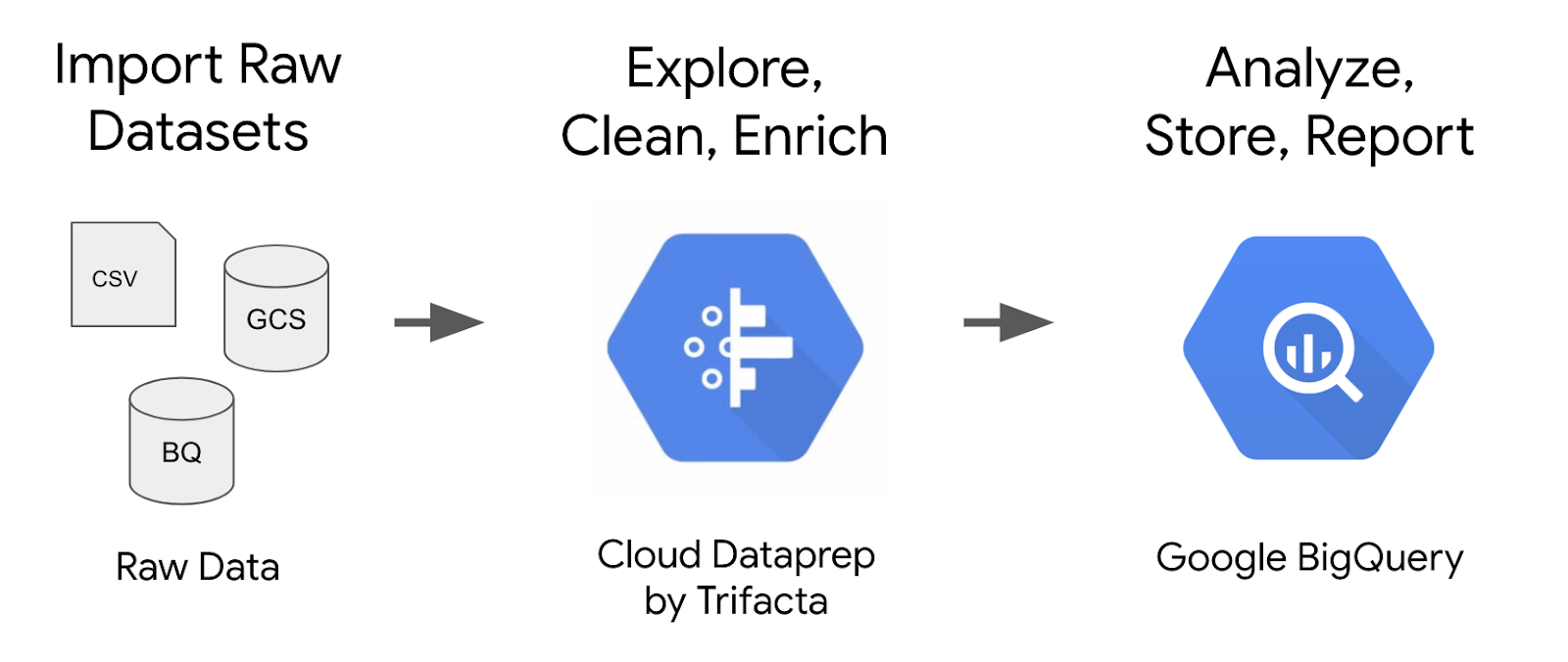
O Cloud Dataprep da Trifacta é um serviço de dados inteligente que permite a exploração visual, a limpeza e a preparação de dados estruturados e não estruturados para análise. Neste laboratório vamos abordar o uso da interface do Cloud Dataprep para criar um pipeline de transformação de e-commerce, que vai ser executado em um intervalo agendado e enviar os resultados de volta ao BigQuery.
O conjunto de dados que vamos usar é um conjunto de dados de e-commerce que dispõe de milhões de registros do Google Analytics para a Google Merchandise Store carregados no BigQuery. Criamos uma cópia desse conjunto de dados para este laboratório, e vamos analisar os campos e linhas disponíveis para extrair insights.
Objetivos
Neste laboratório, você vai aprender a:
Conectar conjuntos de dados do BigQuery ao Cloud Dataprep
Analisar a qualidade do conjunto de dados com o Cloud Dataprep
Criar um pipeline de transformação de dados com o Cloud Dataprep
Programar a saída dos jobs de transformação para o BigQuery
Pré-requisitos
Um projeto do Google Cloud Platform
O navegador Google Chrome. O Cloud Dataprep aceita apenas o navegador Chrome.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Abra o BigQuery no Console do Cloud
No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você vai ver a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da interface.
Clique em Concluído.
Embora o foco deste laboratório seja o Cloud Dataprep, vamos usar o BigQuery como endpoint para fazer a ingestão de conjuntos de dados para o pipeline e como destino da saída após a conclusão do pipeline.
Tarefa 1. Criar um conjunto de dados vazio do BigQuery
Nesta tarefa, você vai criar um conjunto de dados do BigQuery para receber a tabela de resposta do novo pipeline.
No painel esquerdo, clique em View actions (), ao lado do ID do projeto, e selecione Create dataset.
Na caixa de diálogo Create dataset, siga estas instruções:
Em Dataset ID, insira ecommerce.
Mantenha os outros valores padrão.
Clique em Create dataset.
Copie e cole esta consulta SQL na área de texto do Editor de consultas:
#standardSQL
CREATE OR REPLACE TABLE ecommerce.all_sessions_raw_dataprep
OPTIONS(
description="Raw data from analyst team to ingest into Cloud Dataprep"
) AS
SELECT * FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE date = '20170801'; # limitado a um dia de dados, 56 mil linhas para este laboratório
Clique em Run.
Essa consulta copia um subconjunto do conjunto de dados brutos públicos de e-commerce para seu próprio conjunto de dados do projeto, para que você possa explorar e limpar no Cloud Dataprep.
