GSP774

Visão geral
Neste laboratório, você vai analisar fraudes em dados de transações financeiras e aplicar técnicas de engenharia de atributos e machine learning para detectar atividades fraudulentas usando o BigQuery ML.
Serão usados dados de transações financeiras públicas. Os dados contêm as seguintes colunas:
- Tipo da transação
- Valor transferido
- ID da conta de origem e de destino
- Saldos novos e antigos
- Tempo relativo da transação (número de horas desde o início do período de 30 dias)
- Sinalização
isfraud
A coluna de destino isfraud inclui os rótulos das transações fraudulentas. Com esses rótulos, você vai treinar modelos supervisionados para detecção de fraudes e aplicar modelos não supervisionados para detecção de anomalias.
The data for this lab is from the Kaggle site. If you do not have a Kaggle account, it's free to create one.
Você vai aprender a:
- Carregar dados no BigQuery e analisá-los.
- Criar novos atributos no BigQuery.
- Criar um modelo não supervisionado para detecção de anomalias.
- Criar modelos supervisionados (com regressão logística e árvore otimizada) para detecção de fraudes.
- Avaliar e comparar os modelos e selecionar o mais adequado.
- Usar o modelo selecionado para prever a probabilidade de fraude nos dados de teste.
Neste laboratório, você vai usar a interface do BigQuery para engenharia de atributos, desenvolvimento de modelos, avaliação e previsão.
Participants that prefer Notebooks as the model development interface may choose to build models in AI Platform Notebooks instead of BigQuery ML. Then at the end of the lab, you can also complete the optional section. You can import open source libraries and create custom models or you can call BigQuery ML models within Notebooks using BigQuery magic commands.
If you want to train models in an automated way without any coding, you can use Google Cloud AutoML which builds models using state-of-the-art algorithms. The training process for AutoML would take almost 2 hours, that's why it is recommended to initiate it at the beginning of the lab, as soon as the data is prepared, so that you can see the results at the end. Check for the "Attention" phrase at the end of the data preparation step.
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
Clique em Ativar o Cloud Shell  na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.
-
Clique nas seguintes janelas:
- Continue na janela de informações do Cloud Shell.
- Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
- Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Tarefa 1. Baixar o arquivo de dados do laboratório
- Execute o seguinte comando para baixar o arquivo de dados para o projeto:
gsutil cp gs://spls/gsp774/archive.zip .
- Se for solicitado, clique em Autorizar.
- Depois do upload do arquivo ZIP, execute o comando
unzip:
unzip archive.zip
Perceba que um arquivo foi aumentado.
- Para facilitar a consulta posterior a esse arquivo, crie uma variável de ambiente para o nome do arquivo:
export DATA_FILE=PS_20174392719_1491204439457_log.csv
- Execute o seguinte comando para encontrar o ID do projeto do laboratório e, depois, copie o ID:
gcloud config list project
- Crie uma variável de ambiente para o ID do projeto copiado e substitua <project_id> por ele:
export PROJECT_ID=<project_id>
- Execute o seguinte comando no Cloud Shell para criar um conjunto de dados do BigQuery chamado
finanças a fim de armazenar as tabelas e os modelos deste laboratório:
bq mk --dataset $PROJECT_ID:finance
A execução do comando acima resultará neste resultado:
Dataset `$PROJECT_ID:finance` successfully created.
Clique em Verificar meu progresso para conferir o objetivo.
Criar um conjunto de dados
Tarefa 2. Copie o conjunto de dados para o Cloud Storage
- Execute o seguinte comando para criar um bucket do Cloud Storage usando o ID de projeto exclusivo como nome:
gsutil mb gs://$PROJECT_ID
- Copie o arquivo CSV para o bucket recém-criado:
gsutil cp $DATA_FILE gs://$PROJECT_ID
Tarefa 3. Carregue dados em tabelas do BigQuery
Para carregar dados no BigQuery, use a interface do usuário do BigQuery ou o terminal de comando no Cloud Shell. Escolha uma das opções abaixo para carregar os dados.
Opção 1: linha de comando
- Carregue os dados na tabela
finance.fraud_data executando o seguinte comando:
bq load --autodetect --source_format=CSV --max_bad_records=100000 finance.fraud_data gs://$PROJECT_ID/$DATA_FILE
A opção --autodetect lê automaticamente o esquema da tabela (nomes de variáveis, tipos etc.).
