GSP283

Übersicht
Angenommen, Sie haben Datasets, die sich an verschiedenen Orten auf der ganzen
Welt befinden, und Ihre Daten sind in Google Cloud Storage-Buckets oder in
BigQuery-Tabellen gespeichert. Wie können Sie diese Daten so organisieren,
dass sie sich konsolidieren und analysieren lassen, um Ihnen
geschäftsrelevante Informationen zu liefern?
Mit Managed Service for Apache Airflow können Sie Workflows erstellen, planen
und überwachen, um Daten über eine intuitive grafische Oberfläche zwischen
verschiedenen Regionen und Speichersystemen zu verschieben und zu verarbeiten.
Der Dienst bietet ein flexibles Framework mit Operatoren und Integrationen,
die eine zuverlässige Datenübertragung zwischen Diensten wie BigQuery und
Cloud Storage ermöglichen.
In diesem Lab erstellen und führen Sie einen
Apache Airflow-Workflow mit
Managed Service for Apache Airflow
aus, der die folgenden Aufgaben erledigt:
-
eine Liste der zu kopierenden Tabellen aus einer Konfigurationsdatei lesen
-
die Liste der Tabellen aus einem
BigQuery-Dataset in
den USA nach
Cloud Storage
exportieren
-
die exportierten Tabellen aus dem Cloud Storage-Bucket in den USA in den
Cloud Storage-Bucket in der EU kopieren
-
die Liste der Tabellen in das BigQuery-Ziel-Dataset in der EU importieren
Aufgaben
Sie lernen, wie Sie:
- Eine Managed Airflow-Umgebung erstellen
- Cloud Storage-Buckets erstellen
- BigQuery-Datasets erstellen
-
Apache Airflow-Workflows in Managed Airflow erstellen und ausführen, um
Daten zwischen Cloud Storage und BigQuery zu verschieben
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
- Schaltfläche „Google Cloud Console öffnen“
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
-
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren  .
.
-
Klicken Sie sich durch die folgenden Fenster:
- Fahren Sie mit dem Informationsfenster zu Cloud Shell fort.
- Autorisieren Sie Cloud Shell, Ihre Anmeldedaten für Google Cloud API-Aufrufe zu verwenden.
Wenn eine Verbindung besteht, sind Sie bereits authentifiziert und das Projekt ist auf Project_ID, eingestellt. Die Ausgabe enthält eine Zeile, in der die Project_ID für diese Sitzung angegeben ist:
Ihr Cloud-Projekt in dieser Sitzung ist festgelegt als {{{project_0.project_id | "PROJECT_ID"}}}
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
- Klicken Sie auf Autorisieren.
Ausgabe:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Um das aktive Konto festzulegen, führen Sie diesen Befehl aus:
$ gcloud config set account `ACCOUNT`
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Hinweis: Die vollständige Dokumentation für gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Aufgabe 1: Managed Airflow-Umgebung erstellen
-
Geben Sie in der Titelleiste der Google Cloud Console
Managed Airflow in das Suchfeld ein und klicken Sie dann
im Bereich „Produkte und Seiten“ auf Managed Airflow, um
eine Managed Airflow-Umgebung einzurichten.
-
Klicken Sie danach auf Umgebung erstellen.
-
Wählen Sie im Drop-down-Menü
Verwaltetes Airflow Gen 3 aus.
-
Legen Sie für Ihre Umgebung folgende Parameter fest:
-
Name: airflow-advanced-lab
-
Standort:
-
Image-Version: composer-3-airflow-2.n.n-build.n
(wählen Sie die neueste Version des jeweiligen Image aus)
-
Dienstkonto: Standarddienstkonto für Compute Engine
-
Modus für Ausfallsicherheit: Wählen Sie
Standardausfallsicherheit und für die
Airflow-Datenbankzone die Option
aus.
-
Wählen Sie unter Umgebungsressourcen die Option
Klein aus.
-
Wählen Sie für
Webserver-Netzwerkzugriffssteuerung die Option
Zugriff über alle IP-Adressen zulassen aus.
Lassen Sie alle anderen Standardeinstellungen unverändert.
-
Klicken Sie auf Erstellen.
Die Umgebung ist erstellt, wenn auf der Seite „Umgebungen“ in der Cloud
Console links neben dem Umgebungsnamen ein grünes Häkchen angezeigt wird.
Hinweis: Der Vorgang kann bis zu
20 Minuten dauern. Fahren Sie mit dem nächsten Abschnitt
fort:
Cloud Storage-Buckets und BigQuery-Ziel-Dataset erstellen.
Klicken Sie auf Fortschritt prüfen.
Managed Airflow-Umgebung erstellen
Aufgabe 2: Cloud Storage-Buckets erstellen
In dieser Aufgabe erstellen Sie zwei multiregionale Cloud Storage-Buckets.
Diese werden verwendet, um die exportierten Tabellen zwischen verschiedenen
Standorten zu kopieren, z. B. von den USA in die EU.
Bucket in den USA erstellen
-
Rufen Sie Cloud Storage > Buckets auf und klicken Sie auf
Erstellen.
-
Geben Sie dem Bucket einen eindeutigen Namen, in dem die Projekt-ID
enthalten ist (z. B.
-us).
-
Wählen Sie als Standorttyp die Option
USA (mehrere Regionen in den USA) aus.
-
Lassen Sie den anderen Wert unverändert und klicken Sie auf
Erstellen.
-
Klicken Sie auf das Kästchen für
Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen. Wenn Sie dazu aufgefordert werden, klicken Sie im Pop-up
Der öffentliche Zugriff wird verhindert auf
Bestätigen.
Bucket in der EU erstellen
Wiederholen Sie die Schritte, um einen weiteren Bucket in der Region
EU zu erstellen. Fügen Sie dem eindeutigen Name des Buckets den
Standort als Suffix hinzu (z. B.
