
准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30
Create an incremental persistent derived table
/ 40
Create an aggregate table
/ 30
Join the minimal amount of views new Explores
/ 30

Looker 是 Google Cloud 中的现代化数据平台,支持您以交互方式分析和直观呈现数据。您可以使用 Looker 深入分析数据,整合来自不同数据源的分析洞见,构建切实可行的数据驱动型工作流,以及创建自定义数据应用。
复杂的查询可能成本高昂,重复运行这些查询会给数据库造成负担,从而降低性能。在理想情况下,对于大规模查询,如果查询内容没有发生任何变化,您应该避免重复运行。您可以将新数据附加到现有结果中,以减少重复请求。优化 LookML 查询性能的方法很多,本实验重点介绍在 Looker 中最常用的查询性能优化方法,包括:永久性派生表、汇总感知和高效联接视图。
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
准备就绪时,点击开始实验。
此时您会看到“实验详细信息”窗格,其中包含您在进行该实验时必须使用的临时凭据。
如果该实验需要付费,系统会打开一个弹出式窗口供您选择支付方式。
请注意,“实验详细信息”窗格中会显示实验凭据。您需要使用这些凭据来登录 Looker 实例以进行该实验。
点击打开 Looker。
在电子邮件地址和密码字段中输入提供的用户名和密码。
用户名:
密码:
点击登录。
登录成功后,您会看到用于本实验的 Looker 实例。
在本部分中,您将了解 Looker 中常用的查询性能优化方法。在本实验中,您将亲身体验前三种方法。
第一种解决方案是永久性派生表,简称 PDT。Looker 允许您将 SQL 和 LookML 查询作为临时表写入数据库。此表被缓存或持久化时,就变成了永久性派生表。这样,您就可以重复运行复杂或常用的查询,并缓存其结果,以便快速访问。
通过将这些查询保存为表,您可以控制何时或如何构建它们。例如,您可以在每天早上重建表,也可以每月重建一次,或者仅在添加了新数据时才重建。理想情况下,您应配置派生表来反映数据的性质。
派生表可用于创建底层数据库表中未提供的新结构或汇总,但并非所有派生表都需要持久化才能发挥作用。持久化通常适用于运行成本高昂的复杂查询,也适用于大量用户或应用频繁使用的查询。
您还可以创建增量 PDT,这样,您无需重建整个表即可添加新数据。对于现有(较早)数据不常更新的大型表,增量更新是一个非常有效的解决方案,因为这些表的主要更改是添加新记录。
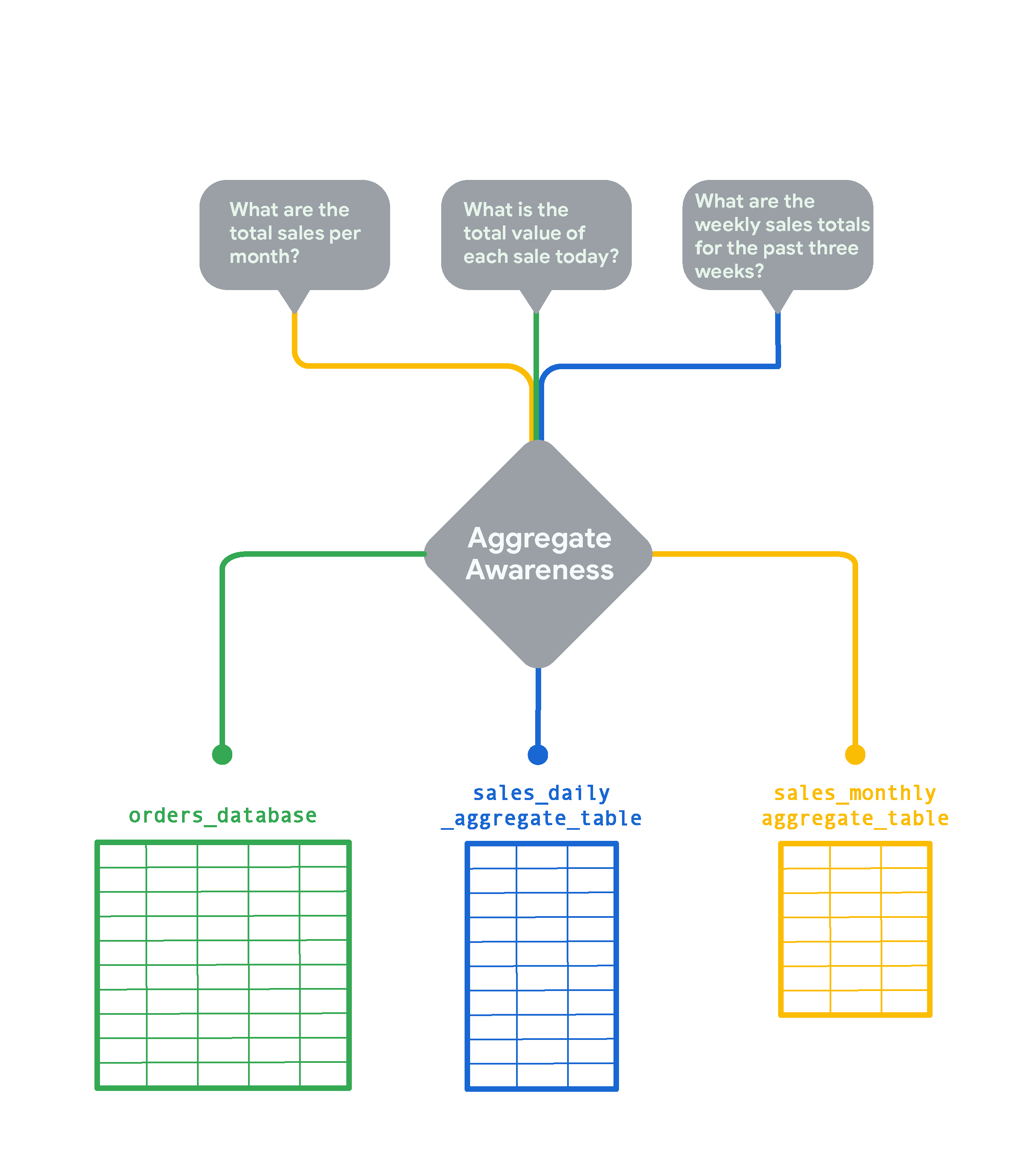
