Este conteúdo ainda não foi otimizado para dispositivos móveis.
Para aproveitar a melhor experiência, acesse nosso site em um computador desktop usando o link enviado a você por e-mail.
Informações gerais
O BigQuery é um banco de dados de análise NoOps, totalmente gerenciado e de baixo custo desenvolvido pelo Google. Com ele, você pode consultar muitos terabytes de dados sem ter que gerenciar uma infraestrutura ou precisar de um administrador de banco de dados. O BigQuery usa SQL e está disponível no modelo de pagamento por uso. Assim, você pode se concentrar na análise dos dados para encontrar informações relevantes.
A mesclagem de tabelas de dados gera insights significativos sobre o conjunto de dados. No entanto, alguns problemas comuns podem corromper os resultados ao mesclar dados. Este laboratório explica como evitá-los.
Tipos de mesclagem:
Cross join (Correlação): combina cada uma das linhas do primeiro conjunto de dados com uma linha do segundo, e todas as combinações são representadas nos resultados.
Inner join (Mesclagem interna): exige que as chaves-valor estejam em ambas as tabelas para que os registros sejam incluídos nos resultados. Esses registros só aparecerão na mesclagem se houver correspondências das chaves-valor nas duas tabelas.
Left join (Mesclagem à esquerda): todas as linhas da tabela à esquerda aparecem nos resultados, mesmo sem correspondências à direita.
Right join (Mesclagem à direita): é o contrário de uma mesclagem à esquerda. Todas as linhas da tabela à direita são incluídas nos resultados, mesmo que não haja correspondências à esquerda.
Você usará um conjunto de dados de comércio eletrônico com milhões de registros do Google Analytics referentes à Google Merchandise Store e carregados no BigQuery. Com uma cópia do conjunto de dados, você analisará os campos e linhas disponíveis para extrair insights.
Se você quiser informações sobre sintaxe para acompanhar e atualizar as consultas, consulte Sintaxe de consultas SQL padrão.
Atividades deste laboratório
Neste laboratório, você poderá:
usar o BigQuery para explorar um conjunto de dados;
Remover linhas duplicadas em um conjunto de dados
Criar mesclagens de tabelas de dados
entender cada tipo de mesclagem.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Abra o BigQuery no Console do Cloud
No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você vai ver a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da interface.
Clique em Concluído.
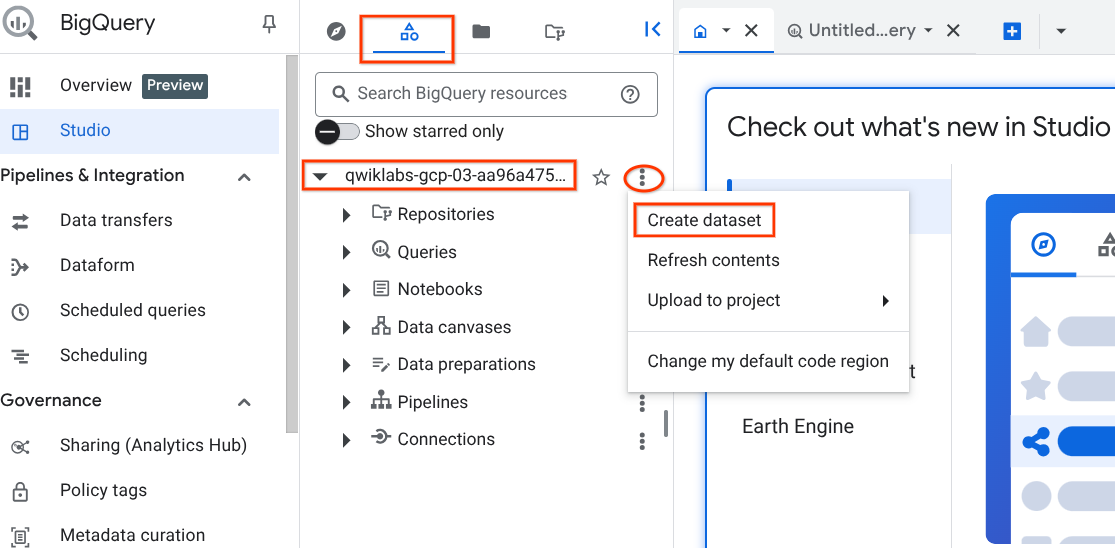
Tarefa 1. Crie um novo conjunto de dados para armazenar as tabelas
No projeto do BigQuery, crie um novo conjunto de dados intitulado ecommerce.