-eu).
Klicken Sie auf Fortschritt prüfen.
Zwei Cloud Storage-Buckets erstellen
Aufgabe 3: BigQuery-Ziel-Dataset erstellen
-
Erstellen Sie in der neuen Weboberfläche von BigQuery das
BigQuery-Ziel-Dataset in der EU.
-
Rufen Sie im Navigationsmenü die Option
Big Query auf.
Zuerst wird das Fenster
Willkommen bei BigQuery in der Cloud Console geöffnet, das
einen Link zur Kurzanleitung und Informationen zu Aktualisierungen der
Benutzeroberfläche enthält.
-
Klicken Sie auf Fertig.
-
Klicken Sie dann auf das Dreipunkt-Menü neben der Qwiklabs-Projekt-ID und
wählen Sie Dataset erstellen aus.
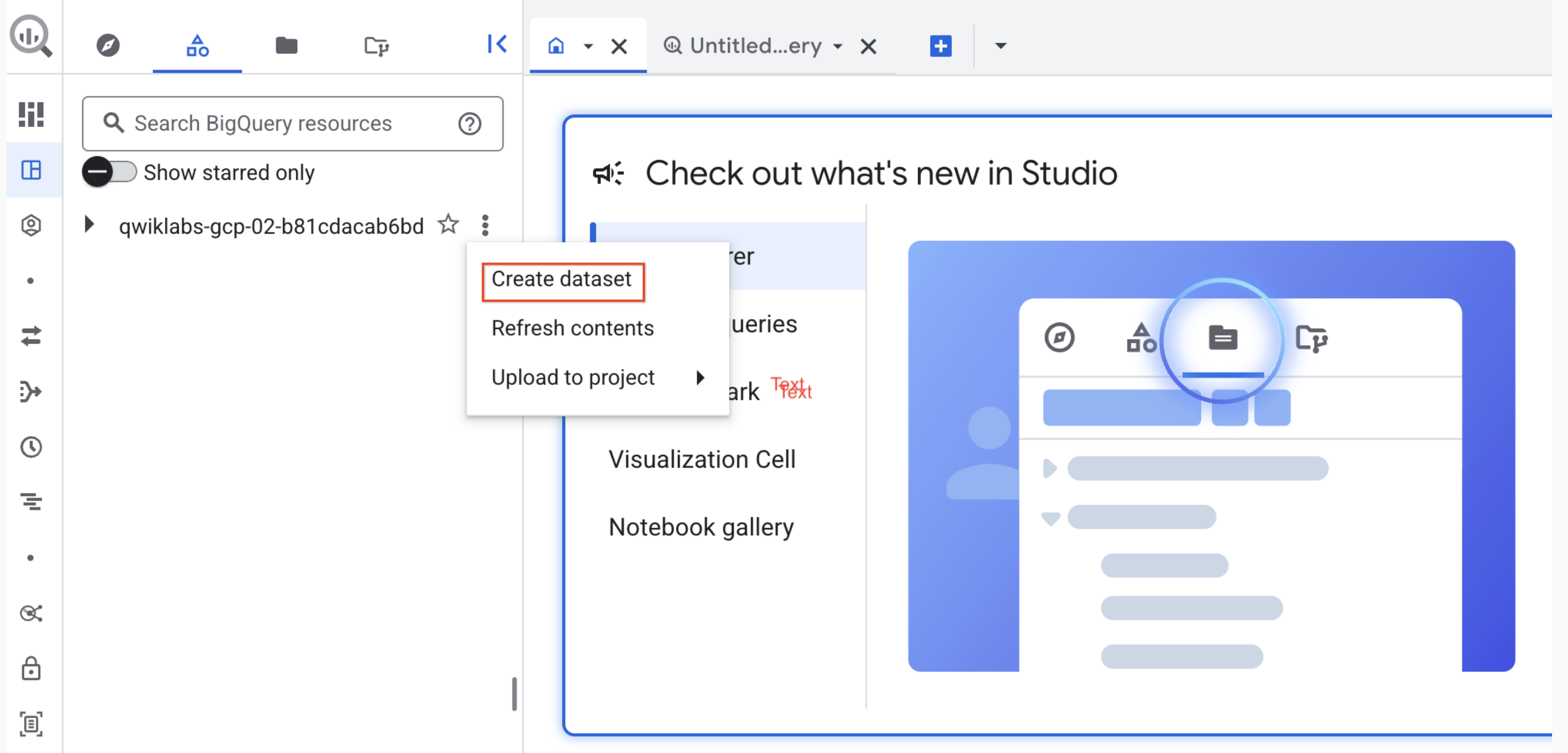
-
Geben Sie als Dataset-ID den String
nyc_tlc_EU ein. Wählen Sie aus dem Drop-down-Menü unter
Mehrere Regionen als Standorttyp die
Option EU aus.
