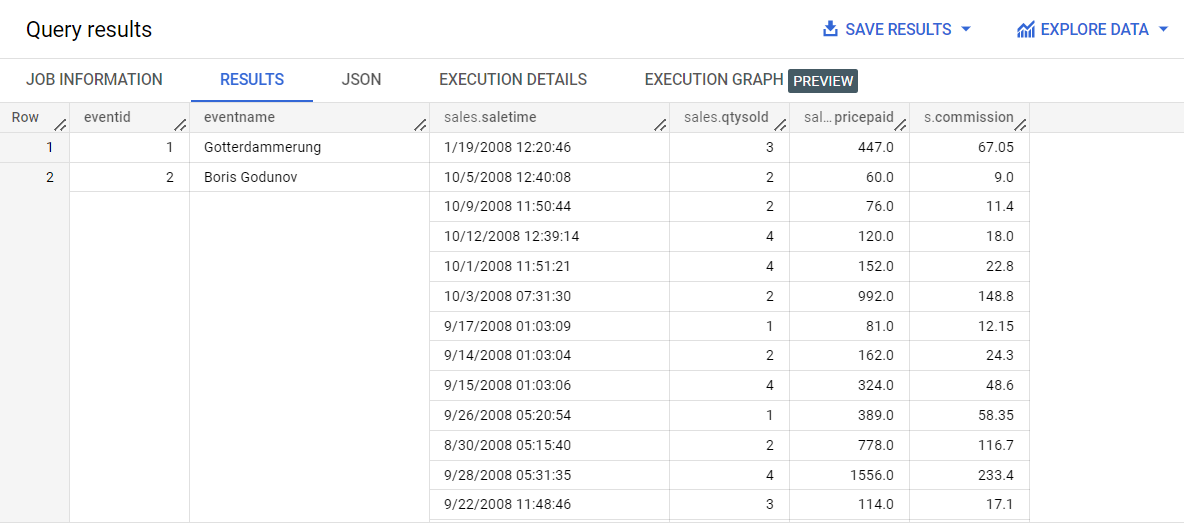
Você também pode incluir a consulta anterior em uma instrução CREATE TABLE para criar uma tabela hierárquica aninhada.
No editor, execute esta consulta:
CREATE OR REPLACE TABLE ticket_sales.event_sales
as (
SELECT
e.eventid,
e.eventname,
ARRAY_AGG(STRUCT(
s.saletime,
s.qtysold,
s.pricepaid,
s.commission)) as sales
FROM
ticket_sales.events e
JOIN
ticket_sales.sales s
ON
e.eventid = s.eventid
GROUP BY
eventid, eventname
);
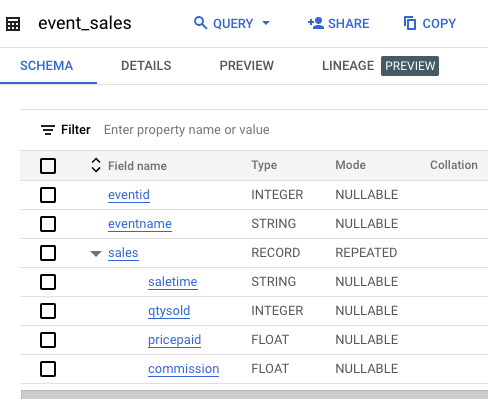
Clique em Acessar a tabela e analise o esquema dela.
O esquema inclui um campo aninhado e repetido chamado sales, que contém o horário da venda, a quantidade vendida, o preço pago e a comissão de cada venda do evento.
Essa nova estrutura aninhada e repetida muda a forma de escrever consultas.
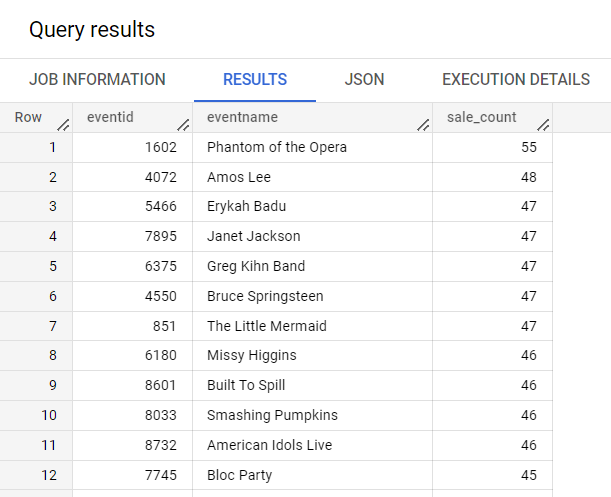
Para contar o número de vendas por evento, execute a seguinte consulta:
SELECT
eventid,
eventname,
ARRAY_LENGTH(sales) AS sale_count
FROM
ticket_sales.event_sales
ORDER BY
sale_count DESC;
E se você quisesse conferir as principais comissões por evento? Seria preciso ter uma consulta na matriz. Para isso, você precisa nivelar a matriz ou remover o aninhamento dela.
