

Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create a Cloud Storage bucket
/ 25
Upload CSV files to Cloud Storage
/ 25
Create a Cloud SQL instance
/ 25
Create a database
/ 25
Create a Cloud Storage bucket
/ 25
Upload CSV files to Cloud Storage
/ 25
Create a Cloud SQL instance
/ 25
Create a database
/ 25

SQL (ראשי תיבות של Structured Query Language) היא שפה סטנדרטית לפעולות בנתונים, שבעזרתה אפשר לשאול שאלות ולהפיק תובנות ממערכי נתונים מובְנים. משתמשים בה בדרך כלל בניהול מסדי נתונים כדי לבצע משימות כמו כתיבת רשומות של טרנזקציות במסדי נתונים רלציוניים וניתוח נתונים בקנה מידה של פטה-בייט.
שיעור ה-Lab הזה הוא מבוא ל-SQL, ומטרתו להכין אתכם ליחידות ה-Quest ושיעורי ה-Lab הרבים ב-Google Skills שעוסקים במדעי הנתונים. השיעור מחולק לשניים: בחלק הראשון תלמדו מילות מפתח בסיסיות לשאילתות SQL. את השאילתות האלה תריצו במסוף BigQuery על מערך נתונים ציבורי שמכיל מידע על אופניים שיתופיים בלונדון.
בחלק השני תלמדו איך לייצא לקובצי CSV קבוצות של נתונים מהמערך של נתוני האופניים השיתופים בלונדון, ותעלו את הקבצים האלה ל-Cloud SQL. אחר כך תלמדו איך להשתמש ב-Cloud SQL כדי ליצור ולנהל טבלאות ומסדי נתונים. לקראת סיום, תתרגלו מילות מפתח נוספות של SQL כדי להציג נתונים בדרכים שונות ולערוך אותם.
בשיעור ה-Lab הזה תלמדו איך:
SELECT, FROM ו-WHERE
כדי ליצור שאילתות פשוטות.
COUNT, GROUP BY, AS
ו-ORDER BY.
CREATE DATABASE, CREATE TABLE,
DELETE, INSERT INTO ו-UNION ב-Cloud
SQL.
חשוב מאוד: לפני התחלת שיעור ה-Lab הזה, תצטרכו לצאת מחשבון Gmail האישי או העסקי שלכם.
זהו שיעור Lab ברמת מבוא. אנחנו יוצאים מנקודת הנחה שיש לכם מעט מאוד ניסיון ב-SQL, או שאין לכם ניסיון בכלל. מומלץ להכיר את Cloud Storage ואת Cloud Shell, אבל לא חובה. בשיעור ה-Lab הזה תלמדו את העקרונות הבסיסיים של קריאה וכתיבה של שאילתות ב-SQL, ותיישמו אותם באמצעות BigQuery ו-Cloud SQL.
לפני שתתחילו את שיעור ה-Lab הזה, כדאי שתעצרו ותחשבו מה רמת הידע והניסיון שלכם ב-SQL. השיעורים הבאים יותר מאתגרים ויאפשרו לכם להשתמש בידע שלכם בתרחישים יותר מתקדמים:
כשתהיו מוכנים, גללו מטה והשלימו את השלבים שבהמשך כדי להגדיר את סביבת שיעור ה-Lab.
עליכם לקרוא את ההוראות האלו. המעבדות מוגבלות בזמן ואי אפשר להשהות אותן. הטיימר מתחיל כשלוחצים על Start Lab ומראה את משך הזמן שבו תוכלו להשתמש במשאבים ב-Google Cloud.
במעבדה המעשית הזו של Qwiklabs, תוכלו לבצע את פעילויות המעבדה בעצמכם בסביבת ענן אמיתית, ולא בהדמיה או בסביבה להדגמה. לשם כך, יינתנו לכם פרטי כניסה זמניים שאיתם תיכנסו ותיגשו אל Google Cloud במשך הפעילות של המעבדה.
כדי להשלים את המעבדה, תצטרכו:
הערה: אם כבר יש לכם פרויקט או חשבון Google Cloud אישי משלכם, אין להשתמש בו במעבדה הזו.
הערה: אם משתמשים במכשיר עם Chrome OS, צריך לפתוח חלון אנונימי כדי להריץ את המעבדה הזו.
לוחצים על הלחצן Start Lab (התחלת השיעור המעשי). אם זה שיעור בתשלום, יקפוץ חלון שבו בוחרים אמצעי תשלום. מימין יש חלונית עם פרטי כניסה זמניים שמולאו מראש. צריך להשתמש בפרטים האלו בשיעור המעשי הזה.
מעתיקים את שם המשתמש ואז לוחצים על Open Google Console (פתיחת Google Console). יופעלו משאבים במעבדה, ואז ייפתח הדף Sign in (כניסה) בכרטיסייה נפרדת.