No painel esquerdo da seção Explorer, clique no ícone View actions próximo ao ID do projeto e selecione Create dataset.
Defina o ID do conjunto de dados como ecommerce. Deixe as demais opções nos valores padrão e clique em Create dataset.
No painel esquerdo, um conjunto de dados de ecommerce relacionado no projeto será exibido.
Tarefa 2. Fixe o projeto do laboratório no BigQuery
Cenário: a equipe cria um novo conjunto de dados com os níveis de estoque de cada um dos produtos à venda no seu site de e-commerce. Conheça melhor os produtos do site e os campos que podem ser mesclados com outros conjuntos de dados.
O projeto com o novo conjunto de dados é chamado data-to-insights.
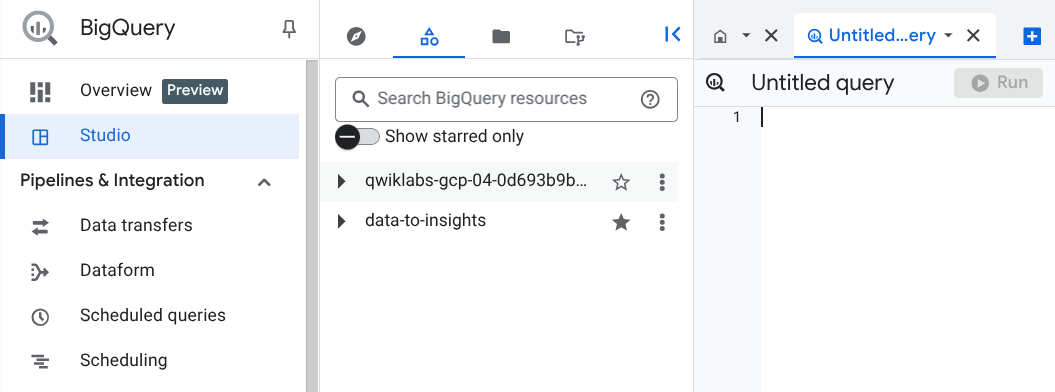
Os conjuntos de dados públicos do BigQuery não são exibidos por padrão na interface da Web do BigQuery. Como o data-to-insights é um projeto de conjunto de dados público, é preciso fixá-lo na árvore de recursos:
No painel "Explorer", clique em + ADICIONAR.
Selecione Marcar um projeto com estrela por nome.
Em Nome do projeto, insira data-to-insights.
Clique em Marcar com estrela.
No painel Explorer, o projeto data-to-insights vai estar marcado com estrela.
Tarefa 3: Examine os campos
Conheça os produtos do site e os campos que você pode usar para criar consultas de análise do conjunto de dados.
No painel esquerdo, acesse a seção Explorer e navegue até data-to-insights > ecommerce > all_sessions_raw.
À direita, clique na guia Esquema para conferir os campos e as informações sobre eles.
Tarefa 4: Identifique um campo chave no conjunto de dados de ecommerce
Examine os produtos e campos mais detalhadamente. Conheça melhor os produtos do site e os campos que podem ser mesclados com outros conjuntos de dados.
Analise os registros
Nesta seção, você verá quantos nomes e SKUs de produtos estão no site e se algum desses campos é exclusivo.
