GSP037

Übersicht
Die Cloud Vision API ist ein cloudbasierter Dienst, mit dem Sie Bilder analysieren und Informationen extrahieren können. Damit lassen sich Objekte, Gesichter und Text in Bildern erkennen. Mit der Cloud Vision API erhalten Sie Informationen über den Inhalt eines Bildes, indem Sie über eine nutzerfreundliche REST API leistungsstarke Modelle für maschinelles Lernen verwenden.
In diesem Lab erfahren Sie, wie Sie Bilder an die Cloud Vision API senden, damit sie Objekte, Gesichter und Sehenswürdigkeiten erkennt.
Ziele
Aufgaben in diesem Lab:
- Eine Cloud Vision API-Anfrage erstellen und die API mit
curl aufrufen
- Methoden zur Erkennung von Labels, Gesichtern und Sehenswürdigkeiten der API verwenden
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Dialogfeld geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich „Details zum Lab“ mit diesen Informationen:
- Schaltfläche „Google Cloud Console öffnen“
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite „Anmelden“ geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich „Details zum Lab“.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie auf Google Cloud-Produkte und ‑Dienste zugreifen möchten, klicken Sie auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
-
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren  .
.
-
Klicken Sie sich durch die folgenden Fenster:
- Fahren Sie mit dem Informationsfenster zu Cloud Shell fort.
- Autorisieren Sie Cloud Shell, Ihre Anmeldedaten für Google Cloud API-Aufrufe zu verwenden.
Wenn eine Verbindung besteht, sind Sie bereits authentifiziert und das Projekt ist auf Project_ID, eingestellt. Die Ausgabe enthält eine Zeile, in der die Project_ID für diese Sitzung angegeben ist:
Ihr Cloud-Projekt in dieser Sitzung ist festgelegt als {{{project_0.project_id | "PROJECT_ID"}}}
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
- Klicken Sie auf Autorisieren.
Ausgabe:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Um das aktive Konto festzulegen, führen Sie diesen Befehl aus:
$ gcloud config set account `ACCOUNT`
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Hinweis: Die vollständige Dokumentation für gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Aufgabe 1: API-Schlüssel erstellen
In dieser Aufgabe generieren Sie einen API-Schlüssel, um ihn in der Anfrage-URL zu übergeben. Dies ist eine Vorbereitung darauf, mit curl eine Anfrage an die Vision API zu senden.
-
Klicken Sie zum Erstellen eines API-Schlüssels im Navigationsmenü der Cloud Console auf APIs und Dienste > Anmeldedaten.
-
Klicken Sie auf Anmeldedaten erstellen und wählen Sie den API-Schlüssel aus.
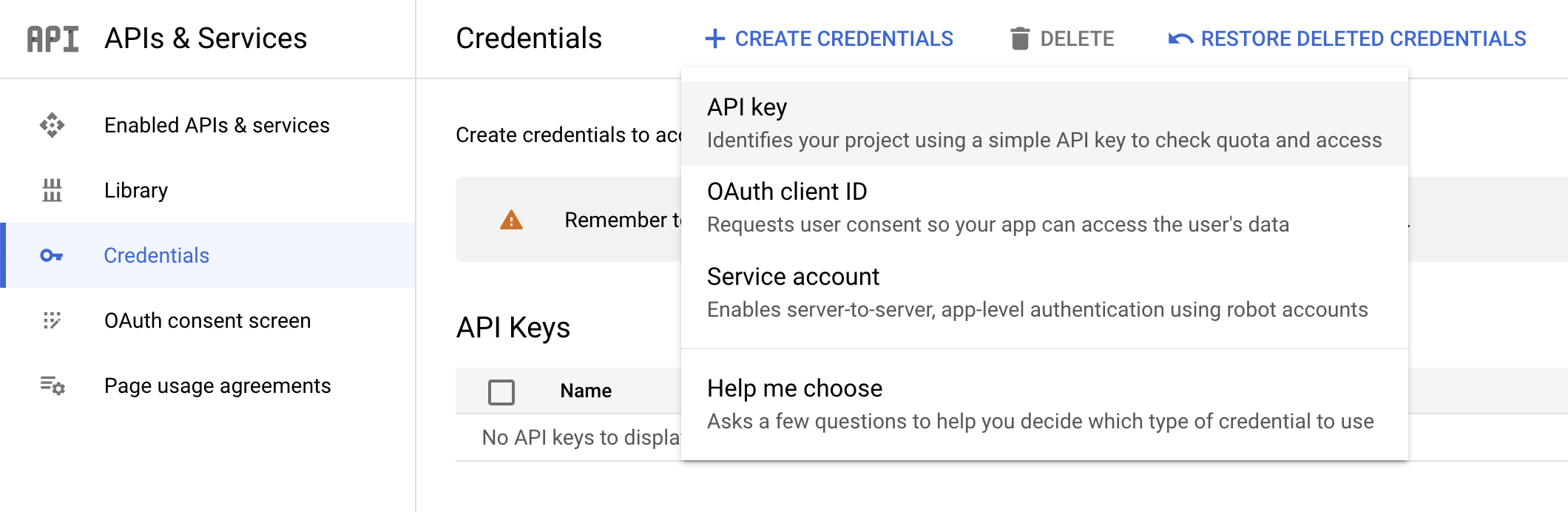
- Kopieren Sie dann den gerade erstellten Schlüssel und klicken Sie auf Schließen.
