Vertex AI is now Gemini Enterprise Agent Platform! We are currently updating our content to reflect this change. Please bear with us if you encounter naming inconsistencies during this transition.
Aplique suas habilidades no console do Google Cloud
Checkpoints
Create a training dataset
Verificar meu progresso
/ 5
Improving the model through feature engineering
Verificar meu progresso
/ 5
Make predictions
Verificar meu progresso
/ 5
Examine model weights
Verificar meu progresso
/ 5
Create a training dataset
Verificar meu progresso
/ 5
Improving the model through feature engineering
Verificar meu progresso
/ 5
Make predictions
Verificar meu progresso
/ 5
Examine model weights
Verificar meu progresso
/ 5
Este laboratório pode incorporar ferramentas de IA para ajudar no seu aprendizado.
Visão geral
O BigQuery é um banco de dados de análise NoOps, totalmente gerenciado e de baixo custo desenvolvido pelo Google. Com ele, você pode consultar muitos terabytes de dados sem ter que gerenciar uma infraestrutura ou precisar de um administrador de banco de dados. O BigQuery usa SQL e está disponível no modelo de pagamento por uso. Assim, você pode se concentrar na análise dos dados para encontrar insights relevantes.
O BigQuery Machine Learning é um recurso do BigQuery usado por analistas de dados para criar, treinar, avaliar e fazer previsões utilizando modelos de machine learning e um mínimo de programação.
Neste laboratório, você usará o conjunto de dados de bicicletas de Londres para criar um modelo de regressão no BigQuery ML e prever a duração dos passeios. Digamos que você trabalha em uma empresa de aluguel de bicicletas que oferece dois tipos de bicicleta: um modelo mais resistente para deslocamento diário e um modelo de estrada mais rápido e mais frágil. Para aluguéis de longa duração, precisamos ter as bicicletas de estrada em estoque. Mas, para aluguéis de curta duração, precisamos dos modelos para deslocamento diário. Portanto, para criar um sistema de estocagem, precisamos prever a duração dos aluguéis.
Objetivos
Neste laboratório, você aprenderá a realizar estas tarefas:
Consultar e analisar o conjunto de dados de bicicletas de Londres para fazer engenharia de atributos
Criar um modelo de regressão linear no BigQuery ML
Avaliar o desempenho do seu modelo de machine learning
Extrair os pesos do seu modelo
Pré-requisitos
Um projeto do Google Cloud Platform
Um navegador (como o Google Chrome ou o Mozilla Firefox)
Configurar o ambiente
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Abra o BigQuery no Console do Cloud
No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você vai ver a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da interface.
Clique em Concluído.
Tarefa 1: analise os dados de uso das bicicletas para a engenharia de atributos
A primeira etapa para solucionar um problema de ML é a formulação, ou seja, identificar os atributos do modelo e o rótulo. Já que o objetivo do primeiro modelo é prever a duração do aluguel com base no conjunto de dados históricos, o rótulo é a duração.
Se acharmos que a duração varia de acordo com a estação onde a bicicleta é alugada, o dia da semana e o horário do dia, esses serão os atributos. Mas, antes de criar um modelo com eles, é melhor verificar se esses fatores realmente influenciam o rótulo.
O processo de identificar os atributos de um modelo de machine learning é chamado de engenharia de atributos. Geralmente, a engenharia de atributos é a parte mais importante na criação de modelos de ML precisos. Ela pode ter maior impacto do que o algoritmo usado ou o ajuste de hiperparâmetros. Para uma boa engenharia de atributos, é preciso entender bem os dados e o domínio. O processo se resume a testar hipóteses. Você pensa em um atributo, verifica se ele funciona (se tem informações mútuas com o rótulo) e depois o adiciona ao modelo. Se ele não funcionar, basta tentar novamente.
Impacto da estação
Para verificar se a duração do aluguel varia de acordo com a estação, podemos visualizar o resultado da consulta abaixo no Looker Studio.
No EDITOR de consulta, cole o seguinte:
SELECT
start_station_name,
AVG(duration) AS duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name
Clique em EXECUTAR.
Clique em ABRIR EM > Looker Studio no console do Cloud do BigQuery.