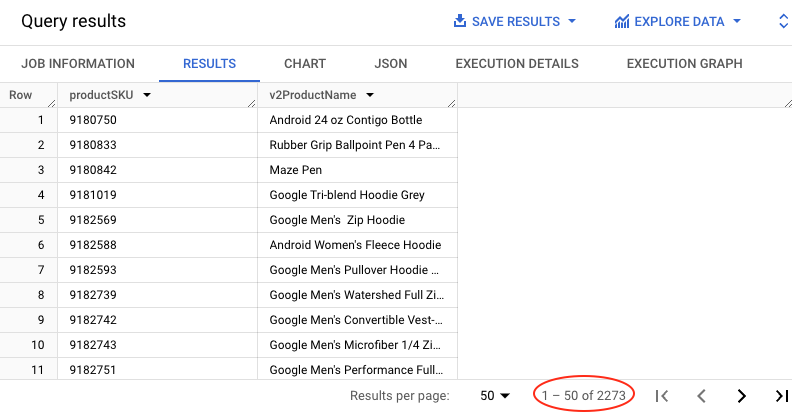
Saiba quantos nomes e SKUs de produtos estão no site. Copie e cole a consulta abaixo no EDITOR de consultas:
#standardSQL
# how many products are on the website?
SELECT DISTINCT
productSKU,
v2ProductName
FROM `data-to-insights.ecommerce.all_sessions_raw`
Clique em EXECUTAR.
Nos resultados de paginação na interface da Web, busque o número total de registros retornados, que nesse caso é de 2.273 produtos e SKUs.
Será que esses resultados significam que há 2.273 SKUs exclusivas de produtos?
Copie e cole a consulta abaixo para conferir o número de SKUs distintas usando DISTINCT:
#standardSQL
# find the count of unique SKUs
SELECT
DISTINCT
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
Clique em EXECUTAR.
O número de SKUs distintas é 1.909.
Há 1.909 SKUs distintas, menos que o total de 2.273 produtos no site. Os primeiros resultados provavelmente contêm produtos com SKUs duplicadas.
Examine melhor os registros. Determine quais produtos têm mais de uma SKU e quais SKUs têm mais de um produto.
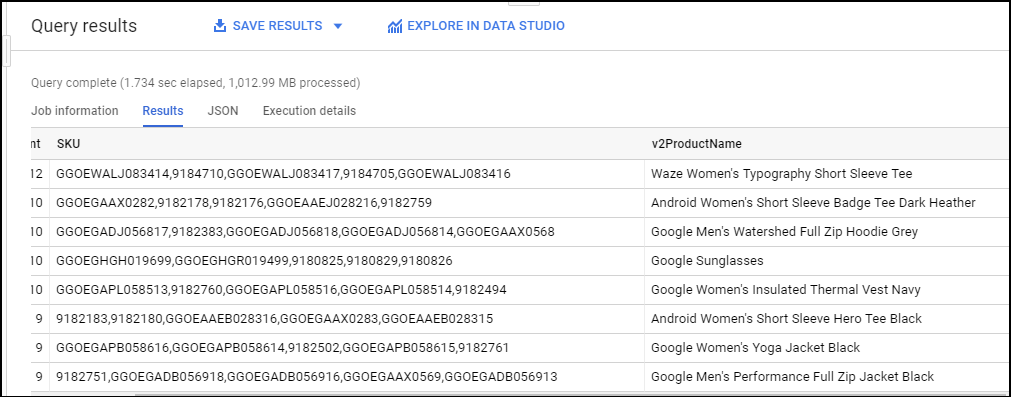
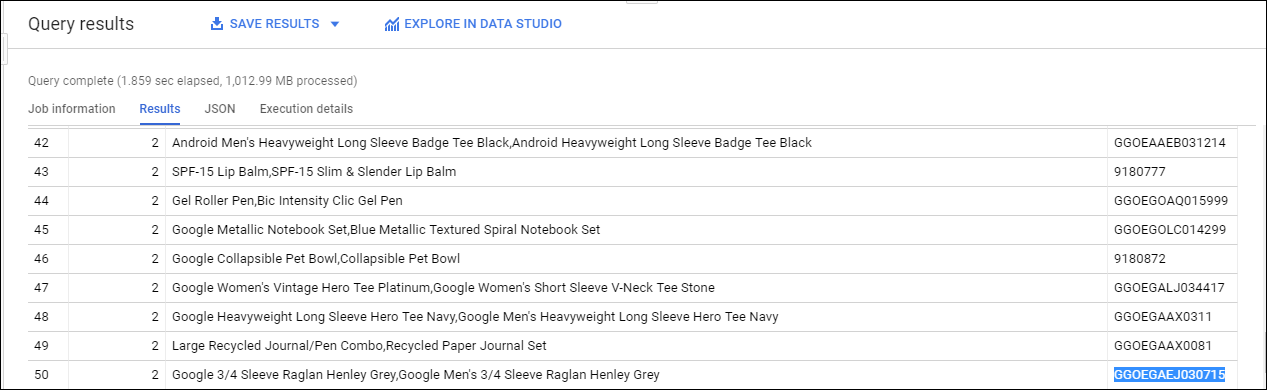
Copie e cole a consulta abaixo para determinar se alguns nomes de produtos têm mais de uma SKU. Observe que a função STRING_AGG() é usada para agregar todas as SKUs associadas a um nome de produto.
