Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
Neste laboratório, você vai aprender a criar e executar pipelines de ML com o Vertex Pipelines.
Objetivos
Criar um notebook de instância do Workbench.
Usar o SDK do Kubeflow Pipelines para criar pipelines de ML escalonáveis.
Criar e executar um pipeline introdutório de três etapas que recebe uma entrada de texto.
A Vertex AI tem duas soluções de notebooks, o Workbench e o Colab Enterprise.
Workbench
O Vertex AI Workbench é uma boa opção para projetos que priorizam o controle e a personalização. Ele é ótimo para quando há vários arquivos com dependências complexas. Também é uma boa escolha para cientistas de dados que estão fazendo a transição da nuvem para uma estação de trabalho ou notebook.
As instâncias do Vertex AI Workbench vêm com um pacote pré-instalado de pacotes de aprendizado profundo, incluindo o suporte para os frameworks TensorFlow e PyTorch.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Iniciar o Cloud Shell
Neste laboratório, você vai trabalhar em uma sessão do Cloud Shell, que é um interpretador de comandos hospedado por uma máquina virtual em execução na nuvem do Google. A sessão também pode ser executada localmente no seu computador, mas se você usar o Cloud Shell, todas as pessoas vão ter acesso a uma experiência reproduzível em um ambiente consistente. Após concluir o laboratório, é uma boa ideia testar a sessão no seu computador.
Na primeira vez que você solicitar uma autorização no Cloud Shell, a caixa de diálogo "Autorizar Cloud Shell" vai aparecer. Você já pode clicar no botão Autorizar.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ().
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:
O Cloud Shell tem algumas variáveis de ambiente, incluindo a GOOGLE_CLOUD_PROJECT que contém o nome do nosso projeto atual do Cloud. Vamos usar esses dados várias vezes neste laboratório. É possível ver essa variável ao executar:
echo $GOOGLE_CLOUD_PROJECT
Ative as APIs
Nas próximas etapas, você vai entender onde e por que esses serviços são necessários. Por enquanto, apenas execute este comando para conceder ao seu projeto acesso aos serviços do Compute Engine, Container Registry e Vertex AI:
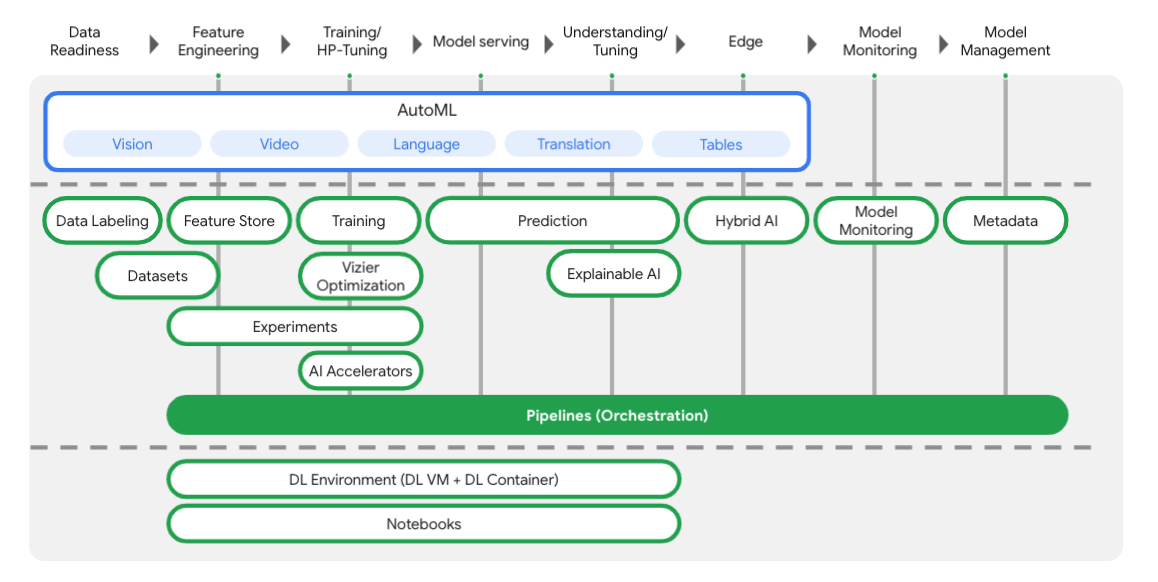
Este laboratório usa a Vertex AI, que integra as soluções de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos existentes para a Vertex AI.