Opção 2: interface do usuário do BigQuery
É possível carregar dados do bucket do Cloud Storage abrindo o BigQuery no console do Cloud.
- Clique no nó Expandir ao lado do ID do projeto na seção Explorer clássico.
- Clique em Visualizar ações ao lado do conjunto de dados finanças e clique em Criar tabela.
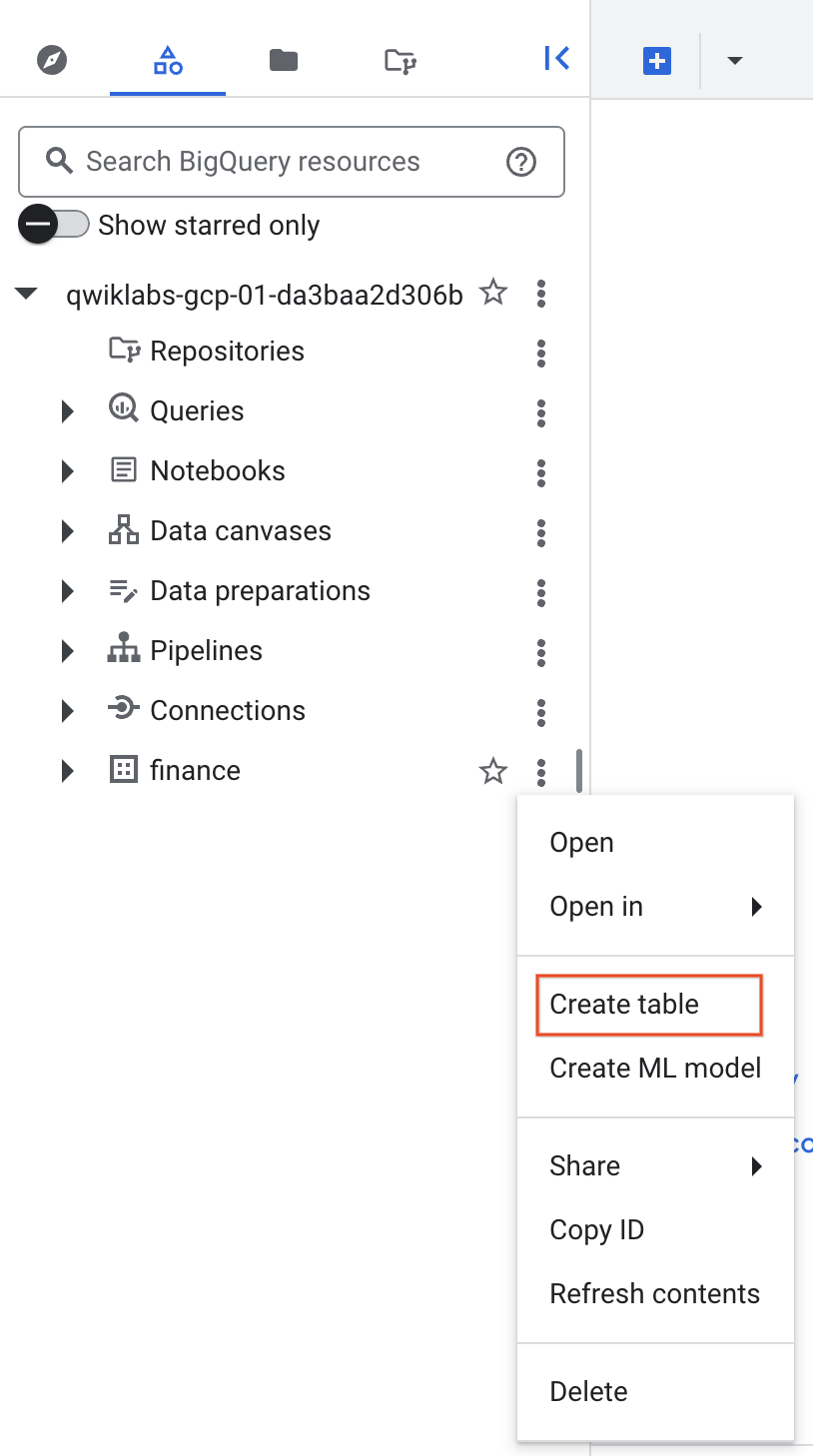
-
Na janela pop-up Criar tabela, defina Origem como Google Cloud Storage e selecione o arquivo CSV bruto no bucket do Cloud Storage.
