GSP037

概览
Cloud Vision API 是一项云端服务,用于分析图片并提取信息。您可以用它来检测图片中的对象、人脸和文本。Cloud Vision API 将强大的机器学习模型封装在一个简单的 REST API 中,让您能够了解图片的内容。
在本实验中,您将探索如何将图片发送到 Cloud Vision API,并观察其检测对象、人脸和地标。
目标
在本实验中,您将学习如何执行以下任务:
- 创建 Cloud Vision API 请求,并使用
curl 调用该 API。
- 使用该 API 的标签检测、人脸检测和地标检测方法。
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式(推荐)或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:请仅使用学生账号完成本实验。如果您使用其他 Google Cloud 账号,则可能会向该账号收取费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
- “打开 Google Cloud 控制台”按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在“实验详细信息”窗格中找到“用户名”。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在“实验详细信息”窗格中找到“密码”。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。
注意:在本实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于这是临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需访问 Google Cloud 产品和服务,请点击导航菜单,或在搜索字段中输入服务或产品的名称。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
-
点击 Google Cloud 控制台顶部的激活 Cloud Shell  。
。
-
在弹出的窗口中执行以下操作:
- 继续完成 Cloud Shell 信息窗口中的设置。
- 授权 Cloud Shell 使用您的凭据进行 Google Cloud API 调用。
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID 。输出内容中有一行说明了此会话的 Project_ID:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
gcloud auth list
- 点击授权。
输出:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (可选)您可以通过此命令列出项目 ID:
gcloud config list project
