GSP985

Übersicht
Looker ist eine moderne Datenplattform in Google Cloud, mit der Daten interaktiv analysiert und visualisiert werden können. Mit Looker können Sie detaillierte Datenanalysen durchführen, Informationen aus verschiedenen Datenquellen einbinden, umsetzbare datengesteuerte Workflows erstellen und benutzerdefinierte Datenanwendungen entwickeln.
Komplexe Abfragen können kostspielig sein und die Datenbank belasten, was die Leistung beeinträchtigt. Idealerweise vermeiden Sie es, umfangreiche Abfragen neu auszuführen, wenn sich nichts geändert hat. Stattdessen können Sie neue Daten an vorhandene Ergebnisse anhängen, um wiederholte Anfragen zu reduzieren. Es gibt viele Möglichkeiten, die Leistung von LookML-Abfragen zu optimieren. In diesem Lab konzentrieren wir uns auf die gängigsten Methoden: persistente abgeleitete Tabellen, Aggregate Awareness (Erkennung zusammengefasster Tabellen) und effiziente Verknüpfung von Ansichten.
Aufgaben
- Sie erfahren, wann und wie Sie abgeleiteten Tabellen Persistenz und inkrementelle Aktualisierungen hinzufügen.
- Sie optimieren Abfragen für zusammengefasste Daten mithilfe von Aggregate Awareness.
- Sie erstellen ein Refinement eines vorhandenen Explores.
- Sie verknüpfen Ansichten auf effiziente Weise, um Explore-Abfragen zu optimieren.
- Sie überwachen die Builds persistenter abgeleiteter Tabellen in einer Looker-Instanz.
Einrichtung und Anforderungen
Vor dem Klick auf „Lab starten“
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus, um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem privaten Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr privates Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Wenn Sie über ein privates Google Cloud-Konto oder ‑Projekt verfügen, verwenden Sie es nicht für dieses Lab. So werden zusätzliche Kosten für Ihr Konto vermieden.
Lab starten und bei Looker anmelden
-
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Der Bereich mit den Lab-Details wird angezeigt und enthält die temporären Anmeldedaten für dieses Lab.
Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
In den Lab-Details finden Sie Ihre Anmeldedaten, die Sie für die Anmeldung bei der Looker-Instanz benötigen.
Hinweis: Wenn Sie andere Anmeldedaten verwenden, treten Fehler auf oder es fallen Gebühren an.
-
Klicken Sie auf Looker öffnen.
-
Geben Sie den Benutzernamen und das Passwort in die Felder E-Mail und Passwort ein.
Nutzername:
{{{looker.developer_username | Username}}}
Passwort:
{{{looker.developer_password | Passwort}}}
Wichtig: Sie müssen die Anmeldedaten aus dem Bereich mit den Lab-Details auf dieser Seite verwenden. Bitte geben Sie nicht Ihre Anmeldedaten für Google Cloud Skills Boost ein. Wenn Sie ein privates Looker-Konto haben, sollten Sie es nicht für dieses Lab verwenden.
-
Klicken Sie auf Anmelden.
Nach erfolgreicher Anmeldung wird die Looker-Instanz für dieses Lab angezeigt.
Wichtige Empfehlungen für eine optimale Abfrageleistung
In diesem Abschnitt erfahren Sie mehr über die gängigen Methoden zur Optimierung der Abfrageleistung in Looker. Im Lab wenden Sie die ersten drei Methoden praktisch an.
Persistente abgeleitete Tabellen
Die erste Lösung sind persistente abgeleitete Tabellen (PATs). Mit Looker können Sie SQL- und LookML-Abfragen in Ihre Datenbank als temporäre Tabelle schreiben. Wenn diese Tabelle im Cache oder persistent gespeichert wird, wird sie zu einer PAT. Sie können dann komplexe oder häufig verwendete Abfragen wiederholt ausführen und die Ergebnisse im Cache speichern, um schnell auf sie zuzugreifen.
Wenn Sie diese Abfragen als Tabelle speichern, können Sie steuern, wann und wie sie erstellt werden. Tabellen können z. B. jeden Morgen, einmal im Monat oder nur dann neu generiert werden, wenn Daten hinzukommen. Idealerweise konfigurieren Sie abgeleitete Tabellen so, dass sie die Art Ihrer Daten widerspiegeln.
Abgeleitete Tabellen sind hilfreich, um neue Strukturen oder Aggregationen zu erstellen, die in Ihren zugrunde liegenden Datenbanktabellen noch nicht verfügbar sind. Allerdings müssen nicht alle abgeleiteten Tabellen persistent gespeichert werden, um sinnvoll zu sein. Persistenz wird in der Regel für komplexe, rechenintensive Abfragen eingesetzt oder für Abfragen, die häufig von vielen Personen oder Anwendungen ausgeführt werden.
Sie können auch inkrementelle PATs erstellen, um neue Daten anzuhängen, ohne die gesamte Tabelle neu zu erstellen. Inkrementelle Änderungen eignen sich gut für große Tabellen, in denen vorhandene (ältere) Daten nicht häufig aktualisiert werden, da die Tabelle hauptsächlich mit neuen Daten aktualisiert wird.
Aggregate Awareness
Bei sehr großen Tabellen in Ihrer Datenbank kann Looker mit der Funktion „Aggregate Awareness“ kleinere zusammengefasste Tabellen mit Daten erstellen, die nach verschiedenen Attributkombinationen gruppiert sind. Diese zusammengefassten Tabellen dienen als sogenannte „Rollup-“ bzw. Zusammenfassungstabellen, die Looker – wann immer möglich – anstelle der ursprünglichen großen Tabelle für Abfragen verwenden kann. Durch Aggregate Awareness findet Looker automatisch die kleinste und effizienteste Tabelle in Ihrer Datenbank, die für die jeweilige Abfrage geeignet ist, ohne dabei die Accuracy zu beeinträchtigen. Wird Aggregate Awareness strategisch eingesetzt, kann die durchschnittliche Abfragegeschwindigkeit deutlich steigen. Stellen Sie sich dafür eine Tabelle mit Onlinebestellungen eines stark frequentierten E-Commerce-Shops vor, in die alle paar Sekunden neue Zeilen eingefügt werden.
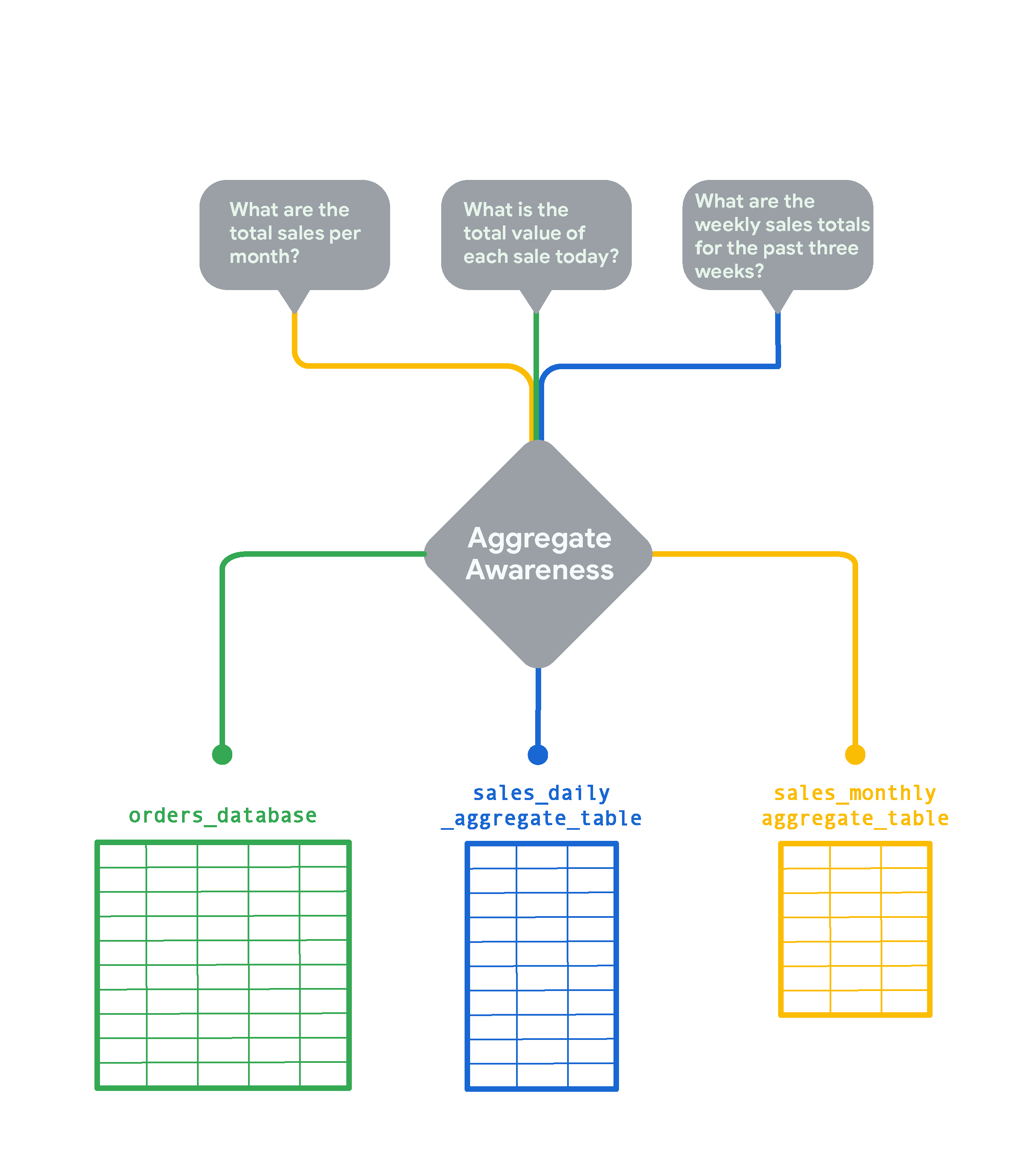
Wenn Sie Echtzeitdaten zu Bestellungen sehen möchten, benötigen Sie detailliertere Informationen. Um jedoch lediglich monatliche Trends wie „Gesamtumsatz pro Monat“ zu analysieren, ist eine monatliche Zusammenfassung der Daten viel schneller und kostengünstiger. In diesem Fall erstellt Looker die Tabelle sales_monthly_aggregate_table und greift für Abfragen darauf zu.
