Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
Neste laboratório, você vai usar a tabela de pinguins para criar um modelo para prever o peso de um pinguim com base na espécie do pinguim, ilha onde residem, comprimento e profundidade do cúlmen, comprimento da nadadeira e sexo.
Este tutorial ensina analistas de dados a usar o BigQuery ML. Com o BigQuery ML, é possível criar e executar modelos de machine learning no BigQuery usando consultas do SQL. O objetivo é democratizar o machine learning, de modo que os especialistas em SQL criem modelos usando as respectivas ferramentas e aumentem a velocidade de desenvolvimento ao eliminar a necessidade de movimentar os dados.
Objetivos de aprendizado
Criar um modelo de regressão linear usando a instrução CREATE MODEL com o ML do BigQuery.
Avaliar o modelo de ML com a função ML.EVALUATE.
Fazer previsões usando o modelo de ML com a função ML.PREDICT.
Configuração
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative a API BigQuery
No console do Cloud, acesse Menu de navegação () e clique em APIs e serviços > Biblioteca.
Procure a API BigQuery e clique em Ativar, caso ainda não esteja habilitada.
Tarefa 1: crie seu conjunto de dados
A primeira etapa é criar um conjunto de dados do BigQuery para armazenar seu modelo de ML. Para criar o conjunto de dados, faça o seguinte:
No Console do Cloud, acesse o Menu de navegação e clique em BigQuery.
No painel Explorer, clique no ícone de Ver ações (três pontos verticais) ao lado do ID do projeto, e depois clique em Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
No campo ID do conjunto de dados, digite bqml_tutorial
(Opcional) Em Local dos dados, clique em us (várias regiões nos Estados Unidos).
No momento, os conjuntos de dados públicos são armazenados no local multirregional "EUA". Para simplificar, coloque seu conjunto de dados no mesmo local.
Não altere as demais configurações e clique em Criar conjunto de dados.
Tarefa 2: crie um modelo.
Em seguida, crie um modelo de regressão linear usando a tabela de pinguins do BigQuery.
Com a consulta SQL padrão abaixo, você cria o modelo usado para prever o peso de um pinguim:
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Além disso, a execução do comando CREATE MODEL cria e treina esse modelo.
Detalhes da consulta
A cláusula CREATE MODEL é usada para criar e treinar o modelo nomeado bqml_tutorial.penguins_model.
A cláusula OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) indica que você está criando um modelo de regressão linear. A Regressão linear é um tipo de modelo de regressão que gera um valor contínuo a partir de uma combinação linear de recursos de entrada. A coluna body_mass_g é a coluna do rótulo de entrada. Para modelos de regressão linear, é preciso que a coluna de rótulo tenha valor real, isto é, os valores da coluna precisam ser números reais.
A instrução SELECT dessa consulta usa todas as colunas na tabela bigquery-public-data.ml_datasets.penguins. Esta tabela contém as seguintes colunas que vão ser todas usadas para prever o peso de um pinguim:
species: espécie do pinguim (STRING)
island: ilha onde o pinguim vive (STRING)
culmen_length_mm: comprimento do bico em milímetros (FLOAT64)
culmen_depth_mm: profundidade do bico em milímetros (FLOAT64)
flipper_length_mm: comprimento da nadadeira em milímetros (FLOAT64)
sex: o sexo do pinguim (STRING)
A cláusula FROM — bigquery-public-data.ml_datasets.penguins — indica que você está consultando a tabela de pinguins no conjunto de dados ml_datasets. Este conjunto de dados está no projeto bigquery-public-data.
A cláusula WHERE — WHERE body_mass_g IS NOT NULL — exclui linhas em que body_mass_g é NULO.
Execute a consulta CREATE MODEL
Para executar a consulta CREATE MODEL para criar e treinar seu modelo, faça o seguinte:
No Console do Cloud, clique em Escrever nova consulta.
Na área de texto do Editor de consultas, insira a consulta SQL padrão a seguir:
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Clique em Executar.
A conclusão da consulta leva cerca de 30 segundos. Depois disso, seu modelo (penguins_model) vai aparecer no painel de navegação. Como a consulta usa uma instrução CREATE MODEL para criar uma tabela, os resultados dela não aparecem.
Observação: é possível ignorar o aviso sobre valores NULOS para dados de entrada.