输出:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注意:如需查看在 Google Cloud 中使用 gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
任务 1. 创建 API 密钥
在此任务中,您将生成 API 密钥来传入请求网址,为使用 curl 向 Vision API 发送请求做准备。
-
如需创建 API 密钥,请在 Cloud 控制台中依次点击导航菜单 > API 和服务 > 凭证。
-
点击创建凭证,然后选择 API 密钥。
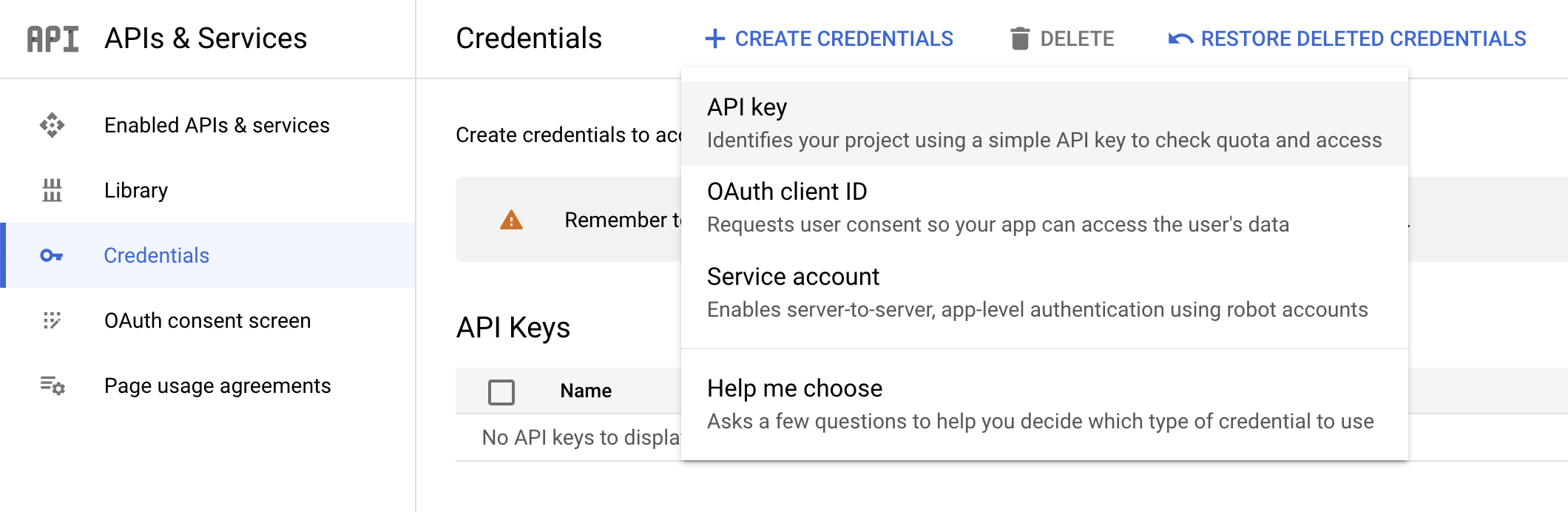
- 接下来,复制您刚刚生成的密钥,然后点击关闭。
点击检查我的进度,以检查您的实验进度。
创建 API 密钥
接下来,将密钥保存为一个环境变量,这样就不必在每个请求中都插入该 API 密钥的值。
- 更新以下命令,将占位符文本替换为您复制的 API 密钥,然后在 Cloud Shell 中运行该命令,将该值设置为环境变量:
export API_KEY=<YOUR_API_KEY>
任务 2. 将图片上传到 Cloud Storage 存储桶
可以通过两种方式将图片发送到 Cloud Vision API 进行图片检测:向该 API 发送 base64 编码的图片字符串,或向其传递 Cloud Storage 中存储的文件的网址。
本实验使用传递 Cloud Storage 网址这一方法。第一步是创建 Cloud Storage 存储桶来存储图片。
-
在导航菜单中,依次选择 Cloud Storage > 存储桶。在存储桶旁边,点击创建。
-
为您的存储桶指定唯一的名称:-bucket。
-
为存储桶命名后,点击选择如何控制对对象的访问权限。
-
取消选中禁止公开访问此存储桶复选框,然后选中精细控制单选按钮。
存储桶的其他所有设置都可以保留默认设置。
- 点击创建。
将图片上传到存储桶
- 右键点击以下甜甜圈图片,然后选择图片另存为,将其保存到您的计算机中,命名为 donuts.png。

- 前往您刚刚创建的存储桶,依次点击上传 > 上传文件,然后选择 donuts.png,点击打开。
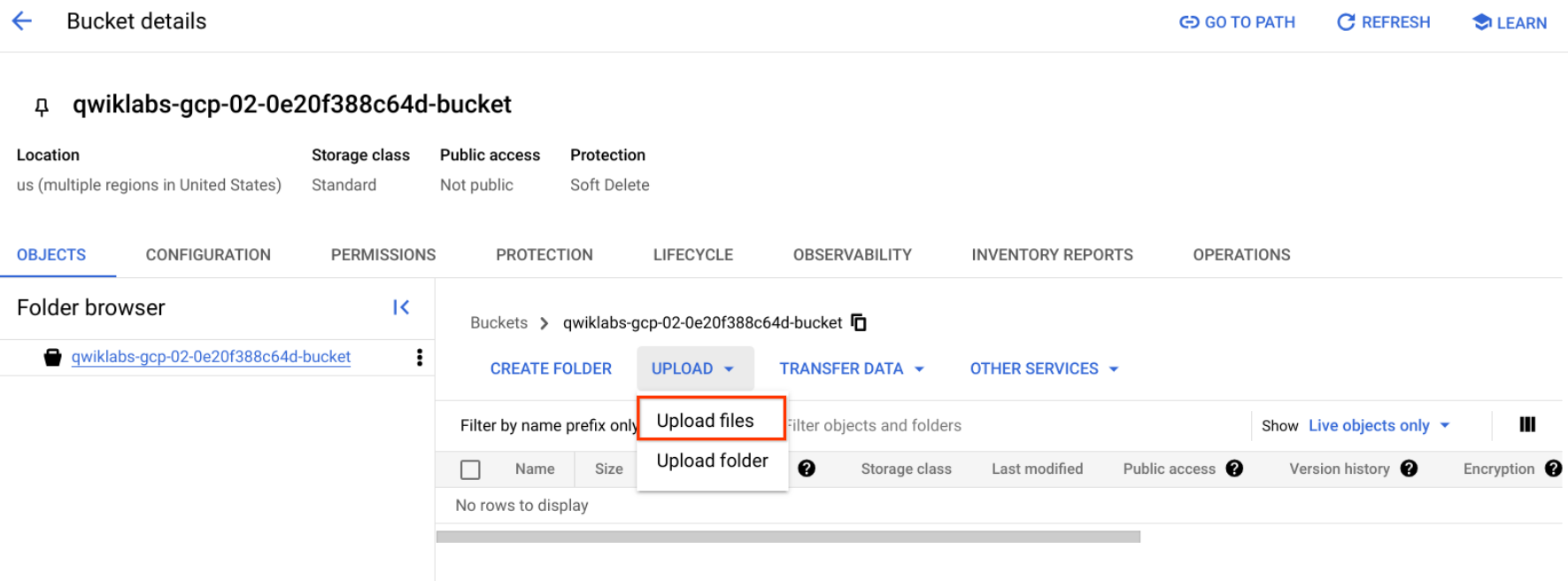
您应会在存储桶中看到相应文件。
现在,您需要公开此图片。
- 点击图片对应的三点状图,然后选择修改访问权限。
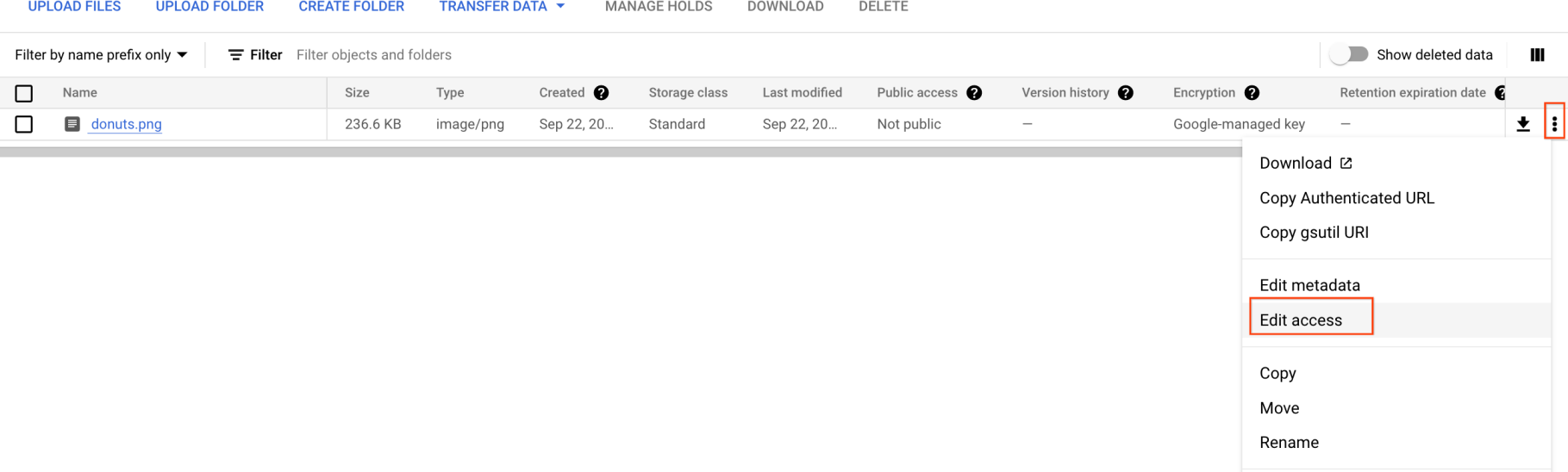
-
点击添加条目,然后输入以下内容:
-
实体:Public
-
名称:allUsers
-
访问权限:Reader
-
然后,点击保存。
将文件放入存储桶后,您就可以创建 Cloud Vision API 请求,向该 API 传递此甜甜圈图片的网址。
点击检查我的进度,以检查您的实验进度。
将图片上传到存储桶
任务 3. 创建请求
在 Cloud Shell 主目录中创建 request.json 文件。
- 使用 Cloud Shell 代码编辑器(通过点击 Cloud Shell 功能区中的铅笔图标)

或您首选的命令行编辑器(nano、vim 或 emacs),创建 request.json 文件。
