



Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Generate synthetic data
/ 10
Aggregating site traffic by user and run your pipeline
/ 10
Aggregating site traffic by minute and run the pipeline
/ 10

In this lab, you:
Basic familiarity with Java.
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Google Skills using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
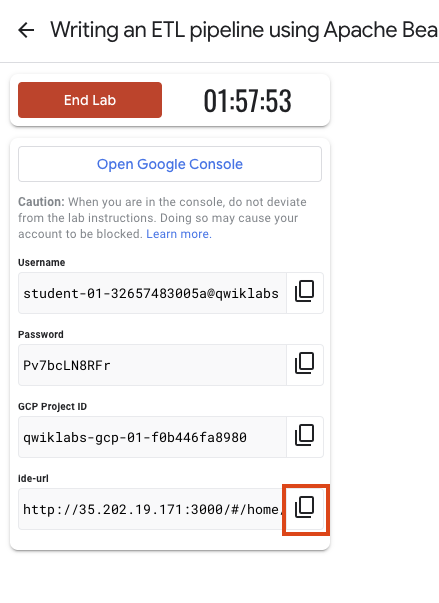
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts. If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
Before you begin your work on Google Cloud, you need to ensure that your project has the correct permissions within Identity and Access Management (IAM).
In the Google Cloud console, on the Navigation menu (
Confirm that the default compute Service Account {project-number}-compute@developer.gserviceaccount.com is present and has the editor role assigned. The account prefix is the project number, which you can find on Navigation menu > Cloud Overview > Dashboard.
editor role, follow the steps below to assign the required role.729328892908).{project-number} with your project number.Google Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud.
Google Cloud Shell provides command-line access to your Google Cloud resources.
In Cloud console, on the top right toolbar, click the Open Cloud Shell button.
Click Continue.
It takes a few moments to provision and connect to the environment. When you are connected, you are already authenticated, and the project is set to your PROJECT_ID. For example:
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
Output:
Example output:
Output:
Example output:
For the purposes of this lab, you will mainly be using a Theia Web IDE hosted on Google Compute Engine. It has the lab repo pre-cloned. There is java langauge server support, as well as a terminal for programmatic access to Google Cloud APIs via the gcloud command line tool, similar to Cloud Shell.
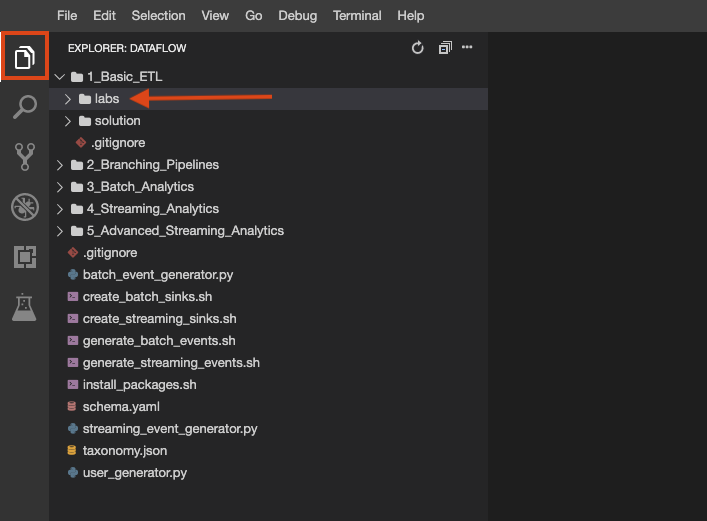
The lab repo has been cloned to your environment. Each lab is divided into a labs folder with code to be completed by you, and a solution folder with a fully workable example to reference if you get stuck.
