Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Visão geral
O BigQuery é um banco de dados NoOps totalmente gerenciado, de baixo custo, desenvolvido pelo Google e utilizado para análises. Com o BigQuery, você consulta terabytes e terabytes de dados sem gerenciar infraestrutura alguma e sem precisar de um administrador de banco de dados. O BigQuery usa SQL e oferece o modelo de pagamento por utilização. Assim, você pode se concentrar na análise dos dados para encontrar insights relevantes.
O BigQuery Machine Learning (BQML, produto na versão Beta) é um novo recurso do BigQuery. Nele, os analistas de dados podem criar, treinar, avaliar e fazer previsões com modelos de machine learning que exigem o mínimo de programação.
Neste laboratório, você analisará milhões de corridas dos táxis amarelos de Nova York, disponibilizadas em um conjunto de dados público do BigQuery. Em seguida, você criará um modelo de machine learning dentro do BigQuery para prever as tarifas cobradas, tendo como base as entradas do seu modelo. Por fim, você avaliará o desempenho do seu modelo ao fazer as previsões.
Objetivos
Neste laboratório, você aprenderá a realizar estas tarefas:
Usar o BigQuery para encontrar conjuntos de dados públicos
Consultar e analisar o conjunto de dados público sobre os táxis
Criar um conjunto de dados de treinamento e avaliação e usá-lo para fazer previsões em lote
Criar um modelo de previsão (regressão linear) no BQML
Avaliar o desempenho do seu modelo de machine learning
Você precisará do seguinte:
Um projeto do Google Cloud Platform
Um navegador (como o Google Chrome ou o Mozilla Firefox)
Configure o ambiente
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Abra o BigQuery no Console do Cloud
No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você vai ver a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da interface.
Clique em Concluído.
Analise os dados sobre corridas de táxi em Nova York
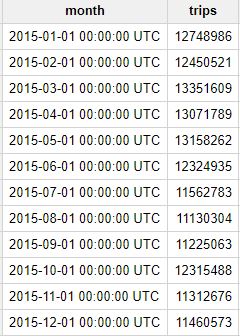
Pergunta: Quantas corridas os táxis amarelos fizeram por mês em 2015?
Adicione a seguinte consulta no Editor de consultas:
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
Depois, clique em Executar.
Resultado:
Pergunta: Qual foi a velocidade média das corridas dos táxis amarelos em 2015?
Substitua a consulta anterior pelas informações abaixo e clique em Executar:
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
Resultado:
Durante o dia, a velocidade média é de aproximadamente 18 a 19 km/h, mas ela quase dobra para 34 km/h às 5h da manhã. Isso faz sentido, já que provavelmente há menos tráfego nesse horário.
Identifique um objetivo
Agora você criará um modelo de machine learning no BigQuery para prever o preço de uma corrida de táxi em Nova York com base no conjunto de dados históricos das corridas e dados sobre as corridas. Prever a tarifa antes da corrida pode ser muito útil no planejamento da viagem, tanto para o passageiro quanto para a empresa de táxi.
Selecione atributos e crie seu conjunto de dados de treinamento
O conjunto de dados público sobre os táxis amarelos de Nova York é fornecido pela cidade e foi carregado no BigQuery para você analisar. Veja a lista completa dos campos aqui e depois visualize o conjunto de dados para encontrar atributos úteis que podem ajudar um modelo de machine learning a entender a relação entre os dados históricos das corridas de táxi e as tarifas cobradas.
Sua equipe decide testar se os campos abaixo serão úteis para o modelo de previsão de tarifas:
Valor dos pedágios
Valor da tarifa
Hora do dia
Endereço de partida
Endereço de destino
Número de passageiros
Substitua a consulta pelo seguinte:
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
Observe estas características da consulta:
A parte principal da consulta está no final: (SELECT * from taxitrips)
taxitrips faz a maior parte da extração para o conjunto de dados de Nova York, e SELECT contém o rótulo e os atributos do treinamento.
WHERE remove os dados que você não quer adicionar ao treinamento.
WHERE também inclui uma cláusula de amostra para coletar apenas 1/1.000 dos dados.
Definimos uma variável chamada TRAIN para você criar um conjunto EVAL independente com rapidez.
Depois, clique em Executar.
Resultados da amostra:
Qual é o rótulo (resposta correta)?
total_fare é o rótulo (o que será previsto). Como você criou esse campo com base em tolls_amount e fare_amount, pode desconsiderar a inclusão das gorjetas dos clientes no modelo, porque elas são opcionais.
Crie um conjunto de dados do BigQuery para armazenar modelos
Em seguida, crie um novo conjunto de dados do BigQuery que também armazenará seus modelos de ML.
No painel esquerdo, clique no nome do projeto e em Criar conjunto de dados.
