Informações gerais
Neste laboratório, você vai aprender a usar o Vertex AI Pipelines para executar um pipeline de ML simples derivado do SDK do Kubeflow Pipelines.
Objetivos
Neste laboratório, você vai executar as seguintes tarefas:
- Configurar o ambiente do projeto.
- Inspecionar e configurar o código do pipeline.
- Executar o pipeline de IA.
Configuração e requisitos
Antes de clicar no botão "Começar o laboratório"
Importante: leia estas instruções.
Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático do Google Skills permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
O que é necessário
Veja os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo disponível para concluir as atividades
Observação: não use seu projeto ou conta pessoal do Google Cloud neste laboratório.
Observação: se você estiver usando um Pixelbook, faça o laboratório em uma janela anônima.
Como começar o laboratório e fazer login no console
-
Clique no botão Começar o laboratório. Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Um painel aparece à esquerda contendo as credenciais temporárias que você precisa usar no laboratório.

-
Copie o nome de usuário e clique em Abrir console do Google.
O laboratório ativa os recursos e depois abre a página Escolha uma conta em outra guia.
Observação: abra as guias em janelas separadas, lado a lado.
-
Na página "Escolha uma conta", clique em Usar outra conta. A página de login abre.

-
Cole o nome de usuário que foi copiado do painel "Detalhes da conexão". Em seguida, copie e cole a senha.
Observação: é necessário usar as credenciais do painel "Detalhes da conexão". Não use suas credenciais do Google Skills. Caso tenha sua própria conta do Google Cloud, não a use para este laboratório (isso evita cobranças).
- Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes sem custo financeiro.
Depois de alguns instantes, o console do Cloud abre nesta guia.
Observação: para acessar a lista dos produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo.

Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
-
No console do Google Cloud, em Menu de navegação ( ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.
-
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.

Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
- No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
- Copie o número do projeto, por exemplo,
729328892908.
- Em Menu de navegação, clique em IAM e administrador > IAM.
- Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
- Em Novos principais, digite:
{número-do-projeto}-compute@developer.gserviceaccount.com
- Substitua
{project-number} pelo número do seu projeto.
- Em Papel, selecione Projeto (ou Básico) > Editor.
- Clique em Save.
Tarefa 1: configurar o ambiente do projeto
O Vertex AI Pipelines é executado em um framework sem servidor em que pipelines pré-compilados são implantados sob demanda ou de maneira programada. Para que a execução ocorra sem problemas, é necessário configurar o ambiente.
Para facilitar a execução do código do pipeline em um ambiente do Qwiklabs, a conta de serviço do Compute precisa ter privilégios elevados no Cloud Storage.
-
No console do Google Cloud, acesse o Menu de navegação () e clique em IAM e administrador > IAM.
-
Clique no ícone de lápis da conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com e atribua o papel de Administrador do Storage.
-
Na janela deslizante, clique em Adicionar outro papel. Na caixa de pesquisa, digite Administrador do Storage. Selecione Administrador do Storage em Concede controle total sobre buckets e objetos na lista de resultados.
-
Clique em Salvar para atribuir o papel à conta de serviço do Compute.
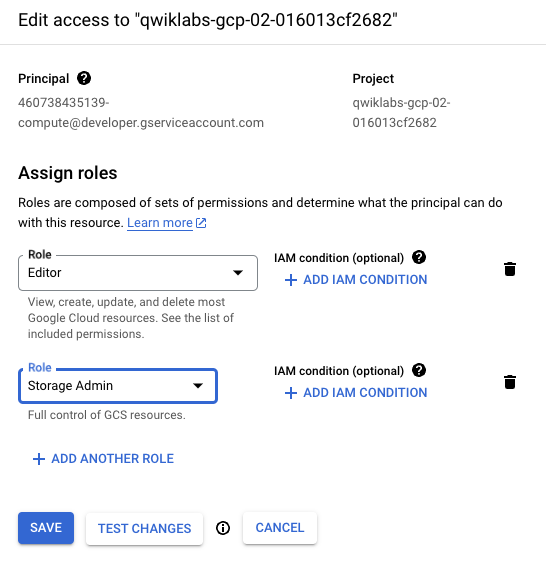
Os artefatos serão acessados na ingestão e na exportação à medida que o pipeline for executado.