#standardSQL
# how can we find the products with more than 1 sku?
SELECT
DISTINCT
COUNT(DISTINCT productSKU) AS SKU_count,
STRING_AGG(DISTINCT productSKU LIMIT 5) AS SKU,
v2ProductName
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE productSKU IS NOT NULL
GROUP BY v2ProductName
HAVING SKU_count > 1
ORDER BY SKU_count DESC
# product name is not unique (expected for variants)
Clique em EXECUTAR.
Resultados:
Alguns nomes de produtos têm mais de uma SKU? Confira os resultados da consulta para confirmar.
Resposta: sim.
Também é possível que um nome de produto seja associado a mais de uma SKU. Isso pode acontecer devido à variação. Por exemplo, um nome de produto, como "camiseta", pode ter diversas variantes, como cor, tamanho etc. É normal que um produto tenha muitas SKUs.
Copie e cole a consulta abaixo para verificar:
#standardSQL
SELECT
DISTINCT
COUNT(DISTINCT v2ProductName) AS product_count,
STRING_AGG(DISTINCT v2ProductName LIMIT 5) AS product_name,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE v2ProductName IS NOT NULL
GROUP BY productSKU
HAVING product_count > 1
ORDER BY product_count DESC
# SKU is not unique (indicates data quality issues)
Clique em EXECUTAR.
Pergunta: nos resultados da consulta, há valores de SKU únicos com mais de um nome de produto associado? O que você observou nos nomes desses produtos?
Resposta: sim, parece que há várias SKUs com mais de um nome de produto. Muitos dos nomes são bem parecidos, com alguns erros ortográficos ou palavras de mesmo significado (por exemplo, "bolsa de equipamento impermeável" ou "bolsa de equipamento à prova d'água").
Na próxima seção, você vai entender por que isso pode ser um problema.
Tarefa 5. Problema: chave não exclusiva
As SKUs foram feitas para identificar cada produto de maneira exclusiva e serão a base da condição de mesclagem com outras tabelas. A presença de uma chave não exclusiva pode causar sérios problemas nos dados.
Crie uma consulta para identificar todos os nomes de produtos referentes à SKU 'GGOEGPJC019099'.
Possível solução:
#standardSQL
# multiple records for this SKU
SELECT DISTINCT
v2ProductName,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE productSKU = 'GGOEGPJC019099'
Clique em EXECUTAR.
v2ProductName
productSKU
7" Dog Frisbee
GGOEGPJC019099
7" Dog Frisbee
GGOEGPJC019099
Google 7-inch Dog Flying Disc Blue
GGOEGPJC019099
Nos resultados da consulta, parece que há três nomes diferentes para o mesmo produto. No exemplo, um dos nomes tem um caractere especial, e outro é um pouco diferente dos demais:
Como mesclar dados do site à lista de inventário de produtos
Observe o impacto de mesclar um conjunto de dados com vários produtos da mesma SKU. Primeiro, analise o conjunto de dados do inventário de produtos (a tabela products) para confirmar se a SKU é exclusiva.
Copie e cole a consulta abaixo:
#standardSQL
# join in another table
# products (has inventory)
SELECT * FROM `data-to-insights.ecommerce.products`
WHERE SKU = 'GGOEGPJC019099'
Clique em EXECUTAR.