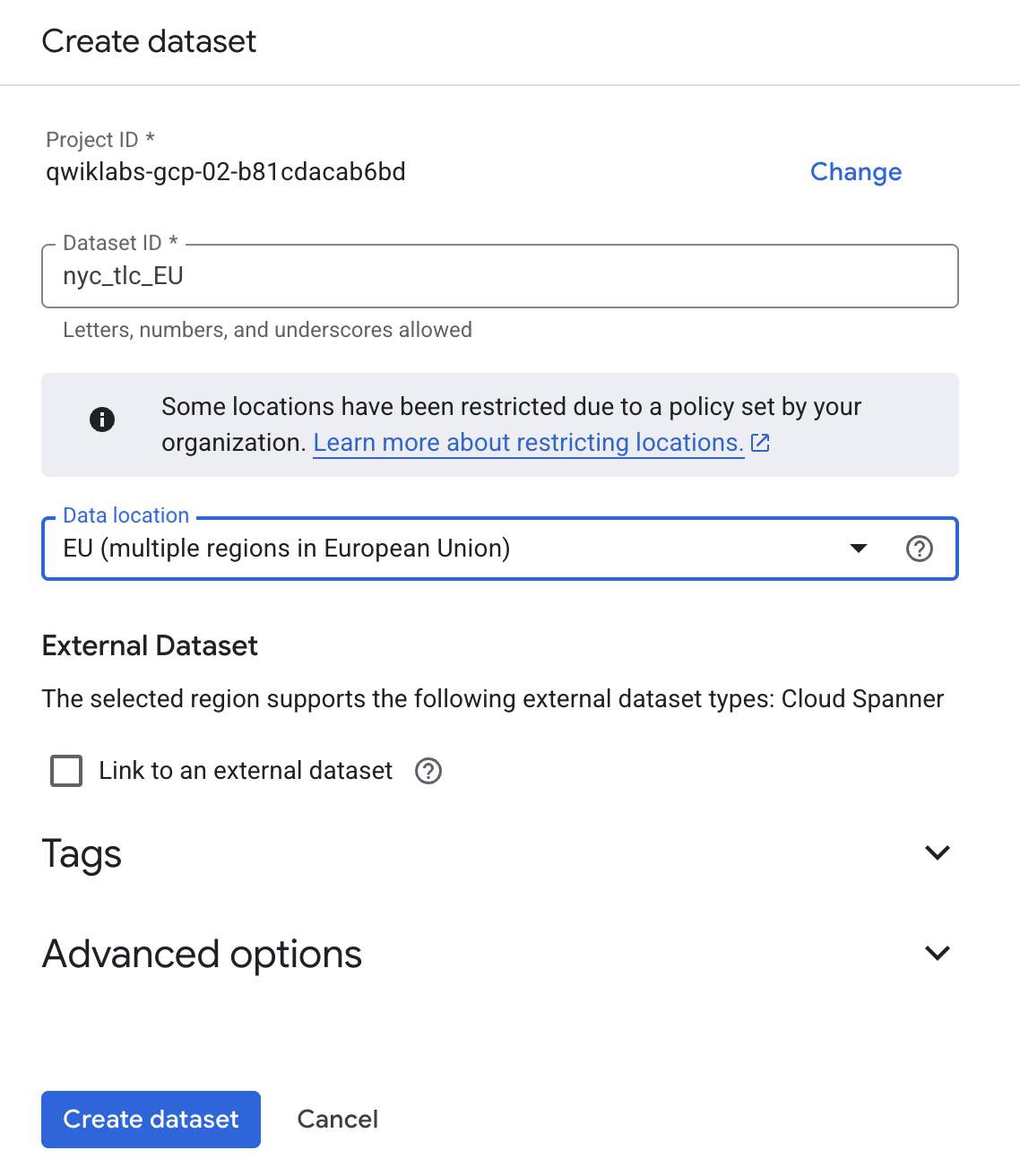
- Klicken Sie auf Dataset erstellen.
Klicken Sie auf Fortschritt prüfen.
BigQuery-Dataset erstellen
Aufgabe 4: Kurze Einführung: Die wichtigsten Konzepte in Airflow
-
Während die Umgebung erstellt wird, können Sie die Zeit nutzen und sich über
die Beispieldatei dieses Labs informieren.
Airflow ist eine Plattform zum
programmgesteuerten Erstellen, Planen und Beobachten von Workflows.
Damit lassen sich Workflows als gerichtete azyklische Graphen (Directed
Acyclic Graphs, DAGs) von Aufgaben erstellen. Der Airflow-Planer führt Ihre
Aufgaben in einem Array von Workern aus, wobei alle geltenden Abhängigkeiten
eingehalten werden.
Wichtige Konzepte
DAG: Ein „Directed Acyclic Graph“ (gerichteter azyklischer Graph) ist eine
Sammlung von Aufgaben, die entsprechend ihren Beziehungen und Abhängigkeiten
angeordnet sind.
Operator: Die Beschreibung einer einzelnen Aufgabe; normalerweise atomar. Mit dem
BashOperator wird beispielsweise ein Bash-Befehl ausgeführt.
Task
(Aufgabe): Parametrisierte Instanz eines Operators; ein Knoten im DAG.
Taskinstanz: Bestimmte Ausführung einer Aufgabe; charakterisiert durch einen DAG, einen
Task und einen Zeitpunkt. Außerdem ist ein indikativer Status zugeordnet:
running (wird ausgeführt), success (Erfolg),
failed (fehlgeschlagen), skipped (übersprungen) usw.
Weitere Informationen über Airflow-Konzepte finden Sie in der
entsprechenden Dokumentation.
Aufgabe 5: Workflow definieren
Workflows in Apache Airflow bestehen aus
gerichteten azyklischen Graphen (Directed Acyclic Graphs, DAGs). Der Code in
bq_copy_across_locations.py
stellt den Workflow dar, der auch als DAG bezeichnet wird. Öffnen Sie die
Datei, um zu sehen, wie der DAG aufgebaut ist. Im nächsten Abschnitt werden
die wichtigsten Komponenten genauer betrachtet.
Zur Orchestrierung der Workflowaufgaben werden die folgenden Operatoren für
den DAG importiert:
-
DummyOperator: Erstellt „Start“- und „End“-Beispielaufgaben für
eine bessere visuelle Darstellung des DAG.
-
BigQueryToCloudStorageOperator: Exportiert BigQuery-Tabellen im
Avro-Format in Cloud Storage-Buckets.
-
GoogleCloudStorageToGoogleCloudStorageOperator: Kopiert Dateien
zwischen Cloud Storage-Buckets.
