

准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Create an API Key
/ 25
Create a request to Classify a news article
/ 25
Check the Entity Analysis response
/ 25
Create a new Dataset and table for categorized text data
/ 25

通过 Cloud Natural Language API,您可以从文本中提取实体,执行情感和语法分析并对文本进行分类。本实验的重点是文本分类。此 API 功能借助含 700 多个类别的数据库,让您能轻松地对大型文本数据集进行分类。
在本实验中,您将学习如何完成以下操作:
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
点击 Google Cloud 控制台顶部的激活 Cloud Shell 
在弹出的窗口中执行以下操作:
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
输出:
输出:
gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
展开屏幕左上角的导航菜单 (
依次选择 API 和服务 > 已启用的 API 和服务。
然后,在搜索框中搜索 language。
点击 Cloud Natural Language API。
如果此 API 尚未启用,您会看到启用按钮。
启用此 API 后,Google Cloud 会显示 API 信息,如下所示:
由于您要使用 curl 向 Natural Language API 发送请求,因此需要生成 API 密钥,以传递到请求网址中。
要创建 API 密钥,请在控制台中依次点击导航菜单 > API 和服务 > 凭证。
然后点击创建凭证。
在下拉菜单中选择 API 密钥。
接下来,复制您刚刚生成的密钥,然后点击关闭。
点击检查我的进度以验证是否完成了以下目标:
现在您已经有了 API 密钥,请将其保存为一个环境变量,这样就不必在每个请求中都插入 API 密钥的值。
