
准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Apply a datagroup to an Explore
/ 100
Apply a datagroup to an Explore
/ 100

Looker 是 Google Cloud 中的现代化数据平台,支持您以交互方式分析和直观呈现数据。您可以使用 Looker 展开深入数据分析、整合来自不同数据源的分析洞见,构建切实可行的数据驱动型工作流,以及创建自定义数据应用。
Looker 会不断生成 SQL 查询并将其发送到连接的数据库。每当有人在 Looker 中运行查询,SQL 结果都会被缓存并存储到 Looker 实例上的加密文件中。
缓存会利用之前执行的查询所保存的结果,从而避免对数据库重复运行相同的查询。这有助于降低数据库负载。缓存还有助于优化 Looker 性能。在本实验中,您将了解 Looker 中的缓存机制,并探索如何使用 LookML 数据组定义缓存政策。
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
准备就绪时,点击开始实验。
此时您会看到“实验详细信息”窗格,其中包含您在进行该实验时必须使用的临时凭据。
如果该实验需要付费,系统会打开一个弹出式窗口供您选择支付方式。
请注意,“实验详细信息”窗格中会显示实验凭据。您需要使用这些凭据来登录 Looker 实例以进行该实验。
点击打开 Looker。
在电子邮件地址和密码字段中输入提供的用户名和密码。
用户名:
密码:
点击登录。
登录成功后,您会看到用于本实验的 Looker 实例。
Looker 就像数据库的前台服务人员。当用户运行查询时,Looker 会确定之前是否运行过完全相同的查询。如果没有,则允许在数据库上运行查询。返回结果后,Looker 会缓存这些结果以供日后参考。