-
GoogleCloudStorageToBigQueryOperator: Importiert Tabellen aus
Avro-Dateien in einen Cloud Storage-Bucket.
-
In diesem Beispiel ist die Funktion
read_table_list() so
definiert, dass sie die Konfigurationsdatei liest und die Liste der zu
kopierenden Tabellen erstellt:
#
--------------------------------------------------------------------------------
# Functions #
--------------------------------------------------------------------------------
def read_table_list(table_list_file): """ Reads the master CSV file that will
help in creating Airflow tasks in the DAG dynamically. :param table_list_file:
(String) The file location of the master file, e.g.
'/home/airflow/framework/master.csv' :return master_record_all: (List) List of
Python dictionaries containing the information for a single row in master CSV
file. """ master_record_all = [] logger.info('Reading table_list_file from :
%s' % str(table_list_file)) try: with open(table_list_file, 'rb') as csv_file:
csv_reader = csv.reader(csv_file) next(csv_reader) # skip the headers for row
in csv_reader: logger.info(row) master_record = { 'table_source': row[0],
'table_dest': row[1] } master_record_all.append(master_record) return
master_record_all except IOError as e: logger.error('Error opening
table_list_file %s: ' % str( table_list_file), e)
-
Der Name des DAG ist
bq_copy_us_to_eu_01. Die Ausführung ist
nicht geplant, sondern muss manuell ausgelöst werden.
default_args = { 'owner': 'airflow', 'start_date': datetime.today(),
'depends_on_past': False, 'email': [''], 'email_on_failure': False,
'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5), }
# DAG object. with models.DAG('bq_copy_us_to_eu_01',
default_args=default_args, schedule_interval=None) as dag:
-
Zum Definieren des Cloud Storage-Plug-ins ist die Klasse
Cloud StoragePlugin(AirflowPlugin) definiert. Damit werden Hook
und Operator, die vom stabilen Airflow 1.10-Zweig heruntergeladen wurden,
zugeordnet.
# Import operator from plugins from gcs_plugin.operators import gcs_to_gcs
Aufgabe 6: Umgebungsinformationen prüfen
-
Gehen Sie zurück zu Managed Airflow, um den Status der
Umgebung zu prüfen.
-
Sobald die Umgebung erstellt wurde, klicken Sie auf den Namen, um Details
aufzurufen.
Die Seite Umgebungsdetails enthält verschiedene
Informationen, wie die URL der Airflow-Benutzeroberfläche, die Cluster-ID der
Google Kubernetes Engine und den Namen des mit dem DAG-Ordner verbundenen
Cloud Storage-Bucket.
Hinweis : Verwaltete Apache Airflow-Dienste verwenden
Cloud Storage
zum Speichern von DAGs, die auch als Workflows bezeichnet werden.
Jede Umgebung ist mit einem Cloud Storage-Bucket verknüpft. Nur die DAGs, die
sich in diesem Bucket befinden, werden von Airflow geplant.
Die nächsten Schritte werden in Cloud Shell ausgeführt.
Virtuelle Umgebung erstellen
Virtuelle Python-Umgebungen werden verwendet, um die Paketinstallation vom System zu isolieren.
-
virtualenv-Umgebung installieren:
sudo apt-get install -y virtualenv
- Virtuelle Umgebung erstellen:
python3 -m venv venv
- Aktivieren Sie die virtuelle Umgebung:
source venv/bin/activate
Aufgabe 7: Variable für die DAGs im Cloud Storage-Bucket erstellen
-
Führen Sie in Cloud Shell den folgenden Befehl aus, um auf der Seite
„Umgebungsdetails“ den Namen des Buckets mit den DAGs zu kopieren und eine
Variable festzulegen, mit der in Cloud Shell darauf verwiesen wird:
Hinweis: Ersetzen Sie im folgenden Befehl den Namen des
Buckets durch Ihren Bucket mit den DAGs. Rufen Sie im
Navigationsmenü die Option Cloud Storage >
Buckets auf. Sie sollte in etwa so aussehen:
-airflow-advance-YOURDAGSBUCKET-bucket.
DAGS_BUCKET=<your DAGs bucket name>
Diese Variable nutzen Sie in diesem Lab mehrmals.
Aufgabe 8: Airflow-Variablen festlegen
Airflow-Variablen sind ein Airflow-spezifisches Konzept und unterscheiden sich
von
Umgebungsvariablen. In diesem Schritt legen Sie die folgenden drei
Airflow-Variablen
fest, die vom bereitzustellenden DAG verwendet werden:
table_list_file_path, gcs_source_bucket und
gcs_dest_bucket.
| Schlüssel |
Wert |
Details |
table_list_file_path |
/home/airflow/gcs/dags/bq_copy_eu_to_us_sample.csv |
CSV-Datei mit Quell- und Zieltabellen, einschließlich Dataset
|
gcs_source_bucket |
{UNIQUE ID}-us |
Cloud Storage-Bucket zum Exportieren von BigQuery-Tabellen aus der
Quelle
|
gcs_dest_bucket |
{UNIQUE ID}-eu |
Cloud Storage-Bucket zum Importieren von BigQuery-Tabellen am Ziel
|
Mit dem folgenden gcloud composer-Befehl werden die
Unterbefehlvariablen
der Airflow-Befehlszeile ausgeführt. Dabei werden die Argumente an das
gcloud-Befehlszeilentool übergeben.