Quando solicitado, selecione o botão PRIMEIROS PASSOS.
Clique no Gráfico que aparece na tela.
Na guia CONFIGURAÇÃO do menu no lado direito, faça estas configurações:
Dimensão: start_station_name
Métrica: duration
Classificação: por duração, em ordem Descendente.
Interação do gráfico: ative as opções Cruzamento de filtros e Mudar classificação.
Na guia ESTILO do menu no lado direito, faça estas configurações:
Gráfico de barras: Vertical
Barras: 100
Eixos: Mostrar eixos
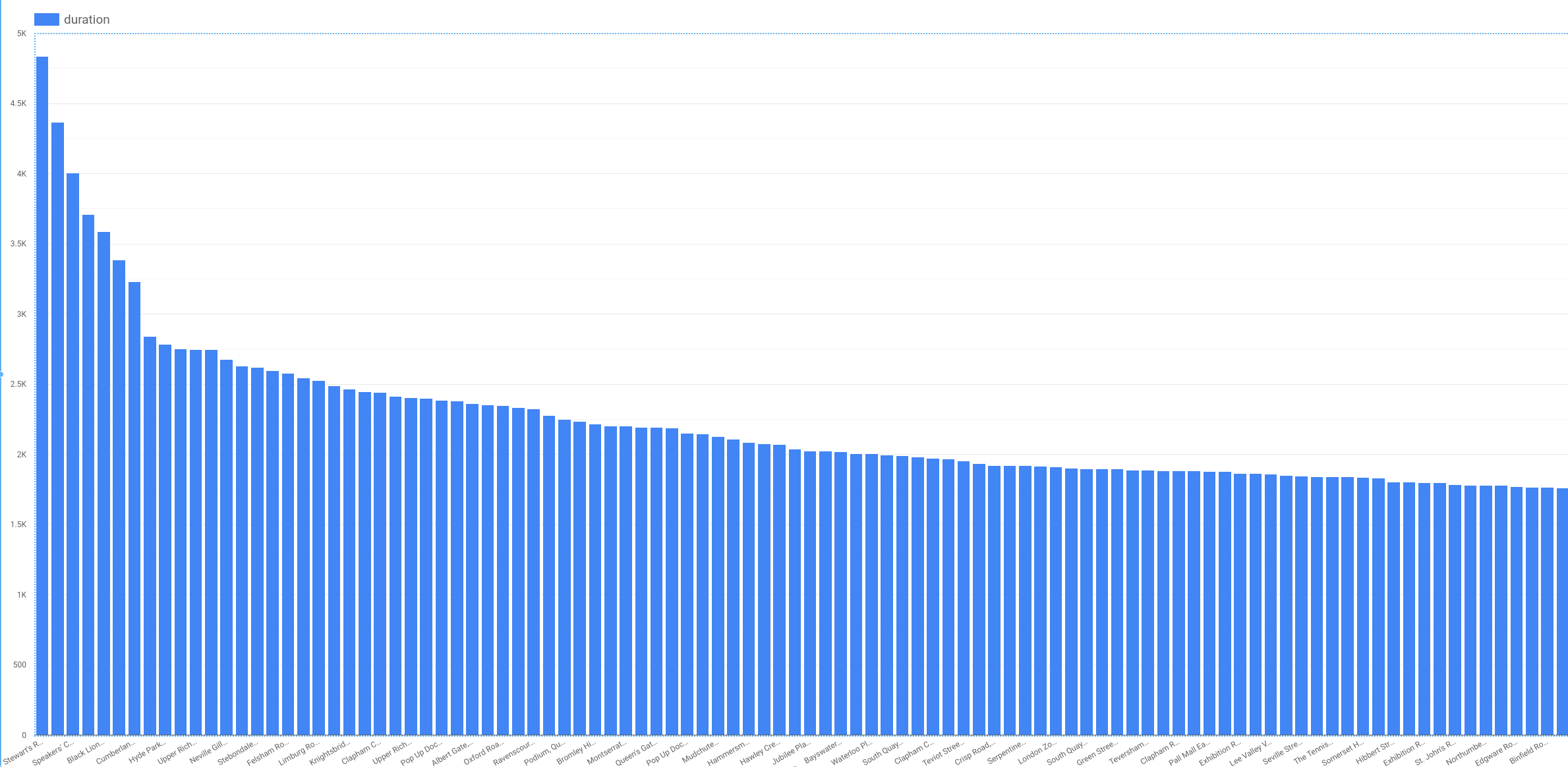
Seu plot será semelhante a este:
Algumas estações estão relacionadas a aluguéis de longa duração (mais de 3.000 segundos), mas, na maioria das estações, o intervalo de duração é relativamente curto. Se todas as estações de Londres tivessem um intervalo de duração curto, a estação de início do aluguel não seria um bom atributo. Mas neste problema, como demonstra o gráfico, start_station_name é importante.
