Présentation
Dans cet atelier, vous allez apprendre à utiliser Vertex AI Pipelines pour exécuter un pipeline de ML simple dérivé du SDK Kubeflow Pipelines.
Objectifs
Dans cet atelier, vous allez réaliser les tâches suivantes :
- Configurer l'environnement du projet
- Configurer et inspecter le code du pipeline
- Exécuter le pipeline d'IA
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Remarque : Lisez ces instructions.
Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique Google Skills vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Ce dont vous avez besoin
Pour réaliser cet atelier, vous devez :
- avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- disposer de suffisamment de temps pour effectuer l'atelier en une fois.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier.
Remarque : Si vous utilisez un Pixelbook, veuillez exécuter cet atelier dans une fenêtre de navigation privée.
Démarrer votre atelier et vous connecter à la console
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous verrez un panneau contenant les identifiants temporaires à utiliser pour cet atelier.

-
Copiez le nom d'utilisateur, puis cliquez sur Ouvrir la console Google.
L'atelier lance les ressources, puis la page Sélectionner un compte dans un nouvel onglet.
Remarque : Ouvrez les onglets dans des fenêtres distinctes, placées côte à côte.
-
Sur la page "Sélectionner un compte", cliquez sur Utiliser un autre compte. La page de connexion s'affiche.

-
Collez le nom d'utilisateur que vous avez copié dans le panneau "Détails de connexion". Copiez et collez ensuite le mot de passe.
Remarque : Vous devez utiliser les identifiants fournis dans le panneau "Détails de connexion", et non ceux de votre compte Google Skills. Si vous possédez un compte Google Cloud, ne vous en servez pas pour cet atelier (vous éviterez ainsi que des frais vous soient facturés).
- Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.

Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
-
Dans la console Google Cloud, accédez au menu de navigation ( ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.
-
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.

Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
- Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
- Copiez le numéro du projet (par exemple,
729328892908).
- Dans le menu de navigation, sélectionnez IAM et administration > IAM.
- Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
- Dans le champ Nouveaux comptes principaux, saisissez :
{project-number}-compute@developer.gserviceaccount.com
- Remplacez
{project-number} par le numéro de votre projet.
- Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
- Cliquez sur Enregistrer.
Tâche 1 : Configurer l'environnement du projet
Vertex AI Pipelines s'exécute dans un framework sans serveur au sein duquel des pipelines précompilés sont déployés à la demande ou selon une programmation. Il est nécessaire de configurer l'environnement afin de faciliter l'exécution.
Pour une exécution aisée du code de pipeline dans un environnement Qwiklabs, le compte de service Compute doit disposer de droits élevés sur Cloud Storage.
-
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur IAM et administration > IAM.
-
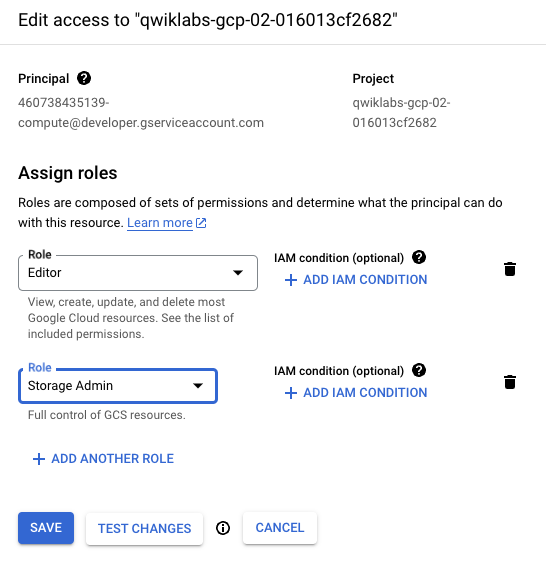
Cliquez sur l'icône en forme de crayon correspondant au compte de service Compute par défaut {numéro-projet}-compute@developer.gserviceaccount.com pour lui attribuer le rôle Administrateur Storage.
-
Dans la fenêtre latérale, cliquez sur Ajouter un autre rôle. Saisissez Administrateur Storage dans le champ de recherche. Dans la liste des résultats, sélectionnez Administrateur Storage avec Accorde un contrôle complet sur les buckets et les objets.
-
Cliquez sur Enregistrer pour attribuer le rôle au compte de service Compute.
Les artefacts seront traités au moment de l'ingestion et de l'exportation lors de l'exécution du pipeline.
- Exécutez ce bloc de code dans Cloud Shell pour créer un bucket dans votre projet, ainsi que deux dossiers contenant chacun un fichier vide :
gcloud storage buckets create gs://{{{primary_project.project_id|Project ID}}}
touch emptyfile1
touch emptyfile2
gcloud storage cp emptyfile1 gs://{{{primary_project.project_id|Project ID}}}/pipeline-output/emptyfile1
gcloud storage cp emptyfile2 gs://{{{primary_project.project_id|Project ID}}}/pipeline-input/emptyfile2
Le pipeline a déjà été créé. Seuls quelques ajustements mineurs sont nécessaires pour autoriser son exécution dans votre projet Qwiklabs.