Zum Festlegen der drei Variablen wird der composer-Befehl jeweils
einmal für jede Zeile der Tabelle oben ausgeführt. So sieht der Befehl aus:
gcloud composer environments run ENVIRONMENT_NAME \ --location LOCATION
variables -- \ set KEY VALUE
Sie können diesen gcloud-Fehler ignorieren:
(ERROR: gcloud crashed (TypeError): 'NoneType' object is not
callable). Das ist ein
bekanntes Problem
bei der Verwendung des Befehls
gcloud composer environments run mit der Version 410.0.0 von
gcloud. Ihre Variablen werden trotz der Fehlermeldung entsprechend festgelegt.
-
ENVIRONMENT_NAME ist der Name der Umgebung.
-
LOCATION ist die Compute Engine-Region, in der sich die
Umgebung befindet. Im „gcloud composer“-Befehl muss das Flag
--location enthalten sein oder
Sie legen den Standardort vor der Ausführung des Befehls fest.
-
Mit
KEY und VALUE werden die Variable und ihr
festzulegender Wert angegeben. Fügen Sie ein Leerzeichen, zwei Bindestriche
und ein Leerzeichen ( -- ) zwischen dem linken
gcloud-Befehl mit zugehörigen Argumenten und den rechten
Argumenten für den Airflow-Unterbefehl ein. Auch zwischen den
KEY- und VALUE-Argumenten muss sich ein
Leerzeichen befinden. Der Befehl
gcloud composer environments run wird mit den
Unterbefehlvariablen ausgeführt.
Führen Sie diese Befehle in Cloud Shell aus. Ersetzen Sie dabei
gcs_source_bucket und gcs_dest_bucket durch die
Namen der Buckets, die Sie unter Aufgabe 2 erstellt haben.
gcloud composer environments run airflow-advanced-lab \ --location {{{
project_0.default_region | "REGION" }}} variables -- \ set
table_list_file_path /home/airflow/gcs/dags/bq_copy_eu_to_us_sample.csv gcloud
composer environments run airflow-advanced-lab \ --location {{{
project_0.default_region | "REGION" }}} variables -- \ set gcs_source_bucket
{UNIQUE ID}-us gcloud composer environments run airflow-advanced-lab \
--location {{{ project_0.default_region | "REGION" }}} variables -- \ set
gcs_dest_bucket {UNIQUE_ID}-eu
Um den Wert einer Variablen abzurufen, führen Sie den Unterbefehl
variables
in der Airflow-Befehlszeile mit dem Argument get aus oder
verwenden Sie die
Airflow-Benutzeroberfläche.
Führen Sie z. B. Folgendes aus:
gcloud composer environments run airflow-advanced-lab \ --location {{{
project_0.default_region | "REGION" }}} variables -- \ get gcs_source_bucket
Hinweis: Legen Sie unbedingt alle drei Airflow-Variablen
fest, die vom DAG verwendet werden.
Aufgabe 9: DAG und Abhängigkeiten in Cloud Storage hochladen
-
Kopieren Sie die Beispieldateien der Python-Dokumentation von Google Cloud
in Cloud Shell:
cd ~ gcloud storage cp -r gs://spls/gsp283/python-docs-samples .
-
Laden Sie eine Kopie der Drittanbieter-Hooks und -Operatoren in den Ordner
„plugins“ des Cloud Storage-Bucket für Airflow-DAGs in Managed Service for
Airflow hoch:
gcloud storage cp -r python-docs-samples/third_party/apache-airflow/plugins/*
gs://$DAGS_BUCKET/plugins
-
Laden Sie anschließend den DAG und die Konfigurationsdatei in den Cloud
Storage-Bucket für DAGs Ihrer Umgebung hoch:
gcloud storage cp
python-docs-samples/composer/workflows/bq_copy_across_locations.py
gs://$DAGS_BUCKET/dags gcloud storage cp
python-docs-samples/composer/workflows/bq_copy_eu_to_us_sample.csv
gs://$DAGS_BUCKET/dags
Verwaltete Apache Airflow-Dienste erkennen und registrieren DAGs automatisch
in der Airflow-Umgebung. Aktualisierungen werden in der Regel innerhalb
weniger Minuten übernommen. Sie können den Aufgabenstatus über die
Airflow-Weboberfläche überwachen und prüfen, ob das DAG-Scheduling-Verhalten
der definierten Konfiguration entspricht.
Aufgabe 10: Airflow-Benutzeroberfläche untersuchen
So greifen Sie mit der Cloud Console auf die Airflow-Weboberfläche zu:
-
Kehren Sie in Managed Airflow zur Seite Umgebungen zurück.
-
Klicken Sie in der Spalte Airflow-Webserver für die
Umgebung auf den Link Airflow.

- Klicken Sie auf Ihre Lab-Anmeldedaten.
-
Die Airflow-Weboberfläche wird in einem neuen Browserfenster geöffnet. Das
Laden der Daten dauert einen Moment, aber Sie können inzwischen mit dem Lab
fortfahren.
