
准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Storing and querying massive datasets can be time consuming and expensive without the right hardware and infrastructure. BigQuery is an enterprise data warehouse that solves this problem by enabling super-fast SQL queries using the processing power of Google's infrastructure. Simply move your data into BigQuery and let us handle the hard work. You can control access to both the project and your data based on your business needs, such as giving others the ability to view or query your data.
You access BigQuery through the Cloud Console, the command-line tool, or by making calls to the BigQuery REST API using a variety of client libraries such as Java, .NET, or Python. There are also a variety of third-party tools that you can use to interact with BigQuery, such as visualizing the data or loading the data. In this lab, you access BigQuery using the web UI.
You can use the BigQuery web UI in the Cloud Console as a visual interface to complete tasks like running queries, loading data, and exporting data. This hands-on lab shows you how to query tables in a public dataset and how to load sample data into BigQuery through the Cloud Console.
In this lab, you learn how to perform the following tasks:
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Google Skills using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts. If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
The Welcome to BigQuery in the Cloud Console message box opens. This message box provides a link to the quickstart guide and lists UI updates.
In this task, you load a public dataset, USA Names, into BigQuery, then query the dataset to determine the most common names in the US between 1910 and 2013.
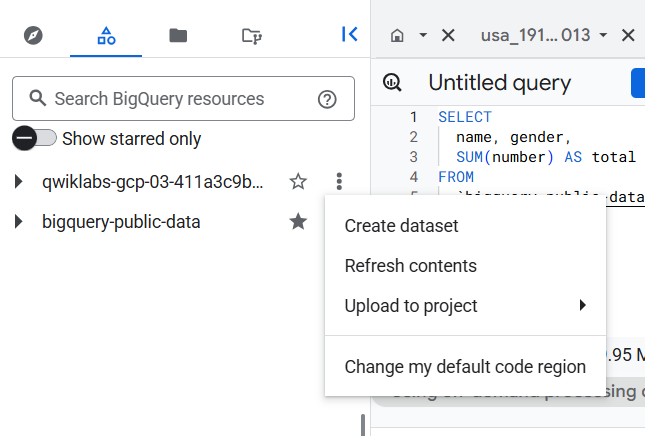
In the Classic Explorer pane, hover the pointer over bigquery-public-data, and then click 
In Search BigQuery resources field, type bigquery-public-data.
This display all the datasets in the project.
bigquery-public-data doesn't appear to the Explorer pane, then click on + ADD DATA > Star a project by name > Star a project (bigquery-public-data) and STAR.
Click Expand node for bigquery-public-data.
Scroll down the list of public datasets, click More Results until you find usa_names.
Click usa_names to expand the dataset.
Click usa_1910_2013 to open that table.
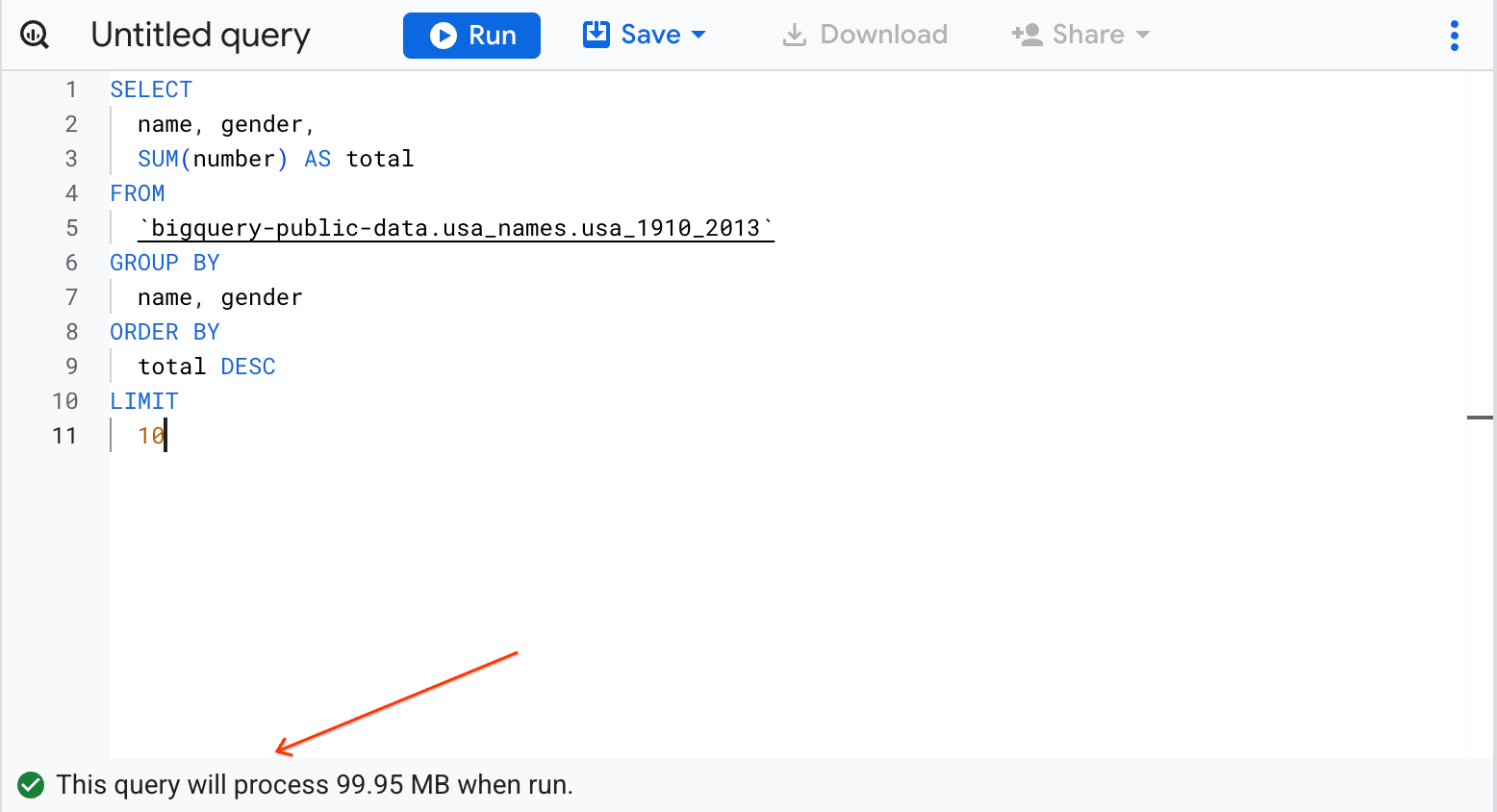
Query bigquery-public-data.usa_names.usa_1910_2013 for the name and gender of the babies in this dataset, and then list the top 10 names in descending order.
