Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
Neste laboratório, você vai:
escrever um pipeline para agregar o tráfego do site por usuário;
escrever um pipeline para agregar o tráfego do site por minuto;
implementar o janelamento com base em dados de série temporal.
Pré-requisitos
Ter noções básicas sobre Java.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
Faça login no Google Skills usando uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
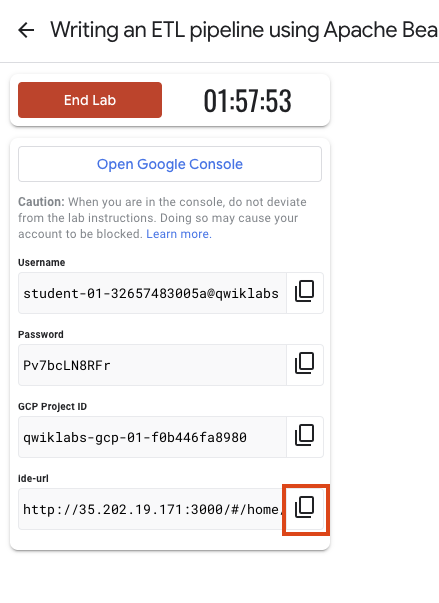
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Configuração do ambiente de desenvolvimento integrado
Neste laboratório, você vai usar, na maior parte do tempo, a versão do ambiente de desenvolvimento integrado (IDE) Theia para web. Ela é hospedada no Google Compute Engine e contém o repositório do laboratório pré-clonado. Além disso, o Theia oferece suporte de servidor à linguagem Java e um terminal para acesso programático às APIs do Google Cloud com a ferramenta de linha de comando gcloud, similar ao Cloud Shell.
Para acessar o IDE Theia, copie e cole o link que aparece no Google Skills em uma nova guia.
Observação: mesmo depois que o URL aparecer, talvez você precise esperar de 3 a 5 minutos para o ambiente ser totalmente provisionado. Até isso acontecer, você verá uma mensagem de erro no navegador.
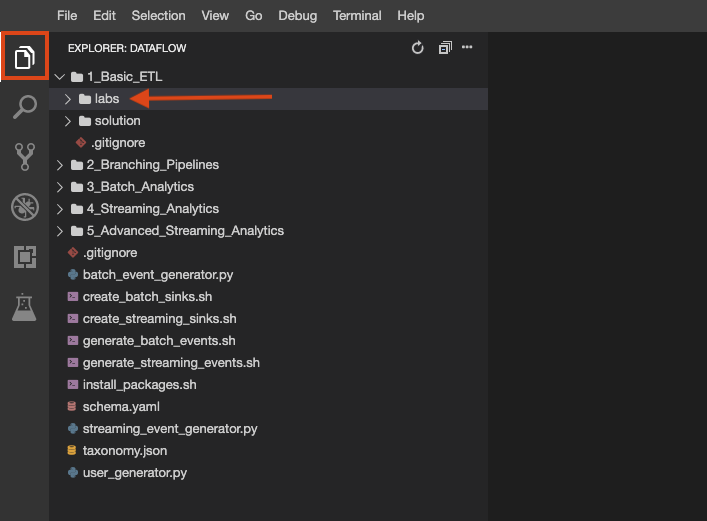
O repositório do laboratório foi clonado para seu ambiente. Cada laboratório é dividido em uma pasta labs com códigos que você vai concluir e uma pasta solution com um exemplo totalmente funcional para consulta, caso você tenha dificuldades.
