Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Aplique suas habilidades no console do Google Cloud
Checkpoints
Estimate the amount of data processed by a query
Verificar meu progresso
/ 20
Determine slot usage using SQL query
Verificar meu progresso
/ 20
Complete a dry run of a query
Verificar meu progresso
/ 20
Instruções e requisitos de configuração do laboratório
Proteja sua conta e seu progresso. Sempre use uma janela anônima do navegador e suas credenciais para realizar este laboratório.
Como monitorar cargas de trabalho do BigQuery
Laboratório
1 hora
universal_currency_alt
5 créditos
show_chart
Introdutório
info
Este laboratório pode incorporar ferramentas de IA para ajudar no seu aprendizado.
Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
O armazenamento e a consulta de grandes conjuntos de dados podem levar muito tempo e custar caro sem a infraestrutura adequada. O BigQuery é um data warehouse empresarial sem servidor e totalmente gerenciado que permite consultas rápidas e baratas usando a capacidade de processamento da infraestrutura do Google. No BigQuery, os recursos de armazenamento e computação ficam desacoplado, o que oferece flexibilidade para armazenar e consultar dados de acordo com o que sua empresa precisa.
Neste laboratório, você vai usar o validador de consulta do BigQuery e a ferramenta de linha de comando bq para estimar a quantidade de dados a serem processados antes de executar uma consulta. Você também vai utilizar uma consulta SQL e a API para determinar o uso de recursos depois que uma consulta é executada com sucesso.
Objetivos
Neste laboratório, você vai aprender a:
Usar o validador de consulta do BigQuery para estimar a quantidade de dados que serão processados por uma consulta.
Determinar o uso de slots para consultas executadas usando uma consulta SQL e a API.
Simular uma consulta para estimar a quantidade de dados a serem processados.
Configuração e requisitos
Configuração do laboratório
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Como começar o laboratório e fazer login no console
Clique no botão Começar o laboratório. Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Um painel aparece à esquerda contendo as credenciais temporárias que você precisa usar no laboratório.
Copie o nome de usuário e clique em Abrir console do Google.
O laboratório ativa os recursos e depois abre a página Escolha uma conta em outra guia.
Observação: abra as guias em janelas separadas, lado a lado.
Na página "Escolha uma conta", clique em Usar outra conta. A página de login abre.
Cole o nome de usuário que foi copiado do painel "Detalhes da conexão". Em seguida, copie e cole a senha.
Observação: é necessário usar as credenciais do painel "Detalhes da conexão". Não use suas credenciais do Google Skills. Caso tenha sua própria conta do Google Cloud, não a use para este laboratório (isso evita cobranças).
Acesse as próximas páginas:
Aceite os Termos e Condições.
Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
Não se inscreva em testes sem custo financeiro.
Depois de alguns instantes, o console do Cloud abre nesta guia.
Observação: para acessar a lista dos produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Tarefa 1: usar o validador de consultas para estimar a quantidade de dados que serão processados
Quando você insere uma consulta no console do Google Cloud, o validador de consulta do BigQuery verifica a sintaxe dela e estima quantos bytes serão processados.
Nesta tarefa, você vai consultar um conjunto público de dados (New York Citi Bikes) mantido pelo programa Conjuntos de dados públicos do BigQuery. Com esse conjunto de dados, você vai aprender a usar o validador para validar uma consulta SQL e estimar a quantidade de dados a processar em uma consulta antes de executá-la.
No console do Google Cloud, no Menu de navegação (), em "Analytics", clique em BigQuery.
A caixa de mensagem "Olá! Este é o BigQuery no console do Cloud" vai aparecer. Esta caixa de mensagem fornece um link para o guia de início rápido e para as notas da versão.
Clique em Concluído.
Na barra do espaço de trabalho SQL, clique na guia Editor para abrir o editor de consultas SQL.