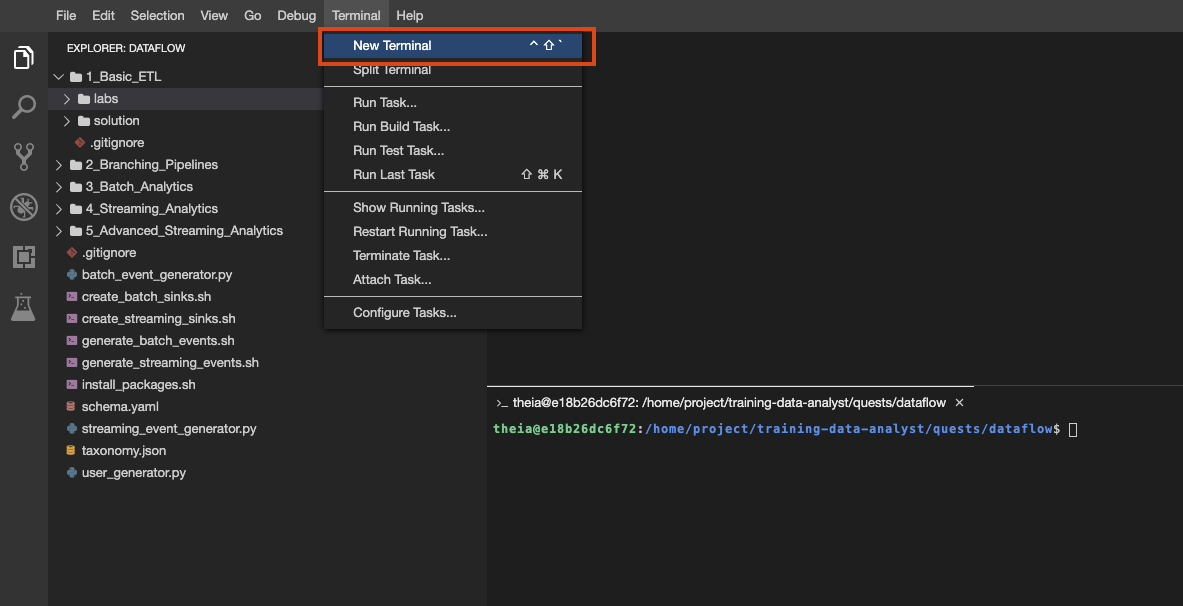
File Explorer button to look:You can also create multiple terminals in this environment, just as you would with cloud shell:
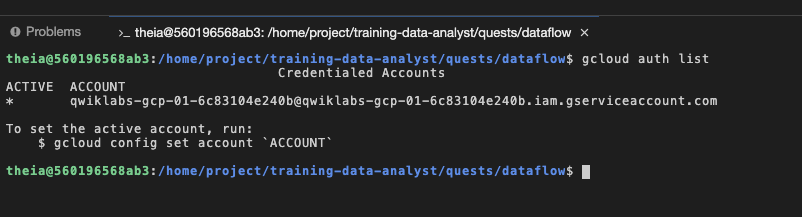
You can see with by running gcloud auth list on the terminal that you're logged in as a provided service account, which has the exact same permissions are your lab user account:
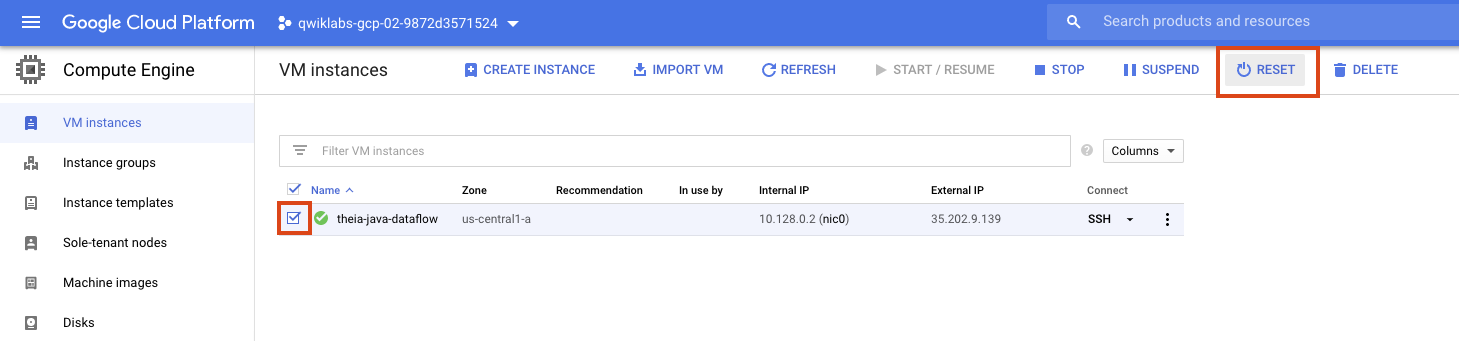
If at any point your environment stops working, you can try resetting the VM hosting your IDE from the GCE console like this:
In this part of the lab, you write a pipeline that:
CommonLog object.As in the prior labs, the first step is to generate data for the pipeline to process. You will open the lab environment and generate the data as before:
The script creates a file called events.json containing lines resembling the following:
It then automatically copies this file to your Google Cloud Storage bucket at gs://my-project-id/events.json.
Click Check my progress to verify the objective.
BatchUserTrafficPipeline.java in your IDE, which can be found in 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.This pipeline already contains the necessary code to accept command-line options for the input path and the output table name, as well as code to read in events from Google Cloud Storage, parse those events, and write results to BigQuery. However, some important parts are missing.
user_id and count pagviews for each. Any easy way to do this on Rows or objects with a Beam schema is to use the Group.byFieldNames() transform and then perform some aggregations on the resulting group. For example:will return a PCollection of rows with two fields, "key" and "values". The "key" field is itself a Row with schema <userID:STRING, address:STRING> representing every unique combination of userID and address. The "values" field is of type ITERABLE[ROW[MyObject]] containing all of the objects in that unique group.
| FieldName | FieldType |
|---|---|
| key | ROW{userId:STRING, streetAddress:STRING} |
| values | ITERABLE[ROW[Purchase]] |
This returns a "key" "value" Row, as opposed to "values" plural.
| FieldName | FieldType |
|---|---|
| key | ROW{userId:STRING} |
| value | ROW{numPurchases: INT64, totalSpendCents: INT64, largestPurchases: INT64} |
The Sum and Count transforms are perfect for this use. Sum and Count are examples of Combine transforms that can act on groups of data.