- 将以下代码粘贴到
request.json 文件中:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}
-
保存文件。
在 Cloud Shell IDE 中启用 Gemini Code Assist
您可以在集成开发环境 (IDE)(例如 Cloud Shell)中使用 Gemini Code Assist,以获取代码方面的指导或解决代码问题。您需要先启用 Gemini Code Assist,然后才能使用该功能。
- 在 Cloud Shell 中,使用以下命令启用 Gemini for Google Cloud API:
gcloud services enable cloudaicompanion.googleapis.com
- 点击 Cloud Shell 工具栏上的打开编辑器。
注意:如需打开 Cloud Shell 编辑器,请点击 Cloud Shell 工具栏上的打开编辑器。您可以根据需要点击打开编辑器或打开终端,在 Cloud Shell 和代码编辑器之间切换。
-
点击屏幕底部状态栏中的 Cloud Code - 无项目。
-
按照说明对插件进行授权。如果系统未自动选择项目,请点击选择 Google Cloud 项目,然后选择 。
-
检查您的 Google Cloud 项目 () 是否显示在状态栏的 Cloud Code 状态消息中。
任务 4. 执行标签检测
您将首先探索 Cloud Vision API 的标签检测功能。您所用的方法会返回图片内容的标签(字词)列表。
- 在 Cloud Shell 终端中,运行以下
curl 命令来调用 Cloud Vision API,并将响应保存到 label_detection.json 文件:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} -o label_detection.json && cat label_detection.json
您的响应应如下所示。
输出:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "Powdered sugar",
"score": 0.9861496,
"topicality": 0.9861496
},
{
"mid": "/m/01wydv",
"description": "Beignet",
"score": 0.9565117,
"topicality": 0.9565117
},
{
"mid": "/m/02wbm",
"description": "Food",
"score": 0.9424965,
"topicality": 0.9424965
},
{
"mid": "/m/0hnyx",
"description": "Pastry",
"score": 0.8173416,
"topicality": 0.8173416
},
{
"mid": "/m/02q08p0",
"description": "Dish",
"score": 0.8076026,
