Visão geral
Neste laboratório, você tem uma frota de táxis na cidade de Nova York e procura monitorar o desempenho dos seus negócios em tempo real. Você vai criar um pipeline de dados de streaming para capturar a receita dos táxis, o número de passageiros, o status da viagem e muito mais. Depois você vai conferir os resultados em um painel de gerenciamento.
Objetivos
Neste laboratório, você vai aprender a:
- Criar um job do Dataflow com base em um modelo
- Transmitir um pipeline do Dataflow para o BigQuery
- Monitorar um pipeline do Dataflow no BigQuery
- Analisar resultados com SQL
- Conferir as métricas principais no Looker Studio
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento.
No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
- O botão Abrir console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Nome de usuário"}}}
Você também encontra o Nome de usuário no painel Detalhes do laboratório.
-
Clique em Seguinte.
-
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
{{{user_0.password | "Senha"}}}
Você também encontra a Senha no painel Detalhes do laboratório.
-
Clique em Seguinte.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar uma lista de produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo ou digite o nome do serviço ou produto no campo Pesquisar.

Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.

-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:

A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- Para listar o nome da conta ativa, use este comando:
gcloud auth list
Saída:
Credentialed accounts:
- @.com (active)
Exemplo de saída:
Credentialed accounts:
- google1623327_student@qwiklabs.net
- Para listar o ID do projeto, use este comando:
gcloud config list project
Saída:
[core]
project =
Exemplo de saída:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Observação:
a documentação completa da gcloud está disponível no
guia com informações gerais sobre a gcloud CLI
.
Tarefa 1: crie um conjunto de dados do BigQuery
Nesta tarefa, você vai criar o conjunto de dados taxirides usando o Google Cloud Shell ou o console do Google Cloud.
Neste laboratório, você vai usar um extrato do conjunto de dados aberto da Comissão de Táxis e Limusines de Nova York. Um pequeno arquivo de dados separados por vírgulas será utilizado para simular atualizações periódicas de informações sobre táxis.
O BigQuery é um data warehouse sem servidor. As tabelas no BigQuery são organizadas em conjuntos de dados. Neste laboratório, os dados de táxis vão fluir do arquivo independente pelo Dataflow para serem armazenados no BigQuery. Com essa configuração, qualquer novo arquivo de dados depositado no bucket de origem do Cloud Storage seria automaticamente processado para carregamento.
Escolha uma destas opções para criar um conjunto de dados do BigQuery:
Opção 1: a ferramenta de linha de comando
- No Cloud Shell (
 ), execute o comando a seguir para criar o conjunto de dados
), execute o comando a seguir para criar o conjunto de dados taxirides.
bq --location={{{project_0.default_region|Region}}} mk taxirides
- Execute este comando para criar a tabela
taxirides.realtime (esquema vazio para o streaming).
bq --location={{{project_0.default_region|Region}}} mk \
--time_partitioning_field timestamp \
--schema ride_id:string,point_idx:integer,latitude:float,longitude:float,\
timestamp:timestamp,meter_reading:float,meter_increment:float,ride_status:string,\
passenger_count:integer -t taxirides.realtime
Opção 2: a interface do console do BigQuery
Observação: ignore as próximas etapas se você tiver usado a linha de comando para criar as tabelas.
-
No Menu de navegação ( ) do console do Google Cloud, clique em BigQuery.
) do console do Google Cloud, clique em BigQuery.
-
Na caixa de diálogo "Olá", clique em Concluído.
-
Clique em Ver ações ( ) ao lado de "ID do projeto" e, depois, em Criar conjunto de dados.
) ao lado de "ID do projeto" e, depois, em Criar conjunto de dados.
-
Em "ID do conjunto de dados", digite taxirides.
-
Em "Local dos dados", selecione:
{{{project_0.default_region|Region}}}
depois clique em Criar conjunto de dados.
-
No painel "Explorer", abra o nó (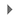 ) para ver o novo conjunto "taxirides".
