Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
Com a API Cloud Natural Language, é possível extrair entidades do texto, fazer análises sintáticas e de sentimento e classificar o texto em categorias. Neste laboratório, vamos conferir a classificação de texto. Com um banco de dados de mais de 700 categorias, esse recurso de API facilita a classificação de um grande conjunto de dados de texto.
Conteúdo do laboratório
Como criar uma solicitação da API Natural Language e chamar a API com curl
Como usar o recurso de classificação de texto da API NL
Como usar a classificação de texto para entender um conjunto de dados de artigos de notícias
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Tarefa 1: confirme se a API Cloud Natural Language está ativada
Clique no ícone do menu de navegação () na parte de cima à esquerda da tela.
Selecione APIs e serviços > APIs e serviços ativados.
Clique em + ATIVAR APIS E SERVIÇOS.
Em seguida, digite language na caixa de pesquisa. Clique em API Cloud Natural Language.
O botão ATIVAR vai aparecer se a API não estiver ativada. Clique em ATIVAR para ativar a API Cloud Natural Language.
Quando a API é ativada, o botão GERENCIAR aparece no bloco API Cloud Natural Language.
Tarefa 2: crie uma chave de API
Já que você usa curl para enviar uma solicitação à API Natural Language, é necessário gerar uma chave de API para transmitir o URL da solicitação.
Para criar a chave, acesse o console e clique em Menu de navegação > APIs e serviços > Credenciais.
Clique em + CRIAR CREDENCIAIS.
No menu suspenso, selecione Chave de API:
Em seguida, copie a chave que você acabou de gerar. Clique em FECHAR.
Agora salve a chave de API em uma variável de ambiente para não precisar inserir o valor dela em cada solicitação.
No Cloud Shell, execute o comando abaixo. Substitua <your_api_key> pela chave que você copiou.
export API_KEY=<YOUR_API_KEY>
Tarefa 3: classifique uma notícia
Com o método classifyText da API Natural Language, você pode classificar dados de texto em categorias com uma única chamada da API. Esse método retorna uma lista de categorias de conteúdo que se aplicam a um documento de texto. Elas variam desde categorias amplas como /Computadores e eletrônicos até outras altamente específicas como /Computadores e eletrônicos/Programação/Java (linguagem de programação). A lista completa das mais de 700 categorias possíveis está disponível no guia de categorias de conteúdo.
Vamos começar com a classificação de um único artigo. Depois vamos aprender a usar o método para analisar um grande conjunto de notícias. Para começar, confira o título e a descrição de um artigo do New York Times na seção de alimentos:
A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.
No seu ambiente do Cloud Shell, crie um arquivo request.json com o código abaixo. É possível criar o arquivo usando um dos editores de linha de comando que preferir (nano, vim, emacs) ou usar o editor de código do Cloud Shell:
Crie um arquivo chamado request.json e adicione o seguinte:
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}
Agora é possível enviar esse texto para o método classifyText da API Natural Language com o seguinte comando curl:
O texto não menciona explicitamente que se trata de uma receita ou mesmo que inclui frutos do mar, mas a API é capaz de categorizá-lo. Classificar um único artigo é interessante. No entanto, para conhecer toda a capacidade desse recurso, vamos classificar muitos dados de texto.
Tarefa 4: como classificar um conjunto grande de dados de texto
Para ver como o método classifyText pode nos ajudar a entender um grande conjunto de dados de texto, você usará este conjunto de dados públicos de artigos de notícias da BBC. O conjunto de dados é composto por 2.225 artigos em cinco áreas temáticas (negócios, entretenimento, política, esportes e tecnologia) de 2004 a 2005. Um subconjunto desses artigos está armazenado em um bucket público do Google Cloud Storage. Cada um dos artigos está em um arquivo .txt.
Para examinar os dados e enviá-los para a API Natural Language, você escreverá um script do Python para ler cada arquivo de texto do Cloud Storage, enviá-lo para o endpoint classifyText e armazenar os resultados em uma tabela do BigQuery. O BigQuery é a ferramenta de data warehouse para Big Data do Google Cloud. Com ele, você pode armazenar e analisar facilmente grandes conjuntos de dados.
Execute o comando a seguir para conferir um dos artigos com que você vai trabalhar.
Em seguida, você vai criar uma tabela do BigQuery para os dados.
Tarefa 5: crie uma tabela do BigQuery para os dados de texto categorizados
Antes de enviar o texto para a API Natural Language, você precisa de um local para armazenar o texto e a categoria de cada artigo.
No console do Google Cloud, clique no Menu de navegação () > BigQuery.
Quando a mensagem de recepção ao BigQuery aparecer, clique em Concluído.
No painel à esquerda, clique no ícone Exibir ações (), ao lado do nome do projeto e, em seguida, em Criar banco de dados.