טיפ: כדאי לפתוח את הכרטיסיות בחלונות נפרדים, אחד לצד השני.
בדף Sign in (כניסה), מדביקים את שם המשתמש שהעתקתם מהחלונית Connection Details (פרטי התחברות). אחר כך מעתיקים ומדביקים את הסיסמה.
חשוב: צריך להשתמש בפרטי הכניסה מהחלונית Connection Details. אין להשתמש בפרטי הכניסה של Qwiklabs. אם יש לכם חשבון Google Cloud משלכם, אל תשתמשו בו בשיעור המעשי הזה (כך תימנעו מחיוב בתשלום).
לוחצים כדי לעבור את הדפים הבאים:
לאחר כמה דקות, Cloud Console ייפתח בכרטיסייה הזו.
כמו שציינו קודם, בעזרת SQL אתם יכולים לחלץ מידע מ"מערכי נתונים מובְנים". למערכים כאלה יש עיצוב וכללים ברורים, והרבה פעמים הם מחולקים לטבלאות: נתונים שמסודרים בשורות ובעמודות.
קובץ תמונה הוא דוגמה לנתונים לא מובְנים. אי אפשר לבצע פעולות על נתונים לא מובנים באמצעות SQL, ואי אפשר לשמור אותם בטבלאות או במערכי נתונים של BigQuery (לפחות לא בצורה טבעית). כדי להשתמש בנתוני תמונה (למשל), נדרש שירות כמו Cloud Vision, אולי ישירות דרך ה-API שלו.
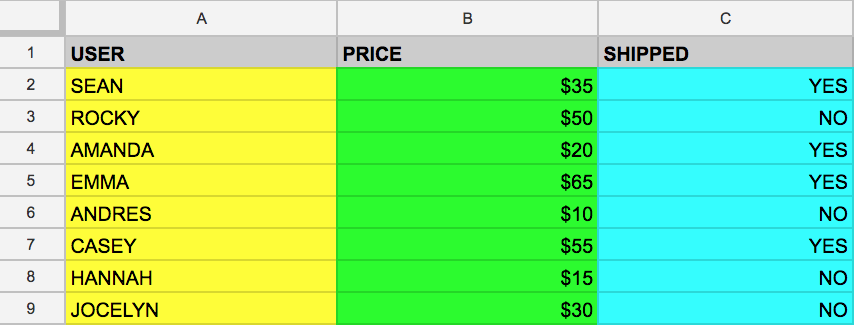
הדוגמה הבאה היא של מערך נתונים מובְנים – טבלה פשוטה:
|
משתמש |
מחיר |
נשלחה |
שמעון |
35$ |
כן |
בני |
50$ |
לא |
אם יש לכם ניסיון ב-Google Sheet, הטבלה הזו אמורה להיראות לכם די מוכרת. לטבלה יש עמודות (USER, PRICE ו-SHIPPED) ושתי שורות עם ערכים שמולאו בכל עמודה.
מסד נתונים הוא בעצם אוסף של טבלה אחת או יותר. SQL היא כלי לניהול מסדי נתונים מובְנים, אבל הרבה פעמים (וגם בשיעור ה-Lab הזה) מריצים שאילתות על טבלה אחת או מספר טבלאות מחוברות – לא על מסדי נתונים שלמים.
SQL היא שפה פונטית, כך שלפני שמריצים שאילתות כדאי לחשוב על השאלה שרוצים לשאול ועל תשובה שרוצים לקבל מהנתונים (אלא אם סתם מתנסים בה בשביל הכיף).
ל-SQL יש מילות מפתח מוגדרות מראש, ואפשר להשתמש בהן כדי "לתרגם" את השאלה לתחביר של SQL (שמזכיר אנגלית) ואז תתקבל התשובה הרצויה מהמנוע של מסד הנתונים.
מילות המפתח החיוניות ביותר הן SELECT ו-FROM:
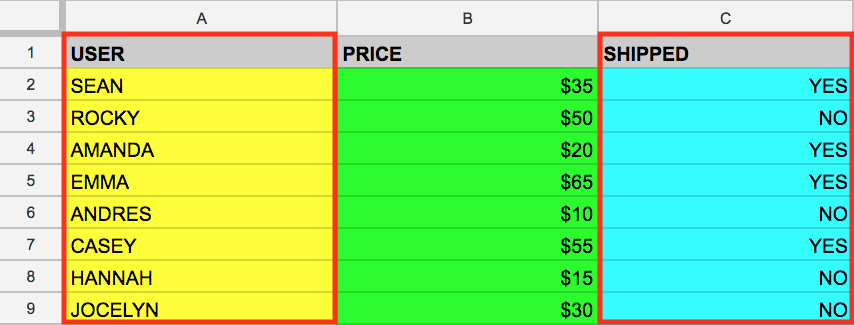
SELECT כדי לציין אילו שדות רוצים לשלוף ממערך הנתונים.