Tarefa 3: acesse as estatísticas de treinamento (opcional)
Para ver os resultados do treinamento de modelo, você pode usar a função ML.TRAINING_INFO ou consultar as estatísticas no Console do Cloud. Neste tutorial, você vai usar o Console do Cloud.
Para criar um modelo, o algoritmo de machine learning examina vários exemplos e tenta encontrar um modelo que minimize a perda. Esse processo é chamado de minimização do risco empírico.
Perda é a penalidade para uma previsão ruim, ou seja, um número que indica quão ruim foi a previsão do modelo em um único exemplo. Para uma previsão de modelo perfeita, a perda é zero. Caso contrário, a perda é maior que zero. O treinamento de um modelo visa encontrar um conjunto de ponderações e tendências com uma média de perda menor em todos os exemplos.
Para ver as estatísticas de treinamento de modelo geradas quando você executou a consulta CREATE MODEL, faça o seguinte:
No painel de navegação do Console do Cloud, na seção Explorer, expanda [PROJECT_ID] > bqml_tutorial > Models (1), e depois clique em penguins_model.
Clique na guia Treinamento e depois em Tabela. Os resultados terão a seguinte aparência:
A coluna Perda de dados de treinamento representa a métrica de perda que foi calculada depois de o modelo ser treinado no conjunto de dados de treinamento. Como você executou uma regressão linear, essa coluna é o erro quadrático médio.
Uma estratégia de otimização "normal_equation" é usada automaticamente neste treinamento. Portanto, apenas uma iteração precisa convergir para o modelo final. Para saber mais sobre a opção de optimize_strategy, confira a instrução CREATE MODEL para modelos lineares generalizados.
Após criar seu modelo, avalie o desempenho dele usando a função ML.EVALUATE. A função ML.EVALUATE avalia os valores previstos em relação aos dados reais.
A seguinte consulta é usada para avaliar o modelo:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
Detalhes da consulta
A primeira instrução SELECT recupera as colunas do seu modelo.
A cláusula FROM usa a função ML.EVALUATE no modelo: bqml_tutorial.penguins_model.
A instrução aninhada SELECT e a cláusula FROM desta consulta são as mesmas que as da consulta CREATE MODEL.
A cláusula WHERE — WHERE body_mass_g IS NOT NULL — exclui linhas em que body_mass_g é NULO.
Uma avaliação adequada seria feita em um subconjunto da tabela de pinguins, separada dos dados usados para treinar o modelo. Também é possível chamar ML.EVALUATE sem fornecer os dados de entrada. ML.EVALUATE vai recuperar as métricas de avaliação calculadas durante o treinamento, que usa o conjunto de dados de avaliação reservado automaticamente:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`)
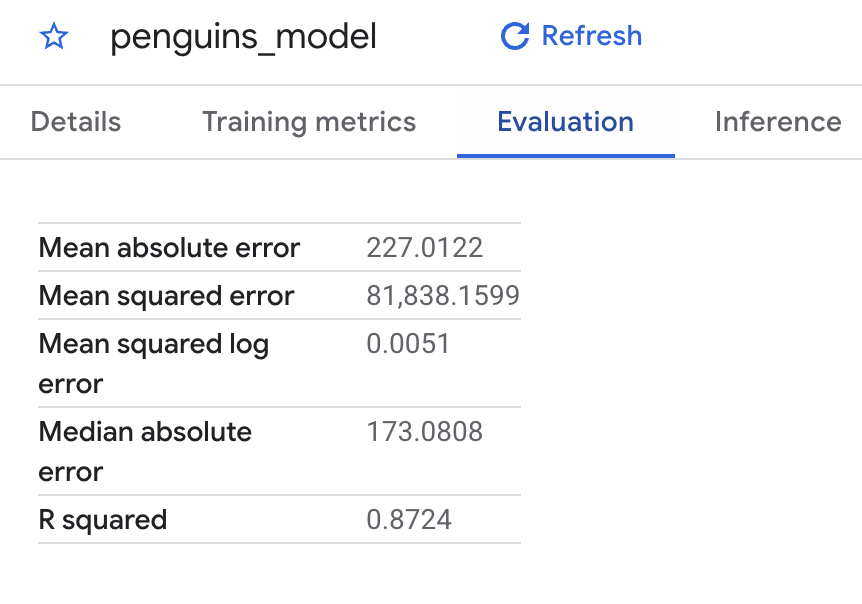
Também é possível usar o Console do Cloud para visualizar as métricas de avaliação calculadas durante o treinamento. Os resultados terão a seguinte aparência:
Execute a consulta ML.EVALUATE
Para executar a consulta ML.EVALUATE, que avalia o modelo, faça o seguinte:
No Console do Cloud, clique em Escrever nova consulta.