"topicality": 0.8076026
},
{
"mid": "/m/01ykh",
"description": "Cuisine",
"score": 0.79036003,
"topicality": 0.79036003
},
{
"mid": "/m/03nsjgy",
"description": "Kourabiedes",
"score": 0.77726763,
"topicality": 0.77726763
},
{
"mid": "/m/06gd3r",
"description": "Angel wings",
"score": 0.73792106,
"topicality": 0.73792106
},
{
"mid": "/m/06x4c",
"description": "Sugar",
"score": 0.71921736,
"topicality": 0.71921736
},
{
"mid": "/m/01zl9v",
"description": "Zeppole",
"score": 0.7111677,
"topicality": 0.7111677
}
]
}
]
}
该 API 能够识别出这些甜甜圈的具体类型:糖粉甜甜圈。不错!对于 Vision API 找到的每个标签,它都会返回:
-
description:物品名称。
-
score:一个介于 0 到 1 之间的数值,表示该 API 对描述与图片内容匹配的置信度。
-
mid 值:与物品在 Google 知识图谱中的 mid 相对应。在调用 Knowledge Graph API 时,您可以使用 mid 来获取有关相应物品的更多信息。
- 在 Cloud Shell 编辑器中,找到
label_detection.json。此操作会启用 Gemini Code Assist,启用后,编辑器右上角会显示  图标。
图标。
为了在最大程度减少上下文切换的同时提高效率,Gemini Code Assist 直接在代码编辑器中提供依托 AI 技术的智能操作。在本部分中,您决定让 Gemini Code Assist 帮忙向团队成员解释 Cloud Vision API 响应。
-
点击 Gemini Code Assist:智能操作 图标,然后选择 Explain this(解释此内容)。
-
Gemini Code Assist 会打开一个聊天窗格,其中预填充了 Explain this 提示。在 Code Assist 聊天窗格的内嵌文本框中,将预填充的提示替换为以下内容,然后点击发送:
You are a Machine Learning Engineer at Cymbal AI. A new team member needs help understanding this Cloud Vision API response. Explain the label_detection.json file in detail. Break down its key components and their function within the JSON code.