Clique no botão Explorador de Arquivos para conferir:
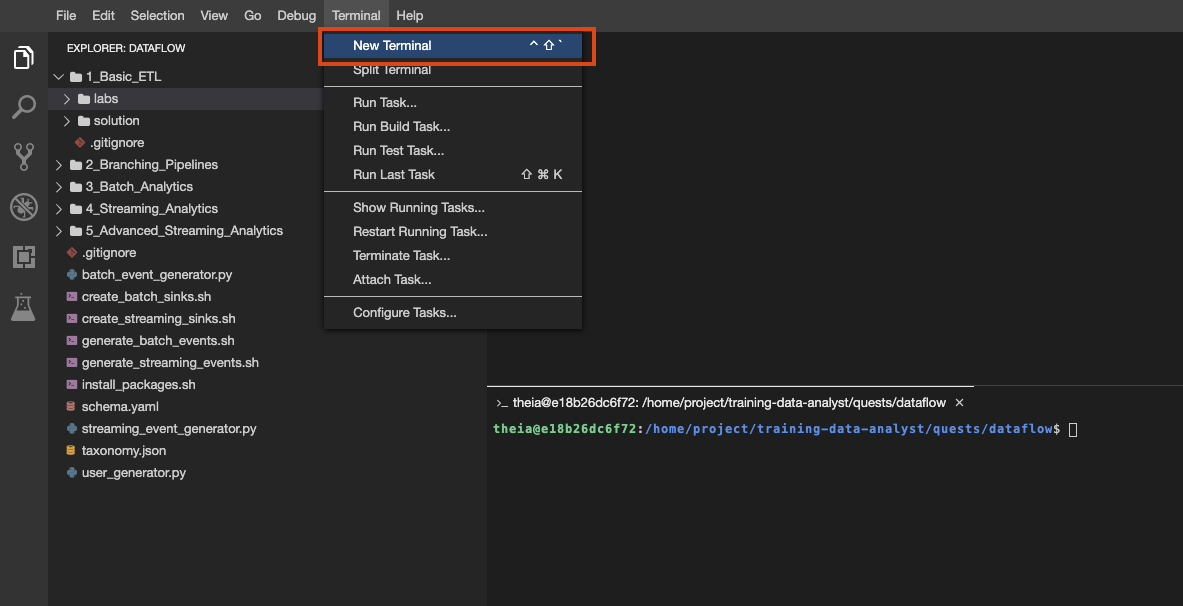
Também é possível criar vários terminais nesse ambiente, como você faria com o Cloud Shell:
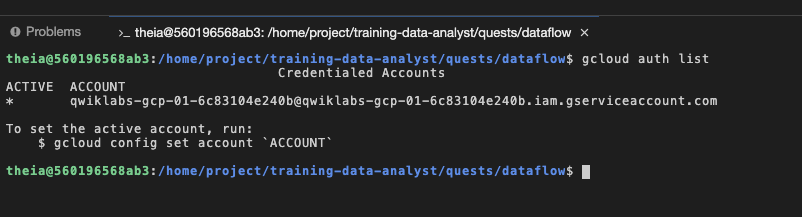
Outra forma de visualizar é executando gcloud auth list no terminal em que você fez login com uma conta de serviço fornecida. Ela tem as mesmas permissões que a sua conta de usuário do laboratório:
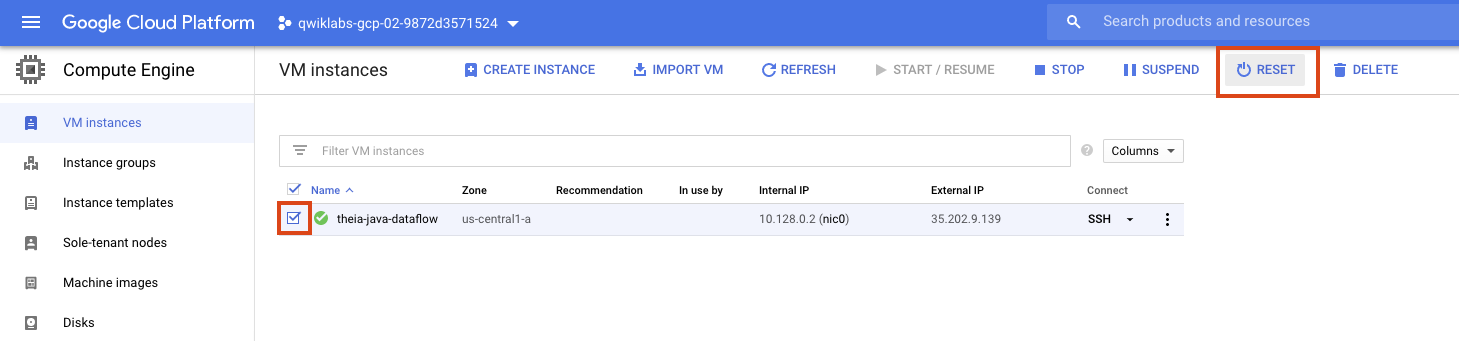
Se em algum momento o ambiente parar de funcionar, redefina a VM que hospeda o ambiente de desenvolvimento integrado no Console do GCE, conforme este exemplo:
Parte 1: Como agregar o tráfego do site por usuário
Nesta parte do laboratório, você vai criar um pipeline que:
Lê o tráfego do dia de um arquivo no Cloud Storage
Converte cada evento em um objeto CommonLog
Soma o número de hits de cada usuário único agrupando cada objeto por ID do usuário e combinando os valores para ter o número total de hits desse usuário específico
Realiza agregações extras em cada usuário
Grava os dados de resultado no BigQuery.