- Execute este bloco de código no Cloud Shell para criar um bucket no seu projeto. O código também criará duas pastas e um arquivo vazio em cada uma delas:
gcloud storage buckets create gs://{{{primary_project.project_id|Project ID}}}
touch emptyfile1
touch emptyfile2
gcloud storage cp emptyfile1 gs://{{{primary_project.project_id|Project ID}}}/pipeline-output/emptyfile1
gcloud storage cp emptyfile2 gs://{{{primary_project.project_id|Project ID}}}/pipeline-input/emptyfile2
O pipeline já foi criado e só precisa de alguns ajustes para ser executado no projeto do Qwiklabs.
- Faça o download do pipeline de IA na pasta de recursos do laboratório:
wget https://storage.googleapis.com/cloud-training/dataengineering/lab_assets/ai_pipelines/basic_pipeline.json
Clique em Verificar meu progresso para conferir o objetivo.
Configurar o ambiente
Tarefa 2: configurar e inspecionar o código do pipeline
O código do pipeline é uma compilação de duas operações de IA escritas em Python. O exemplo é bem simples, mas mostra como é fácil orquestrar procedimentos de ML escritos em diversas linguagens (TensorFlow, Python, Java etc.) em um pipeline de IA fácil de implantar. O exemplo do laboratório mostra duas operações, concatenação e reversão, em dois valores de string.
- Primeiro, é preciso fazer um ajuste de configuração para atualizar a pasta de saída da execução do pipeline de IA. Para fazer isso, use o comando Linux Stream EDitor (sed) no Cloud Shell:
sed -i 's/PROJECT_ID/{{{primary_project.project_id|Project ID}}}/g' basic_pipeline.json
- Inspecione basic_pipeline.json para confirmar que a pasta de saída está configurada no projeto:
head -20 basic_pipeline.json
As partes mais importantes do código em basic_pipeline.json são os blocos deploymentSpec e command. O bloco abaixo é o primeiro comando, o job que concatena as strings de entrada. Este é o código do SDK do Kubeflow Pipelines (kfp), projetado para ser executado pelo mecanismo do Python 3.13. Como você não precisa mudar o código, esta seção é apenas para referência:
"program_path=$(mktemp -d)\n\nprintf \"%s\" \"$0\" > \"$program_path/ephemeral_component.py\"\n_KFP_RUNTIME=true python3 -m kfp.dsl.executor_main --component_module_path \"$program_path/ephemeral_component.py\" \"$@\"\n",
"\nimport kfp\nfrom kfp import dsl\nfrom kfp.dsl import *\nfrom typing import *\n\ndef concat(a: str, b: str) -> str:\n return a + b\n\n"
],
"image": "python:3.13"
- Para ter acesso ao arquivo completo, basta inserir o comando abaixo:
more basic_pipeline.json
Observação: pressione a tecla de espaço para avançar até o final do arquivo. Se você quiser fechar o arquivo antes do final, insira q para encerrar o comando more.
- Para ter acesso ao arquivo basic_pipeline.json atualizado e poder executar o job do pipeline de IA, mova o arquivo para o bucket do Cloud Storage que você criou:
gcloud storage cp basic_pipeline.json gs://{{{primary_project.project_id|Project ID}}}/pipeline-input/basic_pipeline.json
Clique em Verificar meu progresso para conferir o objetivo.
Implantar o pipeline
Tarefa 3: executar o pipeline de IA
-
No console, abra o Menu de navegação () e clique em Vertex AI > Painel.
-
Clique em Ativar todas as APIs recomendadas.
-
Aguarde a ativação e clique em Pipelines no menu à esquerda.
-
Clique em Criar execução no menu superior.
-
Em Detalhes da execução, selecione Importar do Cloud Storage e, para URL do Cloud Storage, navegue até a pasta pipeline-input que você criou dentro do bucket do projeto. Selecione o arquivo basic_pipeline.json.
-
Clique em Selecionar.
-
Em Região, escolha .
-
Mantenha os outros valores como o padrão e clique em Continuar.
Também é possível manter os valores de configuração do ambiente de execução como o padrão. Repare que o diretório de saída do Cloud Storage está definido como a pasta do bucket criada em uma etapa anterior. Os parâmetros de pipeline são preenchidos com os valores do arquivo basic_pipeline.json, mas podem ser alterados no ambiente de execução usando o assistente.
- Clique em Enviar para iniciar a execução do pipeline.
Observação: se você receber a mensagem Ocorreu um erro interno, aguarde de um a dois minutos e tente enviar o job novamente.
- Você vai voltar ao painel do pipeline, e a execução passa de Pendente para Em execução e, finalmente, Concluído.
Observação: a execução completa leva entre 3 e 6 minutos.