- Téléchargez le pipeline Vertex AI depuis le dossier des ressources de l'atelier :
wget https://storage.googleapis.com/cloud-training/dataengineering/lab_assets/ai_pipelines/basic_pipeline.json
Cliquez sur Vérifier ma progression pour valider l'objectif.
Configurer l'environnement
Tâche 2 : Configurer et inspecter le code du pipeline
Le code du pipeline, rédigé en Python, correspond à deux opérations d'IA. Il s'agit d'un exemple très basique, mais qui montre à quel point il est simple d'orchestrer des procédures de ML écrites dans de nombreux langages (TensorFlow, Python, Java, etc.) au sein d'un pipeline Vertex AI facile à déployer. L'exemple de code de l'atelier exécute deux opérations, concaténation et inversion, sur deux valeurs de chaîne.
- Tout d'abord, vous devez définir un nouveau dossier de sortie pour l'exécution du pipeline Vertex AI. Dans Cloud Shell, utilisez la commande Linux Stream EDitor (sed) pour ajuster ce paramètre :
sed -i 's/PROJECT_ID/{{{primary_project.project_id|Project ID}}}/g' basic_pipeline.json
- Inspectez le fichier basic_pipeline.json pour vérifier que le dossier de sortie est défini sur votre projet :
head -20 basic_pipeline.json
Les portions de code les plus importantes dans basic_pipeline.json sont les blocs deploymentSpec et command. Vous pouvez voir ci-dessous le bloc "command", lequel correspond au job qui concatène les chaînes d'entrée. Il s'agit de code du SDK Kubeflow Pipelines (kfp), destiné à être exécuté par le moteur Python 3.13. Aucune modification n'est à apporter ici, cette portion de code n'est présentée qu'à titre de référence :
"program_path=$(mktemp -d)\n\nprintf \"%s\" \"$0\" > \"$program_path/ephemeral_component.py\"\n_KFP_RUNTIME=true python3 -m kfp.dsl.executor_main --component_module_path \"$program_path/ephemeral_component.py\" \"$@\"\n",
"\nimport kfp\nfrom kfp import dsl\nfrom kfp.dsl import *\nfrom typing import *\n\ndef concat(a: str, b: str) -> str:\n return a + b\n\n"
],
"image": "python:3.13"
- Vous pouvez parcourir l'intégralité du fichier en saisissant la commande suivante :
more basic_pipeline.json
Remarque : Appuyez sur la barre d'espace pour faire défiler le fichier jusqu'à la fin. Si vous souhaitez fermer le fichier avant d'atteindre la fin, saisissez q pour arrêter la commande more.
- Ensuite, déplacez le fichier basic_pipeline.json mis à jour vers le bucket Cloud Storage créé précédemment. Ainsi, le fichier sera disponible pour l'exécution du pipeline Vertex AI :
gcloud storage cp basic_pipeline.json gs://{{{primary_project.project_id|Project ID}}}/pipeline-input/basic_pipeline.json
Cliquez sur Vérifier ma progression pour valider l'objectif.
Déployer le pipeline
Tâche 3 : Exécuter le pipeline Vertex AI
-
Dans la console, ouvrez le menu de navigation (), puis cliquez sur Vertex AI > Tableau de bord.
-
Cliquez sur Activer toutes les API recommandées.
-
Une fois l'API activée, cliquez sur Pipelines dans le menu de gauche.
-
Cliquez sur Créer une exécution dans le menu supérieur.
-
Dans Détails de l'exécution, sélectionnez Importer depuis Cloud Storage et pour URL Cloud Storage, accédez au dossier pipeline-input que vous avez créé dans le bucket Cloud Storage de votre projet. Sélectionnez le fichier basic_pipeline.json.
-
Cliquez sur Sélectionner.
-
Pour Région, sélectionnez .
-
Conservez les autres valeurs par défaut et cliquez sur Continuer.
Vous pouvez laisser les valeurs par défaut pour Configuration de l'environnement d'exécution. Notez que le répertoire de sortie Cloud Storage est défini sur le dossier de bucket créé précédemment. Les champs de paramètres du pipeline sont préremplis à l'aide des valeurs du fichier basic_pipeline.json. Sachez toutefois qu'un assistant vous permet de modifier ces valeurs au moment de l'exécution.
- Cliquez sur Envoyer pour lancer l'exécution du pipeline.
Remarque : Si le message Internal error encountered (Erreur interne rencontrée) s'affiche, veuillez patienter une ou deux minutes, puis réessayez d'envoyer le job.
- Vous êtes redirigé vers le tableau de bord du pipeline, où vous verrez la tâche passer par ces trois états : En attente, En cours d'exécution, et enfin Réussie.