Klicken Sie unten auf Fortschritt prüfen.
API-Schlüssel erstellen
Speichern Sie den API-Schlüssel in einer Umgebungsvariablen, damit Sie dessen Wert nicht in jede Anfrage einfügen müssen.
- Aktualisieren Sie den folgenden Befehl, indem Sie den Platzhaltertext durch den kopierten API-Schlüssel ersetzen. Führen Sie dann den Befehl in der Cloud Shell aus, um den Wert als Umgebungsvariable festzulegen:
export API_KEY=<YOUR_API_KEY>
Aufgabe 2: Bild in einen Cloud Storage-Bucket hochladen
Es gibt zwei Möglichkeiten, ein Bild zur Bilderkennung an die Cloud Vision API zu senden: Entweder Sie senden der API einen Base64-codierten Bildstring oder Sie übergeben die URL einer in Cloud Storage gespeicherten Datei.
In diesem Lab wird der Cloud Storage-URL-Ansatz verwendet. Erstellen Sie zuerst einen Cloud Storage-Bucket, in dem die Bilder gespeichert werden sollen.
-
Wählen Sie im Navigationsmenü die Option Cloud Storage > Buckets aus. Klicken Sie neben Buckets auf Erstellen.
-
Geben Sie Ihrem Bucket einen eindeutigen Namen: -bucket.
-
Klicken Sie anschließend auf Legen Sie fest, wie der Zugriff auf Objekte gesteuert wird.
-
Deaktivieren Sie das Kästchen Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen und wählen Sie das Optionsfeld Detailgenau aus.
Alle anderen Einstellungen für den Bucket können bei den Standardwerten belassen werden.
- Klicken Sie auf Erstellen.
Bild in den Bucket hochladen
- Klicken Sie mit der rechten Maustaste auf das folgende Donutbild. Anschließend klicken Sie auf Bild speichern unter und speichern Sie es unter dem Namen donuts.png auf Ihrem Computer.

- Gehen Sie zum eben erstellten Bucket und klicken Sie auf Hochladen > Dateien hochladen. Wählen Sie dann donuts.png aus und klicken Sie auf Öffnen.