Observação: não podemos usar end_station_name como atributo porque, no momento em que o aluguel é feito, não sabemos onde a bicicleta será devolvida.
Ao criarmos um modelo de machine learning para prever eventos no futuro, não podemos usar colunas com valores desconhecidos no momento em que o modelo faz a previsão. Essa limitação de tempo ou causalidade impõe alguns limites aos atributos que podemos usar.
Impacto do dia da semana e do horário do dia
Para os próximos candidatos a atributos, o processo é semelhante. Podemos verificar se dayofweek ou hourofday são importantes.
Na janela do editor de consultas, cole a seguinte consulta:
SELECT
EXTRACT(dayofweek
FROM
start_date) AS dayofweek,
AVG(duration) AS duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
dayofweek
Clique em ABRIR EM > Looker Studio no console do Cloud do BigQuery.
Observação: caso veja uma mensagem de erro do sistema, você precisará fazer algumas mudanças para visualizar os dados no Looker Studio descritos nas etapas 3 a 11.
Clique na tabela que contém os dados duration e dayofweek.
Em Configuração > Métrica, passe o cursor sobre dayofweek e clique no ícone de lápis Editar.
No menu suspenso Formato de exibição, clique em Número da semana e escolha Formato de data personalizado.
Modifique a data personalizada para Day w e clique em Aplicar.
No gráfico, o campo dayofweek agora mostra do dia 1 ao 7.
Clique no gráfico que mostra o erro do sistema.
Em Configuração > Dimensão, clique em Duração e altere para dayofweek.
Em Configuração > Dimensão, passe o cursor sobre dayofweek e clique no ícone de lápis Editar.
No menu suspenso Formato de exibição, selecione Formato de data personalizado e mude a data personalizada para Day w. Em seguida, clique em Aplicar.
Em Configuração > Métrica, clique em dayofweek e altere para duration.
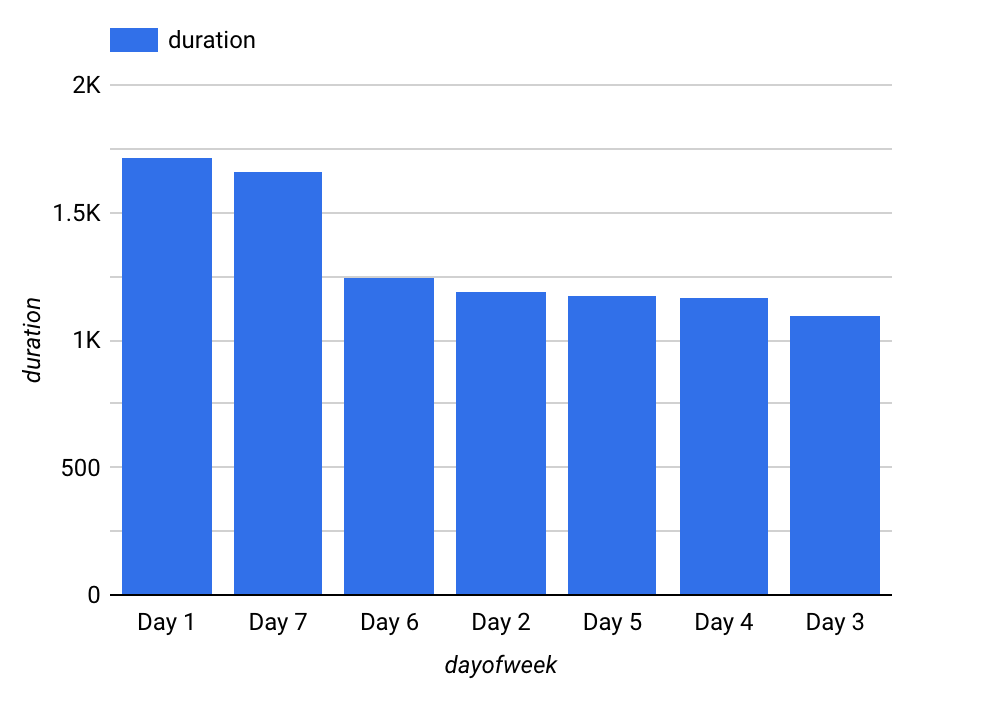
Para o dia da semana, sua visualização será semelhante a esta:
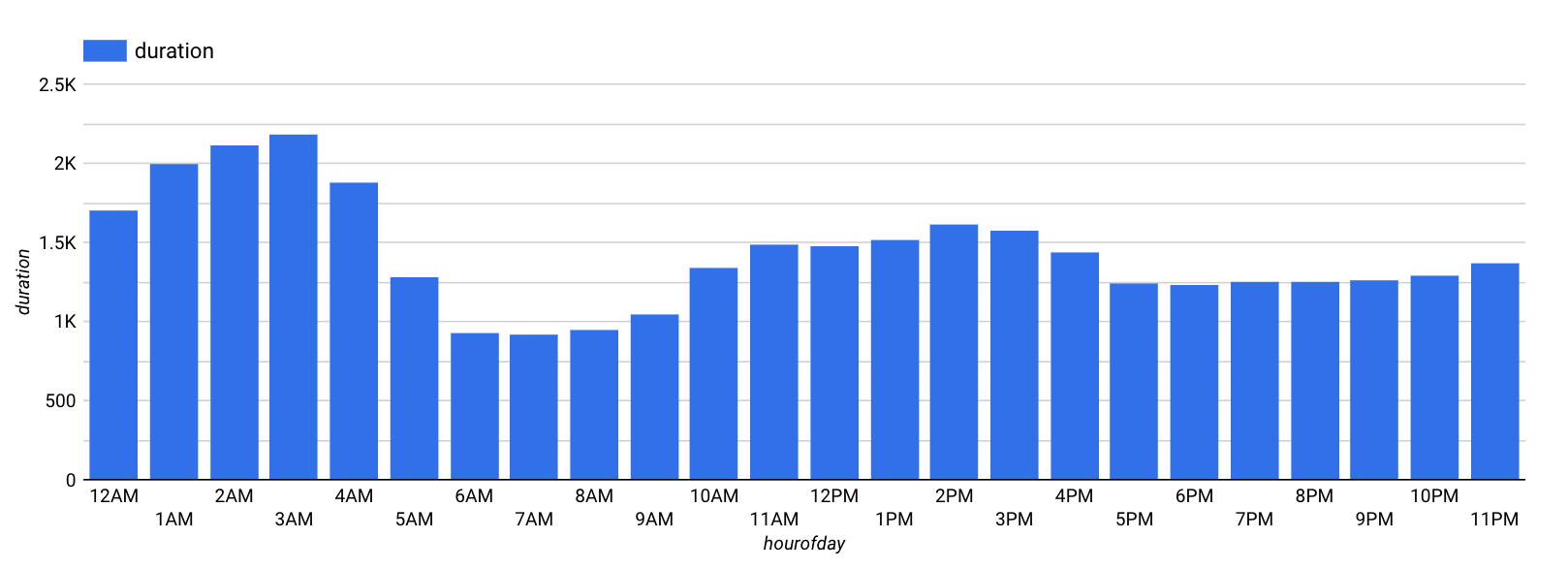
Para o horário do dia, sua visualização será semelhante a esta:
Observação: assim como nas etapas anteriores, você pode precisar modificar as propriedades no Looker Studio para ver os resultados esperados.
A duração varia de acordo com o dia da semana e com o horário. Parece que a duração dos aluguéis é mais longa nos fins de semana (dias 1 e 7) do que nos dias úteis. A duração também é maior no início da manhã e no meio da tarde. Portanto, dayofweek e hourofday são ambos bons atributos.