Tarefa 1: gerar dados sintéticos
Assim como nos laboratórios anteriores, a primeira coisa a se fazer é gerar os dados que o pipeline vai processar. Abra o ambiente do laboratório e gere os dados como antes:
Abra o laboratório apropriado
Crie um novo terminal no ambiente de desenvolvimento integrado, caso ainda não tenha feito isso. Depois copie e cole este comando:
# Change directory into the lab
cd 3_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configure o ambiente de dados
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
O script cria um arquivo chamado events.json com linhas semelhantes às seguintes:
Em seguida, ele copia o arquivo para o bucket do Google Cloud Storage em gs://my-project-id/events.json.
Acesse o Google Cloud Storage e confirme se o bucket de armazenamento contém um arquivo chamado events.json.
Clique em Verificar meu progresso para conferir o objetivo.
Gerar dados sintéticos
Tarefa 2: some as visualizações de página por usuário
Abra o BatchUserTrafficPipeline.java no ambiente de desenvolvimento integrado, encontrado em 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
O pipeline contém o código necessário para aceitar as opções de linha de comando do caminho de entrada e o nome da tabela de resultados, além do código para ler eventos no Google Cloud Storage, analisar esses eventos e gravar resultados no BigQuery. No entanto, estão faltando algumas partes importantes.
A próxima etapa no pipeline é agregar os eventos de cada user_id exclusivo e contar as visualizações de cada um. A maneira fácil de fazer isso em Linhas ou objetos com um esquema do Beam é usar a transformação Group.byFieldNames() e, em seguida, executar algumas agregações no grupo resultante. Exemplo:
vai retornar uma PCollection de linhas com dois campos: "key" e "values". O campo "key" é uma Linha com o esquema <userID:STRING, address:STRING> representando todas as combinações únicas de userID e address. O campo "values" é do tipo ITERABLE[ROW[MyObject]], em que estão todos os objetos nesse grupo exclusivo.
FieldName
FieldType
key
ROW{userId:STRING, streetAddress:STRING}
values
ITERABLE[ROW[Purchase]]
Isso tem utilidade quando é possível realizar cálculos agregados nesse agrupamento e nomear os campos resultantes da seguinte maneira:
As transformações Sum e Count são perfeitas para esse uso. Elas são exemplos de transformações Combine que podem atuar em grupos de dados.
Observação: neste exemplo, é possível agregar em qualquer um dos campos para Count.combineFn() ou até mesmo no campo curinga *, porque essa transformação apenas conta quantos elementos há em todo o grupo.
A próxima etapa no pipeline é agregar eventos por user_id, somar as visualizações de página e calcular mais algumas agregações em "num_bytes", por exemplo, o total de bytes do usuário.
Para concluir esta tarefa, adicione ao pipeline outra transformação que agrupe os eventos por user_id e, em seguida, realize as agregações relevantes. Importante: anote a entrada, a CombineFns a ser usada e os nomes dos campos de resposta.
Tarefa 3: nivele o esquema
Neste ponto, a nova transformação está retornando uma PCollection com o esquema <Key,Value>, já mencionado. Se você executar o pipeline como está, ele será gravado no BigQuery como dois RECORDS aninhados, mesmo se houver apenas uma linha de valores em cada um.
