GSP893

Visão geral
O Looker é uma plataforma de dados moderna do Google Cloud que serve para analisar e visualizar dados de forma interativa. Com ele, você pode fazer análises de dados detalhadas, integrar insights entre diferentes fontes de dados, gerar fluxos de trabalho orientados por dados e criar aplicativos de dados personalizados.
O Looker gera consultas SQL e as envia para o banco de dados conectado constantemente. Sempre que alguém faz uma consulta na plataforma, os resultados SQL são armazenados em cache e guardados em um arquivo criptografado na instância da plataforma.
O armazenamento em cache usa os resultados salvos de consultas anteriores para evitar repetições e reduzir a carga do banco de dados, além de otimizar a performance do Looker. Neste laboratório, você vai ver como o armazenamento em cache funciona no Looker e como usar datagroups do LookML para definir políticas.
Atividades deste laboratório
- Entender o que são o armazenamento em cache e os diferentes objetos de datagroup no LookML
- Aplicar um datagroup a uma Análise específica em um modelo do LookML
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O cronômetro começa ao clicar em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça, depois de começar, não será possível pausar o laboratório.
Observação: não use seu projeto ou conta pessoal do Google Cloud neste laboratório para evitar cobranças extras.
Como iniciar o laboratório e fazer login no Looker
-
Quando tudo estiver pronto, clique em Começar o laboratório.
O painel "Detalhes do laboratório" aparece com as credenciais temporárias que você precisa usar neste laboratório.
Se for preciso pagar pelo laboratório, você verá um pop-up para selecionar a forma de pagamento.
Confira suas credenciais do laboratório no painel "Detalhes do laboratório". É com elas que você vai fazer login na instância do Looker neste laboratório.
Observação: se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Clique em Abrir o Looker.
-
Digite o nome de usuário e a senha fornecidos nos campos E-mail e Senha.
Nome de usuário:
{{{looker.developer_username | Username}}}
Senha:
{{{looker.developer_password | Password}}}
Importante: é necessário usar as credenciais do painel "Detalhes do laboratório" nesta página. Não use suas credenciais do Google Cloud Ensina. Se você tiver uma conta pessoal do Looker, não a use neste laboratório.
-
Clique em Fazer login.
Depois de se conectar, você verá a instância do Looker deste laboratório.
Como o armazenamento em cache funciona no Looker
O Looker funciona como um recepcionista do banco de dados. Quando um usuário inicia uma consulta, ele verifica se alguém já fez a mesma solicitação antes. Se não encontrar nada, ele vai permitir a execução da consulta no banco de dados. Depois disso, o Looker armazena os resultados em cache.
Se a mesma consulta já tiver sido feita, o Looker verifica a política de armazenamento em cache para conferir se os resultados ainda são válidos. Caso sejam, o Looker vai mostrar para usuários comerciais. Isso acontece em menos de um segundo.
Quando houver registros de consultas iguais, mas os resultados não forem mais válidos de acordo com a política, o Looker vai enviar a consulta para o banco de dados. Depois, ele vai armazenar os novos resultados em cache.
Datagroups
Um datagroup é o termo do Looker para políticas ou regras de armazenamento em cache que têm nome. Os desenvolvedores do LookML usam esse recurso para gerenciar o armazenamento em cache em uma instância do Looker. Cada política de armazenamento em cache precisa ter definições de datagroups específicas. A quantidade e os tipos de datagroups que você precisa criar dependem dos requisitos de negócios e dos processos de extração, transformação e carregamento (ETL) dos seus dados.
Por exemplo, talvez seja necessário definir datagroups no modelo para Análises individuais ou para tabelas derivadas permanentes (TDP), dependendo da frequência de uso dos dados.
- Para aplicar um datagroup como padrão para todas as Análises, use o parâmetro
persist_with no modelo.
- Se quiser atribuir um datagroup a uma Análise específica, use o parâmetro
persist_with na definição da Análise.
- Para aplicar um datagroup a um conjunto específico de Análises, mas não a todas em um modelo, use o parâmetro
persist_with na definição de cada Análise e especifique o mesmo nome de datagroup.