对于数据库中的超大型表,Looker 的汇总感知功能可以为其创建较小的汇总表,该表中包含按各种属性组合分组的数据。这些汇总表充当“汇总”或摘要表,Looker 可以在查询时尽可能使用它们来替代原始大型表。借助汇总感知功能,Looker 可以在数据库中找到最小、最有效的表来运行查询,同时仍保持准确性。经过战略性部署后,汇总感知功能可以将平均查询速度提高几个数量级。假设有一个繁忙的电子商务商店的在线订单表,每隔几秒钟就会添加几行新纪录。
如果您想实时跟踪订单状况,就需要更详细的数据;但如果您只想查看“每月总销售额”等月度趋势,那么查询月度汇总数据会更快速、更经济。在这种情况下,Looker 会创建并查询 sales_monthly_aggregate_table。
对于“今天每笔销售交易的总价值是多少”这样的问题,您需要精确到行级的精细订单数据。在这种情况下,Looker 将查询原始的 orders_database 表,而不进行任何汇总。如果您希望查看过去三周的每周销售总额,Looker 会创建并选择一个每日销售汇总表。此表比月度销售表更精细,但它是原始 orders_database 的汇总。
Looker 中的汇总感知功能通常用于汇总或总结多个时间段的数据。此外,汇总表必须在 Looker 实例中持久化,才能用于汇总感知。
优化性能的另一种方法是,在定义新探索时仅联接所需的视图。为了尽量减少联接,您可以定义多个探索来实现不同目的(例如,按用户查询数据、查询汇总销售数据)。此外,您应该使用基本字段作为主键,而不是使用串联字段。尽可能使用 many_to_one 联接:将视图从最精细的级别联接到最高细节级别 (many_to_one),通常可在 Looker 中提供最佳查询性能。
在探索定义中包含过滤条件可以优化性能,因为这能避免系统在默认情况下返回海量数据。Looker 有很多过滤选项,包括用户可见和可修改的过滤条件,例如 always_filter 和 conditionally_filter。您还可以修改探索中字段的过滤条件建议。如需了解详情并练习使用探索过滤条件,请尝试完成实验使用 LookML 过滤探索数据。
为了减少数据库查询流量,您应尽可能最大程度利用缓存,并尽可能使其与您的 ETL(提取、加载和转换)政策保持同步。默认情况下,Looker 会将查询缓存一小时。您可以使用 persist_with 参数在探索中应用数据组,从而控制缓存政策,并使 Looker 数据刷新与您的 ETL 流程同步。这样,Looker 就可以与后端数据流水线更紧密地集成,从而最大程度利用缓存,同时避免分析过时数据的风险。
例如,某些数据表可能每天才更新一次,在这种情况下,每小时刷新一次缓存并不能带来任何实际价值。在本实验中,您将使用 Looker 中用于自定义缓存的各种选项(包括数据组或缓存政策),使派生表持久化。如需了解详情并练习缓存政策,请尝试完成实验LookML 中的缓存和数据组。
根据您的具体数据库方言,您可以探索其他查询优化功能,例如 cluster_keys 和 indexes。
如前所述,永久性派生表 (PDT) 是一种派生表,它会写入数据库中的底层存储架构,并按照您使用持久性策略指定的计划重新生成。PDT 非常有用,因为当用户请求表中的数据时,该表通常已存在,这可以减少查询时间和数据库负载。
