Descripción general
En este lab, aprenderás a usar Vertex AI Pipelines para ejecutar una canalización de AA simple derivada del SDK de Kubeflow Pipelines.
Objetivos
En este lab, realizarás las siguientes tareas:
- Configurar el entorno del proyecto
- Inspeccionar y configurar el código de la canalización
- Ejecutar la canalización de IA
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Nota: Lee estas instrucciones.
Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico de Google Skills te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que usarás para acceder a Google Cloud durante todo el lab.
Requisitos
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab
Nota: Si ya tienes un proyecto o una cuenta personal de Google Cloud, no los uses para el lab.
Nota: Si usas una Pixelbook, abre una ventana de incógnito para ejecutar el lab.
Cómo iniciar tu lab y acceder a la consola
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá una ventana emergente para que selecciones tu forma de pago.
A la izquierda, verás un panel con las credenciales temporales que debes usar para este lab.

-
Copia el nombre de usuario y, luego, haz clic en Abrir la consola de Google.
El lab inicia los recursos y abre otra pestaña que muestra la página Elige una cuenta.
Sugerencia: Abre las pestañas en ventanas separadas, una junto a la otra.
-
En la página Elige una cuenta, haz clic en Usar otra cuenta. Se abrirá la página de acceso.

-
Pega el nombre de usuario que copiaste del panel Detalles de la conexión. Luego, copia y pega la contraseña.
Nota: Debes usar las credenciales del panel Detalles de la conexión. No uses tus credenciales de Google Skills. Si tienes una cuenta propia de Google Cloud, no la utilices para este lab para no incurrir en cargos.
- Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Cloud en esta pestaña.
Nota: Para ver el menú con una lista de los productos y servicios de Google Cloud, haz clic en el menú de navegación que se encuentra en la parte superior izquierda de la pantalla.

Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
-
En la consola de Google Cloud, en el Menú de navegación ( ), selecciona IAM y administración > IAM.
), selecciona IAM y administración > IAM.
-
Confirma que aparezca la cuenta de servicio predeterminada de Compute {número-del-proyecto}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud > Panel.

Nota: Si la cuenta no aparece en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
- En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud > Panel.
- Copia el número del proyecto (p. ej.,
729328892908).
- En el Menú de navegación, selecciona IAM y administración > IAM.
- En la parte superior de la tabla de funciones, debajo de Ver por principales, haz clic en Otorgar acceso.
- En Principales nuevas, escribe lo siguiente:
{project-number}-compute@developer.gserviceaccount.com
- Reemplaza
{número-del-proyecto} por el número de tu proyecto.
- En Rol, selecciona Proyecto (o Básico) > Editor.
- Haz clic en Guardar.
Tarea 1. Configura el entorno del proyecto
Vertex AI Pipelines se ejecuta en un framework sin servidores en el que las canalizaciones precompiladas se implementan a pedido demanda o en un horario. Para facilitar la ejecución correcta se requiere una configuración determinada del entorno.
Para ejecutar sin problemas el código de la canalización en un entorno de Qwiklabs, la cuenta de servicio de Compute necesita privilegios elevados en Cloud Storage.
-
En el menú de navegación () de la consola de Google Cloud, haz clic en IAM y administración > IAM.
-
Haz clic en el ícono de lápiz para que la cuenta de servicio de Compute predeterminada {project-number}-compute@developer.gserviceaccount.com asigne el rol de Administrador de almacenamiento.
-
En la ventana deslizante, haz clic en Agregar otro rol. Escribe Administrador de almacenamiento en el cuadro de búsqueda. Selecciona Administrador de almacenamiento con Otorga control total sobre los buckets y los objetos en la lista de resultados.
-
Haz clic en Guardar para asignar el rol a la cuenta de servicio de Compute.
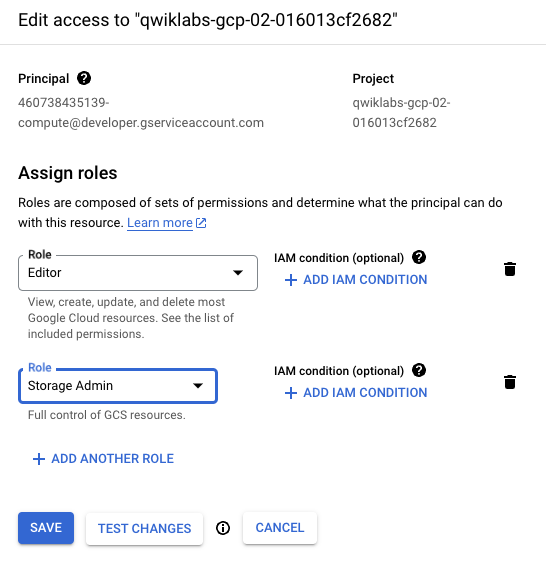
Se accederá a los artefactos en la transferencia y exportación como ejecuciones de canalización.