如果之前运行过相同的查询,Looker 会检查缓存政策,以确定结果是否仍然有效。如果是,Looker 会将缓存的结果返回给业务用户。这个过程耗时不到一秒。
如果之前运行过相同的查询,但根据缓存政策,结果不再有效,Looker 会将查询发送到数据库。然后,它会缓存新结果以供日后参考。
在 Looker 中,“数据组”指已命名的缓存政策或规则。LookML 开发者使用数据组来管理 Looker 实例上的缓存。不同的缓存政策需要不同的数据组定义。您需要创建的数据组的数量和类型取决于您数据的提取、转换和加载 (ETL) 流程以及业务需求。
例如,您可能需要在模型级别、针对各个探索或针对永久性派生表 (PDT) 定义数据组,具体取决于数据的更新频率。
persist_with 参数。persist_with 参数。persist_with 参数,并指定相同的数据组名称。persist_with如果您在模型级别应用数据组,Looker 默认会将相同的缓存规则应用于该模型中的所有探索。
不过,您也可以在单个探索中应用数据组,这会覆盖模型级别的任何设置。由于探索是所有内容的基础,因此相同的缓存逻辑也适用于探索中的 Look 和信息中心。
persist_for 参数对探索查询执行固定时间的缓存,并针对永久性派生表使用 sql_trigger_value 或 persist_for。
datagroup_trigger对于 PDT,您可以应用数据组来指定如何重建 PDT。
Look 和信息中心的时间表也可以在数据组上运行。您可以指示 Looker 在缓存政策到期时自动运行 Look 或信息中心,以便检索新数据并为需要新数据的业务用户“预缓存”这些数据。
数据组接受两个参数:max_cache_age 和 sql_trigger。