Problema de mesclagem: relação não intencional de muitas SKUs para uma
A seguir, junte o conjunto de dados do inventário aos nomes de produtos e SKUs do site para ter o nível de estoque associado a cada produto à venda no site.
Copie e cole a consulta abaixo:
#standardSQL
SELECT DISTINCT
website.v2ProductName,
website.productSKU,
inventory.stockLevel
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE productSKU = 'GGOEGPJC019099'
Clique em EXECUTAR.
O que acontece quando você mescla a tabela do site e a tabela de inventário de produtos na SKU? Você tem agora os níveis de estoque para os produtos?
Resposta: sim, mas o nível de estoque (stockLevel) aparece três vezes (uma vez para cada registro).
Em seguida, execute uma consulta que mostre o nível de estoque total de cada item do inventário.
Copie e cole a consulta abaixo:
#standardSQL
SELECT
productSKU,
SUM(stockLevel) AS total_inventory
FROM (
SELECT DISTINCT
website.v2ProductName,
website.productSKU,
inventory.stockLevel
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE productSKU = 'GGOEGPJC019099'
)
GROUP BY productSKU
Clique em EXECUTAR.
Tarefa 6. Solução do problema de mesclagem: use SKUs diferentes antes de mesclar
Quais são as opções para resolver o dilema da contagem tripla? Primeiro, é preciso selecionar apenas SKUs distintas do site antes de mesclar a outros conjuntos de dados.
Crie uma consulta para retornar a contagem de SKUs de produtos (productSKU) distintas de data-to-insights.ecommerce.all_sessions_raw.
Possível solução:
#standardSQL
SELECT
COUNT(DISTINCT website.productSKU) AS distinct_sku_count
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
Resposta: 1.909 SKUs distintas do conjunto de dados do site
Problema de mesclagem: perda de registros de dados após uma mesclagem
Agora está tudo pronto para a mesclagem do conjunto de dados do inventário de produtos novamente.
Copie e cole a consulta abaixo:
#standardSQL
SELECT DISTINCT
website.productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
Clique em EXECUTAR.
Quantos registros foram retornados? Todas as 1.909 SKUs distintas?
Resposta: não, somente 1.090 registros.
Parece que 819 SKUs foram perdidas após a mesclagem dos conjuntos de dados. Investigue adicionando mais detalhes nos campos.
Copie e cole a consulta abaixo:
#standardSQL
# pull ID fields from both tables
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
# IDs are present in both tables, how can we dig deeper?
Clique em EXECUTAR.
Parece que as SKUs estão em ambos os conjuntos de dados após a mesclagem.
Solução do problema da mesclagem: selecionar o tipo de mesclagem correto e filtrar por NULL
O tipo padrão de JOIN é um INNER JOIN que retorna registros somente se houver uma correspondência nas tabelas à esquerda e à direita que foram mescladas.
Reescreva a consulta anterior para usar um outro tipo de mesclagem que inclua todos os registros da tabela do site, independentemente de haver correspondência no registro de SKU do inventário de produtos. As opções de tipo de mesclagem são: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN e CROSS JOIN.
Possível solução:
#standardSQL
# the secret is in the JOIN type
# pull ID fields from both tables
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
LEFT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
Clique em EXECUTAR.
Você usou LEFT JOIN para retornar todas as 1.909 SKUs originais do site nos resultados.
Quantas SKUs faltam no conjunto de inventário de produtos?
Escreva uma consulta para filtrar os valores NULL da tabela de inventário.
Possível solução:
#standardSQL
# find product SKUs in website table but not in product inventory table
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
LEFT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE inventory.SKU IS NULL
Clique em EXECUTAR.
Copie e cole a consulta abaixo para confirmar usando uma das SKUs específicas do conjunto de dados do site:
#standardSQL
# you can even pick one and confirm
SELECT * FROM `data-to-insights.ecommerce.products`
WHERE SKU = 'GGOEGATJ060517'
# query returns zero results
Clique em EXECUTAR.
Por que faltam SKUs no conjunto de dados do inventário de produtos?