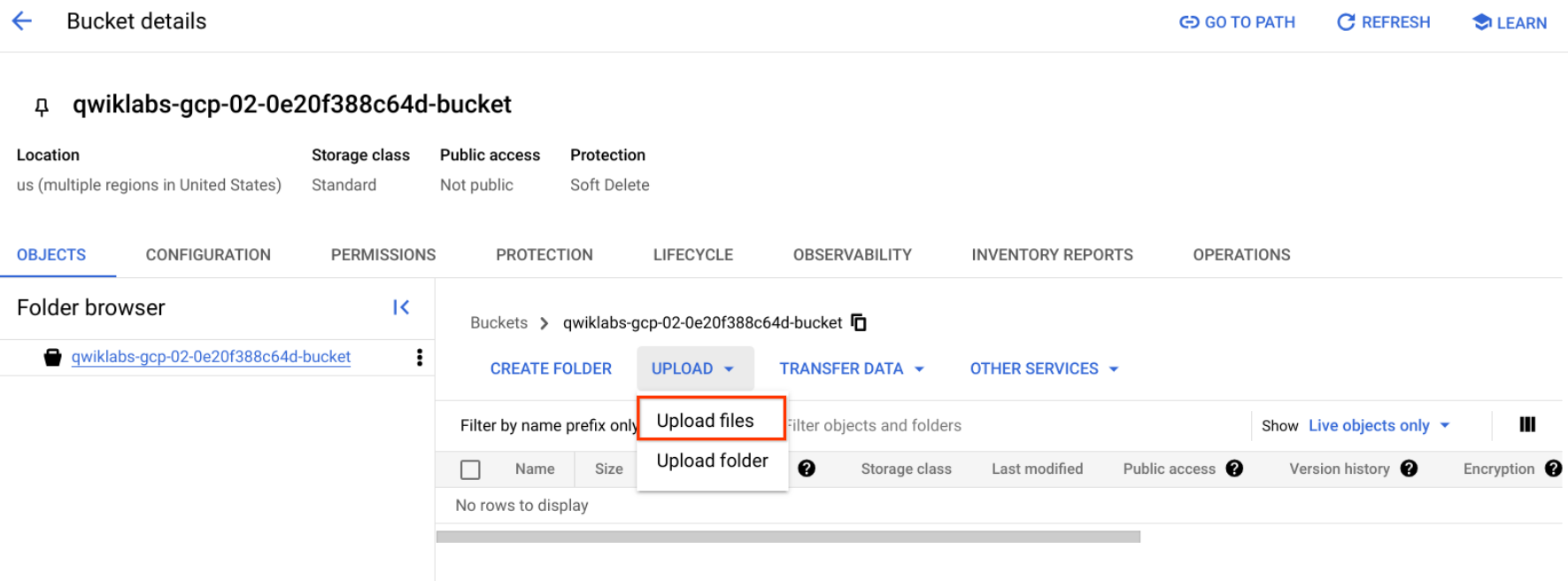
Die Datei sollte im Bucket angezeigt werden.
Jetzt müssen Sie dieses Bild öffentlich verfügbar machen.
- Klicken Sie auf die drei Punkte für die Bilddatei und wählen Sie Zugriff bearbeiten aus.
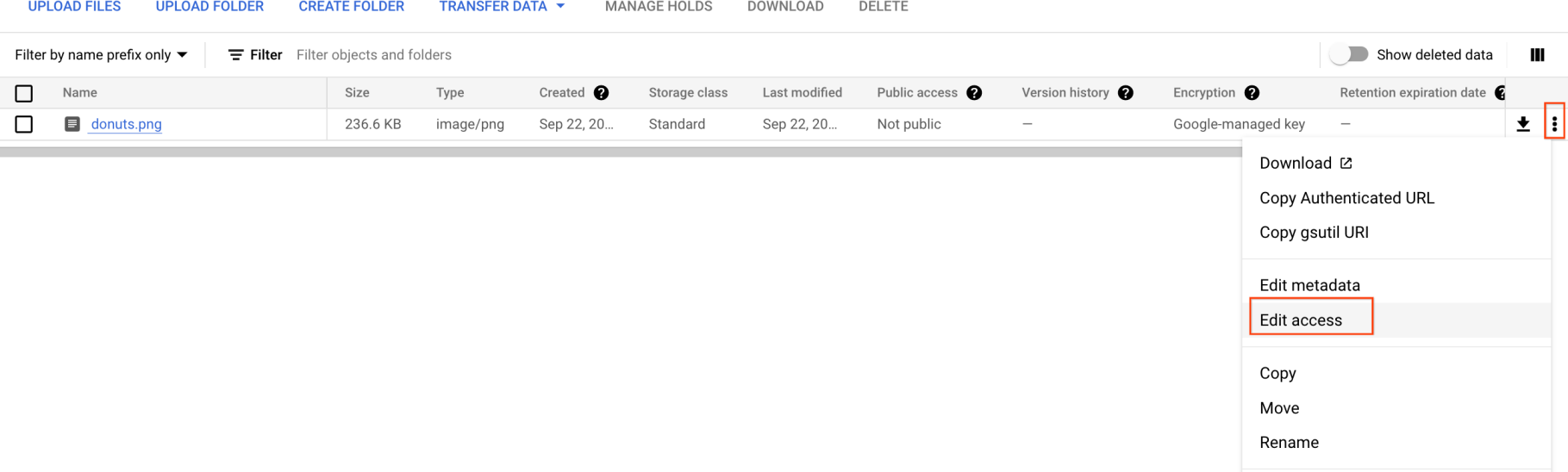
-
Klicken Sie auf Eintrag hinzufügen und geben Sie Folgendes ein:
-
Entität: Öffentlich
-
Name: allUsers
-
Zugriff: Leser
-
Klicken Sie anschließend auf Speichern.