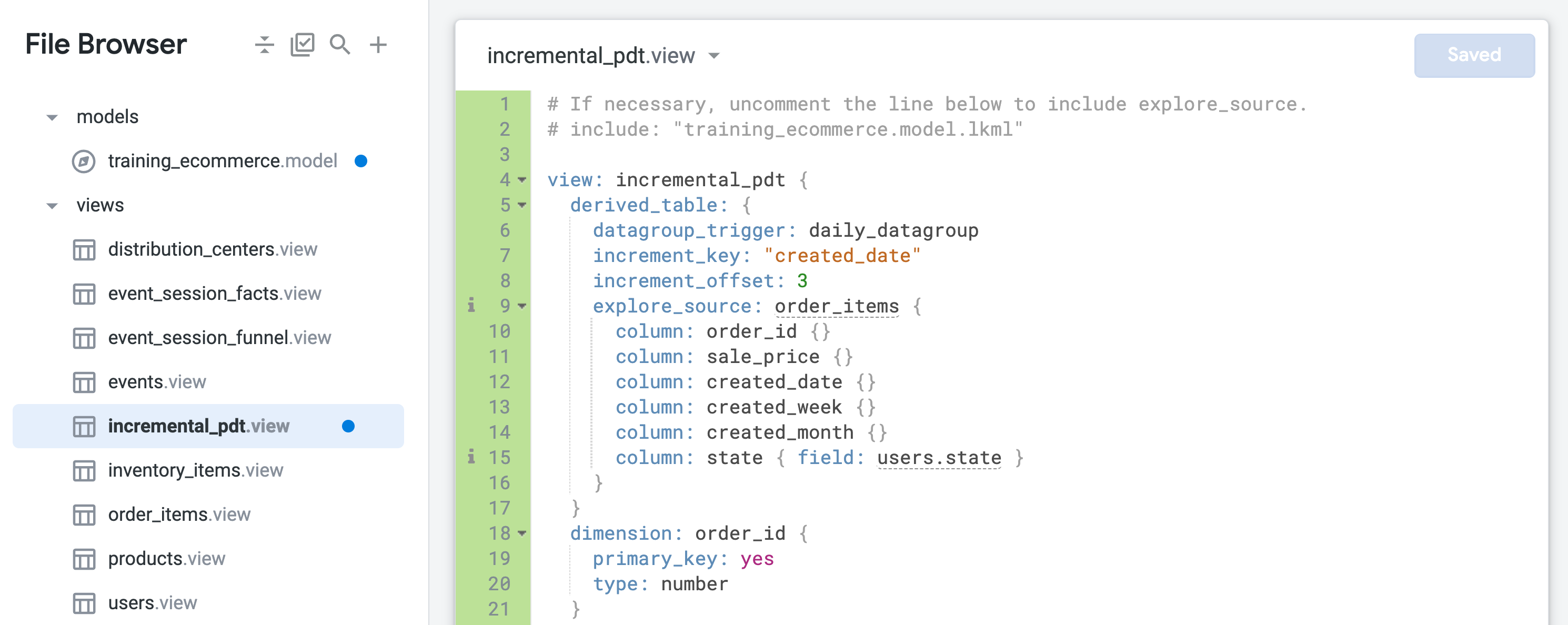
在标准 PDT 中,系统会根据其缓存政策中设置的时间表重建整个表。与之相比,增量 PDT 只会将最新数据添加到现有表中。这可以大大减小发送到数据库的查询规模。
在此任务中,您将创建一个原生派生表 (NDT),以便按时间范围或州/省汇总订单数据。您还可以通过每日刷新来启用持久化功能,并使用回溯 3 天的增量更新来检索延迟数据。
点击切换按钮进入开发模式。
依次点击探索 > Order Items(订购商品数)。
在 Order Items > Dimensions(订购商品数 > 维度)下,选择以下项:
在用户 > 维度下,选择 State(州/省)。
点击运行。
点击设置图标 (
选择获取 LookML。
在派生表标签页上,将 LookML 代码复制到文本编辑器中。
您将使用此代码为原生派生表创建一个新视图。
在新浏览器标签页中打开新的 Looker 窗口。
在开发菜单中,点击 qwiklabs_ecommerce。
点击文件浏览器旁边的加号图标 (+),然后选择创建视图。
将新文件命名为 incremental_pdt,然后点击创建。
在文件浏览器中,点击 incremental_pdt.view,并将其拖动到 views 文件夹下。
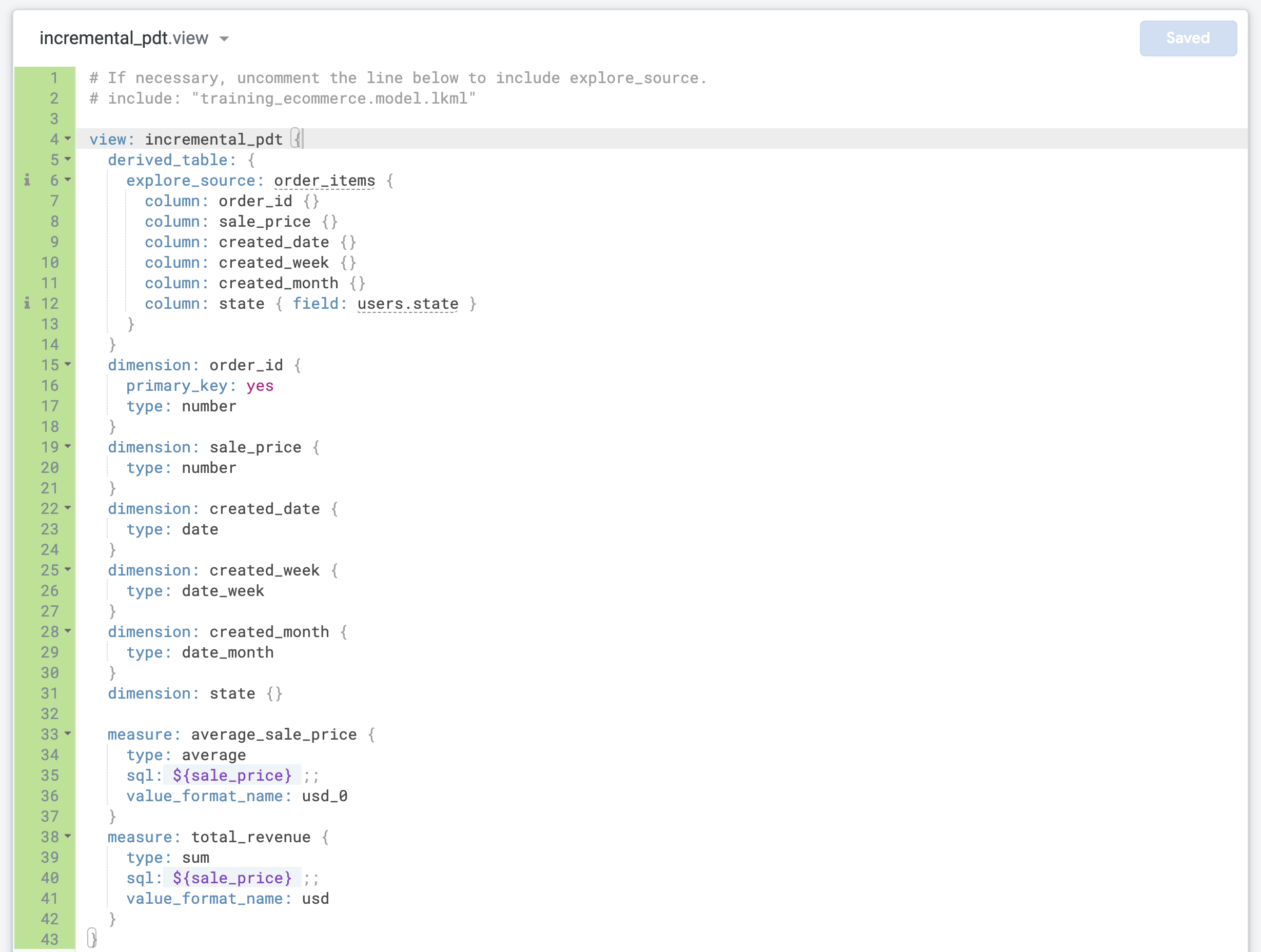
将 incremental_pdt.view 中的默认 LookML 代码替换为您之前复制的本地派生表的代码。
将第 4 行更新为正确的视图名称 (incremental_pdt)。
更新 order_id 维度,将其定义为视图的 primary_key:
这是因为每条记录都代表一个具有唯一 order_id 的订单。
}) 之前添加两个新度量:打开 training_ecommerce.model。
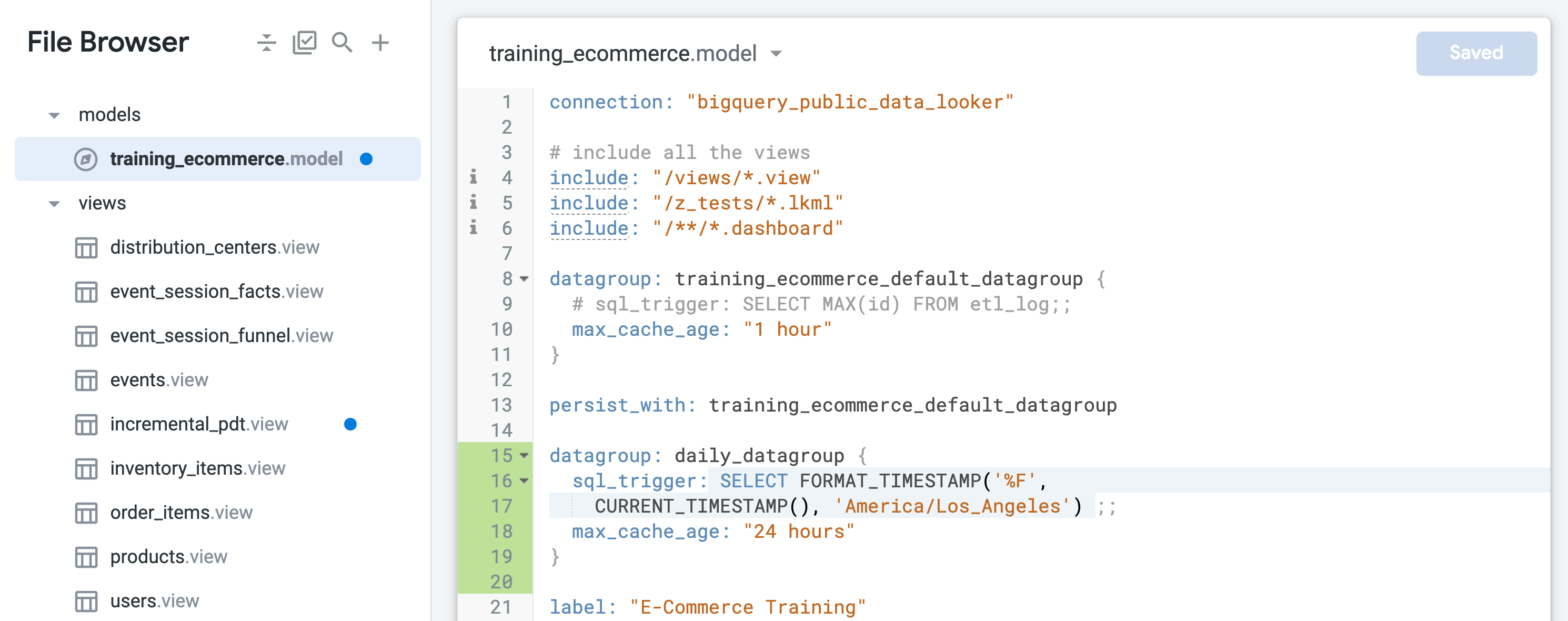
找到名为 training_ecommerce_default_datagroup 的默认数据组,并添加一行新内容(第 13 行)。
定义一个新数据组,并通过每日刷新(最长 24 小时)来持久化对象:
sql_trigger 会检查当前日期,并在日期发生变化时触发刷新,而 max_cache_age 可确保即使 sql_trigger 未成功运行,该表也会在 24 小时后重建。
training_ecommerce.model 的末尾(大约在第 67 行),定义一个仅包含 incremental_pdt 视图的新探索,以便在后续步骤中对其进行测试:现在,永久性派生表将持久化,并每天重建一次,从而回溯 3 天以捕获可能发生了延迟的订单。
在浏览器标签页中打开新的 Looker 窗口。
依次点击探索 > 增量 PDT。
在“数据”窗格中,打开 SQL 标签页。
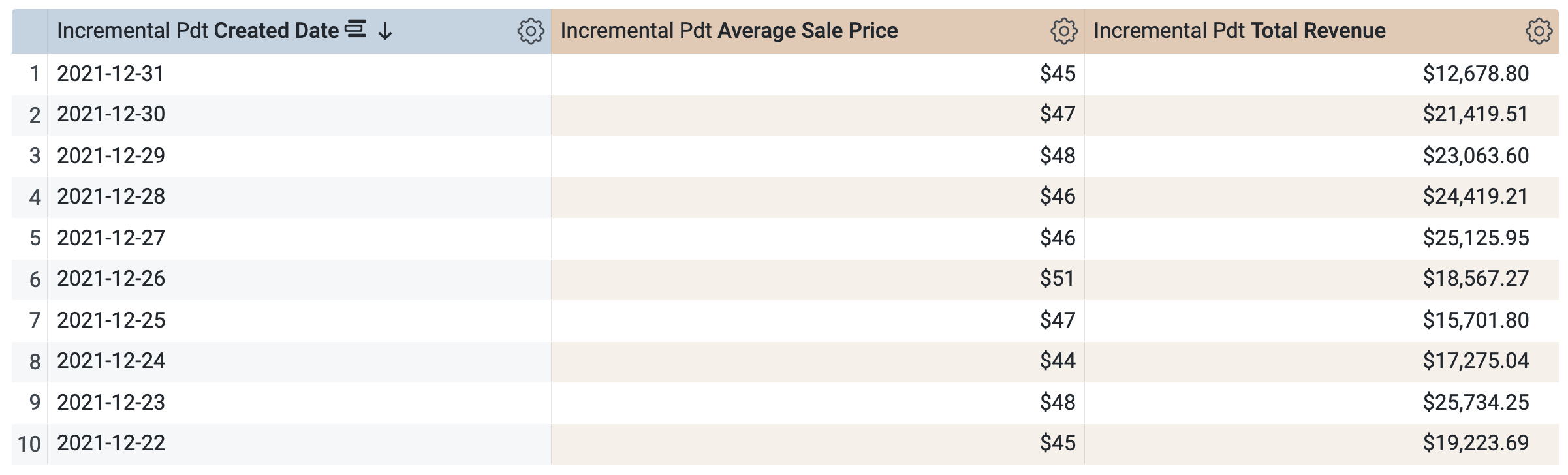