Confirme se a nova tabela de dados brutos existe em seu projeto.
Tarefa 2. Abrir o Cloud Dataprep
Nesta tarefa, você vai aceitar os Termos de Serviço do Google e da Trifacta e permitir que a Trifacta acesse os dados do seu projeto.
Execute o comando a seguir no Cloud Shell para criar uma conta de serviço, necessária para permitir o acesso ao Dataprep.
No console do GCP, verifique se seu projeto do laboratório está selecionado.
No Menu de navegação (), no agrupamento Analytics, clique em Dataprep.
Selecione os Termos de Serviço do Google e da Trifacta e depois clique em Aceitar.
Na caixa de diálogo Compartilhar informações da conta com a Trifacta, marque a caixa de seleção e clique em Concordar e continuar.
Para possibilitar que a Trifacta acesse os dados do seu projeto, clique em Permitir. Este processo de autorização pode demorar uns minutos.
Na janela Fazer login com o Google, selecione sua conta do Qwiklabs e clique em Permitir. Clique em Aceitar, caso seja necessário após marcar a caixa de seleção.
Para usar o local padrão para o bucket de armazenamento, clique em Continuar.
A página inicial do Cloud Dataprep é exibida. Se necessário, clique em Início.
Tarefa 3. Conectar os dados do BigQuery ao Cloud Dataprep
Nesta tarefa, você vai conectar o Cloud Dataprep à sua fonte de dados do BigQuery.
Na página do Cloud Dataprep, faça o seguinte:
Clique em Create a new flow.
Clique em Untitled Flow na parte superior da página.