For the suggested improvements, don't make any changes to the file's content.
label_detection.json 代码中 Cloud Vision API 响应的详细说明会显示在 Gemini Code Assist 对话中。
任务 5. 执行 Web 检测
除了获取图片内容的标签外,Cloud Vision API 还可以搜索互联网,查找有关图片的更多详细信息。通过该 API 的 WebDetection 方法,您可以获得许多有趣的数据:
- 在您的图片中发现的实体列表,根据包含类似图片的网页上的内容生成。
- 在网络上找到的完全匹配和部分匹配图片的网址,以及这些页面的网址。
- 类似图片的网址,就像执行以图搜图一样。
如需试用 Web 检测,请使用同一张贝涅饼的图片,并更改 request.json 文件中的一行内容(也可以大胆尝试,使用完全不同的图片)。
-
在 Cloud Shell 编辑器中的同一目录下,找到 request.json 并将其打开。
-
点击工具栏上的 Gemini Code Assist:智能操作 图标。
除了提供详细的代码说明外,您还可以使用 Gemini Code Assist 的 AI 赋能功能,直接在代码编辑器中更改代码。在这里,您决定让 Gemini Code Assist 帮助修改 request.json 文件的内容。
- 修改
request.json 文件,方法是将以下提示粘贴到工具栏中打开的 Gemini Code Assist 内嵌文本字段中。
In the request.json file, update the features list, change type from LABEL_DETECTION to WEB_DETECTION.
-
如需提示 Gemini Code Assist 按要求修改代码,请按 Enter 键。
-
在 Gemini Diff 视图中看到提示时,点击应用所有更改。
request.json 文件的内容现在应如下所示。
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}
- 在 Cloud Shell 终端中,运行以下
curl 命令来调用 Cloud Vision API:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- 深入了解响应,首先是
webEntities。以下是此图片返回的一些实体:
{
"responses": [
{
"webDetection": {
"webEntities": [
{
"entityId": "/m/0z5n",
"score": 0.8868,
"description": "Application programming interface"
},
{
"entityId": "/m/07kg1sq",
"score": 0.3139,
"description": "Encapsulation"
},
{
"entityId": "/m/0105pbj4",
"score": 0.2713,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/01hyh_",
"score": 0.2594,
"description": "Machine learning"
},
...
]
这张图片曾在许多关于 Cloud ML API 的演示文稿中使用过,因此,该 API 找到了“Machine learning”和“Google Cloud Platform”这两个实体。
如果您检查 fullMatchingImages、partialMatchingImages 和 pagesWithMatchingImages 下的网址,会发现其中许多网址都指向本实验网站(自我参照!)。
假设您想查找贝涅饼的其他图片,但并非完全相同的图片。这时,API 响应中的 visuallySimilarImages 部分就派上用场了。以下是它找到的一些视觉效果类似的图片:
"visuallySimilarImages": [
{
"url": "https://media.istockphoto.com/photos/cafe-du-monde-picture-id1063530570?k=6&m=1063530570&s=612x612&w=0&h=b74EYAjlfxMw8G-G_6BW-6ltP9Y2UFQ3TjZopN-pigI="
},
{
"url": "https://s3-media2.fl.yelpcdn.com/bphoto/oid0KchdCqlSqZzpznCEoA/o.jpg"
},
{
"url": "https://s3-media1.fl.yelpcdn.com/bphoto/mgAhrlLFvXe0IkT5UMOUlw/348s.jpg"
},
...