FROM כדי לציין מאיזו טבלה או מאילו טבלאות רוצים לשלוף
את הנתונים.
ניעזר בדוגמה כדי להבין. נניח שיש לכם את הטבלה הבאה,
example_table, עם העמודות USER, PRICE ו-SHIPPED.
ונניח שאתם רוצים לשלוף ממנה רק את הנתונים שבעמודה USER. כדי לעשות זאת, תוכלו
להריץ את השאילתה הבאה עם מילות המפתח SELECT ו-FROM:
אם תריצו את הפקודה הזו, תבחרו את כל השמות מהעמודה USERשנמצאים
בטבלה example_table.
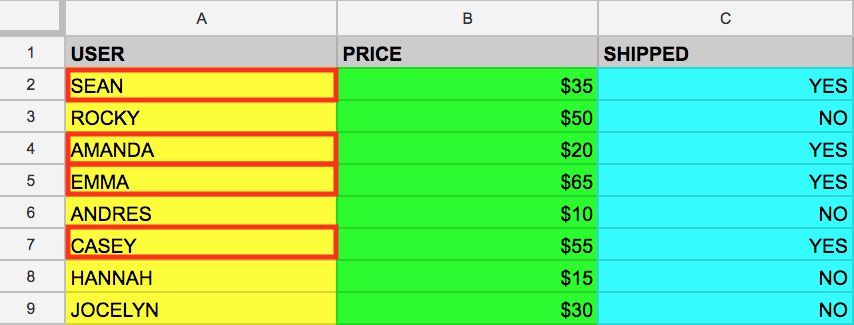
אפשר לבחור גם מספר עמודות באמצעות מילת המפתח SELECT של SQL. נניח
שאנחנו רוצים לשלוף את הנתונים מעמודות USER ו-SHIPPED. כדי לעשות את זה, נשנה את
השאילתה הקודמת ונוסיף עוד שם של עמודה למילת המפתח SELECT (חשוב
להפריד בין השמות באמצעות פסיקים!):
אם נריץ את הפקודה הזו, נשלוף את הנתונים מהעמודות
USER ו-SHIPPED:
וזהו! למדתם שתי מילות מפתח בסיסיות ב-SQL! עכשיו ניכנס קצת יותר בעובי הקורה.
מילת המפתח WHERE היא פקודה נוספת של SQL שמשמשת לסינון טבלאות לפי
ערכים ספציפיים בעמודות. נניח שאנחנו רוצים לשלוף מהטבלה
example_table רק את השמות של מי שהחבילה שלו נשלחה. נוכל להוסיף
לשאילתה את מילת המפתח WHERE, כמו בדוגמה הבאה:
אם נריץ את הפקודה הזו, נשלוף מהעמודה USER רק את הנתונים של מי שהחבילה שלו נשלחה:
עכשיו, אחרי שהבנתם את מילות המפתח הבסיסיות של SQL, תוכלו ליישם את מה שלמדתם ולהריץ את שאילתות מהסוג הזה במסוף BigQuery.
נסו לענות כמיטב יכולתכם על השאלות האמריקאיות הבאות כדי לחדד את ההבנה של הנושאים שעברנו עליהם עד עכשיו.
BigQuery הוא מחסן נתונים (data warehouse) מנוהל בקנה מידה של פטה-בייט שפועל ב-Google Cloud. אנליסטים ומדעני נתונים יכולים להריץ בקלות שאילתות כדי לסנן מערכי נתונים גדולים, לאחד תוצאות ולבצע פעולות מורכבות, בלי לדאוג להגדרה ולניהול של שרתים. הגישה אליו מתבצעת דרך כלי שורת הפקודה (שמותקן מראש ב-cloudshell) או דרך מסוף אינטרנט. בשני המקומות אפשר לנהל נתונים ולהריץ עליהם שאילתות בפרויקטים ב-Google Cloud.
בשיעור ה-Lab הזה נשתמש במסוף האינטרנט כדי להריץ שאילתות SQL.
ב-Google Cloud Console, בוחרים בתפריט הניווט > BigQuery:
תיפתח ההודעה Welcome to BigQuery in the Cloud Console (ברוך בואך אל BigQuery ב-Cloud Console). בהודעה הזו יש קישור למדריך למתחילים ולהערות המוצר.
לוחצים על סיום.
המסוף של BigQuery ייפתח.
נעבור רגע על חלק מהתכונות החשובות ביותר בממשק המשתמש. בצד ימין של המסוף נמצא עורך השאילתות. כאן כותבים ומריצים פקודות SQL כמו הדוגמאות שראינו קודם. מתחתיו נמצאת היסטוריית השאילתות, שהיא רשימת השאילתות שהרצתם.
