GSP985

Visão geral
O Looker é uma plataforma de dados moderna no Google Cloud que você pode usar para analisar e visualizar dados de forma interativa. Ele pode ser usado para fazer análises de dados detalhadas, integrar insights entre diferentes fontes de dados, gerar fluxos de trabalho úteis orientados por dados e criar aplicativos de dados personalizados.
Consultas complexas podem ser caras, e executá-las repetidamente sobrecarrega seu banco de dados, reduzindo o desempenho. O ideal é evitar a nova execução de consultas massivas se nada mudou e, em vez disso, adicionar ao final novos dados aos resultados atuais para reduzir solicitações repetitivas. Embora haja muitas maneiras de otimizar o desempenho das consultas do LookML, este laboratório se concentra nos métodos mais usados para otimizar o desempenho das consultas no Looker: tabelas derivadas permanentes, reconhecimento de agregados e junção eficiente de visualizações.
Atividades deste laboratório
- Entender quando e como adicionar persistência e atualizações incrementais a tabelas derivadas.
- Usar a consciência agregada para otimizar consultas em dados resumidos ou consolidados.
- Criar um refinamento de uma Análise existente.
- Juntar as visualizações de maneira eficiente para otimizar as consultas da Análise.
- Monitorar as criações de tabelas derivadas persistentes em uma instância do Looker.
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O cronômetro começa ao clicar em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça, depois de começar, não será possível pausar o laboratório.
Observação: não use seu projeto ou conta pessoal do Google Cloud neste laboratório para evitar cobranças extras.
Como iniciar o laboratório e fazer login no Looker
-
Quando tudo estiver pronto, clique em Começar o laboratório.
O painel "Detalhes do laboratório" aparece com as credenciais temporárias que você precisa usar neste laboratório.
Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Confira suas credenciais do laboratório no painel "Detalhes do laboratório". É com elas que você vai fazer login na instância do Looker neste laboratório.
Observação: se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Clique em Abrir o Looker.
-
Digite o nome de usuário e a senha fornecidos nos campos E-mail e Senha.
Nome de usuário:
{{{looker.developer_username | Username}}}
Senha:
{{{looker.developer_password | Password}}}
Importante: é necessário usar as credenciais do painel "Detalhes do laboratório" nesta página. Não use suas credenciais do Google Cloud Ensina. Se você tiver uma conta pessoal do Looker, não a use neste laboratório.
-
Clique em Fazer login.
Depois de se conectar, você verá a instância do Looker deste laboratório.
Principais recomendações para otimizar o desempenho da consulta
Nesta seção, você vai conhecer os métodos mais usados para otimizar o desempenho das consultas no Looker. Neste laboratório, você vai aprender na prática os três primeiros métodos.
Tabelas derivadas persistentes (TDPs)
A primeira solução são as tabelas derivadas persistentes (TDPs). O Looker permite que você escreva consultas SQL e LookML no seu banco de dados como uma tabela temporária. Quando essa tabela é armazenada em cache ou persistida, ela é chamada de TDP. Isso permite executar repetidamente consultas complexas ou usadas com frequência e armazenar os resultados em cache para acesso rápido.
Ao salvar essas consultas como uma tabela, você tem controle sobre quando ou como elas são criadas. As tabelas podem ser recriadas todas as manhãs, uma vez por mês ou apenas quando novos dados são adicionados. O ideal é configurar as tabelas derivadas para refletir a natureza dos dados.
As tabelas derivadas são úteis para criar estruturas ou agregações que ainda não estão disponíveis nas tabelas do banco de dados, mas nem todas as tabelas derivadas precisam ser persistidas para serem úteis. A persistência é aplicada com frequência a consultas complexas que são caras para executar ou a consultas que são usadas com frequência por um grande número de usuários ou aplicativos.
Você também pode criar TDPs incrementais para adicionar ao final novos dados sem recriar a tabela inteira. A aplicação de mudanças incrementais funciona bem para tabelas grandes em que os dados existentes (mais antigos) não são atualizados com frequência, porque a principal atualização da tabela são novos registros.
Reconhecimento agregado
Para tabelas muito grandes no seu banco de dados, o reconhecimento agregado do Looker pode criar tabelas agregadas menores de dados agrupados por várias combinações de atributos. As tabelas agregadas atuam como "resumos" ou tabelas de resumo que o Looker pode usar em vez da tabela grande original para consultas sempre que possível. O reconhecimento agregado permite que o Looker encontre a tabela menor e mais eficiente disponível no seu banco de dados para executar uma consulta, mantendo a acurácia. Quando implementada de forma estratégica, o reconhecimento agregado pode acelerar a consulta média em ordens de magnitude. Considere uma tabela de pedidos on-line para uma loja de e-commerce movimentada, que tem novas linhas adicionadas a cada poucos segundos.
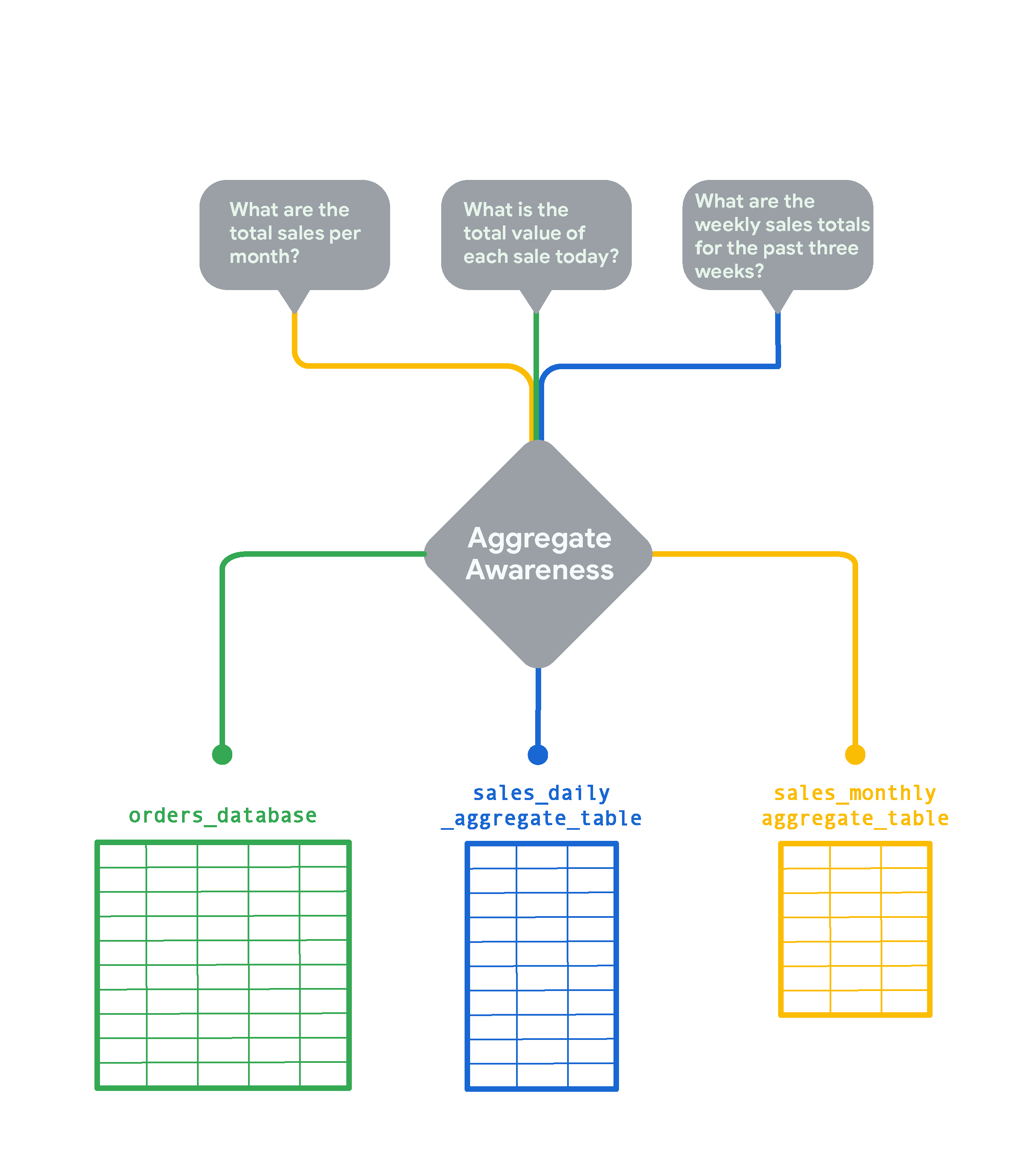
Se você quiser acompanhar pedidos em tempo real, será necessário um nível maior de detalhes. Mas se quiser analisar tendências mensais, como "Total de vendas por mês", analisar um resumo mensal dos dados é muito mais rápido e econômico. Nesse caso, o Looker cria e consulta a sales_monthly_aggregate_table.