Além de oferecer treinamento de modelos e serviços de implantação, a Vertex AI também inclui uma variedade de produtos de MLOps, como o Vertex Pipelines (o assunto desse laboratório), Monitoramento de modelos, Feature Store e outros. Confira todos as ofertas de produtos da Vertex AI no diagrama abaixo.
Por que pipelines de ML são úteis?
Antes de começar, primeiro entenda em quais situações você usaria um pipeline. Imagine que você está criando um fluxo de trabalho de ML que inclui processamento de dados, treinamento de modelos, ajuste de hiperparâmetros, avaliação e implantação de modelos. Cada uma dessas etapas pode ter dependências diferentes, o que pode ser difícil de administrar se você tratar o fluxo inteiro como algo monolítico.
Ao começar a escalonar seu processo de ML, você pode querer compartilhar seu fluxo de trabalho de ML com outras pessoas da sua equipe para que elas possam executar e colaborar com código. Sem um processo confiável e possível de ser reproduzido, isso pode ser difícil. Com pipelines, cada etapa do seu processo de ML é um contêiner próprio, o que permite que você desenvolva as etapas independentemente e rastreie a entrada e a saída de cada etapa de maneira possível de ser reproduzida. Você também pode agendar ou acionar execuções do seu pipeline com base em outros eventos do seu ambiente do Cloud, como iniciar uma execução de pipeline quando novos dados de treinamento estiverem disponíveis.
Tarefa 1: criar um bucket do Cloud Storage
Para executar um job de treinamento na Vertex AI, precisamos de um bucket de armazenamento para nossos recursos de modelo salvos. O bucket precisa ser regional. Estamos usando a região aqui, mas você pode usar qualquer outra, é só fazer a substituição durante o laboratório.
Se você já tem um bucket, pule esta etapa.
Execute os comandos a seguir no terminal do Cloud Shell para criar um bucket:
A próxima etapa é configurar o acesso da conta de serviço do computador a esse bucket. Isso garante que o Vertex Pipelines tenha o papel do IAM necessário para gravar arquivos no bucket.
Execute o comando a seguir para adicionar esse papel do IAM:
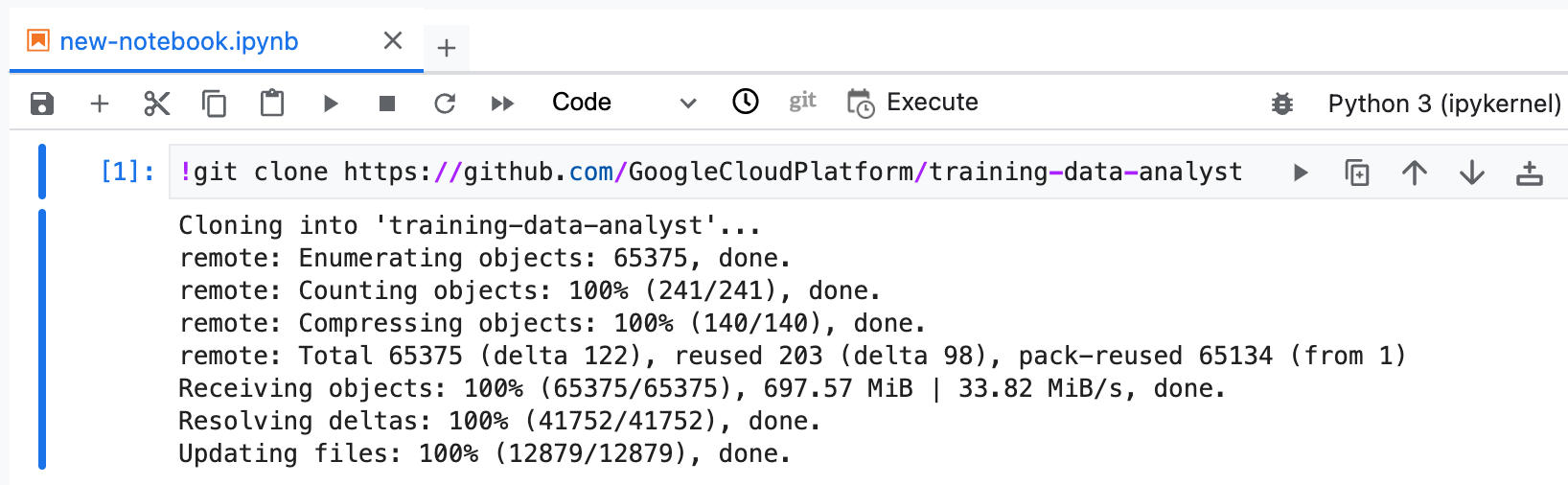
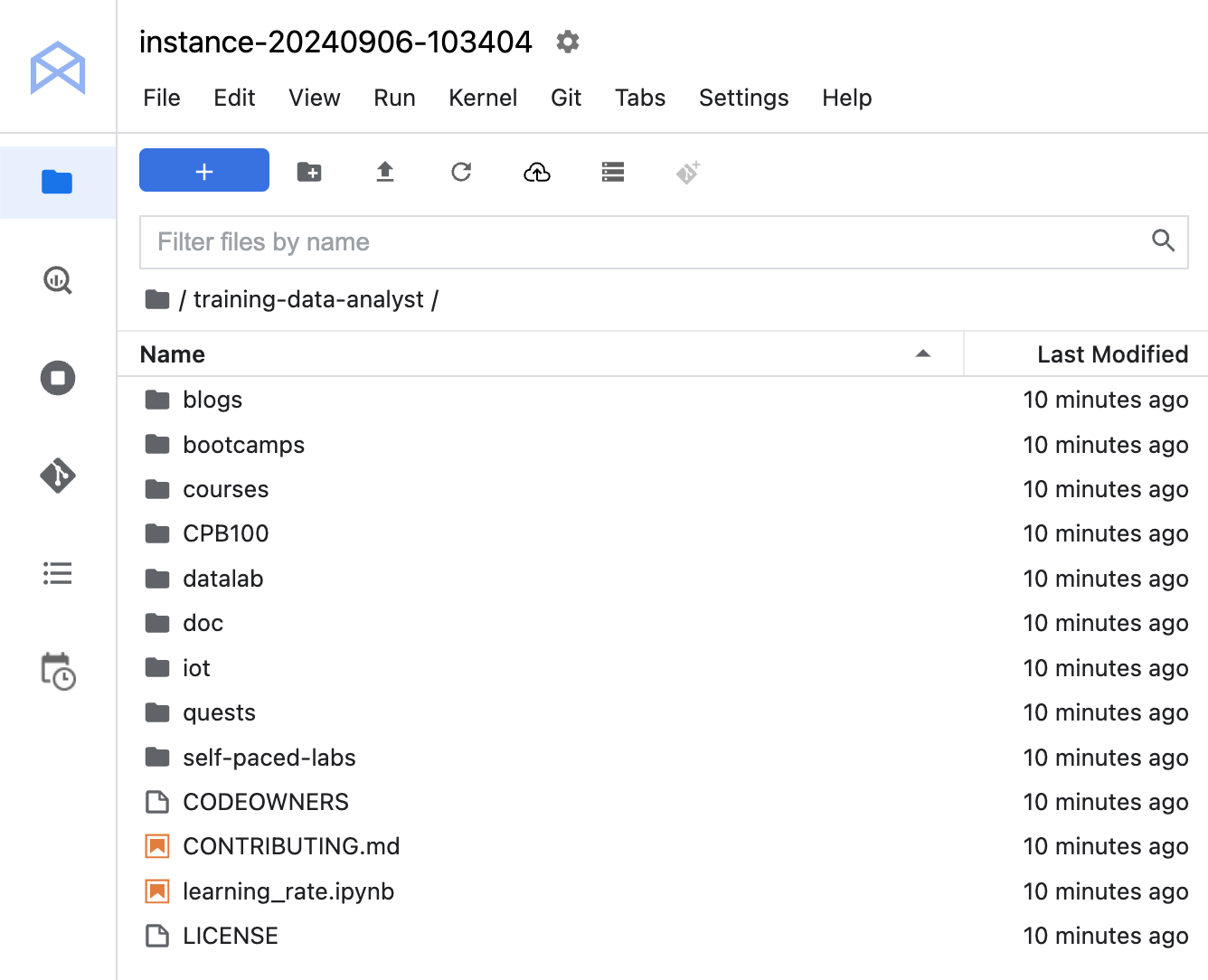
Para confirmar que você clonou o repositório, clique duas vezes no diretório training-data-analyst e veja se o conteúdo aparece.