-
Insira o nome da tabela como fraud_data e selecione a opção Detecção automática em Esquema para que os nomes das variáveis sejam lidos automaticamente na primeira linha do arquivo bruto.
-
Selecione Criar tabela.
O processo de carregamento pode levar um ou dois minutos.
- Depois de concluído, na visualização do painel Explorer clássico no BigQuery, clique no conjunto de dados finance e depois na tabela fraud_data para visualizar os metadados e os dados da tabela.
Clique em Verificar meu progresso para conferir o objetivo.
Carregar dados em tabelas do BigQuery
Tarefa 4. Analisar e investigar os dados com o BigQuery
Se você ainda não abriu o BigQuery no console do Cloud, faça isso agora.
- Clique em Menu de navegação > BigQuery.
Em seguida, você vai começar a analisar os dados para entendê-los melhor e prepará-los para modelos de machine learning.
-
Adicione as seguintes consultas ao EDITOR de consultas, clique em EXECUTAR e analise os dados.
-
Clique em (+) Consulta SQL para iniciar a próxima consulta. Isso permite a comparação fácil dos resultados após a conclusão.
- Qual é o número de transações fraudulentas em cada tipo de transação?
SELECT type, isFraud, count(*) as cnt
FROM `finance.fraud_data`
GROUP BY isFraud, type
ORDER BY type
Procure na coluna isFraud 1 = sim.
- Execute o seguinte comando para conferir a proporção de atividades fraudulentas nos tipos de transação TRANSFER e CASH_OUT (fornece as contagens de
isFraud):
SELECT isFraud, count(*) as cnt
FROM `finance.fraud_data`
WHERE type in ("CASH_OUT", "TRANSFER")
GROUP BY isFraud
- Execute o seguinte comando para conferir os 10 principais valores máximos de transações:
SELECT *
FROM `finance.fraud_data`
ORDER BY amount desc
LIMIT 10
MOMENTO DE REFLEXÃO:
- Você notou algum valor de saldo interessante nas transações? Como fazer uma transação com o saldo da conta de origem zerado? Por que o saldo da conta de destino permanece zerado após a transferência do dinheiro? Esses casos deverão ser sinalizados e adicionados como novos atributos na próxima etapa.
- Você acha que os dados estão desequilibrados? Sim. A proporção de transações fraudulentas é muito inferior a 1%? Ao dividir o número de
isfraud pelo número total de observações, você tem como resultado a proporção de transações fraudulentas.
Na próxima seção, você vai aprender a lidar com essas questões e melhorar os dados para modelos de machine learning.
Clique em Verificar meu progresso para conferir o objetivo.
Analisar e investigar os dados com o BigQuery
Tarefa 5. Prepare os dados
É possível melhorar os dados de modelagem adicionando novos atributos, filtrando tipos de transações desnecessários e aumentando a proporção da variável de destino isFraud com a aplicação de subamostragem.
Com base nas descobertas da fase de análise, você só precisa analisar os tipos de transação "TRANSFER" e "CASH_OUT" e filtrar o restante. Também é possível calcular novas variáveis com base nos valores atuais.
O conjunto de dados contém um destino de fraude extremamente desequilibrado (taxa de fraude nos dados brutos = 0,0013%). Ter eventos raros é comum em fraudes. A fim de tornar o padrão de comportamento fraudulento mais óbvio para os algoritmos de machine learning, além de facilitar a interpretação dos resultados, estratifique os dados e aumente a proporção das sinalizações fraudulentas.