החלונית שנמצאת בצד שמאל של המסוף היא חלונית הניווט. מלבד היסטוריית השאילתות, השאילתות השמורות והיסטוריית המשימות, ישנה הכרטיסייה Explorer.
ברמה הגבוהה ביותר של המשאבים בכרטיסייה Explorer נמצאים הפרויקטים ב-Google Cloud, בדיוק כמו הפרויקטים הזמניים ב-Google Cloud שאתם נכנסים אליהם ומשתמשים בהם בכל שיעור Lab ב-Google Skills. כמו שאפשר לראות במסוף ובצילום המסך האחרון, בכרטיסייה Explorer נמצאים רק הפרויקטים שלכם כרגע. אם תנסו ללחוץ על החץ שליד שם הפרויקט, שום דבר לא יופיע.
הסיבה היא שהפרויקט לא מכיל אף מערך נתונים או טבלה, כך שאין מה לחפש באמצעות שאילתות. קודם למדנו שמערכי נתונים מכילים טבלאות. כשאתם מוסיפים נתונים לפרויקט, שימו לב שב-BigQuery הפרויקטים מכילים מערכי נתונים, ומערכי הנתונים מכילים טבלאות. עכשיו, כשאתם מבינים יותר טוב את הפרדיגמה 'פרויקט > מערך נתונים > טבלה' ואת המורכבויות של המסוף, אתם יכולים לטעון נתונים ולהריץ עליהם שאילתות.
בחלק הזה נשלוף נתונים ציבוריים לפרויקט כדי שתוכלו לתרגל הרצת פקודות SQL ב-BigQuery.
לוחצים על + ADD.
בוחרים באפשרות Star a project by name.
נותנים לפרויקט את השם bigquery-public-data.
לוחצים על STAR.
חשוב לזכור שבכרטיסייה החדשה הזו אנחנו עדיין עובדים על הפרויקט של שיעור ה-Lab. כל מה שעשינו הוא לשלוף נתונים מפרויקט ציבורי שמכיל טבלאות ומערכי נתונים ולהעלות אותם ל-BigQuery לצורך ניתוח הנתונים – לא עברנו לפרויקט הזה. כל המשימות והשירותים שלכם עדיין מקושרים לחשבון ב-Google Skills. אתם יכולים לראות זאת בעצמכם בשדה הפרויקט, בחלק העליון של המסוף:
bigquery-public-data
london_bicycles
cycle_hire
cycle_stations
בשיעור ה-Lab הזה נשתמש בנתונים מהטבלה cycle_hire. פותחים את
הטבלה cycle_hire ולוחצים על הכרטיסייה Preview.
הדף שנפתח אמור להיראות כך:
אתם מוזמנים לעיין בעמודות ובערכים שבשורות. עכשיו אתם מוכנים להריץ כמה שאילתות
SQL על הטבלה cycle_hire.
עכשיו אמורה להיות לכם הבנה בסיסית במילות המפתח לשאילתות SQL ובפרדיגמת הנתונים של BigQuery, ויש לכם גם נתונים שאתם יכולים להתנסות בהם. באמצעות השירות הזה תוכלו להריץ פקודות SQL.
אם תסתכלו בפינה הימנית התחתונה במסוף, תראו שיש 24,369,201 שורות של נתונים, או נסיעות באופניים שיתופיים בלונדון בין השנים 2015 ל-2017 (מספר לא מבוטל של נסיעות!)
עכשיו תסתכלו בעמודה השביעית, end_station_name, שבה כתוב שם התחנה
שבה הסתיימה הנסיעה באופניים. לפני שנצלול יותר מדי לעומק, בואו נריץ שאילתה
פשוטה כדי לבודד את העמודה end_station_name.
אחרי כ-20 שניות אמורות להופיע 24,369,201 שורות רק עם העמודה שבודדנו באמצעות
השאילתה, end_station_name.
עכשיו ננסה לבדוק כמה נסיעות באופניים נמשכו 20 דקות או יותר.
WHERE.
הרצת השאילתה הזו תימשך כדקה.
הפקודה SELECT * מחזירה את כל ערכי העמודות מהטבלה. משך הנסיעה הוא
בשניות, ולכן השתמשנו בערך 1,200 (מכפלה של 60 ב-20).
אם תסתכלו בפינה הימנית התחתונה, תראו שיש עכשיו 7,334,890 תוצאות. אם נחלק את המספר הזה בסך כל השורות (7,334,890 חלקי 24,369,201), נראה שכ-30% מהנסיעות באופניים שיתופיים בלונדון נמשכו 20 דקות או יותר (לזה אנחנו קוראים נסיעות ארוכות!)
נסו לענות כמיטב יכולתכם על השאלות האמריקאיות הבאות, כדי לחדד את ההבנה של הנושאים שעברנו עליהם עד עכשיו.