) para ver o novo conjunto "taxirides".
-
Clique em Conferir ações () ao lado do conjunto de dados taxirides e em Abrir.
-
Clique em Criar tabela.
-
Em "Tabela", digite realtime.
-
Para o esquema, clique em Editar como texto e cole o seguinte:
ride_id:string,
point_idx:integer,
latitude:float,
longitude:float,
timestamp:timestamp,
meter_reading:float,
meter_increment:float,
ride_status:string,
passenger_count:integer
-
Em Configurações de particionamento e cluster, selecione carimbo de data/hora.
-
Clique em Criar tabela.
Tarefa 2: copie os artefatos obrigatórios do laboratório
Nesta tarefa, você vai mover os arquivos necessários para seu projeto.
O Cloud Storage permite o armazenamento e a recuperação de volumes de dados a qualquer momento e em escala global. É possível usar o Cloud Storage para vários cenários, como veiculação de conteúdo de sites, armazenamento de dados para arquivamento e recuperação de desastres ou distribuição de objetos de dados grandes aos usuários por download direto.
Um bucket do Cloud Storage foi criado para você no início do laboratório.
- No Cloud Shell (), execute os comandos abaixo para mover os arquivos necessários para o job do Dataflow.
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/schema.json gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/schema.json
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/transform.js gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/transform.js
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/rt_taxidata.csv gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/rt_taxidata.csv
Tarefa 3: configure um pipeline do Dataflow
Nesta tarefa, você vai configurar um pipeline de dados de streaming para ler arquivos do seu bucket do Cloud Storage e gravar dados no BigQuery.
O Dataflow é um modo de análise de dados sem servidor.
Reinicie a conexão com a API Dataflow.
- No Cloud Shell, execute estes comandos para garantir que a API Dataflow esteja ativada sem problemas no projeto.
gcloud services disable dataflow.googleapis.com
gcloud services enable dataflow.googleapis.com
Crie um pipeline de streaming:
-
No console do Cloud, acesse o Menu de navegação () e clique em Mostrar todos os produtos > Análise de dados > Dataflow.
-
Na barra do menu superior, clique em Criar job usando um modelo.
-
Digite streaming-taxi-pipeline como o nome do seu job do Dataflow.
-
Em Endpoint regional, selecione
{{{project_0.default_region|Region}}}
- No modelo do Dataflow, selecione a opção Cloud Storage Text para BigQuery (stream) em Processar dados continuamente (stream).
Observação: selecione a opção de modelo que corresponde aos parâmetros listados abaixo.
- Em Arquivos de entrada do Cloud Storage, cole ou digite:
{{{project_0.project_id|Project_ID}}}-bucket/tmp/rt_taxidata.csv
- No local do Cloud Storage do seu arquivo de esquema do BigQuery, descrito como JSON, cole ou digite:
{{{project_0.project_id|Project_ID}}}-bucket/tmp/schema.json
- Na Tabela de saída do BigQuery, cole ou digite:
{{{project_0.project_id|Project_ID}}}:taxirides.realtime
- No diretório temporário do processo de carregamento do BigQuery, cole ou digite:
{{{project_0.project_id|Project_ID}}}-bucket/tmp
-
Clique em Parâmetros obrigatórios.
-
Em Local temporário, usado para gravar arquivos temporários, cole ou digite:
{{{project_0.project_id|Project_ID}}}-bucket/tmp
- Em Caminho da UDF JavaScript no Cloud Storage, cole ou digite:
{{{project_0.project_id|Project_ID}}}-bucket/tmp/transform.js
- Em Nome da UDF JavaScript, cole ou digite:
transform
-
Em Número máximo de workers, digite 2
-
Em Número de workers, digite 1
-
Desmarque a opção Usar o tipo de máquina padrão.
-
Em Uso geral, escolha o seguinte:
Série: E2
Tipo de máquina: e2-medium (2 vCPUs, 4 GB de memória)
- Clique em Executar job.