Für die Frage „Wie hoch ist der Gesamtwert jeder einzelnen Bestellung heute?“ benötigen Sie z. B. detaillierte, zeilenbasierte Bestelldaten. In diesem Fall greift Looker ohne Aggregation auf die ursprüngliche Tabelle orders_database zu. Wenn Sie hingegen die wöchentlichen Gesamtumsätze der vergangenen drei Wochen betrachten möchten, erstellt Looker eine täglich zusammengefasste Tabelle und verwendet diese. Diese Tabelle ist detaillierter als die Tabelle mit den monatlichen Umsatzzahlen, stellt aber trotzdem eine Zusammenfassung der Rohdaten aus orders_database dar.
Aggregate Awareness in Looker wird häufig verwendet, um Daten aus mehreren Zeiträumen zusammenzufassen. Außerdem müssen zusammengefasste Tabellen persistent in einer Looker-Instanz gespeichert werden, damit sie für Aggregate Awareness genutzt werden können.
Ansichten effizient einbinden
Eine weitere Möglichkeit zur Leistungsoptimierung besteht darin, beim Erstellen eines Explores nur die Ansichten einzubinden, die Sie benötigen. Um die Anzahl der Joins zu minimieren, können Sie mehrere separate Explores für unterschiedliche Zwecke definieren (z. B. ein Explore für nutzerbezogene Abfragen, ein anderes für zusammengefasste Umsatzdaten). Außerdem sollten Sie Basisfelder anstelle verketteter Felder als Primärschlüssel verwenden. Verwenden Sie nach Möglichkeit Joins mit einer n:1-Beziehung (many_to_one): Wenn Sie Ansichten von der feinsten Detailebene mit höher aggregierten Ebenen zusammenführen, erzielen Sie in Looker in der Regel die beste Abfrageleistung.
Filter in Explore-Definitionen einbeziehen
Wenn Sie Filter in Explore-Definitionen einbeziehen, können Sie die Leistung optimieren, da dann nicht standardmäßig eine große Datenmenge zurückgegeben wird. Es gibt viele Filteroptionen, darunter Filter, die für Nutzer und Nutzerinnen sichtbar sind und von ihnen geändert werden können, wie always_filter und conditionally_filter. Außerdem können Sie die Filtervorschläge für Felder in einem Explore ändern. Weitere Informationen und Übungen zu Explore-Filtern finden Sie im Lab Explores mit LookML filtern.
Caching-Richtlinien implementieren
Um den Datenbanktraffic durch Abfragen zu reduzieren, sollten Sie das Caching umfassend nutzen und nach Möglichkeit mit Ihren Richtlinien zum Extrahieren, Transformieren und Laden (ETL) synchronisieren. Standardmäßig speichert Looker Abfragen für eine Stunde im Cache. Sie können die Caching-Richtlinie steuern und Looker-Datenaktualisierungen mit Ihrem ETL-Prozess synchronisieren, indem Sie den Parameter persist_with verwenden, um Datengruppen in Explores anzuwenden. Dadurch kann Looker enger in die Backend-Datenpipeline eingebunden werden. Der Cache wird dann optimal genutzt, ohne das Risiko, dass veraltete Daten analysiert werden.
Einige Datentabellen werden beispielsweise nur einmal pro Tag aktualisiert. In diesem Fall ist es nicht sinnvoll, den Cache für diese Tabellen stündlich zu aktualisieren. In Looker stehen verschiedene Optionen zur Anpassung des Cachings zur Verfügung, darunter Datengruppen und Caching-Richtlinien, die Sie in diesem Lab einsetzen, um abgeleitete Tabellen persistent zu speichern. Weitere Informationen und Übungen zu Caching-Richtlinien finden Sie im Lab Caching und Datengruppen mit LookML.
Zusätzliche Abfrageoptimierung
Je nach Datenbankdialekt können Sie weitere Funktionen zur Abfrageoptimierung nutzen, z. B. cluster_keys und Indexe.
Aufgabe 1: Inkrementelle persistente abgeleitete Tabelle erstellen, die sich automatisch aktualisiert, ohne jedes Mal vollständig neu aufgebaut zu werden
Wie bereits beschrieben, wird eine persistente abgeleitete Tabelle (PAT) in ein Scratch-Schema in der Datenbank geschrieben und nach dem Zeitplan neu generiert, den Sie mit einer Persistenzstrategie angeben. PATs sind nützlich, da die Tabelle bei Datenabfragen oft bereits existiert. Sie können so die Abfragezeit verkürzen und die Belastung der Datenbank reduzieren.
Bei einer Standard-PAT wird die gesamte Tabelle nach einem Zeitplan neu erstellt, der in der Caching-Richtlinie festgelegt ist. Im Gegensatz dazu werden bei PATs, die inkrementell erstellt werden, neue Daten an eine bestehende Tabelle angehängt. Dadurch kann die Größe der an die Datenbank gesendeten Abfrage erheblich reduziert werden.
In dieser Aufgabe erstellen Sie eine native abgeleitete Tabelle (native derived table, NDT), um Bestelldaten nach Zeitraum oder Bundesstaat zu aggregieren. Außerdem aktivieren Sie die Persistenz mit einer täglichen Aktualisierung sowie inkrementellen Updates, die drei Tage zurückreichen, um verspätet eingetroffene Daten zu berücksichtigen.
Native abgeleitete Tabelle mit einem Explore erstellen
-
Klicken Sie auf den Ein/Aus-Button, um den Entwicklungsmodus zu aktivieren.
-
Gehen Sie zu Explore > Order Items (Analysieren > Bestellpositionen).
-
Wählen Sie unter Order Items > Dimensions (Bestellpositionen > Dimensionen) Folgendes aus:
-
Order ID (Bestell-ID)
-
Sale Price (Verkaufspreis)
-
Created Date > Date (Erstellungsdatum > Datum)
-
Created Date > Week (Erstellungsdatum > Woche)
-
Created Date > Month (Erstellungsdatum > Monat)
-
Wählen Sie unter Nutzer > Dimensionen die Option State (Bundesland/‑staat) aus.
-
Klicken Sie auf Ausführen.
-
Klicken Sie auf Einstellungen ( ).
).
-
Wählen Sie LookML abrufen aus.
-
Kopieren Sie auf dem Tab Abgeleitete Tabelle den LookML-Code in einen Texteditor.
Mit diesem Code erstellen Sie eine neue Ansicht für die native abgeleitete Tabelle.
Ansichtsdatei für eine abgeleitete Tabelle erstellen
-
Öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Klicken Sie im Menü Entwickeln auf qwiklabs_ecommerce.
-
Klicken Sie neben Dateibrowser auf das Pluszeichen (+) und wählen Sie Ansicht erstellen aus.
-
Nennen Sie die neue Datei incremental_pdt und klicken Sie auf Erstellen.
-
Klicken Sie im Dateibrowser auf incremental_pdt.view und ziehen Sie die Ansicht in den Ordner views.
-
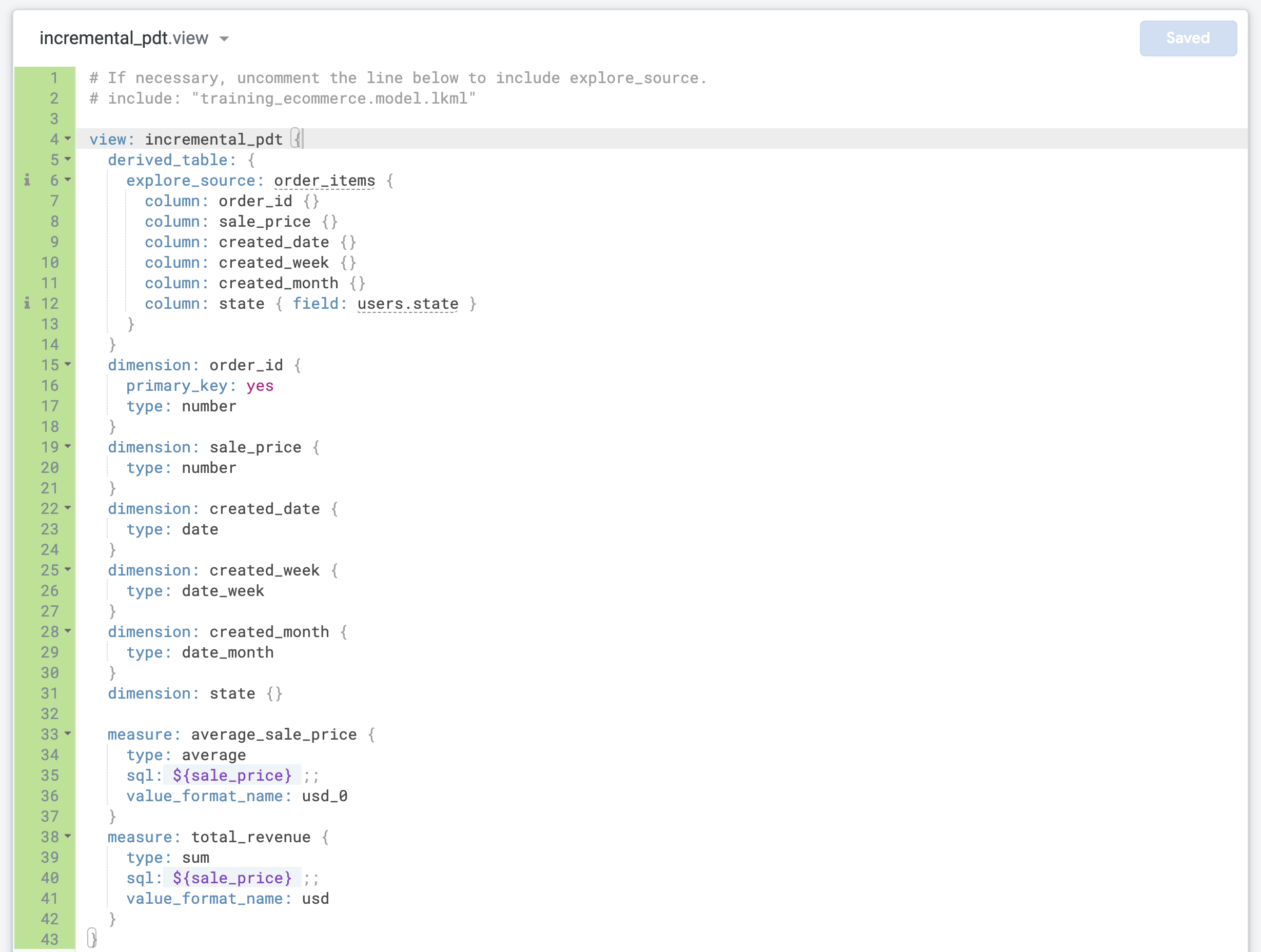
Ersetzen Sie den Standard-LookML-Code in incremental_pdt.view durch den Code, den Sie zuvor für die native abgeleitete Tabelle kopiert haben.