为执行后续步骤,请通过 SSH 连接到为您预配的实例。
linux-instance。点击 SSH 按钮。此时会跳转至一个交互式 shell。
在命令行中,输入以下内容,并将 <YOUR_API_KEY> 替换为您刚刚复制的密钥:
使用 Natural Language API 的 classifyText 方法,只需调用一次 API 即可完成文本数据的分类。此方法返回一个适用于文本文档的内容类别列表。
这些类别的精细程度各有不同,既有 /Computers & Electronics 这样的宽泛大类,也有 /Computers & Electronics/Programming/Java (Programming Language) 这种非常精细的小类。如需查看 700 多个类别的完整列表,请访问内容类别页面。
首先,对单篇文章进行分类,然后了解如何使用此方法来理解大型新闻语料库。
A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.
request.json 的文件,并添加以下代码。您可以使用自己喜欢的一种命令行编辑器(例如 nano、vim、emacs)创建该文件。curl 命令将此文本发送到 Natural Language API 的 classifyText 方法:请看响应结果:
您刚才创建了 Speech API 请求并调用了 Speech API。
result.json 文件:对于这段文本,API 返回了 2 个类别:
/Food & Drink/Cooking & Recipes/Food & Drink/Food/Meat & Seafood这段文本没有明确提到这是一份食谱,甚至没有提到其中包含海鲜,但 API 能够这样对它分类。单篇文章的分类确实不错,但要想真正见识此功能的强大之处,还要对大量的文本数据进行分类。
要想了解 classifyText 方法如何帮助您理解包含大量文本的数据集,请使用 BBC 新闻报道的这一公共数据集。该数据集包含 2004 年至 2005 年间的 2,225 篇文章,涉及五个主题领域(商业、娱乐、政治、体育、科技)。其中一部分文章位于公共 Cloud Storage 存储桶中。每篇文章都存储在一个 .txt 文件中。