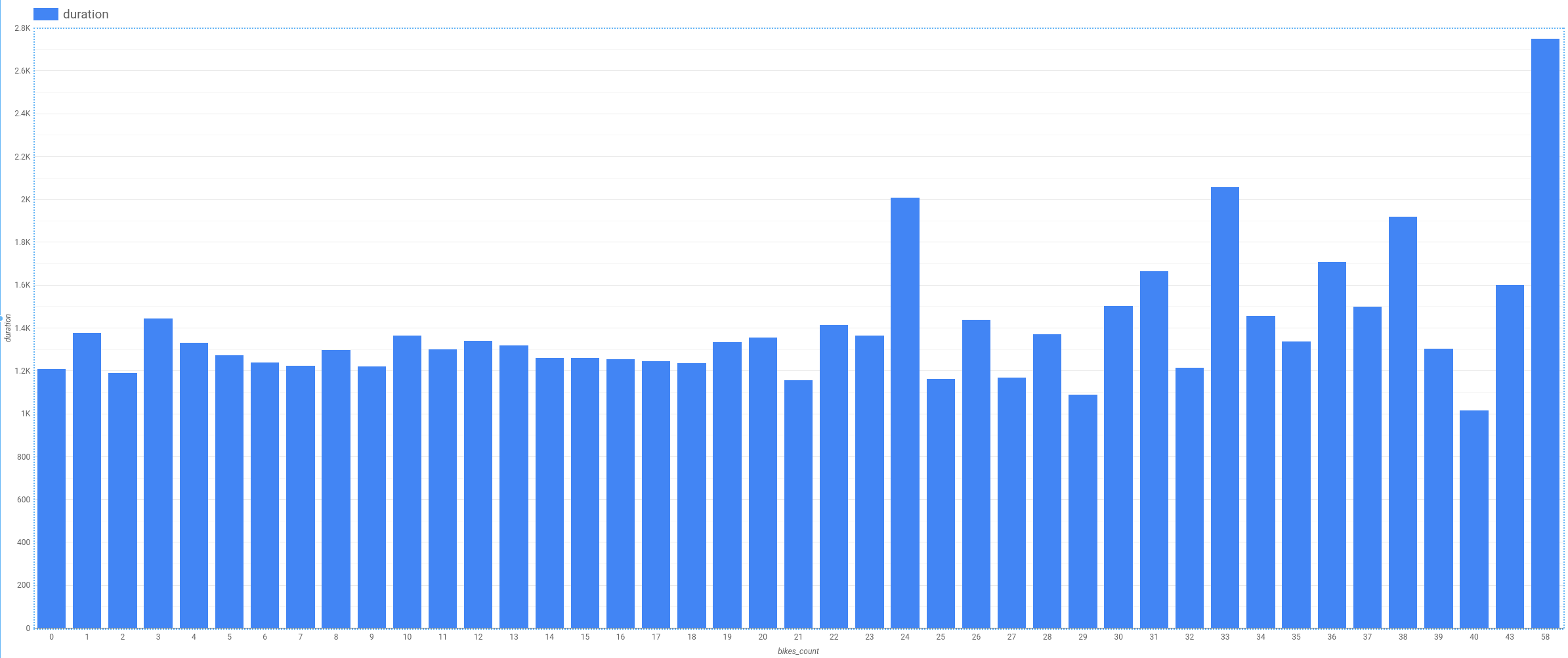
Impacto do número de bicicletas
Outro atributo possível é o número de bicicletas na estação. Nós formulamos a hipótese de que as pessoas manteriam as bicicletas por mais tempo se houvesse um número menor delas na estação de retirada.
Na janela do editor de consultas, cole a seguinte consulta:
SELECT
bikes_count,
AVG(duration) AS duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations
ON
cycle_hire.start_station_name = cycle_stations.name
GROUP BY
bikes_count
Visualize seus dados no Looker Studio.
A relação entre os fatores é confusa e não mostra uma tendência clara (em comparação com hour-of-day (hora do dia), por exemplo). Isso indica que o número de bicicletas não é um bom atributo.