- Na próxima etapa, crie uma nova consulta, adicione o seguinte código para incluir novos atributos nos dados, filtre os tipos de transação desnecessários e selecione um subconjunto das transações não fraudulentas com subamostragem:
CREATE OR REPLACE TABLE finance.fraud_data_sample AS
SELECT
type,
amount,
nameOrig,
nameDest,
oldbalanceOrg as oldbalanceOrig, #standardize the naming.
newbalanceOrig,
oldbalanceDest,
newbalanceDest,
# add new features:
if(oldbalanceOrg = 0.0, 1, 0) as origzeroFlag,
if(newbalanceDest = 0.0, 1, 0) as destzeroFlag,
round((newbalanceDest-oldbalanceDest-amount)) as amountError,
generate_uuid() as id, #create a unique id for each transaction.
isFraud
FROM finance.fraud_data
WHERE
# filter unnecessary transaction types:
type in("CASH_OUT","TRANSFER") AND
# undersample:
(isFraud = 1 or (RAND()< 10/100)) # select 10% of the non-fraud cases
-
Execute a consulta.
-
Crie uma tabela de dados TEST selecionando uma amostra aleatória de 20%:
CREATE OR REPLACE TABLE finance.fraud_data_test AS
SELECT *
FROM finance.fraud_data_sample
where RAND() < 20/100
-
Execute a consulta.
Esses dados vão ser mantidos separados e não vão ser incluídos no treinamento. Você vai usá-los para pontuar o modelo na fase final.
O BigQuery ML e o AutoML vão automaticamente particionar os dados do model como TRAIN e VALIDATE usando os algoritmos de machine learning para testar a taxa de erro nos dados de treinamento e de validação e evitar overfitting.
- Execute o seguinte comando para criar dados de amostra:
CREATE OR REPLACE TABLE finance.fraud_data_model AS
SELECT
*
FROM finance.fraud_data_sample
EXCEPT distinct select * from finance.fraud_data_test
Os dados de amostra criados para modelagem contêm aproximadamente 228 mil linhas de transações bancárias.
Também é possível particionar o conjunto de dados manualmente como TRAIN/VALIDATE e TEST, especialmente para comparar modelos de diferentes ambientes, como AutoML ou AI Platform, e ter consistência.
MOMENTO DE REFLEXÃO:
- Como lidar com a ausência de eventos de fraude rotulados nos dados? Se não houver transações rotuladas, use técnicas de modelagem não supervisionada para analisar as anomalias nos dados, como clustering k-means. Na próxima seção, você vai testar esse método.
Clique em Verificar meu progresso para conferir o objetivo.
Preparar os dados
Tarefa 6. Treine um modelo não supervisionado para detectar anomalias
Métodos não supervisionados são usados com frequência na detecção de fraudes, para ajudar na análise de comportamentos anormais nos dados. Eles também são úteis quando não há rótulos de fraude ou a taxa de eventos é muito baixa e o número de ocorrências não permite a criação de um modelo supervisionado.
Nesta seção, você vai usar o algoritmo de clustering k-means para criar segmentos de transações, analisar cada segmento e detectar quais deles têm anomalias.
- Crie uma consulta SQL e execute o seguinte código no BigQuery com CREATE ou REPLACE MODEL e defina model_type como
kmeans:
CREATE OR REPLACE MODEL
finance.model_unsupervised OPTIONS(model_type='kmeans', num_clusters=5) AS
SELECT
amount, oldbalanceOrig, newbalanceOrig, oldbalanceDest, newbalanceDest, type, origzeroFlag, destzeroFlag, amountError
FROM
`finance.fraud_data_model`
Isso vai criar um modelo k-means chamado model_unsupervised com 5 clusters que usam as variáveis selecionadas de fraud_data_model.
Observação: o treinamento do modelo levará alguns minutos para ser concluído.
Depois do treinamento do modelo, ele será exibido em Finanças > Modelos.
- Clique em model_unsupervised e, em seguida, na guia Avaliação.
O algoritmo k-means cria uma variável de saída chamada centroid_id. Cada transação recebe um centroid_id. As transações semelhantes/mais próximas umas das outras são atribuídas ao mesmo cluster pelo algoritmo.
O índice Davies-Bouldin mostra uma indicação do nível de homogeneidade dos clusters. Quanto menor o valor, mais distantes os clusters estão uns dos outros, que é o resultado desejado.
