GSP924

概览
Document AI API 是一种文档理解解决方案,可以提取文档、邮件等非结构化数据,从而让用户更容易理解、分析和使用这些数据。借助本实验中使用的通用表单处理器,您可以从简单文档中提取键值对。
在本实验中,您将学习如何使用 Document AI 创建文档解析器,如何使用 Cloud 控制台和命令行,通过 Google Cloud 提交文档来进行处理,以及如何使用 Python 进行同步 API 调用。
学习内容
您将学习如何执行以下任务:
- 使用控制台创建和测试 Document AI 处理器。
- 使用命令行测试 Document AI 处理器。
- 使用 Python 测试 Document AI 同步 API 调用。
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式(推荐)或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:请仅使用学生账号完成本实验。如果您使用其他 Google Cloud 账号,则可能会向该账号收取费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。右侧是实验设置和访问权限面板,其中包含以下内容:
-
打开 Google Cloud 控制台按钮
- 您在本实验中必须使用的临时凭证(用户名和密码)
- 帮助您逐步完成该实验所需的其他信息(如果需要)
请注意,实验计时器位于页面顶部附近,将显示剩余时间。
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:可以将这些标签页分别放在不同的窗口中,并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在实验设置和访问权限面板中找到“用户名”。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在实验设置和访问权限面板中找到“密码”。
-
点击下一步。
重要提示:您必须使用实验提供的凭证。请勿使用您的 Google Cloud 账号凭证。
注意:在本实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
依次点击进入后续页面:
- 接受条款及条件。
- 由于这是临时账号,请勿添加账号恢复选项或双重身份验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需访问 Google Cloud 产品和服务,请点击导航菜单,或在搜索字段中输入服务或产品的名称。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
-
点击 Google Cloud 控制台顶部的激活 Cloud Shell  。
。
-
在弹出的窗口中执行以下操作:
- 继续完成 Cloud Shell 信息窗口中的设置。
- 授权 Cloud Shell 使用您的凭据进行 Google Cloud API 调用。
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID 。输出内容中有一行说明了此会话的 Project_ID:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
gcloud auth list
- 点击授权。
输出:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (可选)您可以通过此命令列出项目 ID:
gcloud config list project