Na caixa de diálogo "Rename", especifique os seguintes detalhes:
Em Flow name, digite Ecommerce Analytics Pipeline.
Em Flow Description, digite Revenue reporting table for Apparel
Clique em OK.
Clique no ícone (+) para adicionar um conjunto de dados.
Na caixa de diálogo "Add datasets to flow", clique em Import datasets no canto inferior esquerdo.
No painel esquerdo, clique em BigQuery.
Quando seu conjunto de dados de e-commerce for carregado, clique nele.
Para criar um conjunto de dados, clique em Create dataset ().
Clique em Import & Add to Flow.
A origem de dados vai ser atualizada automaticamente.
Tarefa 4. Analisar os campos de dados de e-commerce com uma interface.
Nesta tarefa, você vai carregar e analisar parte do conjunto de dados no Cloud Dataprep.
Clique em Edit Recipe no painel direito.
Clique em Don't show me any helpers na caixa de diálogo The Transformer, se necessário.
O Cloud Dataprep carrega uma amostra do seu conjunto de dados na visualização do Transformer. Esse processo pode levar alguns minutos.
Responda às perguntas:
O Cloud Dataprep vai carregar uma amostra do conjunto de dados de origem para acelerar a análise.
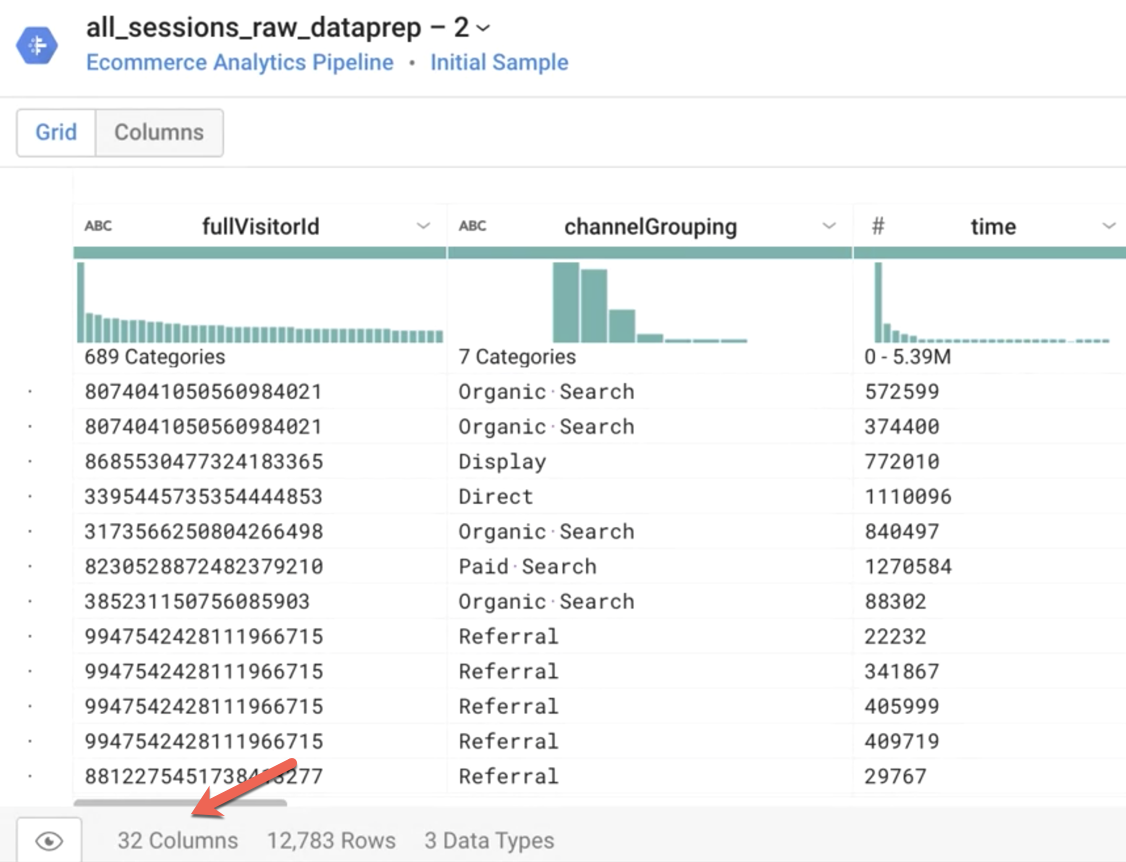
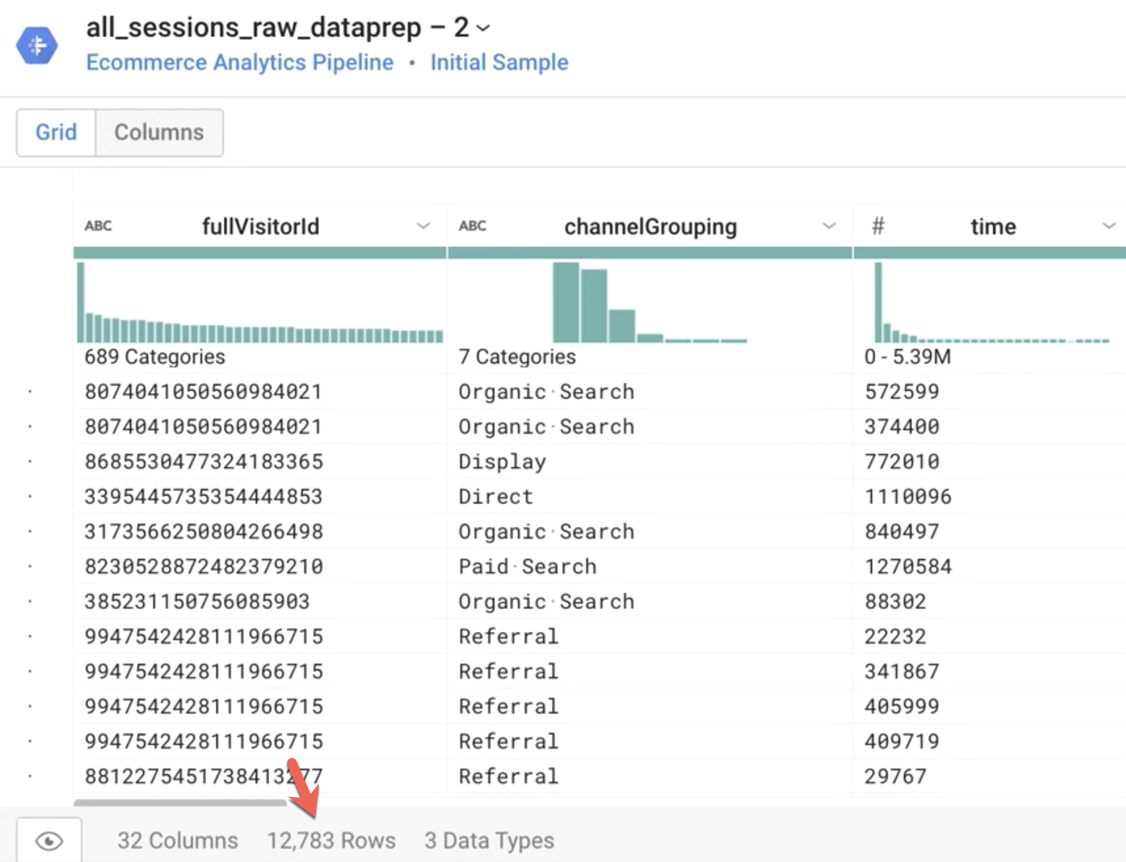
Observação: quando o pipeline for executado, ele vai operar em todo o conjunto de dados de origem. Quantas linhas a amostra tem?
Resposta: aproximadamente 12 mil linhas
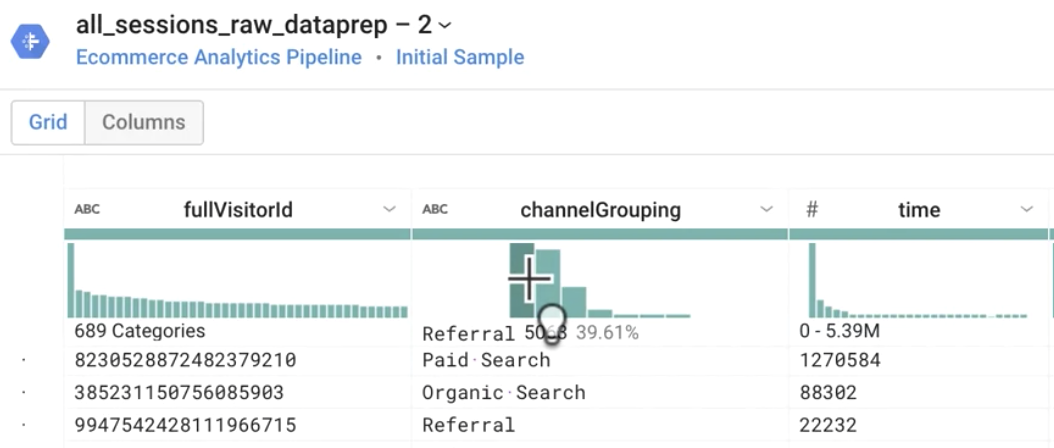
Qual é o valor mais comum da coluna channelGrouping?