Para uma pergunta como "Qual é o valor total de cada venda hoje?", você precisa de dados de pedidos granulares no nível da linha. Nesse caso, o Looker vai consultar a tabela original orders_database sem nenhuma agregação. Se você quiser analisar os totais de vendas semanais das últimas três semanas, o Looker vai criar e selecionar uma tabela agregada diária de vendas. Essa tabela é mais granular do que a tabela de vendas mensal, mas é um resumo do orders_database bruto.
O reconhecimento agregado no Looker é usada com frequência para resumir ou consolidar dados em vários períodos. Além disso, as tabelas agregadas precisam ser persistidas em uma instância do Looker para serem usadas no reconhecimento agregado.
Unir visualizações de maneira eficiente
Outra forma de otimizar a performance é unir apenas as visualizações necessárias ao definir uma nova análise. Para minimizar as junções, você pode definir várias análises para diferentes finalidades (por exemplo, consultar dados por usuário, consultar dados agregados de vendas). Além disso, você deve usar campos de base em vez de campos concatenados como chaves primárias. Quando possível, use junções muitos para um: unir visualizações do nível mais granular ao nível mais alto de detalhes (muitos para um) geralmente oferece o melhor desempenho de consulta no Looker.
Incluir filtros nas definições da Análise
Incluir filtros nas definições da Análise pode otimizar o desempenho, evitando que uma grande quantidade de dados seja retornada por padrão. Há muitas opções de filtro, incluindo filtros que são visíveis e modificáveis pelos usuários, como always_filter e conditionally_filter. Também é possível modificar as sugestões de filtro para campos em uma análise detalhada. Para mais informações e prática com filtros da Análise, faça o laboratório Como filtrar Análises com o LookML.
Implementar políticas de armazenamento em cache
Para reduzir o tráfego de consultas de banco de dados, você deve maximizar o armazenamento em cache para sincronizar com suas políticas de extração, carregamento e transformação (ETL) sempre que possível. Por padrão, o Looker armazena consultas em cache por uma hora. Você pode controlar a política de armazenamento em cache e sincronizar as atualizações de dados do Looker com seu processo de ETL usando o parâmetro persist_with para aplicar datagroups nas análises detalhadas. Isso permite que o Looker se integre mais de perto ao pipeline de dados de back-end para que o uso do cache possa ser maximizado sem o risco de analisar dados desatualizados.
Por exemplo, algumas tabelas de dados podem ser atualizadas apenas uma vez por dia, então atualizar o cache a cada hora para essas tabelas não agrega valor. Neste laboratório, você vai usar várias opções para personalizar o armazenamento em cache no Looker, incluindo grupos de dados ou políticas de armazenamento em cache, para persistir tabelas derivadas. Para mais informações e prática com políticas de armazenamento em cache, faça o laboratório Armazenamento em cache e datagroups com LookML.
Otimização adicional de consultas
Dependendo do dialeto específico do seu banco de dados, você pode conferir outros recursos de otimização de consultas, como cluster_keys e indexes.
Tarefa 1: Criar uma tabela derivada persistente incremental que será atualizada automaticamente sem reconstruir a tabela inteira
Como descrito anteriormente, uma tabela derivada persistente (TDP) é uma tabela derivada que é gravada em um esquema de rascunho no seu banco de dados e regenerada na programação que você especifica com uma estratégia de persistência. TDPs são úteis porque, quando o usuário solicita dados da tabela, ela geralmente já existe, o que reduz o tempo de consulta e a carga do banco de dados.
Em uma TDP padrão, a tabela inteira é recriada de acordo com uma programação definida na política de armazenamento em cache. Por outro lado, as TDPs criadas de forma incremental vão adicionar ao final dados novos a uma tabela atual. Isso pode reduzir muito o tamanho da consulta que você está enviando ao banco de dados.
Nesta tarefa, você vai criar uma tabela derivada nativa (NDT, na sigla em inglês) para agregar dados de pedidos por período ou estado. Você também ativa a persistência com uma atualização diária e atualizações incrementais que voltam três dias para recuperar dados atrasados.
Usar uma análise para criar uma tabela derivada nativa
-
Clique no botão ativar/desativar para entrar no Modo de Desenvolvimento.
-
Acesse Análise > Itens do pedido.
-
Em Itens do pedido > Dimensões, selecione o seguinte:
- ID do pedido
- Preço de venda
-
Data de criação > Data
-
Data de criação > Semana
-
Data de criação > Mês
-
Em Usuários > Dimensões, selecione Estado.
-
Clique em Executar.
-
Clique em Configurações ( ).
).
-
Selecione Acessar o LookML.
-
Na guia Tabela derivada, copie o código LookML para um editor de texto.
Você vai usar esse código para criar uma nova visualização para a tabela derivada nativa.
Criar um arquivo de visualização para uma tabela derivada
-
Abra uma nova janela do Looker em uma nova guia do navegador.
-
No menu Desenvolver, clique em qwiklabs_ecommerce.
-
Clique no ícone de adição (+) ao lado de Navegador de arquivos e selecione Criar visualização.
-
Nomeie o novo arquivo como incremental_pdt e clique em Criar.
-
No navegador de arquivos, clique em incremental_pdt.view e arraste para a pasta views.
-
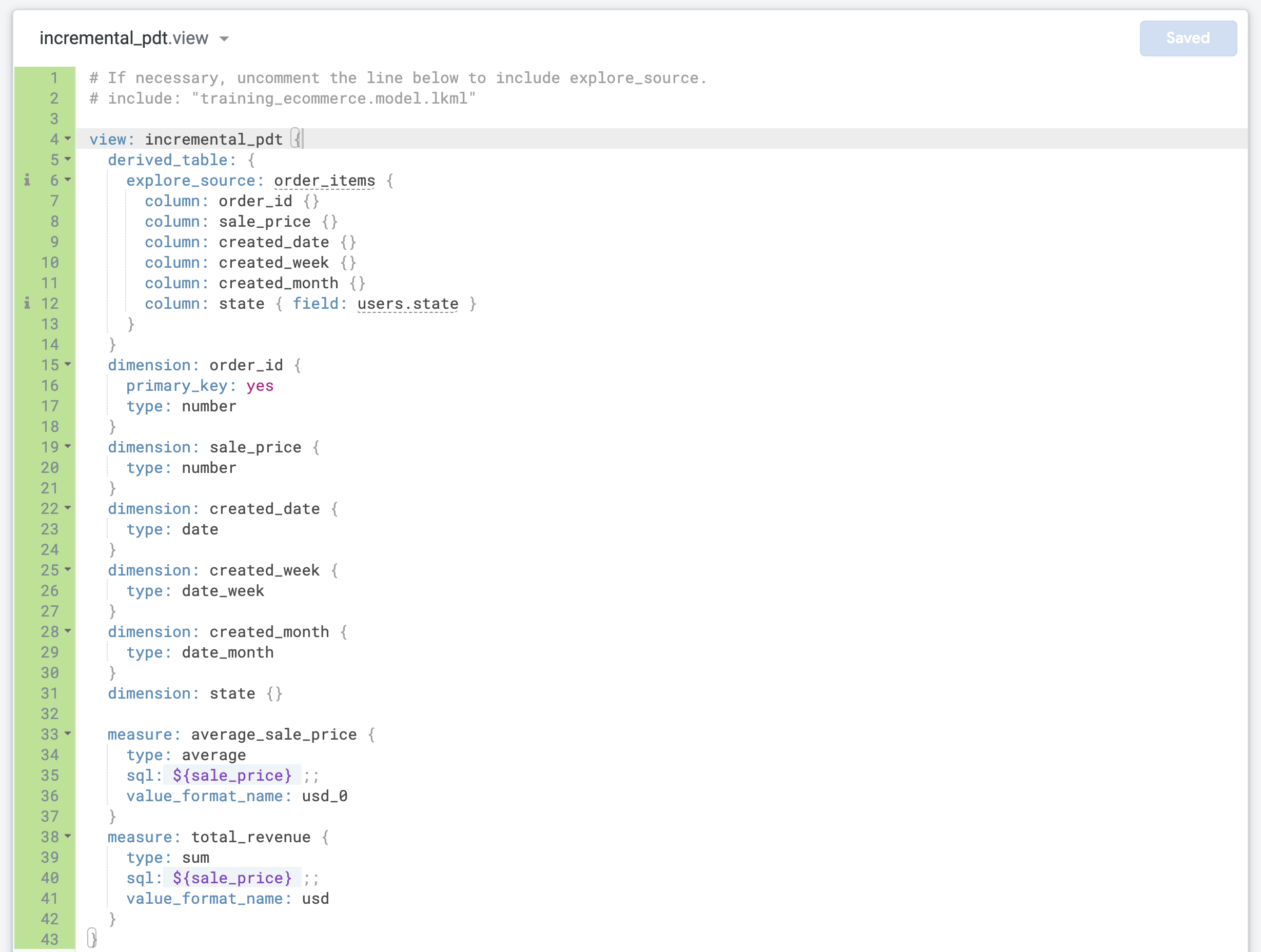
Substitua o código LookML padrão em incremental_pdt.view pelo código que você copiou anteriormente para a tabela derivada nativa.