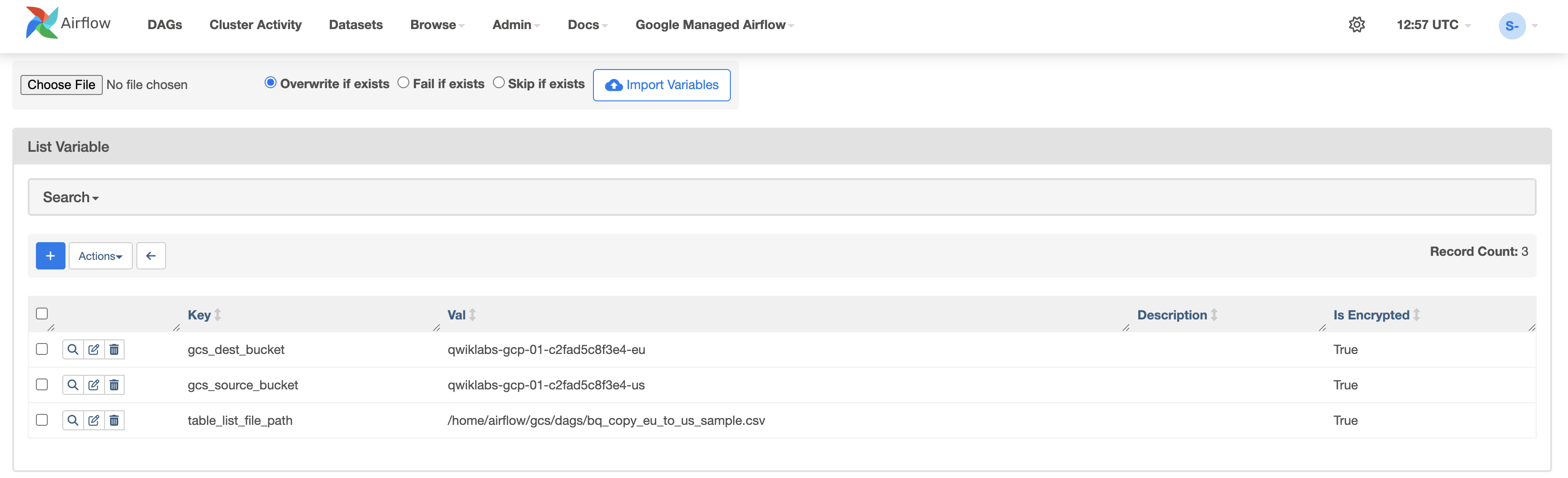
Variablen prüfen
Die zuvor erstellten Variablen sind dauerhaft in Ihrer Umgebung vorhanden.
-
Wenn Sie die Variablen prüfen möchten, wählen Sie in der Airflow-Menüleiste
Admin > Variablen aus.
DAG-Ausführung manuell auslösen
-
Klicken Sie auf den Tab DAGs und warten Sie, bis die
Links geladen wurden.
-
Um den DAG manuell auszulösen, klicken Sie auf die Wiedergabeschaltfläche
für composer_sample_bq_copy_across_locations:
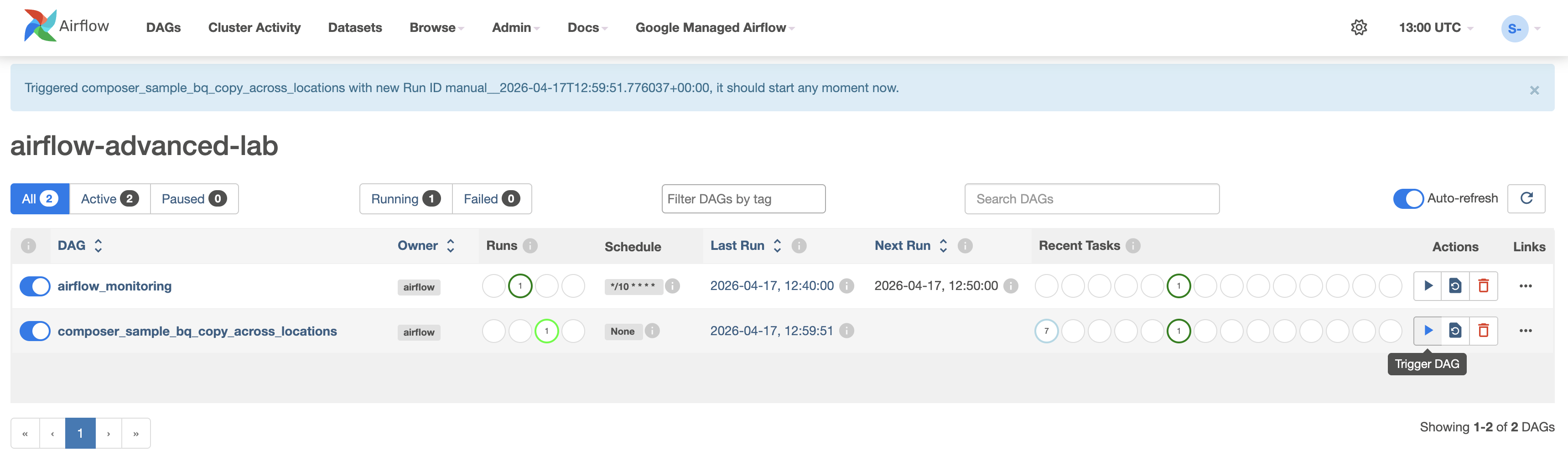
- Klicken Sie zur Bestätigung auf DAG auslösen.
Klicken Sie auf Fortschritt prüfen.
DAG und Abhängigkeiten in Cloud Storage hochladen
Weitere Informationen zu DAG-Ausführungen
Wenn Sie Ihre DAG-Datei in den DAGs-Ordner (konfigurierter Speicherort)
hochladen, parst Apache Airflow die Datei. Werden keine Fehler gefunden, wird
der Workflow in der DAG-Liste angezeigt und in die Warteschlange gestellt,
damit er gemäß seiner Zeitplankonfiguration ausgeführt wird. Wenn der Zeitplan
auf „Keiner“ gesetzt ist, wird der Workflow nicht automatisch ausgeführt und
muss manuell ausgelöst werden.