בעזרת מילת המפתח GROUP BY נוכל לקבץ את התוצאות משורות שחולקות
קריטריונים נפוצים (למשל ערך מסוים בעמודה), ולהציג את כל הערכים הייחודיים
שנמצאו לפי אותם קריטריונים.
זו מילת מפתח שימושית לבירור מידע קטגורי מטבלאות.
בתוצאות תוצג רשימה של ערכים ייחודיים בעמודות (ללא כפילויות).
בלי GROUP BY, השאילתה הייתה מחזירה את כל
24,369,201 השורות. אבל מכיוון שהשתמשנו ב-GROUP BY, מופיעים רק הערכים הייחודיים שנמצאו בטבלה. אתם יכולים לראות זאת בעצמכם בפינה
הימנית התחתונה. תוכלו לראות שיש 880 שורות. כלומר יש 880
נקודות התחלה שונות לאופניים שיתופיים בלונדון.
הפונקציה COUNT() מחזירה את מספר השורות שחולקות אותם קריטריונים
(למשל אותו ערך בעמודה). זו פונקציה שימושית מאוד לשילוב עם
GROUP BY.
נוכל להוסיף את הפונקציה COUNT לשאילתה הקודמת, כדי לברר כמה נסיעות
התחילו בכל אחת מנקודות ההתחלה.
עכשיו אנחנו רואים בפלט כמה נסיעות באופניים שיתופיים התחילו בכל אחת מנקודות ההתחלה.
מילת מפתח נוספת של SQL היא AS, שיוצרת כינוי לטבלה או
לעמודה. כינוי הוא שם חדש שניתן לעמודה או לטבלה שמוחזרת, לפי מה שמציינים
ב-AS.
AS לשאילתה
האחרונה שהרצנו. מחקו את השאילתה בעורך, והעתיקו והדביקו את הפקודה הבאה:
השם של העמודה הימנית בתוצאות ישתנה מ-COUNT(*)
ל-num_starts.
כמו שאתם רואים, העמודה COUNT(*) בטבלה שהוחזרה נקראת עכשיו
num_starts – הכינוי שנתנו לה. מילת המפתח הזו שימושית במיוחד אם
מערכי הנתונים גדולים – השמות של עמודות או טבלאות נפוצים יותר ממה שאתם חושבים!
מילת המפתח ORDER BY משמשת למיון הנתונים שהוחזרו מהשאילתה בסדר
עולה או יורד, לפי קריטריונים מסוימים או ערך בעמודה. הוסיפו אותה לשאילתה הקודמת
כדי:
כל אחת מהפקודות הבאות היא שאילתה נפרדת. בכל אחת מהפקודות:
התוצאות של השאילתה האחרונה מוינו לפי מספר הנסיעות שהתחילו בכל אחת מתחנות ההתחלה.
נוכל לראות שבתחנה "Belgrove Street, King's Cross" התחילו הכי הרבה נסיעות. עם זאת, אם תחלקו את המספר הזה בסך כל השורות (234,458 חלקי 24,369,201), תראו שפחות מ-1% מהנסיעות התחילו בתחנה הזו.
נסו לענות כמיטב יכולתכם על השאלות האמריקאיות הבאות כדי לחדד את ההבנה של הנושאים שעברנו עליהם עד עכשיו.
Cloud SQL הוא שירות מנוהל של מסד
נתונים, שבעזרתו אפשר ליצור, לתחזק ולנהל מסדי נתונים רלציוניים של PostgreSQL
ו-MySQL בענן. ב-Cloud SQL אפשר להשתמש בשני פורמטים של נתונים: קובצי SQL מוכנים
לשימוש (sql.) וקובצי CSV (csv.) כאן תלמדו איך לייצא לקובצי CSV קבוצות של
נתונים מהטבלה cycle_hire ולהעלות אותם ל-Cloud Storage בתור מיקום
זמני.
נחזור למסוף BigQuery. זו אמורה להיות הפקודה האחרונה שהרצתם:
בחלק עם תוצאות השאילתה, לוחצים על SAVE RESULTS > CSV(local file). תתחיל הורדה של קובץ CSV עם תוצאות השאילתה. שימו לב איך הקובץ נקרא ואיפה הוא נשמר, כי תצטרכו אותו בקרוב.
מוחקים את הפקודה בעורך השאילתות, מעתיקים ומדביקים את הפקודה הבאה ואז מריצים אותה:
תוחזר טבלה שמכילה את מספר הנסיעות באופניים שיתופיים שהסתיימו בכל אחת מתחנות הסיום, מהגבוה לנמוך.
נכנסים למסוף Cloud ויוצרים קטגוריית אחסון שאליה אפשר להעלות את הקבצים שנוצרו.
לוחצים על תפריט הניווט > Cloud Storage > Buckets ואז על CREATE BUCKET.