输出:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注意:如需查看在 Google Cloud 中使用 gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
任务 1. 启用 Cloud Document AI API
在此任务中,您将启用 Document AI API,并创建和测试通用表单处理器。通用表单处理器可处理各种类型的文档,还能提取文档中所有可识别的文本内容。除了打印的文本,它还可以处理手写的和沿任意方向排列的文本,并支持多种语言,理解表单数据元素之间的关联,因此可以帮助您从包含文本标签的表单字段中提取键值对。
启用 Cloud Document AI API
您必须先启用 Cloud Document AI API,然后才能开始使用 Document AI。
-
在导航菜单 ( ) 中,点击 API 和服务 > 库。
) 中,点击 API 和服务 > 库。
-
搜索 Cloud Document AI API,然后点击启用按钮,以便在 Google Cloud 项目中使用该 API。
如果 Cloud Document AI API 已启用,将会出现管理按钮,您可以继续进行实验。
点击检查我的进度以验证是否完成了以下目标:
已启用 Cloud Document AI API
任务 2. 创建并测试通用表单处理器
接下来,您将使用 Document AI 表单解析器来创建 Document AI 处理器。
创建处理器
-
在控制台的导航菜单 () 中,点击 Document AI > 概览。
-
点击探索处理器。
-
点击表单解析器,这是一种通用处理器。
-
将处理器的名称指定为 form-parser,并从地区列表中选择 US(美国)。
-
点击创建,创建通用的 form-parser 处理器。
此操作将创建该处理器并返回处理器详情页面。页面中将显示处理器 ID、状态和预测端点。
- 记下处理器 ID,因为您将在后面的任务中使用
curl 来对 API 进行 POST 调用。
下载示例表单
在此任务中,您将从 Cloud Storage 下载示例表单。为了在下一个任务中上传此表单,您需要先将其下载到本地机器。
- 将 form.pdf 文件下载到本地机器。
该文件应该会直接下载。如果该文件在浏览器中打开,请使用浏览器中的文件控件进行下载。form.pdf 文件的标题是“HEALTH INTAKE FORM”(健康状况调查表),其中包含手写数据。
上传表单以供 Document AI 处理
接下来,您需要将下载的示例表单上传到 form-parser 处理器。然后,系统会对该文件进行分析,并将结果显示在控制台中。
- 在 form-parser 页面上,点击上传测试文档按钮。系统会弹出一个对话框,告诉您选择在上一个任务中下载的文件来进行上传。
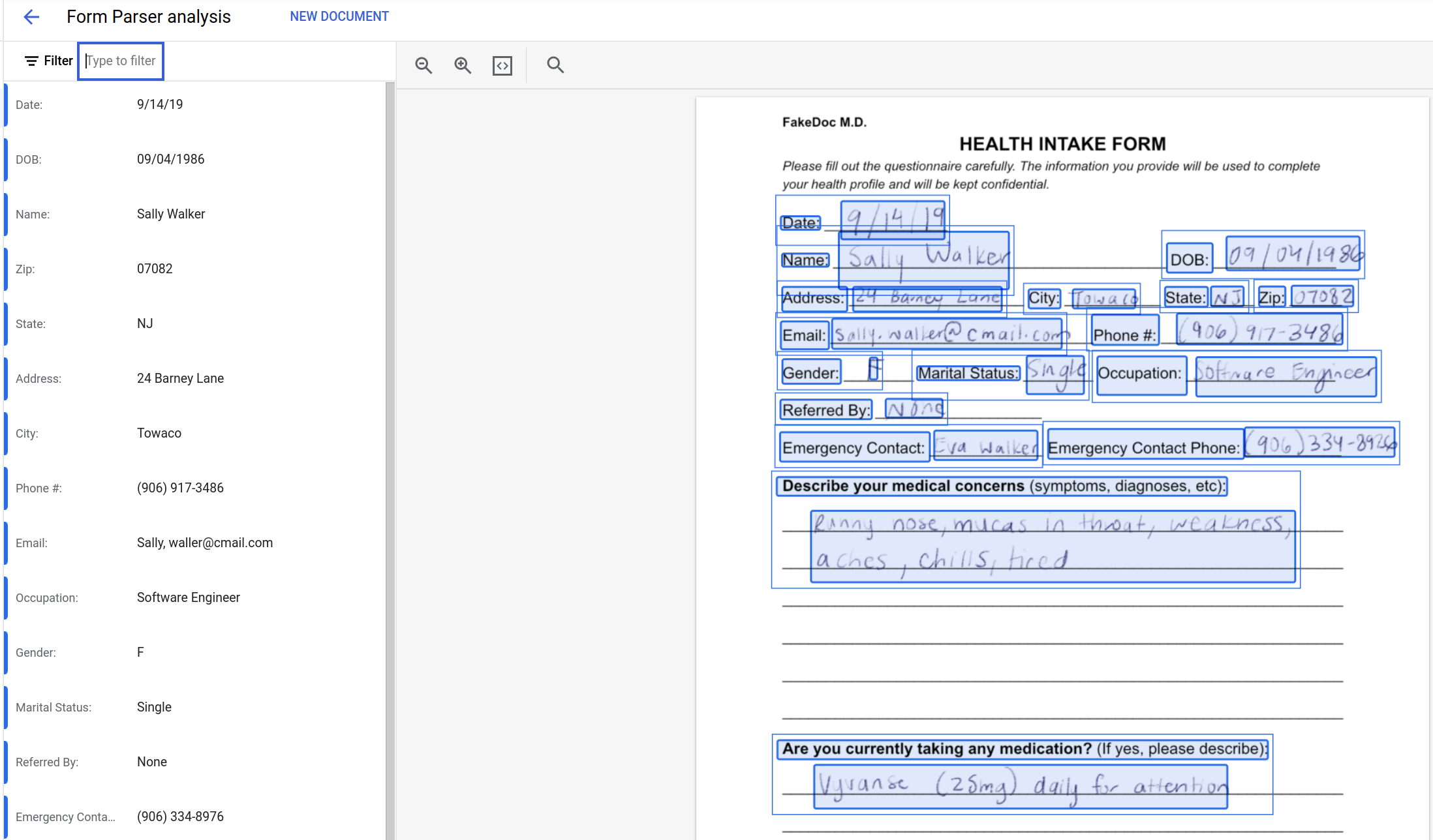
将有一个进度条指示分析过程的完成程度,最后将显示结果。您会发现该通用处理器已将表单上的数据捕获到一组键值对中。
从源文档解析出的键值对将显示在控制台中。左侧窗格列出了数据,右侧窗格则用蓝色方框突出显示了已解析文档中的来源位置。检查输出,并将结果与源数据进行比较。
在此任务中,您将从命令行调用 API,以便测试 Document AI 通用表单处理器。
点击检查我的进度以验证是否完成了以下目标:
创建并测试通用表单处理器
任务 3. 设置实验实例
在本部分中,您将设置实验实例以使用 Document AI API。
使用 SSH 连接到实验虚拟机实例
您将在名为 document-ai-dev 的实验虚拟机中完成实验的其余任务。
-
在导航菜单 () 中,点击 Compute Engine > 虚拟机实例。
