

准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Create a view table
/ 30
Create a BQML model
/ 30
Fix the error and retrieve the top 10 purchases for each country.
/ 40
BigQuery Machine Learning (BigQuery ML) 让用户可以利用 SQL 查询,在 BigQuery 中创建和执行机器学习模型。其目标是让 SQL 专业人员能够利用现有的工具构建模型,并通过消除数据移动需求来提高开发速度,从而实现机器学习的普及。
本实验中有一个电子商务数据集,其中包含 Google Merchandise Store 的上百万条 Google Analytics 记录,并且已加载到 BigQuery。在此实验中,您要使用这些数据创建一个预测访问者是否会进行交易的模型。
如何在 BigQuery 中创建、评估和使用机器学习模型
对于每个实验,您都会免费获得一个新的 Google Cloud 项目及一组资源,它们都有固定的使用时限。
请使用无痕式窗口登录 Qwiklabs。
留意实验的访问时限(例如 1:15:00)并确保能在相应时间段内完成实验。
系统不提供暂停功能。如有需要,您可以重新开始实验,不过必须从头开始。
准备就绪时,点击开始实验。
请记好您的实验凭据(用户名和密码)。您需要使用这组凭据来登录 Google Cloud 控制台。
点击打开 Google 控制台。
点击使用其他帐号,然后将此实验的凭据复制并粘贴到相应提示框中。
如果您使用其他凭据,将会收到错误消息或产生费用。
接受条款并跳过恢复资源页面。
您会看到欢迎在 Cloud 控制台中使用 BigQuery 消息框,其中会显示快速入门指南的链接以及界面更新。
在此任务中,您将探索并准备一个公开数据集,以用于机器学习模型。您将执行 SQL 查询以检查 Google Analytics 数据样本,并将结果保存为 training_data。
我们将在本实验中使用的数据位于 bigquery-public-data 项目中,该项目可供所有用户使用。我们来看此数据的一个示例。
如需验证 bqml_lab 数据集是否存在,请点击以 qwiklabs-gcp-00-XXXXXXXXXX 开头的 Project_ID 左侧的箭头。bqml_lab 数据集应该会在下方列出。
点击 
选中该查询。
点击该查询左侧的 
点击解释此查询。
Gemini 对话框将在 BigQuery Studio 的右侧打开。
Gemini 窗格中将显示“欢迎使用 Cloud 控制台中的 Gemini”。点击开始聊天。在聊天窗口中,您将看到类似以下内容的查询解释:
Gemini 给出的回答可能类似以下内容:
点击运行。
点击保存,然后选择保存视图。
在“保存视图”对话框中,点击数据集,然后选择 bqml_lab。
对于“表”,输入 training_data,然后点击保存。
点击检查我的进度,验证已完成以下目标:
在此任务中,您将使用 BigQuery 中的 SQL 查询自然语言提示生成新的机器学习模型,以预测访问者交易量。您将指定逻辑回归模型类型,并使用现有的 training_data 对其进行训练。
点击
点击 
复制并粘贴下方的提示。
点击生成。Gemini 建议的 SQL 查询可能类似以下内容:
点击插入。
点击运行。
在此例中,bqml_lab 是数据集的名称,sample_model 是模型的名称,training_data 是我们在上一个任务中分析的交易数据。指定的模型类型是二进制逻辑回归。
运行 CREATE MODEL 命令会创建一个异步运行的查询作业,这样就可以执行关闭或刷新 BigQuery 界面窗口等任务。