נותנים שם ייחודי לקטגוריה, משאירים את שאר ההגדרות לפי ברירת המחדל ולוחצים על Create.
אם מופיעה הודעה, לוחצים על Confirm בתיבת הדו שיח
Public access will be prevented.
לוחצים על Check my progress למטה כדי לבדוק את ההתקדמות בשיעור ה-Lab. אם הקטגוריה נוצרה, יופיע ציון בדיקה.
עכשיו אתם אמורים להיות במסוף Cloud ולראות את הקטגוריה החדשה של Cloud Storage שיצרתם.
לוחצים על UPLOAD FILES ובוחרים את קובץ ה-CSV שמכיל את
הנתונים של start_station_name.
עכשיו לוחצים על Open. חוזרים על הפעולות האלה גם לנתונים
של end_station_name.
לוחצים על סמל שלוש הנקודות שליד הקובץ start_station_name כדי
לשנות את השם שלו, ואז לוחצים על Rename. משנים את שם הקובץ
ל-start_station_data.csv.
לוחצים על סמל שלוש הנקודות שליד הקובץ end_station_name כדי
לשנות את השם שלו, ואז לוחצים על Rename. משנים את שם הקובץ
ל-end_station_data.csv.
הקבצים start_station_data.csv ו-end_station_data.csv
אמורים להופיע ברשימה Objects בדף
Bucket details.
לוחצים על Check my progress כדי לוודא שהשלמתם את המשימה. אם קובצי ה-CSV הועלו כאובייקטים לקטגוריה, יופיע ציון בדיקה.
פותחים את המסוף ולוחצים על תפריט הניווט > SQL.
לוחצים על CREATE INSTANCE > Choose MySQL .
כמזהה המכונה, כותבים my-demo.
בשדה Password כותבים סיסמה מאובטחת (וזוכרים אותה!).
בוחרים את הגרסה MySQL 5.8 למסד הנתונים.
ב-Choose a Cloud SQL edition, בוחרים באפשרות Enterprise.
ב-Preset, בוחרים באפשרות Development (4 vCPU, 16 GB RAM, 100 GB Storage, Single zone).
בשדה Multi zones (Highly available) בוחרים באפשרות
לוחצים על CREATE INSTANCE.
לוחצים על Check my progress למטה כדי לבדוק את ההתקדמות בשיעור ה-Lab. אם נוצרה מכונה של Cloud SQL, יופיע ציון בדיקה.
עכשיו, אחרי שיצרנו מכונה של Cloud SQL, ניצור בתוכה מסד נתונים באמצעות שורת הפקודה של Cloud Shell.
לוחצים על הסמל של Cloud Shell בפינה הימנית העליונה של המסוף כדי לפתוח אותו.
מריצים את הפקודה הבאה כדי להגדיר את מזהה הפרויקט בתור משתנה סביבה:
הפקודה הזאת מספקת קישור לפתיחה בדפדפן. פותחים את הקישור באותו דפדפן שבו נכנסתם לחשבון Qwiklabs. אחרי הכניסה לחשבון תקבלו קוד אימות שצריך להעתיק – הדביקו אותו ב-Cloud Shell.
my-demo למכונה, זכרו להחליף אותו בשם שבחרתם:
הפלט אמור להיראות כך:
כל מכונה של Cloud SQL כוללת מסדי נתונים שהוגדרו מראש, אבל כאן ניצור מסד נתונים משלנו שבו נאחסן את נתוני האופניים השיתופיים מלונדון.
bike, מריצים את הפקודה הבאה בשורת
הפקודה של MySQL:
הפלט הבא אמור להתקבל:
לוחצים על Check my progress כדי לוודא שהשלמתם את המשימה. אם נוצר מסד נתונים במכונה של Cloud SQL, יופיע ציון בדיקה.
בפקודה הזו השתמשנו במילת המפתח CREATE, אבל הפעם השתמשנו בתנאי
TABLE כדי לציין שאנחנו רוצים ליצור טבלה במקום מסד נתונים. במילת
המפתח USE מציינים לאיזה מסד נתונים רוצים להתחבר. עכשיו יש לכם
טבלה בשם london1 שמכילה שתי עמודות: start_station_name ו-num. החלק
VARCHAR(255) מציין את האורך המקסימלי של כל מחרוזת בעמודה – במקרה
שלנו, 255 תווים. החלק INT מציין שמדובר בעמודה מסוג מספרים שלמים.
הפלט הבא אמור להתקבל משתי הפקודות:
מכיוון שלא טענתם נתונים, מופיע הכיתוב empty set.
נחזור למסוף Cloud SQL. עכשיו נעלה את קובצי ה-CSV ששמרנו,
start_station_name ו-end_station_name, לטבלאות
החדשות שיצרנו, london1 ו-london2.
start_station_data.csv.