max_cache_age 指定缓存结果的保留时间(以小时为单位),例如 24 小时。sql_trigger 用于编写 SELECT 语句,该语句可以告诉 Looker 结果是否发生了变化。sql_trigger 应编写为仅返回一个值。Looker 会定期将此语句发送到连接的数据库。如果结果发生了变化,Looker 会刷新缓存。虽然只需要一个参数,但最好同时使用这两个参数,以实现理想的缓存结果。例如,如果 sql_trigger 检查未检测到任何变化,则可能意味着 ETL 流程或 sql_trigger 本身出了问题。如果您添加了 max_cache_age 参数,则无论 sql_trigger 检查的结果如何,缓存都会在设定的时长后刷新。
在 LookML 模型中为各个探索定义并应用数据组。具体来说,您需要更新“Order Items”探索中所有视图的缓存配置,以便在添加新的 order_item_id 时进行刷新,因为 order_item_id 是“Order Items”的主键。
点击切换按钮进入开发模式。
在开发标签页中,选择 qwiklabs-ecommerce LookML 项目。
打开 training_ecommerce.model 文件。
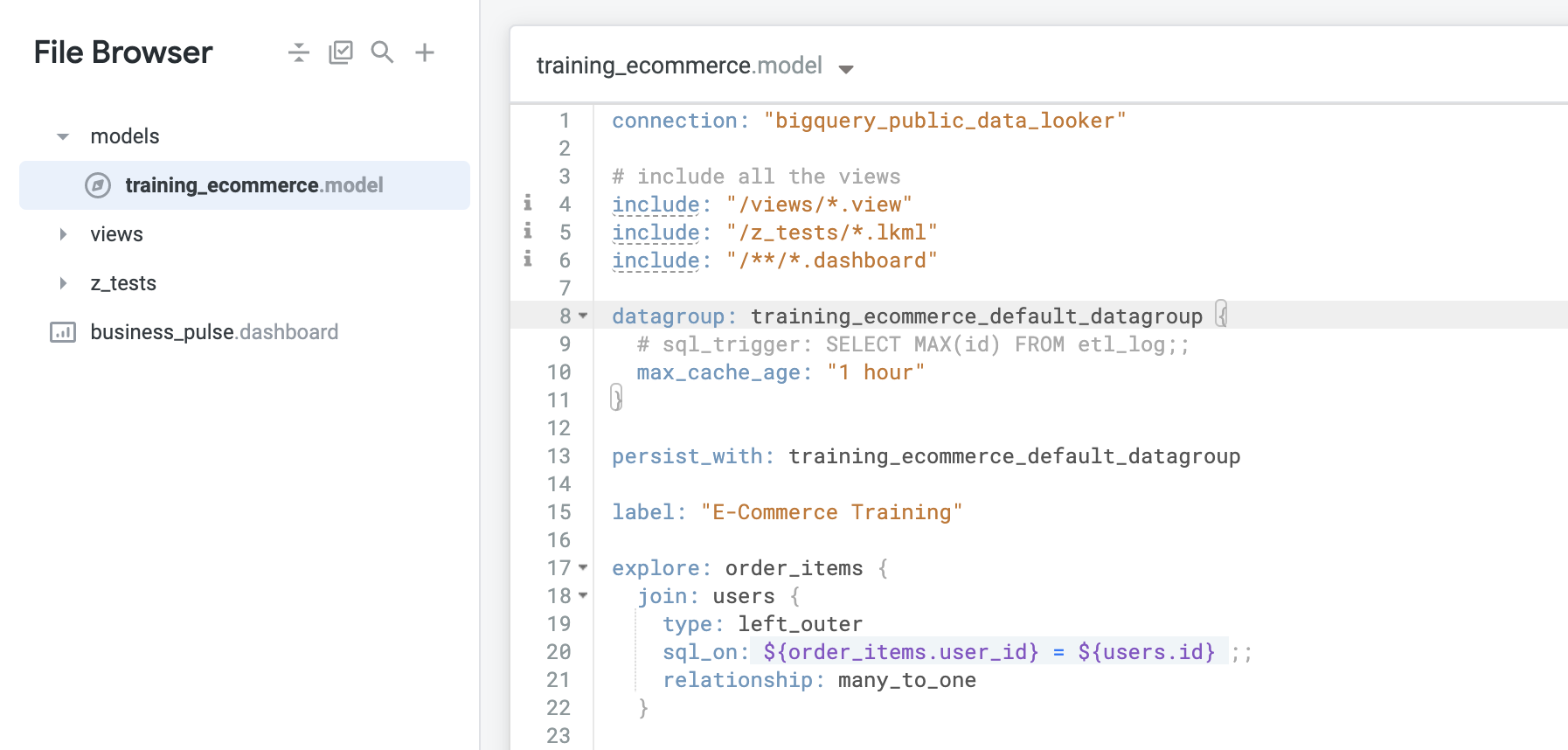
请注意,此模型文件有一个默认数据组,其 max_cache_age 为 1 小时。每当您通过让 Looker 根据数据库架构生成模型来创建新的 LookML 项目时,Looker 都会自动创建一个默认数据组,其名称为模型名称(在本例中为 training_ecommerce)后跟 _default_datagroup。
由于此默认数据组目前是在模型级别定义的,因此它会应用于模型中定义的所有探索。您需要将新的数据组应用于探索,因此必须移除默认数据组并进行更新。要完成新数据组的定义,您需要为两个参数提供值:sql_trigger 和 max_cache_age。