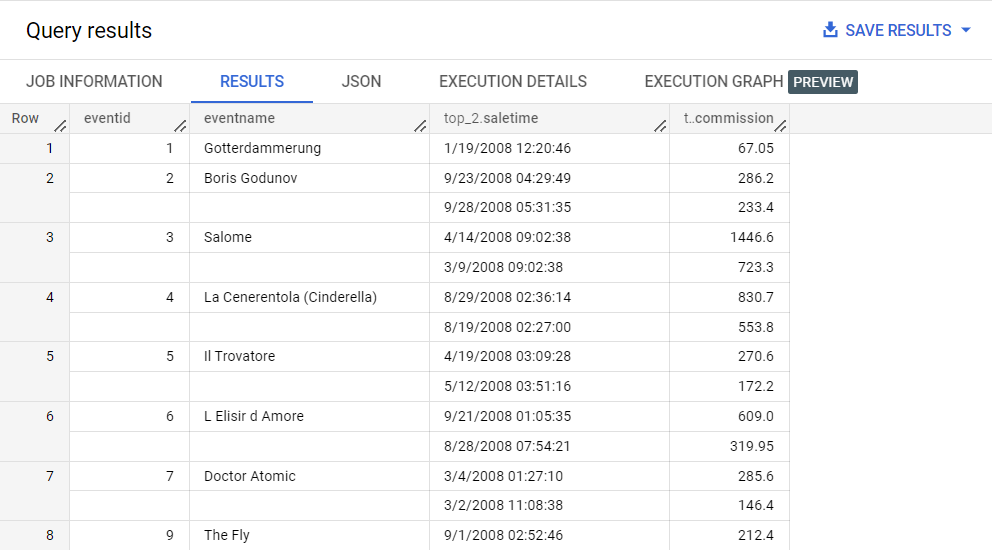
Para remover o aninhamento e identificar as duas principais comissões por evento, execute o seguinte:
SELECT
eventid,
eventname,
ARRAY((SELECT AS STRUCT saletime, commission FROM UNNEST(sales)
ORDER BY(commission) DESC LIMIT 2)) as top_2
FROM
ticket_sales.event_sales
ORDER BY
eventid;
O operador UNNEST é usado para nivelar a matriz de vendas e facilitar as consultas, e esses resultados são convertidos em uma matriz.
Para saber como usar UNNEST e nivelar matrizes, consulte a documentação Operador UNNEST.
Clique em Verificar meu progresso para conferir o objetivo.
criar e consultar campos aninhados e repetidos
Tarefa 3: criar e consultar tabelas particionadas
No BigQuery, um método para reduzir os bytes processados pelas consultas é dividir uma tabela grande em segmentos menores (partições) e incluir um filtro nas consultas para selecionar apenas os dados da partição que você escolher. Esse processo se chama remoção de partições e pode ser usado para reduzir os custos de uma consulta.
Nesta tarefa, você vai aprender a criar e consultar tabelas particionadas por unidade de tempo (em uma coluna DATETIME) para minimizar os bytes processados por consulta.
No editor de consultas, cole o seguinte código (não clique em "Executar" ainda):
SELECT * FROM ticket_sales.sales;
O validador de consultas no BigQuery estima quantos bytes serão processados durante a execução. Nesta consulta, a estimativa é de 15,12 MB.
Cole a consulta a seguir (não clique em "Executar" ainda):
SELECT * FROM ticket_sales.sales
WHERE saletime = '12/14/2008 09:13:17';
O número de bytes processados é o mesmo da consulta na Etapa 1 (15,12 MB), mesmo que a nova consulta esteja trazendo apenas vendas de uma data específica.