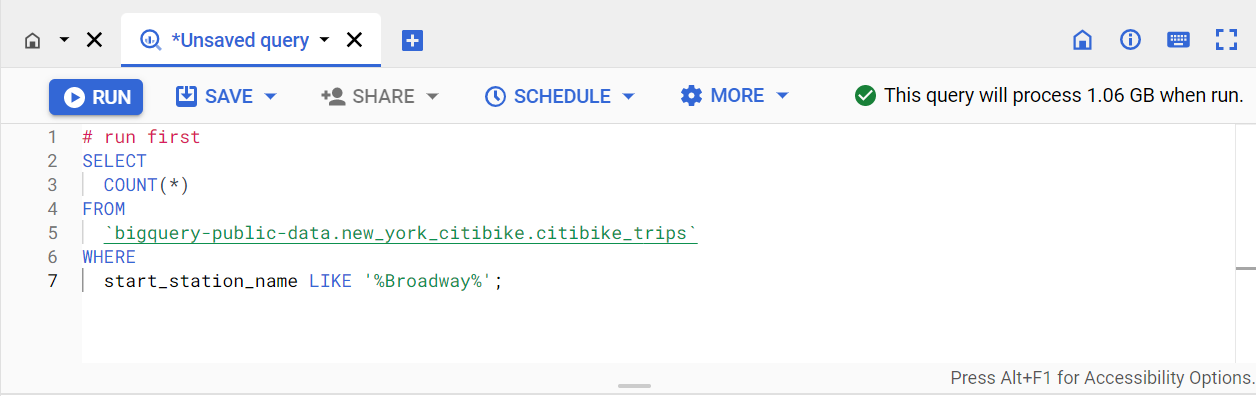
No editor de consultas do BigQuery, cole a consulta a seguir (não execute ainda):
SELECT
COUNT(*)
FROM
`bigquery-public-data.new_york_citibike.citibike_trips`
WHERE
start_station_name LIKE '%Broadway%';
Essa consulta retorna a contagem dos nomes de estações que contêm o texto "Broadway" na coluna start_station_name da tabela citibike_trips.
Na barra de ferramentas do editor de consultas, você encontra o ícone de marca de seleção circular, que ativa o validador e confirma se a consulta é válida.
O BigQuery executa o validador de consulta quando você adiciona ou modifica o código no editor de consultas.
A marca de verificação verde ou vermelha, respectivamente, indica se a consulta é válida ou inválida. Se a consulta for válida, o validador também vai mostrar a quantidade de dados que serão processados se você executar a consulta.
O validador estimou que essa consulta vai processar 1,06 GB quando for executada.
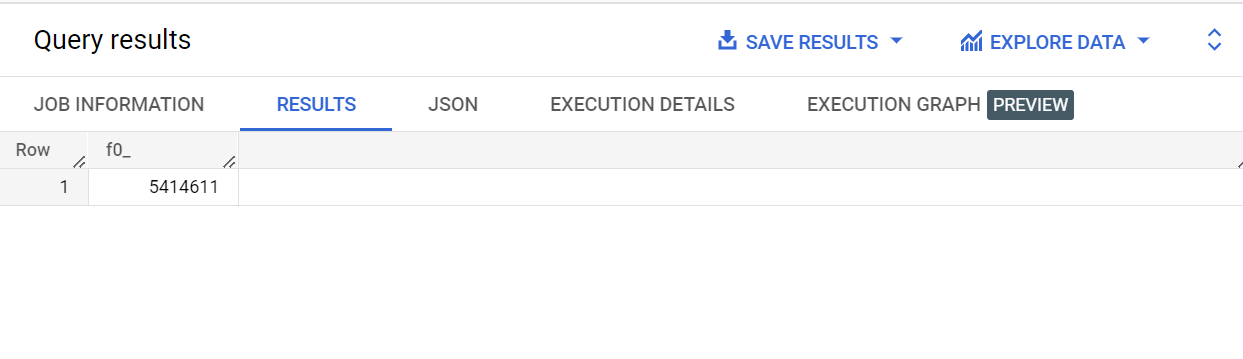
Clique em Executar.
A consulta retorna o número de registros (5.414.611) que contêm o texto "Broadway" na coluna start_station_name.
Clique em Verificar meu progresso para conferir o objetivo.
Estimar a quantidade de dados que uma consulta vai processar
Tarefa 2: determinar o uso de slots usando uma consulta SQL
O BigQuery usa slots (CPUs virtuais) para executar consultas SQL e calcula quantos slots cada consulta vai precisar, dependendo do tamanho e da complexidade da consulta. Depois de executar uma consulta no console do Google Cloud, você recebe os resultados e um resumo dos recursos usados no processo.
Nesta tarefa, você vai identificar o ID do job da consulta executada na tarefa anterior e usar em uma nova consulta SQL para trazer mais informações sobre o job.