-
Aktualisieren Sie Zeile 4 und geben Sie den richtigen Ansichtsnamen (incremental_pdt) ein.
-
Aktualisieren Sie die Dimension order_id und definieren Sie sie als primary_key für die Ansicht:
dimension: order_id {
primary_key: yes
type: number
}
Das liegt daran, dass jeder Eintrag eine Bestellung mit einer eindeutigen order_id darstellt.
- Suchen Sie die letzte Dimension und fügen Sie vor der schließenden geschweiften Klammer (
}) zwei neue Messwerte in die Datei ein:
measure: average_sale_price {
type: average
sql: ${sale_price} ;;
value_format_name: usd_0
}
measure: total_revenue {
type: sum
sql: ${sale_price} ;;
value_format_name: usd
}
- Klicken Sie auf Änderungen speichern. Die Datei sollte jetzt in etwa so aussehen:
Einer abgeleiteten Tabelle Persistenz und inkrementelle Aktualisierungen hinzufügen
-
Öffnen Sie training_ecommerce.model.
-
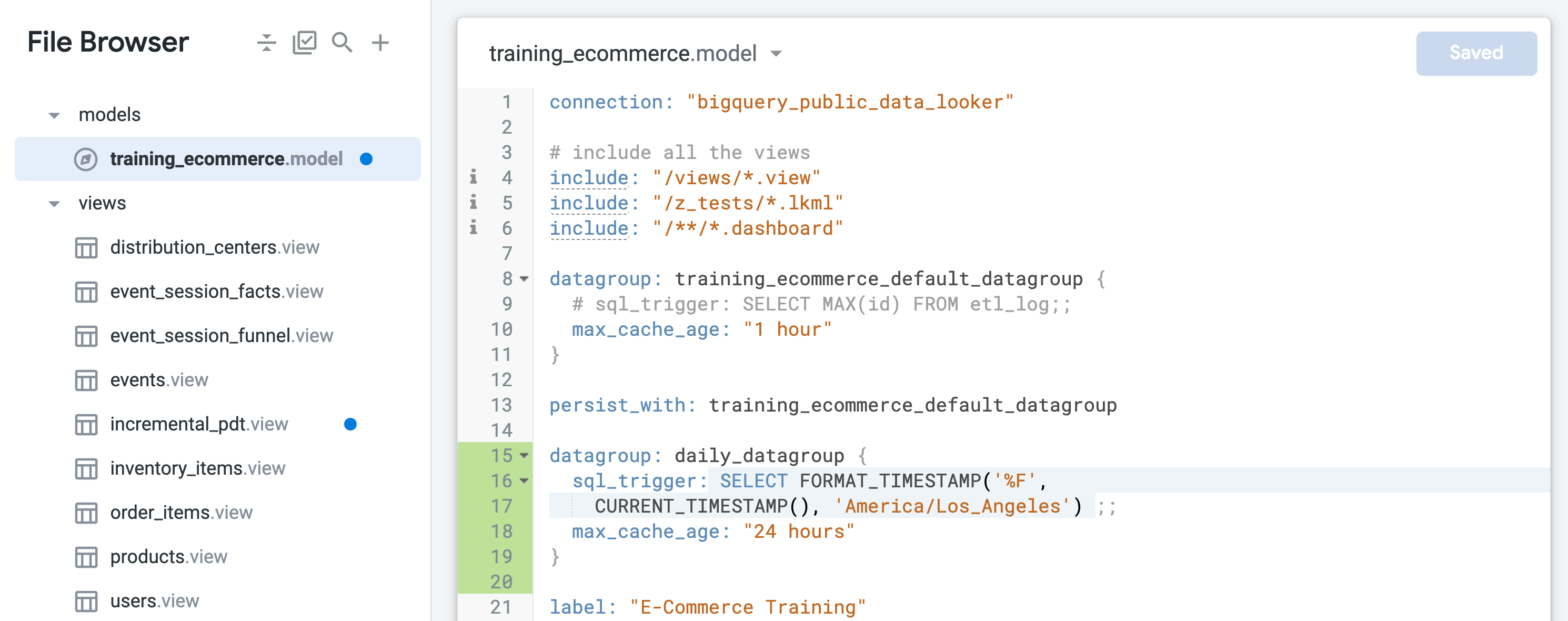
Suchen Sie die Standarddatengruppe mit dem Namen training_ecommerce_default_datagroup und fügen Sie eine neue Zeile ein (Zeile 13).
-
Definieren Sie eine neue Datengruppe, um Objekte mit einer täglichen Aktualisierung (mit einer maximalen Zeitspanne von 24 Stunden) persistent zu speichern:
datagroup: daily_datagroup {
sql_trigger: SELECT FORMAT_TIMESTAMP('%F',
CURRENT_TIMESTAMP(), 'America/Los_Angeles') ;;
max_cache_age: "24 hours"
}
Der sql_trigger prüft das aktuelle Datum und löst eine Aktualisierung aus, wenn sich das Datum ändert. max_cache_age sorgt dafür, dass die Tabelle nach 24 Stunden neu erstellt wird, selbst wenn der sql_trigger nicht erfolgreich ausgeführt wird.
- Definieren Sie am Ende von
training_ecommerce.model (etwa in Zeile 67) ein neues Explore, das nur die Ansicht incremental_pdt enthält, damit Sie es in den folgenden Schritten testen können:
explore: incremental_pdt {}
- Klicken Sie auf Änderungen speichern.
- Öffnen Sie incremental_pdt.view und fügen Sie der Definition der abgeleiteten Tabelle in Zeile 6 Persistenz hinzu, indem Sie die tägliche Datengruppe (daily_datagroup) einbinden:
datagroup_trigger: daily_datagroup
- Fügen Sie inkrementelle Aktualisierungen hinzu, indem Sie in der Definition der abgeleiteten Tabelle in den Zeilen 7 und 8 die folgenden Parameter einfügen:
increment_key: "created_date"
increment_offset: 3
- Klicken Sie auf Änderungen speichern. Die Datei sollte jetzt in etwa so aussehen:
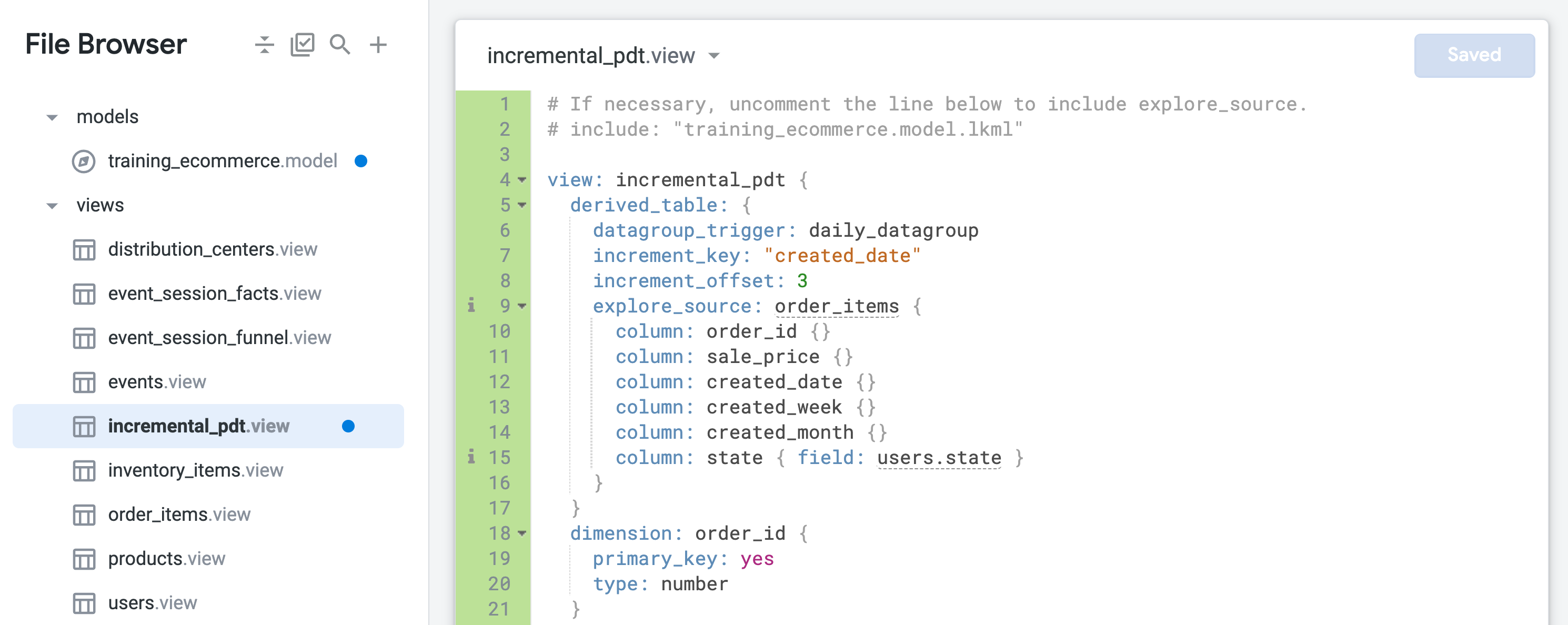
Die persistente abgeleitete Tabelle wird nun persistent gespeichert und einmal täglich neu erstellt. Dabei werden die letzten drei Tage berücksichtigt, um auch verspätet eingegangene Bestellungen zu erfassen.
- Schließen Sie den Browsertab für die ursprüngliche Explore-Abfrage, lassen Sie aber den Tab für die Looker-IDE geöffnet.
Explore-Abfragen für eine inkrementelle persistente abgeleitete Tabelle testen
-
Öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Gehen Sie zu Analysieren > Inkrementelle PTA.
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
-
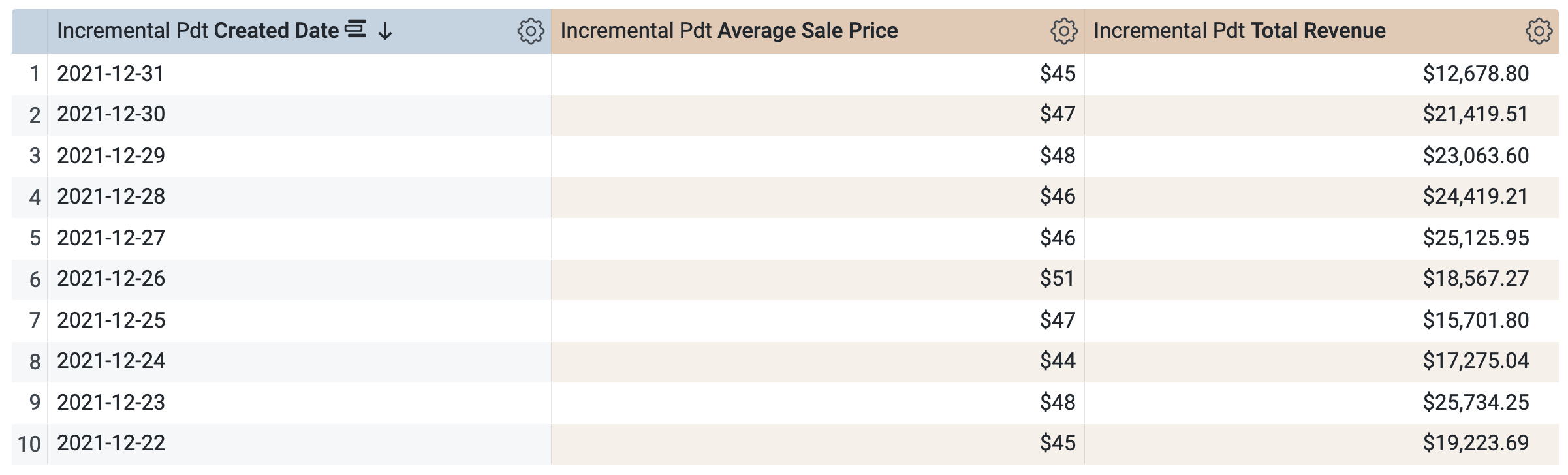
Wählen Sie unter Inkrementelle PAT > Dimensionen die Option Erstellungsdatum aus.
-
Wählen Sie unter Inkrementelle PAT > Messungen die Optionen Average Sale Price (Durchschnittlicher Verkaufspreis) und Total Revenue (Gesamtumsatz) aus.
Bevor Sie die Abfrage ausführen, sehen Sie sich das SQL-Fenster an. Dort werden zwei Abfragen angezeigt. Eventuell dauert es einige Sekunden, bis sie geladen werden. Die erste Abfrage generiert die PAT mit dem Namen incremental_pdt. Die zweite Abfrage ruft die Ergebnisse aus der neu erstellten PAT ab.
-
Klicken Sie auf Ausführen.
-
Öffnen Sie den Tab Ergebnisse, um die Ergebnisse zu sehen.
-
Unter Inkrementelle PTA > Dimensionen:
-
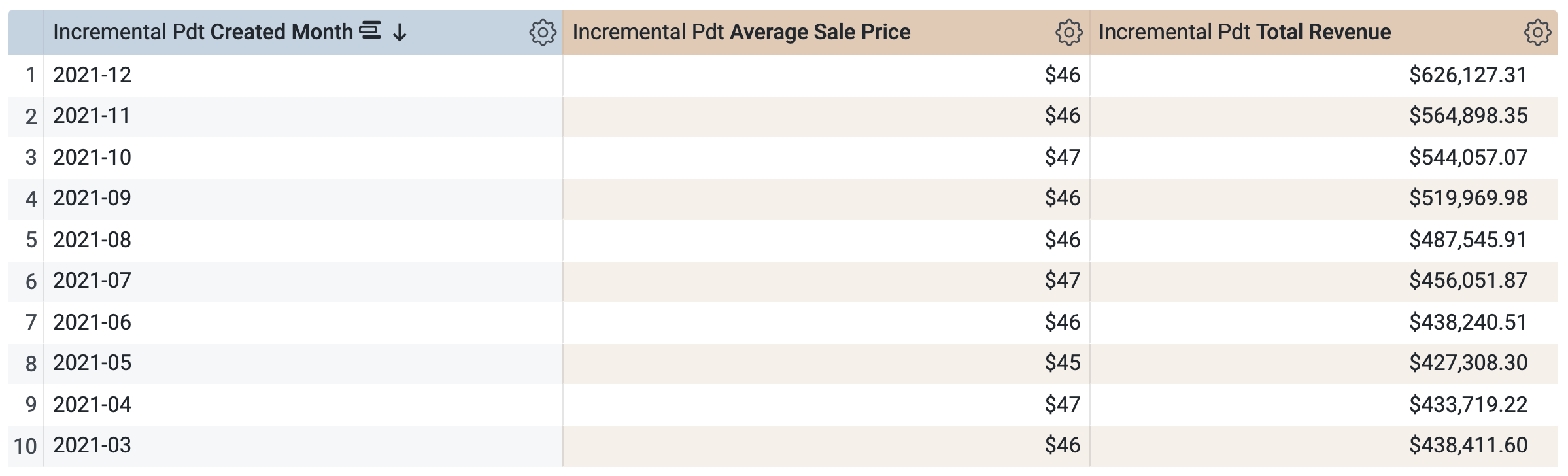
Löschen Sie Erstellungsdatum.
- Wählen Sie Erstellungsmonat aus.
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
Die Abfrage verwendet dieselbe PAT, um die Ergebnisse abzurufen. Das ist sinnvoll, da Sie Daten für einen Zeitraum abgefragt haben, der bereits in der PAT definiert (und im Cache gespeichert) ist. Sie können keine Abfrage für einen Zeitraum auswählen und ausführen, der noch nicht in der PAT verfügbar ist, z. B. Quartal oder Jahr.
-
Klicken Sie auf Ausführen.
-
Öffnen Sie den Tab Ergebnisse, um die Ergebnisse zu sehen.
Aufgabe
- Führen Sie eine neue Abfrage aus. Verwenden Sie dabei nur die Dimension State und die Messwerte Average Sale Price (Durchschnittlicher Verkaufspreis) und Total Revenue (Gesamtumsatz). Beantworten Sie die folgende Frage.
-
Schließen Sie den Browsertab für die Explore-Abfrage und kehren Sie zum Browsertab mit der Looker-IDE zurück.
-
Klicken Sie auf LookML validieren.
Es sollten keine LookML-Fehler auftreten.
Commit für Änderungen durchführen und für die Produktion bereitstellen
-
Klicken Sie auf LookML validieren und dann auf Commit für Änderungen durchführen und pushen.
-
Fügen Sie eine Commit-Nachricht hinzu und klicken Sie auf Commit durchführen.
-
Klicken Sie abschließend auf Für Produktion bereitstellen.
Bleiben Sie im Browsertab für die Looker-IDE, wenn Sie mit der nächsten Aufgabe beginnen.
Klicken Sie auf Fortschritt prüfen.
Inkrementelle persistente abgeleitete Tabelle erstellen
Aufgabe 2: Inkrementelle zusammengefasste Tabelle erstellen, um Bestelldaten über mehrere Zeiträume hinweg zusammenzufassen
In Looker können Sie strategisch zusammengefasste Tabellen erstellen, die die Anzahl der erforderlichen Abfragen für die großen Tabellen in einer Datenbank minimieren. Zusammengefasste Tabellen müssen persistent in Ihrer Datenbank gespeichert werden, damit sie für Aggregate Awareness zugänglich sind. Zusammengefasste Tabellen sind also eine Art persistenter abgeleiteter Tabelle (PAT).
Eine zusammengefasste Tabelle wird in Ihrem LookML-Projekt unter einem Explore-Parameter mit dem Parameter aggregate_table definiert. Nachdem Sie Ihre zusammengefassten Tabellen erstellt haben, können Sie Abfragen im Explore ausführen, um zu sehen, welche Tabellen Looker verwendet. Durch Aggregate Awareness findet Looker automatisch die kleinste und effizienteste zusammengefasste Tabelle in Ihrer Datenbank, die für die jeweilige Abfrage geeignet ist, ohne dabei die Accuracy zu beeinträchtigen.
In dieser Aufgabe erstellen Sie die inkrementelle PAT aus der vorherigen Aufgabe als inkrementelle zusammengefasste Tabelle neu. Außerdem stellen Sie die neue zusammengefasste Tabelle den Nutzern und Nutzerinnen zur Verfügung. Dazu verwenden Sie ein Refinement des vorhandenen Explores „order_items“.
Zusammengefasste Tabelle in einem Refinement eines vorhandenen Explores erstellen
-
Öffnen Sie auf der Seite der Looker-IDE die Datei training_ecommerce.model.
-
Fügen Sie am Ende der Datei (etwa in Zeile 69) den folgenden Code hinzu, um ein Refinement des Explores order_items zu erstellen:
explore: +order_items {
label: "Order Items - Aggregate Sales"
}
Dieses Refinement erweitert das vorhandene Explore order_items, das in der Modelldatei definiert ist, um die im neuen LookML-Code angegebenen Änderungen, z. B. das Label oder die zusammengefasste Tabelle, die Sie in den nächsten Schritten hinzufügen werden.
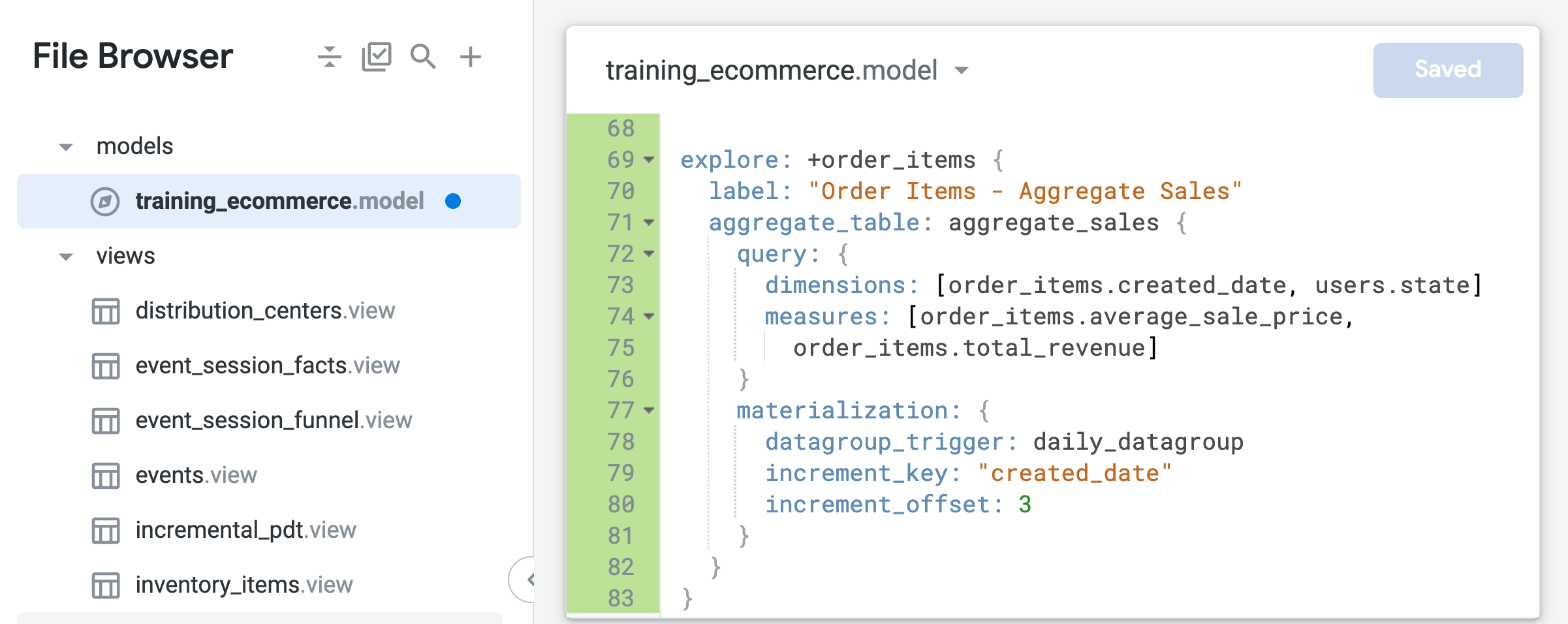
- Erweitern Sie den LookML-Code für das Refinement, um eine zusammengefasste Tabelle einzubinden, in der Bestelldaten nach Zeitraum oder Bundesland zusammengefasst werden:
explore: +order_items {
label: "Order Items - Aggregate Sales"
aggregate_table: aggregate_sales {
query: {
dimensions: [order_items.created_date, users.state]
measures: [order_items.average_sale_price,
order_items.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
Im Gegensatz zur nativen abgeleiteten Tabelle, die Sie in der vorherigen Aufgabe erstellt haben, ist in der zusammengefassten Tabelle nur die Zeitdimension created_date definiert. Mit Aggregate Awareness kann Looker diese eine Tabelle für Explore-Abfragen nutzen, die zeitaggregierte Werte wie durchschnittlichen Verkaufspreis oder Gesamtumsatz enthalten, unabhängig davon, ob die Abfrage Tages-, Monats- oder Jahreswerte betrifft.
- Klicken Sie auf Änderungen speichern.
Lassen Sie diesen Tab für die Looker-IDE geöffnet.
Explore-Abfragen für eine inkrementelle persistente zusammengefasste Tabelle testen
-
Öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Gehen Sie zu Explore > Order Items – Aggregate Sales (Analysieren > Bestellpositionen – Zusammengefasster Umsatz).
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
-
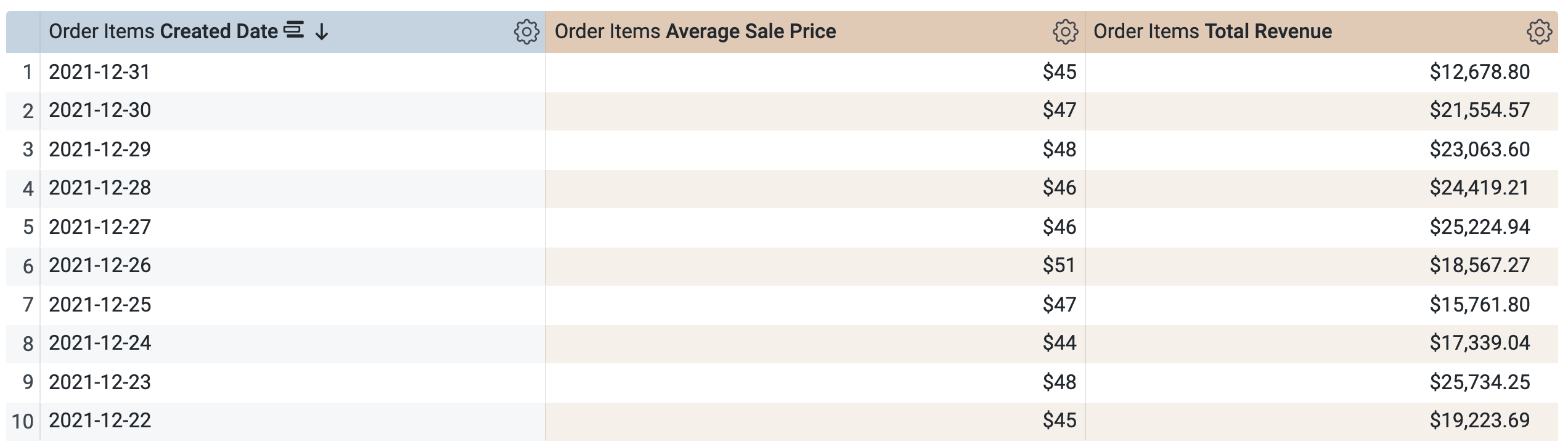
Wählen Sie unter Order Items > Dimensions (Bestellpositionen > Dimensionen) die Option Erstellungsdatum > Datum aus.
-
Klicken Sie unter Order Items > Measures (Bestellpositionen > Messungen) auf Average Sale Price (Durchschnittlicher Verkaufspreis) und Total Revenue (Gesamtumsatz).
Vor dem Ausführen der Abfrage beachten Sie, dass es auch hier zwei Abfragen gibt, ähnlich dem SQL-Fenster in Aufgabe 1. Die erste Abfrage generiert die PAT aggregate_sales und die zweite Abfrage ruft die Ergebnisse aus ihr ab.
-
Klicken Sie auf Ausführen.
-
Öffnen Sie den Tab Ergebnisse, um die Ergebnisse zu sehen.
-
Unter Order Items > Dimensions > Created Date (Bestellpositionen > Dimensionen > Erstellungsdatum):
-
Löschen Sie Datum.
- Wählen Sie Quartal aus.
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
Die Abfrage verwendet dieselbe PAT (aggregate_sales), um die Ergebnisse nach Quartal abzurufen. Looker wendet Aggregate Awareness an, um den durchschnittlichen Verkaufspreis und den Gesamtumsatz auf die angeforderten Zeiträume hochzuaggregieren, die unter „Erstellungsdatum“ verfügbar sind.
-
Klicken Sie auf Ausführen.
-
Öffnen Sie den Tab Ergebnisse, um die Ergebnisse zu sehen.
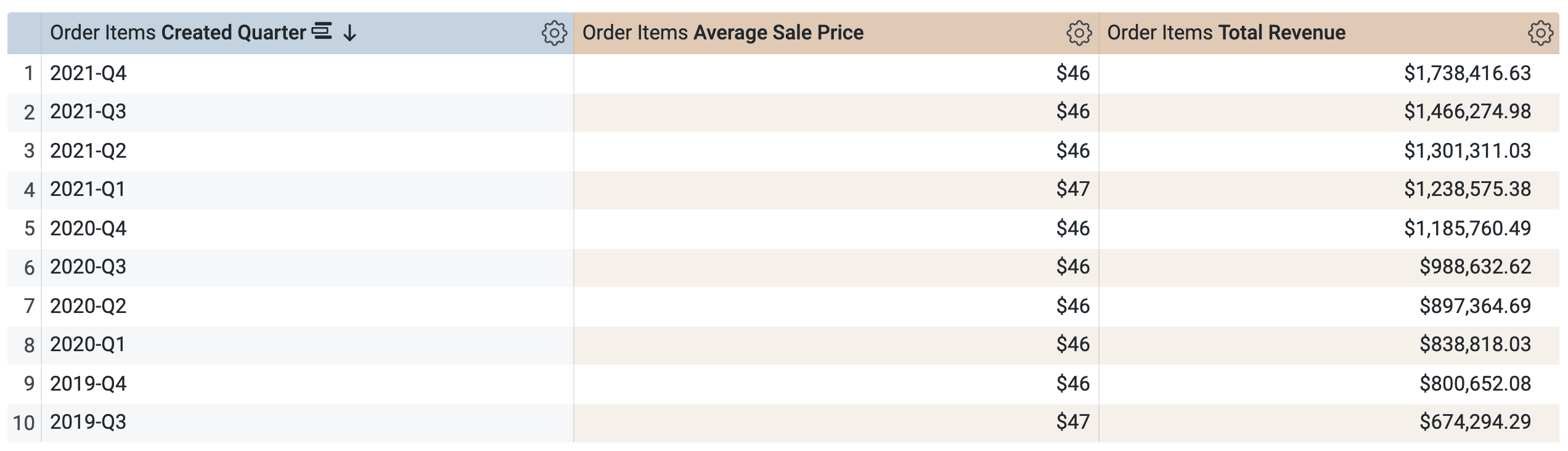
Aufgabe
- Führen Sie eine neue Abfrage aus. Verwenden Sie dabei nur die Dimension State (Bundesland) (unter „Nutzer“) und die Messwerte Average Sale Price (Durchschnittlicher Verkaufspreis) und Total Revenue (Gesamtumsatz). Beantworten Sie die folgende Frage.
- Führen Sie eine neue Abfrage aus. Verwenden Sie dabei nur die Dimension Country (Land) (unter „Nutzer“) und die Messwerte Average Sale Price (Durchschnittlicher Verkaufspreis) und Total Revenue (Gesamtumsatz). Beantworten Sie die folgende Frage.
-
Schließen Sie den Browsertab für die Explore-Abfrage und kehren Sie zum Browsertab mit der Looker-IDE zurück.
-
Klicken Sie auf LookML validieren. Es sollten keine LookML-Fehler auftreten.
Commit für Änderungen durchführen und für die Produktion bereitstellen
-
Klicken Sie auf LookML validieren und dann auf Commit für Änderungen durchführen und pushen.
-
Fügen Sie eine Commit-Nachricht hinzu und klicken Sie auf Commit durchführen.
-
Klicken Sie abschließend auf Für Produktion bereitstellen.
Bleiben Sie im Browsertab für die Looker-IDE, wenn Sie mit der nächsten Aufgabe beginnen.
Klicken Sie auf Fortschritt prüfen.
Zusammengefasste Tabelle erstellen
Aufgabe 3: Ansichten effizient einbinden, um Explore-Abfragen zu optimieren
Um leistungsstarke Explores in Looker zu definieren, sind effiziente Joins unerlässlich. Um die Effizienz von Joins zu verbessern, sollten Sie nur die Ansichten einbinden, die zum Definieren des Explores erforderlich sind, Basisfelder (anstatt verkettete Felder) als Primärschlüssel für die Ansichten verwenden und nach Möglichkeit many_to_one-Joins verwenden.
Wie in der Dokumentation beschrieben, liefern Primärschlüssel eine eindeutige Kennung für Einträge in einer Ansicht und sind für genaue Aggregationen und Beziehungen in Looker unerlässlich. Der Primärschlüssel für eine Ansicht ist ein Feld mit eindeutigen Werten (z. B. eine ID-Spalte). Er wird in der Ansichtsdatei mit dem Parameter primary_key: yes angegeben.
In diesem Abschnitt ermitteln Sie zuerst die Spalte, die sich am besten als Primärschlüssel für eine Ansicht eignet. Anschließend definieren Sie einen neuen Explore für die zusammengefasste Tabelle, in das nur die Ansicht „users“ (Nutzer) eingebunden ist. Mit dem Parameter „from“ (von) geben Sie order_items als Basisansicht des Explores an und binden dann die Ansicht „users“ ein. Schließlich lassen Sie die zusätzlichen Joins weg, die im vorhandenen Explore „order_items“ enthalten sind, und verwenden die many_to_one-Join-Beziehung, um die Abfrageeffizienz zu verbessern.
Das Feld identifizieren, das am besten als Primärschlüssel einer Ansicht geeignet ist
- Öffnen Sie die Datei users.view. Beantworten Sie die folgende Frage.
In „users.view“ ist die Spalte „ID“ bereits mit primary_key: yes als Primärschlüssel gekennzeichnet. Es ist ein Basisfeld, das eindeutige Werte enthält (eine ID pro Nutzer*in) und kein verkettetes Feld, das aus mehreren Spalten erstellt wurde. Daher ist „ID“ die beste Wahl als Primärschlüssel der Ansicht „users“. Sie kann effiziente Joins unterstützen.
- Öffnen Sie die Datei order_items.view. Beantworten Sie die folgende Frage.
Die order_item_id basiert auf der ID-Spalte in der Tabelle order_items und ist als Primärschlüssel gekennzeichnet. Andere ID-Felder in dieser Ansicht könnten jedoch auch als eindeutiger Schlüssel der Tabelle verwendet werden, darunter order_id, das auf der Spalte order_id in der Tabelle order_items basiert.
In den nächsten Schritten analysieren Sie die Tabelle order_items im SQL-Runner, um herauszufinden, warum order_item_id das beste Feld für den Primärschlüssel ist.
-
Öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Gehen Sie zu Entwickeln > SQL-Runner.
-
Klicken Sie neben „Verbindung“ auf Einstellungen () und wählen Sie Search public projects (Öffentliche Projekte durchsuchen) aus.
-
Das Feld für „Projekt“ ist jetzt leer. Geben Sie cloud-training-demos ein und drücken Sie die Eingabetaste.
-
Wählen Sie als Dataset looker_ecomm aus.
Es wird eine Liste der verfügbaren Tabellen in diesem BigQuery-Dataset angezeigt.
Eine schnelle und einfache Methode, um zu prüfen, ob eine Spalte als Primärschlüssel geeignet ist, besteht darin, die Anzahl der Einträge in der Tabelle mit der Anzahl der eindeutigen Werte in der Spalte zu vergleichen. Wenn beide Zahlen übereinstimmen, enthält die Spalte eindeutige Werte und ist ein geeigneter Primärschlüssel für die Tabelle.
- Fügen Sie die folgende Abfrage in das Fenster „SQL-Abfrage“ ein und klicken Sie auf Ausführen, um zu prüfen, ob die Spalte
user_id als Primärschlüssel geeignet ist:
SELECT count(*), count(distinct user_id)
FROM cloud-training-demos.looker_ecomm.order_items
- Wiederholen Sie die Abfrage für die Spalten
order_id, inventory_item_id und id.
In diesem Fall stimmten sowohl id als auch inventory_item_id mit der Anzahl der Einträge in der Tabelle überein, da es sich um unterschiedliche IDs für denselben Artikel innerhalb einer Bestellung handelt. Beide könnten also als Primärschlüssel verwendet werden.
Die Spalte id wurde als Primärschlüssel für order_items ausgewählt, da sie die generierte ID für einen Artikel in der Tabelle order_items ist. Allerdings ist inventory_item_id die ID desselben Artikels in der Tabelle inventory_items.
- Schließen Sie den Browsertab für SQL-Runner und kehren Sie zum Browsertab mit der Looker-IDE zurück.
Mindestanzahl an Ansichten zusammenführen, um neue Explores zu definieren
-
Öffnen Sie training_ecommerce.model.
-
Sehen Sie sich das vorhandene Explore order_items an.
Es enthält vier verschiedene Joins, die alle den Beziehungstyp many_to_one verwenden. Je nach Anwendungsfall können alle diese Joins erforderlich sein. Was aber, wenn Sie nur die Nutzer- und Bestelldaten nach Bundesland oder Zeitraum zusammenfassen möchten? In diesem Fall würden diese zusätzlichen Joins nie verwendet werden und die Abfragen im Explore verlangsamen.
In den nächsten Schritten erstellen Sie ein neues Explore, das nur die Bestell- und Nutzerdaten auf der Grundlage von user_id in der Ansicht order_items und id in der Ansicht users zusammenführt.
- Fügen Sie am Ende der Datei (etwa in Zeile 85) den folgenden Code ein, um ein neues Explore mit
order_items als Basisansicht und nur der Ansicht „users“ als Join zu definieren:
explore: aggregated_orders {
from: order_items
label: "Aggregated Sales"
join: users {
type: left_outer
sql_on: ${aggregated_orders.user_id} = ${users.id} ;;
relationship: one_to_many
}
aggregate_table: aggregate_sales {
query: {
dimensions: [aggregated_orders.created_date,
users.state]
measures: [aggregated_orders.average_sale_price,
aggregated_orders.total_revenue]
}
materialization: {
datagroup_trigger: daily_datagroup
increment_key: "created_date"
increment_offset: 3
}
}
}
- Klicken Sie auf Änderungen speichern.