Resposta: Referral
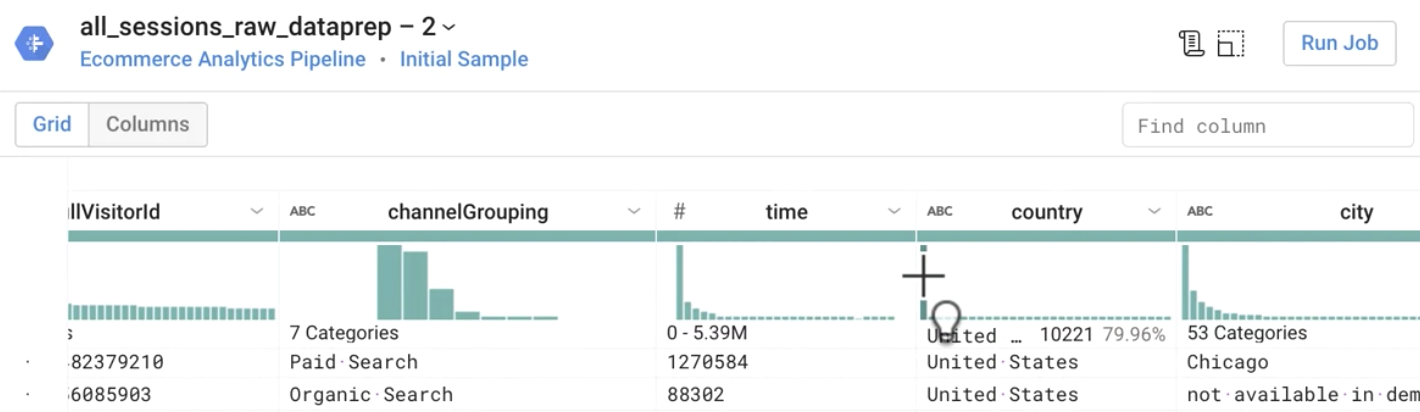
Quais são os três países de onde se origina a maioria das sessões?
Resposta: EUA, Índia, Reino Unido
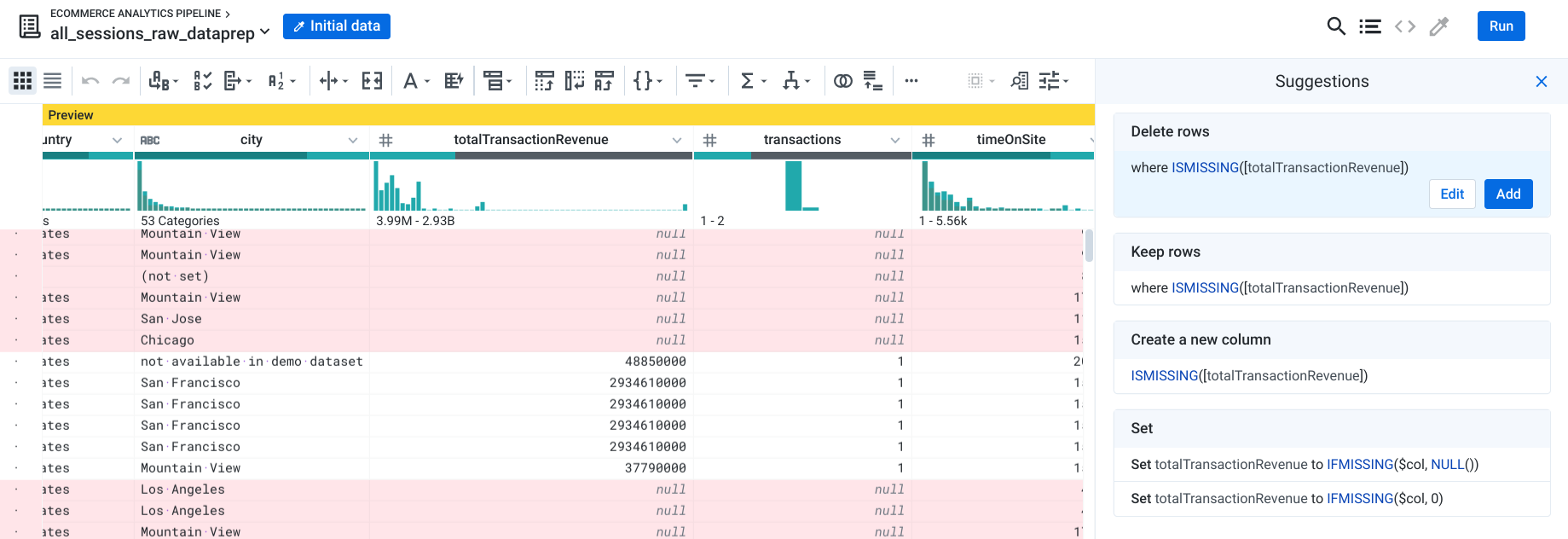
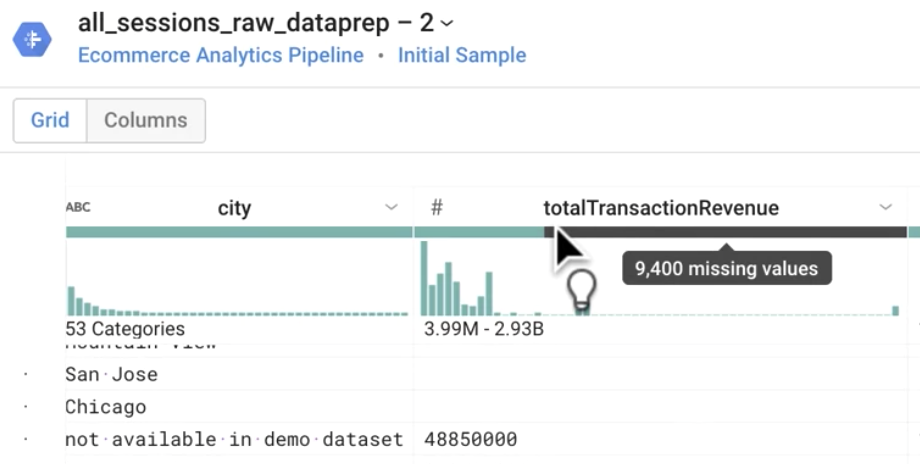
O que significa a barra cinza abaixo de totalTransactionRevenue?