Para evitar que isso aconteça, adicione uma transformação Select, como a seguinte:
Isso vai manter os nomes de campo relevantes no novo esquema nivelado e remover "key" e "value".
Para concluir a tarefa, adicione uma transformação Select para nivelar o esquema da nova linha.
Observação: não se esqueça de alterar a dica do objeto em BigQueryIO.<CommonLog>write() para <Row>, caso ainda não tenha feito isso.
Tarefa 4: Executar o pipeline
Volte ao Cloud Shell e use o comando a seguir para executar o pipeline com o serviço do Dataflow. Se você tiver problemas, use o DirectRunner ou confira a solução.
Clique em Verificar meu progresso para conferir o objetivo.
Agregue o tráfego do site por usuário e execute o pipeline
Tarefa 5: verifique os resultados no BigQuery
Para terminar essa tarefa, aguarde alguns minutos até que o pipeline seja concluído. Em seguida, navegue até o BigQuery e veja a tabela user_traffic.
Se tiver curiosidade, comente a etapa de transformação Select e execute o pipeline de novo para ver o esquema resultante do BigQuery.
Parte 2: Como agregar o tráfego do site por minuto
Nesta parte do laboratório, você vai criar um novo pipeline chamado BatchMinuteTraffic, que se expande nos princípios básicos de análise em lote usados no BatchUserTraffic e, em vez de agregar por usuários em todo o lote, agrega os dados quando os eventos ocorreram.
No ambiente de desenvolvimento integrado, abra o arquivo BatchMinuteTrafficPipeline.java em 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Tarefa 1: adicione carimbos de data/hora a cada elemento
Uma origem ilimitada fornece um carimbo de data/hora para cada elemento. Dependendo da origem ilimitada, pode ser necessário configurar como o carimbo de data/hora é extraído do fluxo de dados brutos.
No entanto, as origens limitadas, por exemplo, um arquivo de TextIO como o usado neste pipeline, não fornecem carimbos de data/hora.
É possível analisar o campo de carimbo de data/hora com base em cada registro e usar a transformação WithTimestamps para anexar os carimbos de data/hora a cada elemento na PCollection:
Para concluir essa tarefa, adicione ao pipeline uma transformação que inclua carimbos de data/hora em cada elemento dele.
Tarefa 2: agrupe em janelas de um minuto
A gestão de janelas subdivide uma PCollection de acordo com os carimbos de data/hora dos elementos individuais dela. Transformações que agregam vários elementos, como GroupByKey e Combine, funcionam de maneira implícita por janela. Elas processam cada PCollection como uma sucessão de janelas múltiplas finitas, mas a coleção inteira pode ser de tamanho ilimitado.
É possível definir diferentes tipos de janelas para dividir os elementos da PCollection. O Beam fornece várias funções de gestão de janelas, incluindo:
Janelas de tempo fixo
Janelas de tempo variável
Janelas por sessão
Janela única global
Janelas baseadas em calendário (não compatíveis com o SDK do Beam para Python)
Neste laboratório, você usará janelas de tempo fixo. Uma janela de tempo fixo representa um intervalo de tempo de duração consistente e não coincidente no fluxo de dados. Pense em janelas com duração de cinco minutos: todos os elementos na PCollection ilimitada com valores de carimbo de data/hora de 0:00:00 até (mas não incluindo) 0:05:00 pertencem à primeira janela. Elementos com valores de carimbo de data/hora de 0:05:00 até (mas não incluindo) 0:10:00 pertencem à segunda janela e assim por diante.
Implemente uma janela de tempo fixo com duração de um segundo, da seguinte maneira:
O pipeline precisa calcular o número de eventos que ocorreram em cada janela. No pipeline BatchUserTraffic, uma transformação "Sum" foi usada para somar por chave. Nesse caso, ao contrário desse pipeline, os elementos foram exibidos em janelas e a computação escolhida precisa respeitar os limites da janela.
Mesmo com essa nova restrição, a transformação "Combine" ainda é adequada. Isso ocorre porque as transformações "Combine" respeitam os limites da janela.
