![[認証情報] パネル](https://cdn.qwiklabs.com/%2FtHp4GI5VSDyTtdqi3qDFtevuY014F88%2BFow%2FadnRgE%3D)
![[別のアカウントを使用] オプションがハイライト表示されている、アカウントのダイアログ ボックスを選択します。](https://cdn.qwiklabs.com/eQ6xPnPn13GjiJP3RWlHWwiMjhooHxTNvzfg1AL2WPw%3D)
![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
![権限の編集のダイアログ。前述のフィールドと [保存] ボタンを含みます。](https://cdn.qwiklabs.com/Ld5CofNEngBLa3H9z7dgrddG4vgTsqk1KBTEkrp6Bvc%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Configure the environment
/ 20
Deploy Pipeline
/ 10

このラボでは、Vertex AI Pipelines を使用して、Kubeflow Pipeline SDK で作成したシンプルな ML パイプラインを実行する方法について学習します。
このラボでは、次のタスクを行います。
この Google Skills ハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを実施できます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側のパネルには、このラボで使用する必要がある一時的な認証情報が表示されます。
ユーザー名をコピーし、[Google Console を開く] をクリックします。 ラボでリソースが起動し、別のタブで [アカウントの選択] ページが表示されます。
[アカウントの選択] ページで [別のアカウントを使用] をクリックします。[ログイン] ページが開きます。
[接続の詳細] パネルでコピーしたユーザー名を貼り付けます。パスワードもコピーして貼り付けます。
しばらくすると、このタブで Cloud コンソールが開きます。

Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。Vertex AI Pipelines はサーバーレスのフレームワークで実行されます。このフレームワークでは、事前コンパイル済みのパイプラインがオンデマンドで、またはスケジュールに従ってデプロイされます。円滑に実行するためには、環境の構成を行う必要があります。
Qwiklabs 環境でパイプライン コードをシームレスに実行するには、コンピューティング サービス アカウントの Cloud Storage に対する権限昇格を行う必要があります。
Google Cloud コンソールのナビゲーション メニュー(
デフォルトのコンピューティング サービス アカウント {project-number}-compute@developer.gserviceaccount.com の鉛筆アイコンをクリックし、[ストレージ管理者] ロールを割り当てます。
スライドアウト ウィンドウで [別のロールを追加] をクリックします。検索ボックスに「ストレージ管理者」と入力します。検索結果のリストから、[バケットとオブジェクトのすべてを管理する権限を付与します] と書かれた [ストレージ管理者] を選択します。
[保存] をクリックし、コンピューティング サービス アカウントにロールを割り当てます。