-
点击名为 document-ai-dev 的虚拟机实例的 SSH 链接。
在这一步,您需要提供在任务 2 中创建的处理器的 Document AI 处理器 ID。如果您没有保存,请在 Cloud 控制台标签页中执行以下操作:
- 打开导航菜单 ()。
- 点击 Document AI > 处理器。
- 点击处理器的名称以打开详情页面。
- 您可以在该页面上复制处理器 ID。
- 在 SSH 会话中,创建一个环境变量,以包含 Document AI 处理器 ID。您必须替换
[your processor id] 这一占位符:
export PROCESSOR_ID=[your processor id]
- 在 SSH 会话中,确认环境变量包含 Document AI 处理器 ID:
echo Your processor ID is:$PROCESSOR_ID
- 这应该会输出类似如下的处理器 ID:
Your processor ID is:4897d834d2f4415d
在本实验的剩余任务中,您将使用此 SSH 会话。
对 API 请求进行身份验证
如需向 Document AI API 发出请求,您需要提供有效的凭证。在此任务中,您将创建一个服务账号,仅向该服务账号授予实验所需的权限,然后为该账号生成凭证,该凭证可用于对 Document AI API 请求进行身份验证。
- 使用您的项目 ID 设置一个环境变量,以在此实验中全程使用:
export PROJECT_ID=$(gcloud config get-value core/project)
- 使用以下命令创建一个新服务账号来访问 Document AI API:
export SA_NAME="document-ai-service-account"
gcloud iam service-accounts create $SA_NAME --display-name $SA_NAME
- 将该服务账号绑定到 Document AI API User 角色:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:$SA_NAME@${PROJECT_ID}.iam.gserviceaccount.com" \
--role="roles/documentai.apiUser"
- 创建将用于以您的新服务账号身份登录的凭证,并将这些凭证保存到工作目录中名为
key.json 的 JSON 文件中:
gcloud iam service-accounts keys create key.json \
--iam-account $SA_NAME@${PROJECT_ID}.iam.gserviceaccount.com
- 设置
GOOGLE_APPLICATION_CREDENTIALS 环境变量,供库用来查找您的凭证,并将其指向凭证文件:
export GOOGLE_APPLICATION_CREDENTIALS="$PWD/key.json"
- 检查
GOOGLE_APPLICATION_CREDENTIALS 环境变量是否已设置为您之前创建的凭证 JSON 文件的完整路径:
echo $GOOGLE_APPLICATION_CREDENTIALS
gcloud 命令行工具会通过此环境变量指定执行命令时要使用的凭证。如需详细了解此身份验证形式,请参阅应用默认凭证指南。
将示例表单下载到虚拟机实例
现在,您可以下载一个示例表单,然后对其进行 base64 编码,以便提交给 Document AI API。
- 在 SSH 窗口中输入以下命令,将示例表单下载到您的工作目录中:
gsutil cp gs://spls/gsp924/health-intake-form.pdf .