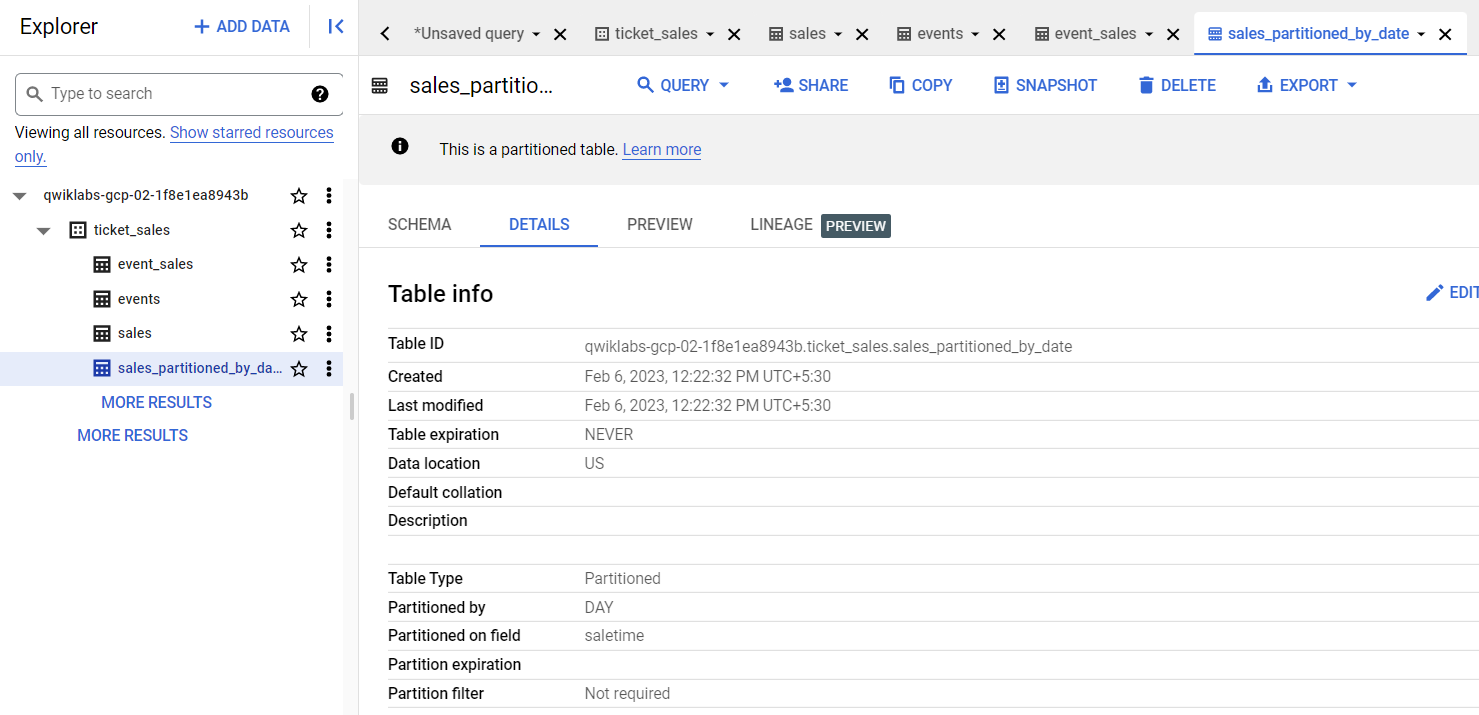
Para criar uma tabela de vendas particionada diariamente com a coluna saletime, execute a seguinte consulta:
CREATE OR REPLACE TABLE
ticket_sales.sales_partitioned_by_date
PARTITION BY
DATETIME_TRUNC(saletime, DAY)
AS (
SELECT
* except (saletime),
PARSE_DATETIME( "%m/%d/%Y %H:%M:%S", saletime) as saletime
FROM
ticket_sales.sales );
Clique na guia Detalhes para confirmar que a tabela está particionada por DIA na coluna saletime.
Cole a consulta a seguir para ver a estimativa menor de dados a processar (18, 98 KB).
SELECT *
FROM ticket_sales.sales_partitioned_by_date
WHERE saletime = parse_datetime("%m/%d/%Y %H:%M:%S", '12/14/2008 09:13:17');
Clique em Executar para trazer os resultados da consulta.