- Ejecuta este bloque de código en Cloud Shell para crear un bucket en tu proyecto y dos carpetas, cada una con un archivo vacío:
gcloud storage buckets create gs://{{{primary_project.project_id|Project ID}}}
touch emptyfile1
touch emptyfile2
gcloud storage cp emptyfile1 gs://{{{primary_project.project_id|Project ID}}}/pipeline-output/emptyfile1
gcloud storage cp emptyfile2 gs://{{{primary_project.project_id|Project ID}}}/pipeline-input/emptyfile2
La canalización se creó para ti y simplemente requiere unos pequeños ajustes para permitir que se ejecute en tu proyecto de Qwiklabs.
- Descarga la canalización de IA desde la carpeta de recursos del lab:
wget https://storage.googleapis.com/cloud-training/dataengineering/lab_assets/ai_pipelines/basic_pipeline.json
Haz clic en Revisar mi progreso para verificar el objetivo.
Configurar el entorno
Tarea 2. Inspecciona y configura el código de la canalización
El código de la canalización es una compilación de dos operaciones de IA escritas en Python. El ejemplo es muy simple, pero demuestra lo fácil que es organizar los procedimientos de AA escritos en una variedad de lenguajes (TensorFlow, Python, Java, etc.) en una canalización de IA fácil de implementar. En el ejemplo del lab, se realizan dos operaciones, concatenación e inversión, sobre dos valores de cadena.
- En primer lugar, debes realizar un ajuste para actualizar la carpeta de salida de la ejecución de la canalización de IA. En Cloud Shell, usa el comando de Linux Stream EDitor (sed) para cambiar este parámetro de configuración:
sed -i 's/PROJECT_ID/{{{primary_project.project_id|Project ID}}}/g' basic_pipeline.json
- Inspecciona basic_pipeline.json para confirmar que la carpeta de salida sea la de tu proyecto:
head -20 basic_pipeline.json
Las secciones clave de código en basic_pipeline.json son los bloques deploymentSpec y command. A continuación, se muestra el primer bloque de comandos, el trabajo que concatena las cadenas de entrada. Este es el código del SDK de Kubeflow Pipelines (kfp) que está diseñado para que lo ejecute el motor de Python 3.13. No cambiarás ningún código, la sección se muestra aquí para que tengas una referencia:
"program_path=$(mktemp -d)\n\nprintf \"%s\" \"$0\" > \"$program_path/ephemeral_component.py\"\n_KFP_RUNTIME=true python3 -m kfp.dsl.executor_main --component_module_path \"$program_path/ephemeral_component.py\" \"$@\"\n",
"\nimport kfp\nfrom kfp import dsl\nfrom kfp.dsl import *\nfrom typing import *\n\ndef concat(a: str, b: str) -> str:\n return a + b\n\n"
],
"image": "python:3.13"
- Puedes explorar todo el archivo con el siguiente comando:
more basic_pipeline.json
Nota: Presiona la barra espaciadora para avanzar por el archivo hasta el final. Si deseas cerrar antes el archivo, escribe q para cerrar el comando more.
- A continuación, mueve el archivo basic_pipeline.json actualizado al bucket de Cloud Storage que se creó anteriormente para poder acceder a él y ejecutar un trabajo de canalización de IA:
gcloud storage cp basic_pipeline.json gs://{{{primary_project.project_id|Project ID}}}/pipeline-input/basic_pipeline.json
Haz clic en Revisar mi progreso para verificar el objetivo.
Implementar la canalización
Tarea 3. Ejecuta la canalización de IA
-
En la consola, abre el menú de navegación () y haz clic en Vertex AI > Panel.
-
Haz clic en Habilitar todas las APIs recomendadas.
-
Cuando se habilite la API, haz clic en Canalizaciones en el menú de la izquierda.
-
Haz clic en Crear ejecución en el menú superior.
-
En Detalles de ejecución, selecciona Importar desde Cloud Storage y para la URL de Cloud Storage, ve a la carpeta pipeline-input que creaste en el bucket de Cloud Storage del proyecto. Selecciona el archivo basic_pipeline.json.
-
Haz clic en Seleccionar.
-
En Región, selecciona .
-
Conserva los demás valores predeterminados y haz clic en Continuar.
Puedes conservar los valores predeterminados de Configuración del entorno de ejecución. Observa que el directorio de salida de Cloud Storage es la carpeta de bucket creada en un paso anterior. Los parámetros de la canalización se completaron previamente a partir de los valores del archivo basic_pipeline.json, pero puedes modificarlos en el entorno de ejecución con este asistente.
- Haz clic en Enviar para iniciar la ejecución de la canalización.
Nota: Si ves el mensaje Se produjo un error interno, espera entre 1 y 2 minutos y vuelve a enviar el trabajo.