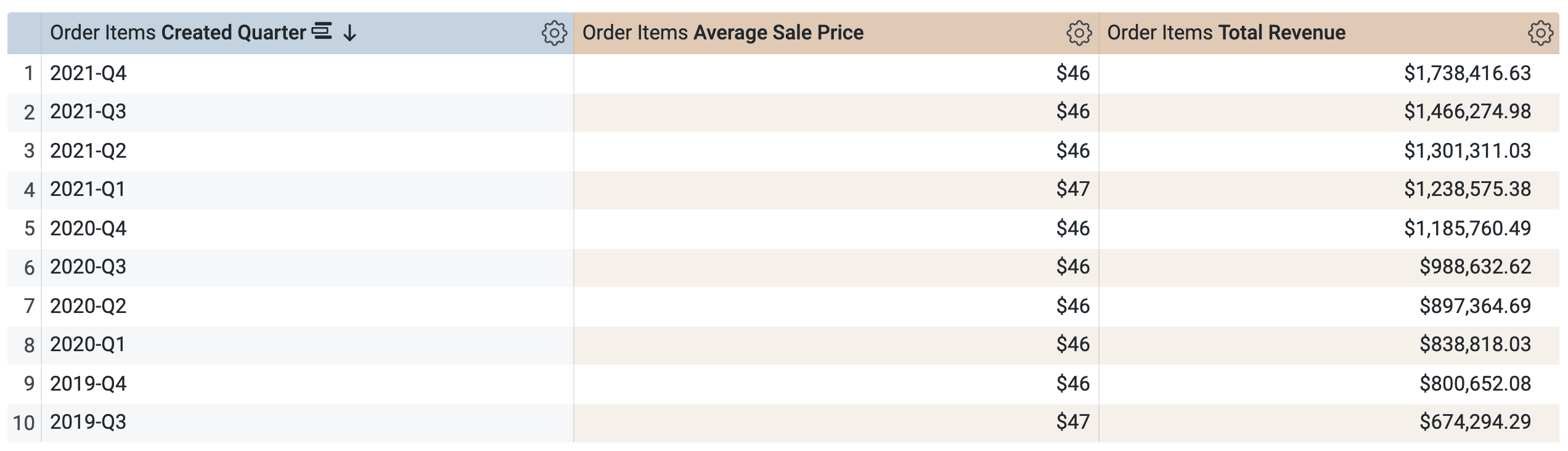
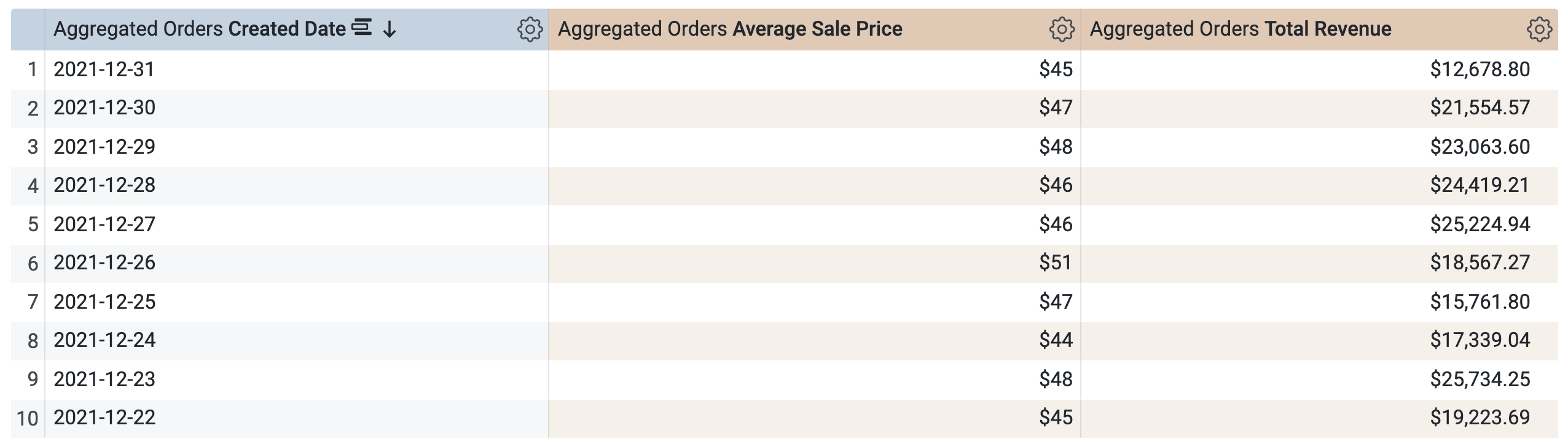
在增量 PDT > 维度下,选择创建日期。
在增量 PDT > 度量下,选择 Average Sale Price(平均售价)和 Total Revenue(总收入)。
在运行查询之前,请注意 SQL 窗口中有两条查询(可能需要几秒钟才能加载完成)。第一个查询将生成名为 incremental_pdt 的 PDT,第二个查询会从新创建的 PDT 中检索结果。
点击运行。
打开结果标签页以查看结果。
在增量 PDT > 维度下:
在“数据”窗格中,打开 SQL 标签页。
请注意,该查询将使用同一 PDT 来检索结果,这是有道理的,因为您请求的时间范围已在 PDT 中定义(并缓存)。不过请注意,您无法选择和运行 PDT 中未包含的其他时间范围(例如“季度”或“年份”)的查询。
点击运行。
打开结果标签页以查看结果。
关闭探索查询的浏览器标签页,然后返回包含 Looker IDE 的浏览器标签页。
点击验证 LookML。
应该没有 LookML 错误。
点击验证 LookML,然后点击提交更改并推送。
添加提交消息,然后点击提交。
最后,点击部署到生产环境。
在开始下一项任务时,请继续留在 Looker IDE 的浏览器标签页中。
点击检查我的进度以验证是否完成了以下目标:
在 Looker 中,您可以创建战略性汇总表,以最大程度减少对数据库中大型表执行查询的次数。汇总表必须在数据库中持久化,以便访问它们来实现汇总感知。因此,汇总表是一种永久性派生表 (PDT)。
汇总表使用 LookML 项目中探索参数下的 aggregate_table 参数进行定义。创建汇总表后,您可以在探索中运行查询,以便查看 Looker 使用了哪些汇总表。Looker 使用汇总感知逻辑在数据库中查找最小、最有效的可用汇总表,从而运行查询,同时仍保持正确性。
在此任务中,您将重新创建上一个任务中的增量 PDT,并将其作为新的增量汇总表。您还可以对现有“订购商品数”探索使用优化功能,以便让用户可以使用新的汇总表。
在 Looker IDE 页面中,打开 training_ecommerce.model。
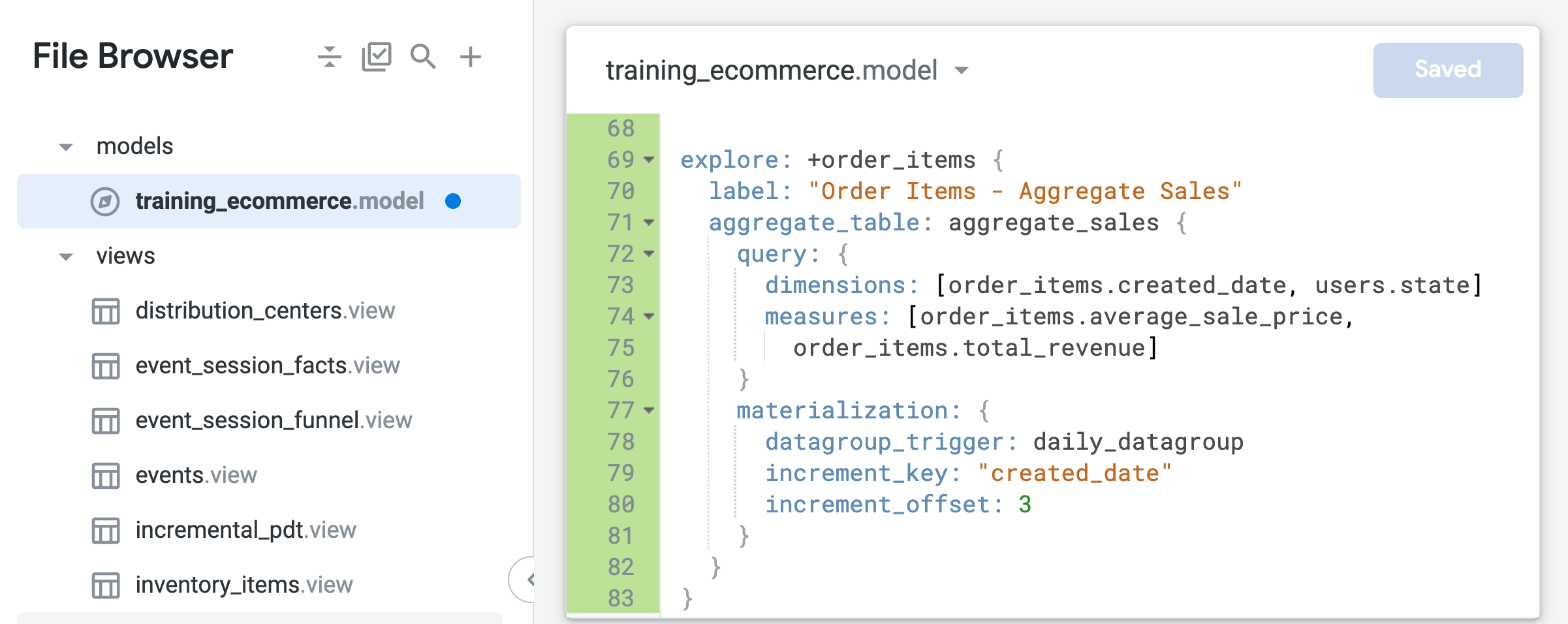
在该文件的末尾(大约在第 69 行),添加以下代码来创建 order_items 的优化版本:
此优化版本以模型文件中定义的现有 order_items 探索为基础,并添加新 LookML 代码中指定的修改,例如标签或您将在后续步骤中添加的汇总表。
请注意,与您在上一个任务中创建的原生派生表不同,汇总表中指定的唯一时间维度是 created_date。借助汇总感知功能,Looker 可以利用这一个表来处理探索查询,请求按时间汇总的平均销售价格或总收入,而无需考虑请求的时间范围(日、月、年)。
请勿关闭此标签页,Looker IDE 稍后会用到。