Nachdem die Datei in den Bucket hochgeladen wurde, können Sie eine Cloud Vision API-Anfrage erstellen und die URL dieses Donutbildes übergeben.
Klicken Sie unten auf Fortschritt prüfen.
Bild in den Bucket hochladen
Aufgabe 3: Anfrage erstellen
Erstellen Sie eine Datei request.json im Cloud Shell-Basisverzeichnis.
- Verwenden Sie dazu den Code-Editor der Cloud Shell (durch Klicken auf das Stiftsymbol in der Cloud Shell-Seitenleiste)

oder Ihren bevorzugten Befehlszeileneditor (nano, vim oder emacs)
- Fügen Sie den folgenden Code in die Datei
request.json ein:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}
-
Speichern Sie die Datei.
Gemini Code Assist in der Cloud Shell-IDE aktivieren
Sie können Gemini Code Assist in einer integrierten Entwicklungsumgebung (Integrated Development Environment, IDE) wie Cloud Shell verwenden, um Unterstützung beim Programmieren zu erhalten oder Probleme mit Ihrem Code zu lösen. Bevor Sie Gemini Code Assist verwenden können, müssen Sie das Tool aktivieren.
- Aktivieren Sie in Cloud Shell die Gemini for Google Cloud API mit dem folgenden Befehl:
gcloud services enable cloudaicompanion.googleapis.com
- Klicken Sie in der Cloud Shell-Symbolleiste auf Editor öffnen.
Hinweis: Klicken Sie zum Öffnen des Cloud Shell-Editors in der Cloud Shell-Symbolleiste auf Editor öffnen. Sie können zwischen Cloud Shell und dem Code-Editor wechseln. Klicken Sie dazu entsprechend auf Editor öffnen oder Terminal öffnen.
-
Klicken Sie in der Statusleiste unten auf dem Bildschirm auf Cloud Code – kein Projekt.
-
Autorisieren Sie das Plug-in wie beschrieben. Wenn kein Projekt automatisch ausgewählt wurde, klicken Sie auf Google Cloud-Projekt auswählen und wählen Sie aus.
-
Prüfen Sie, ob Ihr Google Cloud-Projekt () in der Cloud Code-Statusmeldung in der Statusleiste angezeigt wird.
Aufgabe 4: Labelerkennung durchführen
Als erste Cloud Vision API-Funktion probieren Sie die Labelerkennung aus. Die verwendete Methode gibt eine Liste mit Labels (Wörtern) zurück, die den Bildinhalt beschreiben.
- Führen Sie im Cloud Shell-Terminal den folgenden
curl-Befehl aus, um die Cloud Vision API aufzurufen und die Antwort in der Datei label_detection.json zu speichern:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} -o label_detection.json && cat label_detection.json
Die Antwort sollte in etwa so aussehen:
Ausgabe:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "Powdered sugar",
"score": 0.9861496,
"topicality": 0.9861496
},
{
"mid": "/m/01wydv",
"description": "Beignet",
"score": 0.9565117,
"topicality": 0.9565117
},
{
"mid": "/m/02wbm",
"description": "Food",
"score": 0.9424965,
"topicality": 0.9424965
},
{
"mid": "/m/0hnyx",
"description": "Pastry",
"score": 0.8173416,
"topicality": 0.8173416
},
{
"mid": "/m/02q08p0",
"description": "Dish",
"score": 0.8076026,
"topicality": 0.8076026
},
{
"mid": "/m/01ykh",
"description": "Cuisine",
"score": 0.79036003,
"topicality": 0.79036003
},
{
"mid": "/m/03nsjgy",
"description": "Kourabiedes",
"score": 0.77726763,
"topicality": 0.77726763
},
{
"mid": "/m/06gd3r",
"description": "Angel wings",
"score": 0.73792106,
"topicality": 0.73792106
},
{
"mid": "/m/06x4c",
"description": "Sugar",
"score": 0.71921736,
"topicality": 0.71921736
},
{
"mid": "/m/01zl9v",
"description": "Zeppole",
"score": 0.7111677,
"topicality": 0.7111677
}
]
}
]
}
Die API konnte sogar erkennen, dass es sich um eine spezielle Art von Donuts handelt, nämlich mit Puderzucker. Nicht schlecht, oder? Für jedes Label, das die Vision API gefunden hat, werden folgende Informationen zurückgegeben:
-
description: Name des Objekts
-
score: eine Zahl zwischen 0 und 1, die angibt, wie genau die Beschreibung mit dem Bild übereinstimmt
-
mid: ein Wert, der dem mid-Wert des Objekts im Google Knowledge Graph zugeordnet ist. Sie können den mid-Wert verwenden, wenn Sie die Knowledge Graph API aufrufen, um weitere Informationen zum Objekt abzurufen.
