Te treści nie są jeszcze zoptymalizowane pod kątem urządzeń mobilnych.
Dla maksymalnej wygody odwiedź nas na komputerze, korzystając z linku przesłanego e-mailem.
Overview
BigQuery is Google's fully managed, NoOps, low cost analytics database. With BigQuery you can query terabytes and terabytes of data without having any infrastructure to manage, or needing a database administrator. BigQuery uses SQL and can take advantage of the pay-as-you-go model. BigQuery allows you to focus on analyzing data to find meaningful insights.
BigQuery Machine Learning (BQML, product in beta) is a new feature in BigQuery where data analysts can create, train, evaluate, and predict with machine learning models with minimal coding.
In this lab, you will explore millions of New York City yellow taxi cab trips available in a BigQuery public dataset. Then you will create a machine learning model inside of BigQuery to predict the fare of the cab ride given your model inputs. Lastly, you will evaluate the performance of your model and make predictions.
Objectives
In this lab, you will learn how to perform the following tasks:
Use BigQuery to find public datasets.
Query and explore the public taxi cab dataset.
Create a training and evaluation dataset to be used for batch prediction.
Create a forecasting (linear regression) model in BQML.
Evaluate the performance of your machine learning model.
What you'll need
A Google Cloud Platform Project.
A Browser, such as Google Chrome or Mozilla Firefox.
Setup and requirements
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Google Skills using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
Open BigQuery Console
In the Google Cloud Console, select Navigation menu > BigQuery.
The Welcome to BigQuery in the Cloud Console message box opens. This message box provides a link to the quickstart guide and lists UI updates.
Click Done.
Task 1. Explore NYC taxi cab data
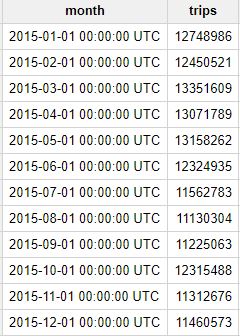
Question: How many trips did Yellow taxis take each month in 2015?
Add the following query in the SQLquery editor field:
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
Then click Run.
The result is output as follows.
Question: What was the average speed of Yellow taxi trips in 2015?
Replace the previous query with the following, and then click Run:
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
The result is output as follows.
During the day, the average speed is around 11-12 MPH; but at 5:00 AM the average speed almost doubles to 21 MPH. Intuitively this makes sense since there is likely less traffic on the road at 5:00 AM.
Task 2. Identify an objective
You will now create a machine learning model in BigQuery to predict the price of a cab ride in New York city given the historical dataset of trips and trip data. Predicting the fare before the ride could be very useful for trip planning for both the rider and the taxi agency.
Select features and create your training dataset
The New York City Yellow Cab dataset is a public dataset provided by the city and has been loaded into BigQuery for your exploration. Browse the complete list of fields and then preview the dataset to find useful features that will help a machine learning model understand the relationship between data about historical cab rides and the price of the fare.
Your team decides to test whether these below fields are good inputs to your fare forecasting model:
Tolls Amount
Fare Amount
Hour of Day
Pick up address
Drop off address
Number of passengers
Replace the query with the following:
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
Note a few things about the query:
The main part of the query is at the bottom: (SELECT * from taxitrips).
taxitrips does the bulk of the extraction for the NYC dataset, with the SELECT containing your training features and label.
The WHERE removes data that you don't want to train on.
The WHERE also includes a sampling clause to pick up only 1/1000th of the data.
We define a variable called TRAIN so that you can quickly build an independent EVAL set.
Then click Run.
The sample results are as indicated below.
Question: What is the label (correct answer)?
In this case, total_fare is the label (that we will be predicting). You created this field out of tolls_amount and fare_amount, so you could ignore customer tips as part of the model, as they are discretionary.
Task 3. Create a BigQuery dataset to store models
Next, create a new BigQuery dataset which will also store your ML models.
In the Explorer pane, click the View actions icon next to your project ID. Click Create datatset.
In the Create dataset dialog:
For Dataset ID, type taxi.
Leave the other values at their defaults.
Click Create dataset.
Task 4. Select a BQML model type and specify options
Now that you have your initial features selected, you are now ready to create your first ML model in BigQuery.
There are the two model types to choose from.
Model
Model Type
Label Data type
Example
Forecasting
linear_reg
Numeric value (typically an integer or floating point)
Forecast sales figures for next year given historical sales data.
Classification
logistic_reg
0 or 1 for binary classification
Classify an email as spam or not spam given the context.
Multiclass Classification
logistic_reg
These models can be used to predict multiple possible values such as whether an input is "low-value", "medium-value", or "high-value". Labels can have up to 50 unique values.