לוחצים על Select.
bike וכותבים את שם הטבלה
london1.
חוזרים על הפעולות האלה לקובץ ה-CSV הנוסף.
end_station_data.csv, ואחר כך לוחצים
על Select.
london2.
עכשיו שני קובצי ה-CSV אמורים להופיע בטבלאות שבמסד הנתונים bike.
בפלט אמורות להיות 955 שורות, אחת לכל שם של תחנה.
בפלט אמורות להיות 959 שורות, אחת לכל שם של תחנה.
עכשיו נכיר עוד כמה מילות מפתח של SQL שיכולות לעזור לנו בניהול נתונים. הראשונה
היא DELETE.
אחרי הרצת שתי הפקודות, הפלט הבא אמור להתקבל:
השורות שנמחקו היו הכותרות של העמודות בקובצי ה-CSV. למעשה, לא השתמשנו במילת
המפתח DELETE בפקודה כדי להסיר את השורה הראשונה בכל קובץ, אלא בכל
השורות בטבלה שבהן שם העמודה (num) הכיל ערך ספציפי (0). אם תריצו את
השאילתות SELECT * FROM london1; ו-SELECT * FROM london2;
ותגללו לראש הטבלה, תראו שהשורות האלה לא קיימות יותר.
אתם יכולים גם להוסיף ערכים לטבלאות באמצעות מילת המפתח
INSERT INTO.
start_station_name ואת המספר 1 לעמודה
num.
כשמשתמשים במילת המפתח INSERT INTO צריך לציין טבלה (london1).
הפקודה תיצור שורה חדשה עם עמודות לפי התנאים בסוגריים הראשונים (במקרה שלנו,
start_station_name ו-num). מה שבא אחרי התנאי VALUES יתווסף בתור ערכים לשורה
החדשה.
הפלט הבא אמור להתקבל:
עכשיו, אם נריץ את השאילתה SELECT * FROM london1; נראה שנוספה
שורה חדשה בתחתית הטבלה london1.
מילת המפתח האחרונה של SQL שנלמד עליה היא UNION. משתמשים במילת
המפתח הזו כדי לשלב בין הפלט של מספר שאילתות SELECT לפלט אחד של
תוצאות. במקרה שלנו, נשתמש ב-UNION כדי לשלב בין נתוני הטבלאות
london1 ו-london2.
בשאילתה הבאה נשלוף נתונים ספציפיים משתי הטבלאות ונשלב אותם בעזרת האופרטור
UNION.
בשאילתה הראשונה עם SELECT בחרנו את שתי העמודות מהטבלה london1,
ויצרנו לעמודה start_station_name את הכינוי top_stations. השתמשנו במילת המפתח
WHERE כדי לשלוף רק שמות של תחנות שבהן התחילו יותר מ-100,000
נסיעות באופניים שיתופיים.
בשאילתה השנייה עם SELECT בחרנו את שתי העמודות מהטבלה london2,
והשתמשנו במילת המפתח WHERE כדי לשלוף רק שמות של תחנות שבהן
הסתיימו יותר מ-100,000 נסיעות באופניים שיתופיים.
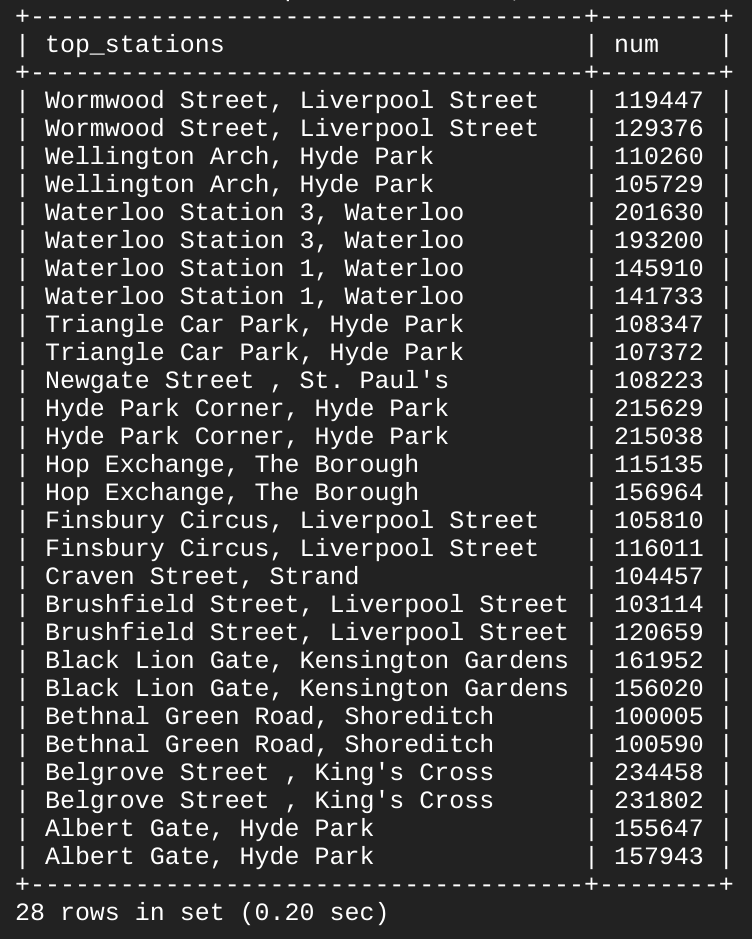
באמצעות מילת המפתח UNION שילבנו בין הנתונים מ-london2 ל-london1
לפלט אחד. מכיוון שאיחדנו בין הנתונים מ-london1 ל-london2, העמודות ייקראו
top_stations ו-num.