在浏览器标签页中打开新的 Looker 窗口。
依次点击 Explore > Order Items - Aggregate Sales(探索 > 订购商品数 - 汇总销售额)。
在“数据”窗格中,打开 SQL 标签页。
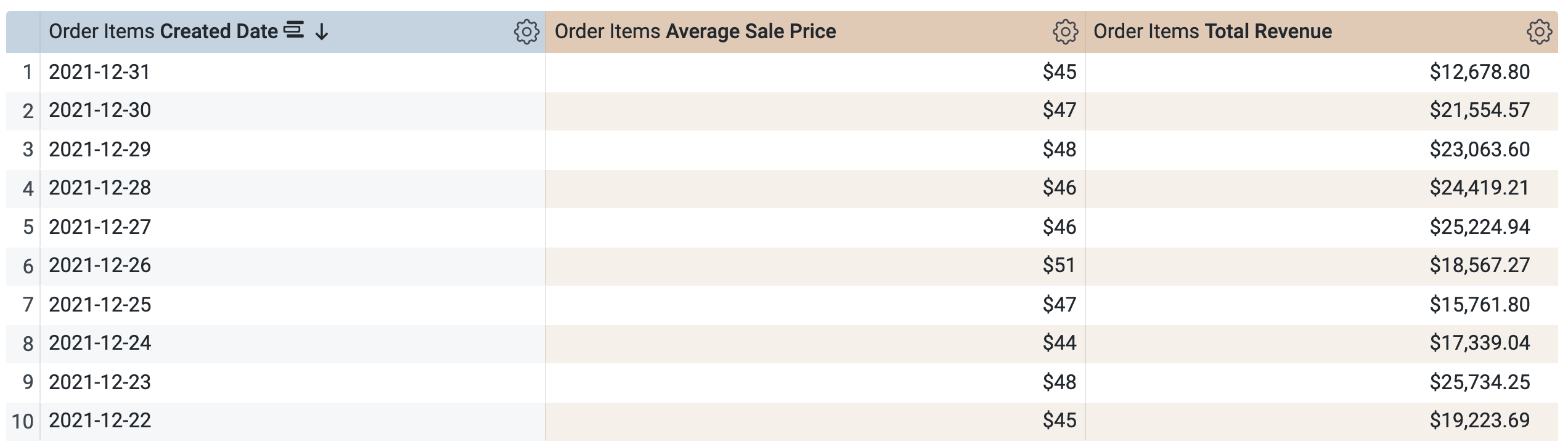
在 Order Items > Dimensions(订购商品数 > 维度)下,选择创建日期 > 日期。
在 Order Items > Measures(订购商品数 > 度量)下,选择 Average Sale Price(平均售价)和 Total Revenue(总收入)。
在运行查询之前,请注意有两个查询,与任务 1 中的 SQL 窗口类似。第一个查询会生成名为 aggregate_sales 的 PDT,第二个查询会从这个新 PDT 中检索结果。
点击运行。
打开结果标签页以查看结果。
在 Order Items > Dimensions > Created Date(订购商品数 > 维度 > 创建日期)下:
在“数据”窗格中,打开 SQL 标签页。
请注意,该查询将使用同一 PDT (aggregate_sales) 来按季度检索结果。Looker 会应用汇总感知功能,将“平均售价”和“总收入”汇总到“创建日期”下您所请求的时间范围内。
点击运行。
打开结果标签页以查看结果。
关闭探索查询的浏览器标签页,然后返回包含 Looker IDE 的浏览器标签页。
点击验证 LookML。应该没有 LookML 错误。
点击验证 LookML,然后点击提交更改并推送。
添加提交消息,然后点击提交。
最后,点击部署到生产环境。
在开始下一项任务时,请继续留在 Looker IDE 的浏览器标签页中。
点击检查我的进度以验证是否完成了以下目标:
高效联接是在 Looker 中定义高性能探索的关键组成部分。为了提高联接效率,请确保仅联接定义探索所需的视图,使用基本字段(而不是串联字段)作为视图的主键,并尽可能使用 many_to_one 联接。
如文档中所述,主键为视图中的记录提供唯一标识符,这对 Looker 中的准确汇总和关系至关重要。视图的主键是包含唯一值的字段(例如 ID 列),在视图文件中使用参数 primary_key: yes 进行标识。
在本部分中,您首先要确定最适合用作视图主键的列。然后,您需要为汇总表定义一个仅联接 users 视图的新探索,并使用 from 参数将 order_items 指定为探索的基本视图,然后联接 users 视图。最后,您省略了现有订购商品数探索中包含的额外联接,并使用 many_to_one 联接关系来提高查询效率。
在 users.view 中,ID 列已使用 primary_key: yes 标识为主键。这是一个包含唯一值(每个用户有一个 ID)的基本字段,而不是由多个列串联而成的字段。因此,ID 最适合作为 users 视图主键,它支持高效联接。