Um novo job de streaming é iniciado. Agora você pode conferir uma representação visual do pipeline de dados. A transferência de dados para o BigQuery vai começar depois do intervalo de 3 a 5 minutos.
Observação: se o job do Dataflow falhar na primeira vez, crie e execute outro modelo de job com um novo nome.
Tarefa 4: analise os dados sobre táxis com o BigQuery
Nesta tarefa, você vai analisar os dados durante o streaming.
-
No console do Cloud, acesse o Menu de navegação () e clique em BigQuery.
-
Quando a caixa de diálogo "Olá" aparecer, clique em Concluído.
-
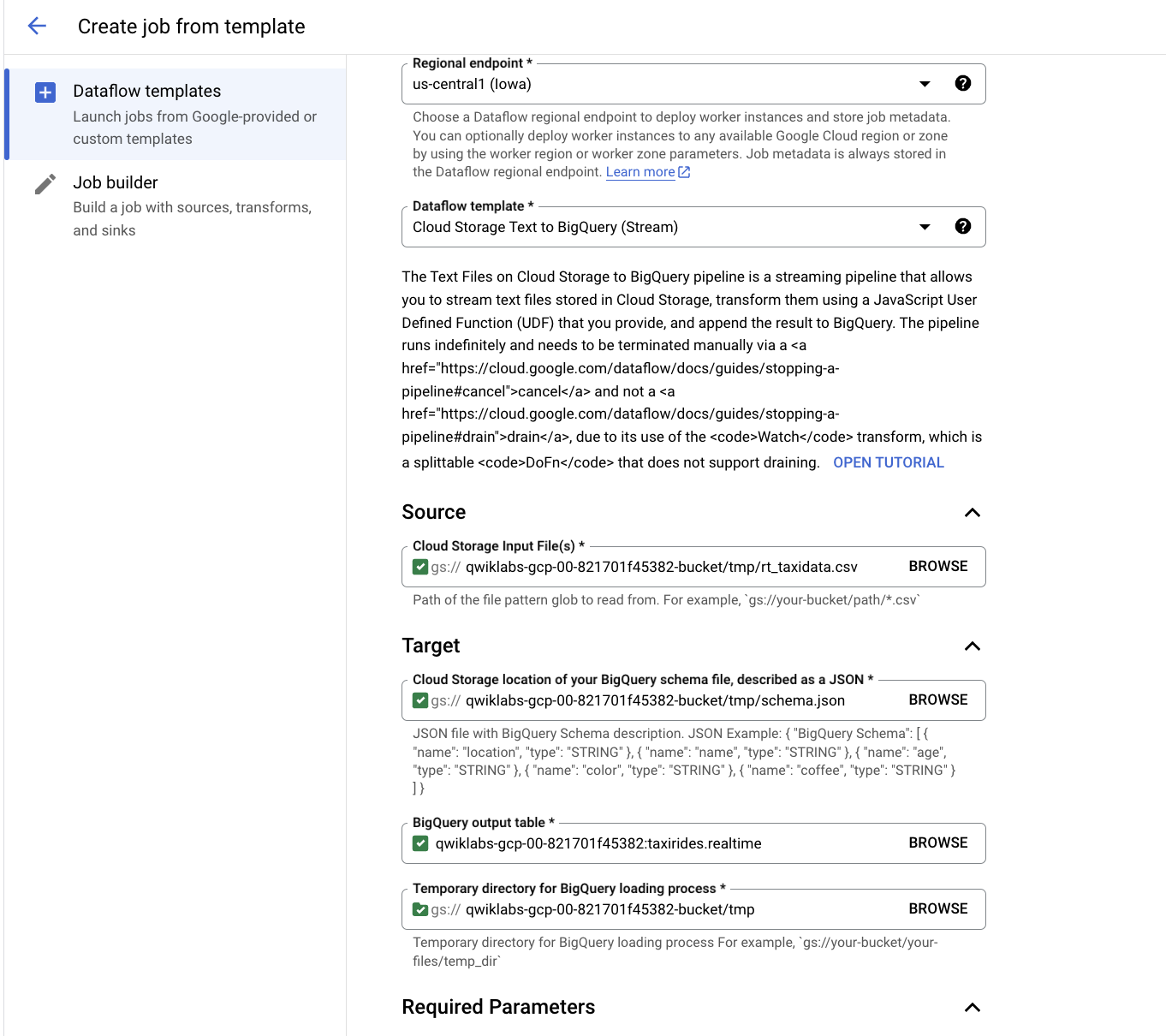
Em "Editor de consultas", digite a consulta a seguir e clique em Executar:
SELECT * FROM taxirides.realtime LIMIT 10
Observação: se você não receber nenhum registro, espere mais um minuto e repita a consulta acima (o Dataflow leva de 3 a 5 minutos para configurar o stream).