Os atributos numéricos são exibidos com gráficos de barras para cada centroide (cluster) na guia Avaliação. Os números próximos às barras mostram o valor médio das variáveis em cada cluster. Como prática recomendada, é possível padronizar ou agrupar as variáveis de entrada em buckets para evitar o impacto de grandes números ou outliers nos cálculos de distância para clustering. Para simplificar, este laboratório usa as variáveis originais neste exercício.
As variáveis categóricas usadas como entrada são exibidas separadamente. É possível conferir a distribuição das transações TRANSFER e CASH_OUT em cada segmento abaixo.
Embora os gráficos possam parecer diferentes para o modelo, concentre-se nos segmentos menores e tente interpretar as distribuições.
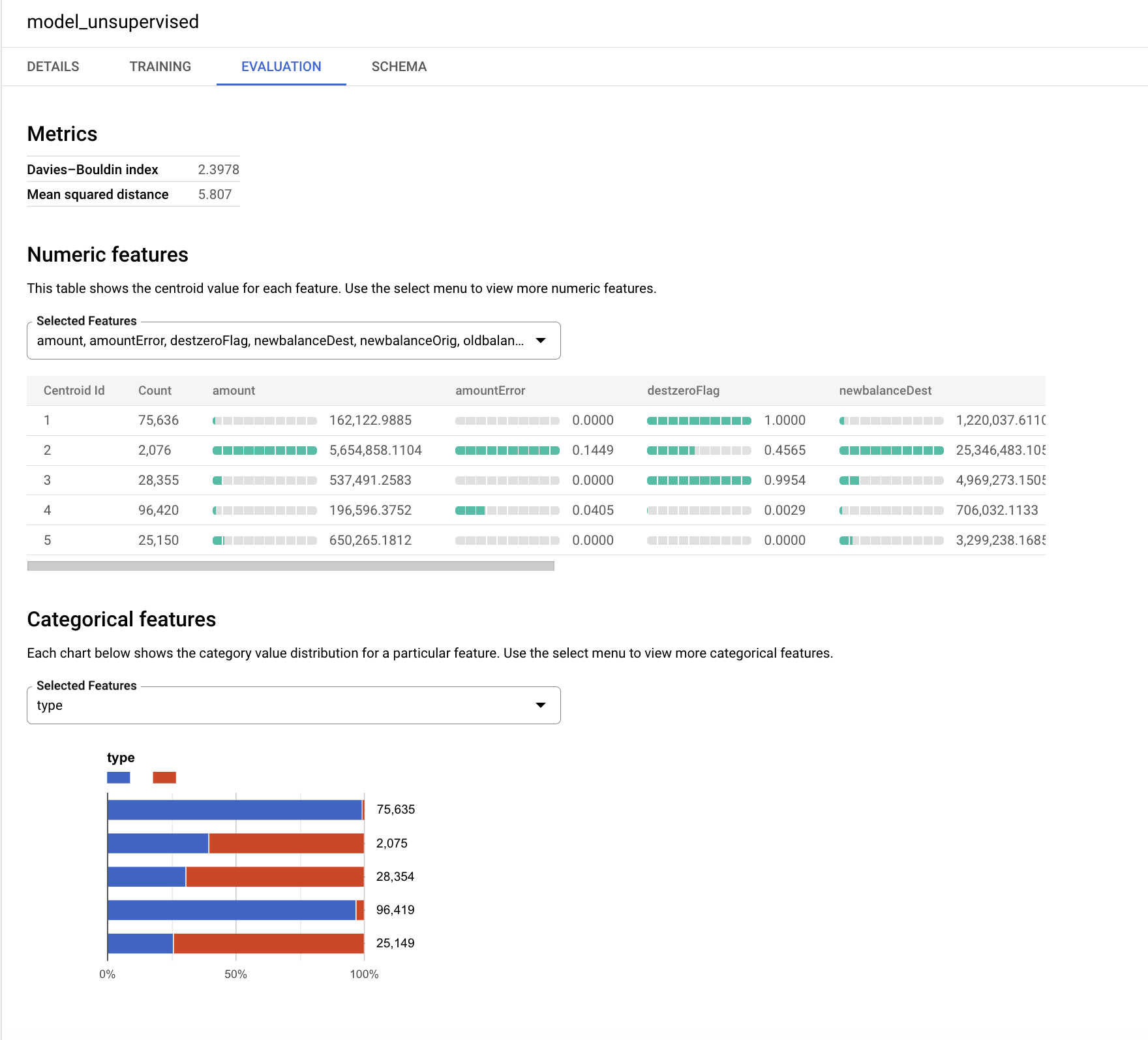
A variável de destino isFraud não foi usada neste modelo não supervisionado. Neste exercício, é recomendado manter essa variável para a caracterização de perfil e utilizá-la para analisar a distribuição de atividades fraudulentas em cada cluster.