Tarefa 2: crie um conjunto de dados de treinamento
Com base na análise do conjunto de dados de bicicletas e na relação das demais colunas com a coluna do rótulo, podemos extrair os atributos e o rótulo para preparar o conjunto de dados de treinamento:
SELECT
duration,
start_station_name,
CAST(EXTRACT(dayofweek
FROM
start_date) AS STRING) AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
As colunas de atributos precisam ser do tipo numérico (INT64, FLOAT64 etc.) ou categórico (STRING). Quando precisamos tratar um atributo numérico como categórico, é necessário convertê-lo em uma string. Foi por isso que convertemos em strings as colunas dayofweek e hourofday, que são números inteiros (nos intervalos de 1 a 7 e 0 a 23, respectivamente).
Quando a preparação dos dados envolve um excesso de operações de transformação ou mesclagem, é melhor salvar os dados de treinamento preparados em uma tabela para não repetir esse trabalho na experimentação. Quando as transformações são comuns, mas a consulta em si é longa, talvez seja melhor salvá-la em uma visualização para evitar a repetição.
Neste caso em que a consulta é simples e curta, para facilitar, não vamos salvá-la.
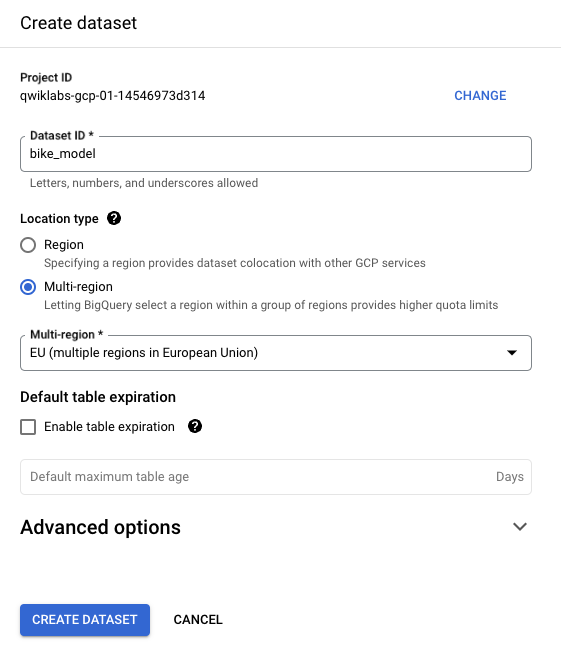
No BigQuery, crie um conjunto de dados chamado bike_model para armazenar seu modelo. Defina Tipo de local como Multirregional e selecione UE (várias regiões na União Europeia) já que os dados de treinamento são de lá. Clique em Criar conjunto de dados.
Para treinar e salvar o modelo de ML no conjunto de dados bike_model, precisamos chamar CREATE MODEL, que é semelhante a CREATE TABLE. Como o rótulo que queremos prever é numérico, este é um problema de regressão. Por isso, a opção mais apropriada é escolher linear_reg no tipo de modelo emOPTIONS.
Digite esta consulta no editor de consultas:
CREATE OR REPLACE MODEL
bike_model.model
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
CAST(EXTRACT(dayofweek
FROM
start_date) AS STRING) AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
O treinamento do modelo demora de dois a três minutos.
Para ver algumas métricas relacionadas ao treinamento do modelo, digite esta consulta na janela do editor do BigQuery:
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model`)
O erro absoluto médio é de 1.025 segundos, ou cerca de 17 minutos. Isso significa que podemos prever a duração dos aluguéis de bicicleta com um erro médio de cerca de 17 minutos.
Clique em Verificar meu progresso para ver o objetivo.
Crie um conjunto de dados de treinamento
Tarefa 3: melhore o modelo com a engenharia de atributos
Combine os dias da semana
Existem outras maneiras de representar os recursos disponíveis. Por exemplo, nós analisamos a relação entre dayofweek e duration dos aluguéis, constatando que a duração era maior nos fins de semana. Portanto, em vez de tratarmos o valor bruto de dayofweek como um atributo, podemos usar essa informação para unir vários valores de dayofweek na categoria "weekday".