Na área de texto do Editor de consultas, insira a consulta SQL padrão a seguir:
#standardSQL
SELECT
*
FROM
ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL))
(Opcional) Para definir o local dos dados, clique em Mais > Configurações de consulta. Em Local dos dados, clique em us (várias regiões nos Estados Unidos).
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a seguinte aparência:
Como você executou uma regressão linear, os resultados incluem as seguintes colunas:
mean_absolute_error
mean_squared_error
mean_squared_log_error
median_absolute_error
r2_score
explained_variance
Uma métrica importante nos resultados da avaliação é a pontuação R2. A pontuação R2 é uma medida estatística que determina se as previsões de regressão linear se aproximam dos dados reais. O valor 0 indica que o modelo não explica a variabilidade dos dados de resposta em torno da média. O valor 1 indica que o modelo explica toda a variabilidade dos dados de resposta em torno da média.
Tarefa 5: use seu modelo para prever resultados
Agora que seu modelo foi avaliado, a próxima etapa é usá-lo para prever um resultado. Use seu modelo para prever a massa corporal em gramas de todos os pinguins que residem em Biscoe.
A consulta a seguir é usada para prever o resultado:
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
Detalhes da consulta
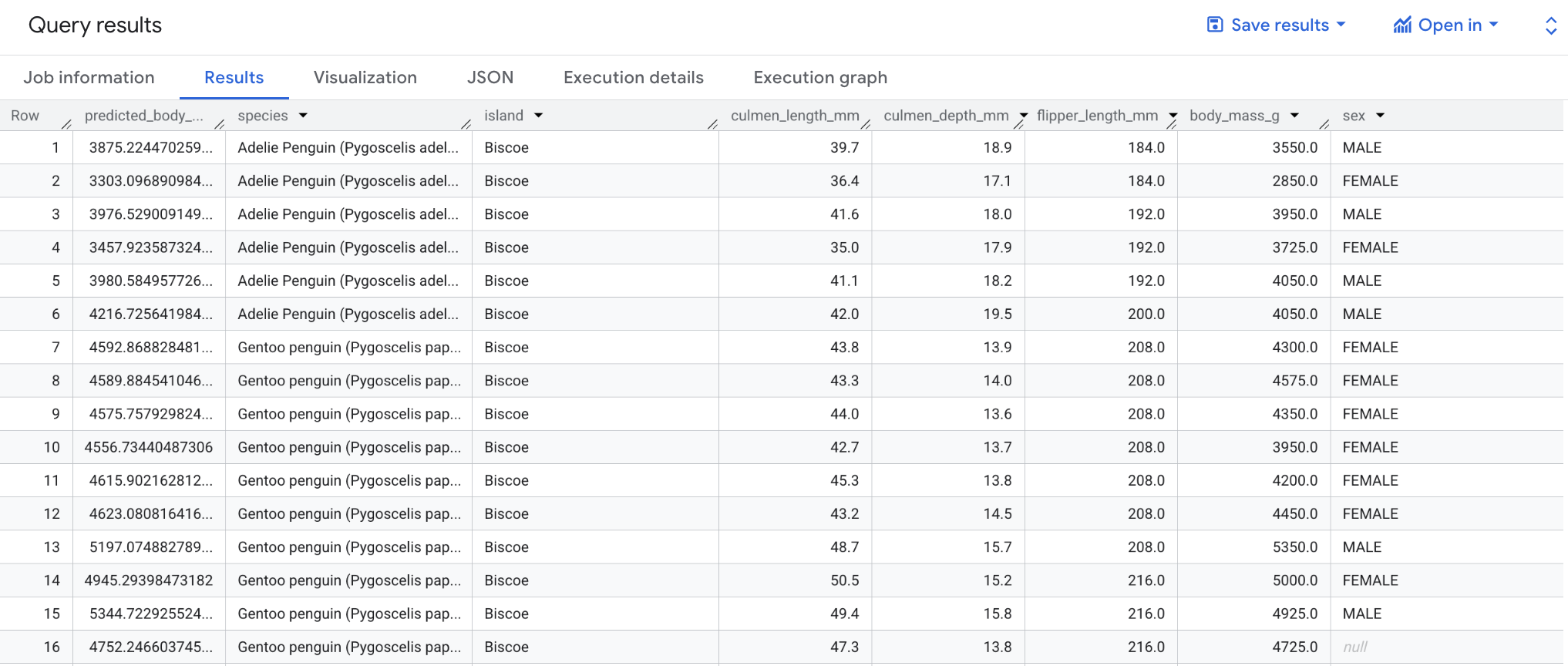
A primeira instrução SELECT recupera a coluna predicted_body_mass_g juntamente das colunas em bigquery-public-data.ml_datasets.penguins. Esta coluna é gerada pela função ML.PREDICT. Quando você usa a função ML.PREDICT, o nome da coluna de saída para o modelo é predicted_<label_column_name>. Para modelos de regressão linear, predicted_label é o valor estimado de label. Em modelos de regressão logística, predicted_label é um dos dois rótulos de entrada, dependendo de qual tiver a maior probabilidade de predição.