パイプラインの実行に伴い、アーティファクトは取り込み時とエクスポート時にアクセスされます。
パイプラインはすでに作成されています。このパイプラインを Qwiklabs プロジェクトで実行できるようにするには、いくつかの微調整が必要です。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
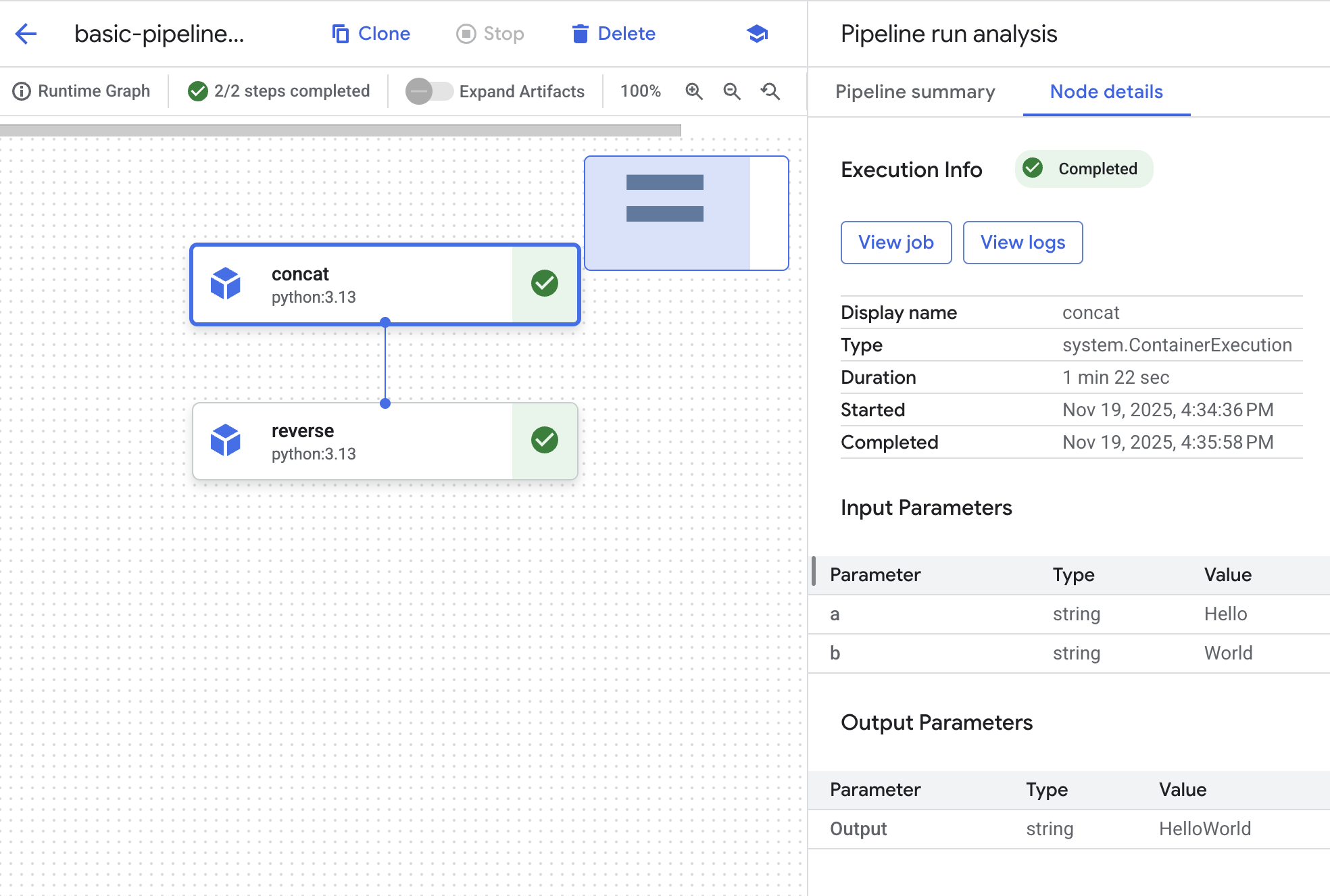
パイプライン コードは、Python で記述された 2 つの AI オペレーションで構成されます。この例はとてもシンプルですが、さまざまな言語(TensorFlow、Python、Java など)で記述された ML プロシージャを、デプロイしやすい AI パイプラインにオーケストレーションすることがいかに簡単であるかを示しています。ラボの例では、2 つの文字列の値に対して連結と取り消しの 2 つのオペレーションを実行します。
basic_pipeline.json のコードの主なセクションは、deploymentSpec ブロックと command ブロックです。以下は、最初の command ブロックである、入力文字列を連結するジョブです。これは、Python 3.13 エンジンで実行されるように設計された Kubeflow Pipeline SDK(kfp)コードです。今回はコードを変更しません。以下は参照用のセクションです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
コンソールでナビゲーション メニュー(
[すべての推奨 API を有効にする] をクリックします。
API が有効になったら、左側のメニューの [パイプライン] をクリックします。
トップメニューにある [実行を作成] をクリックします。
[実行の詳細] で [Cloud Storage からインポートする] を選択し、[Cloud Storage の URL] でプロジェクトの Cloud Storage バケット内で作成した pipeline-input フォルダを参照します。basic_pipeline.json ファイルを選択します。
[選択] をクリックします。
[リージョン] で
残りのデフォルト値は変更せず、[続行] をクリックします。
[ランタイムの構成] はデフォルト値のままにします。Cloud Storage 出力ディレクトリが、前のステップで作成したバケット フォルダに設定されていることに注目してください。パイプライン パラメータは basic_pipeline.json ファイルの値から事前に入力されていますが、このウィザードで実行時に変更することもできます。
ステップごとにグラフの要素が存在します。concat オブジェクトをクリックしてジョブの詳細を確認します。
[ジョブを表示] ボタンをクリックします。新しいタブが開き、パイプラインのリクエストを満たすためにバックエンドに送信された Vertex AI のカスタムジョブが表示されます。
必要に応じて、パイプラインの実行に関するその他の詳細も確認できます。
Vertex AI Pipelines を使用して、Kubeflow Pipeline SDK で作ったシンプルな ML パイプラインを実行しました。
マニュアルの最終更新日: 2025 年 11 月 21 日
ラボの最終テスト日: 2025 年 11 月 21 日
Copyright 2026 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください