GSP935

Visão geral
O Looker é uma plataforma de dados moderna no Google Cloud que permite analisar e visualizar dados de forma interativa. Ele pode ser usado para fazer análises de dados detalhadas, integrar insights entre diferentes fontes de dados, gerar fluxos de trabalho úteis orientados por dados e criar aplicativos de dados personalizados.
Neste laboratório, você vai aprender a usar tabelas derivadas nativas para responder a perguntas complexas, resolver casos de uso avançados e personalizá-los usando parâmetros integrados.
O que você vai aprender
Você vai aprender o seguinte:
- Crie tabelas derivadas nativas para responder a perguntas complexas usando colunas derivadas.
- Atualize uma tabela derivada nativa para gerar valores dinâmicos usando parâmetros de filtro integrados.
- Entenda como os usuários comerciais aproveitam as tabelas derivadas nativas personalizadas para responder a perguntas complexas.
Pré-requisitos:
Para maximizar seu aprendizado, é necessário ter familiaridade com o LookML. Recomendamos que você conclua o curso do selo de habilidade Conceitos básicos do LookML no Looker antes de começar este laboratório.
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O cronômetro começa ao clicar em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça, depois de começar, não será possível pausar o laboratório.
Observação: não use seu projeto ou conta pessoal do Google Cloud neste laboratório para evitar cobranças extras.
Como iniciar o laboratório e fazer login no Looker
-
Quando tudo estiver pronto, clique em Começar o laboratório.
O painel "Detalhes do laboratório" aparece com as credenciais temporárias que você precisa usar neste laboratório.
Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Confira suas credenciais do laboratório no painel "Detalhes do laboratório". É com elas que você vai fazer login na instância do Looker neste laboratório.
Observação: se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Clique em Abrir o Looker.
-
Digite o nome de usuário e a senha fornecidos nos campos E-mail e Senha.
Nome de usuário:
{{{looker.developer_username | Username}}}
Senha:
{{{looker.developer_password | Password}}}
Importante: é necessário usar as credenciais do painel "Detalhes do laboratório" nesta página. Não use suas credenciais do Google Cloud Ensina. Se você tiver uma conta pessoal do Looker, não a use neste laboratório.
-
Clique em Fazer login.
Depois de se conectar, você verá a instância do Looker deste laboratório.
Tarefa 1: personalizar tabelas derivadas nativas usando colunas derivadas
As tabelas derivadas nativas executam a mesma função que uma consulta SQL escrita, mas são expressas nativamente na linguagem LookML.
Por que usar tabelas derivadas nativas? Pense na tabela derivada em SQL user_facts que você criou no laboratório anterior. Você fez uma COUNT de IDs de pedidos como lifetime_order_count e uma SUM de sale_price como lifetime_revenue. Essas agregações já existem no seu modelo como medidas. Sua visualização order_items já tem order_count e total_sales.
As tabelas derivadas nativas são ótimas porque incorporam o princípio principal do LookML de reutilização. Elas permitem herdar dimensões, medições e até mesmo análises detalhadas e lógica de mesclagem. Isso torna seu modelo muito mais fácil de manter a longo prazo, já que você está minimizando o número de referências de banco de dados "codificadas".
Nesta seção, você vai criar a tabela derivada nativa brand_order_facts, que contém uma coluna derivada para classificar as marcas por receita total e pode ser filtrada usando um período dinâmico e/ou entradas do usuário. Você também vai criar novas dimensões que rotulam as linhas como estando entre as cinco principais marcas ou não (ou seja, agrupar todas as marcas classificadas em 6º lugar ou mais como um nome de marca "6) Outras").
Criar uma tabela derivada nativa que classifique as cinco principais marcas por venda total
-
Na parte de baixo à esquerda da interface do Looker, clique no botão ativar/desativar para entrar no Modo de Desenvolvimento.
-
No menu de navegação do Looker, clique em Explorar.
-
Em E-Commerce Training, clique em Order Items.
-
Na visualização Inventory Items, clique na dimensão Product Brand.
-
Na visualização Order Items, clique na métrica Total Revenue.
-
Clique em Executar.
-
Clique no ícone de engrenagem ( ) ao lado de Executar (canto superior direito da página) e selecione Acessar o LookML.
) ao lado de Executar (canto superior direito da página) e selecione Acessar o LookML.
-
Acesse a guia Derived Table, clique no código do LookML na caixa e copie-o para a área de transferência.
-
Acesse o ambiente de desenvolvimento integrado do Looker (Develop > qwiklabs-ecommerce), clique no ícone de adição (+) ao lado de "File Browser" e escolha Create View.
-
Nomeie a nova visualização como brand_order_facts e clique em Create.
-
Clique em brand_order_facts.view e arraste para a pasta views.
-
Apague todo o código de amostra gerado automaticamente e cole o código copiado da análise detalhada. Não se esqueça de corrigir o nome da visualização gerado automaticamente para brand_order_facts. Sua visualização será semelhante a esta:
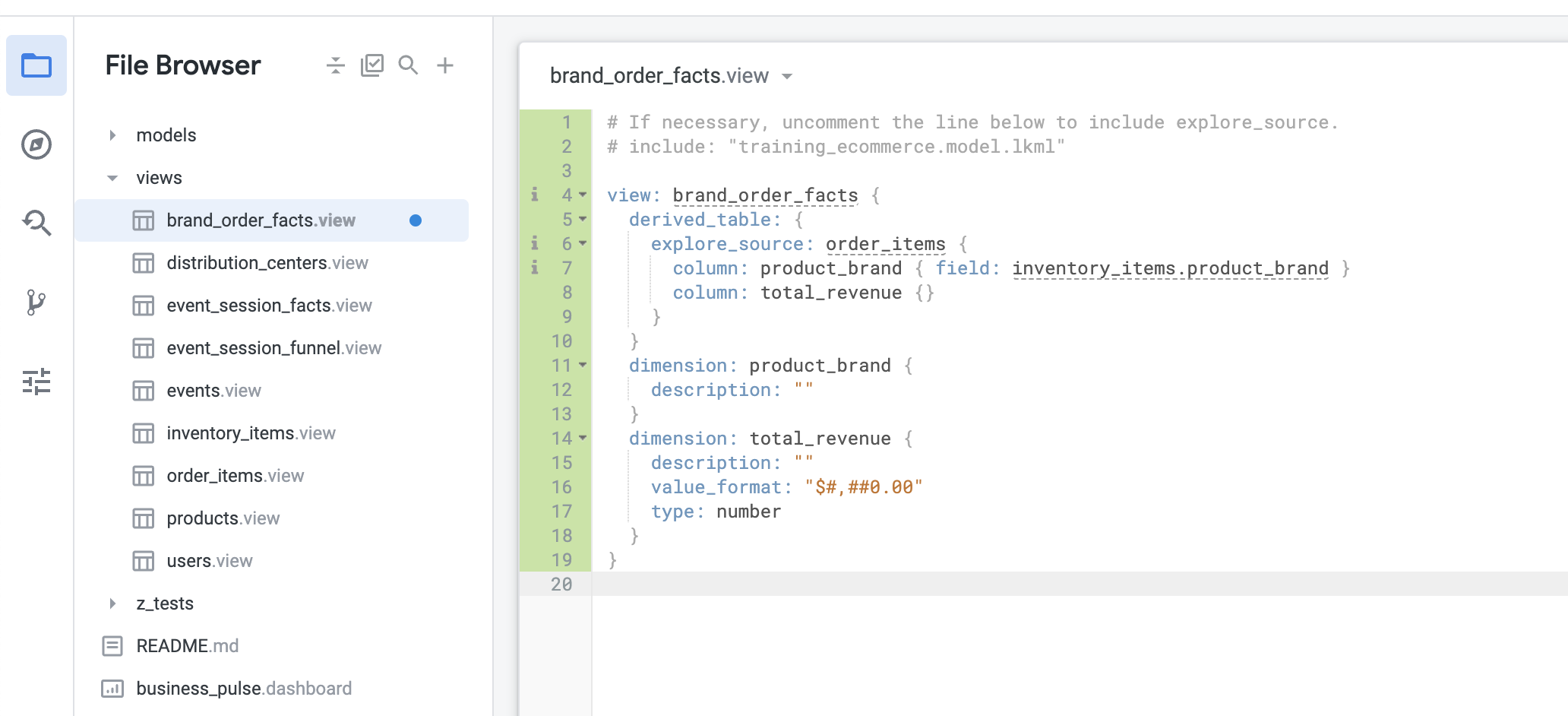
- Clique em Salvar alterações.
Adicionar uma coluna derivada de classificação da marca
Agora você tem a base para sua tabela derivada nativa. A próxima tarefa é classificar as marcas. Isso pode ser feito na maioria dos dialetos SQL usando uma função chamada ROW_NUMBER().
Para isso, adicione uma derived_column à explore_source das tabelas derivadas nativas. Em uma tabela derivada nativa, é possível usar derived_column para especificar uma coluna que ainda não existe na Análise especificada pelo parâmetro explore_source. Para este exemplo, vamos chamar essa coluna de brand_rank.
- Na definição
column: total_revenue {}, comece definindo a coluna derivada brand_rank:
derived_column: brand_rank {}
- Em seguida, nas chaves, adicione o seguinte parâmetro SQL:
derived_column: brand_rank {
sql: row_number() over (order by total_revenue desc) ;;
}
Sempre que você cria uma coluna derivada, também precisa adicionar uma dimensão a ela. É o mesmo que quando você tem uma coluna na tabela de banco de dados comum. A coluna precisa ser representada em LookML como uma dimensão. Você percebeu que as dimensões geradas automaticamente não têm um parâmetro SQL? Isso acontece porque, quando você não especifica o SQL de uma dimensão, o Looker pressupõe que ele deve apontar para uma coluna nos dados subjacentes com o mesmo nome da dimensão. Isso pode ser um atalho útil para outras áreas do seu projeto, se você quiser. No entanto, é recomendável ser explícito sempre que possível. Nesse caso, especifique pelo menos o tipo. Caso contrário, o Looker vai usar a string como padrão, o que não é o que você quer.
- Fora da definição derived_table, logo acima da dimensão
product_brand, adicione este código:
dimension: brand_rank {
type: number
}
A nova visualização será parecida com esta:
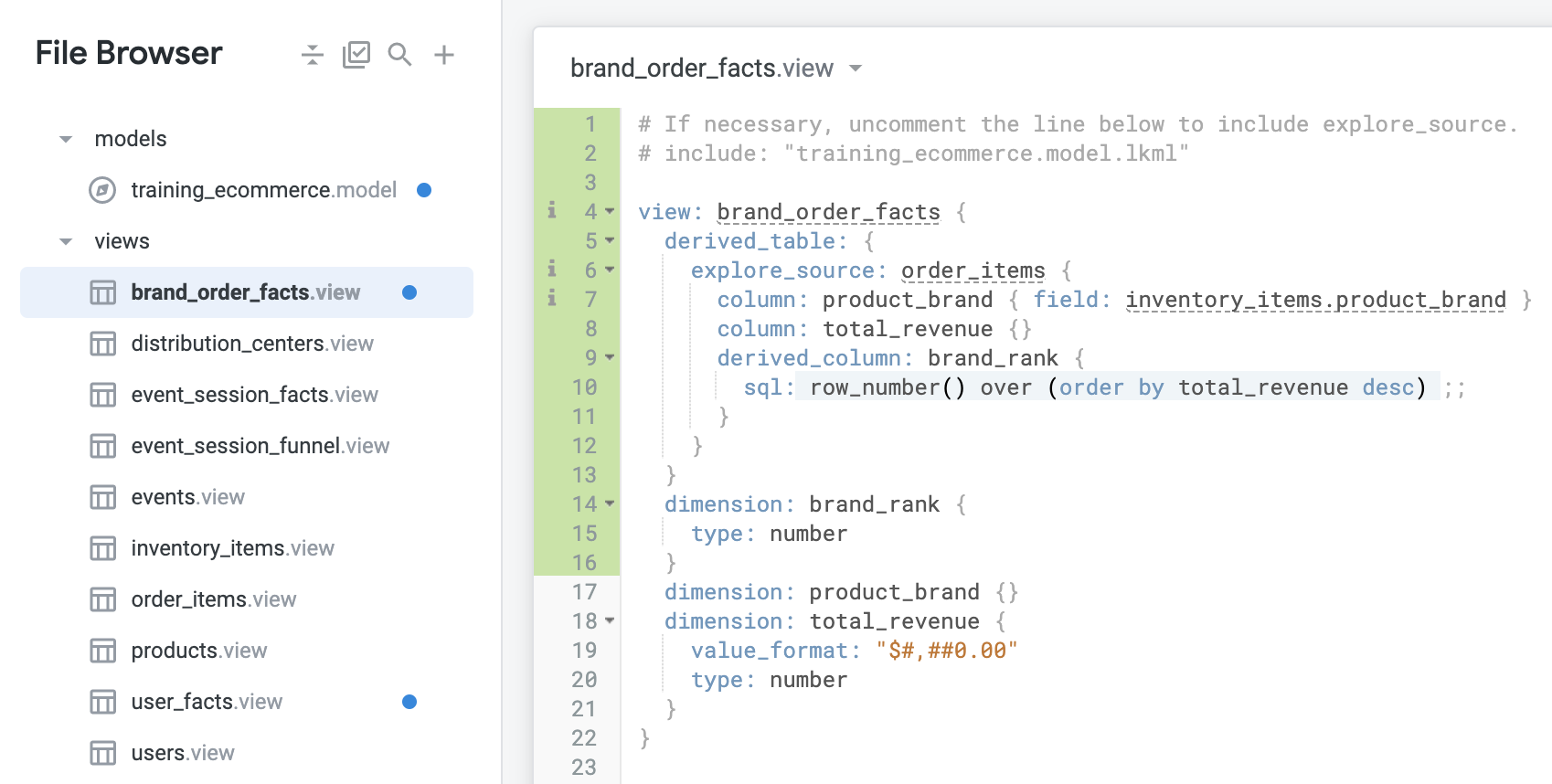
-
Clique em Salvar alterações.
-
Na mesma página, clique no arquivo training_ecommerce.model na pasta model para modificar o conteúdo.
-
Localize a definição de explore: order_items.
-
Na definição explore: order_items, adicione uma nova mesclagem para brand_order_facts especificando o seguinte:
join: brand_order_facts {
type: left_outer
sql_on: ${inventory_items.product_brand} = ${brand_order_facts.product_brand} ;;
relationship: many_to_one
}
-
Clique em Salvar alterações.
-
O arquivo modelo será parecido com este:
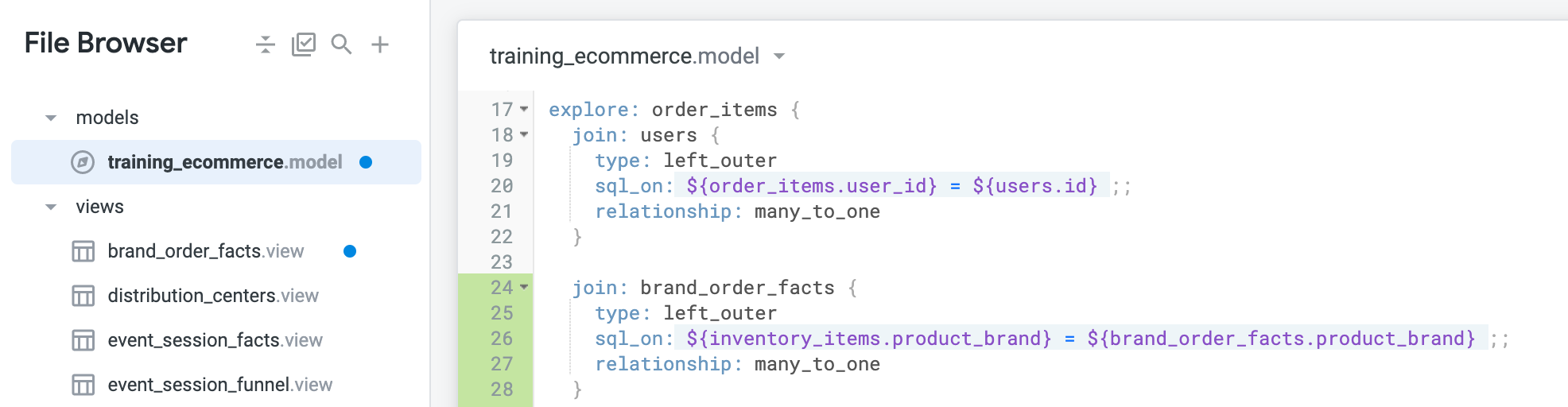
-
Agora que você mesclou a visualização brand_order_facts à análise detalhada, acesse a página da Análise de Order Items.
-
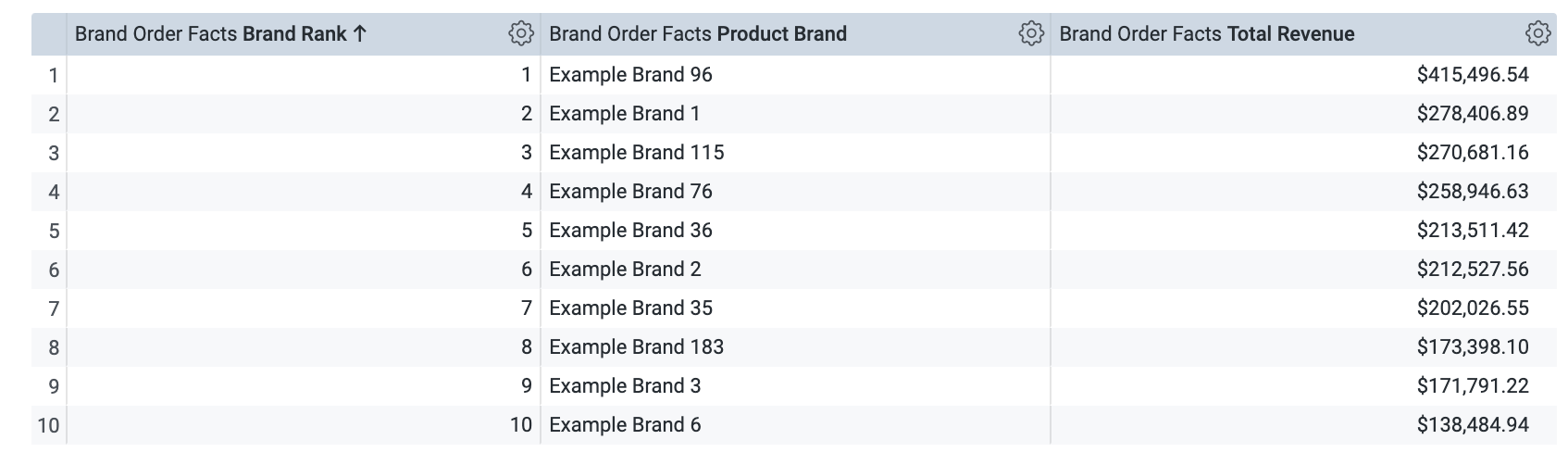
Na visualização Brand Order Facts, selecione as dimensões Brand Rank, Product Brand e Total Revenue.
-
Defina o limite de linhas como 10.
-
Clique em Executar. O resultado precisa ser semelhante a este:
Até aqui, tudo bem. Mas e se os usuários da sua empresa quiserem ver os nomes das marcas exibidos como "1) Marca de exemplo", e não apenas "Marca de exemplo"? Como isso pode ser feito? Nesse caso, você pode criar uma dimensão que concatene dois outros valores de dimensão.
-
Volte para a visualização brand_order_facts.
-
Crie a dimensão brand_rank_concat, que concatena a classificação da marca e a marca do produto:
dimension: brand_rank_concat {
type: string
sql: ${brand_rank} || ') ' || ${product_brand} ;;
}
- Oculte
brand_rank porque os usuários empresariais provavelmente só vão encontrar o número da classificação no novo brand_rank_concat e não vão querer usar um campo separado:
dimension: brand_rank {
hidden: yes
type: number
}
- Adicione um rótulo a
brand_rank_concat para que ele apareça de forma mais fácil de usar. Use o rótulo "Nome da marca":
dimension: brand_rank_concat {
label: "Brand Name"
type: string
sql: ${brand_rank} || ') ' || ${product_brand} ;;
}
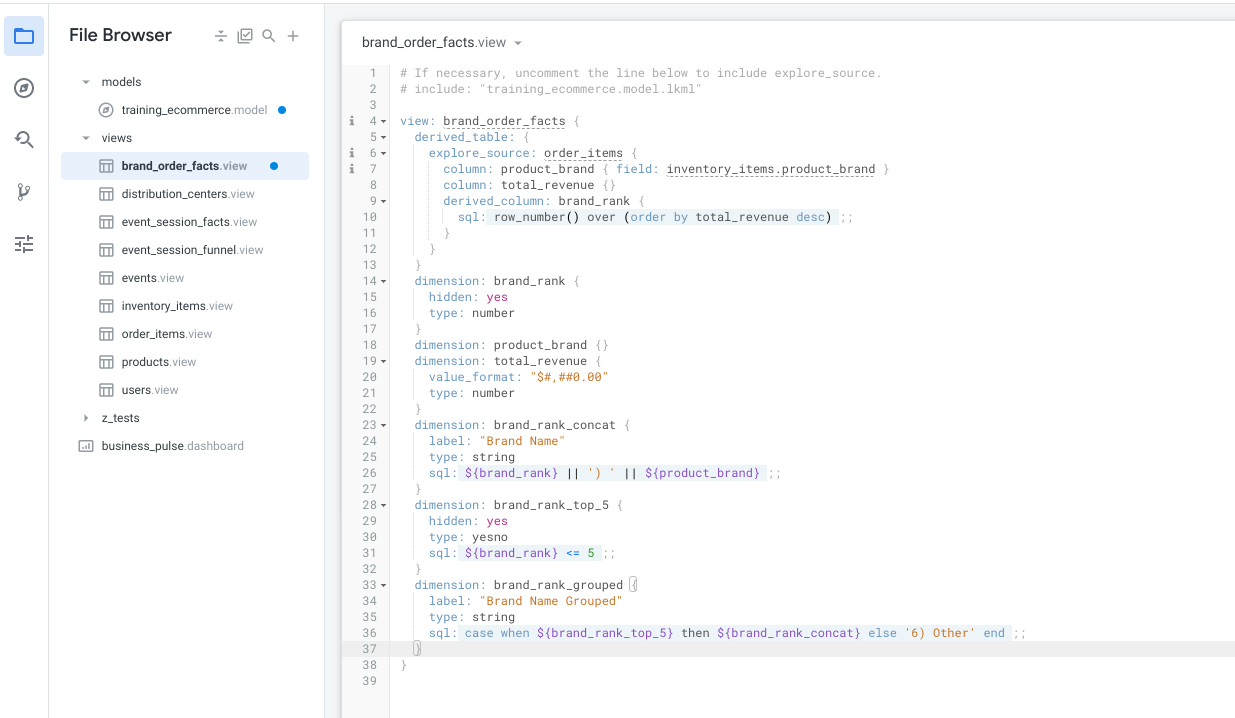
Na etapa final, você precisa agrupar todas as marcas na posição 6 e acima em uma classificação "Other". Para isso, primeiro crie uma dimensão "stepping-stone" que avalia se a classificação de uma marca está entre as cinco primeiras ou não.
- Na mesma visualização brand_order_facts, crie uma dimensão chamada
brand_rank_top_5 com os seguintes parâmetros:
dimension: brand_rank_top_5 {
hidden: yes
type: yesno
sql: ${brand_rank} <= 5 ;;
}
- Em seguida, crie uma dimensão chamada
brand_rank_grouped e incorpore a brand_rank_top_5 a ela com o seguinte código:
dimension: brand_rank_grouped {
label: "Brand Name Grouped"
type: string
sql: case when ${brand_rank_top_5} then ${brand_rank_concat} else '6) Other' end ;;
}
- Clique em Salvar alterações.
A página será parecida com esta:
-
Acesse a página da Análise de Order Items.
-
Na visualização Brand Order Facts, selecione a dimensão Brand Name Grouped.
Na visualização Order Items, selecione a medida Total Revenue. Defina o limite de linhas como 10.
-
Clique em Executar.
-
Verifique se a coluna Brand Name Grouped está ordenada do primeiro ao último. Em seguida, na guia "Visualization", clique em Pie Chart.
-
Verifique se a visualização é parecida com esta:
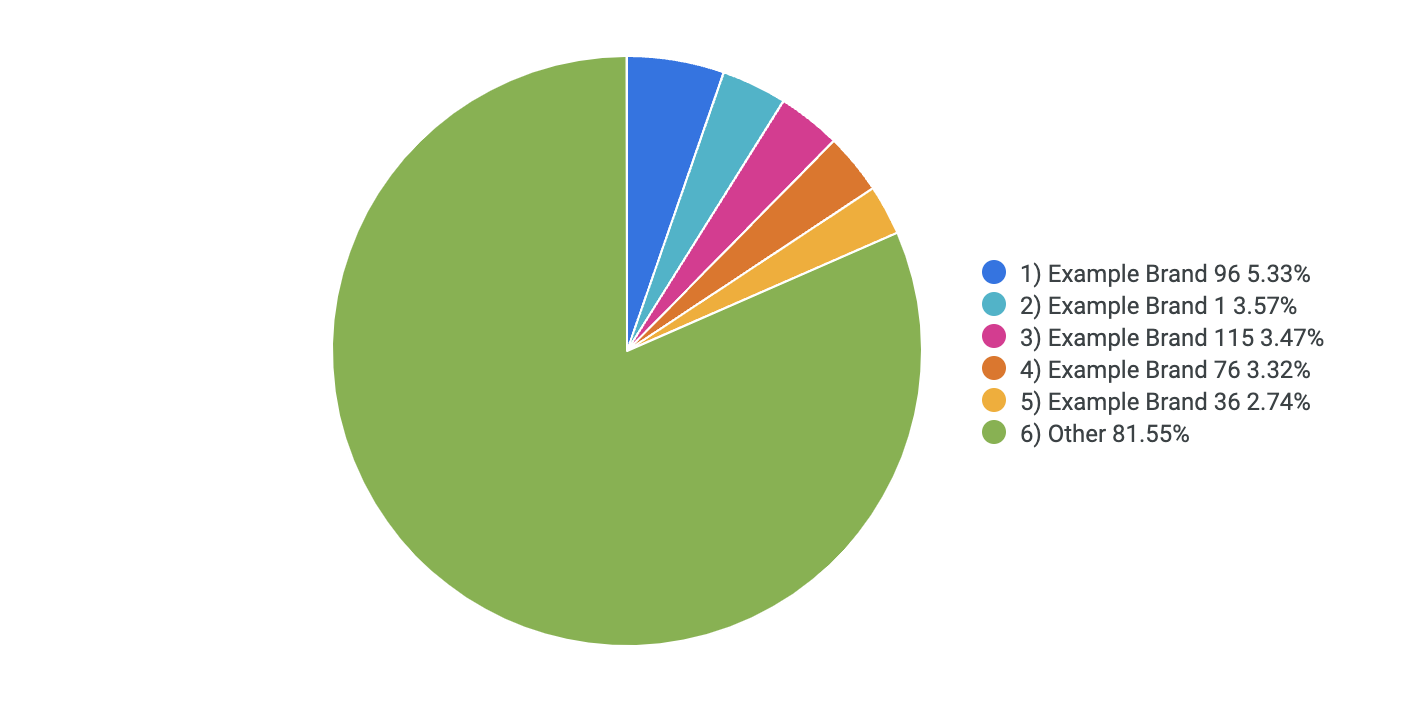
-
Clique no ícone de engrenagem () ao lado de Executar (canto superior direito da página) e selecione Salvar > Como um Look.
-
Dê o título Receita da marca classificada ao Look.
-
Clique em Salvar.
-
Volte para a visualização brand_order_facts.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Ótimo! Esperamos que isso ajude você a entender como é útil dividir um caso de uso ou uma lógica em dimensões básicas separadas, que podem ser combinadas ou usadas para responder a perguntas específicas da empresa. É muito comum no desenvolvimento de LookML com práticas recomendadas ter muitas dimensões e medidas ocultas como essas que sirvam de base para outras configurações.
Clique em Verificar meu progresso para conferir se você executou a tarefa. Personalizar tabelas derivadas nativas usando colunas derivadas
Tarefa 2: personalizar tabelas derivadas nativas usando filtros
Agora, digamos que a empresa só se importe com pedidos recentes feitos nos últimos 365 dias. Talvez algumas dessas cinco principais marcas tenham sido muito populares há anos devido a tendências diferentes, mas os rankings podem ter mudado no último ano.
Nesta seção, você vai conhecer os diferentes tipos de filtros que podem ser usados na sua tabela derivada nativa em LookML. Os filtros podem ser usados para aplicar filtros à tabela derivada, de maneira semelhante a uma métrica filtrada. Eles adicionam uma cláusula WHERE ou HAVING.
Adicionar um filtro de data estático
-
Primeiro, volte para a visualização brand_order_facts.
-
Na definição derived_column, adicione um filtro para restringir a tabela derivada nativa a pedidos criados nos últimos 365 dias:
filters: [order_items.created_date: "365 days"]
- Clique em Salvar alterações. O arquivo será parecido com este:
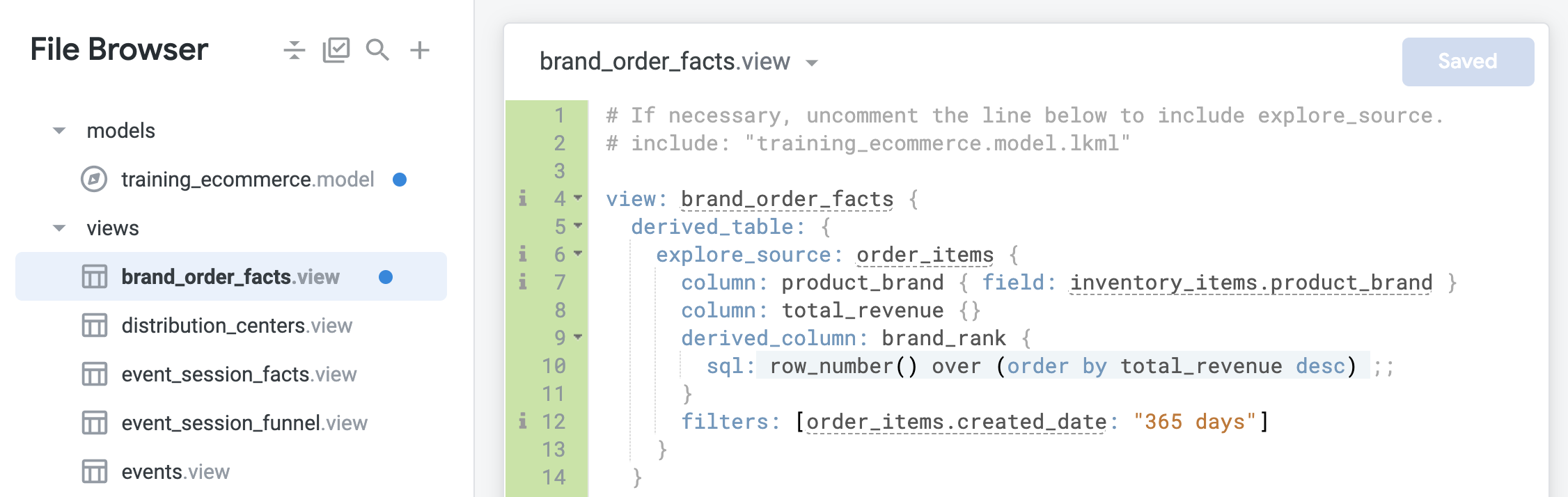
-
Volte para a Análise de Order Items.
-
Na visualização Brand Order Facts, selecione a dimensão Brand Name Grouped.
-
Na visualização Order Items, selecione a medida Total Revenue.
-
Clique em Executar.
-
Na barra Data, clique na guia SQL para ver como o filtro é usado na consulta.
Como você adicionou um filtro à data de criação dos itens solicitados para analisar apenas os pedidos feitos nos últimos 365 dias, a condição WHERE só é gerada no que é chamado de consulta externa. Esse é o comportamento padrão de qualquer filtro de dimensão. Não é possível pedir que ele entre na expressão de tabela comum da tabela derivada nem fazer com que a cláusula WHERE externa "vaze" para a consulta interna. É aí que adicionar um filtro à própria NDT se torna útil.
Adicionar um filtro de vinculação
E se a empresa achar muito rígido restringir os dados apenas aos pedidos dos últimos 365 dias? Talvez os usuários queiram analisar as classificações dos últimos dois anos. Com filters: [order_items.created_date: "365 days"], você está codificando o período.
Nesse caso, bind_filters pode ser um parâmetro mais útil do que apenas filtros. Você pode indicar qual campo da Análise externa quer "transferir" para a consulta interna da tabela derivada nativa (o from_field) e para qual campo da tabela derivada nativa ele deve ser mapeado (o to_field). Na maioria das vezes, esses dois valores são iguais.
O subparâmetro bind_filters de explore_source transmite um filtro específico da consulta da Análise para a subconsulta da tabela derivada nativa:
- O
to_field é o campo na tabela derivada nativa a qual o filtro é aplicado. O to_field precisa ser um campo da explore_source subjacente.
- O
from_field especifica o campo na Análise de onde o filtro será extraído, caso o usuário especifique um filtro no tempo de execução.
-
Volte para a visualização brand_order_facts.
-
Para usar o filtro de vinculação, comece removendo o filtro de data estática na definição de tabela derivada que você criou na seção anterior.
-
Em seguida, adicione o seguinte modelo de bind_filters na definição de derived_column:
bind_filters: {
from_field: # O campo com que o usuário final interage na área de filtros
to_field: # O campo que deve ser filtrado na NDT
}
Nesse caso, você vai querer pegar o filtro from_field: order_items.created_date e fazer com que ele influencie ou aplique to_field: order_items.created_date.
- Adicione o seguinte código para os campos de filtro de vinculação:
bind_filters: {
from_field: order_items.created_date
to_field: order_items.created_date
}
Observação: isso equivale a adicionar um filtro com modelo à tabela derivada em SQL. Como você viu no laboratório anterior, um filtro com modelo foi adicionado a uma tabela derivada do SQL para que os usuários pudessem escolher uma data e ver os valores atualizados com base nessa data.
- Clique em Salvar alterações. O arquivo deve ser semelhante ao seguinte:
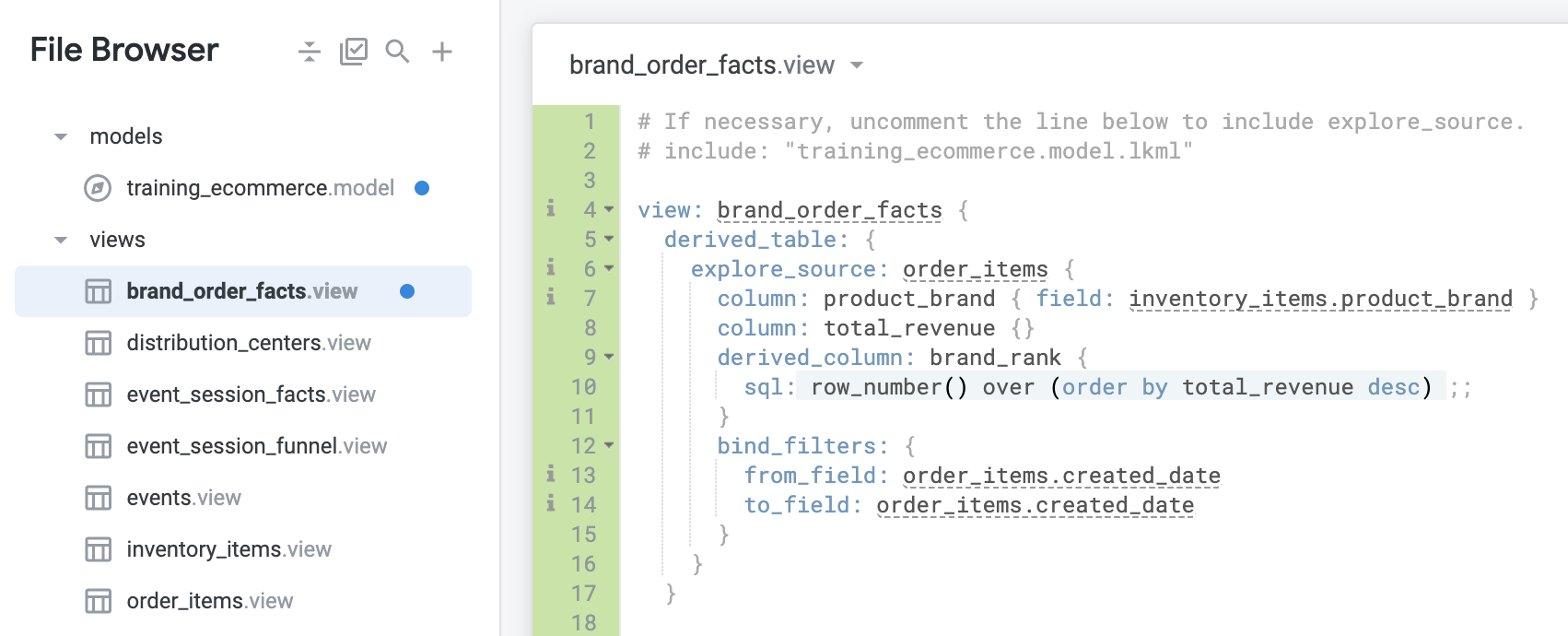
-
Volte para a Análise de Order Items.
-
Na visualização Brand Order Facts, selecione a dimensão Brand Name Grouped.
-
Na visualização Order Items, selecione a medida Total Revenue.
-
Ainda na visualização Order Items, na dimensão Created Date, selecione o campo Date e clique no botão de filtro ao lado de Date.
-
Na definição de filtro, especifique que o filtro seja: está nos últimos 1.000 dias. Para fins de demonstração, você está usando 1.000 dias para garantir que o filtro não seja muito restritivo e capture os últimos três anos.
-
Clique em Executar.

- Na barra Data, clique na guia SQL para ver como o filtro é usado na consulta. Observe que o SQL gerado agora atualiza dinamicamente a condição WHERE na expressão de tabela comum para a tabela derivada e a condição externa WHERE.
Como você pode ver, isso é muito mais flexível. Se você filtrar por pedidos criados nos últimos três trimestres, a tabela derivada nativa vai calcular as classificações dos últimos três trimestres de acordo com o filtro. Se você filtrar por pedidos criados em um determinado período, a tabela derivada nativa também usará esse mesmo período na condição WHERE.
-
Agora, no campo Users, selecione Country e Age e adicione um filtro. Defina como Country is equal to USA e Age is greater than 21.
-
Clique em Executar.
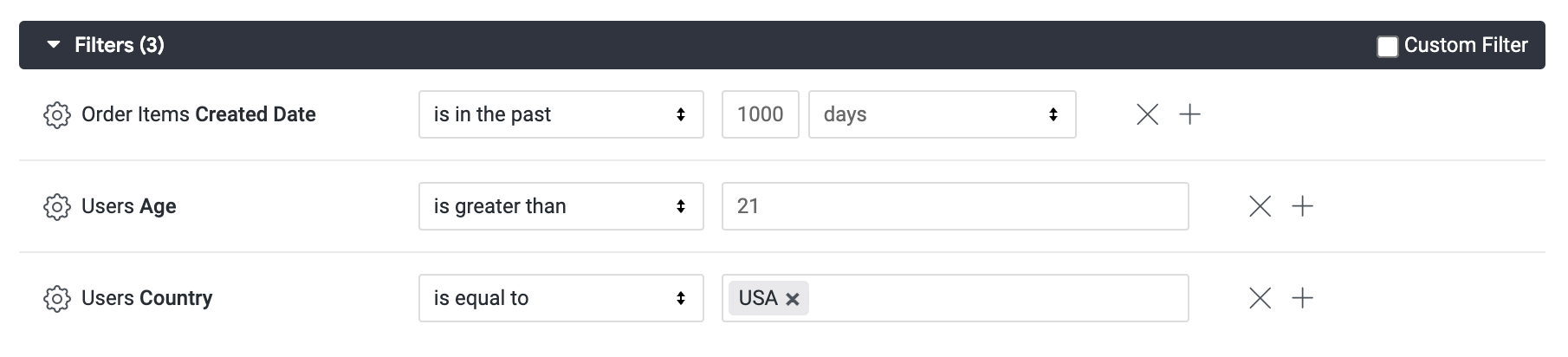
- Clique na guia SQL.
Observe como a condição WHERE da tabela derivada não é afetada. E se os usuários comerciais tiverem outros critérios além da data de criação dos itens solicitados? E se eles quiserem ver apenas as classificações de pedidos feitos por clientes nos EUA ou por clientes do sexo masculino?