- 创建一个 JSON 请求文件,用于提交 base64 编码的表单以进行处理:
echo '{"inlineDocument": {"mimeType": "application/pdf","content": "' > temp.json
base64 health-intake-form.pdf >> temp.json
echo '"}}' >> temp.json
cat temp.json | tr -d \\n > request.json
点击检查我的进度以验证是否完成了以下目标:
对 API 请求进行身份验证并下载示例表单
任务 4. 使用 curl 请求同步处理文档
在此任务中,您将使用 curl 调用同步 Document AI API 端点来处理示例文档。
- 通过
curl 提交表单以进行处理。结果将存储在 output.json 中:
export LOCATION="us"
export PROJECT_ID=$(gcloud config get-value core/project)
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
https://${LOCATION}-documentai.googleapis.com/v1beta3/projects/${PROJECT_ID}/locations/${LOCATION}/processors/${PROCESSOR_ID}:process > output.json
- 确保
output.json 文件包含 API 调用的结果:
cat output.json
如果您收到身份验证错误,请确保已将 GOOGLE_APPLICATION_CREDENTIALS 环境变量设置为指向您之前创建的 JSON 凭证文件。您可能需要等待几分钟,IAM 政策才能传播完成,因此如果您收到错误,请重试。
Cloud IAM 服务账号的访问令牌是即时生成的,并通过 Authorization: HTTP 标头传递给 API。响应包含 JSON 格式的数据,这些数据会保存到 output.json 文件中。
提取表单实体
接下来,探索从示例表单中提取的一些信息。
- 按如下方式提取文档中检测到的原始文本:
sudo apt-get update
sudo apt-get install jq
cat output.json | jq -r ".document.text"
此列表会列出在上传的文档中检测到的所有文本。
- 提取表单处理器检测到的表单字段列表:
cat output.json | jq -r ".document.pages[].formFields"
此列表显示文档中检测到的所有表单字段的对象数据。每个表单包含 textAnchor.startIndex 和 textAnchor.endIndex 值,可用于在 document.text 字段中找到所检测表单的名称。在下一个任务中,您将使用一个 Python 脚本,该脚本将为您完成此映射。
这个 JSON 文件很大,因为它包含 base64 编码的源文档以及所有检测到的文本和文档属性。您可以在文本编辑器中打开该 JSON 文件,或使用 jq 等 JSON 查询工具来探索该文件。
检查是否已通过 Document AI API 处理文档。
任务 5. 使用 Python 客户端库测试 Document AI 表单处理器
使用 Python Document AI 客户端库同步调用 Document AI API。
现在,您将使用同步端点来处理文档。如需一次性处理大量文档,可以使用异步 API。请查阅此指南,详细了解如何使用 Document AI API。
如果您想直接运行 Python 脚本,则需要为这些脚本提供适当的凭证,它们才能使用已配置正确权限的服务账号来调用 API。如需详细了解如何配置这种身份验证形式,请参阅以服务账号身份进行身份验证。
将虚拟机实例配置为使用 Document AI Python 客户端
现在,将 Python 版 Google Cloud 客户端库安装到虚拟机实例中。
- 在 SSH 终端 shell 中输入以下命令,以便将实验文件导入虚拟机实例:
gsutil cp gs://spls/gsp924/synchronous_doc_ai.py .
- 输入以下命令,安装 Document AI 所需的 Python 客户端库和本实验所需的其他库:
sudo apt install python3-pip
python3 -m pip install --upgrade google-cloud-documentai google-cloud-storage prettytable
如果系统提示 Do you want to continue? (Y/n),请输入 Y。
您会看到输出消息,指示库已成功安装。
查看 Document AI API Python 代码
请花点时间查看示例文件中的 Python 代码。您可以使用自己选择的编辑器(例如 vi 或 nano),在 SSH 会话中查看代码,也可以使用上一部分中的命令将示例代码复制到 Cloud Shell 中,然后使用代码编辑器查看源代码。
- 前两个代码块会导入必需的库并解析参数,以初始化用于标识 Document AI 处理器和输入数据的变量。
import argparse
from google.cloud import documentai_v1beta3 as documentai
from google.cloud import storage
from prettytable import PrettyTable
parser = argparse.ArgumentParser() parser.add_argument("-P", "--project_id", help="Google Cloud Project ID") parser.add_argument("-D", "--processor_id", help="Document AI Processor ID") parser.add_argument("-F", "--file_name", help="Input file name", default="form.pdf") parser.add_argument("-L", "--location", help="Processor Location", default="us") args = parser.parse_args()
-
process_document 函数用于同步调用 Document AI 处理器。此函数会创建 Document AI API 客户端对象。
该 API 调用所需的处理器名称使用 project_id、location 和 processor_id 参数来创建,而要处理的文档则以 mime_type 结构进行读取和存储。
然后,处理器名称和文档会传递给 Document API 客户端对象,并对该 API 进行同步调用。如果请求成功,返回的文档对象将包含一些属性,这些属性包含 Document AI 处理器检测到的数据。
def process_document(project_id, location, processor_id, file_path ):
# Instantiates a client
client = documentai.DocumentProcessorServiceClient()
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
name = f"projects/{project_id}/locations/{location}/processors/{processor_id}"
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Create the document object
document = {"content": image_content, "mime_type": "application/pdf"}
# Configure the process request
request = {"name": name, "document": document}
# Use the Document AI client synchronous endpoint to process the request
result = client.process_document(request=request)
return result.document
- 然后,该脚本会使用必需的参数调用
process_document 函数,并将响应保存在 document 变量中。
document = process_document(args.project_id,args.location,args.processor_id,args.file_name )
- 最后一段代码会输出
.text 属性,其中包含在文档中检测到的所有文本,然后使用表单解析器检测到的每个表单字段的文本锚点数据来显示表单信息。
print("Document processing complete.")