-
Atualize a linha 4 com o nome correto da visualização (incremental_pdt).
-
Atualize a dimensão order_id para defini-la como a primary_key da visualização:
dimension: order_id {
primary_key: yes
type: number
}
Isso acontece porque cada registro representa um pedido com um order_id exclusivo.
- Encontre a última dimensão e adicione duas novas medições antes da chave de fechamento final (
}) no arquivo:
measure: average_sale_price {
type: average
sql: ${sale_price} ;;
value_format_name: usd_0
}
measure: total_revenue {
type: sum
sql: ${sale_price} ;;
value_format_name: usd
}
- Clique em Salvar alterações. O arquivo deve ser semelhante ao seguinte:
Adicionar persistência e atualizações incrementais a uma tabela derivada
-
Abra training_ecommerce.model.
-
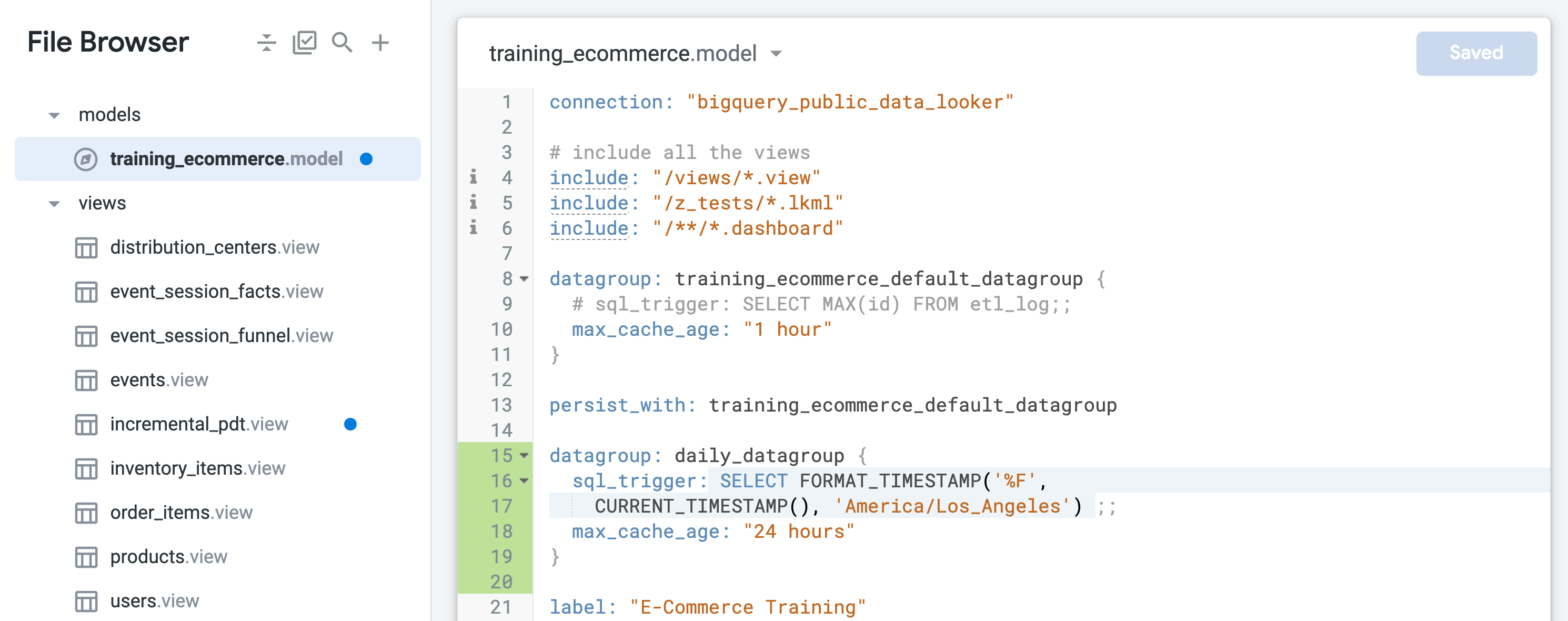
Encontre o grupo de dados padrão chamado training_ecommerce_default_datagroup e adicione uma nova linha (linha 13).
-
Defina um novo grupo de dados para persistir objetos com atualização diária (tempo máximo de 24 horas):
datagroup: daily_datagroup {
sql_trigger: SELECT FORMAT_TIMESTAMP('%F',
CURRENT_TIMESTAMP(), 'America/Los_Angeles') ;;
max_cache_age: "24 hours"
}
O sql_trigger verifica a data atual e aciona uma atualização quando a data muda, e o max_cache_age garante que a tabela seja recriada após 24 horas, mesmo que o sql_trigger não seja executado com sucesso.
- No final de
training_ecommerce.model (por volta da linha 67), defina uma nova análise que contenha apenas a visualização incremental_pdt para que você possa testá-la nas etapas subsequentes:
explore: incremental_pdt {}
- Clique em Salvar alterações.
- Abra incremental_pdt.view e adicione a persistência incluindo o datagroup diário na definição da tabela derivada na linha 6:
datagroup_trigger: daily_datagroup
- Adicione atualizações incrementais incluindo os seguintes parâmetros na definição da tabela derivada nas linhas 7 e 8:
increment_key: "created_date"
increment_offset: 3
- Clique em Salvar alterações. O arquivo deve ser semelhante ao seguinte:
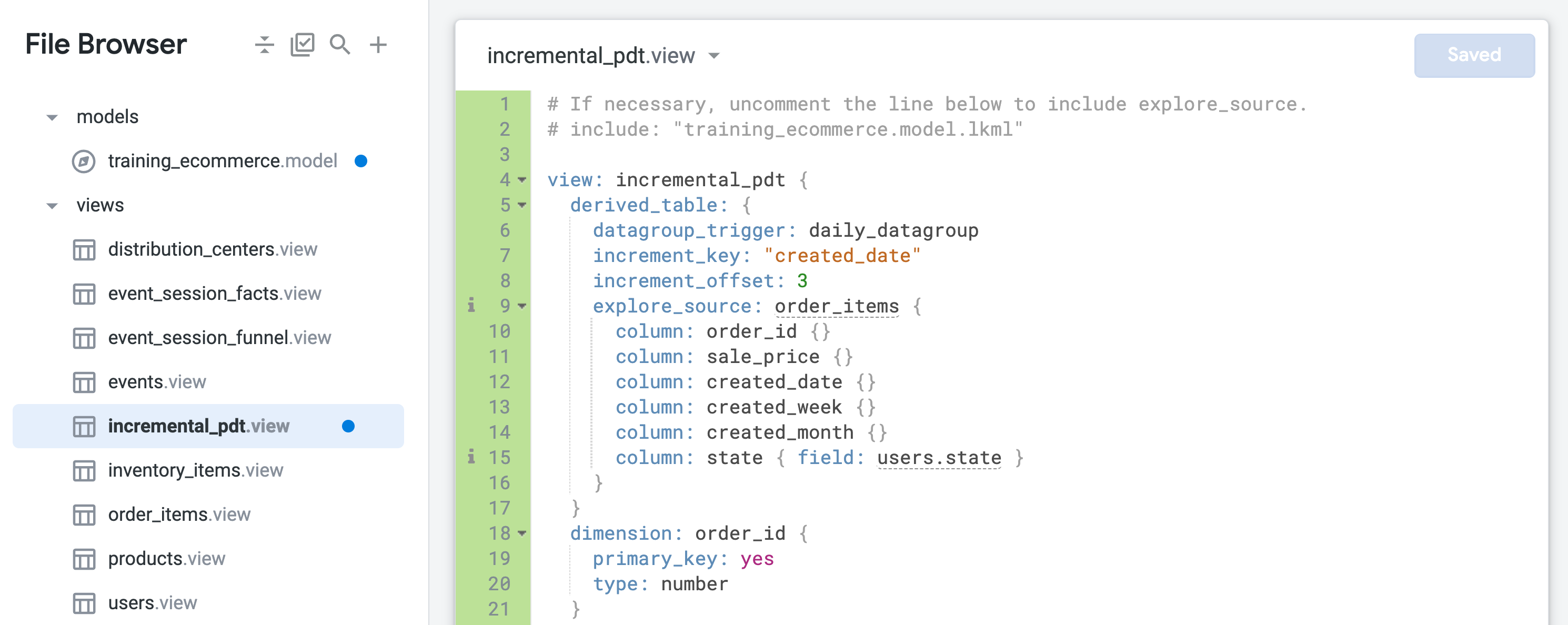
A tabela derivada persistente agora será mantida e será recriada uma vez por dia, voltando três dias para capturar quaisquer pedidos que possam ter chegado atrasados.