Clique em Verificar meu progresso para conferir o objetivo.
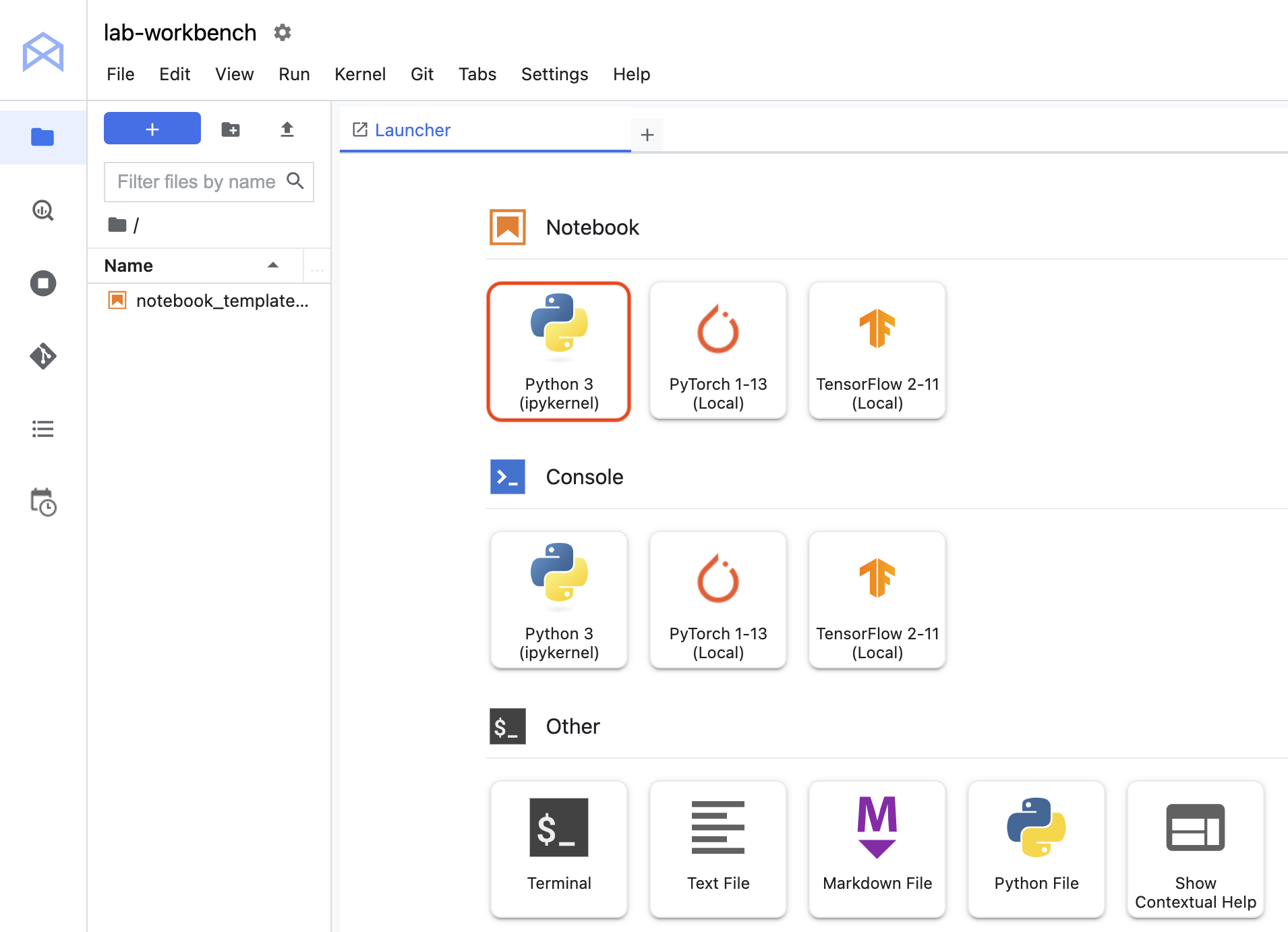
Clonar um repositório do curso na sua interface do JupyterLab.