点击检查我的进度,验证已完成以下目标:
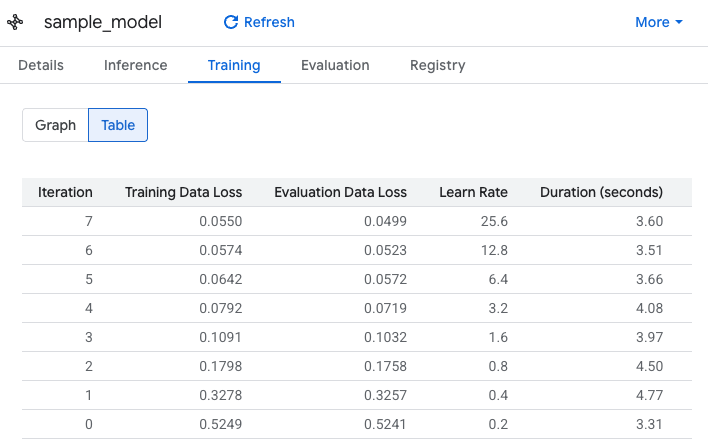
如果有兴趣,可以在左侧菜单中点击 bqml_lab 数据集,然后在界面中点击 sample_model 数据集来获取有关模型的信息。在详细信息标签页下,可以找到一些基础的模型信息和用于生成模型的训练选项。在训练下,应该可以看到类似如下所示的表:
在此任务中,您将使用 ML.EVALUATE 函数来评估机器学习模型的性能。这可提供关键指标,以显示模型预测访问者交易量的准确程度。
点击
点击
复制并粘贴下方的提示。
点击生成。Gemini 建议的 SQL 查询可能类似以下内容:
点击插入。
点击运行。
您应该会看到类似如下所示的表:
在此任务中,您将学习如何使用 BigQuery 的 ML.PREDICT 函数进行预测,但首先,您必须调试一个使用了错误函数的查询。您将使用 Gemini 识别并更正语法错误,然后再运行查询来预测购买量最高的 10 个国家/地区。
以创建一个新的 SQL 查询,然后运行以下查询:您将发现,查询的 SELECT 和 FROM 部分与用来生成训练数据的部分类似。还有一个额外的 fullVisitorId 列,您可以使用该列来预测单个用户的交易。WHERE 部分反映了时间范围的变化(2017 年 7 月 1 日至 8 月 1 日)。
我们来保存一下七月份的数据,以便在接下来的步骤中用我们的模型基于这些数据进行预测。
点击保存,然后选择保存视图。
在“保存视图”对话框中,点击数据集,然后选择 bqml_lab。
对于“表”,输入 july_data,然后点击保存。
预测每个国家/地区的购买量
利用这个查询,您可以尝试预测每个国家/地区的访问者的交易量,对结果排序,并选出购买量最高的 10 个国家/地区:
点击
复制并粘贴以下查询。
点击运行。您会发现该查询运行失败了,并显示如下错误:
点击 BigQuery 中的 Gemini 聊天窗口。
在聊天窗口中,复制并粘贴以下问题。
在聊天窗口中按下 <SHIFT><ENTER>(Mac 用户请按下 <SHIFT><return>)来换行。
选中并复制该查询。
将复制的查询粘贴到您刚才输入的问题下方。
在聊天窗口中按下 <SHIFT><ENTER>(Mac 用户请按下 <SHIFT><return>)来换行。
复制并粘贴以下句子:
点击 
仔细阅读回答中提供的建议。根据这些建议,可以得知 TOTAL() 在 BigQuery 中不是有效的 SQL 聚合函数。
建议中提供了类似以下内容的优化查询,有可能解决问题:
复制该优化的查询。
点击
将优化后的查询粘贴到新的未命名查询标签页中。
点击运行。
在此查询中,您将使用 ml.PREDICT,查询的 BigQuery ML 部分会使用标准 SQL 命令进行封装。对于此实验,您关注的是国家/地区以及每个国家/地区的购买总量,所以才使用 SELECT、GROUP BY 和 ORDER BY. LIMIT 来确保只获取排名前十的结果。
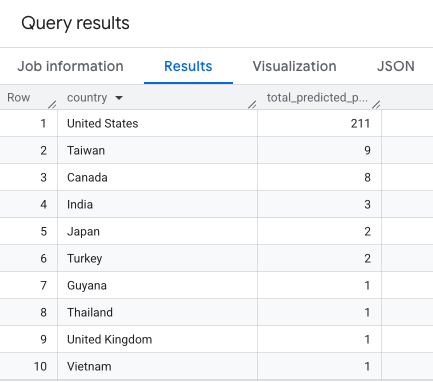
您应该会看到类似如下所示的表:
点击检查我的进度,验证已完成以下目标:
预测每位用户的购买量
现在,您将试着预测每个访问者的交易量,对结果排序,并选出交易量最高的前十个访问者。
完成实验后,请点击结束实验。Google Cloud Skills Boost 会移除您使用过的资源并为您清理帐号。
系统会提示您为实验体验评分。请选择相应的星级数,输入评论,然后点击提交。
星级数的含义如下:
如果您不想提供反馈,可以关闭该对话框。
如果要留言反馈、提出建议或做出更正,请使用支持标签页。
版权所有 2020 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验