- Feche a guia do navegador da consulta original da Análise, mas deixe a guia do ambiente de desenvolvimento integrado do Looker aberta.
Testar consultas de análise em uma tabela derivada persistente incremental
-
Abra uma nova janela do Looker em uma nova guia do navegador.
-
Acesse Análise > TDP incremental.
-
No painel "Dados", abra a guia SQL.
-
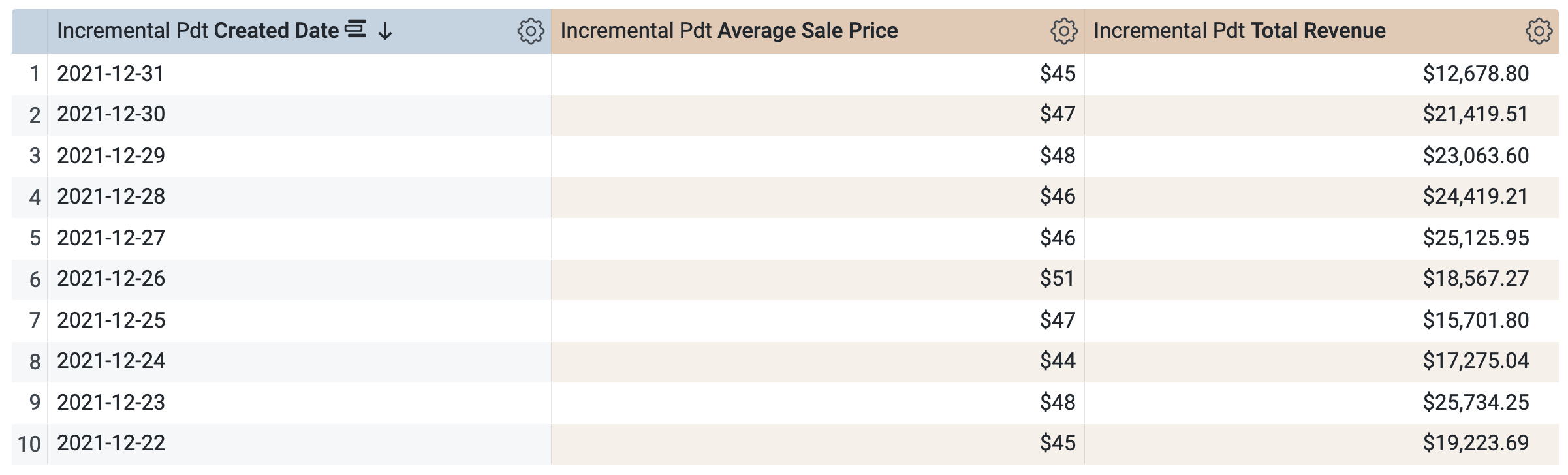
Em TDP incremental > Dimensões, selecione Data de criação.
-
Em TDP incremental > Medições, selecione Preço médio de venda e Receita total.
Antes de executar a consulta, observe que há duas consultas na janela SQL (que podem levar alguns segundos para carregar). A primeira consulta gera a TDP chamada incremental_pdt, e a segunda consulta recupera os resultados da TDP recém-criada.
-
Clique em Executar.
-
Abra a guia Resultados para conferir os resultados.
-
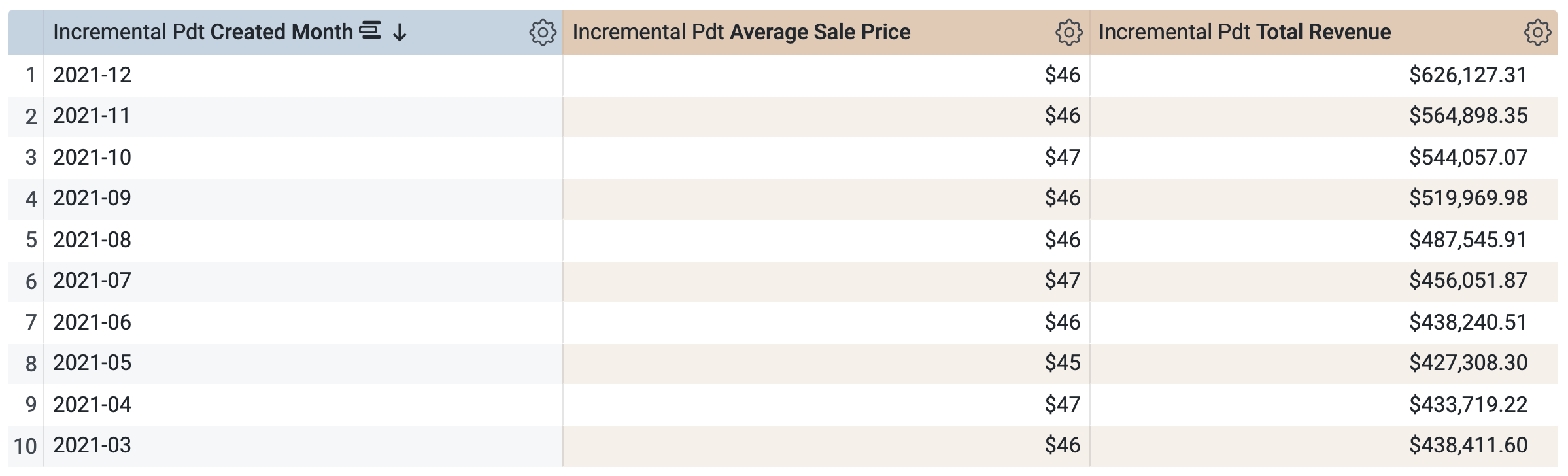
Em TDP incremental > Dimensões:
-
Limpar Data de criação.
- Selecione Mês de criação.
-
No painel "Dados", abra a guia SQL.
Observe que a consulta vai usar a mesma TDP para recuperar os resultados, o que faz sentido porque você solicitou um período que já está definido (e armazenado em cache) na TDP. No entanto, observe que não é possível selecionar e executar uma consulta em um período diferente que não esteja incluída na TDP, como trimestre ou ano.
-
Clique em Executar.
-
Abra a guia Resultados para conferir os resultados.
Desafio
- Execute uma nova consulta usando apenas a dimensão Estado e as medições Preço promocional médio e Receita total. Responda à pergunta abaixo.
-
Feche a guia do navegador da consulta Análise e volte para a guia do navegador com o Looker IDE.
-
Clique em Validar o LookML.
Não deve haver erros no LookML.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Permaneça na guia do navegador do Looker IDE ao iniciar a próxima tarefa.
Clique em Verificar meu progresso para conferir o objetivo.
Criar uma tabela derivada persistente incremental
Tarefa 2: Criar uma tabela agregada incremental para resumir os dados de pedidos em vários períodos
No Looker, é possível criar tabelas agregadas estratégicas que minimizam o número de consultas necessárias nas tabelas grandes de um banco de dados. As tabelas agregadas precisam ser persistidas no banco de dados para que possam ser acessíveis para reconhecimento de agregados. Portanto, as tabelas agregadas são um tipo de tabela derivada persistente (TDP).
Uma tabela agregada é definida usando o parâmetro aggregate_table em um parâmetro das Análises no seu projeto do LookML. Depois de criar as tabelas agregadas, você pode executar consultas na Análise para ver quais tabelas agregadas o Looker usa. O Looker usa a lógica de reconhecimento agregado para encontrar a menor e mais eficiente tabela agregada disponível no seu banco de dados para executar uma consulta, mantendo a correção.
Nesta tarefa, você vai recriar a TDP incremental da tarefa anterior como uma nova tabela agregada incremental. Você também disponibiliza a nova tabela agregada para os usuários usando um refinamento da Análise de itens do pedido existente.
Criar uma tabela agregada em um refinamento de uma Análise existente
-
Na página do ambiente de desenvolvimento integrado do Looker, abra training_ecommerce.model.