A função ML.PREDICT é usada para prever resultados usando o modelo: bqml_tutorial.penguins_model.
A instrução aninhada SELECT e a cláusula FROM desta consulta são as mesmas que as da consulta CREATE MODEL.
A cláusula WHERE — WHERE island = "Biscoe" — indica que você está limitando a previsão à ilha de Biscoe.
Execute a consulta ML.PREDICT
Veja como executar a consulta que usa o modelo para prever um resultado:
No Console do Cloud, clique em Escrever nova consulta.
Na área de texto do Editor de consultas, insira a consulta SQL padrão a seguir:
#standardSQL
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))
(Opcional) Para definir o local dos dados, clique em Mais > Configurações de consulta. Em Local dos dados, clique em us (várias regiões nos Estados Unidos).
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a seguinte aparência:
Tarefa 6: explique os resultados de previsão com os métodos da Explainable AI
Para entender por que seu modelo está gerando esses resultados de previsão, use a função ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT é uma versão estendida de ML.PREDICT. ML.EXPLAIN_PREDICT retorna resultados da previsão com colunas adicionais que explicam esses resultados.
É possível executar ML.EXPLAIN_PREDICT sem usar ML.PREDICT. Para uma explicação detalhada dos valores de Shapley e da IA explicável no BigQuery ML, confira Visão geral da IA explicável do BigQuery ML.
A consulta a seguir é usada para gerar explicações:
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Detalhes da consulta
Executar a consulta ML.EXPLAIN_PREDICT
Para executar a consulta ML.EXPLAIN_PREDICT que explica o modelo:
No Console do Cloud, clique em Escrever nova consulta.
Na área de texto do Editor de consultas, insira a consulta SQL padrão a seguir:
#standardSQL
SELECT
*
FROM
ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"),
STRUCT(3 as top_k_features))
Clique em Executar.