Na caixa de diálogo Criar conjunto de dados, siga estas instruções:
Em ID do conjunto de dados, insira taxi.
Mantenha os outros valores padrão.
Clique em Criar conjunto de dados.
Selecione um tipo de modelo do BQML e especifique as opções
Agora que você selecionou os atributos iniciais, já pode criar o primeiro modelo de ML no BigQuery.
Há dois tipos de modelos para escolher:
Modelo
Tipo de modelo
Tipo de dados de rótulo
Exemplo
Previsão
linear_reg
Valor numérico (normalmente um número inteiro ou ponto flutuante)
Prever os valores de vendas para o próximo ano com base nos dados históricos das vendas.
Classificação
logistic_reg
0 ou 1 para classificação binária
Classificar um e-mail como spam ou não spam, de acordo com o contexto.
Classificação multiclasse
logistic_reg
Esses modelos podem ser usados para prever diversos valores possíveis. Por exemplo, se uma entrada tem um valor "baixo", "médio" ou "alto". Os rótulos podem ter até 50 valores exclusivos.
Classificar um e-mail como spam, prioridade normal ou alta importância.
Observação: vários outros tipos de modelo usados em machine learning, como redes neurais e árvores de decisão, estão disponíveis em bibliotecas como o TensorFlow. Por enquanto, o BQML aceita os dois tipos indicados acima.
Qual tipo de modelo você deve escolher? Como você está prevendo um valor numérico (tarifa de táxi), use a regressão linear.
Insira a seguinte consulta para criar um modelo e especificar opções de modelo, substituindo -- paste the previous training dataset query here pela consulta de conjunto de dados de treinamento criada anteriormente (sem a linha #standardSQL):
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
-- paste the previous training dataset query here
Depois, clique em Executar para treinar o modelo.
Aguarde o modelo ser treinado (5 a 10 minutos).
Após o treinamento do modelo, você verá o resultado This statement created a new model named <Project-ID>:taxi.taxifare_. Isso indica que seu modelo foi treinado corretamente.
Abra seu conjunto de dados sobre os táxis e confirme se taxifare_model aparece desta vez.
Em seguida, você avaliará o desempenho do modelo com novos dados de avaliação.
Avalie o desempenho do modelo de classificação
Selecione os critérios de desempenho
Para modelos de regressão linear, convém usar uma métrica de perda, como a Raiz do erro médio quadrado. Continue treinando e melhorando o modelo até ele atingir a menor RMSE.
No BQML, mean_squared_error é apenas um campo que pode ser consultado durante a avaliação do seu modelo de ML treinado. Basta adicionar SQRT () para gerar a RMSE.
Agora que o treinamento foi concluído, você pode avaliar o desempenho do modelo com essa consulta usando ML.EVALUATE:
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
Agora você está avaliando o modelo com outro conjunto de viagens de táxi usando seu filtro params.EVAL.
Depois que o modelo for executado, revise os resultados (o valor da RMSE do modelo apresentará pequenas variações).
Linha
RMSE
1
9.477056435999074
Após avaliar o modelo, você receberá uma RMSE de US$ 9,47. Saber se essa métrica de perda é aceitável ou não para a produção do seu modelo depende totalmente dos critérios de referência definidos antes do treinamento. A referência define um nível mínimo aceitável de desempenho e precisão para o modelo.
Compare as perdas de treinamento e avaliação
Você quer ter certeza de que não está causando o superajustamento, ou overfitting, do seu modelo com os dados. Causar overfitting no seu modelo reduzirá o desempenho dele com dados novos e ainda não acessados. Você pode comparar a perda de treinamento com a perda de avaliação usando ML.TRAINING_INFO.
SELECT * FROM ML.TRAINING_INFO(model `taxi.taxifare_model`);
Isso selecionará todas as informações de cada iteração do treinamento do modelo. O comando incluirá o número da iteração de treinamento, a perda de treinamento e a perda de avaliação.
Para comparar as perdas de treinamento e avaliação, analisaremos visualmente a diferença nas curvas de perda. Clique em EXPLORAR DADOS > Explorar com o Data Studio no Console do Cloud do BigQuery. Isso abrirá o Data Studio com os dados da sua consulta conectados como uma origem de entrada.
Quando solicitado, selecione o botão PRIMEIROS PASSOS.
Selecione AUTORIZAR para permitir que o Google Data Studio acesse seus dados.
Observação: se a mensagem Oops… Not able to connect to your data aparecer, clique em Voltar. Clique em Salvar no Data Studio Explorer.
Clique em PRIMEIROS PASSOS e aceite os Termos de Serviço. Clique em Aceitar.
Selecione Não, obrigado para todas as preferências e clique em Concluído.
Atualize a guia para carregar os dados.