- Öffnen Sie im Cloud Shell-Editor die Datei
label_detection.json. Dadurch wird Gemini Code Assist aktiviert. Dies lässt sich am Symbol  rechts oben im Editor ablesen.
rechts oben im Editor ablesen.
Damit Sie produktiver arbeiten können und weniger Kontextwechsel erforderlich sind, bietet Gemini Code Assist KI-basierte intelligente Aktionen direkt in Ihrem Code-Editor. In diesem Abschnitt bitten Sie Gemini Code Assist, die Antwort der Cloud Vision API einem Teammitglied zu erklären.
-
Klicken Sie auf das Gemini Code Assist: Intelligente Aktionen-Symbol und wählen Sie Erkläre mir das aus.
-
Gemini Code Assist öffnet ein Chatfenster mit dem vorausgefüllten Prompt Erkläre mir das. Ersetzen Sie im Inline-Textfeld des Code Assist-Chats den vorausgefüllten Prompt durch Folgendes und klicken Sie auf Senden:
You are a Machine Learning Engineer at Cymbal AI. A new team member needs help understanding this Cloud Vision API response. Explain the label_detection.json file in detail. Break down its key components and their function within the JSON code.
For the suggested improvements, don't make any changes to the file's content.
Detaillierte Erklärungen zur Cloud Vision API-Antwort im label_detection.json-Code werden im Gemini Code Assist-Chat angezeigt.
Aufgabe 5: Weberkennung durchführen
Mit der Cloud Vision API können Sie nicht nur Labels zu einem Bild abrufen, sondern auch im Internet nach weiteren Details zum Bild suchen. Über die WebDetection-Methode der API erhalten Sie viele interessante Daten:
- Eine Liste der im Bild gefundenen Entitäten, basierend auf Inhalten von Seiten mit ähnlichen Bildern
- URLs von vollständig und teilweise übereinstimmenden Bildern im Web sowie die URLs dieser Seiten
- URLs ähnlicher Bilder (wie bei einer umgekehrten Bildersuche)
Zum Ausprobieren der Weberkennung können Sie wieder das Bild mit den Beignets verwenden. Dazu müssen Sie eine Zeile in der Datei request.json ändern. Sie können aber auch ein ganz anderes Bild nehmen.
-
Öffnen Sie im Cloud Shell-Editor im selben Verzeichnis die Datei request.json.
-
Klicken Sie in der Symbolleiste auf das Symbol Gemini Code Assist: Intelligente Aktionen .
Gemini Code Assist kann nicht nur detaillierte Erklärungen zu Code liefern, sondern auch KI-basierte Funktionen nutzen, um Änderungen direkt im Code-Editor vorzunehmen. In diesem Fall lassen Sie sich von Gemini Code Assist beim Bearbeiten des Inhalts der Datei request.json unterstützen.
- Fügen Sie den folgenden Prompt in das Inline-Textfeld von Gemini Code Assist ein, das über die Symbolleiste geöffnet wird, um die Datei
request.json zu bearbeiten.
In the request.json file, update the features list, change type from LABEL_DETECTION to WEB_DETECTION.
-
Drücken Sie die Eingabetaste, damit Gemini Code Assist den Code entsprechend ändert.
-
Klicken Sie in der Ansicht „Unterschied“ von Gemini auf Alle Änderungen übernehmen, wenn Sie dazu aufgefordert werden.
Der Inhalt der Datei request.json sollte jetzt in etwa so aussehen:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}
- Führen Sie im Cloud Shell-Terminal den folgenden
curl-Befehl aus, um die Cloud Vision API aufzurufen:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Sehen Sie sich in der Antwort zuerst den Abschnitt
webEntities an. Hier sind einige der Entitäten, die dieses Bild zurückgegeben hat:
{
"responses": [
{
"webDetection": {
"webEntities": [
{
"entityId": "/m/0z5n",
"score": 0.8868,
"description": "Application programming interface"
},
{
"entityId": "/m/07kg1sq",
"score": 0.3139,
"description": "Encapsulation"
},
{
"entityId": "/m/0105pbj4",
"score": 0.2713,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/01hyh_",
"score": 0.2594,
"description": "Machine learning"
},
...