- Volverás al panel de la canalización y tu ejecución pasará de Pendiente a En ejecución y, luego, a Sin errores.
Nota: El proceso tardará entre 3 y 6 minutos en completarse.
- Cuando el estado cambie a Sin errores, haz clic en el nombre de la ejecución para ver el gráfico y los detalles de la ejecución.
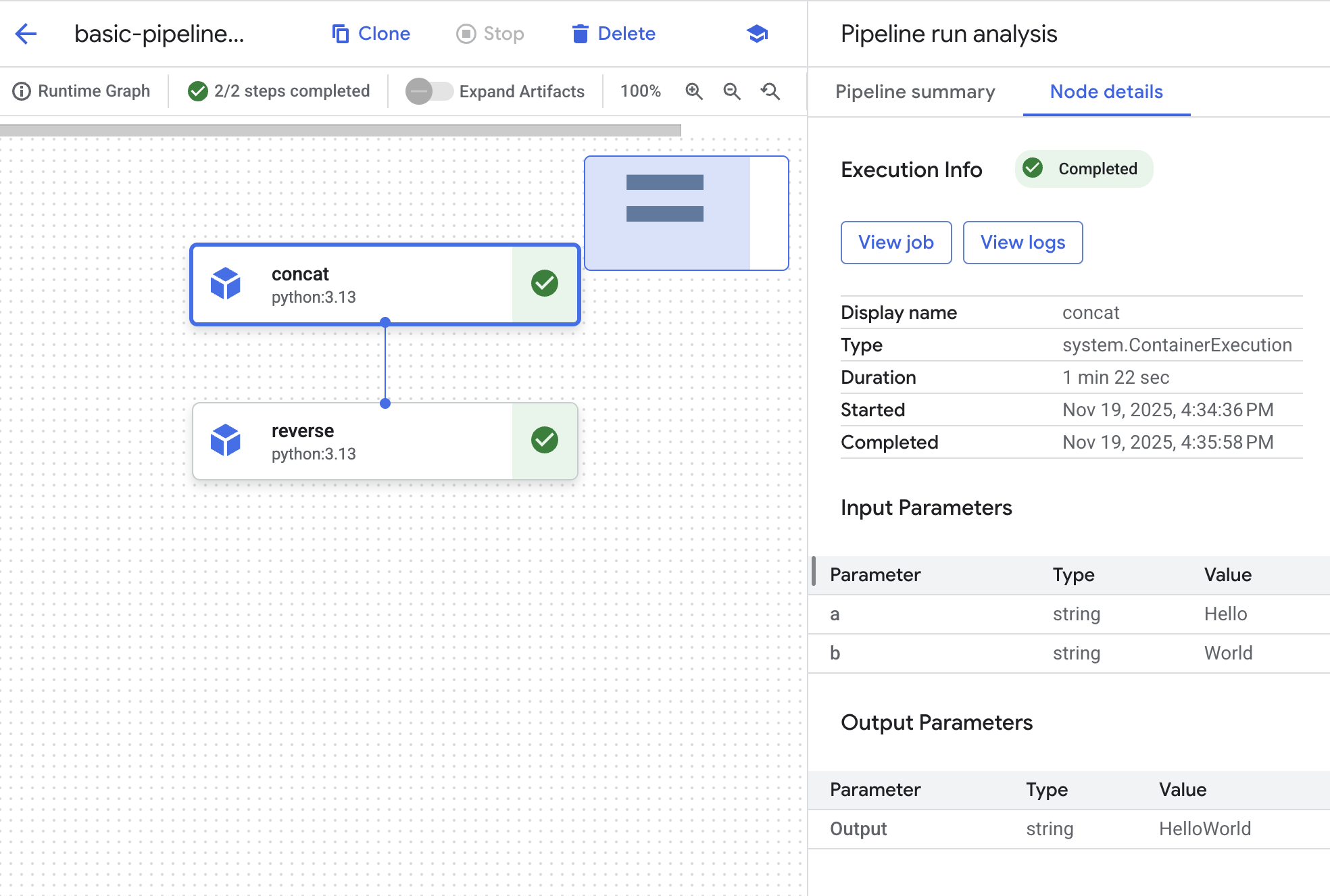
-
Cada elemento del gráfico corresponde a uno de los pasos. Haz clic en el objeto concat para ver los detalles del trabajo.
-
Haz clic en el botón Ver trabajo. Se abrirá una nueva pestaña con el trabajo personalizado de Vertex AI que se envió al backend para cumplir con la solicitud de la canalización.
Siéntete libre de explorar más detalles sobre la ejecución de la canalización.
¡Felicitaciones!
Usaste con éxito Vertex AI Pipelines para ejecutar una canalización de AA simple derivada del SDK de Kubeflow Pipelines.
Actualización más reciente del manual: 21 de noviembre de 2025
Prueba más reciente del lab: 21 de noviembre de 2025
Copyright 2026 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.