# print the raw text
print("Text: \n{}\n".format(document.text))
# Define a function to retrieve an object dictionary for a named element
def get_text(doc_element: dict, document: dict):
"""
Document AI identifies form fields by their offsets
in document text. This function converts offsets
to text snippets.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in doc_element.text_anchor.text_segments:
start_index = (
int(segment.start_index)
if segment in doc_element.text_anchor.text_segments
else 0
)
end_index = int(segment.end_index)
response += document.text[start_index:end_index]
return response
# Grab each key/value pair and their corresponding confidence scores.
document_pages = document.pages
print("Form data detected:\n")
# For each page fetch each form field and display fieldname, value and confidence scores
for page in document_pages:
print("Page Number:{}".format(page.page_number))
for form_field in page.form_fields:
fieldName=get_text(form_field.field_name,document)
nameConfidence = round(form_field.field_name.confidence,4)
fieldValue = get_text(form_field.field_value,document)
valueConfidence = round(form_field.field_value.confidence,4)
print(fieldName+fieldValue +" (Confidence Scores: (Name) "+str(nameConfidence)+", (Value) "+str(valueConfidence)+")\n")
点击检查我的进度以验证是否完成了以下目标:
测试 Document AI 表单处理器
任务 6. 运行 Document AI Python 代码
执行示例代码,并处理与之前相同的文件。
- 为项目 ID 和 IAM 服务账号凭证文件创建环境变量:
export PROJECT_ID=$(gcloud config get-value core/project)
export GOOGLE_APPLICATION_CREDENTIALS="$PWD/key.json"
- 使用所需的参数调用
synchronous_doc_ai.py Python 程序:
python3 synchronous_doc_ai.py \
--project_id=$PROJECT_ID \
--processor_id=$PROCESSOR_ID \
--location=us \
--file_name=health-intake-form.pdf | tee results.txt
您将看到下面这段文本输出内容: FakeDoc M.D. HEALTH INTAKE FORM Please fill out the questionnaire carefully. The information you provide will be used to complete your health profile and will be kept confidential. Date: Sally Walker Name: 9/14/19 ...
第一个文本块是一个单一的文本元素,其中包含文档的全部文本。该文本块不包含对基于表单的数据的任何感知,因此 Date 和 Name 等条目会在此原始文本值中混杂显示。
然后,该代码使用 form-parser 从文档结构中推断出的表单数据,输出数据的结构化视图。这种结构化输出还包括表单字段名称和值的置信度分数。本部分的输出给出了表单字段名称与值之间更有用的映射,例如,可以清晰地看到 Date 和 Name 表单字段与其正确值之间的关联。
Form data detected:
Page Number:1 Phone #: (906) 917-3486 (Confidence Scores: (Name) 1.0, (Value) 1.0) ... Date: 9/14/19 (Confidence Scores: (Name) 0.9999, (Value) 0.9999) ... Name: Sally Walker (Confidence Scores: (Name) 0.9973, (Value) 0.9973) ...
点击检查我的进度以验证是否完成了以下目标:
运行 Document AI Python 代码
恭喜!
您已成功使用 Document AI API,通过通用表单处理器从文档中提取了数据。在本实验中,您使用控制台和命令行创建并测试了 Document AI 处理器,并使用 Python 执行了 Document AI 同步 API 调用。
后续步骤/了解详情
- 如需了解详情,请参阅 Cloud Document AI API 文档。
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
本手册的最后更新时间:2026 年 3 月 10 日
本实验的最后测试时间:2026 年 3 月 10 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。