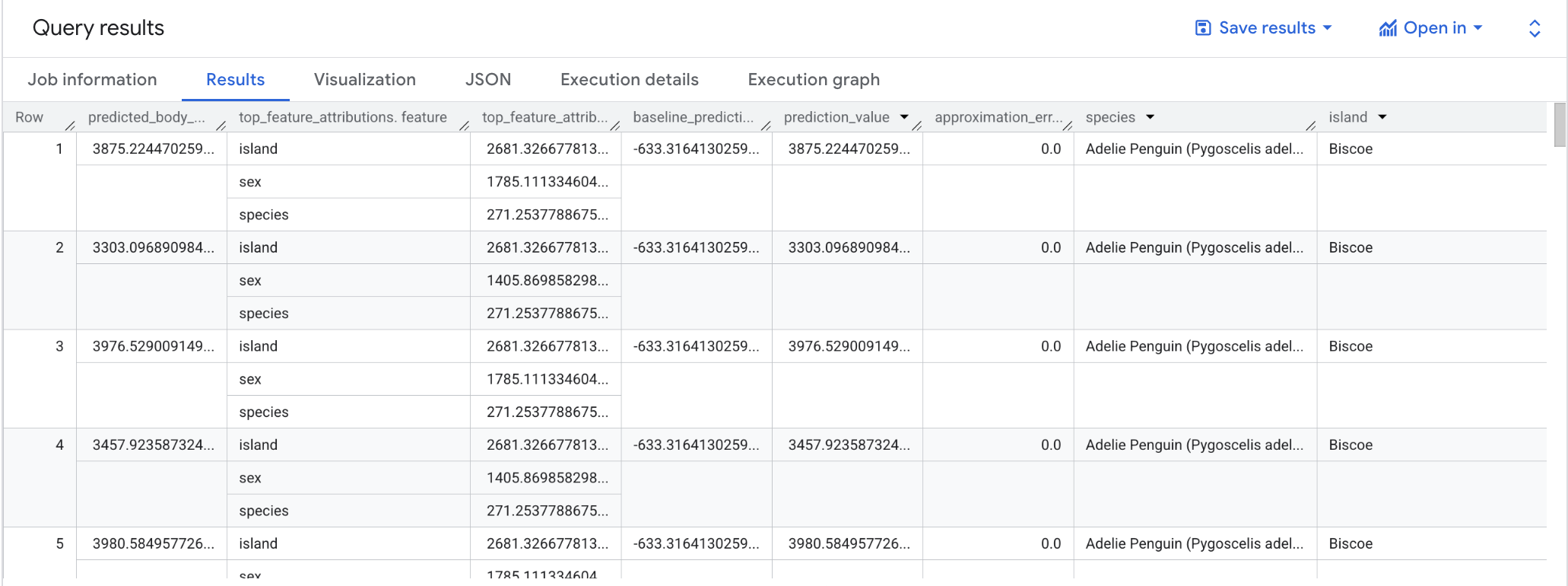
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a seguinte aparência:
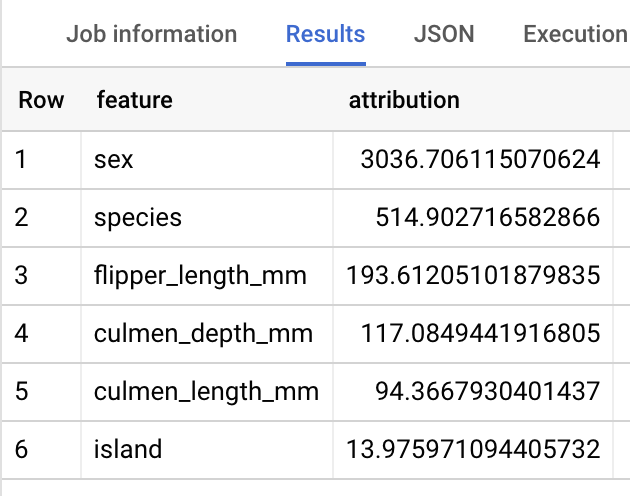
Observação: a consulta ML.EXPLAIN_PREDICT gera como saída todas as colunas de atributos de entrada, semelhante ao ML.PREDICT. Apenas uma coluna de atributos, "espécie", é mostrada na figura acima para fins de legibilidade.
Nos modelos de regressão linear, os valores de Shapley são usados para gerar valores de atribuição de elementos por recurso no modelo. ML.EXPLAIN_PREDICT gera como saída as três principais atribuições de elementos por linha da tabela fornecida porque top_k_features foi definido como 3 na consulta.
Essas atribuições são classificadas pelo valor absoluto de cada uma, em ordem decrescente. Em todos os exemplos, o recurso sex foi o que mais contribuiu com a previsão geral. Confira explicações detalhadas sobre as colunas de saída da consulta ML.EXPLAIN_PREDICT na documentação de sintaxe de ML.EXPLAIN_PREDICT
Tarefa 7: explique seu modelo globalmente (opcional)
Para saber quais recursos são os mais importantes para determinar o peso dos pinguins em geral, você pode usar a função ML.GLOBAL_EXPLAIN. Para usar ML.GLOBAL_EXPLAIN, o modelo precisa ser treinado novamente com a opção ENABLE_GLOBAL_EXPLAIN=TRUE.
Execute novamente a consulta de treinamento com esta opção usando a seguinte consulta:
#standardSQL
CREATE OR REPLACE MODEL bqml_tutorial.penguins_model
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g'],
enable_global_explain=TRUE) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
Observação: é possível ignorar o aviso sobre valores NULOS para dados de entrada.