Classify an email as spam, normal priority, or high importance.
Note: There are many additional model types used in machine learning (like neural networks and decision trees) and available using libraries like TensorFlow. At this time, BQML supports the two listed above.
Question: Which model type should you choose? Since you are predicting a numeric value (cab fare) you want to use linear regression.
Enter the following query to create a model and specify model options, replacing -- paste the previous training dataset query here with the training dataset query you created earlier (omitting the #standardSQL line):
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
-- paste the previous training dataset query here
Next, click Run to train your model.
Wait for the model to train (about 5 - 10 minutes).
After your model is trained, you will see the result This statement created a new model named <Project-ID>:taxi.taxifare_model which indicates that your model has been successfully trained.
Look inside your taxi dataset and confirm taxifare_model now appears.
Next, you will evaluate the performance of the model against new unseen evaluation data.
Task 5. Evaluate classification model performance
Select your performance criteria
For linear regression models, you want to use a loss metric like Root Mean Squared Error. You want to keep training and improving the model until it has the lowest RMSE.
In BQML, mean_squared_error is simply a queryable field when evaluating your trained ML model. Simply add a SQRT() to get RMSE.
Now that training is complete, you can evaluate how well the model performs with this query using ML.EVALUATE:
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
You are now evaluating the model against a different set of taxi cab trips with your params.EVAL filter.
After the model runs, review your model results (your model RMSE value will vary slightly).
Row
rmse
1
9.477056435999074
After evaluating your model you get a RMSE of $9.47.
Knowing whether or not this loss metric is acceptable to productionalize your model is entirely dependent on your benchmark criteria, which is set before model training begins. Benchmarking is establishing a minimum level of model performance and accuracy that is acceptable.
Task 6. Compare training and evaluation loss
You want to make sure that you aren't overfitting your model to your data. Overfitting your model will make it perform worse on new, unseen data.
You can compare the training loss to the evaluation loss with ML.TRAINING_INFO:
SELECT * FROM ML.TRAINING_INFO(model `taxi.taxifare_model`);
This will select all the information from each iteration of the model training. It will include the training iteration number, the training loss, and the evaluation loss.
To compare training and evaluation loss, let's explore the difference in the loss curves visually.
Click on Open in > Looker Studio in the BigQuery Cloud Console. This will open Data Studio with the data from your query connected as an input source.
When prompted, click the Get Started button.
Select Authorize, when asked if Google Data Studio can access your data.
Click on Get Started and acknowledge the Terms of Service. Click Accept.
Select No, thanks for all in preferences and click Done.
Refresh the tab to load the data.