-
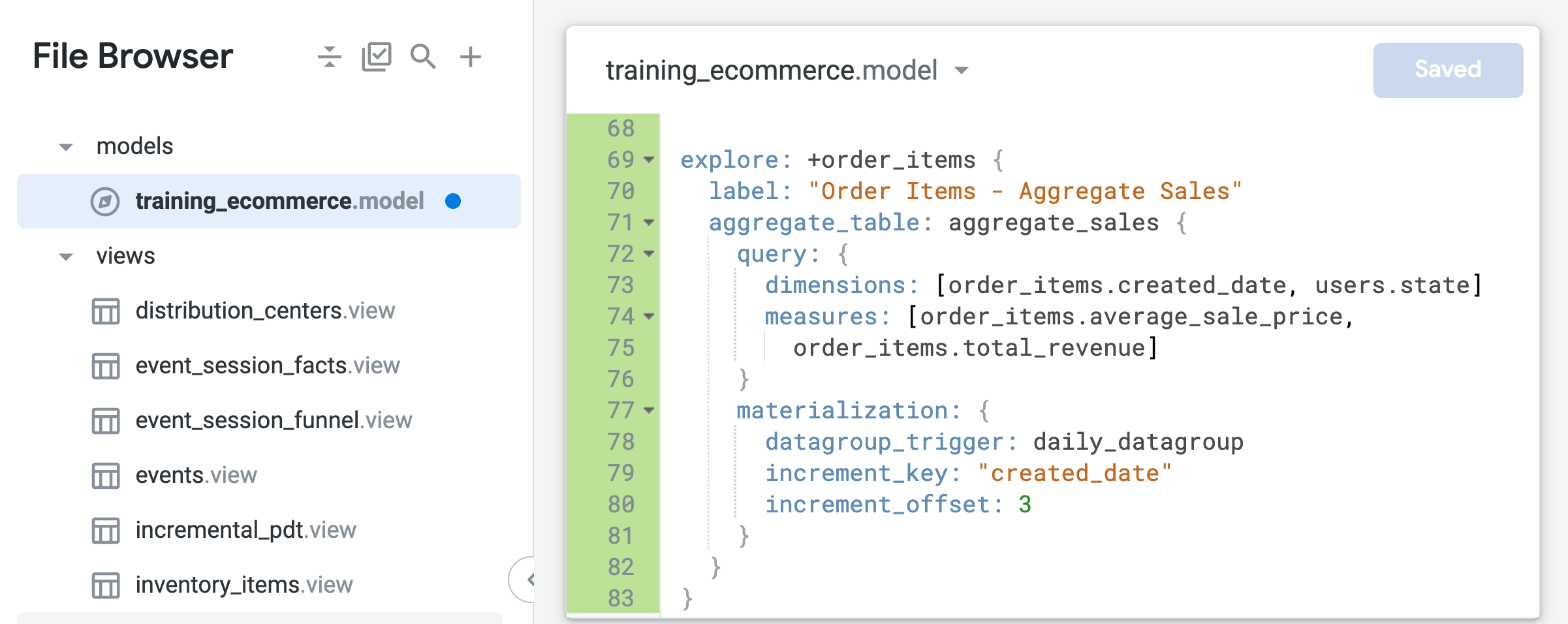
No final do arquivo (por volta da linha 69), adicione o seguinte código para criar um refinamento da Análise order_items:
explore: +order_items {
label: "Order Items - Aggregate Sales"
}
Esse refinamento se baseia na Análise order_items definida no arquivo modelo e adiciona as modificações especificadas no novo código LookML, como o rótulo ou a tabela agregada que você vai adicionar nas próximas etapas.
- Expanda o código LookML do refinamento para incluir uma tabela agregada que resuma os dados de pedidos por período ou estado:
explore: +order_items {
label: "Order Items - Aggregate Sales"
aggregate_table: aggregate_sales {
query: {
dimensions: [order_items.created_date, users.state]
measures: [order_items.average_sale_price,
order_items.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
Observe que, ao contrário da tabela derivada nativa que você criou na tarefa anterior, a única dimensão de tempo especificada na tabela agregada é created_date. Com o reconhecimento agregado, o Looker pode usar essa tabela única para consultas de Análise que solicitam o preço médio de venda ou a receita total agregados por tempo, independentemente do período solicitado (dia, mês, ano).
- Clique em Salvar alterações.
Deixe essa guia aberta para o ambiente de desenvolvimento integrado do Looker.
Testar consultas da Análise em uma tabela agregada incremental persistente
-
Abra uma nova janela do Looker em uma nova guia do navegador.
-
Acesse Análise > Itens do pedido – Vendas agregadas.
-
No painel "Dados", abra a guia SQL.
-
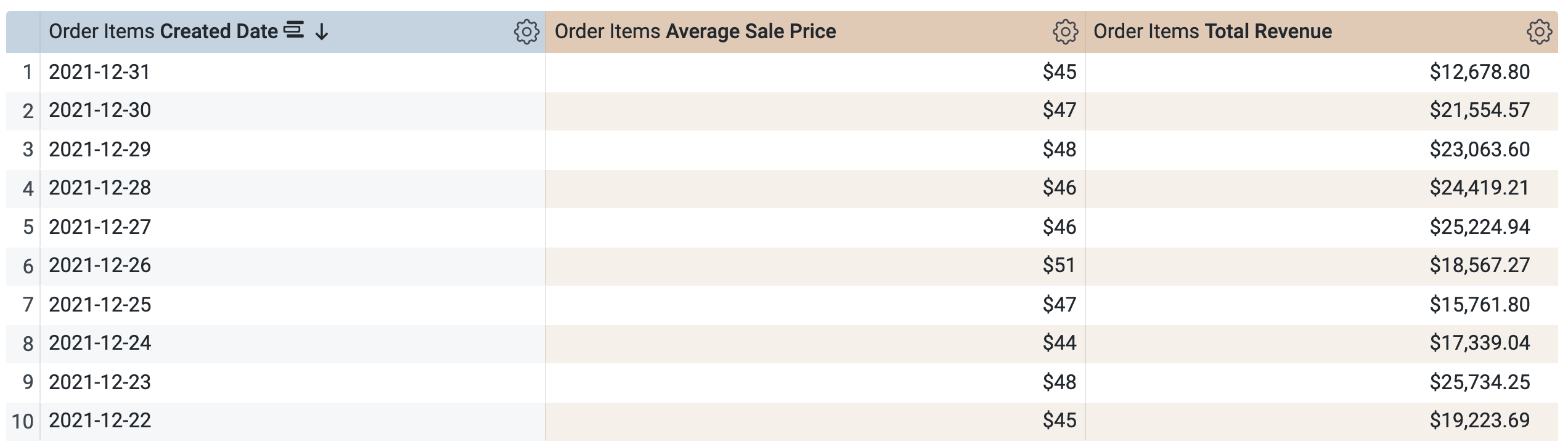
Em Itens do pedido > Dimensões, selecione Data de criação > Data.
-
Em Itens do pedido > Medições, selecione Preço médio de venda e Receita total.
Antes de executar a consulta, observe que há duas consultas, semelhantes à janela SQL na Tarefa 1. A primeira consulta gera a TDP chamada aggregate_sales, e a segunda consulta recupera os resultados dessa nova TDP.
-
Clique em Executar.
-
Abra a guia Resultados para conferir os resultados.
-
Em Itens do pedido > Dimensões > Data de criação:
-
Limpar data.
- Selecionar Trimestre.
-
No painel "Dados", abra a guia SQL.
Observe que a consulta vai usar a mesma TDP (aggregate_sales) para recuperar os resultados por trimestre. O Looker está aplicando o reconhecimento agregado para resumir o preço médio de venda e a receita total nos períodos solicitados disponíveis em "Data de criação".
-
Clique em Executar.
-
Abra a guia Resultados para conferir os resultados.