order_item_id 基于 order_items 表中的 ID 列,并被标识为主键。不过,此视图中的其他 ID 字段也可能是该表的唯一键,包括 order_id,该字段基于 order_items 表中的 order_id 列。
在接下来的步骤中,您将在 SQL Runner 中探索 order_items 表,以确定为什么 order_item_id 最适合用作主键。
在新浏览器标签页中打开新的 Looker 窗口。
依次点击开发 > SQL Runner。
点击“连接”旁边的设置 (
“项目”框现在为空。输入 cloud-training-demos,然后按 Enter 键。
在“数据集”字段中,选择 looker_ecomm。
系统会列出此 BigQuery 数据集中的可用表。
检查某列是否适合作为主键的一种方便快捷的方法是,将表中的“记录数”与列中的“不同值数”进行比较。如果这两个计数相匹配,则说明该列包含的是唯一值,适合作为表的主键。
user_id 列是否适合作为主键,请将以下查询添加到 SQL 查询窗口中,然后点击运行:order_id、inventory_item_id 和 id 列重复执行此查询。在本例中,id 和 inventory_item_id 都与表中的记录数相匹配,因为它们是订单中同一商品的不同 ID。因此,两者都有可能用作主键。
之所以选择 id 列作为 order_items 表的主键,是因为它是 order_items 表中商品的生成 ID,而 inventory_item_id 是 inventory_items 表中同一商品的 ID。
打开 training_ecommerce.model。
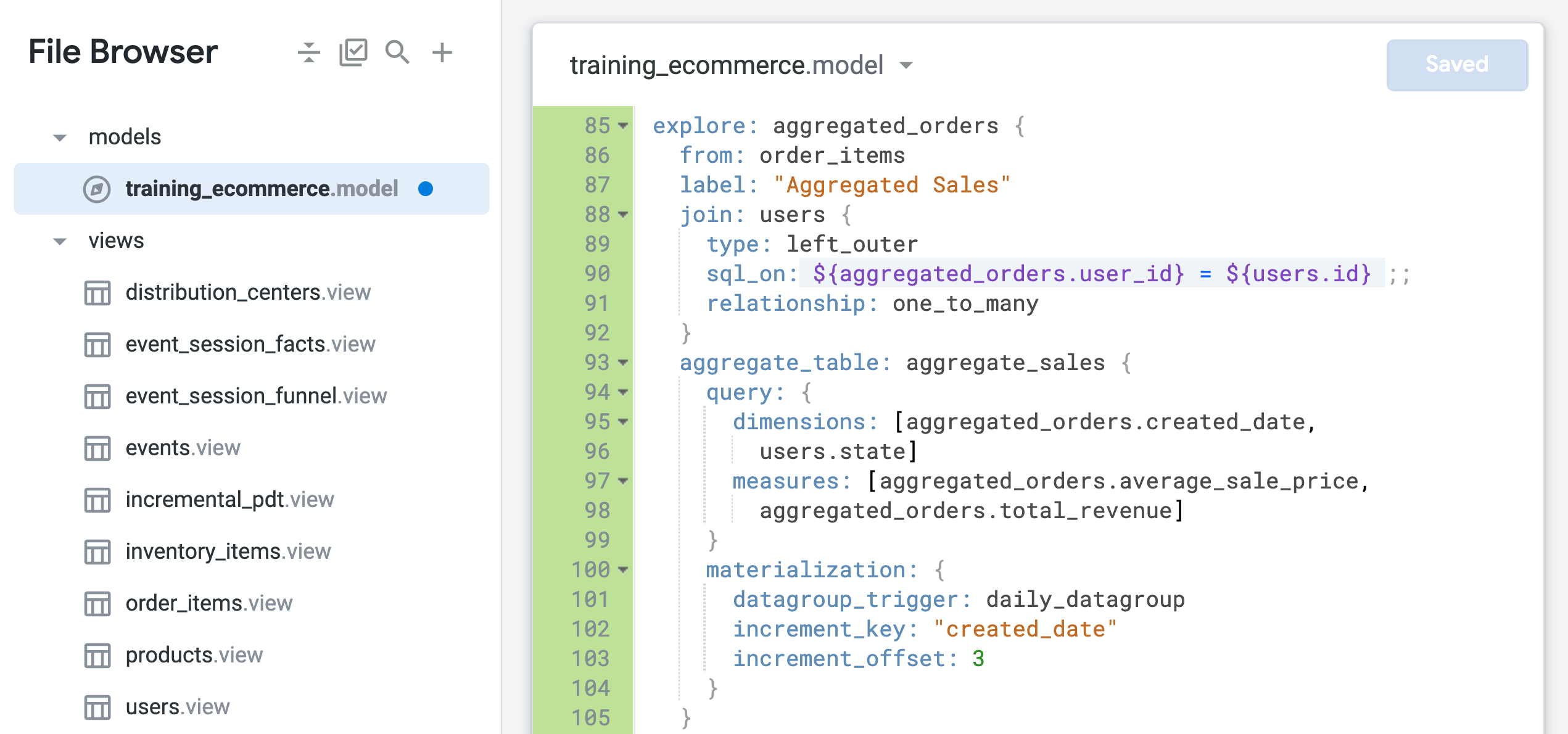
查看现有的 order_items 探索。
请注意,它包含四个不同的联接,每个联接都使用 many_to_one 关系类型。根据具体应用场景,您可能需要所有这些联接。但是,如果您只需要按州/省或时间范围汇总的用户和订单数据,该怎么办?如果是这样,您实际上永远不会使用这些额外的联接,而且这些联接会减慢探索的查询速度。
在接下来的步骤中,您将创建一个新探索,该探索仅联接订单数据和用户数据,联接依据是 order_items 视图中的 user_id 和 users 视图中的 id。
order_items 将作为基本视图,并且仅联接了 users 视图:from 参数用于将 order_items 指定为探索的基本视图,users 视图将联接到该视图。order_items 视图中的字段现在使用新探索名称 aggregated_orders.fieldname 来标识。
另请注意,users 视图与 order_items 视图之间的关系目前被识别为 one_to_many。在接下来的步骤中,您将测试这种基于 one_to_many 关系的联接是否是此探索的最佳配置。
在新浏览器标签页中打开新的 Looker 窗口。
依次点击探索 > Aggregated Sales(汇总销售额)。
在“数据”窗格中,打开 SQL 标签页。