要想检查数据并将其发送到 Natural Language API,您需要编写一个 Python 脚本,从 Cloud Storage 读取每个文本文件,将文本发送到 classifyText 端点,然后将结果存储在 BigQuery 表中。BigQuery 是 Google Cloud 的大数据仓库工具,可让您轻松存储和分析大型数据集。
gsutil 提供访问 Cloud Storage 的命令行界面):接下来,您将为您的数据创建一个 BigQuery 表。
在将文本发送到 Natural Language API 之前,您需要一个地方来存储每篇文章的文本和类别。
在控制台中,前往导航菜单 > BigQuery。
点击完成。
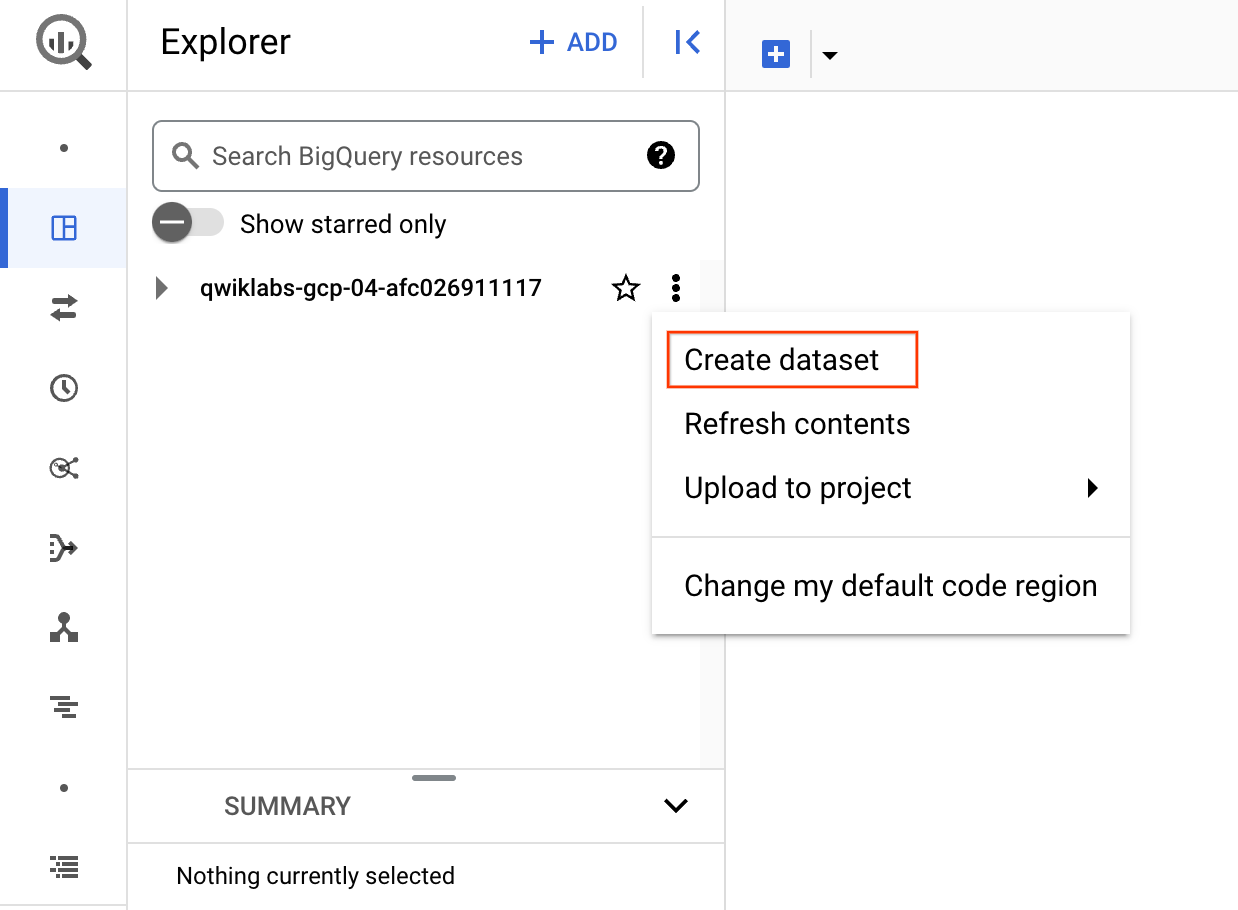
要想创建数据集,请点击项目 ID 旁边的查看操作图标,然后选择创建数据集。
将数据集命名为 news_classification_dataset,然后点击创建数据集。
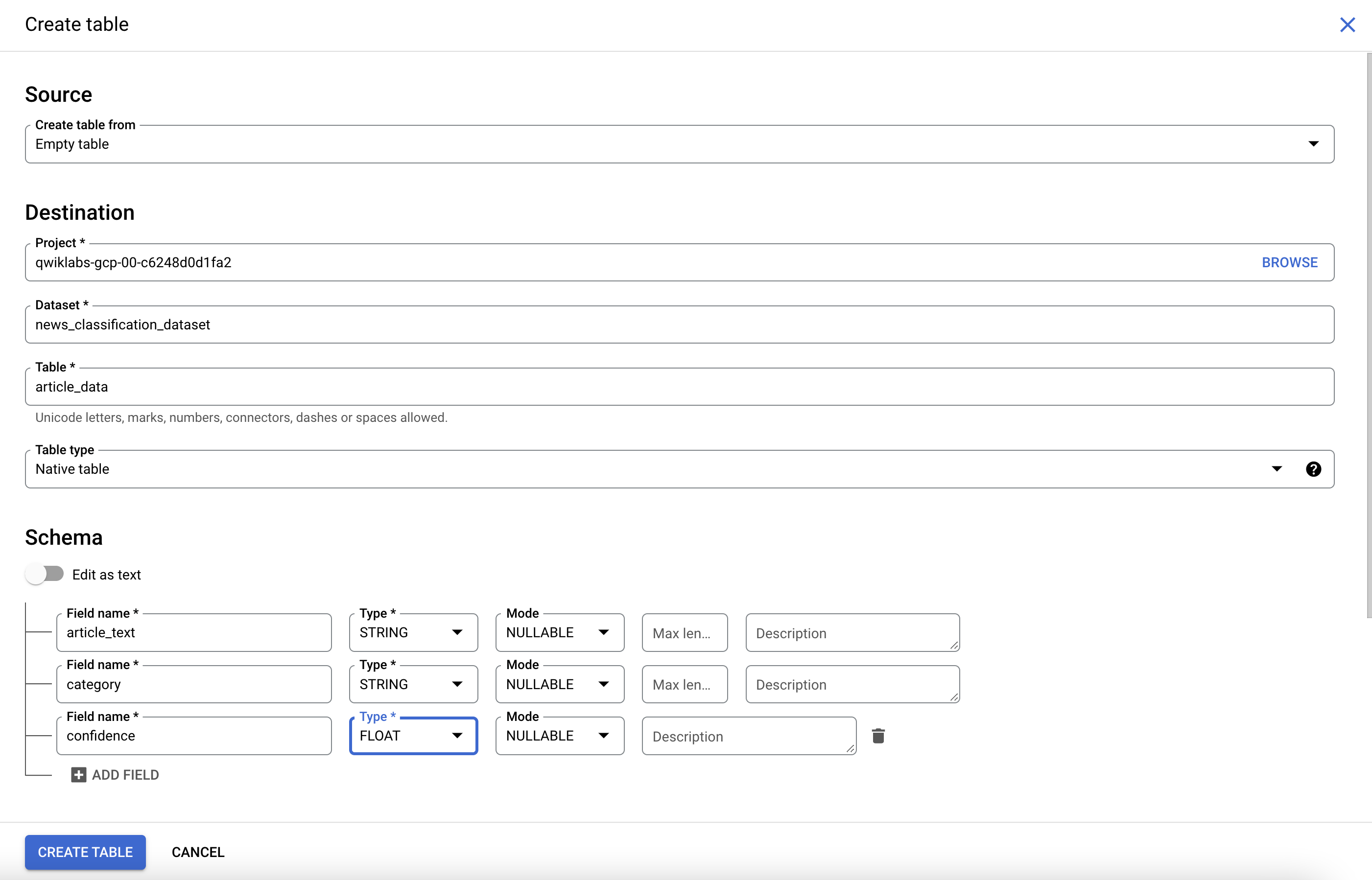
要想创建表,请点击 news_classification_dataset 旁边的查看操作图标,然后选择创建表。
如下设置新表:
在“架构”下,点击添加字段并添加以下 3 个字段:
| 字段名称 | 类型 | 模式 |
|---|---|---|
article_text |
STRING | NULLABLE |
category |
STRING | NULLABLE |
confidence |
FLOAT | NULLABLE |
该表目前为空。下一步,您将从 Cloud Storage 读取文章,将其发送到 Natural Language API 进行分类,并将结果存储在 BigQuery 中。
点击检查我的进度以验证是否完成了以下目标:
为执行后续步骤,请连接到 Cloud Shell。如果出现提示,点击继续。
在编写脚本将新闻数据发送到 Natural Language API 之前,您需要创建一个服务账号。从 Python 脚本向 Natural Language API 和 BigQuery 进行身份验证时将用到此账号。
现在,您可以将文本数据发送到 Natural Language API 了!