-
Pontue os dados de teste (fraud_data_test) usando esse modelo e confira o número de eventos de fraude em cada centroid_id. Os algoritmos de clustering criam grupos homogêneos de observações. Nesta consulta, ML.PREDICT vai chamar o modelo e gerar o centroid_id para cada transação nos dados de teste.
-
Execute o seguinte código na nova consulta:
SELECT
centroid_id, sum(isfraud) as fraud_cnt, count(*) total_cnt
FROM
ML.PREDICT(MODEL `finance.model_unsupervised`,
(
SELECT *
FROM `finance.fraud_data_test`))
group by centroid_id
order by centroid_id
MOMENTO DE REFLEXÃO:
- Qual cluster você considera mais interessante? A resposta certa são os clusters pequenos com altos valores de erro.
Clique em Verificar meu progresso para conferir o objetivo.
Treinar um modelo não supervisionado para detectar anomalias
Tarefa 7. Treine um modelo de machine learning supervisionado
Agora tudo está pronto para você começar a criar modelos supervisionados usando o BigQuery ML para prever a probabilidade de transações fraudulentas. Comece com um modelo simples: use o BigQuery ML para criar um modelo de regressão logística binária para classificação. Esse modelo vai tentar prever se a transação provavelmente é fraudulenta ou não.
Para todas as variáveis não numéricas (categóricas), o BigQuery ML executa automaticamente uma transformação de codificação one-hot. Essa transformação gera um atributo separado para cada valor único na variável. Neste exercício, a codificação one-hot será executada automaticamente pelo BigQuery ML para a variável TYPE.
- Para criar seu primeiro modelo supervisionado, execute a seguinte instrução SQL no BigQuery:
CREATE OR REPLACE MODEL
finance.model_supervised_initial
OPTIONS(model_type='LOGISTIC_REG', INPUT_LABEL_COLS = ["isfraud"]
)
AS
SELECT
type, amount, oldbalanceOrig, newbalanceOrig, oldbalanceDest, newbalanceDest, isFraud
FROM finance.fraud_data_model
Observação: o BigQuery leva alguns minutos para criar e treinar esse modelo de regressão logística.
Quando tudo estiver pronto, a tabela model_supervised_initial será adicionada em Finanças > Modelos.
Depois que o modelo for criado, será possível acessar os metadados, o treinamento e as estatísticas de avaliação do modelo na interface do console do BigQuery.
- Clique em model_supervised_initial no painel esquerdo e, depois, na guia Detalhes, Treinamento, Avaliação ou Esquema para saber mais.
Na guia Avaliação, é possível encontrar várias métricas de performance específicas do modelo de classificação.