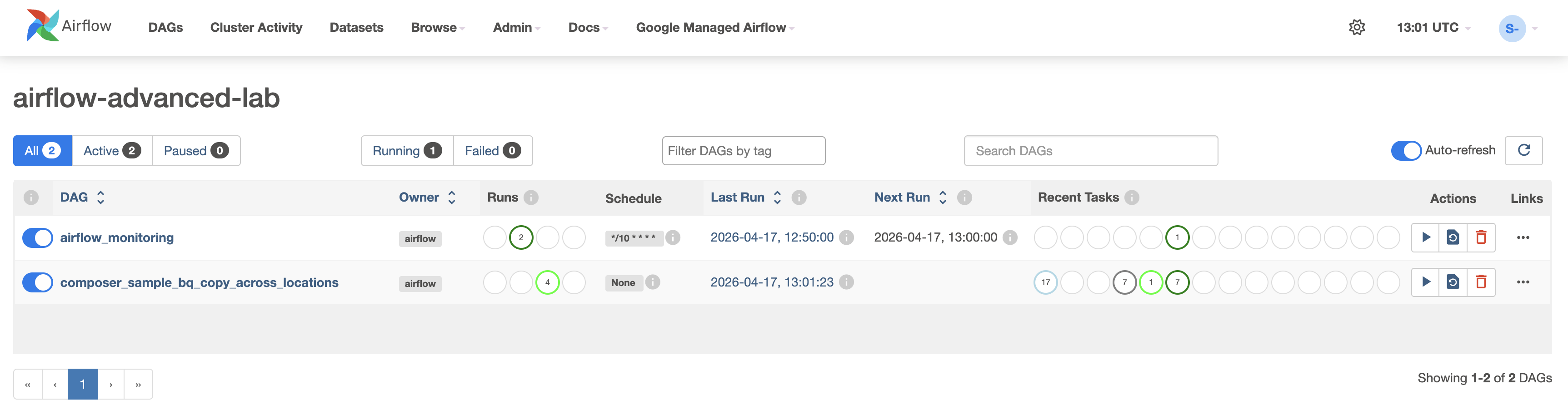
Der Status Ausführungen wird grün, nachdem Sie auf die
Wiedergabeschaltfläche geklickt haben:
-
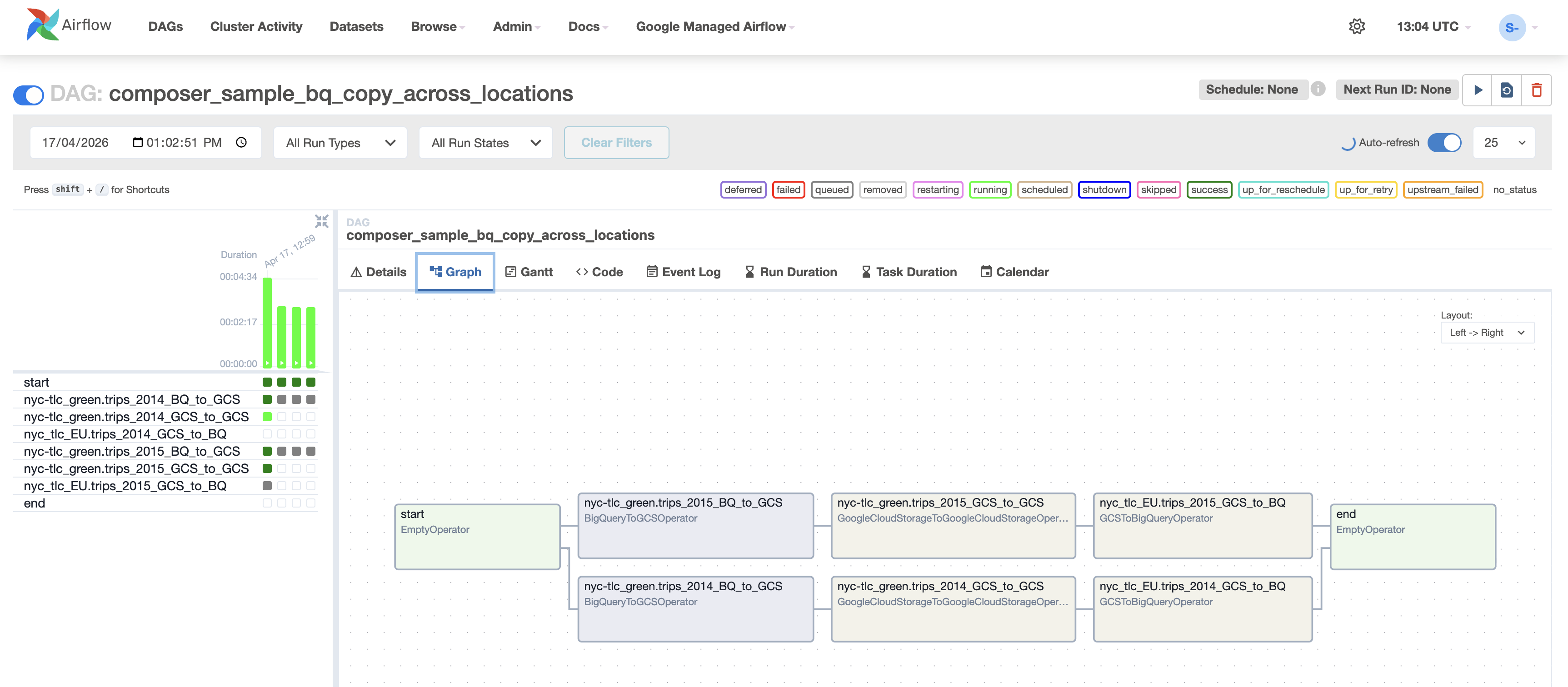
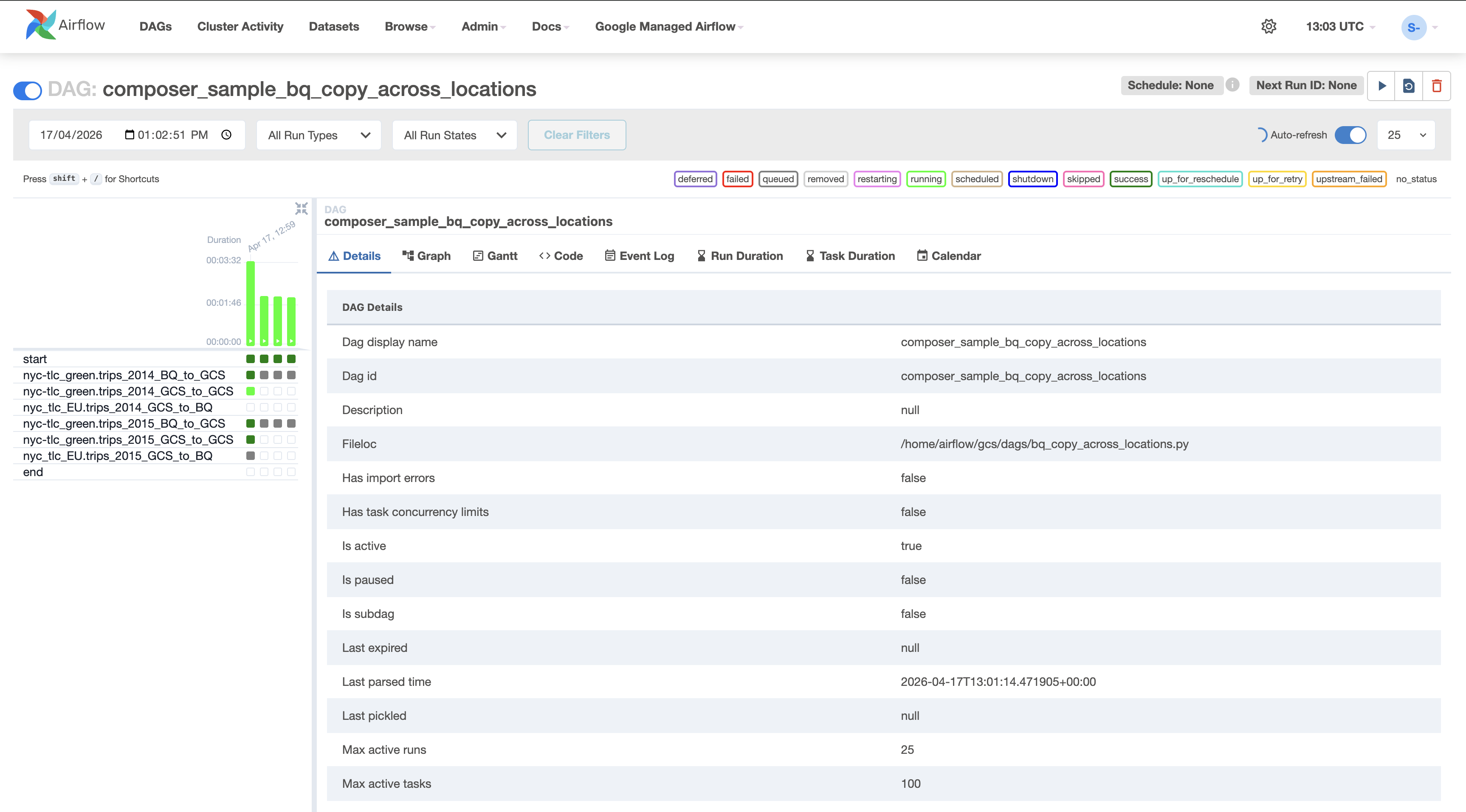
Klicken Sie auf den Namen des DAG, um die zugehörige Detailseite aufzurufen.
Sie enthält eine grafische Darstellung der Workflowaufgaben und
‑abhängigkeiten.
-
Klicken Sie in der Symbolleiste auf Grafik und bewegen Sie
den Mauszeiger über das Diagramm jeder Aufgabe, um ihren Status zu sehen.
Der Rahmen um jede Aufgabe gibt auch deren Status an (grün = läuft; rot =
fehlgeschlagen usw.).
So führen Sie den Workflow über die Diagrammansicht noch
einmal aus:
-
Klicken Sie in der Airflow-Benutzeroberfläche unter „Diagrammansicht“ auf
die Grafik Start.
-
Klicken Sie auf Löschen > Bestehende Aufgabe löschen, um
alle Aufgaben zurückzusetzen, und dann auf
DAG-Ausführung löschen, um den Vorgang zu bestätigen.
Aktualisieren Sie währenddessen Ihren Browser, um die aktuellen Daten zu
sehen.
Aufgabe 11: Ergebnisse prüfen
Prüfen Sie den Status und die Ergebnisse des Workflows auf den folgenden