您可以使用任何语言完成这一项工作,因为云客户端库有很多种。
classify-text.py 的文件,并将以下代码复制到文件中。您可以使用自己喜欢的一种命令行编辑器(例如 nano、vim、emacs)创建该文件。现在,您可以开始对文章进行分类并将其数据导入 BigQuery。
该脚本大约需要两分钟才能运行完毕,因此在运行期间,您可以了解一下工作流程。
您在使用 Google Cloud Python 客户端库访问 Cloud Storage、Natural Language API 和 BigQuery。首先,为每项服务创建一个客户端,然后创建对 BigQuery 表的引用。files 是对公共存储桶中每个 BBC 数据集文件的引用。查看这些文件,将文章下载为字符串,然后在 classify_text 函数中将每个字符串发送到 Natural Language API。对于 Natural Language API 已返回类别的所有文章,文章及其类别数据都保存到 rows_for_bq 列表中。完成每篇文章的分类后,使用 insert_rows() 将数据插入到 BigQuery 中。
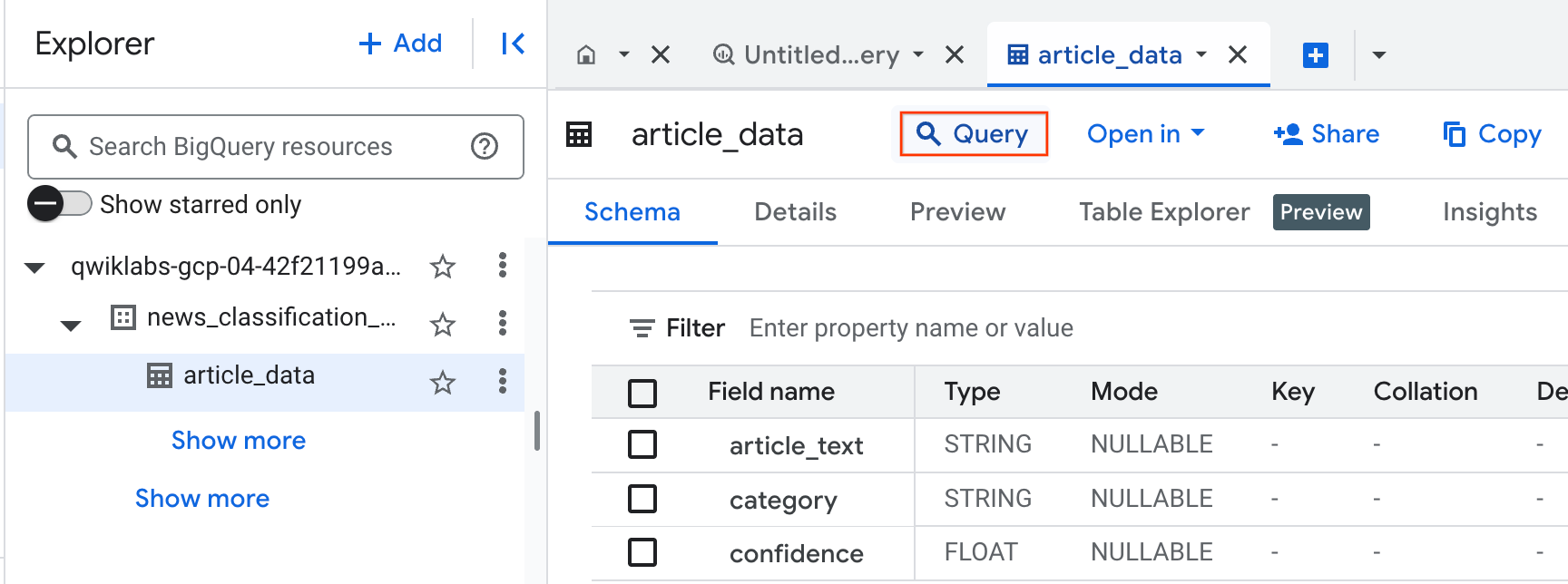
脚本运行完毕后,需要验证文章数据是否已保存到 BigQuery。
article_data 表,然后点击查询以查询该表:查询完成后,您将看到自己的数据。
category 列包含 Natural Language API 为文章返回的第一个类别的名称,confidence 是 0 到 1 之间的一个值,表示 API 对文章分类正确性的置信度。