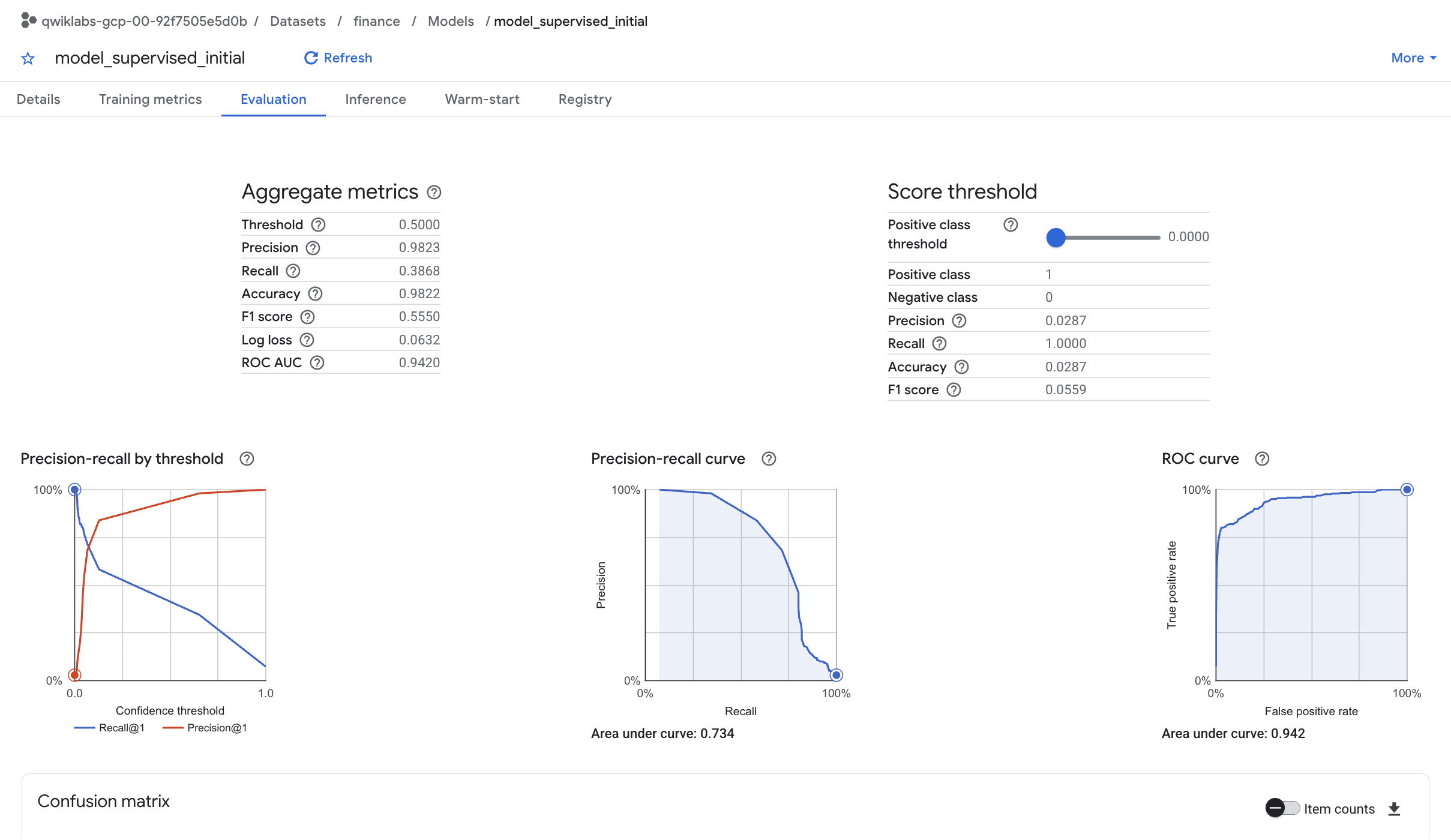
Entender o desempenho do modelo é um tópico importante em machine learning. Como você executou uma regressão logística para classificação, é útil entender os seguintes conceitos importantes:
-
precisão: a precisão identifica a proporção de casos positivos selecionados em que o modelo estava correto.
-
recall: uma métrica que responde à pergunta: de todos os rótulos reais positivos possíveis, quantos o modelo identificou corretamente?
-
acurácia: a acurácia é a proporção geral de previsões corretas.
-
pontuação F1: uma medida da acurácia do modelo. A pontuação f1 é a média harmônica da precisão e do recall, assumindo valores de 0 a 1, em que quanto maior melhor.
- roc auc: a área sob a curva roc. Fornece informações sobre a capacidade de discriminação de um classificador binário considerando diferentes limites, assumindo valores entre 0 e 1, em que quanto maior melhor. Para um modelo moderado, a expectativa seria ter um valor de ROC superior a 0,7.
O gráfico nesta página da Wikipédia explica muito bem os conceitos de precisão e recall.
O valor de ROC para este modelo de regressão é muito alto. É possível compreender melhor a acurácia testando os resultados com relação a diferentes limites de probabilidade.
Agora, observe os atributos mais influentes do modelo.