- Quando o status estiver como "Concluído", clique no nome da execução para acessar o gráfico e os detalhes dela.
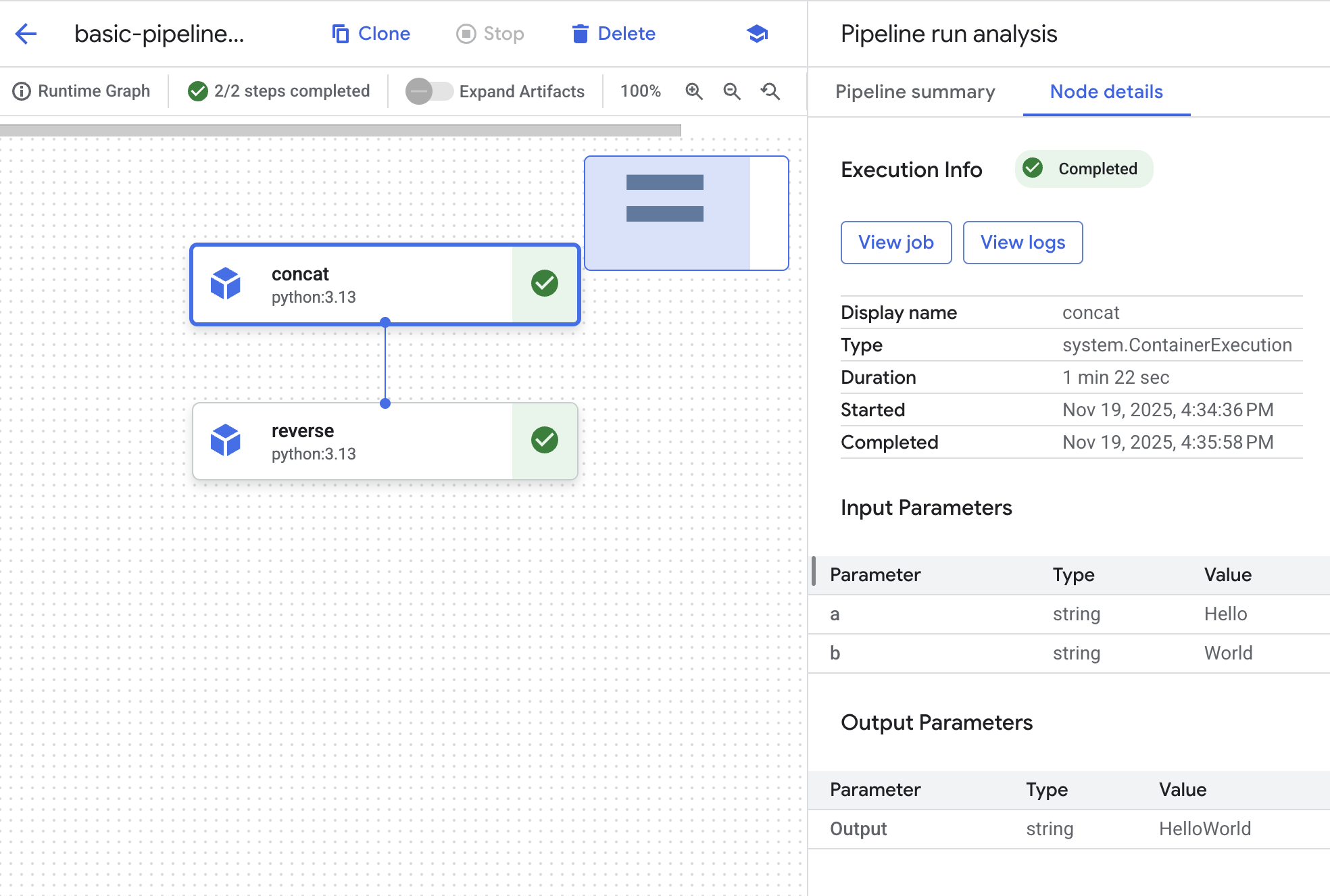
-
Cada etapa tem um elemento gráfico. Clique no objeto concat para conferir os detalhes do job.
-
Clique no botão Ver job. Uma nova guia é aberta com o job personalizado da Vertex AI que foi enviado ao back-end para atender à solicitação do pipeline.
Fique à vontade para conhecer mais detalhes sobre a execução do pipeline.
Parabéns!
Você usou o Vertex AI Pipelines para executar um pipeline de ML simples derivado do SDK do Kubeflow Pipelines.
Manual atualizado em 21 de novembro de 2025
Laboratório testado em 21 de novembro de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.