Objetos que podem usar datagroups
persist_with
Se você aplicar um datagroup no modelo, o Looker vai atribuir as mesmas regras de armazenamento em cache a todas as Análises desse modelo por padrão.
Apesar disso, é possível aplicar um datagroup em uma Análise individual, o que substitui qualquer configuração no nível do modelo. Como as Análises são a base de todo o conteúdo, a mesma lógica de armazenamento em cache se aplica a Looks e dashboards na Análise.
Observação: se a conexão do banco de dados estiver configurada no Looker para usar nomes de usuário dinâmicos, não será possível usar um datagroup para modelos que usam essa conexão. Em vez disso, use um parâmetro persist_for para armazenar em cache as consultas da Análise por um período fixo e use sql_trigger_value ou persist_for para tabelas derivadas persistentes.
datagroup_trigger
Para PDTs, é possível aplicar um datagroup para especificar como a PDT é recriada.
Programações
As programações de Looks e dashboards também podem ser executadas em datagroups. O Looker pode ser instruído para executar um Look ou dashboard automaticamente assim que uma política de armazenamento em cache expirar. Dessa forma, novos dados podem ser recuperados e "pré-armazenados em cache" para usuários comerciais que precisarem deles.
Configuração do datagroup
Os datagroups usam dois parâmetros: max_cache_age e sql_trigger.
-
max_cache_age especifica o número de horas para manter um resultado em cache, por exemplo, 24 horas.
-
sql_trigger é usado para criar uma instrução SELECT que pode informar ao Looker se os resultados mudaram. O sql_trigger precisa ser criado de forma a retornar um valor só. O Looker envia essa instrução para o banco de dados conectado regularmente e, caso o resultado mude, o Looker atualiza o cache.