Resposta: não existe uma resposta fácil. Provavelmente é uma questão relacionada aos negócios:
Algumas SKUs podem ser de produtos digitais que não são armazenados no inventário.
Os produtos antigos que foram vendidos em pedidos anteriores do site não existem mais no inventário atual.
Dados legítimos do inventário se perderam e devem ser rastreados.
Há algum produto no conjunto de dados do inventário de produtos que esteja faltando no site?
Crie uma consulta usando outro tipo de mesclagem para investigar.
Possível solução:
#standardSQL
# reverse the join
# find records in website but not in inventory
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
RIGHT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE website.productSKU IS NULL
Clique em EXECUTAR.
Resposta: sim. Faltam duas SKUs de produtos no conjunto de dados do site.
Em seguida, adicione mais campos do conjunto de dados do inventário de produtos para saber mais detalhes.
Copie e cole a consulta abaixo:
#standardSQL
# what are these products?
# add more fields in the SELECT STATEMENT
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.*
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
RIGHT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE website.productSKU IS NULL
Clique em EXECUTAR.
Por que os produtos abaixo estão faltando no conjunto de dados do site de e-commerce?
Possíveis respostas:
Um deles é um produto novo (não há pedidos ou "sentimentScore") e outro é um produto disponível "somente na loja" (in store only).
Outro é um novo produto com "0" pedido.
Por que os novos produtos não aparecem no conjunto de dados do site?
O conjunto de dados do site contém transações de clientes de pedidos anteriores. Os produtos novos que nunca foram vendidos não serão exibidos na análise da Web até que sejam visualizados ou comprados.
Observação: em geral, não há strings com RIGHT JOIN nas consultas sobre produção. É mais simples usar LEFT JOIN e alterar a ordem das tabelas.
E se você quisesse uma consulta que listasse todos os produtos que não constam no site ou no inventário?
Escreva uma consulta usando um outro tipo de mesclagem.
Possível solução:
#standardSQL
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
FULL JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE website.productSKU IS NULL OR inventory.SKU IS NULL
Clique em EXECUTAR.
Você tem 819 + 2 = 821 SKUs de produtos.
LEFT JOIN + RIGHT JOIN = FULL JOIN de produtos, que retorna todos os registros de ambas as tabelas, sem depender das chaves de mesclagem correspondentes. Depois, basta filtrar as instâncias sem correspondência em um dos lados.
Problema de mesclagem: correlação não intencional
Não saber a relação entre as chaves das tabelas de dados (1:1, 1:N, N:N) pode gerar resultados inesperados, além de prejudicar significativamente o desempenho da consulta.
O último tipo de mesclagem é a CROSS JOIN.
Crie uma nova tabela com a porcentagem de desconto que você quer aplicar em todo o site nos produtos da categoria "Promoção".
Substitua a tabela chamada qwiklabs-***.
Copie e cole a consulta abaixo:
#standardSQL
CREATE OR REPLACE TABLE ecommerce.site_wide_promotion AS
SELECT .05 AS discount;
Clique em EXECUTAR.
No painel esquerdo, o site_wide_promotion está listado na seção "Recursos", em qwiklabs-gcp-xxx > ecommerce.
Copie e cole a consulta abaixo para conferir quantos produtos estão em promoção:
SELECT DISTINCT
productSKU,
v2ProductCategory,
discount
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
CROSS JOIN ecommerce.site_wide_promotion
WHERE v2ProductCategory LIKE '%Clearance%'
Clique em EXECUTAR.
Observação: na sintaxe não há condição de mesclagem (por exemplo, ON ou USING) para usar CROSS JOIN. O campo simplesmente é multiplicado pelo primeiro conjunto de dados ou por 0,05 de desconto em todos os itens.
Vamos conferir o impacto da adição não intencional de mais de um registro na tabela de descontos.
Copie e cole a consulta abaixo para inserir mais dois registros na tabela de promoção:
#standardSQL
INSERT INTO ecommerce.site_wide_promotion (discount)
VALUES (.04),
(.03);
Clique em EXECUTAR.
Em seguida, visualizaremos os valores de dados na tabela de promoção.