Count.combineFn(), or even on the wildcard field *, as this transform is simply counting how many elements are in the entire group.To complete this task, add another transform to the pipeline which groups the events by user_id and then performs the relevant aggregations. Keep in mind the input, the CombineFns to use, and how you name the output fields.
At this point, your new transform is returning a PCollection with schema <Key,Value> as already mentioned. If you run your pipeline as is, it will be written to BigQuery as two nested RECORDS, even though there is essentially only one row of values in each.
Select transform like the following:This will retain the relevant field names in the new flattened Schema, and remove "key" and "value".
Select Transform to flatten the schema of your new row.Note: Remember to change the object hint in BigQueryIO.<CommonLog>write() to <Row> if you haven't already.
Click Check my progress to verify the objective.
To complete this task, wait a few minutes for the pipeline to complete, then navigate to BigQuery and query the user_traffic table.
If you are curious, comment out your Select transform step and re-run the pipeline to see the resulting BigQuery schema.
In this part of the lab, you create a new pipeline called BatchMinuteTraffic. BatchMinuteTraffic expands on the basic batch analysis principles used in BatchUserTraffic and, instead of aggregating by users across the entire batch, aggregates by when events occurred.
BatchMinuteTrafficPipeline.java inside 3_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.An unbounded source provides a timestamp for each element. Depending on your unbounded source, you may need to configure how the timestamp is extracted from the raw data stream.
However, bounded sources (such as a file from TextIO, as is used in this pipeline) do not provide timestamps.
Windowing subdivides a PCollection according to the timestamps of its individual elements. Transforms that aggregate multiple elements, such as GroupByKey and Combine, work implicitly on a per-window basis — they process each PCollection as a succession of multiple, finite windows, though the entire collection itself may be of unbounded size.
You can define different kinds of windows to divide the elements of your PCollection. Beam provides several windowing functions, including:
In this lab, you use fixed-time windows. A fixed-time window represents a consistent duration, non-overlapping time interval of consistent duration in the data stream. Consider windows with a five-minute duration: all of the elements in your unbounded PCollection with timestamp values from 0:00:00 up to (but not including) 0:05:00 belong to the first window, elements with timestamp values from 0:05:00 up to (but not including) 0:10:00 belong to the second window, and so on.
To learn more about other types of windowing, read the section on window functions in the Apache Beam documentation.
Next, the pipeline needs to compute the number of events that occurred within each window. In the BatchUserTraffic pipeline, a Sum transform was used to sum per key. However, unlike in that pipeline, in this case the elements have been windowed and the desired computation needs to respect window boundaries.
Despite this new constraint, the Combine transform is still appropriate. That’s because Combine transforms automatically respect window boundaries.
As of Beam 2.22, the best option to count elements of rows while windowing is to use Combine.globally(Count.<T>combineFn()).withoutDefaults() (that is, without using full-on SQL, which we will cover more in the next lab). This transform will output type PCollection<Long> which, you'll notice, is no longer using Beam schemas.
In order to write to BigQuery, each element needs to be converted back to a Row object with "pageviews" as a field and additional field called "minute". The idea is to use the boundary of each window as one field and the combined number of pageviews as the other.
Thus far, the elements have always conformed to a Beam schema once converted from a JSON String to CommonLog object, and sometimes reverting back to Row object. The original schema was inferred from the CommonLog POJO via the @DefaultSchema(JavaFieldSchema.class) annotation and any subsequently added/deleted fields were specified in pipeline transforms. However, at this point in the pipline, as per the output of the Count transform, every element is of type Long. Therefore, a new Row object will need to be created from scratch.
CommonLog object definition:Row objects of this schema could then be created in a PTransform, potentially based on inputs such as a Long, like:More on creating versus inferring schemas in Apache's Beam SQL walkthrough.
One other issue, at this point, is that the Count transform is only providing elements of type Long that no longer bear any sort of timestamp information.
In fact, however, they do, though not in so obvious a way. Apache Beam runners know by default how to supply the value for a number of additional parameters, including event timestamps, windows, and pipeline options; see Apache's DoFn parameters documentation for a full list.
pageViewsSchema, which has been provided for you, and that has an additional input parameter of type IntervalWindow. Use this additional parameter to create an instance of Instant, and use this to derive a string representation for the minute field":"Click Check my progress to verify the objective.
minute_traffic table.When you have completed your lab, click End Lab. Google Skills removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2026 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one