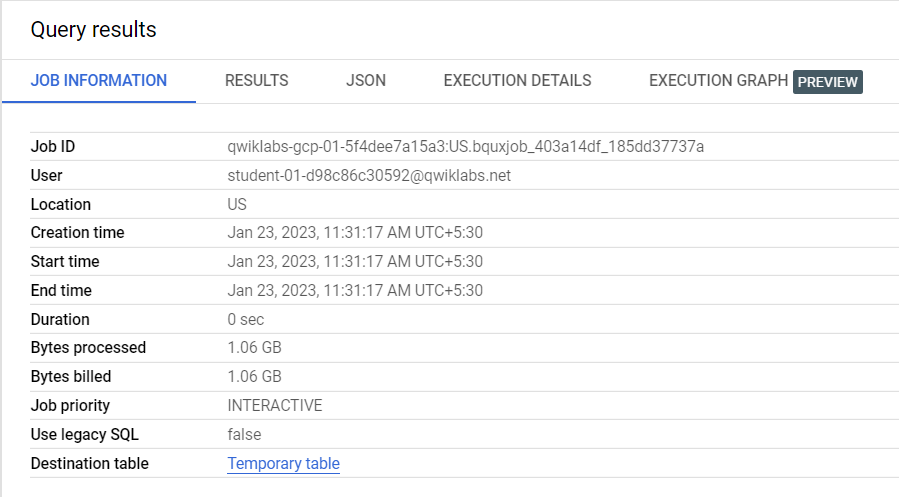
Nos resultados da consulta, clique na guia Informações do job.
Identifique a linha do ID do job e use o valor fornecido para selecionar o ID do projeto e do job.
Por exemplo, o valor qwiklabs-gcp-01-5f4dee7a15a3:US.bquxjob_403a14df_185dd37737a começa com o ID do projeto, seguido pelo local em que o job foi executado e pelo ID do job. A sintaxe de :US. identifica o local em que o job foi executado.
O ID do projeto é a primeira parte, qwiklabs-gcp-01-5f4dee7a15a3 (antes de :US.), enquanto o ID do job é a última parte bquxjob_403a14df_185dd37737a (depois de :US.).
Observação: você pode copiar o valor completo para um editor de texto ou documento e selecionar os IDs do projeto e do job com mais facilidade.
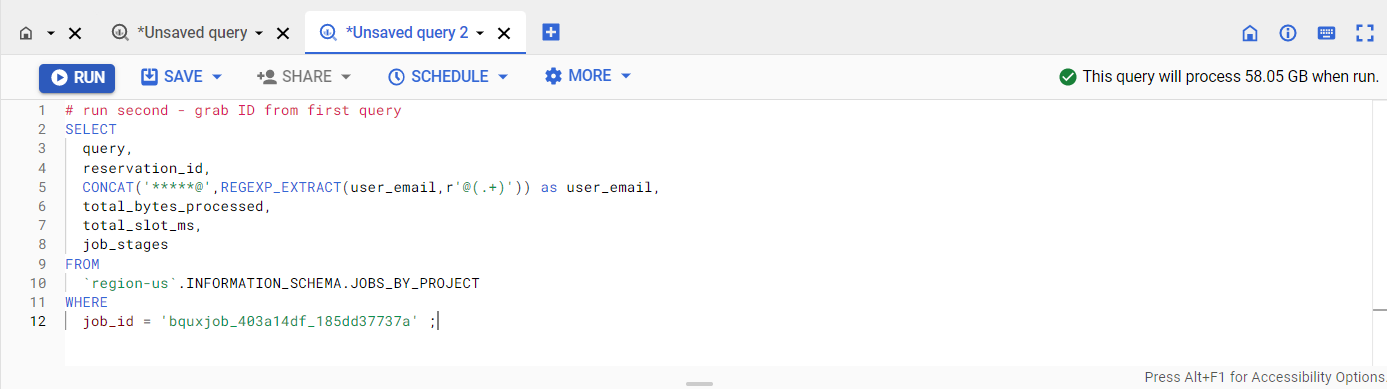
No editor de consultas, copie e cole a consulta a seguir e substitua 'YOUR_ID' pelo ID do job ('bquxjob_403a14df_185dd37737a'):
SELECT
query,
reservation_id,
CONCAT('*****@',REGEXP_EXTRACT(user_email,r'@(.+)'))
AS user_email,
total_bytes_processed,
total_slot_ms,
job_stages
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
job_id = 'YOUR_ID';
Quando executada, essa consulta traz o uso de slots do job de consulta executado antes no conjunto de dados público Citi Bikes.