Die Datei sollte jetzt in etwa so aussehen:
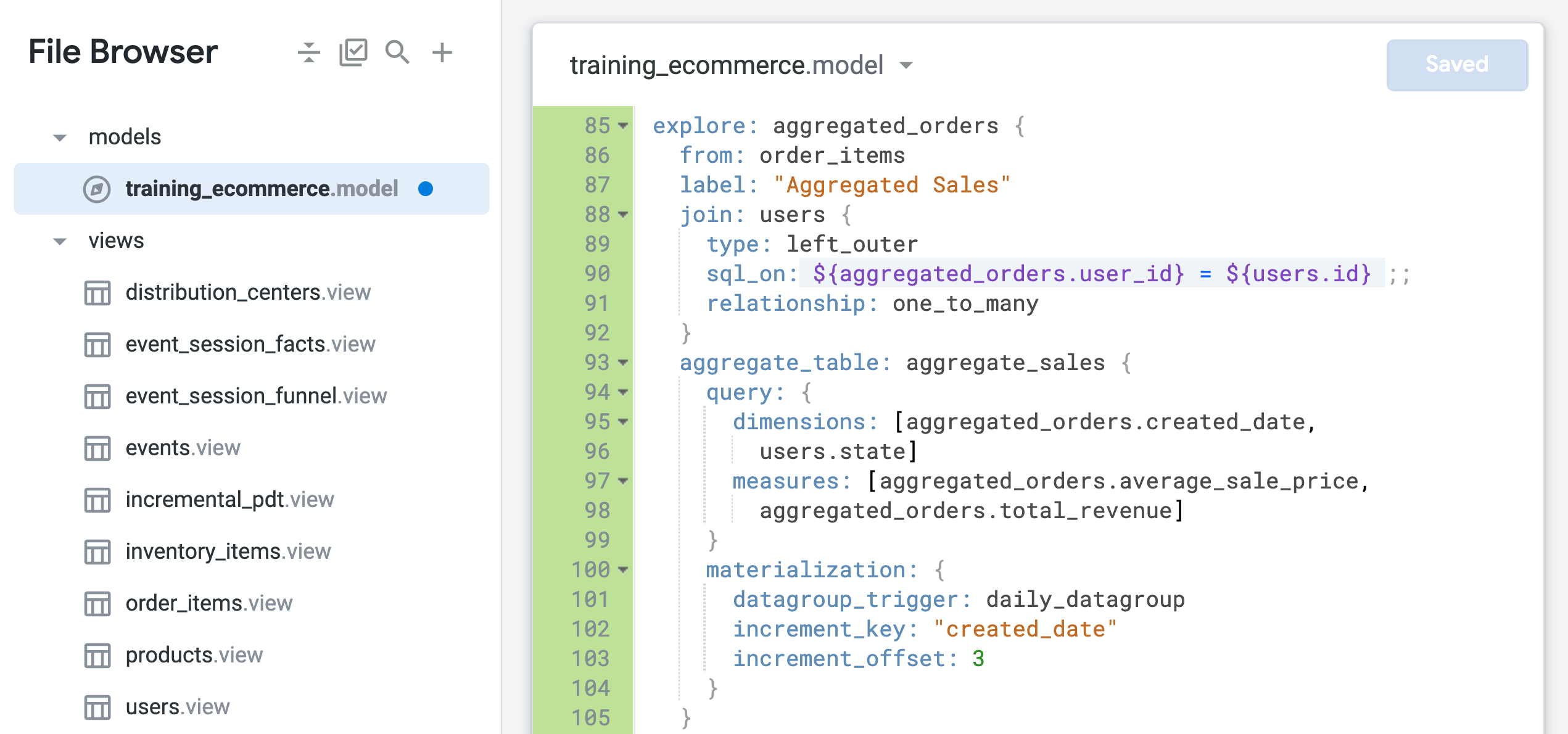
Mit dem Parameter from wird order_items als Basisansicht des Explores definiert, mit der die Ansicht „users“ verknüpft wird. Die Felder in der Ansicht order_items werden jetzt mit dem Namen des neuen Explores als aggregated_orders.fieldname referenziert.
Die Beziehung zwischen der Ansicht users und der Ansicht order_items ist derzeit als one_to_many (1:n-Beziehung) definiert. In den nächsten Schritten testen Sie, ob dieser Join auf der Grundlage einer one_to_many-Beziehung die optimale Konfiguration für dieses Explore ist.
Leistungsstarke Join-Beziehungen für effiziente Explore-Abfragen definieren
-
Öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Gehen Sie zu Explore > Aggregated Sales (Analysieren > Zusammengefasster Umsatz).
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
-
Wählen Sie unter Aggregated Orders > Dimensions (Zusammengefasste Bestellungen > Dimensionen) die Option Erstellungsdatum > Datum aus.
-
Wählen Sie unter Aggregated Orders > Measures (Zusammengefasste Bestellungen > Messungen) Folgendes aus:
-
Average Sale Price (Durchschnittlicher Verkaufspreis)
-
Total Revenue (Gesamtumsatz)
Bevor Sie die Abfrage ausführen, beachten Sie, dass die zusammengefasste Tabelle aufgrund eines Problems mit einem Join-Fanout nicht verwendet wird:
-- Did not use aggregated_orders::aggregate_sales; field aggregated_orders.average_sale_price was DISTINCT in the table due to a join fanout, but there was no fanout in the query
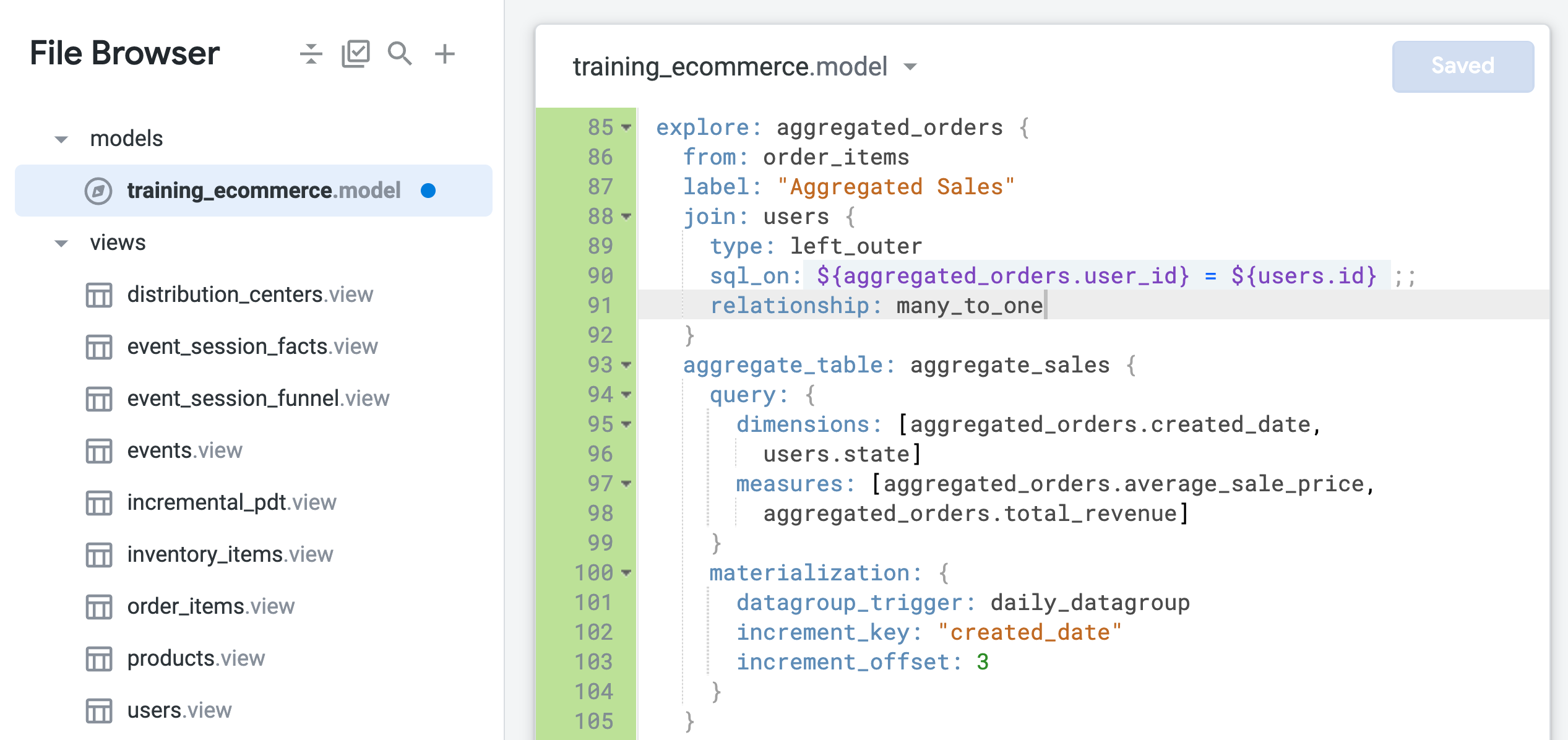
Ein unbeabsichtigter Fanout kann auftreten, wenn die Beziehung zwischen zwei Tabellen für einen Join nicht korrekt definiert ist. In diesem Fall ist order_items die Basisansicht des Explores, die viele Bestellungen pro Nutzer*in enthalten kann. Die Ansicht users enthält jedoch nur einen Eintrag pro Nutzer*in.
Daher sollte dieser Join als many_to_one und nicht als „one_to_many“ definiert werden. Weitere Informationen zum Problem der Fanouts finden Sie in der Looker-Hilfe.
-
Klicken Sie auf Ausführen.
-
Öffnen Sie den Tab „Ergebnisse“.
Die Ergebnisse werden zurückgegeben. Looker hat aber nicht die effiziente zusammengefasste Tabelle verwendet, um sie abzurufen.
-
Lassen Sie diesen Browsertab für das Explore geöffnet und kehren Sie zum Browsertab mit der Looker-IDE zurück.
-
Ändern Sie den Beziehungsparameter im Explore „aggregated_orders“ zu many_to_one (Zeile 91):
relationship: many_to_one
- Klicken Sie auf Änderungen speichern.
Die Datei sollte jetzt in etwa so aussehen:
-
Kehren Sie zum Browsertab für die Explore-Abfrage zurück und aktualisieren Sie die Seite.
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
Ähnlich wie beim SQL-Tab für die Aufgaben 1 und 2 gibt es jetzt zwei Abfragen: Die erste generiert die PAT und die zweite ruft Ergebnisse aus der PAT ab.
- Öffnen Sie den Tab „Ergebnisse“, um die Ergebnisse zu sehen.
-
Schließen Sie den Browsertab für die Explore-Abfrage und kehren Sie zum Browsertab mit der Looker-IDE zurück.
-
Klicken Sie auf LookML validieren.
Es sollten keine LookML-Fehler auftreten.
Commit für Änderungen durchführen und für die Produktion bereitstellen
-
Klicken Sie auf LookML validieren und dann auf Commit für Änderungen durchführen und pushen.
-
Fügen Sie eine Commit-Nachricht hinzu und klicken Sie auf Commit durchführen.
-
Klicken Sie abschließend auf Für Produktion bereitstellen.
Bleiben Sie im Browsertab für die Looker-IDE, wenn Sie mit der nächsten Aufgabe beginnen.
Klicken Sie auf Fortschritt prüfen.