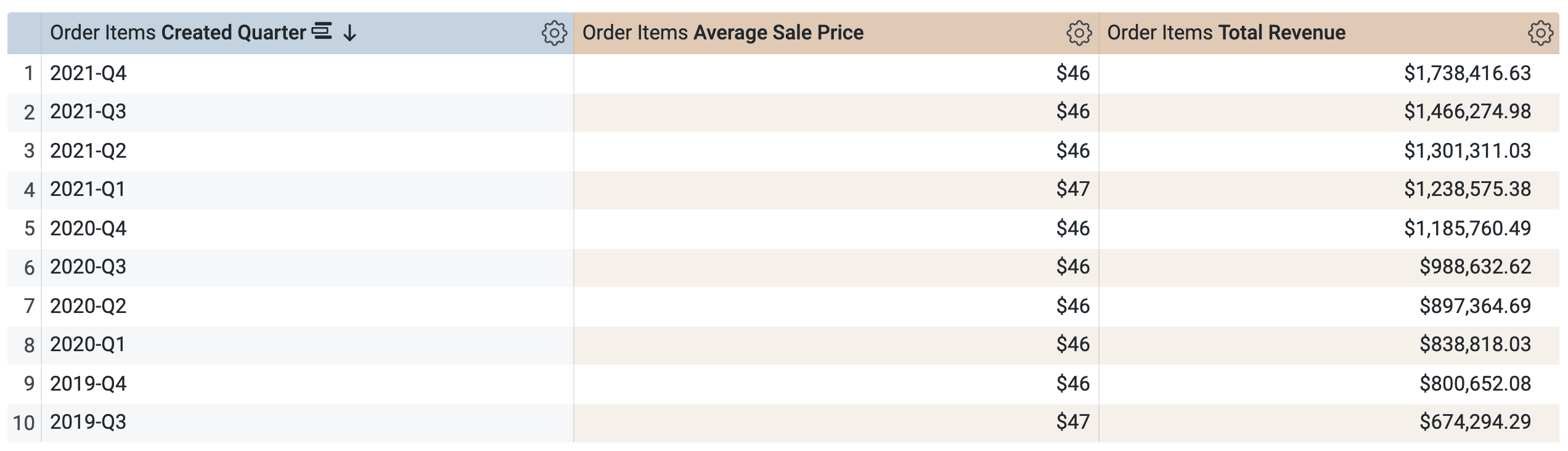
Desafio
- Execute uma nova consulta usando apenas a dimensão Estado (em "Usuários") e as medições Preço médio de venda e Receita total. Responda à pergunta abaixo.
- Execute uma nova consulta usando apenas a dimensão País (em "Usuários") e as medições Preço médio de venda e Receita total. Responda à pergunta abaixo.
-
Feche a guia do navegador da consulta Análise e volte para a guia do navegador com o Looker IDE.
-
Clique em Validar o LookML. Não deve haver erros no LookML.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Permaneça na guia do navegador do Looker IDE ao iniciar a próxima tarefa.
Clique em Verificar meu progresso para conferir o objetivo.
Criar uma tabela agregada
Tarefa 3: Juntar as visualizações de maneira eficiente para otimizar as consultas da Análise
Junções eficientes são componentes essenciais para definir as Análises performáticas no Looker. Para melhorar a eficiência das junções, mescle apenas as visualizações necessárias para definir a análise, use campos básicos (em vez de campos concatenados) como chaves primárias para as visualizações e use junções many_to_one sempre que possível.
Conforme descrito na documentação, as chaves primárias fornecem um identificador exclusivo para registros em uma visualização e são essenciais para agregações e relações precisas no Looker. A chave primária de uma visualização é um campo que contém valores exclusivos (como uma coluna de ID) e é identificada no arquivo de visualização com o parâmetro primary_key: yes.
Nesta seção, você vai identificar a coluna mais adequada para usar como chave primária de uma visualização. Em seguida, você define uma nova análise detalhada para a tabela agregada com apenas a visualização de usuários mesclada, usa o parâmetro from para especificar order_items como a visualização de base da análise detalhada e, em seguida, mescla a visualização de usuários. Por fim, você omite as junções extras incluídas na Análise "Itens do pedido" e usa o relacionamento de junção many_to_one para oferecer suporte à eficiência da consulta.
Identificar o campo mais adequado para usar como chave primária de uma visualização
- Abra o arquivo users.view. Responda à pergunta abaixo.
Em users.view, a coluna ID já está identificada como a chave primária usando primary_key: yes. É um campo de base que contém valores exclusivos (um ID para cada usuário) e não é um campo concatenado criado a partir de várias colunas. Portanto, ID é a melhor opção para a chave primária da visualização de usuários e pode oferecer suporte a junções eficientes.
- Abra o arquivo order_items.view. Responda à pergunta abaixo.
O order_item_id é baseado na coluna ID da tabela order_items e é identificado como a chave primária. No entanto, outros campos de ID nessa visualização podem ser a chave exclusiva da tabela, incluindo order_id, que se baseia na coluna order_id da tabela order_items.
Nas próximas etapas, você vai analisar a tabela order_items no SQL Runner para identificar por que order_item_id é o melhor campo para usar como primary_key.
-
Abra uma nova janela do Looker em uma nova guia do navegador.
-
Acesse Desenvolver > SQL Runner.
-
Clique em Configurações () ao lado de "Conexão" e selecione Pesquisar projetos públicos.
-
A caixa do projeto agora estará vazia. Digite cloud-training-demos e pressione ENTER.
-
Em Conjunto de dados, selecione looker_ecomm.
Uma lista das tabelas disponíveis neste conjunto de dados do BigQuery é exibida.
Um método rápido e fácil para verificar se uma coluna é uma chave primária apropriada é comparar a contagem de registros na tabela com a contagem de valores distintos na coluna. Se as duas contagens forem iguais, a coluna contém valores exclusivos e é uma chave primária apropriada para a tabela.
- Para verificar se a coluna
user_id seria uma chave primária apropriada, adicione a seguinte consulta à janela Consulta SQL e clique em Executar:
SELECT count(*), count(distinct user_id)
FROM cloud-training-demos.looker_ecomm.order_items
- Repita a consulta para as colunas
order_id, inventory_item_id e id.
Nesse caso, id e inventory_item_id corresponderam à contagem de registros na tabela porque são IDs diferentes para o mesmo item em um pedido. Portanto, qualquer um deles pode ser usado como chave primária.
A coluna id foi escolhida como chave primária para order_items porque é o ID gerado para um item na tabela order_items, mas inventory_item_id é o ID do mesmo item na tabela inventory_items.
- Feche a guia do navegador do SQL Runner e volte para a guia do navegador com o Looker IDE.
Mescle a quantidade mínima de visualizações para definir novas Análises
-
Abra training_ecommerce.model.
-
Analise a Análise order_items atual.
Observe que ela inclui quatro junções diferentes que usam o tipo de relacionamento many_to_one. Dependendo do seu caso de uso, todas essas junções podem ser necessárias. Mas e se você só precisasse dos dados de usuários e pedidos agrupados por estado ou período? Se for esse o caso, essas junções extras nunca seriam usadas e diminuiriam a velocidade das consultas na Análise.
Nas próximas etapas, você vai criar uma nova Análise que mescla apenas os dados de pedidos e usuários com base em user_id na visualização order_items e id na visualização users.
- No final do arquivo (por volta da linha 85), adicione o seguinte código para definir uma nova análise detalhada com
order_items como a visualização de base e apenas a visualização de usuários mesclada:
explore: aggregated_orders {
from: order_items
label: "Aggregated Sales"
join: users {
type: left_outer
sql_on: ${aggregated_orders.user_id} = ${users.id} ;;
relationship: one_to_many
}
aggregate_table: aggregate_sales {
query: {
dimensions: [aggregated_orders.created_date,
users.state]
measures: [aggregated_orders.average_sale_price,
aggregated_orders.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
- Clique em Salvar alterações.