Seiten der Cloud Console:
-
Die exportierten Tabellen wurden vom US‑ in den EU-Bucket in Cloud Storage
kopiert. Klicken Sie auf Cloud Storage, um die
Avro-Zwischendateien im Quell-Bucket (USA) und Ziel-Bucket (EU) zu sehen.
-
Die Liste der Tabellen wurde in das BigQuery-Ziel-Dataset importiert.
Klicken Sie auf BigQuery, dann auf den Namen Ihres Projekts
und das Dataset nyc_tlc_EU, um zu prüfen, ob sich die
Tabellen im erstellten Dataset aufrufen lassen.
Cloud Composer-Umgebung löschen
-
Kehren Sie in Cloud Composer zur Seite Umgebungen zurück.
-
Wählen Sie Ihre Cloud Composer-Umgebung aus.
-
Klicken Sie auf Löschen.
-
Klicken Sie im angezeigten Dialogfeld auf Löschen, um zu bestätigen, dass Sie die Cloud Composer-Umgebung löschen möchten.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben Tabellen programmatisch von den USA in die EU kopiert. Das Lab
basiert auf diesem
Blogpost
von David Sabater Dinter.
Weitere Informationen
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 20. April 2026 aktualisiert
Lab zuletzt am 20. April 2026 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