Mindestanzahl von Ansichten mit neuen Explores verknüpfen
Aufgabe 4: Builds persistenter abgeleiteter Tabellen in einer Looker-Instanz überwachen
Über die Seite „Persistente abgeleitete Tabellen“ im Admin-Menü können Sie in Looker die Builds von PATs in einer Looker-Instanz überwachen. Je nach Looker-Konfiguration können Looker-Nutzer mit Berechtigungen zum persistenten Speichern von Tabellen diese Seite auch ohne Zugriff auf das vollständige Admin-Menü aufrufen. Sie können den Status, die Build-Dauer und das Caching von PATs sowohl in Ihrer Entwicklungs- als auch in Ihrer Produktionsumgebung einsehen und PATs in Ihrer Looker-Instanz so einfach testen und überwachen.
In dieser Aufgabe überwachen Sie die in diesem Lab erstellten PATs hinsichtlich Status, Build-Dauer, Caching und dem Unterschied zwischen Produktion und Entwicklung. Die inkrementelle PAT, die aus der NAT (Aufgabe 1) erstellt wurde, sollte die längste Build-Dauer haben, und zusammengefasste Tabellen (Aufgaben 2 und 3) die kürzeste. Das liegt daran, dass sie dieselbe Tabellendefinition verwenden, aber in unterschiedlich konfigurierten Explores enthalten sind. Außerdem ändern Sie eine PAT in der Entwicklung und überwachen ihren Status vor und nach dem Übertragen in die Produktion.
Status von PATs in der Produktion prüfen
-
Öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Gehen Sie zu Admin > Persistente abgeleitete Tabellen.
Auf dem Tab „Entwicklung“ werden keine PATs aufgeführt, da alle Ihre PATs in die Produktion übertragen wurden.
-
Öffnen Sie den Tab Produktion, um die PATs zu sehen, die Sie in den Aufgaben 1 bis 3 erstellt haben.
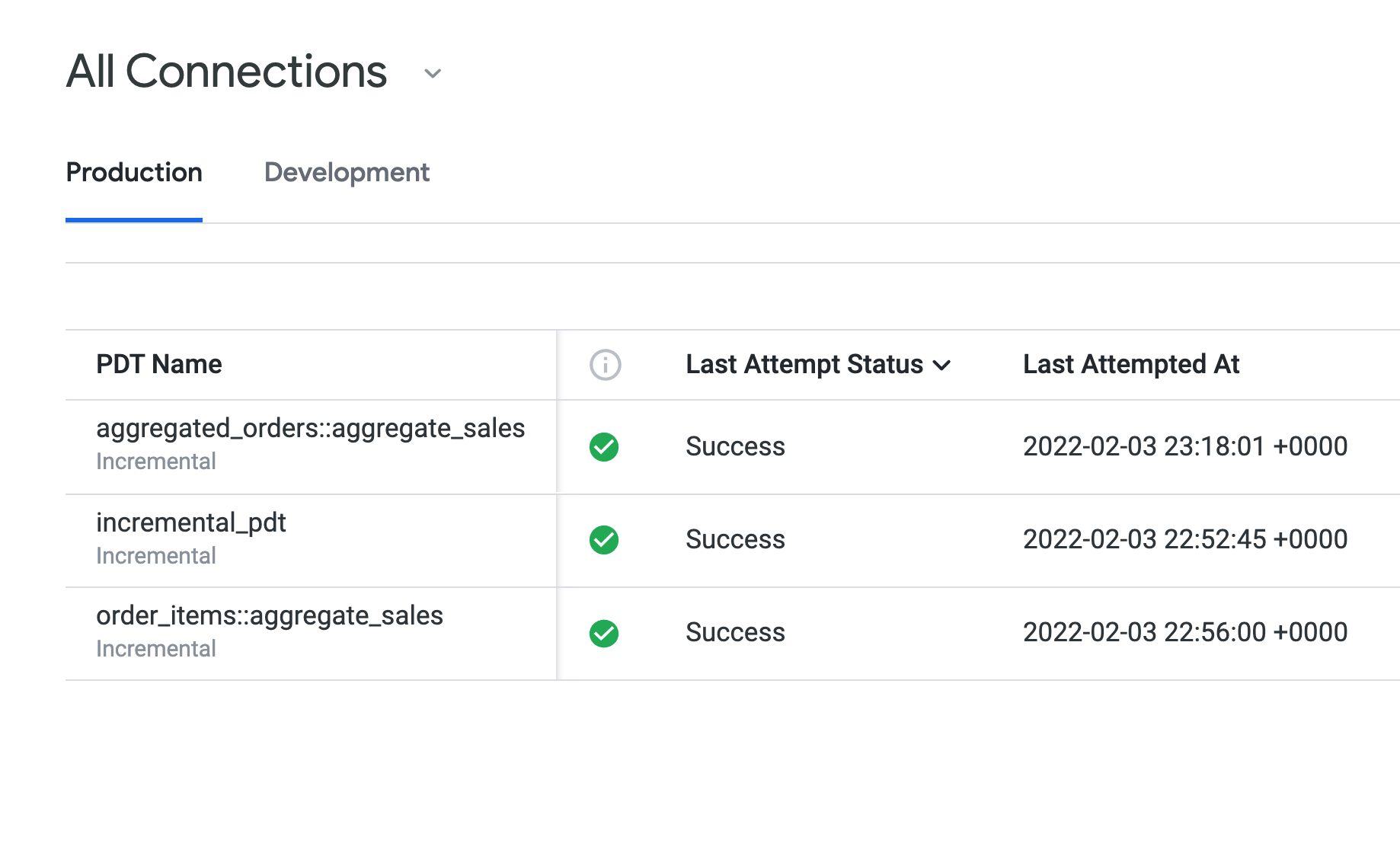
Unter Status des letzten Versuchs wird für alle PATs Erfolgreich angezeigt. Außerdem wird für alle dieselbe Persistenzregel (daily_datagroup) verwendet. Unter „Letzte Build-Dauer“ sieht es so aus, als hätte die incremental_pdt eine etwas längere Build-Dauer als die beiden zusammengefassten Tabellen.
Lassen Sie die Seite Persistente abgeleitete Tabellen geöffnet, wenn Sie mit den nächsten Schritten fortfahren.
PATs in der Entwicklung ändern und überprüfen
-
Kehren Sie zum Browsertab mit der Looker-IDE zurück.
-
Öffnen Sie training_ecommerce.model.
-
Fügen Sie dem Explore aggregated_orders eine neue Dimension für users.country hinzu (etwa Zeile 96):
dimensions: [aggregated_orders.created_date, users.state, users.country]
-
Klicken Sie auf Änderungen speichern.
-
Kehren Sie zur Seite Persistente abgeleitete Tabellen zurück und aktualisieren Sie sie.
Auf dem Tab „Produktion“ wird die PAT aggregated_orders::aggregate_sales weiterhin als erstellt aufgeführt, obwohl Sie ihren LookML-Code im Entwicklungsmodus geändert haben.
Mit Looker lassen sich Änderungen an PATs im Entwicklungsmodus testen, genau wie bei anderen Looker-Objekten. Werden im Entwicklungsmodus z. B. neue Dimensionen und Messwerte erstellt, sind diese neuen Objekte erst in der Produktion sichtbar, nachdem ein Commit für die Änderungen durchgeführt und sie in der Produktion bereitgestellt wurden.
- Öffnen Sie den Tab Entwicklung.
-
Lassen Sie die Seite Persistente abgeleitete Tabellen geöffnet und öffnen Sie in einem neuen Browsertab ein neues Looker-Fenster.
-
Gehen Sie zu Explore > Aggregate Sales (Analysieren > Zusammengefasster Umsatz).
-
Öffnen Sie im Bereich „Daten“ den Tab SQL.
-
Wählen Sie unter Nutzer > Dimensionen die Option Land aus.
-
Wählen Sie unter Aggregated Orders > Measures (Zusammengefasste Bestellungen > Messungen) Folgendes aus:
-
Average Sale Price (Durchschnittlicher Verkaufspreis)
-
Total Revenue (Gesamtumsatz)
Auf dem SQL-Tab sehen Sie zwei Abfragen: Die erste generiert die PAT und die zweite ruft die Ergebnisse aus ihr ab.
-
Klicken Sie auf Ausführen.
-
Öffnen Sie den Tab „Ergebnisse“, um die Ergebnisse zu sehen.
-
Schließen Sie den Browsertab für die Explore-Abfrage, kehren Sie zum Browsertab mit der Seite Persistente abgeleitete Tabellen zurück und aktualisieren Sie die Seite.
Auf dem Tab „Entwicklung“ wird jetzt angezeigt, dass aggregated_orders::aggregate_sales erfolgreich erstellt wurde.
-
Lassen Sie den Browsertab mit der Seite „Persistente abgeleitete Tabellen“ geöffnet und kehren Sie zum Browsertab mit der Looker-IDE zurück.
-
Klicken Sie auf LookML validieren.
Es liegen keine LookML-Fehler vor.
Commit für Änderungen durchführen und für die Produktion bereitstellen
-
Klicken Sie auf LookML validieren und dann auf Commit für Änderungen durchführen und pushen.
-
Fügen Sie eine Commit-Nachricht hinzu und klicken Sie auf Commit durchführen.
-
Klicken Sie abschließend auf Für Produktion bereitstellen.
Kehren Sie zum Browsertab mit der Seite „Persistente abgeleitete Tabellen“ zurück und aktualisieren Sie die Seite. Nachdem die Änderungen in der Produktion bereitgestellt wurden, wird die PAT aggregated_orders::aggregate_sales nicht mehr auf dem Tab „Entwicklung“, sondern nur noch auf dem Tab „Produktion“ aufgeführt.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
In diesem Lab haben Sie gelernt, wann und wie Sie abgeleiteten Tabellen Persistenz und inkrementelle Aktualisierungen hinzufügen. Außerdem wissen Sie jetzt, wie Sie Aggregat Awareness verwenden, Ansichten effizient einbinden und die Builds von PATs überwachen, um Looker-Abfragen zu optimieren.
Weitere Informationen
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 23. April 2024 aktualisiert
Lab zuletzt am 6. Oktober 2023 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