]
Dieses Bild wurde in vielen Präsentationen zu Cloud ML APIs verwendet. Deshalb hat die API die Entitäten „Machine learning“ und „Google Cloud Platform“ gefunden.
Außerdem zeigen viele der URLs unter fullMatchingImages, partialMatchingImages und pagesWithMatchingImages auf diese Lab-Website (gute Metadaten).
Angenommen, Sie suchen andere Bilder mit Beignets, aber nicht genau dieselben. Hierfür bietet sich der Abschnitt visuallySimilarImages der API-Antwort an. Hier sind einige der visuell ähnlichen Bilder, die gefunden wurden:
"visuallySimilarImages": [
{
"url": "https://media.istockphoto.com/photos/cafe-du-monde-picture-id1063530570?k=6&m=1063530570&s=612x612&w=0&h=b74EYAjlfxMw8G-G_6BW-6ltP9Y2UFQ3TjZopN-pigI="
},
{
"url": "https://s3-media2.fl.yelpcdn.com/bphoto/oid0KchdCqlSqZzpznCEoA/o.jpg"
},
{
"url": "https://s3-media1.fl.yelpcdn.com/bphoto/mgAhrlLFvXe0IkT5UMOUlw/348s.jpg"
},
...
]
Sie können diese URLs aufrufen, um sich die ähnlichen Bilder anzusehen:



Jetzt haben Sie vermutlich Appetit auf einen Beignet bekommen. Diese Suche funktioniert ähnlich wie die Bildersuche in Google Bilder.
Mit Cloud Vision können Sie über eine einfach zu verwendende REST API auf diese Funktion zugreifen und sie in Ihre Anwendungen einbinden.
Aufgabe 6: Gesichtserkennung durchführen
Als Nächstes lernen Sie die Methoden zur Gesichtserkennung der Vision API kennen.
Bei der Gesichtserkennung werden Daten zu in einem Bild gefundenen Gesichtern zurückgegeben, einschließlich der Emotionen in den Gesichtern und deren Position im Bild.
Neues Bild hochladen
Um diese Methode zu verwenden, laden Sie ein neues Bild mit Gesichtern in den Cloud Storage-Bucket hoch.
- Klicken Sie mit der rechten Maustaste auf das folgende Bild und anschließend auf Bild speichern unter. Speichern Sie es unter dem Namen selfie.png auf Ihrem Computer.

- Laden Sie es jetzt wie zuvor in Ihren Cloud Storage-Bucket hoch und machen Sie es öffentlich.
Klicken Sie unten auf Fortschritt prüfen.
Bild für die Gesichtserkennung in den Bucket hochladen
Anfragedatei aktualisieren
-
Öffnen Sie im Cloud Shell-Editor im selben Verzeichnis die Datei request.json.
-
Klicken Sie in der Symbolleiste auf das Symbol Gemini Code Assist: Intelligente Aktionen .
-
Fügen Sie den folgenden Prompt in das Inline-Textfeld von Gemini Code Assist ein, das über die Symbolleiste geöffnet wird, um Sie beim Aktualisieren der Datei request.json zu unterstützen.
Update the JSON file request.json to achieve three specific changes:
* Update the gcsImageUri value from donuts.png to selfie.png.
* Replace the existing features array with two new feature types: FACE_DETECTION and LANDMARK_DETECTION.
* Don't want maxResults result.
-
Drücken Sie die Eingabetaste, damit Gemini Code Assist den Code entsprechend ändert.
-
Klicken Sie in der Ansicht „Unterschied“ von Gemini auf Alle Änderungen übernehmen, wenn Sie dazu aufgefordert werden.