]
您可以访问这些网址查看类似图片:



现在,您可能想吃块糖粉贝涅饼了(抱歉)!这与在 Google 图片中按图片搜索类似。
有了 Cloud Vision,您可以通过简单易用的 REST API 使用此功能,并将其集成到您的应用中。
任务 6. 执行人脸检测
接下来,我们来探索 Vision API 的人脸检测方法。
人脸检测方法会返回在图片中找到的人脸数据,包括人脸的情绪以及其在图片中的位置。
上传新图片
如需使用此方法,您需要将一张包含人脸的新图片上传到 Cloud Storage 存储桶。
- 右键点击以下图片,然后选择图片另存为,将其保存到您的计算机中,命名为 selfie.png。

- 现在,按照与之前相同的方式将图片上传到 Cloud Storage 存储桶,并将其设为公开。
点击检查我的进度,以检查您的实验进度。
将用于人脸检测的图片上传到存储桶
更新请求文件
-
在 Cloud Shell 编辑器中的同一目录下,找到 request.json。
-
点击工具栏上的 Gemini Code Assist:智能操作 图标。
-
帮助更新 request.json 文件,方法是将以下提示粘贴到工具栏中打开的 Gemini Code Assist 内嵌文本字段中。
Update the JSON file request.json to achieve three specific changes:
* Update the gcsImageUri value from donuts.png to selfie.png.
* Replace the existing features array with two new feature types: FACE_DETECTION and LANDMARK_DETECTION.
* Don't want maxResults result.
-
如需提示 Gemini Code Assist 按要求修改代码,请按 Enter 键。
-
在 Gemini Diff 视图中看到提示时,点击应用所有更改。
更新后的请求文件应如下所示:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}
调用 Vision API 并解析响应
- 在 Cloud Shell 终端中,运行以下
curl 命令来调用 Cloud Vision API:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- 查看响应中的
faceAnnotations 对象。请注意,该 API 会为图片中找到的每张人脸返回一个对象,在这里一共是三个对象。以下是响应的精简版本:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "LIKELY",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}
-
boundingPoly 提供图片中人脸周围的 x、y 坐标。
-
fdBoundingPoly 是一个比 boundingPoly 更小的框,专注于人脸的皮肤部分。
-
landmarks 是每个人脸特征的对象数组,其中有些可能连您都不知道。这会告诉我们重要部位的类型,以及该特征的 3D 位置(x、y、z 坐标),其中 z 坐标代表深度。其余值则提供了更详细的人脸信息,包括人带有喜悦、悲伤、愤怒和惊奇等情绪的可能性。
您看到的这段响应描述的是图片中站得最靠后的那个人,他做着鬼脸,这解释了 joyLikelihood 为 LIKELY 的原因。
任务 7. 执行地标注解
地标检测可以识别常见的(和模糊的)地标。它会返回地标的名称、经纬度坐标以及图片中识别出该地标的位置。
上传新图片
如需使用此方法,您需要将新图片上传到 Cloud Storage 存储桶。
- 右键点击以下图片,然后选择图片另存为,将其保存到您的计算机中,命名为 city.png。

引用来源:俄罗斯莫斯科圣巴西尔大教堂(2019 年 12 月 19 日),拍摄者:Adrien Wodey,作品发布于免费媒体资源库 Unsplash。检索自 https://unsplash.com/photos/multicolored-dome-temple-yjyWCNx0J1U。此文件已获得 Unsplash 许可授权。
- 现在,按照与之前相同的方式将图片上传到 Cloud Storage 存储桶,并将其设为公开。
点击检查我的进度,以检查您的实验进度。
将用于地标注解的图片上传到存储桶
更新请求文件
- 接下来,使用以下内容更新
request.json 文件(其中包含新图片的网址),并使用地标检测功能:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/city.png"
}
},
"features": [
{
"type": "LANDMARK_DETECTION",
"maxResults": 10
}
]
}
]
}
调用 Vision API 并解析响应
- 在 Cloud Shell 终端中,运行以下
curl 命令来调用 Cloud Vision API:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- 查看响应中的
landmarkAnnotations 部分:
"landmarkAnnotations": [
{
"mid": "/m/0hm_7",
"description": "Red Square",
"score": 0.8557956,
"boundingPoly": {
"vertices": [
{},
{
"x": 503
},
{
"x": 503,
"y": 650
},
{
"y": 650
}
]
},
"locations": [
{
"latLng": {
"latitude": 55.753930299999993,
"longitude": 37.620794999999994
}
...