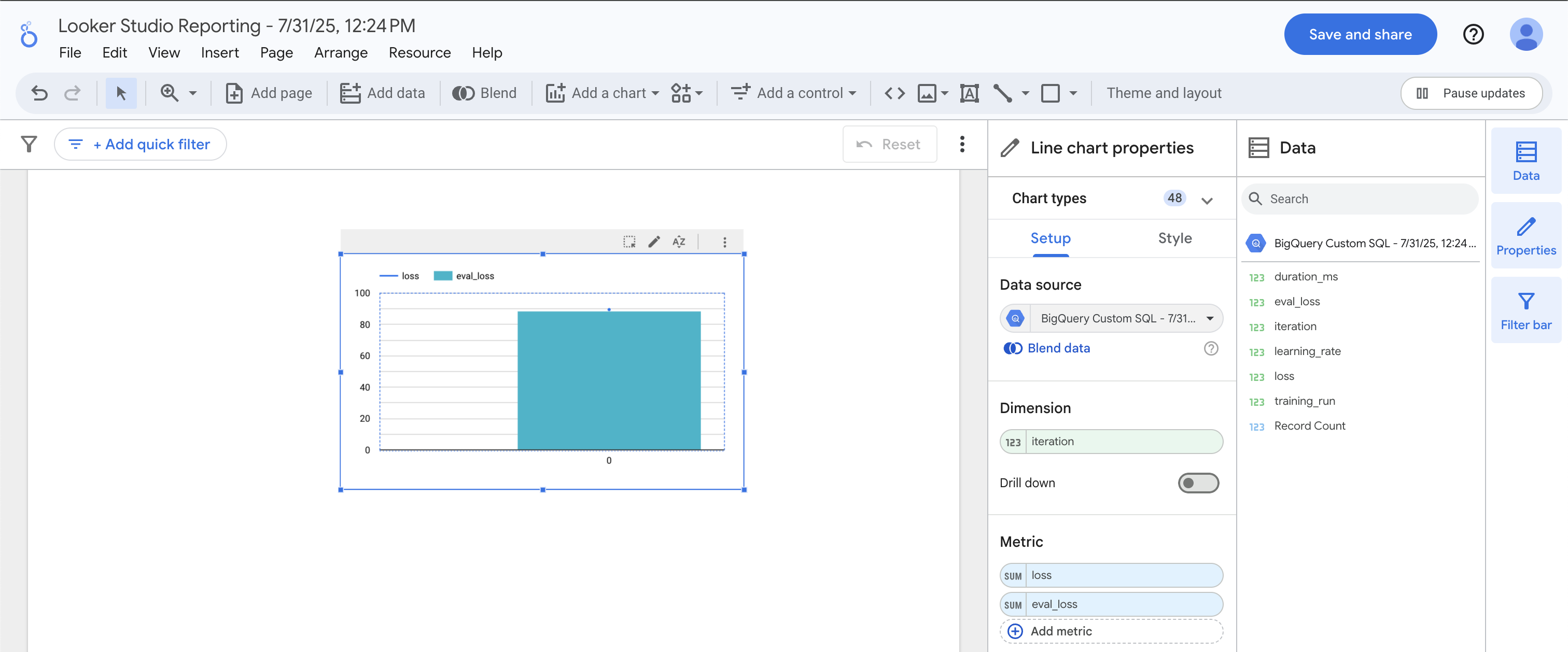
No Data Studio, clique no ícone do Gráfico de combinação.
Em Dimensão, arraste até iteration. Em Métrica, arraste até loss e eval_loss. Isso deve exibir um gráfico de linhas sobre um gráfico de barras.
A perda de treinamento corresponde à perda de avaliação de forma praticamente idêntica, o que indica que não estamos causando overfitting no modelo. Muito bem! É hora de fazer a previsão.
Estime o valor da tarifa de táxi
Agora você escreverá uma consulta para fazer previsões com seu novo modelo:
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
Agora você verá as previsões do modelo para tarifas de táxi, além das tarifas reais e outras informações sobre as corridas.
Mais informações
Dica: ao treinar seu modelo com novos dados, adicione warm_start = true às opções para acelerar o treinamento. Não é possível alterar as colunas de atributos (isso exigiria um novo modelo).
Outros conjuntos de dados para analisar
Use o link abaixo para acessar o projeto bigquery-public-data e criar modelos com outros conjuntos de dados. Você pode estimar as tarifas das corridas de táxi em Chicago:
Você criou um modelo de ML no BigQuery para estimar as tarifas das corridas de táxi da cidade de Nova York.
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você analisará milhões de corridas dos táxis amarelos de Nova York, disponibilizadas em um conjunto de dados público do BigQuery, criará um modelo de ML dentro do BigQuery para estimar as tarifas cobradas e avaliará o desempenho das predições do seu modelo.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 60 minutos