Clique em Executar.
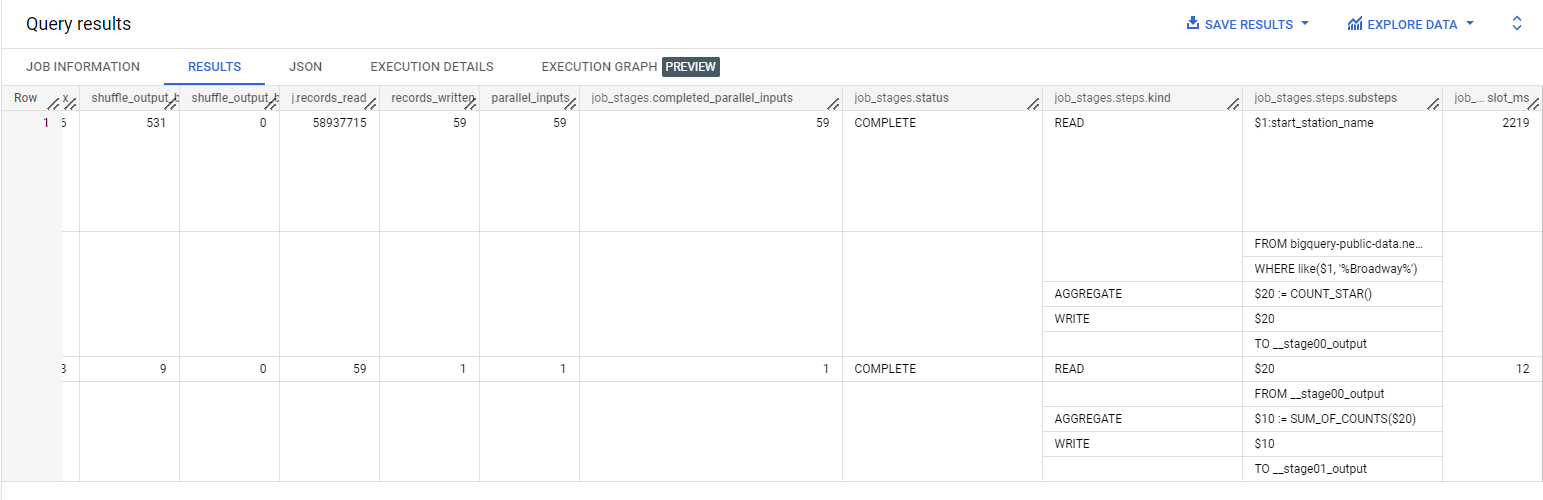
O resultado dessa consulta consiste em uma tabela que mostra as etapas da consulta e o uso de slots associado a cada etapa.
Como uma tarefa individual em uma consulta é executada por um slot, a soma dos valores na coluna job_stages.completed_parallel_inputs é o total de slots usados para executar a consulta.
No entanto, depois que um único slot conclui a primeira tarefa atribuída a ele, ele pode ser atribuído outra vez para outra tarefa.
Por isso, é importante saber qual é o tempo total de slot usado para executar a consulta (valor fornecido na coluna total_slot_ms). O tempo de slot, em milissegundos (ms), é mostrado tanto para todo o job de consulta quanto para cada etapa da consulta, representando a quantidade de tempo de slot utilizada para concluir a etapa em questão.
Por exemplo, uma consulta pode concluir 150 tarefas, mas se cada uma delas for executada rapidamente, a consulta usará menos slots, como 100, em vez de 150.
Clique em Verificar meu progresso para conferir o objetivo.
Determinar o uso de slots usando uma consulta SQL
Tarefa 3: determinar o uso de slots usando uma chamada de API
Também é possível coletar informações sobre um job de consulta específico usando a API. No BigQuery, você consegue usar a API fazendo solicitações ao servidor ou recorrer a bibliotecas de clientes na linguagem que preferir, como C#, Go, Java, Node.js, PHP, Python ou Ruby.
Nesta tarefa, você vai usar o APIs Explorer do Google para testar a API BigQuery e coletar dados de uso de slots da consulta executada em uma tarefa anterior.