Cloud Vision API 能够识别出照片的拍摄地点,并提供该地点的地图坐标(俄罗斯莫斯科红场圣巴西尔大教堂)。
此响应中的值应与上面的 labelAnnotations 响应类似:
- 地标的
mid
- 名称 (
description)
- 置信度
score
-
boundingPoly 显示了图片中识别出该地标的区域。
-
locations 键为我们提供了图片的纬度和经度坐标。
任务 8. 执行对象本地化
Vision API 可以使用对象本地化功能检测并提取图片中的多个对象。对象本地化功能可识别图片中的多个对象,并为图片中的每个对象提供一个 LocalizedObjectAnnotation。每个 LocalizedObjectAnnotation 都会识别对象相关信息、对象位置,以及包含该对象的图片区域的矩形边界。
对象本地化功能可识别图片中显眼和不太显眼的对象。
对象信息仅以英文形式返回。Cloud Translation 可以将英文标签翻译成各种其他语言。
如需使用此方法,您需要使用互联网上的现有图片并更新 request.json 文件。
更新请求文件
- 使用以下内容更新
request.json 文件(其中包含新图片的网址),并使用对象本地化功能。
{
"requests": [
{
"image": {
"source": {
"imageUri": "https://cloud.google.com/vision/docs/images/bicycle_example.png"
}
},
"features": [
{
"maxResults": 10,
"type": "OBJECT_LOCALIZATION"
}
]
}
]
}
调用 Vision API 并解析响应
- 在 Cloud Shell 终端中,运行以下
curl 命令来调用 Cloud Vision API:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- 接下来,查看响应的
localizedObjectAnnotations 部分:
{
"responses": [
{
"localizedObjectAnnotations": [
{
"mid": "/m/01bqk0",
"name": "Bicycle wheel",
"score": 0.89648587,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.32076266,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.97331065
},
{
"x": 0.32076266,
"y": 0.97331065
}
]
}
},
{
"mid": "/m/0199g",
"name": "Bicycle",
"score": 0.886761,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.312,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.9705882
},
{
"x": 0.312,
"y": 0.9705882
}
]
}
},
...
可以看到,Vision API 能够识别出这张图片包含一辆自行车和一个自行车轮。此响应中的值应与上面的 labelAnnotations 响应类似:对象的 mid、名称 (name)、置信度 score,以及 boundingPoly(显示了图片中识别出该对象的区域)。
此外,boundingPoly 还包含一个 normalizedVertices 键,用于提供图片中对象的坐标。这些坐标经过归一化处理,范围为 0 到 1,其中 0 代表图片左上角,1 代表图片右下角。
太棒了!您已成功使用 Vision API 分析图片并提取有关其中对象的信息。
任务 9. 探索 Vision API 的其他方法
您已了解 Vision API 的标签检测、人脸检测、地标检测和对象本地化方法,但还有三种方法尚未探索。请深入阅读方法:images.annotate 文档,了解其他三种方法:
-
徽标检测:识别图片中的常见徽标及其在图片中的位置。
-
安全搜索检测:确定图片是否包含露骨内容。这对任何包含用户生成内容的应用都很有用。您可以根据四个因素过滤图片:成人、医疗、暴力和仿冒内容。
-
文本检测:通过运行 OCR 来从图片中提取文本。此方法甚至可以识别图片中的文本所用的语言。
恭喜!
您已了解如何使用 Vision API 分析图片。在本实验中,您向该 API 传递了不同图片的 Cloud Storage 网址,该 API 返回了在图片中找到的标签、人脸、地标和对象。您还可以向该 API 传递图片的 base64 编码字符串;如果您想分析存储在数据库或内存中的图片,这会非常有用。
后续步骤/了解详情
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
本手册的最后更新时间:2025 年 10 月 14 日
本实验的最后测试时间:2025 年 10 月 14 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。