Ainda que só um parâmetro seja necessário, é melhor usar os dois para alcançar os resultados de armazenamento em cache que você quer. Por exemplo, se a verificação sql_trigger não detectar uma mudança, pode ser que algo tenha dado errado com o processo de ETL ou com o próprio sql_trigger. Se você incluir um parâmetro max_cache_age, o cache será atualizado após uma duração definida, independentemente do resultado da verificação sql_trigger.
Observação: só um desses parâmetros é obrigatório, mas é recomendado usar os dois.
Tarefa 1: aplicar um datagroup a uma Análise
Defina e aplique datagroups a Análises individuais em um modelo do LookML. Especificamente, você vai atualizar o armazenamento em cache de todas as visualizações na Análise Order Items para que elas sejam atualizadas sempre que um novo order_item_id for adicionado, porque order_item_id é a chave primária dos itens do pedido.
Abra o modelo
-
Clique no botão ativar/desativar para entrar no Modo de Desenvolvimento.
-
Na guia Desenvolver, selecione o projeto qwiklabs-ecommerce do LookML.
-
Abra o arquivo training_ecommerce.model.
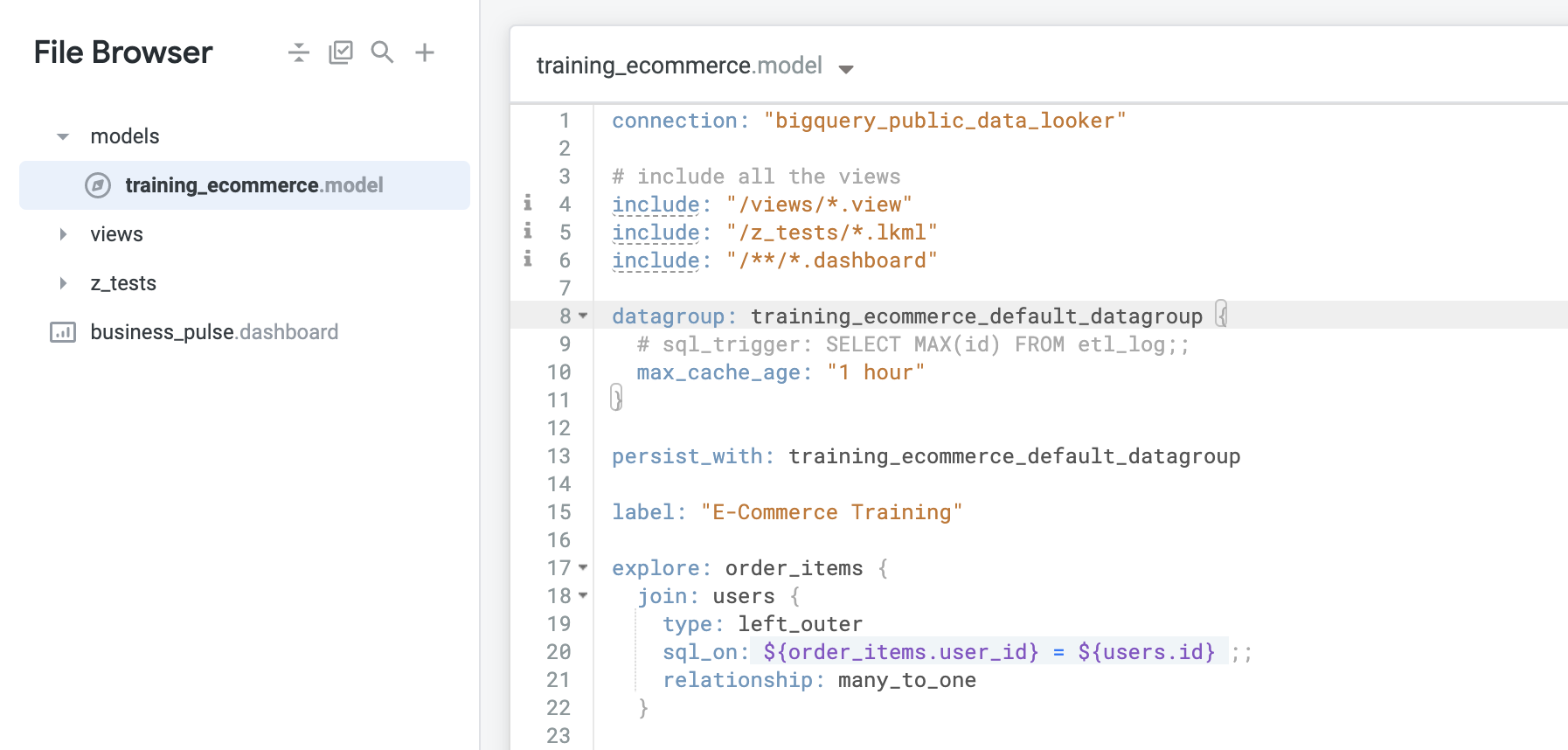
Observe que este arquivo modelo tem um datagroup padrão com um max_cache_age de 1 hora. Sempre que você cria um novo projeto do LookML pedindo para o Looker gerar o modelo com base no esquema do banco de dados, o Looker cria automaticamente um datagroup padrão com o nome do modelo. Nesse caso, training_ecommerce seguido por _default_datagroup.
Exclua e substitua o datagroup padrão
Como esse datagroup padrão está definido no nível do modelo, ele é aplicado a todas as Análises definidas no modelo. Como você quer aplicar o datagroup à Análise, o padrão precisa ser removido e atualizado de acordo. Para concluir a definição do novo datagroup, você precisa indicar valores para os dois parâmetros: sql_trigger e max_cache_age.
-
Exclua o datagroup padrão e a definição persist_with (linhas 8 a 13).