Em ID do conjunto de dados, digite news_classification_dataset
Clique em Criar conjunto de dados.
Clique no ícone Ver ações ao lado do nome do conjunto de dados e clique em Criar tabela. Use as configurações abaixo para a nova tabela:
Criar tabela de: Tabela em branco
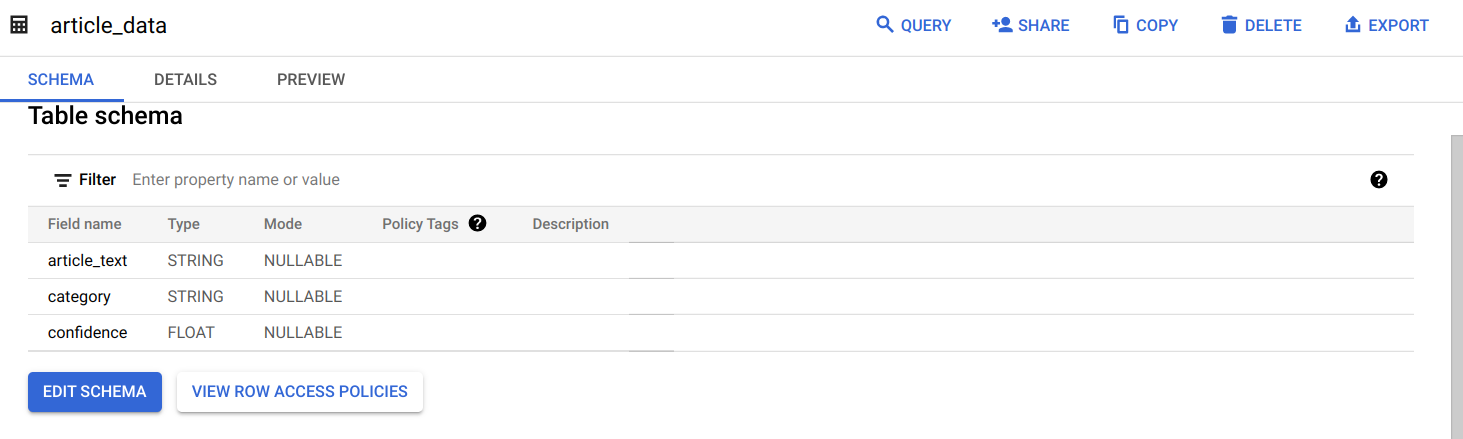
Nomeie a tabela como article_data
Clique em Adicionar campo (+) em Esquema e adicione três campos:
article_text do tipo STRING,
category do tipo STRING e
confidence do tipo FLUTUANTE.
Em seguida, clique em CRIAR TABELA.
A tabela está vazia por enquanto. Na próxima etapa, você vai ler artigos do Cloud Storage, enviar o texto para a classificação da API Natural Language e armazenar o resultado no BigQuery.
Tarefa 6: classifique dados de notícias e armazene o resultado no BigQuery
Antes de escrever um script para enviar os dados de notícias para a API Natural Language, você precisa criar uma conta de serviço. Ela será usada para autenticar a API Natural Language e o BigQuery com um script do Python.
Primeiro, de volta ao Cloud Shell, exporte o nome do projeto do Cloud como uma variável de ambiente. Substitua <your_project_name> pelo ID do projeto do GCP que aparece no painel Detalhes do laboratório:
export PROJECT=<your_project_name>
Em seguida, execute os seguintes comandos no Cloud Shell para criar uma conta de serviço:
Você já pode enviar os dados de texto para a API Natural Language.
Para isso, escreva um script do Python usando o módulo do Python para o Google Cloud. Você pode fazer o mesmo em qualquer linguagem. Existem muitas bibliotecas de clientes de nuvem.
Crie um arquivo chamado classify-text.py e copie o seguinte para ele. Substitua YOUR_PROJECT pelo ID do seu projeto do GCP.
Observação: mantenha as aspas simples ao redor do valor do ID do projeto.
from google.cloud import storage, language_v1, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language_v1.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project id below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_classification_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data') # Update this if you used a different table name
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language_v1.types.Document(
content=article,
type_='PLAIN_TEXT'
)
)
return response
rows_for_bq = []
files = storage_client.bucket('cloud-training-demos-text').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_bytes()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((str(article_text), str(nl_response.categories[0].name), nl_response.categories[0].confidence))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.insert_rows(table, rows_for_bq)
assert errors == []
Você já pode classificar artigos e importá-los para o BigQuery.
Execute o script a seguir:
python3 classify-text.py
O script leva cerca de dois minutos. Enquanto ele está em execução, vamos discutir o que está acontecendo.