Die aktualisierte Anfragedatei sollte in etwa so aussehen:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}
Vision API aufrufen und die Antwort analysieren
- Führen Sie im Cloud Shell-Terminal den folgenden
curl-Befehl aus, um die Cloud Vision API aufzurufen:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Sehen Sie sich das Objekt
faceAnnotations in der Antwort an. Die API gibt ein Objekt für jedes im Bild gefundene Gesicht zurück – in diesem Fall drei. Hier ist ein Ausschnitt aus der Antwort:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "LIKELY",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}
-
boundingPoly: x,y-Koordinaten um das Gesicht im Bild
-
fdBoundingPoly: ein kleinerer Bereich als boundingPoly, der sich auf die Hautpartie des Gesichts beschränkt
-
landmarks: eine Reihe von Objekten für jedes Gesichtsmerkmal; von einigen haben Sie vielleicht noch gar nicht gehört. Hiermit wird der Typ des Orientierungspunktes zusammen mit der 3D-Position dieses Merkmals (x-, y-, z-Koordinaten) angegeben, wobei die z-Koordinate die Tiefe darstellt. Die übrigen Werte geben Ihnen weitere Details zum Gesicht, einschließlich der Wahrscheinlichkeit von Freude, Trauer, Ärger und Überraschung.
Die vorliegende Antwort bezieht sich auf die Person, die ganz hinten im Bild steht. Sie zieht eine Art Grimasse, deshalb steht bei joyLikelihood der Wert LIKELY.
Aufgabe 7: Annotation von Sehenswürdigkeiten durchführen
Bei der Erkennung von Sehenswürdigkeiten werden bekannte (und nicht deutlich erkennbare) Sehenswürdigkeiten identifiziert. Es werden der Name der Sehenswürdigkeit, deren Koordinaten (Breiten- und Längengrade) sowie der Ort zurückgegeben, an dem die Sehenswürdigkeit in einem Bild erkannt wurde.
Neues Bild hochladen
Dazu laden Sie ein neues Bild in den Cloud Storage-Bucket hoch.
- Klicken Sie mit der rechten Maustaste auf das folgende Bild. Anschließend klicken Sie auf Bild speichern unter und speichern es unter dem Namen city.png auf Ihrem Computer.

Quelle: Basilius-Kathedrale, Moskau, Russland (19. Dezember 2019) von Adrien Wodey auf Unsplash, der kostenlosen Mediensammlung. Abgerufen unter https://unsplash.com/photos/multicolored-dome-temple-yjyWCNx0J1U. Diese Datei ist unter der Unsplash-Lizenz lizenziert.
- Laden Sie es jetzt wie zuvor in Ihren Cloud Storage-Bucket hoch und machen Sie es öffentlich.
Klicken Sie unten auf Fortschritt prüfen.
Bild für die Annotation von Sehenswürdigkeiten in den Bucket hochladen
Anfragedatei aktualisieren
- Aktualisieren Sie nun die Datei
request.json. Fügen Sie dazu die URL des neuen Bildes ein und verwenden Sie die Erkennung von Sehenswürdigkeiten:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/city.png"
}
},
"features": [
{
"type": "LANDMARK_DETECTION",
"maxResults": 10
}
]
}
]
}
Vision API aufrufen und die Antwort analysieren
- Führen Sie im Cloud Shell-Terminal den folgenden
curl-Befehl aus, um die Cloud Vision API aufzurufen:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Sehen Sie sich den Abschnitt
landmarkAnnotations der Antwort an:
"landmarkAnnotations": [
{
"mid": "/m/0hm_7",
"description": "Red Square",
"score": 0.8557956,
"boundingPoly": {
"vertices": [
{},
{
"x": 503
},
{
"x": 503,
"y": 650
},
{
"y": 650
}
]
},
"locations": [
{
"latLng": {
"latitude": 55.753930299999993,
"longitude": 37.620794999999994
}
...
Die Cloud Vision API konnte erkennen, wo das Bild aufgenommen wurde, und lieferte die Kartenkoordinaten des Ortes (Basilius-Kathedrale am Roten Platz in Moskau, Russland).
Die Werte in dieser Antwort sollten in etwa so aussehen wie die in der Antwort labelAnnotations oben:
-
mid: mid-Wert der Sehenswürdigkeit
-
description: Name
-
score: Konfidenzwert
-
boundingPoly: Bereich im Bild, in dem die Sehenswürdigkeit erkannt wurde
-
locations: Koordinaten (Breiten- und Längengrade) des Bildes
Aufgabe 8: Objektlokalisierung durchführen
Mit der Objektlokalisierung der Vision API lassen sich mehrere Objekte in einem Bild erkennen und extrahieren. Die Objektlokalisierung kann in einem Bild mehrere Objekte identifizieren und eine LocalizedObjectAnnotation für jedes Objekt im Bild bereitstellen. Mit jeder LocalizedObjectAnnotation lassen sich Informationen über das Objekt, die Position des Objekts und die rechteckigen Grenzen für den Bereich des Bildes ermitteln, in dem sich das Objekt befindet.