A consulta processa menos dados (18,98 KB) porque está sendo executada na tabela particionada. O BigQuery usa a remoção de partições para processar menos dados, o que reduz custos e acelera consultas.
Clique em Verificar meu progresso para conferir o objetivo.
Criar e consultar tabelas particionadas
Tarefa 4: criar e consultar tabelas em cluster
Outro método para otimizar o desempenho das consultas no BigQuery é agrupar valores em uma tabela para classificar e agrupar dados em blocos de armazenamento lógicos. As consultas que filtram ou agregam pelas colunas em cluster só verificam os blocos relevantes com base nas colunas em cluster, e não em toda a tabela ou na partição da tabela. Esse processo é conhecido como remoção de blocos e pode acelerar junções, pesquisas, agrupamentos e classificações.
Nesta tarefa, você vai aprender a criar e consultar tabelas em cluster para otimizar as consultas.
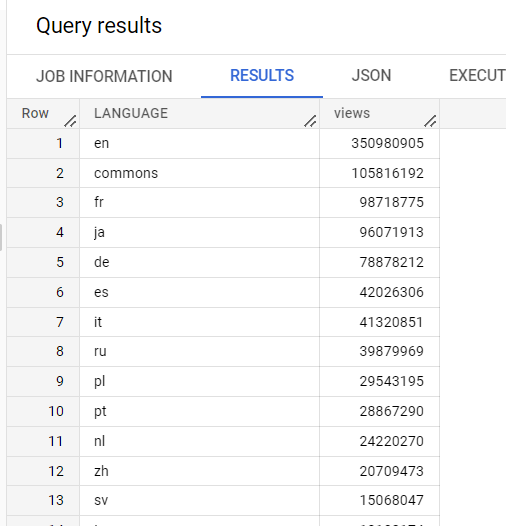
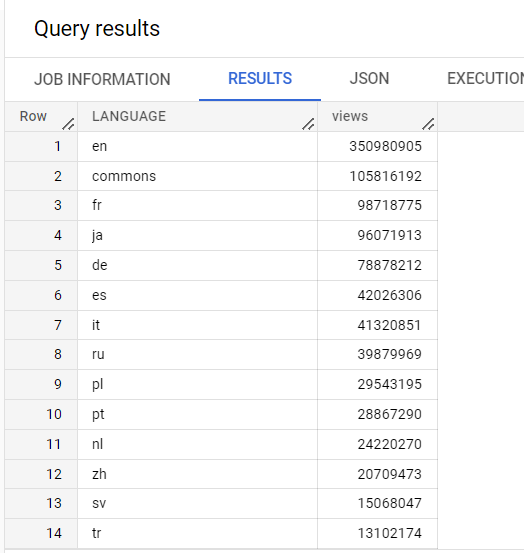
No editor, execute esta consulta:
SELECT
LANGUAGE,
COUNT(views) AS views
FROM
`cloud-training-demos.wikipedia_benchmark.Wiki1B`
GROUP BY
LANGUAGE
ORDER BY
views DESC;
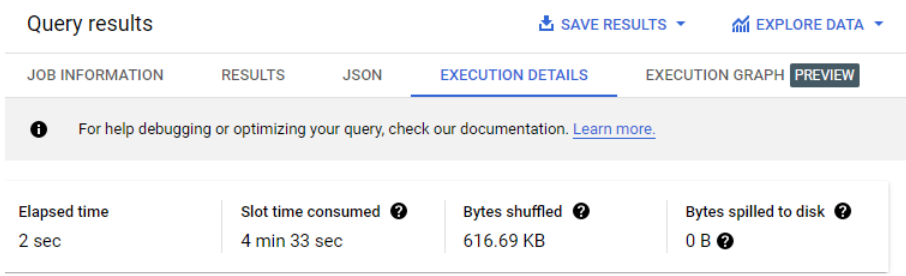
Essa consulta usa um dos conjuntos de dados públicos do Google que contém muitos dados (neste caso, 1 bilhão de linhas). A consulta conta visualizações por idioma em uma tabela de dados da Wikipedia.
No painel Resultados, clique na guia Detalhes da execução.
Observe o número de bytes redistribuídos (619,68 KB).