在 Aggregated Orders > Dimensions(汇总订单 > 维度)下,选择创建日期 > 日期。
在 Aggregated Orders > Measures(汇总订单 > 度量)下,选择:
在运行查询之前,请注意,由于联接扇出问题,汇总表未被使用:
如果联接时未正确识别两个表之间的关系,则可能会发生意外扇出的问题。在本例中,探索的基本视图是 order_items,其中可能包含一个用户的多个订单。不过,users 视图中的每个用户只有一条记录。
因此,此联接实际上应定义为 many_to_one 关系,即多个订单对应一个用户,而不是一个订单对应多个用户。(如需详细了解扇出问题,请访问 Looker 帮助中心。)
点击运行。
打开“结果”标签页。
结果已返回,但 Looker 并未使用高效的汇总表来检索结果。
将此浏览器标签页保持打开状态,然后返回到包含 Looker IDE 的浏览器标签页。
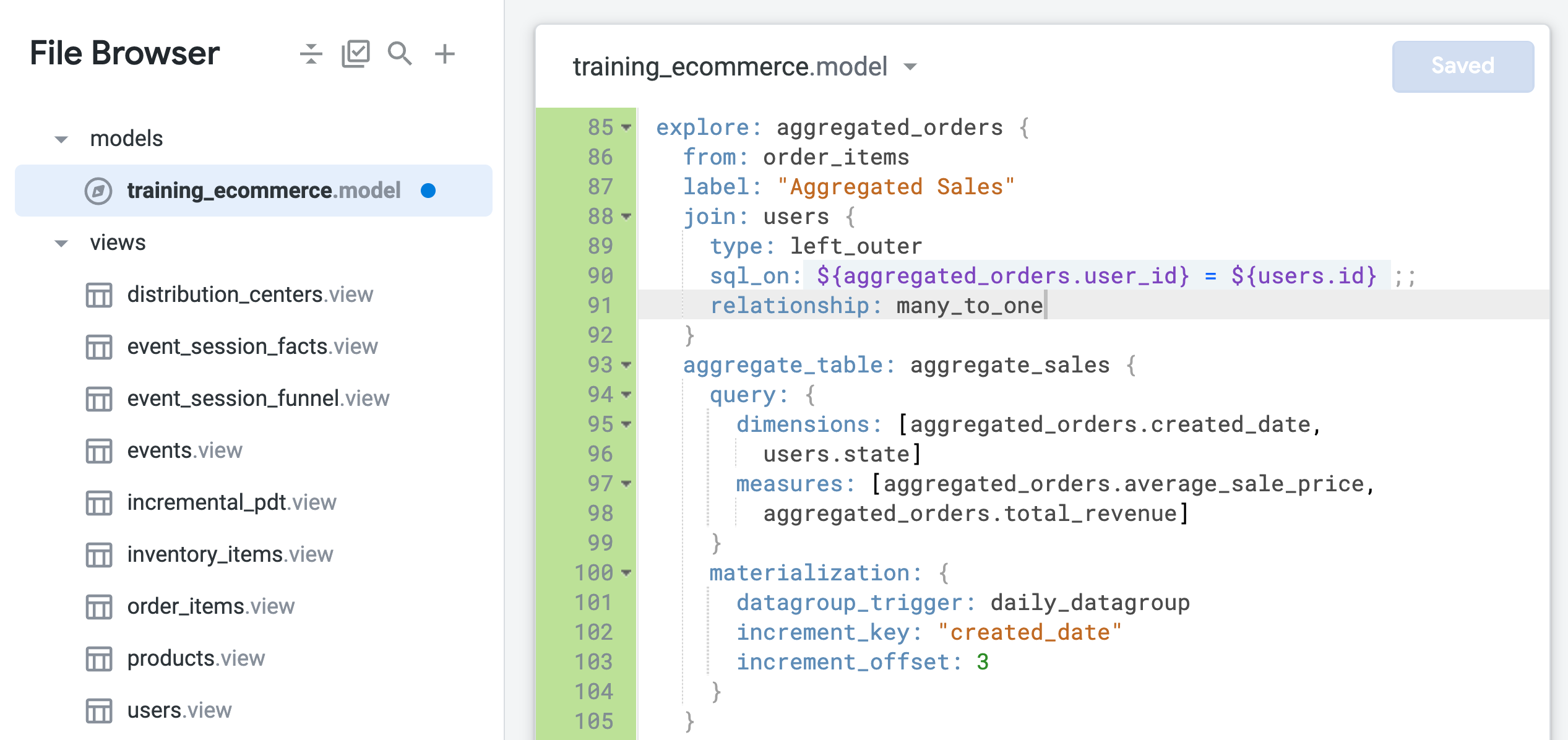
在 aggregated_orders 探索中,将关系参数更新为 many_to_one(第 91 行):
返回到探索查询的浏览器标签页,然后刷新页面。
在“数据”窗格中,打开 SQL 标签页。
与任务 1 和任务 2 的 SQL 标签页类似,现在有两个查询:第一个用于生成 PDT,第二个用于从 PDT 中检索结果。
关闭探索查询的浏览器标签页,然后返回包含 Looker IDE 的浏览器标签页。
点击验证 LookML。
应该没有 LookML 错误。
点击验证 LookML,然后点击提交更改并推送。
添加提交消息,然后点击提交。
最后,点击部署到生产环境。
在开始下一项任务时,请继续留在 Looker IDE 的浏览器标签页中。
点击检查我的进度以验证是否完成了以下目标:
Looker 允许通过“管理”菜单的“永久性派生表”页面监控 Looker 实例中 PDT 的构建。根据 Looker 配置,即使没有完整管理菜单的访问权限,拥有永久表权限的 Looker 用户也可以查看此页面。您可以在开发环境和生产环境中检查 PDT 的状态、构建时间和缓存,以便在 Looker 实例中轻松测试和监控 PDT。
在此任务中,您将监控本实验中创建的 PDT 的状态、构建时间、缓存以及生产与开发情况。从 NDT 创建的增量 PDT(任务 1)的构建时间应该最长,而汇总表(任务 2 和任务 3)的构建时间应该最短。这是因为它们使用了相同的表定义,但却包含在配置不同的探索中。您还将修改正在开发的 PDT,并在推送到生产环境前后监控其状态。
在新浏览器标签页中打开新的 Looker 窗口。
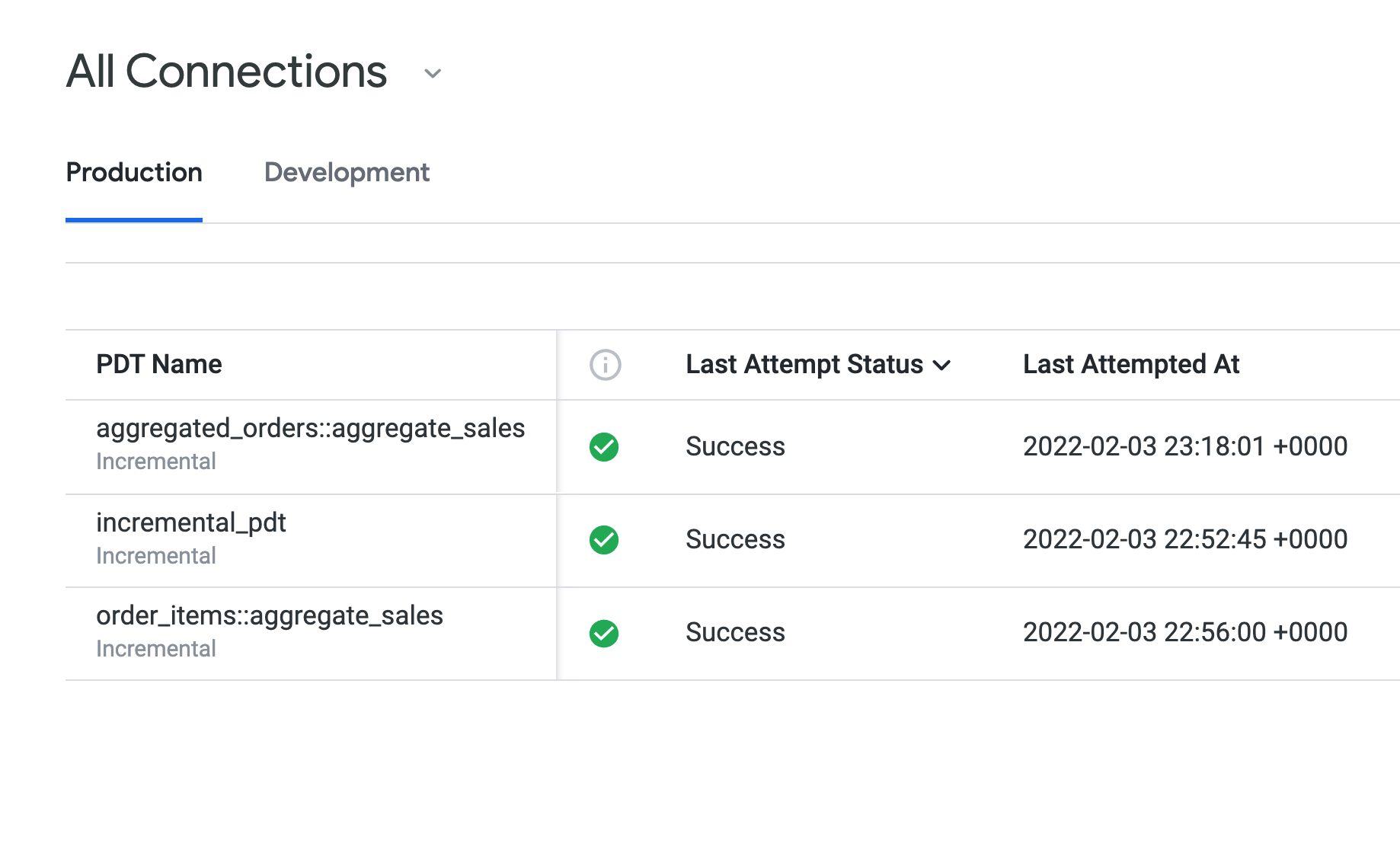
依次点击管理 > 永久性派生表。
“开发”标签页中未列出任何 PDT,因为您的所有 PDT 都已推送到生产环境。
打开生产标签页,查看您在任务 1-3 中创建的 PDT。