删除默认数据组和 persist_with 定义(第 8-13 行)。
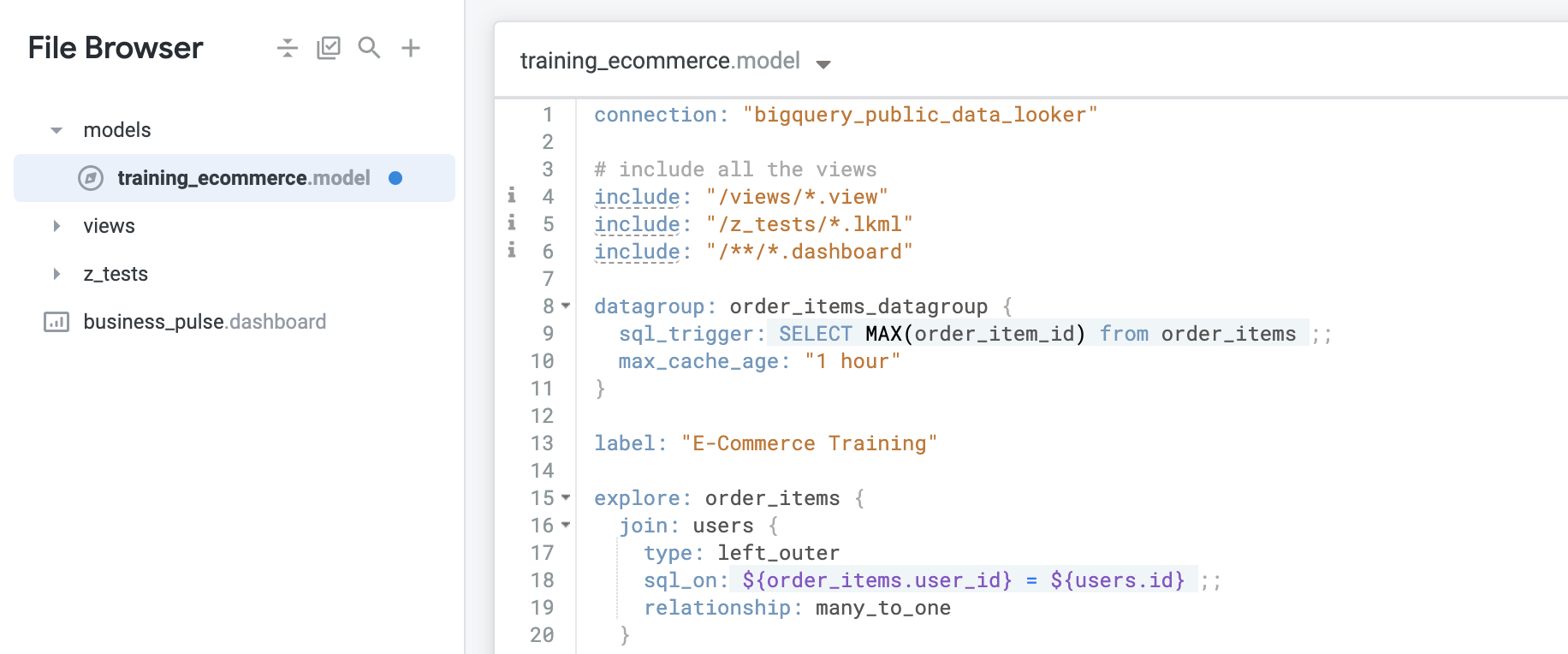
要为特定探索(例如 Order Items)创建新的数据组,请输入以下代码:
sql_trigger,要选择 order_item_id 的最大 ID,请输入以下代码:max_cache_age,以便即使数据更新出现问题,缓存也会继续每小时刷新一次。输入以下代码:请注意,配置数据组本身不会产生任何影响,这是一个两步流程。定义数据组后,您需要使用名为 persist_with 的参数将数据组应用于对象。
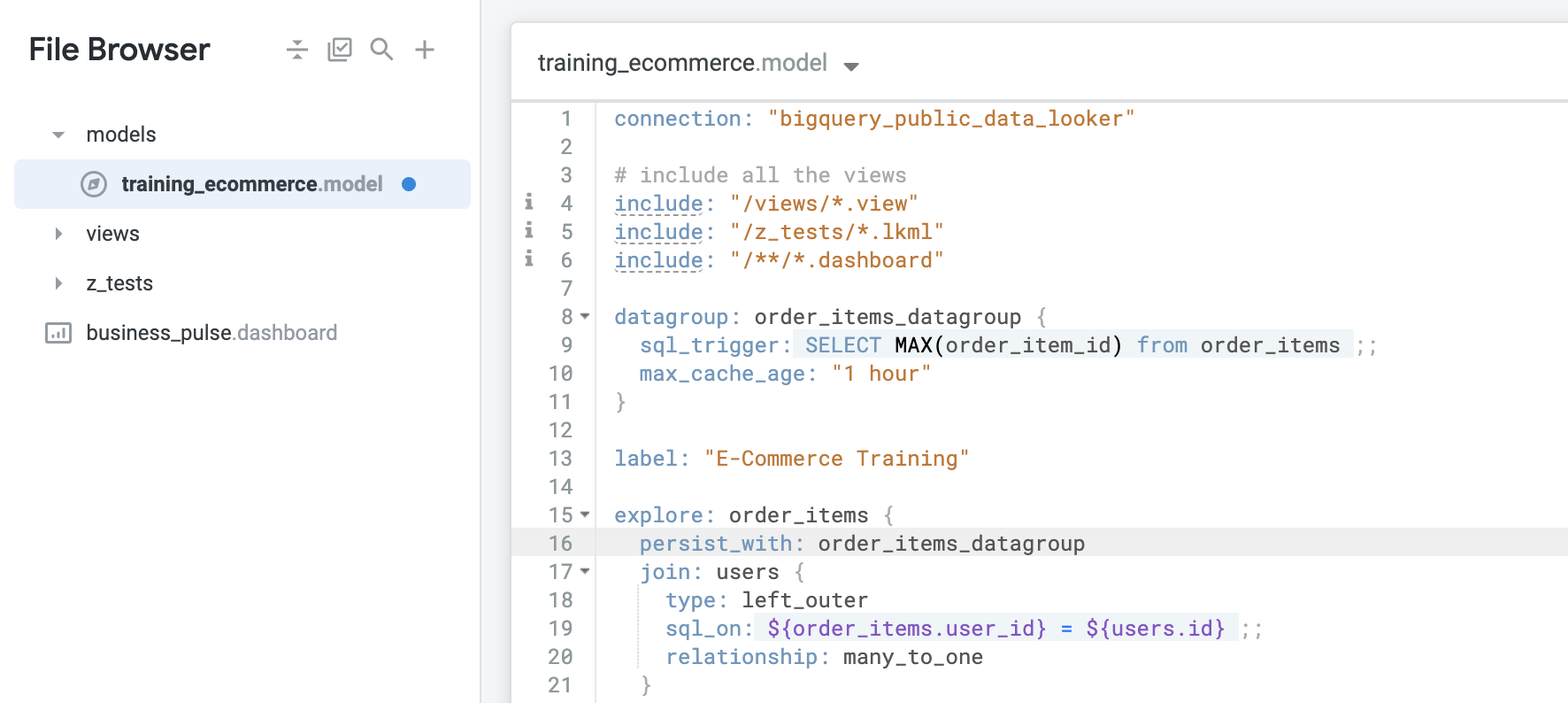
explore: order_items 行的正下方输入以下代码:点击验证 LookML,然后点击提交更改并推送。
添加提交消息,然后点击提交。
最后,点击部署到生产环境。
太棒了!您刚刚定义了自己的缓存策略(数据组),使其在每当新增订单号时进行更新;同时使用了设为 1 小时的最大缓存期限参数,以确保无论数据是否更新,缓存都会每小时刷新一次。然后,您将此数据组应用于单个 Order Items 探索,而非整个模型。
点击“检查我的进度”以验证是否完成了以下目标:
在本实验中,您学习了如何在 Looker 中定义和使用缓存,并探索了如何使用 LookML 数据组来定义缓存政策。
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
本手册的最后更新时间:2025 年 4 月 24 日
本实验的最后测试时间:2025 年 4 月 24 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验
完成此快速步骤即可开始实验。