-
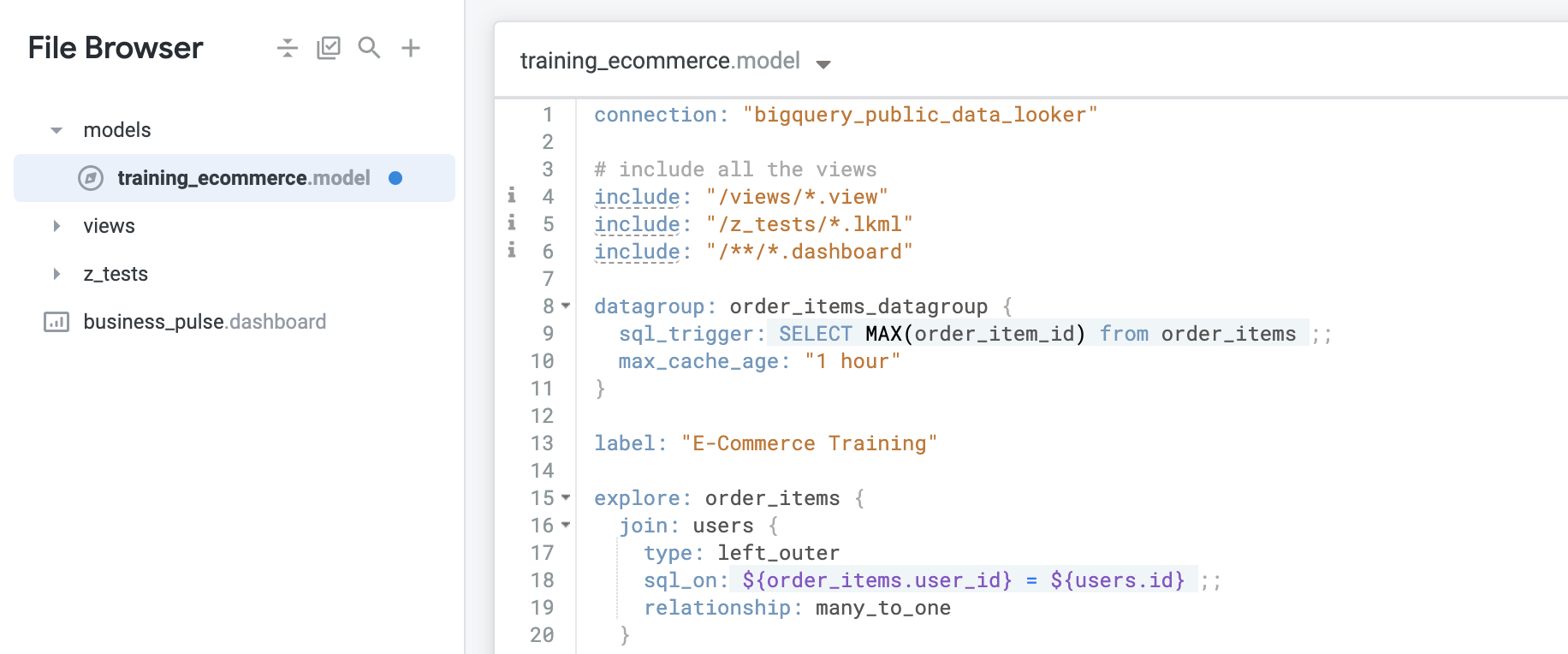
Para criar um novo datagroup para uma Análise específica, como Order Items, insira este código:
datagroup: order_items_datagroup {}
- Em
sql_trigger, para selecionar o ID máximo de order_item_id, insira este código:
sql_trigger: SELECT MAX(order_item_id) from order_items ;;
- Defina o
max_cache_age para que o cache continue a ser atualizado a cada hora, mesmo caso ocorra um problema com as atualizações de dados. Insira este código:
max_cache_age: "1 hour"
Aplique o datagroup
Configurar um datagroup por si só não faz nada, porque processo geral tem duas etapas. Depois que o datagroup é definido, ele precisa ser aplicado a um objeto usando um parâmetro chamado persist_with.