Last Attempt Status(上次尝试状态)显示所有 PDT 的状态均为 Success(成功),并且它们都使用相同的持久性规则 (daily_datagroup)。对于“上次构建时长”下的构建时间,incremental_pdt 的构建时间可能比两个汇总表稍长。
在开始执行后续步骤时,请不要关闭此永久性派生表页面。
返回包含 Looker IDE 的浏览器标签页。
打开 training_ecommerce.model。
向 aggregated_orders 探索添加 users.country 的新维度(大约在第 96 行):
点击保存更改。
返回永久性派生表页面,然后刷新该页面。
在“生产”标签页中,aggregated_orders::aggregate_sales PDT 仍显示为已构建,即使您在开发模式下修改了该 PDT 的 LookML 代码。
Looker 允许开发者在开发模式下测试对 PDT 的更改,这与开发者在开发模式下处理其他 Looker 对象的方式类似。例如,当开发者在开发模式下创建新维度和度量时,这些新对象不会在生产环境中显示,而是等到开发者提交更改并将其部署到生产环境中后才会显示。
请保持永久性派生表页面处于打开状态,并在新的浏览器标签页中打开新的 Looker 窗口。
依次点击探索 > Aggregate Sales(汇总销售额)。
在“数据”窗格中,打开 SQL 标签页。
在用户 > 维度下,选择国家/地区。
在 Aggregated Orders > Measures(汇总订单 > 度量)下,选择:
SQL 标签页中有两个查询:第一个查询用于生成 PDT,第二个查询用于从新建的 PDT 中检索结果。
点击运行。
打开“结果”标签页以查看结果。
关闭探索查询的浏览器标签页,返回到包含永久性派生表页面的浏览器标签页,然后刷新该页面。
“开发”标签页现在显示 aggregated_orders::aggregate_sales 已成功构建。
将浏览器标签页中的“永久性派生表”页面保持打开状态,然后返回到包含 Looker IDE 的浏览器标签页。
点击验证 LookML。
没有 LookML 错误。
点击验证 LookML,然后点击提交更改并推送。
添加提交消息,然后点击提交。
最后,点击部署到生产环境。
返回到包含“永久性派生表”页面的浏览器标签页,然后刷新该页面。现在,对生产环境的更改已部署完毕,aggregated_orders::aggregate_sales PDT 不再列在“开发”标签页中,而是仅列在“生产”标签页中。
在本实验中,您学习了何时以及如何向派生表添加持久性更新和增量更新,如何使用汇总感知功能,如何以高性能的方式联接视图,以及如何监控 PDT 的构建来优化 Looker 查询。
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 4 月 23 日
上次测试实验的时间:2023 年 10 月 6 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验