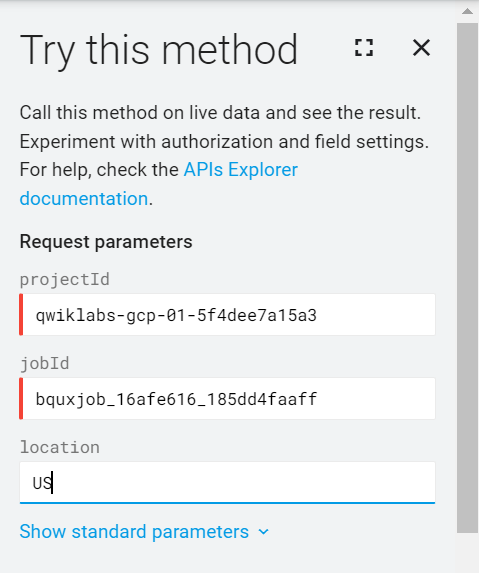
Em uma guia anônima do navegador, acesse a página da API BigQuery para o método jobs.get.
Na janela Testar este método, informe o ID do projeto e o ID do job que você identificou na tarefa anterior.
Por exemplo, qwiklabs-gcp-01-5f4dee7a15a3 para o ID do projeto e bquxjob_403a14df_185dd37737a para o ID do job.
Clique em Executar.
Se precisar confirmar o login, selecione o nome de usuário de estudante que você usou para fazer login no Google Cloud nas tarefas anteriores:
Analise a resposta da API em cada etapa e para o job de consulta por completo.
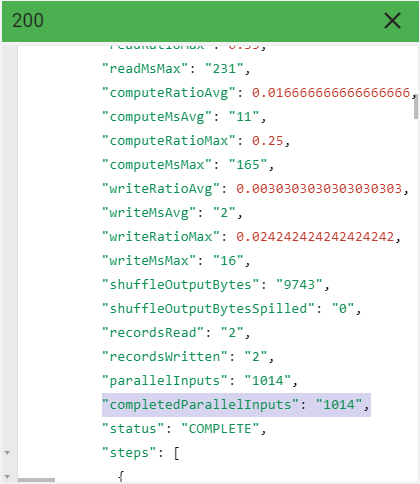
Para conferir o valor das entradas paralelas concluídas na primeira etapa, role a tela para baixo até statistics > query > queryPlan > name: S00 > completedParallelInputs.
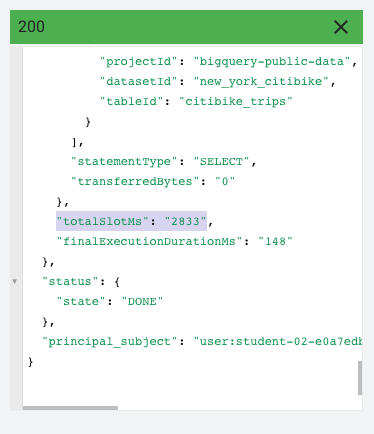
Para conferir o total de slots usados no job de consulta por completo, role a tela até o fim dos resultados e veja qual é o valor de totalSlotMs.
Tarefa 4: simular uma consulta para estimar a quantidade de dados processados
Na ferramenta de linha de comando bq, use a flag --dry_run para estimar o número de bytes lidos pela consulta antes de executá-la. Utilize também o parâmetro dryRun ao enviar um job de consulta pela API ou pelas bibliotecas de clientes. As simulações de consultas não usam slots de consulta, e você não recebe cobrança pelas simulações.
Nesta tarefa, você vai aprender a fazer uma simulação de consulta usando a ferramenta de linha de comando bq no Cloud Shell.
No Cloud Shell, execute este comando:
bq query \
--use_legacy_sql=false \
--dry_run \
'SELECT
COUNT(*)
FROM
`bigquery-public-data`.new_york_citibike.citibike_trips
WHERE
start_station_name LIKE "%Lexington%"'
A saída mostra a quantidade estimada de bytes que a consulta vai processar antes de você executá-la.
Consulta validada. Supondo que não seja feita nenhuma mudança nas tabelas, a execução dessa consulta processaria 1135353688 bytes de dados.
Agora que sabe quantos bytes serão processados pela consulta, você tem as informações necessárias para decidir as próximas etapas do fluxo de trabalho.
Clique em Verificar meu progresso para conferir o objetivo.
Fazer uma simulação de consulta
Finalize o laboratório
Após concluir o laboratório, clique em Terminar o laboratório. O Google Skills remove os recursos usados e limpa a conta para você.
Você poderá classificar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender a executar comandos de SQL e verificar o uso dos slots.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 60 minutos






 ), em "Analytics", clique em BigQuery.
), em "Analytics", clique em BigQuery.