Copie e cole a consulta abaixo:
#standardSQL
SELECT discount FROM ecommerce.site_wide_promotion
Clique em EXECUTAR.
O que acontece se você aplica o desconto novamente em todos os 82 produtos em promoção?
Copie e cole a consulta abaixo:
#standardSQL
# now what happens:
SELECT DISTINCT
productSKU,
v2ProductCategory,
discount
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
CROSS JOIN ecommerce.site_wide_promotion
WHERE v2ProductCategory LIKE '%Clearance%'
Clique em EXECUTAR.
Quantos produtos foram retornados?
Resposta: em vez de 82, agora há 246 retornados, mais registros do que na tabela inicial.
Para investigar a causa subjacente, examine uma SKU de produto.
Copie e cole a consulta abaixo:
#standardSQL
SELECT DISTINCT
productSKU,
v2ProductCategory,
discount
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
CROSS JOIN ecommerce.site_wide_promotion
WHERE v2ProductCategory LIKE '%Clearance%'
AND productSKU = 'GGOEGOLC013299'
Clique em EXECUTAR.
Qual foi o impacto da CROSS JOIN?
Resposta:
como existem três códigos de desconto para correlacionar, o conjunto de dados original está sendo multiplicado por três.
Observação: esse comportamento não se limita a correlações. Com uma mesclagem normal é possível haver correlações não intencionais quando as relações de dados são de muitos para muitos. Isso pode resultar em milhões ou mesmo bilhões de registros retornados de forma não intencional.
A solução é conhecer as relações de dados antes da mesclagem e não presumir que as chaves são exclusivas.
Tarefa 7. Elimine as linhas duplicadas
No início do laboratório, você criou uma consulta que mostrava vários nomes de produtos para uma única SKU. A eliminação de duplicação de registros como essa é uma habilidade comum de analistas de dados. Encontre uma maneira de selecionar somente um produto por SKU.
Primeiro, comece com a consulta para mostrar todos os nomes de produtos por SKU.
Copie e cole a consulta abaixo:
#standardSQL
# recall the earlier query that showed multiple product_names for each SKU
SELECT
DISTINCT
COUNT(DISTINCT v2ProductName) AS product_count,
STRING_AGG(DISTINCT v2ProductName LIMIT 5) AS product_name,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE v2ProductName IS NOT NULL
GROUP BY productSKU
HAVING product_count > 1
ORDER BY product_count DESC
Clique em EXECUTAR.
Como a maioria dos nomes de produtos é semelhante (e é preciso mapear uma SKU exclusiva para um único produto), crie uma consulta que escolha somente um dos nomes do produto (product_names). Use como inspiração esta postagem do StackOverflow do Felipe Hoffa.
Copie e cole a consulta abaixo:
#standardSQL
# take the one name associated with a SKU
WITH product_query AS (
SELECT
DISTINCT
v2ProductName,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE v2ProductName IS NOT NULL
)
SELECT k.* FROM (
# aggregate the products into an array and
# only take 1 result
SELECT ARRAY_AGG(x LIMIT 1)[OFFSET(0)] k
FROM product_query x
GROUP BY productSKU # this is the field you want deduplicated
);
Clique em EXECUTAR.
Você eliminou a duplicação dos nomes dos produtos de cada SKU. Faça testes com a consulta acima nos seus próprios conjuntos de dados para eliminar a duplicação dos campos antes de mesclá-los a outros conjuntos de dados.
Tarefa 8. Teste seu conhecimento
Parabéns!
Você concluiu este laboratório e lidou com alguns problemas sérios da mesclagem de SQL ao identificar registros duplicados e reconhecer quando usar cada tipo de JOIN. Bom trabalho!
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
A melhor maneira de executar este laboratório é usando uma janela de navegação anônima
ou privada. Isso evita conflitos entre sua conta pessoal
e a conta de estudante, o que poderia causar cobranças extras
na sua conta pessoal.
Neste laboratório, você aprenderá a fazer a engenharia reversa das relações entre as tabelas de dados e os problemas que devem ser evitados ao mesclá-las.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 60 minutos