Die Objektlokalisierung identifiziert sowohl wichtige als auch weniger auffällige Objekte in einem Bild.
Objektinformationen werden nur auf Englisch zurückgegeben. Mit Cloud Translation lassen sich englische Labels in verschiedene Sprachen übersetzen.
Bei dieser Methode verwenden Sie ein vorhandenes Bild aus dem Internet und aktualisieren die Datei request.json.
Anfragedatei aktualisieren
- Aktualisieren Sie nun die Datei
request.json. Fügen Sie dazu die URL des neuen Bildes ein und verwenden Sie die Objekterkennung.
{
"requests": [
{
"image": {
"source": {
"imageUri": "https://cloud.google.com/vision/docs/images/bicycle_example.png"
}
},
"features": [
{
"maxResults": 10,
"type": "OBJECT_LOCALIZATION"
}
]
}
]
}
Vision API aufrufen und die Antwort analysieren
- Führen Sie im Cloud Shell-Terminal den folgenden
curl-Befehl aus, um die Cloud Vision API aufzurufen:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Sehen Sie sich als Nächstes den Abschnitt
localizedObjectAnnotations der Antwort an:
{
"responses": [
{
"localizedObjectAnnotations": [
{
"mid": "/m/01bqk0",
"name": "Bicycle wheel",
"score": 0.89648587,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.32076266,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.97331065
},
{
"x": 0.32076266,
"y": 0.97331065
}
]
}
},
{
"mid": "/m/0199g",
"name": "Bicycle",
"score": 0.886761,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.312,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.9705882
},
{
"x": 0.312,
"y": 0.9705882
}
]
}
},
...
Wie Sie sehen, konnte die Vision API erkennen, dass das Bild ein Fahrrad und ein Fahrradrad enthält. Die Werte in dieser Antwort sollten in etwa so aussehen wie die in der Antwort labelAnnotations oben: der mid-Wert des Objekts, sein Name (name) und ein Konfidenzwert (score). Die Angabe boundingPoly zeigt den Bereich im Bild, in dem das Objekt identifiziert wurde.
Außerdem hat boundingPoly einen normalizedVertices-Schlüssel, der die Koordinaten des Objekts im Bild enthält. Diese Koordinaten werden auf einen Bereich von 0 bis 1 normalisiert, wobei 0 die obere linke Ecke des Bildes und 1 die untere rechte Ecke des Bildes darstellt.
Sehr gut. Sie haben die Vision API erfolgreich verwendet, um ein Bild zu analysieren und Informationen zu den Objekten im Bild zu extrahieren.
Aufgabe 9: Weitere Vision API-Methoden
Sie haben die Methoden zur Erkennung von Labels, Gesichtern, Sehenswürdigkeiten und Objekten der Vision API kennengelernt. Es gibt aber drei weitere Methoden, die noch nicht vorgestellt wurden. In der Dokumentation zur Methode „images.annotate“ erfahren Sie mehr darüber:
-
Logoerkennung: Identifizieren Sie bekannte Logos und deren Position in einem Bild.
-
SafeSearch-Erkennung: Finden Sie heraus, ob ein Bild anstößige Inhalte enthält. Das ist sinnvoll bei Apps mit von Nutzern erstellten Inhalten. Sie können Bilder anhand von vier Faktoren filtern: Inhalte nur für Erwachsene sowie medizinische, gewaltverherrlichende und Spoofing-Inhalte.
-
Texterkennung: Führen Sie OCR aus, um Text aus Bildern zu extrahieren. Diese Methode kann sogar die Sprache des in einem Bild enthaltenen Textes erkennen.
Das wars! Sie haben das Lab erfolgreich abgeschlossen
Sie wissen nun, wie Sie Bilder mit der Vision API analysieren. In diesem Lab haben Sie der API die Cloud Storage-URL verschiedener Bilder übergeben. Die API hat dann die Labels, Gesichter, Sehenswürdigkeiten und Objekte zurückgegeben, die sie im Bild gefunden hat. Sie können der API auch einen Base64-codierten String eines Bildes übergeben. Das ist hilfreich, wenn Sie ein Bild analysieren möchten, das in einer Datenbank oder im Arbeitsspeicher gespeichert ist.
Weitere Informationen
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 14. Oktober 2025 aktualisiert
Lab zuletzt am 14. Oktober 2025 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.