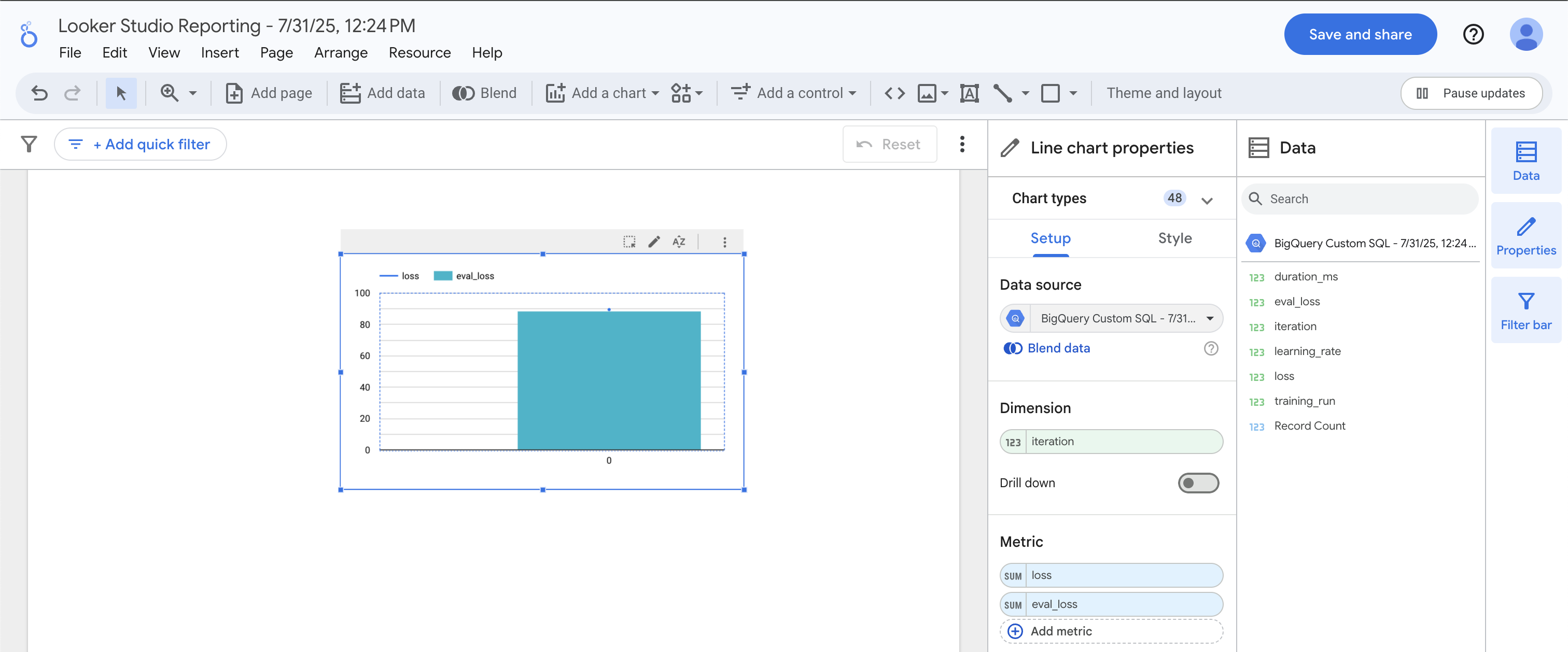
Once in Looker Studio, click on the Add Chart > Combo Chart icon.
Under Dimension, drag over iteration. Under Metric, drag over both loss and eval_loss. You should get a chart that features a line chart superimposed over a bar chart.
The training loss matches the evaluation loss nearly identically, which indicates that we are not overfitting the model.
Excellent! Let's move on to prediction.
Task 7. Predict a taxi fare amount
Next, you will write a query to use your new model to make predictions:
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
Now you will see the model's predictions for taxi fares alongside the actual fares and other features for those rides.
Additional information
Tip: Add warm_start = true to your model options if you are retraining new data on an existing model for faster training times. Note that you cannot change the feature columns (this would necessitate a new model).
Other datasets to explore
You can use the Chicago taxi trips dataset to bring in the bigquery-public-data project if you want to explore modeling on other datasets like forecasting fares for Chicago taxi trips.
Congratulations!
In this lab, you have successfully built an ML model in BigQuery to forecast taxi cab fare for New York City cabs.
End your lab
When you have completed your lab, click End Lab. Google Skills removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
1 star = Very dissatisfied
2 stars = Dissatisfied
3 stars = Neutral
4 stars = Satisfied
5 stars = Very satisfied
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2026 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.
Moduły tworzą projekt Google Cloud i zasoby na określony czas.
Moduły mają ograniczenie czasowe i nie mają funkcji wstrzymywania. Jeśli zakończysz moduł, musisz go zacząć od początku.
Aby rozpocząć, w lewym górnym rogu ekranu kliknij Rozpocznij moduł.
Użyj przeglądania prywatnego
Skopiuj podaną nazwę użytkownika i hasło do modułu.
Kliknij Otwórz konsolę w trybie prywatnym.
Zaloguj się w konsoli
Zaloguj się z użyciem danych logowania do modułu. Użycie innych danych logowania może spowodować błędy lub naliczanie opłat.
Zaakceptuj warunki i pomiń stronę zasobów przywracania.
Nie klikaj Zakończ moduł, chyba że właśnie został przez Ciebie zakończony lub chcesz go uruchomić ponownie, ponieważ spowoduje to usunięcie wyników i projektu.
Ta treść jest obecnie niedostępna
Kiedy dostępność się zmieni, wyślemy Ci e-maila z powiadomieniem
Świetnie
Kiedy dostępność się zmieni, skontaktujemy się z Tobą e-mailem
Jeden moduł, a potem drugi
Potwierdź, aby zakończyć wszystkie istniejące moduły i rozpocząć ten
Aby uruchomić moduł, użyj przeglądania prywatnego
Najlepszym sposobem na uruchomienie tego laboratorium jest użycie okna incognito lub przeglądania prywatnego. Dzięki temu unikniesz konfliktu między swoim kontem osobistym a kontem do nauki, co mogłoby spowodować naliczanie dodatkowych opłat na koncie osobistym.
In this lab you will explore millions of New York City yellow taxi cab trips available in a BigQuery Public Dataset, create a ML model inside of BigQuery to predict the fare, and evaluate the performance of your model to make predictions.
Czas trwania:
Konfiguracja: 0 min
·
Dostęp na 60 min
·
Ukończono w 60 min