- Para aplicar o datagroup à definição da Análise Order Items, insira este código diretamente abaixo da linha
explore: order_items:
persist_with: order_items_datagroup
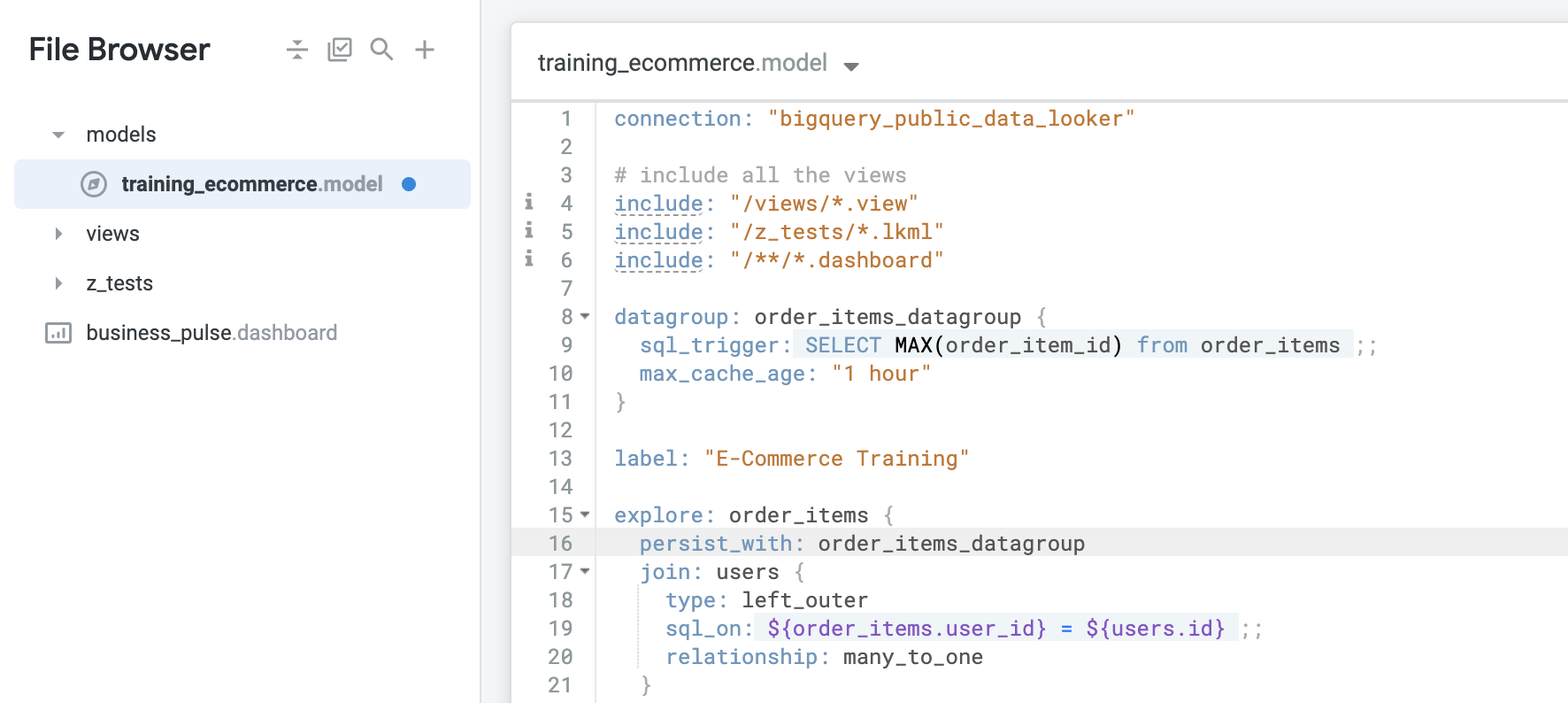
- Clique em Salvar alterações.
Confirmar alterações e implantar na produção
-
Clique em Validar o LookML e em Confirmar alterações e enviar.
-
Adicione uma mensagem de confirmação e clique em Confirmar.
-
Por fim, clique em Implantar na produção.
Ótimo! Você acabou de definir uma política de armazenamento em cache (datagroup) própria que atualiza sempre que um novo número de pedido é adicionado e definiu um parâmetro de idade máxima de armazenamento em cache como 1 hora para que o armazenamento seja atualizado a cada hora, independentemente dos dados. Em seguida, você aplicou o datagroup à Análise Order Items individual, não ao modelo inteiro.
Clique em Verificar meu progresso para conferir o objetivo.
Aplicar um datagroup a uma Análise
Parabéns!
Neste laboratório, você aprendeu a definir e usar o armazenamento em cache no Looker e viu como usar datagroups do LookML para definir políticas de armazenamento em cache.
Próximas etapas / Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 24 de abril de 2025
Laboratório testado em 24 de abril de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