在下一步中,您将学习如何对数据执行更复杂的查询。
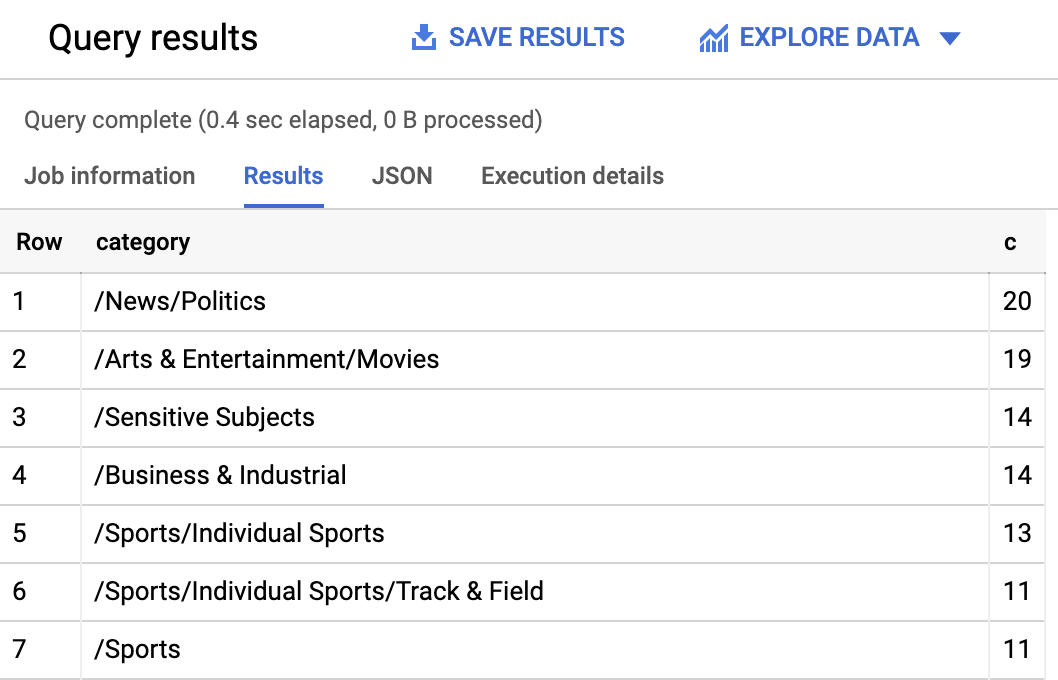
首先,查看数据集中最常见的类别有哪些。
在 BigQuery 控制台中,点击 + SQL 查询。
输入以下查询:
您应该会在查询结果中看到如下内容:
如果您想查找归于 /Arts & Entertainment/Music & Audio/Classical Music 这种小众类别的文章,可以编写以下查询:
您也可以仅查找 Natural Language API 返回的置信度分数大于 90% 的文章:
如需对数据执行更多查询,请查阅 BigQuery 文档。BigQuery 还集成了许多可视化工具。如需为已分类的新闻数据创建可视化图表,请了解一下适用于 BigQuery 的 Looker Studio。
您学习了如何使用 Natural Language API 文本分类方法对新闻报道进行分类。您首先对一篇文章进行了分类,然后学习了如何使用 Natural Language API 和 BigQuery 对大型新闻数据集进行分类和分析。您还学习了如何创建 BigQuery 表并对数据运行查询。
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2025 年 3 月 21 日
上次测试实验的时间:2025 年 3 月 21 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验