Para criar um conjunto com os dados da Wikipedia, execute a seguinte consulta:
CREATE SCHEMA IF NOT EXISTS
wiki_clustered OPTIONS(
location="us");
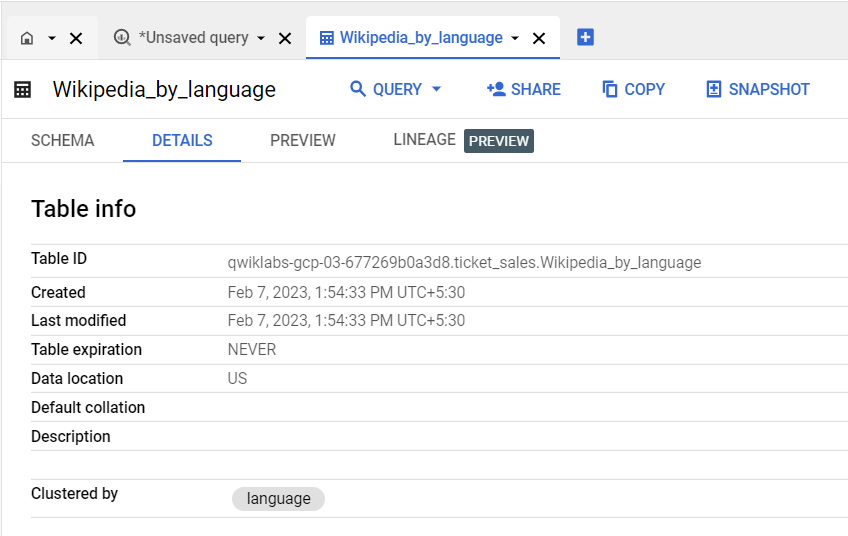
Para criar uma tabela agrupada na coluna language, execute a seguinte consulta:
CREATE OR REPLACE TABLE
wiki_clustered.Wikipedia_by_language
CLUSTER BY
language
AS (
SELECT * FROM `cloud-training-demos.wikipedia_benchmark.Wiki1B`);
Esse comando às vezes demora um pouco para rodar.
Confira na guia Detalhes da tabela se ela está agrupada na coluna language.
Para consultar a tabela em cluster, execute a consulta abaixo:
SELECT
LANGUAGE,
COUNT(views) AS views
FROM
wiki_clustered.Wikipedia_by_language
GROUP BY
language
ORDER BY
views DESC;
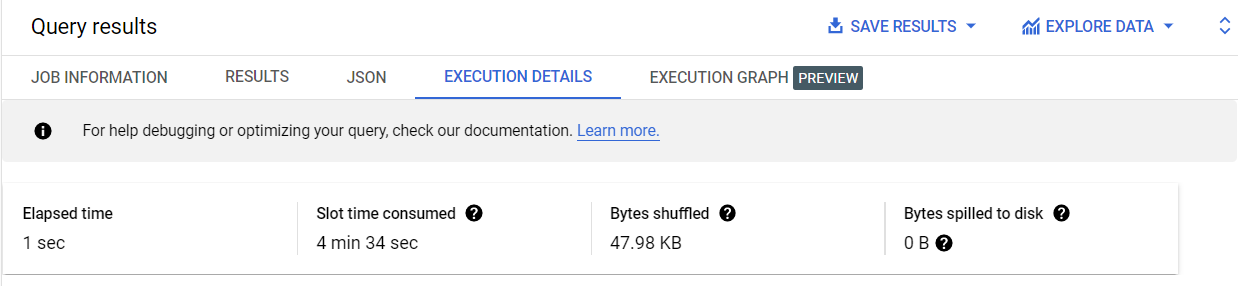
No painel Resultados, clique na guia Detalhes da execução.
O número de bytes redistribuídos fica menor (47,98 KB) quando a mesma consulta é executada na tabela em cluster. Quanto menor a redistribuição de bytes, mais rápida a execução no BigQuery.
Clique em Verificar meu progresso para conferir o objetivo.
Criar e consultar tabelas em cluster
Finalize o laboratório
Após concluir o laboratório, clique em Terminar o laboratório. O Google Skills remove os recursos usados e limpa a conta para você.
Você poderá classificar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender a definir e consultar esquemas de tabelas no BigQuery, além de criar e pesquisar campos aninhados e repetidos, tabelas particionadas e tabelas em cluster.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 60 minutos




 ) do console do Google Cloud, em "Analytics", clique em BigQuery.
) do console do Google Cloud, em "Analytics", clique em BigQuery.