Veja a documentação da Count e saiba como adicionar uma transformação para contar o número de elementos por janela.
A partir do Beam 2.22, a melhor opção para contar elementos de linhas durante o janelamento é usar Combine.globally(Count.<T>combineFn()).withoutDefaults(), isto é, sem usar sobre SQL. Falaremos mais sobre isso no próximo laboratório. Essa transformação vai gerar uma resposta do tipo PCollection<Long> que, você vai perceber, não usa mais os esquemas do Beam.
Para concluir essa tarefa, adicione uma transformação para contagem de todos os elementos de cada janela. Se tiver dificuldades, confira a solução.
Tarefa 4: converta de volta para uma linha e adicionar o carimbo de data/hora
Para gravar no BigQuery, cada elemento precisa ser convertido de volta em um objeto Row com "pageviews" como um campo e um outro campo chamado "minute". A ideia é usar os limites de cada janela como um campo e o número combinado de pageviews como outro.
Até agora, os elementos sempre estiveram em conformidade com um esquema do Beam depois de convertidos de um objeto JSON para o objeto CommonLog e, às vezes, de volta ao objeto Row. O esquema original foi inferido do POJO do CommonLog com a anotação @DefaultSchema(JavaFieldSchema.class) e todos os campos que foram adicionados/excluídos depois foram especificados nas transformações de pipeline. No entanto, nesse ponto do pipeline, de acordo com a resposta da transformação Count, cada elemento é do tipo Long. Portanto, será necessário criar um novo objeto Row do zero.
Os esquemas podem ser criados e registrados manualmente, da seguinte maneira. Esse código é adicionado fora do método main(), semelhante à definição do objeto CommonLog:
// Define the schema for the records.
Schema appSchema =
Schema
.builder()
.addInt32Field("appId")
.addStringField("description")
.addDateTimeField("rowtime")
.build();
Os objetos Row subsequentes desse esquema podem ser criados em uma PTransform, com base em entradas como um Long, como:
Em geral, o Beam requer uma indicação do novo esquema na PTransform, se a transformação estiver criando uma nova linha, em vez de modificar uma anterior:
Nesse ponto, outro problema é que a transformação "Count" só está fornecendo elementos do tipo "Long" que não mais assumem qualquer tipo de informação de carimbo de data/hora.
Na verdade, eles fazem isso, embora não de uma forma tão óbvia. Por padrão, os executores do Apache Beam sabem como fornecer o valor de vários outros parâmetros, incluindo carimbos de data/hora do evento, janelas e opções do pipeline. Consulte a documentação dos parâmetros DoFn do Apache para ver a lista completa.
Para concluir essa tarefa, escreva uma função ParDo que aceite elementos do tipo Long e emita elementos do tipo Row com o tipo de esquema fornecido pageViewsSchema, que tem um outro parâmetro de entrada do tipo IntervalWindow. Use esse outro parâmetro para criar uma instância do Instant e use-o para derivar uma representação de string para o campo de minuto":"
@ProcessElement
public void processElement(@Element T l, OutputReceiver<T> r, IntervalWindow window) {
Instant i = Instant.ofEpochMilli(window.start().getMillis());
...
r.output(...);
}
Tarefa 5: execute o pipeline
Depois de concluir a programação, execute o pipeline usando o comando abaixo. Importante: ao testar o código, a alteração da variável de ambiente "RUNNER" para o DirectRunner, que vai executar o pipeline no dispositivo, será muito mais rápida.
Clique em Verificar meu progresso para conferir o objetivo.
Agregar o tráfego do site por minuto e executar o pipeline
Tarefa 6: verifique os resultados
Para concluir essa tarefa, aguarde alguns minutos para que o pipeline seja executado, navegue até o BigQuery e consulte a tabela minute_traffic.
Finalize o laboratório
Após concluir o laboratório, clique em Terminar o laboratório. O Google Skills remove os recursos usados e limpa a conta para você.
Você poderá classificar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai criar dois pipelines que agregam o tráfego do site: um por usuário e outro por minuto.
Duração:
Configuração: 1 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos

 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.