O arquivo deve ser semelhante ao seguinte:
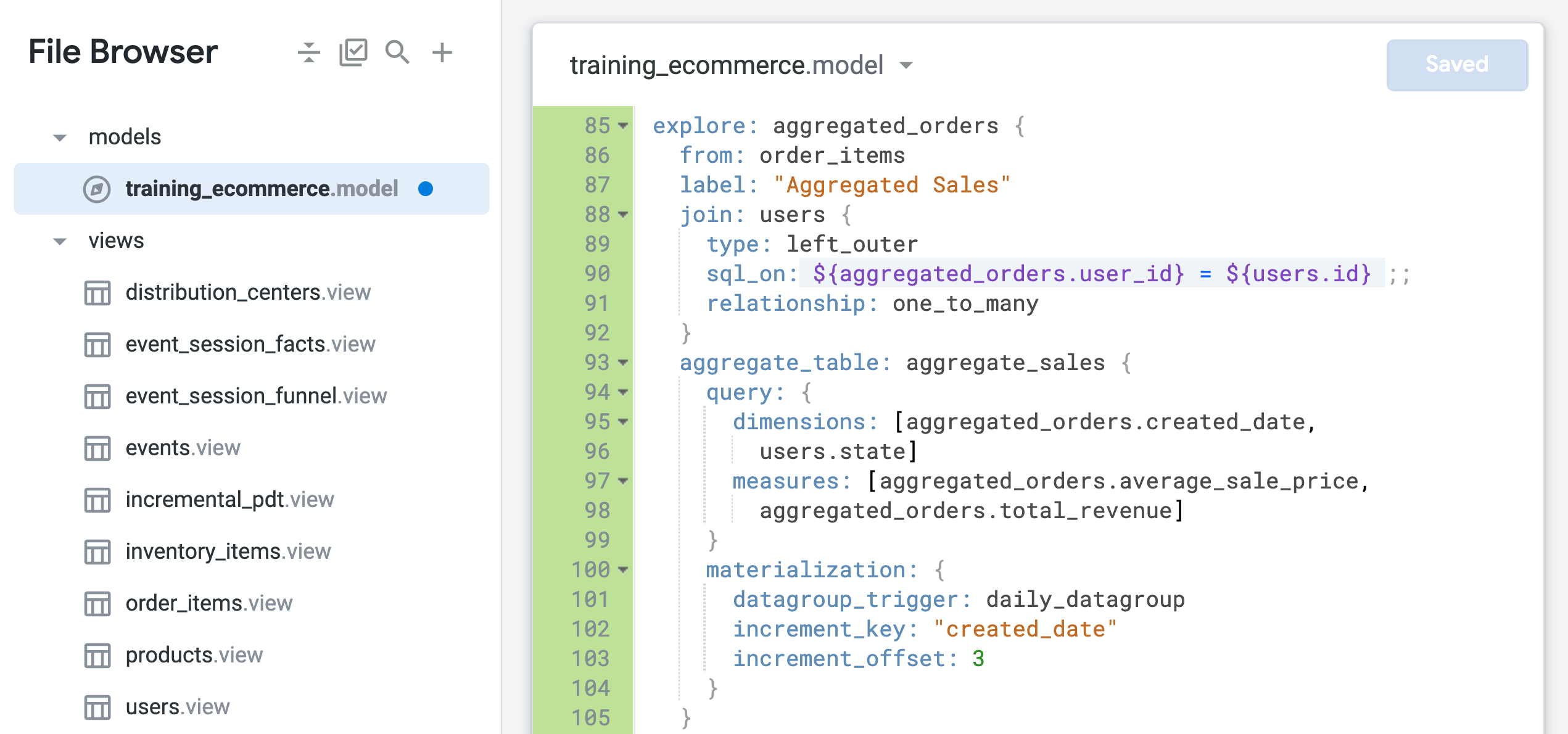
O parâmetro from é usado para especificar order_items como a visualização de base da análise detalhada, à qual a visualização de usuários é mesclada. Os campos na visualização order_items agora são identificados usando o novo nome da análise como aggregated_orders.fieldname.
Observe também que a relação entre a visualização users e a visualização order_items está identificada como one_to_many. Nas próximas etapas, você vai testar se essa junção baseada em um relacionamento um-para-muitos é a configuração mais ideal para essa Análise detalhada.
Definir relações de junção com bom desempenho para consultas eficientes do Explore
-
Abra uma nova janela do Looker em uma nova guia do navegador.
-
Acesse Análise > Vendas agregadas.
-
No painel "Dados", abra a guia SQL.
-
Em Pedidos agregados > Dimensões, selecione Data de criação > Data.
-
Em Pedidos agregados > Medições, selecione:
- Preço de venda médio
- Receita total
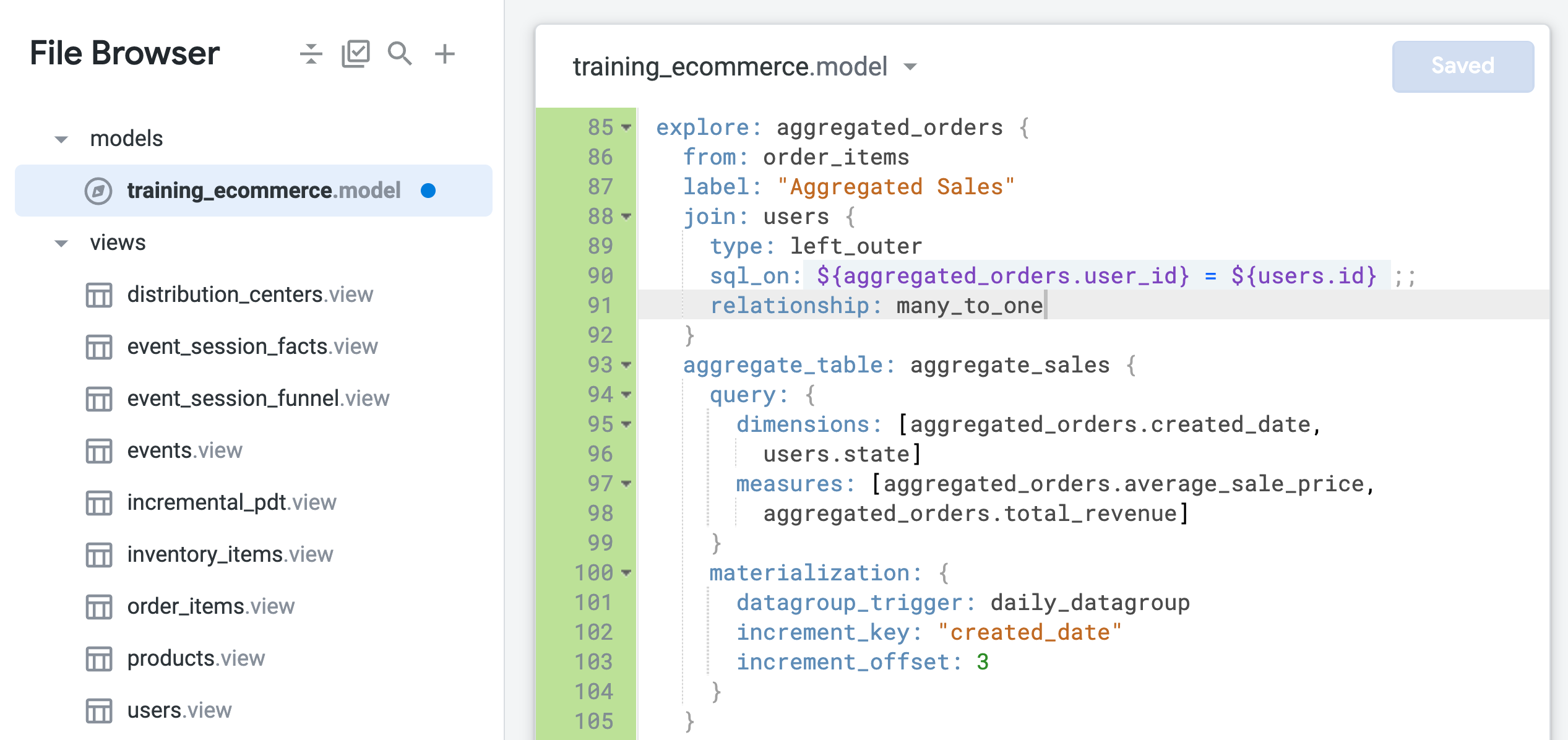
Antes de executar a consulta, observe que a tabela agregada não está sendo usada devido a um problema com a divergência da junção:
-- Did not use aggregated_orders::aggregate_sales; field aggregated_orders.average_sale_price was DISTINCT in the table due to a join fanout, but there was no fanout in the query
Uma divergência não intencional pode ocorrer quando a relação entre duas tabelas não é identificada corretamente para uma junção. Nesse caso, a visualização de base da Análise é order_items, que pode conter muitos pedidos para um usuário. No entanto, a visualização usuários contém apenas um registro para cada usuário.
Portanto, essa junção deve ser definida como many_to_one, ou seja, muitos pedidos para um usuário, em vez de um pedido para muitos usuários. (Saiba mais sobre o problema de divergências na Central de Ajuda do Looker.)
-
Clique em Executar.
-
Abra a guia "Resultados".
Os resultados são retornados, mas o Looker não usou a tabela agregada eficiente para recuperá-los.
-
Deixe esta guia do navegador para a Análise aberta e volte para a guia do navegador com o Looker IDE.
-
Atualize o parâmetro de relacionamento para many_to_one (linha 91) na análise aggregated_orders:
relationship: many_to_one
- Clique em Salvar alterações.
O arquivo deve ser semelhante ao seguinte:
-
Volte para a guia do navegador da consulta "Análise" e atualize a página.
-
No painel "Dados", abra a guia SQL.
Semelhante à guia SQL das tarefas 1 e 2, agora há duas consultas: a primeira para gerar a TDP e a segunda para recuperar resultados da TDP.
- Abra a guia Resultados para conferir os resultados.
-
Feche a guia do navegador da consulta Análise e volte para a guia do navegador com o Looker IDE.
-
Clique em Validar o LookML.