Observação: se ocorrer um erro na execução de python3 classify-text.py, talvez o Cloud Shell esteja desconectado. Para corrigir isso, execute os comandos abaixo para exportar as variáveis de ambiente e execute python3 classify-text.py de novo.
export PROJECT= (GCP PROJECT ID)
export GOOGLE_APPLICATION_CREDENTIALS=key.json
Estamos usando a biblioteca de cliente do Python "google-cloud" para acessar o Cloud Storage, a API Natural Language e o BigQuery. Primeiro, um cliente é criado para cada serviço. Em seguida, são criadas referências para a tabela do BigQuery. O código files é uma referência para cada um dos arquivos do conjunto de dados da BBC no bucket público. Iteramos esses arquivos, salvamos os artigos localmente como strings e enviamos cada um deles para a API Natural Language na função classify_text. Para todos os artigos que a API Natural Language retorna uma categoria, o artigo e os dados de categoria são salvos em uma lista "rows_for_bq". Depois de classificar cada artigo, os dados são inseridos no BigQuery usando insert_rows().
Observação: a API Natural Language pode retornar mais de uma categoria para um documento. Neste laboratório, você armazena apenas a primeira categoria retornada para simplificar o processo.
Quando a execução do script terminar, verifique se os dados do artigo foram salvos no BigQuery.
No BigQuery, acesse a tabela article_data na guia "Explorer" e clique em CONSULTA > Em uma nova guia:
Edite os resultados na caixa Sem título adicionando um asterisco entre SELECT e FROM:
SELECT * FROM `news_classification_dataset.article_data`
Clique em EXECUTAR.
Os dados serão exibidos quando a consulta terminar. Role para a direita para ver a coluna da categoria.
A coluna "categoria" tem o nome da primeira categoria que a API Natural Language retornou para o artigo. A confiança é um valor entre 0 e 1 que indica o grau de confiança da API em categorizar o artigo corretamente. Na próxima etapa, você vai aprender a realizar consultas mais complexas nos dados.
Tarefa 7: analise dados de notícias categorizados no BigQuery
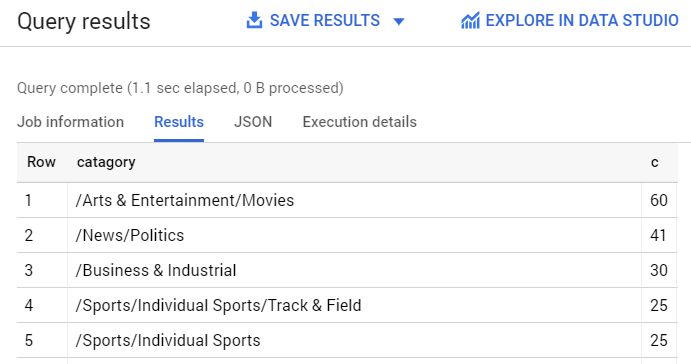
Primeiro confira quais categorias foram mais comuns no conjunto de dados.
No console do BigQuery, clique em + Criar consulta.
Digite a seguinte consulta:
SELECT
category,
COUNT(*) c
FROM
`news_classification_dataset.article_data`
GROUP BY
category
ORDER BY
c DESC
Clique em Executar.
Os resultados da consulta devem ser parecidos com estes:
Para encontrar o artigo retornado para uma categoria mais específica como /Arts & Entertainment/Music & Audio/Classical Music, você poderia executar esta consulta:
SELECT * FROM `news_classification_dataset.article_data`
WHERE category = "/Arts & Entertainment/Music & Audio/Classical Music"
Para exibir apenas os artigos que a API Natural Language retornou com uma pontuação de confiança acima de 90%, execute esta consulta.
SELECT
article_text,
category
FROM `news_classification_dataset.article_data`
WHERE cast(confidence as float64) > 0.9
Para realizar mais consultas nos seus dados, consulte a documentação do BigQuery. O BigQuery também se integra a várias ferramentas de visualização. Para criar visualizações com seus dados de notícias categorizados, confira o Guia de início rápido do Data Studio para o BigQuery.
Parabéns!
Você aprendeu a usar o método de classificação de texto da API Natural Language para classificar artigos de notícias. Você começou classificando um artigo e, em seguida, aprendeu a classificar e analisar um grande conjunto de dados de notícias usando a API NL com o BigQuery.
O que vimos
Como criar uma solicitação classifyText da API Natural Language e chamar a API com curl
Como usar o módulo do Python no Google Cloud para analisar um grande conjunto de dados de notícias
Como importar e analisar dados no BigQuery
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você vai aprender a classificar textos em categorias usando a API Natural Language
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 60 minutos



 ) na parte de cima à esquerda da tela.
) na parte de cima à esquerda da tela.
 ), ao lado do nome do projeto e, em seguida, em Criar banco de dados.
), ao lado do nome do projeto e, em seguida, em Criar banco de dados.