Click + SQL query, to open a new Query editor.
Copy and paste the following query into the Query editor text area, replacing the existing query:
BigQuery displays a green check mark icon if the query is valid. If the query is invalid, a red exclamation point icon is displayed. When the query is valid, the validator also shows the amount of data the query processes when you run it. This helps to determine the cost of running the query.
The query results open below the Query editor. At the top of the Query results section, BigQuery displays the time elapsed and the data processed by the query. Below the time is the table that displays the query results. The header row contains the name of the column as specified in GROUP BY in the query.
In this task, you create a custom table, load data into it, and then run a query against the table.
The file you're downloading contains approximately 7 MB of data about popular baby names, and it is provided by the US Social Security Administration.
yob2014.txt to see what the data looks like. The file is a comma-separated value (CSV) file with the following three columns: name, sex (M or F), and number of children with that name. The file has no header row.yob2014.txt file so that you can find it later.In this task, you create a dataset to hold your table, add data to your project, then make the data table you'll query against.
Datasets help you control access to tables and views in a project. This lab uses only one table, but you still need a dataset to hold the table.
Click on the three dots next to your project ID and then click Create dataset.
On the Create dataset page:
babynames.Click Create dataset at the bottom of the pane.
In this task, you load data into the table you made.
In the Classic Explorer pane, expand your project ID dataset.
Click on the three dots next to babynames, and then click Create table.
Use the default values for all settings unless otherwise indicated.
On the Create table page:
Create table from: dropdown menu.yob2014.txt file and click Open.names_2014.Now that you've loaded data into your table, you can run queries against it. The process is identical to the previous example, except that this time, you're querying your table instead of a public table.
You queried a public dataset, then created a custom table, loaded data into it, and then ran a query against that table.
When you have completed your lab, click End Lab. Google Skills removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2026 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验
完成此快速步骤即可开始实验。