Você pode continuar adicionando bind_filters, mas veja quantos campos você tem na Análise dos Itens solicitados. Levaria muito tempo para adicionar bind_filters a todos eles. Neste caso, outro parâmetro pode ser extremamente útil: bind_all_filters.
Clique em Verificar meu progresso para conferir se você executou a tarefa. personalizar tabelas derivadas nativas usando filtros
Como usar bind_all_filters
A maneira mais fácil de transmitir filtros de uma análise para uma subconsulta de tabela derivada nativa é especificar bind_all_filters: yes no parâmetro explore_source da tabela derivada nativa. Isso vai transmitir todos os filtros de tempo de execução de uma Análise para a subconsulta da tabela derivada nativa.
Se você quiser usar a tabela derivada nativa em outra Análise, use o parâmetro bind_filters, conforme descrito na seção anterior.
-
Comece removendo o bind_filter na definição da tabela derivada que você criou na seção anterior.
-
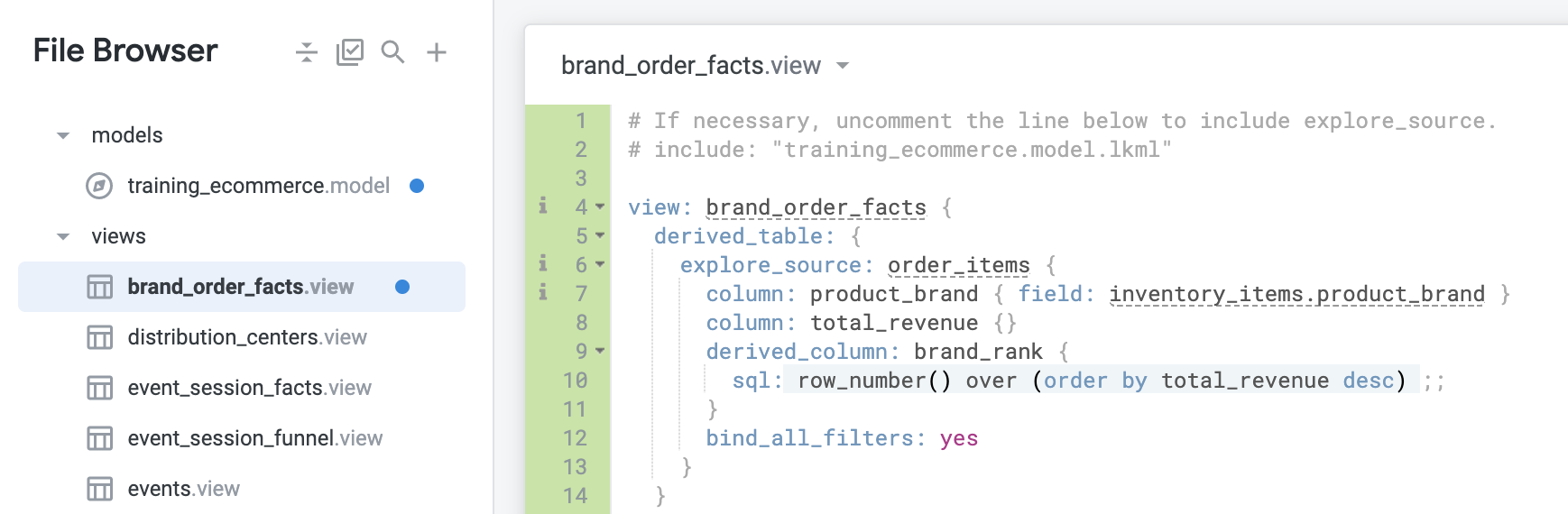
Adicione a definição bind_all_filters: yes em derived_column para vincular não apenas order_created_date a si mesmo, mas todos os filtros a si mesmos:
bind_all_filters: yes
- Clique em Salvar alterações. O arquivo deve ser semelhante ao seguinte:
-
Volte para a Análise de Order Items.
-
Na visualização Brand Order Facts, selecione a dimensão Brand Name Grouped.
-
Na visualização Order Items, selecione a medida Total Revenue.
-
Ainda na visualização Order Items, encontre a dimensão Created Date e clique no botão de filtro ao lado de Date.
-
Na definição do filtro, especifique: is in the past 365 days.
-
Na visualização Users, adicione um filtro em Country e Age. Defina como Country is equal to USA e Age is greater than 21.
-
Clique em Executar.
-
Clique na guia SQL. Observe como a condição WHERE da tabela derivada agora é atualizada dinamicamente.
Embora bind_all_filters seja ótimo, ele só funciona quando você une a tabela derivada nativa a explore_source. Em outras palavras, você só pode usar isso aqui porque mesclou brand_order_facts com a mesma Análise de explore_source, order_items.
Por quê? Porque bind_all_filters significa que o Looker precisa saber como gerar uma condição WHERE para qualquer campo em toda a Análise. Se a tabela derivada nativa estiver usando um explore_source de order_items, mas você a mesclar com outra análise detalhada, essa outra análise poderá ter qualquer número de visualizações e campos mesclados que não existem em order_items e, portanto, não farão sentido em order_items. O Looker não saberia como filtrar a tabela derivada com esses outros campos.
Agora que você viu o bind_all_filters em ação, teste alguns filtros diferentes do Explorar e veja como eles afetam a maneira como a tabela derivada nativa é compilada.
- Volte para a visualização brand_order_facts.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Parabéns!
Neste laboratório, você usou tabelas derivadas nativas para responder a perguntas complexas e resolver casos de uso avançados com colunas derivadas. Além disso, você atualizou essas tabelas para gerar valores dinâmicos usando parâmetros de filtro integrados. Você também aprendeu como os usuários comerciais aproveitam tabelas derivadas nativas personalizadas para responder a perguntas complexas.
Próximas etapas / Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 4 de março de 2024
Laboratório testado em 4 de março de 2024
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