Resposta: valores ausentes
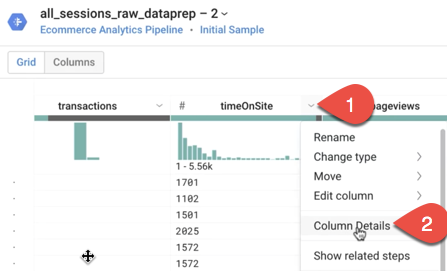
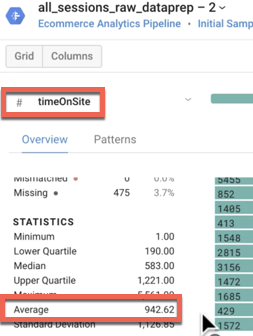
Quais são a média de timeOnSite em segundos, a média de pageviews e a média de sessionQualityDim para a amostra de dados? (Dica: use Column Details.)
Respostas:
Média de tempo no site: 942 segundos (ou 15,7 minutos)
Média de visualizações de páginas: 20,44 páginas
Média de dimensão de qualidade da sessão: 38,36
Observação: as respostas podem variar um pouco devido à amostra de dados usada pelo Cloud Dataprep.
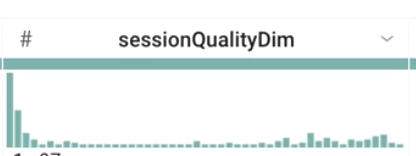
Com base no histograma de sessionQualityDim, é possível dizer que os valores dos dados estão distribuídos de maneira uniforme?
Resposta: não, a maioria tem valores muito baixos (sessões com qualidade ruim), o que é esperado.
Qual é o período da amostra do conjunto de dados?
Resposta: 01/08/2017 (dados de um dia).
Por que há uma barra vermelha sob a coluna productSKU?
Resposta: a barra vermelha indica valores incompatíveis. O Cloud Dataprep identificou automaticamente o tipo da coluna productSKU como um número inteiro. O Cloud Dataprep também detectou alguns valores não inteiros. Por isso, ele os sinalizou como incompatíveis. Na verdade, productSKU não é sempre um número inteiro (por exemplo, “GGOEGOCD078399” também seria um valor correto). Nesse caso, o Cloud Dataprep identificou incorretamente o tipo de coluna: ele deve ser uma string, e não um número inteiro. Você vai consertar isso na etapa seguinte.
Observação: se a coluna productSKU já tem um tipo String, a barra vermelha não aparece.
Para converter o tipo de coluna productSKU para um tipo de dados de string, abra o menu à direita da coluna productSKU, clicando em e depois em Change type > String.
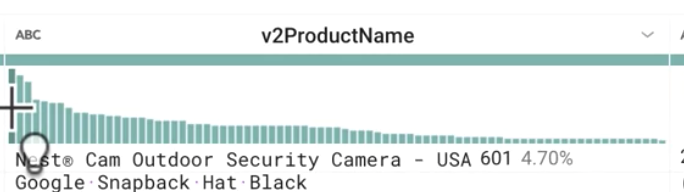
Com base em v2ProductName, quais são os produtos mais procurados?
Resposta: produtos Nest
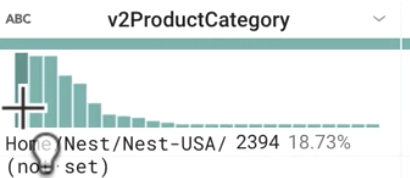
Com base em v2ProductCategory, quais são alguns dos produtos mais populares? Quantas categorias foram amostradas?
Resposta: Nest, (not set) e Apparel são os mais procurados dentre aproximadamente 25 categorias.
Verdadeiro ou Falso: o valor mais comum de productVariant é COLOR.
Resposta: falso. O mais comum é (not set), porque mais de 80% dos produtos não têm variantes.
Quais são as duas categorias de tipo?
Resposta: PAGE e EVENT.
Qual é a média de productQuantity?
Resposta: 3,45, mas sua resposta pode ser diferente.
O conjunto de dados tem quantas SKUs distintas?
Resposta: Mais de 600
Quais são alguns dos nomes de produtos mais populares por contagem de linhas? E as categorias mais populares?
Resposta:
Cam Outdoor Security Camera - USA
Cam Indoor Security Camera - USA
Learning Thermostat 3rd Gen-USA - Stainless Steel
Qual é o código de moeda dominante para as transações?
Resposta: USD (dólares americanos)
Existem valores válidos para itemQuantity ou itemRevenue?
Resposta: não, todos os valores são nulos.
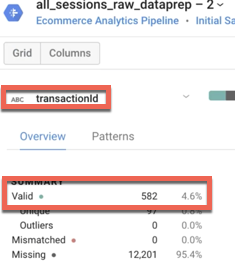
Qual a porcentagem de IDs de transações com valores válidos? O que isso representa para o conjunto de dados de e-commerce?
Resposta: aproximadamente 4,6% dos IDs de transações têm um valor válido, o que representa a taxa de conversão média do site (4,6% dos visitantes fazem transações).
Quantos eCommerceAction_type existem, e qual é a eCommerceAction_step mais popular?
Respostas:
Seis tipos têm dados na nossa amostra.
0 ou NULL é o mais popular.
Tarefa 5. Limpar os dados
Nesta tarefa, você vai fazer a limpeza dos dados excluindo colunas não usadas, eliminando duplicações, criando campos calculados e filtrando as linhas. É comum excluir colunas quando os campos são depreciados no esquema ou têm todos os valores NULL.