A saída será semelhante a esta:
Tarefa 5: faça agregações no stream para gerar relatórios
Nesta tarefa, você vai calcular agregações no stream para gerar relatórios.
-
Em Editor de consultas, apague a consulta atual.
-
Copie e cole a consulta a seguir. Depois clique em Executar.
WITH streaming_data AS (
SELECT
timestamp,
TIMESTAMP_TRUNC(timestamp, HOUR, 'UTC') AS hour,
TIMESTAMP_TRUNC(timestamp, MINUTE, 'UTC') AS minute,
TIMESTAMP_TRUNC(timestamp, SECOND, 'UTC') AS second,
ride_id,
latitude,
longitude,
meter_reading,
ride_status,
passenger_count
FROM
taxirides.realtime
ORDER BY timestamp DESC
LIMIT 1000
)
# calculate aggregations on stream for reporting:
SELECT
ROW_NUMBER() OVER() AS dashboard_sort,
minute,
COUNT(DISTINCT ride_id) AS total_rides,
SUM(meter_reading) AS total_revenue,
SUM(passenger_count) AS total_passengers
FROM streaming_data
GROUP BY minute, timestamp
Observação: antes de prosseguir para a próxima tarefa, confira se o Dataflow registrou os dados no BigQuery.
O resultado mostra as principais métricas por minuto para cada desembarque do táxi.
-
Clique em Salvar > Salvar consulta.
-
Na caixa de diálogo "Salvar consulta", digite Minha consulta salva no campo Nome.
-
Em Região, verifique se a região corresponde à do laboratório do Qwiklabs.
-
Clique em Salvar.
Tarefa 6: interrompa o job do Dataflow
Nesta tarefa, você vai interromper o job do Dataflow para liberar recursos para o projeto.
-
No console do Cloud, acesse o Menu de navegação () e clique em Mostrar todos os produtos > Análise de dados > Dataflow.
-
Clique em streaming-taxi-pipeline ou no nome do novo job.
-
Clique em Interromper e selecione Cancelar > Interromper job.
Tarefa 7: crie um painel em tempo real
Nesta tarefa, você vai criar um painel para visualizar os dados em tempo real.
-
No console do Cloud, acesse o Menu de navegação () e clique em BigQuery.
-
No painel "Explorer", abra o ID do projeto.
-
Abra Consultas e clique em Minha consulta salva.
Sua consulta aparece no editor de consultas.
-
Clique em Executar.
-
Na seção "Resultados da consulta", clique em Abrir em > Looker Studio.
O Looker Studio será aberto. Clique em Começar.
-
Na janela do Looker Studio, clique no gráfico de barras.
( )
)
O painel "Gráfico" aparece.
-
Clique em Adicionar um gráfico e selecione Gráfico de combinação.

-
No painel "Configuração", em "Dimensão do intervalo de dados", passe o mouse sobre minuto (data) e clique em X para removê-lo.
-
No painel "Dados", clique em dashboard_sort e arraste-o para Configuração > Dimensão do intervalo de dados > Adicionar dimensão.
-
Em Configuração > Dimensão, clique em minuto e selecione dashboard_sort.