- Execute a seguinte consulta para verificar a importância do atributo:
SELECT
*
FROM
ML.WEIGHTS(MODEL `finance.model_supervised_initial`,
STRUCT(true AS standardize))
Os pesos são padronizados para eliminar o impacto da escala das variáveis usando a opção padronizar. Os pesos maiores são os mais importantes. O sinal do peso indica a direção, dependendo da relação direta ou inversa com o destino.
MOMENTO DE REFLEXÃO:
- Quais duas variáveis parecem ser as mais importantes?
oldbalanceOrig e type são as variáveis mais importantes.

Clique em Verificar meu progresso para conferir o objetivo.
Treinar um modelo de machine learning supervisionado
Tarefa 8. Aprimore o modelo
Agora é hora de um exercício divertido: crie um modelo e treine os dois modelos para conseguir uma acurácia melhor.
- Crie um modelo de boost de gradiente executando o seguinte comando:
CREATE OR REPLACE MODEL
finance.model_supervised_boosted_tree
OPTIONS(model_type='BOOSTED_TREE_CLASSIFIER', INPUT_LABEL_COLS = ["isfraud"]
)
AS
SELECT
type, amount, oldbalanceOrig, newbalanceOrig, oldbalanceDest, newbalanceDest, isFraud
FROM finance.fraud_data_model
Observação: o treinamento do modelo leva alguns minutos para ser concluído.
A seguir, compare os 2 modelos que você criou e escolha o melhor.
Tarefa 9. Avalie os modelos de machine learning supervisionado
Melhore o modelo de regressão logística atual adicionando novas variáveis.
Depois de criar o modelo, você pode avaliar o desempenho do classificador usando a função ML.EVALUATE. A função ML.EVALUATE avalia o resultado ou os valores previstos em relação aos dados reais.
- Execute as consultas a seguir para anexar os resultados dos dois modelos em uma única tabela e escolha o modelo mais adequado para uso ao pontuar novos dados.
CREATE OR REPLACE TABLE finance.table_perf AS
SELECT "Initial_reg" as model_name, *
FROM ML.EVALUATE(MODEL `finance.model_supervised_initial`, (
SELECT *
FROM `finance.fraud_data_model` ))
insert finance.table_perf
SELECT "improved_reg" as model_name, *
FROM ML.EVALUATE(MODEL `finance.model_supervised_boosted_tree`, (
SELECT *
FROM `finance.fraud_data_model` ))
MOMENTO DE REFLEXÃO:
- Qual modelo apresentou o melhor desempenho?
No início, você executou um modelo de regressão. Em seguida, você adicionou mais variáveis e treinou um novo modelo usando a regressão (o modelo supervisionado). Por fim, você usou uma árvore otimizada como o segundo modelo supervisionado. Ao comparar as tabelas de desempenho, o modelo de árvore otimizada apresenta um desempenho melhor. A adição de novos atributos adicionais melhorou a acurácia do modelo.
Tarefa 10. Preveja transações fraudulentas em dados de teste
A última etapa de machine learning é usar o modelo mais adequado para prever o resultado em novos conjuntos de dados.
Os algoritmos de machine learning no BQML criam uma variável aninhada chamada predicted_<target_name\>_probs. Essa variável inclui as pontuações de probabilidade para a decisão do modelo. A decisão do modelo é relacionada a transações fraudulentas ou genuínas.
- Execute a consulta a seguir no BigQuery para conferir a previsão de transações fraudulentas nos dados de teste criados no início do laboratório. A instrução WHERE abaixo vai fornecer as transações com as maiores pontuações de probabilidade:
SELECT id, label as predicted, isFraud as actual
FROM
ML.PREDICT(MODEL `finance.model_supervised_initial`,
(
SELECT *
FROM `finance.fraud_data_test`
)
), unnest(predicted_isfraud_probs) as p
where p.label = 1 and p.prob > 0.5
MOMENTO DE REFLEXÃO:
- Qual é a proporção de atividades fraudulentas no conjunto previsto de transações? Menos de 3%.
- Quanto a taxa de eventos aumentou no conjunto de linhas previsto em comparação com os dados de teste gerais? Mais de 95%.
Clique em Verificar meu progresso para conferir o objetivo.
Prever transações fraudulentas em dados de teste
Parabéns!
Próximas etapas
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 11 de fevereiro de 2026
Laboratório testado em 11 de fevereiro de 2026
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