Exclua colunas não usadas
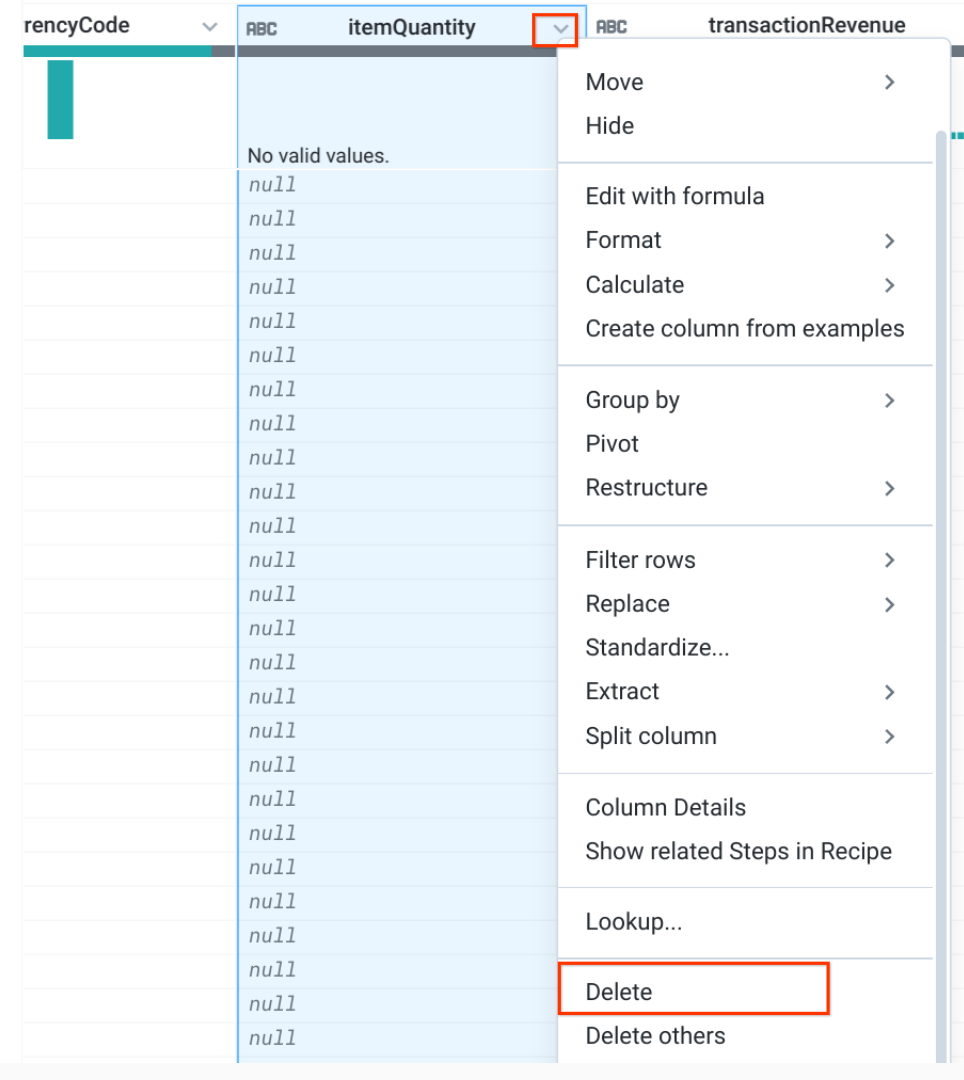
Selecione a coluna indesejada e depois clique em Delete. Faça isso para as colunas que têm todos os valores NULL:
itemRevenue
itemQuantity
Elimine a duplicação de linhas
Sua equipe informou que o conjunto de dados de origem pode ter valores de sessão duplicados. Vamos removê-los em uma nova etapa para eliminar duplicações.
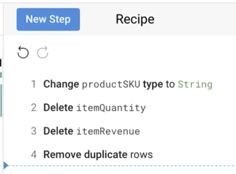
Clique em Recipe (), no canto superior direito, e selecione New Step.
Na caixa de pesquisa de transformação, digite deduplicate e selecione Remove duplicate rows.
Clique em Add.
Confira a receita criada até agora:
Filtrar as sessões sem receita
Sua equipe pediu para você criar uma tabela com todas as sessões de usuários que compraram pelo menos um item no site. Filtre as sessões de usuários com receita NULL.
Na coluna totalTransactionRevenue, clique na barra de valores ausentes.
No painel Suggestions, clique em Delete rows with missing values e depois clique em Add (como mostrado).
Essa etapa filtra o conjunto de dados para incluir somente transações com receita (quando totalTransactionRevenue é NULL).
Filtre as sessões para apenas Type = ‘PAGE’
O conjunto de dados contém visualizações de páginas do site e eventos acionados, como “categorias de produtos visualizados” ou “adicionados ao carrinho”. Para evitar a contagem dupla de visualizações de páginas da sessão, adicione um filtro para incluir apenas eventos relacionados à visualização de páginas.
Na coluna de type, clique na barra para PAGE.
No painel Suggestions, clique em "Keep rows" quando o tipo for PAGE, e depois clique emAdd.