-
Em Configuração > Métrica, clique em dashboard_sort e selecione total_rides.
-
Em Configuração > Métrica, clique em Contagem de registros e selecione total_passengers.
-
Em Configuração > Métrica, clique em Adicionar métrica e selecione total_revenue.
-
Em Configuração > Ordenar, clique em total_ridese selecione dashboard_sort.
-
Em Configuração > Ordenar, clique em Crescente.
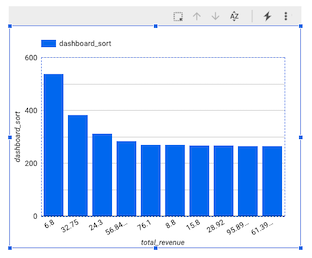
Seu gráfico precisa ser parecido com este:
Observação: no momento, não é possível conferir os dados com granularidade por minuto no Looker Studio como um carimbo de data/hora. Por isso, criamos a dimensão dashboard_sort.
-
Quando você estiver satisfeito com seu painel, clique em Salvar e compartilhar para salvar essa fonte de dados.
-
Se um aviso para concluir a configuração da conta aparecer, digite os detalhes do país e da empresa, concorde com os Termos e Condições e clique em Continuar.
-
Se for solicitado que você escolha qual tipo de atualizações gostaria de receber, selecione não para todas as ofertas e clique em Continuar.
-
Se a mensagem Revise o acesso aos dados antes de salvar aparecer, selecioneConfirmar e salvar.
-
Se for solicitado que você escolha uma conta, selecione sua Conta de estudante.
-
Sempre que alguém acessar seu painel, verá as últimas transações. Para testar, clique em Mais opções ( ) e em Atualizar dados.
) e em Atualizar dados.
Tarefa 8: crie um painel de série temporal
Nesta tarefa, você vai criar um gráfico de série temporal.
-
Clique neste link do Looker Studio para abrir a ferramenta em uma nova guia do navegador.
-
Na página Relatórios, na seção Começar com um modelo, clique em [+] Relatório em branco.
-
Um novo relatório vazio é aberto com a janela Adicionar dados ao relatório.
-
Na lista de Conectores do Google, selecione o bloco do BigQuery.
-
Clique em Consulta personalizada e selecione o ID do projeto. O formato dele será qwiklabs-gcp-xxxxxxx.
-
Em "Insira a consulta personalizada", cole o seguinte:
SELECT
*
FROM
taxirides.realtime
WHERE
ride_status='enroute'
-
Clique em Adicionar > Adicionar ao relatório.
Um novo relatório sem título aparece. Pode levar até um minuto para que a tela seja atualizada.
Crie um gráfico de série temporal
-
No painel Dados, clique em Adicionar um campo > Adicionar campo calculado.
-
No canto esquerdo, clique em Todos os campos.
-
Mude o tipo de campo Carimbo de data/hora para Data e hora > Data, hora e minuto (AAAAMMDDhhmm).
-
Na caixa de diálogo para mudar o carimbo de data/hora, clique em Continuar e em Concluído.
-
No menu superior, clique em Adicionar um gráfico.
-
Escolha Gráfico de série temporal.

-
Posicione o gráfico no canto inferior esquerdo, no espaço em branco.
-
Em Configuração > Dimensão, clique em carimbo de data/hora (data) e selecione
carimbo de data/hora.
-
Em Configuração > Dimensão, clique em carimbo de data/hora e selecione agenda.

-
Em Tipo de dados, selecione Data e hora > Data, hora e minuto.
-
Clique fora da caixa de diálogo para fechá-la. Você não precisa adicionar um nome.
-
Em Configuração > Métrica, clique em Contagem de registros e selecione leitura de medidor.
Parabéns!
Neste laboratório, você usou o Dataflow para transmitir dados por um pipeline para o BigQuery.
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
- 1 estrela = muito insatisfeito
- 2 estrelas = insatisfeito
- 3 estrelas = neutro
- 4 estrelas = satisfeito
- 5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.