Acesse as explicações globais com ML.GLOBAL_EXPLAIN
A consulta a seguir é usada para gerar explicações globais:
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Detalhes da consulta
Execute a consulta ML.GLOBAL_EXPLAIN
Executar a consulta ML.GLOBAL_EXPLAIN:
No Console do Cloud, clique em Escrever nova consulta.
Na área de texto do Editor de consultas, insira a consulta SQL padrão a seguir:
#standardSQL
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
(Opcional) Para definir o local dos dados, clique em Mais > Configurações de consulta. Em Local dos dados, clique em us (várias regiões nos Estados Unidos).
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão a seguinte aparência:
Tarefa 8: limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto ou mantenha o projeto e exclua cada um dos recursos.
Como excluir seu conjunto de dados
A exclusão do seu projeto vai remover todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console do Cloud.
No painel Explorer, clique em Ver ações () ao lado do seu conjunto de dados.
Clique em Excluir.
Na caixa de diálogo de exclusão do conjunto de dados, digite excluir e depois clique em Excluir para confirmar o comando de exclusão.
Como excluir o projeto
Para excluir o projeto:
No console do Cloud, no Menu de navegação, clique em IAM e administrador > Gerenciar recursos.
Observação: se aparecer uma solicitação, clique em SAIR no trabalho não salvo.
Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
Parabéns!
Você aprendeu a:
Criar um modelo de regressão linear usando a instrução CREATE MODEL com o ML do BigQuery.
Avaliar o modelo de ML com a função ML.EVALUATE.
Fazer previsões usando o modelo de ML com a função ML.PREDICT.
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender a criar e executar modelos de machine learning no BigQuery usando consultas SQL.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos

 ) e clique em APIs e serviços > Biblioteca.
) e clique em APIs e serviços > Biblioteca.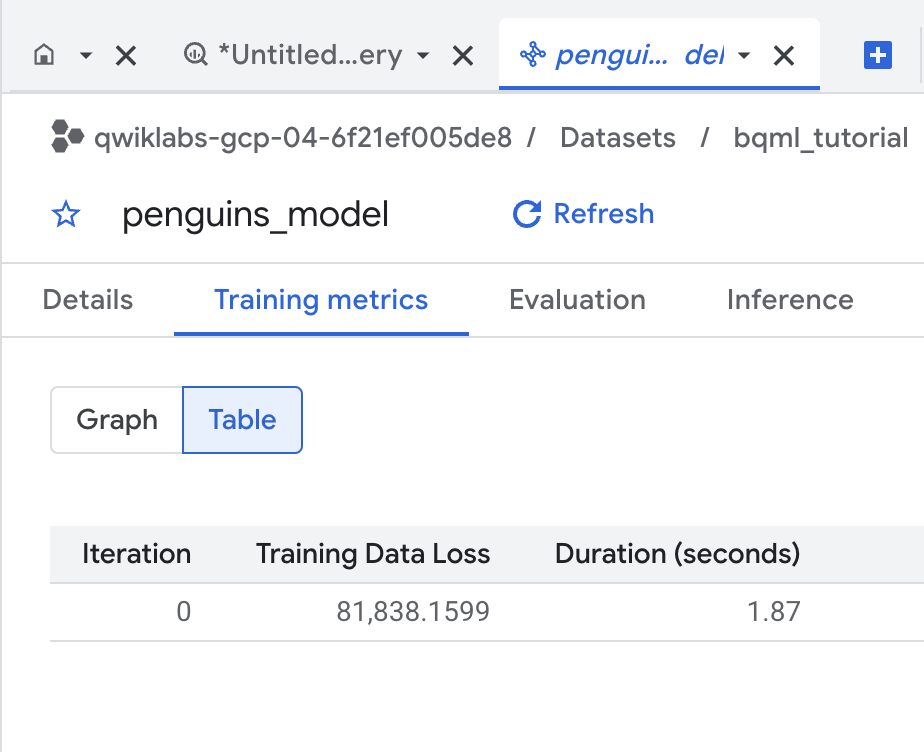

 ) ao lado do seu conjunto de dados.
) ao lado do seu conjunto de dados.