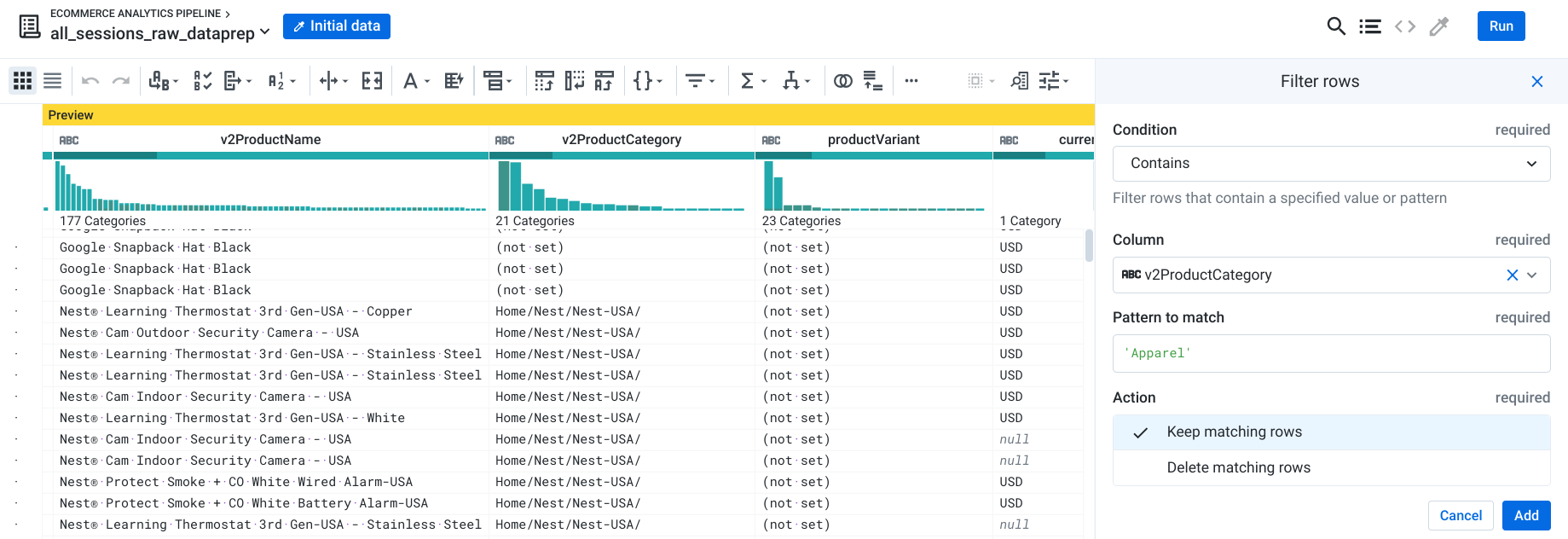
Filtre por produtos de vestuário
Sua equipe pediu para você que filtre ainda mais a saída, para que inclua apenas transações na categoria Vestuário, que inclui itens como camisetas e outros itens de roupa.
Próximo à coluna v2ProductCategory, clique no ícone de lista suspensa.
Selecione Filter rows > On column values.
Selecione Contains.
Na seção Pattern to match, digite "Apparel" (diferencia maiúsculas de minúsculas) e depois clique em Add.
Observação: os produtos do catálogo podem pertencer a mais de uma categoria ("Apparel" e "Home/Apparel/"), e é por isso que estamos fazendo a correspondência de todas as linhas que têm "Apparel" em qualquer lugar no nome da categoria.
Tarefa 6. Enriquecer os dados
Para conhecer o esquema usado neste laboratório, consulte [UA] Esquema BigQuery Export. Procure visitId neste artigo e leia a descrição para saber se ele é único para todas as sessões ou apenas para o usuário.
VisitId é o identificador da sessão. Ele faz parte do valor geralmente armazenado como o cookie _utmb. Esse valor só é único para o usuário. Para gerar um ID completamente exclusivo, use uma combinação de fullVisitorId e visitId.
visitId não é único entre todos os usuários.
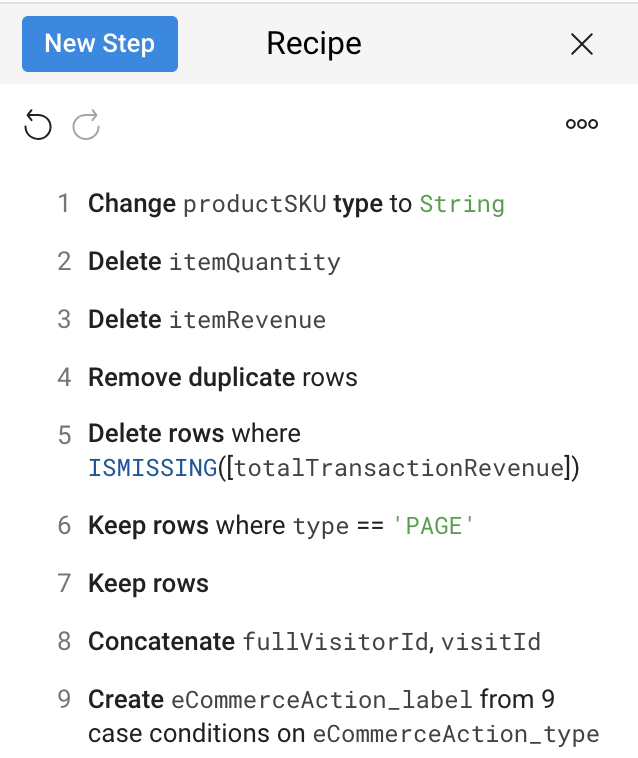
Nesta tarefa, você vai adicionar uma coluna concatenada nova para criar um campo de ID de sessão único. Em seguida, você vai enriquecer seus dados de rótulos de e-commerce com uma instrução "case".
Crie uma nova coluna para um ID de sessão único
Como você viu, o conjunto de dados não tem uma coluna para a sessão de visitante único. Crie um ID exclusivo para cada sessão, concatenando os campos fullVisitorId e visitId.
Clique em New Step.
Em Search transformation, digite concat e depois selecione Merge columns.
Em Columns, selecione fullVisitorId e visitId.
Em New column name, digite unique_session_id e deixe as demais entradas como valores padrão. Em seguida, clique em Add.
Criar uma instrução "case" para o tipo de ação de e-commerce
O campo eCommerceAction_type é um número inteiro relacionado a ações reais de e-commerce realizadas nessa sessão, como 3 = “Adicionar ao carrinho” ou 5 = “Finalizar compra”. Crie uma coluna calculada associada ao valor inteiro.
Clique em New Step.
No painel Transformation, digite case e depois selecione Conditional column.
Clique em Case on single column no menu suspenso.
Em Column to evaluate, especifique eCommerceAction_type.
Ao lado de Cases (X), clique em Add oito vezes. Vai haver nove casos no total.
Para cada Case, especifique os seguintes valores de mapeamento (incluindo as aspas):
Valor comparado
Novo valor
1
'Click through of product lists'
2
'Product detail views'
3
'Add product(s) to cart'
4
'Remove product(s) from cart'
5
'Check out'
6
'Completed purchase'
7
'Refund of purchase'
8
'Checkout options'
0
'Unknown'
Não altere os valores dos outros campos.
Em New column name, digite eCommerceAction_label, e depois clique em Add.