Tarefa 4: introdução ao Vertex Pipelines
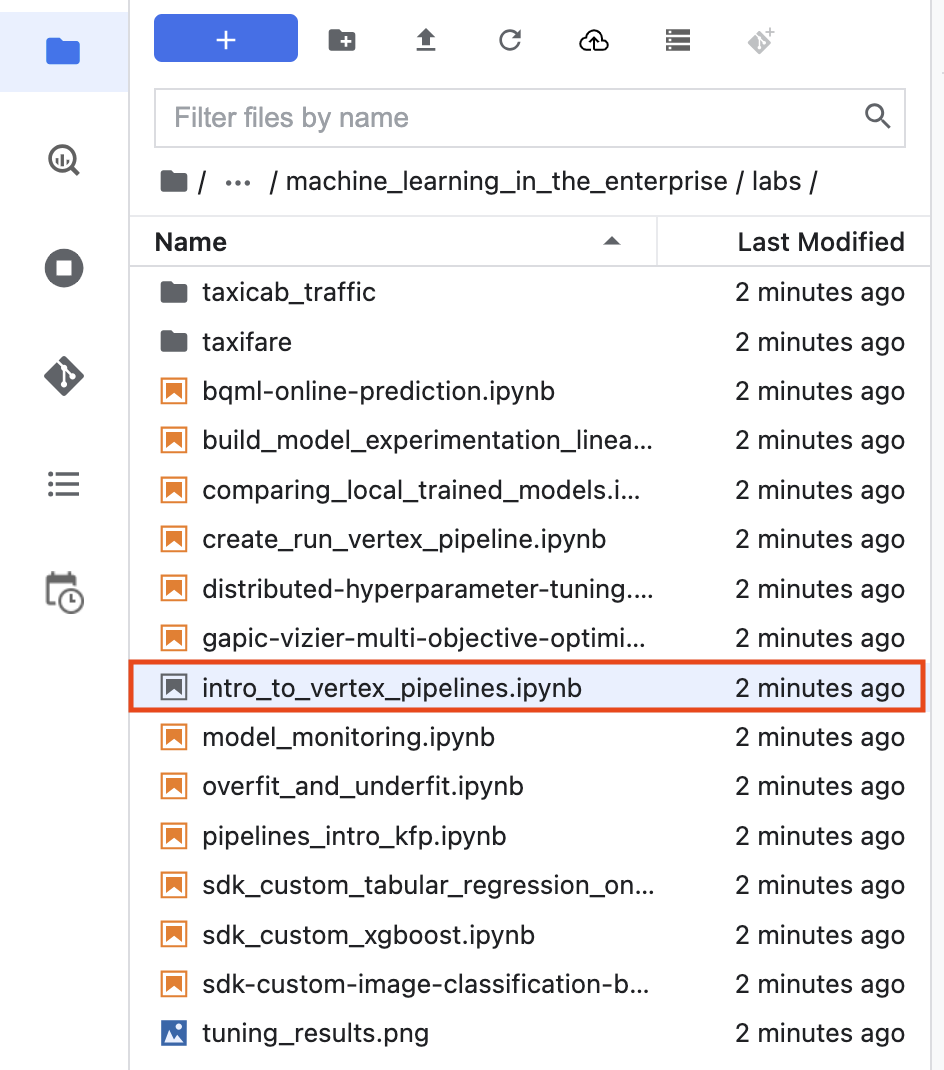
Na interface do notebook, acesse training-data-analyst > courses > machine_learning > deepdive2 > machine_learning_in_the_enterprise > labs e abra intro_to_vertex_pipelines.ipynb.
Escolha Python 3 (ipykernel) (local) para Selecionar kernel.
Na interface do notebook, clique em Editar > Limpar todas as saídas.
Leia com atenção as instruções do notebook e preencha as linhas marcadas com #TODO quando precisar concluir o código. Execute cada célula para observar as saídas.
Clique em Verificar meu progresso para conferir o objetivo.
Introdução ao Vertex Pipelines.
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender como criar e executar pipelines de ML com o Vertex Pipelines.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 90 minutos


 ).
).
 ), clique em Vertex AI.
), clique em Vertex AI. Criar.
Criar.