Use esta consulta para criar um modelo do BigQuery ML com o atributo combinado de dias da semana:
CREATE OR REPLACE MODEL
bike_model.model_weekday
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Para acessar as métricas para este modelo, insira a consulta a seguir na janela do editor do BigQuery:
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model_weekday`)
Este modelo tem um erro absoluto médio de 966 segundos, menor do que o valor de 1.025 segundos do modelo original. Estamos progredindo.
Agrupe a hora do dia em classes
Com base na relação entre hourofday e duration, podemos agrupar as variáveis em quatro classes: (-inf,5), [5,10), [10,17) e [17,inf).
Use esta consulta para criar um modelo de BigQuery ML com a hora do dia agrupada em classes e os atributos combinados de dia da semana:
CREATE OR REPLACE MODEL
bike_model.model_bucketized
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
ML.BUCKETIZE(EXTRACT(hour
FROM
start_date),
[5, 10, 17]) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Para acessar as métricas para este modelo, insira a consulta a seguir na janela do editor do BigQuery:
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model_bucketized`)
Este modelo tem um erro absoluto médio de 904 segundos, menor do que o valor de 966 segundos do modelo de dias da semana/fim de semana. Estamos cada vez melhores.
Clique em Verificar meu progresso para ver o objetivo.
Melhore o modelo com a engenharia de atributos
Tarefa 4: faça previsões
Nosso melhor modelo contém várias transformações de dados. Não seria ótimo se o BigQuery lembrasse dos conjuntos de transformações que fizemos no treinamento e os aplicasse automaticamente no momento da previsão? Ele pode fazer isso com a cláusula TRANSFORM.
Neste caso, o modelo resultante precisa apenas de start_station_name e start_date para prever duration. As transformações são salvas e feitas nos dados brutos fornecidos para criar os atributos de entrada do modelo. A principal vantagem de colocar todas as funções de pré-processamento dentro da cláusula TRANSFORM é que os clientes do modelo não precisam saber qual pré-processamento foi realizado.
Crie um modelo do BigQuery ML com a cláusula TRANSFORM que incorpore a hora do dia agrupada em classes e os atributos combinados de dia da semana. Para isso, use esta consulta:
CREATE OR REPLACE MODEL
bike_model.model_bucketized TRANSFORM(* EXCEPT(start_date),
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
ML.BUCKETIZE(EXTRACT(HOUR
FROM
start_date),
[5, 10, 17]) AS hourofday )
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE `duration` IS NOT NULL
Com a cláusula TRANSFORM implantada, digite esta consulta para prever a duração do aluguel em Park Lane agora mesmo (seu resultado será diferente):
SELECT
*
FROM
ML.PREDICT(MODEL bike_model.model_bucketized,
(
SELECT
'Park Lane , Hyde Park' AS start_station_name,
CURRENT_TIMESTAMP() AS start_date) )
Para fazer previsões em lote usando uma amostra de 100 linhas do conjunto de treinamento, execute esta consulta:
SELECT
*
FROM
ML.PREDICT(MODEL bike_model.model_bucketized,
(
SELECT
start_station_name,
start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT
100) )
Clique em Verificar meu progresso para ver o objetivo.
Faça previsões
Tarefa 5: examine os pesos do modelo
Os modelos de regressão linear preveem o resultado de uma soma ponderada dos valores de entrada. Às vezes, é preciso usar os pesos do modelo em um ambiente de produção.
Use esta consulta para examinar (ou exportar) os pesos do seu modelo:
SELECT * FROM ML.WEIGHTS(MODEL bike_model.model_bucketized)
Os atributos numéricos recebem um único peso, enquanto os atributos categóricos recebem um peso para cada valor possível. Por exemplo, o atributo dayofweek tem estes pesos:
Isso significa que, em dias úteis, a contribuição desse atributo para a duração geral prevista é de 1.709 segundos. Como os pesos que dão o melhor desempenho não são exclusivos, talvez seu resultado seja diferente.
Clique em Verificar meu progresso para ver o objetivo.
Examine os pesos do modelo
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Antes de começar
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você usará o conjunto de dados de bicicletas de Londres para criar um modelo de regressão no BQML e prever a duração dos passeios.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 60 minutos