השתמשנו במילת המפתח ORDER BY כדי לסדר את השורות בטבלה הסופית לפי
סדר אלפביתי יורד של הערכים בעמודה top_stations.
הפלט הבא אמור להתקבל:
כמו שאפשר לראות, 13 מתוך 14 תחנות הן הכי פופולריות להתחלה ולסיום של נסיעות. השתמשתם בכמה מילות מפתח בסיסיות של SQL כדי להריץ שאילתה על מערך נתונים, לקבל נתונים ולענות על שאלות ספציפיות.
בשיעור ה-Lab הזה למדתם את היסודות של SQL, איך להשתמש במילות מפתח ואיך להריץ שאילתות ב-BigQuery וב-CloudSQL. למדתם גם את המושגים המרכזיים של פרויקטים, מסדי נתונים וטבלאות. תרגלתם שימוש במילות מפתח כדי להציג נתונים בדרכים שונות ולערוך אותם. למדתם איך לטעון מערכי נתונים ב-BigQuery ותרגלתם הרצת שאילתות על טבלאות. למדתם גם איך ליצור מכונות ב-Cloud SQL ותרגלתם העברת קבוצות של נתונים לטבלאות במסדי נתונים. לבסוף, הרצתם שאילתות ב-Cloud SQL וחיברתם ביניהן כדי להגיע לכמה מסקנות מעניינות בקשר לתחנות ההתחלה והסיום של נסיעות באופניים שיתופיים בלונדון.
זהו שיעור Lab ללימוד עצמי שהוא חלק מיחידות ה-Quest הבאות: Data Science on Google Cloud, Cloud SQL, BigQuery Basics for Data Analysts, NCAA® March Madness®: Bracketology with Google Cloud, Cloud Engineering, Data Catalog Fundamentals ו-Applying BQML's Classification, Regression, and Demand Forecasting for Retail Applications. יחידת Quest היא מסלול לימוד שבנוי מסדרה של שיעורי Lab. כאשר משלימים יחידת Quest מקבלים תג שמציין את ההישג. אתם יכולים להציג את התג או התגים באופן גלוי לכולם, ולקשר אליהם בקורות החיים שלכם באינטרנט או בחשבון במדיה חברתית. רוצים לקבל קרדיט מיידי על השלמת שיעור ה-Lab הזה? הירשמו לאחת מיחידות ה-Quest שמכילות אותו. בקטלוג של Google Skills מפורטת הרשימה המלאה של יחידות ה-Quest.
רוצים ללמוד עוד על Cloud SQL ו-BigQuery ולתרגל את השימוש בהם? תוכלו להמשיך לשיעורי ה-Lab הבאים של Google Skills:
למידע נוסף על מדעי הנתונים: Data Science on the Google Cloud Platform, 2nd Edition: O'Reilly Media, Inc..
יעזרו לכם להפיק את המרב מהאמצעים הטכנולוגיים של Google Cloud. השיעורים שלנו מכילים מיומנויות טכניות ושיטות מומלצות כדי שתוכלו להתחיל לעבוד מהר ולהמשיך ללמוד ולהתפתח. נציג את העקרונות הבסיסיים להכשרה ברמה מתקדמת, עם אפשרויות וירטואליות, שידורים חיים או על פי דרישה, בהתאם ללוח הזמנים העמוס שלכם. בעזרת ההסמכות תוכלו לאשר ולאמת את המיומנות והמומחיות שלכם באמצעים הטכנולוגיים של Google Cloud.
המדריך עודכן לאחרונה ידנית ב-6 באוקטובר 2023
שיעור ה-Lab נבדק לאחרונה ב-6 באוקטובר 2023
זכויות יוצרים 2026 Google LLC. כל הזכויות שמורות. Google והלוגו של Google הם סימנים מסחריים רשומים של Google LLC. שמות של חברות ומוצרים אחרים עשויים להיות סימנים מסחריים של החברות, בהתאמה, שאליהן הם משויכים.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one
Complete this quick step to start your lab.