Não deve haver erros no LookML.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Permaneça na guia do navegador do Looker IDE ao iniciar a próxima tarefa.
Clique em Verificar meu progresso para conferir o objetivo.
Junte a quantidade mínima de visualizações a novas análises
Tarefa 4: Monitorar as criações de tabelas derivadas persistentes em uma instância do Looker
O Looker oferece a capacidade de monitorar as builds de TDPs em uma instância do Looker pela página "Tabelas derivadas persistentes" do menu "Admin". Dependendo da configuração do Looker, os usuários com privilégios para persistir tabelas podem visualizar essa página mesmo sem acesso ao menu "Admin" completo. Você pode verificar o status, os tempos de build e o armazenamento em cache de TDPs nos ambientes de desenvolvimento e produção para testar e monitorar TDPs na sua instância do Looker.
Nesta tarefa, você vai monitorar as TDPs criadas neste laboratório em relação ao status, tempo de build, armazenamento em cache e produção versus desenvolvimento. A TDP incremental criada a partir da NDT (Tarefa 1) deve ter o maior tempo de build, e as tabelas agregadas (Tarefas 2 e 3) devem ter os menores tempos de build. Isso acontece porque elas usam a mesma definição de tabela, mas estão incluídas em Análises configuradas de maneira diferente. Você também vai modificar uma TDP em desenvolvimento e monitorar o status dela antes e depois de enviá-la para produção.
Revise o status das TDPs em produção
-
Abra uma nova janela do Looker em uma nova guia do navegador.
-
Acesse Admin > Tabelas derivadas persistentes.
Nenhuma TDP está listada na guia "Desenvolvimento" porque todas as suas TDPs foram enviadas para produção.
-
Abra a guia Produção para ver as TDPs criadas nas tarefas 1 a 3.
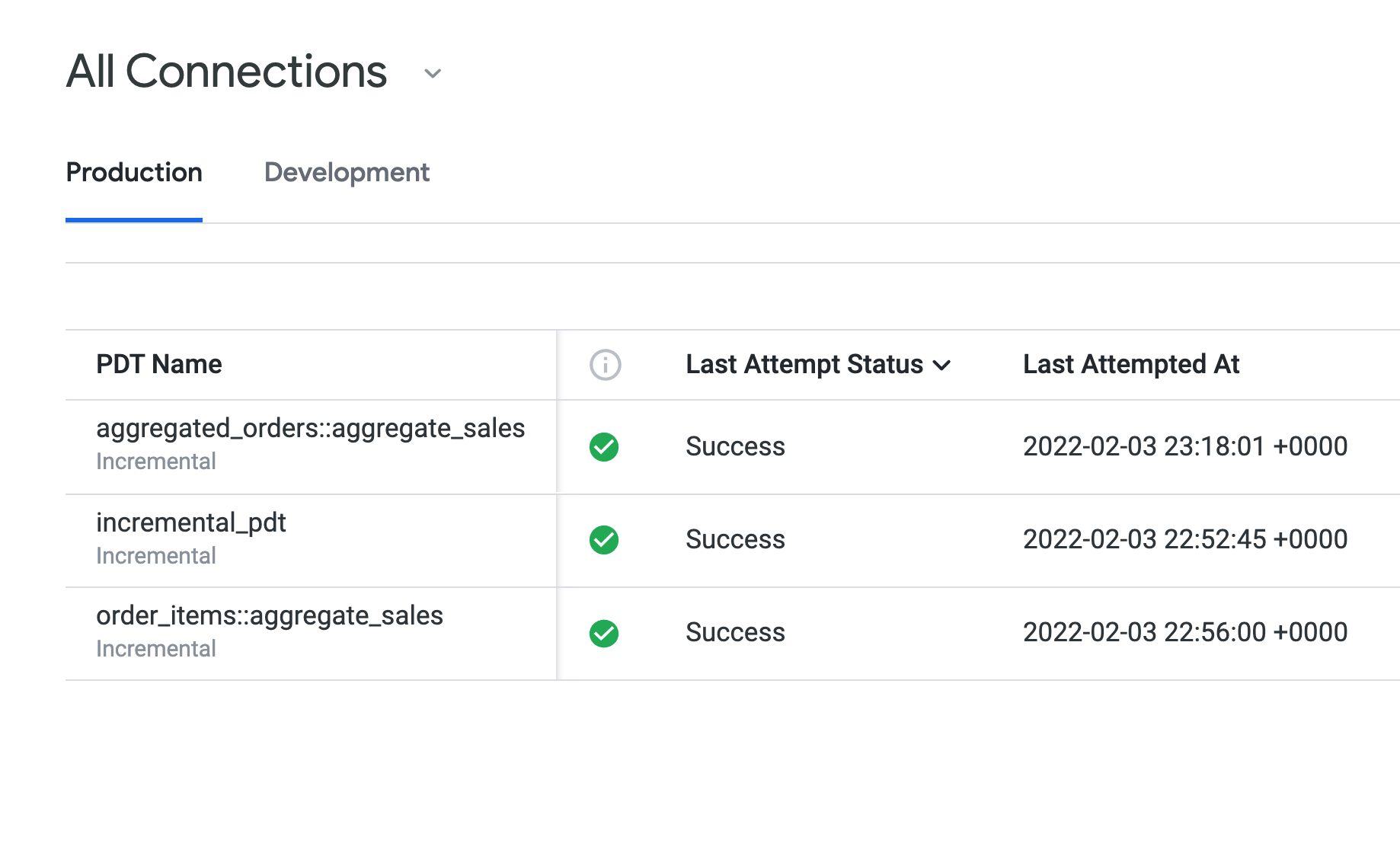
O Status da última tentativa mostra Sucesso para todos as TDPs, e todas elas estão usando a mesma regra de persistência (daily_datagroup). Para o tempo de build em "Duração do último build", o incremental_pdt provavelmente tem um build um pouco mais longo do que as duas tabelas agregadas.
Deixe a página Tabelas derivadas persistentes aberta enquanto começa as próximas etapas.
Modificar e revisar TDPs em desenvolvimento
-
Volte para a guia do navegador com o IDE do Looker.
-
Abra training_ecommerce.model.
-
Adicione uma nova dimensão para users.country à Análise aggregated_orders (por volta da linha 96):
dimensions: [aggregated_orders.created_date, users.state, users.country]
-
Clique em Salvar alterações.
-
Volte para a página Tabelas derivadas persistentes e atualize a página.
Na guia "Produção", a TDP aggregated_orders::aggregate_sales ainda aparece como criada, mesmo que você tenha modificado o código LookML da TDP no modo de desenvolvimento.
O Looker permite que os desenvolvedores testem mudanças em TDPs no modo de desenvolvimento, de forma semelhante a como elas trabalham com outros objetos do Looker nesse modo. Por exemplo, quando os desenvolvedores criam novas dimensões e medições no modo de desenvolvimento, esses novos objetos não aparecem na produção até que o desenvolvedor confirme as alterações e as implante na produção.
- Abra a guia Desenvolvimento.
-
Deixe esta página de tabelas derivadas persistentes aberta e abra uma nova janela do Looker em uma nova guia do navegador.
-
Acesse Análise > Vendas agregadas.
-
No painel "Dados", abra a guia SQL.
-
Em Usuários > Dimensões, selecione País.
-
Em Pedidos agregados > Medições, selecione:
- Preço de venda médio
- Receita total
Há duas consultas na guia SQL: a primeira gera a TDP e a segunda recupera os resultados da TDP recém-criada.
-
Clique em Executar.
-
Abra a guia Resultados para conferir os resultados.
-
Feche a guia do navegador da consulta de Análise, volte para a guia do navegador com a página Tabelas derivadas permanentes e atualize a página.
A guia "Desenvolvimento" agora mostra que aggregated_orders::aggregate_sales foi criado com sucesso.
-
Deixe a guia do navegador da página de tabelas derivadas permanentes aberta e volte para a guia do navegador com o IDE do Looker.
-
Clique em Validar o LookML.
Não há erros do LookML.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Volte para a guia do navegador com a página "Tabelas derivadas persistentes" e atualize a página. Agora que as mudanças na produção foram implantadas, a TDP aggregated_orders::aggregate_sales não está mais listada na guia "Desenvolvimento" e aparece apenas na guia "Produção".
Parabéns!
Neste laboratório, você aprendeu quando e como adicionar persistência e atualizações incrementais a tabelas derivadas, usar o reconhecimento de agregados, unir visualizações de maneira eficiente e monitorar as builds de TDPs para otimizar consultas do Looker.
Próximas etapas/ Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 23 de abril de 2024
Laboratório testado em 6 de outubro de 2023
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