Remarque : L'exécution totale prend entre trois et six minutes.
- Une fois que l'exécution a atteint l'état "Réussie", cliquez sur son nom pour afficher le graphique de l'exécution et les informations détaillées.
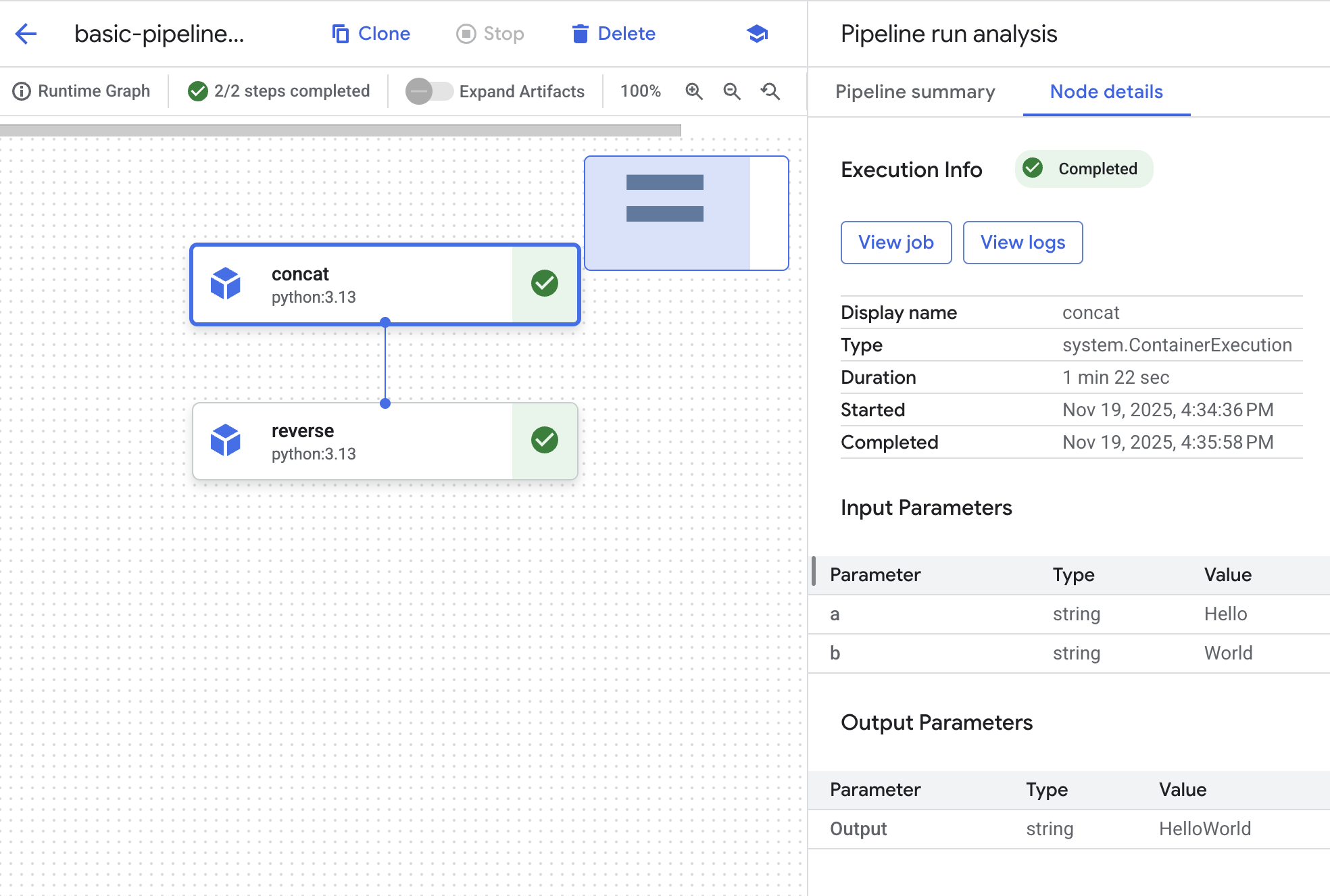
-
Un élément de graphique existe pour chaque étape. Cliquez sur l'objet concat pour consulter les détails du job.
-
Cliquez sur le bouton Afficher le job. Un nouvel onglet s'ouvre avec le job personnalisé Vertex AI qui a été soumis au backend pour faire aboutir la requête de pipeline.
N'hésitez pas à explorer plus en détail l'exécution du pipeline.
Félicitations !
Vous avez utilisé Vertex AI Pipelines pour exécuter un pipeline de ML simple dérivé du SDK Kubeflow Pipelines.
Dernière mise à jour du manuel : 21 novembre 2025
Dernier test de l'atelier : 21 novembre 2025
Copyright 2026 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.