Revise a receita e compare-a com este exemplo:
Tarefa 7. Executar um job do Cloud Dataprep para carregar o BigQuery
Quando o fluxo estiver pronto, execute a receita de transformação em seu conjunto de dados de origem. Para fazer isso, você vai executar e monitorar um job do Cloud Dataprep, que inicia e executa um job do Cloud Dataflow.
No canto superior direito da página "Transformer", clique em Run.
Na seção "Publishing Actions", passe o mouse sobre Create-CSV e clique em Edit.
Selecione BigQuery no painel esquerdo, acesse o conjunto de dados de e-commerce e clique em Create a new table.
Nomeie a tabela de saída apparel_revenue e selecione Drop the table every run no painel direito.
Clique em Update.
Clique em Run.
Clique em Job history no painel esquerdo para monitorar o job do Cloud Dataprep.
Aguarde de um a dois minutos para que seu job seja executado
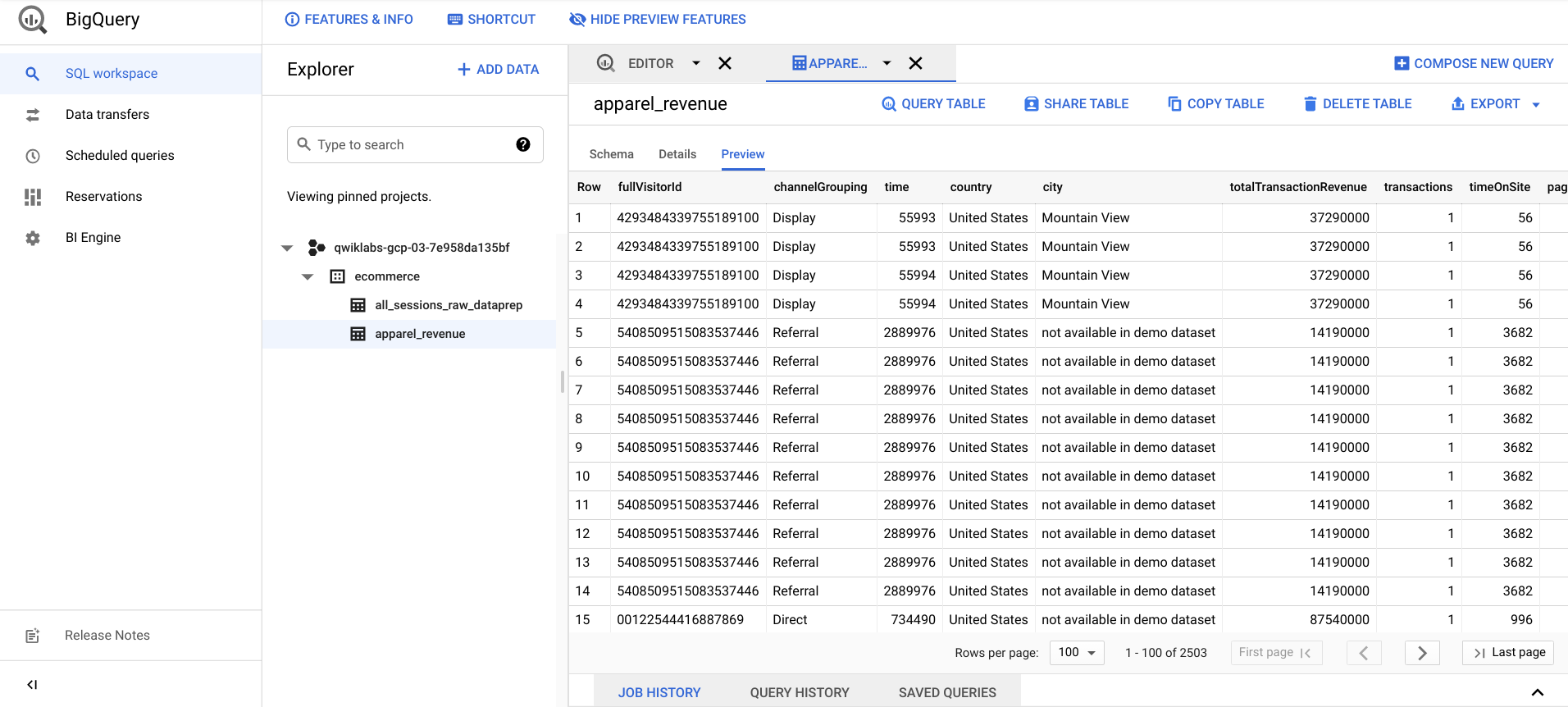
Depois que seu job do Cloud Dataprep for concluído, atualize a página do BigQuery e confirme que a tabela de saída apparel_revenue existe.
Selecione apparel_revenue > Preview e verifique se você tem dados de transações de receita para produtos de "Apparel".
Parabéns!
Você analisou seu conjunto de dados de e-commerce e criou um pipeline de transformação de dados recorrente com o Cloud Dataprep.
Você já tem uma conta do Google Analytics e quer consultar seus próprios conjuntos de dados no BigQuery? Siga o guia Configurar o BigQuery Export.
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, abordaremos o uso da interface do Cloud Dataprep para criar um pipeline de transformação de e-commerce que será executado em um intervalo agendado e retornará os resultados ao BigQuery.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 90 minutos
 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.
 ), ao lado do ID do projeto, e selecione Create dataset.
), ao lado do ID do projeto, e selecione Create dataset.
 ).
).
 e depois em Change type > String.
e depois em Change type > String.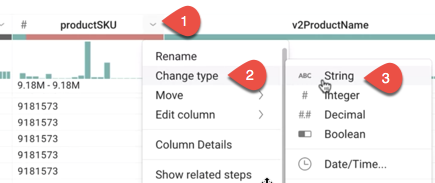
 ), no canto superior direito, e selecione New Step.
), no canto superior direito, e selecione New Step.