Este laboratório foi desenvolvido com nosso parceiro, a
Alteryx Designer Cloud (Trifacta). Suas informações pessoais podem ser compartilhadas com a Trifacta,
patrocinadora do laboratório, caso você tenha optado por receber
atualizações de produtos, anúncios e ofertas no perfil de conta.
GSP823

Visão geral
O Dataprep da
Alteryx Designer Cloud (Trifacta)
é a ferramenta de autoatendimento de preparação de dados do Google criada em
colaboração com a Alteryx. Neste laboratório, você vai aprender técnicas mais
avançadas com o Dataprep.
Cenário de caso de uso
O Monte Rainier é um dos vulcões ativos mais altos da América do Norte. Apesar
da alta probabilidade de erupção, milhares de pessoas enfrentam os elementos
para escalar esse pico de 4.392 m. Usando informações coletadas do Serviço
Nacional de Parques e da Administração Oceânica e Atmosférica Nacional (NOAA),
você vai analisar como o clima afeta os alpinistas nas expedições.
Objetivos
Neste laboratório, você vai aprender a:
- Criar conjuntos de dados parametrizados no Cloud Dataprep
- Manipular datas e horas
- Criar e usar novas amostras
- Criar casos condicionais
- Criar agregações
- Cabeçalhos limpos para o BigQuery
- Visualizar resultados no Data Studio
- Fluxos de exportação
Configuração e requisitos
Observação: para executar este laboratório, é necessário
usar o Google Chrome. No momento, o Cloud Dataprep não dá suporte a outros
navegadores.
Recomendamos que você faça o laboratório
Como trabalhar com o Google Cloud Dataprep
antes.
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Tarefa 1: abrir o Google Cloud Dataprep
- No Cloud Shell, execute este comando:
gcloud beta services identity create --service=dataprep.googleapis.com
-
No console do Cloud, acesse o Menu de navegação, clique
em Ver todos os produtos > Analytics >
Alteryx Designer Cloud.
-
Para entrar no Cloud Dataprep, concorde com os Termos de Serviço e clique
em Aceitar.
-
Marque a caixa de seleção e clique em
Concordar e continuar para autorizar o compartilhamento
das informações da conta com a Trifacta.
-
Clique em Permitir para autorizar a Trifacta a acessar o
projeto.
-
Selecione suas credenciais do laboratório para fazer login e clique em
Permitir.
-
Marque a caixa de seleção e clique em Aceitar para
concordar com os Termos de Serviço da Trifacta.
-
Se for solicitado o uso do local padrão para o bucket de armazenamento,
clique em Continuar.
Clique em Verificar meu progresso para conferir o objetivo.
Iniciar o Dataprep
Tarefa 2: conectar os dados
Os dados têm informações do Serviço Nacional de Parques sobre tentativas de
escalada ao Monte Rainier. Os dados de escalada são separados por ano. Também
há dados climáticos da NOAA coletados na estação Paradise Ranger do Monte
Rainier durante o mesmo período.
Criar um fluxo
-
Clique em Criar um novo fluxo no canto superior direito.
-
Clique em Fluxo sem nome e, na caixa de diálogo
Renomear, em Nome do fluxo, use
Rainier Climbs.
-
Clique em OK.
-
No Conjunto de dados, clique em + para adicionar uma nova
fonte.
-
Clique em Importar conjuntos de dados e clique no
navegador Cloud Storage à esquerda.
-
Navegue até o bucket com o ID do seu projeto.
Essa pasta contém dados de cada ano, de 2006 a 2015. Também inclui informações
sobre a previsão do tempo para os períodos. Neste laboratório, você vai usar
todos os conjuntos de dados.
Podemos importar cada conjunto de dados individualmente e uni-los, mas o que
acontece quando você recebe um novo arquivo com os anos mais recentes? Teria
que adicionar outro conjunto de dados e reconstruir a união. E se pudesse
evitar todo esse trabalho e apenas criar uma regra que contabilizasse novos
arquivos no pipeline?
Parametrização do conjunto de dados
A parametrização de conjuntos de dados permite usar padrões ou variáveis para
corresponder a vários arquivos ao importar ou publicar dados.
-
Passe o cursor sobre um dos conjuntos de dados da expedição. À direita,
vai aparecer uma opção para parametrizar o conjunto de dados. Clique para
Parametrizar os dados de importação.
-
Isso vai abrir o assistente de parametrização. No início, ele preenche
previamente a seleção com o caminho do arquivo para os dados selecionados.
-
Selecione a parte do caminho que quer parametrizar. Observe que todos os
dados de escalada são nomeados como "climbs", seguidos pelo ano.
Destaque o ano (2006) no caminho.

-
Depois que algum texto é destacado, confira as opções para mudar a parte
destacada do caminho em um parâmetro. Selecione o parâmetro
Adicionar parâmetro de padrão.
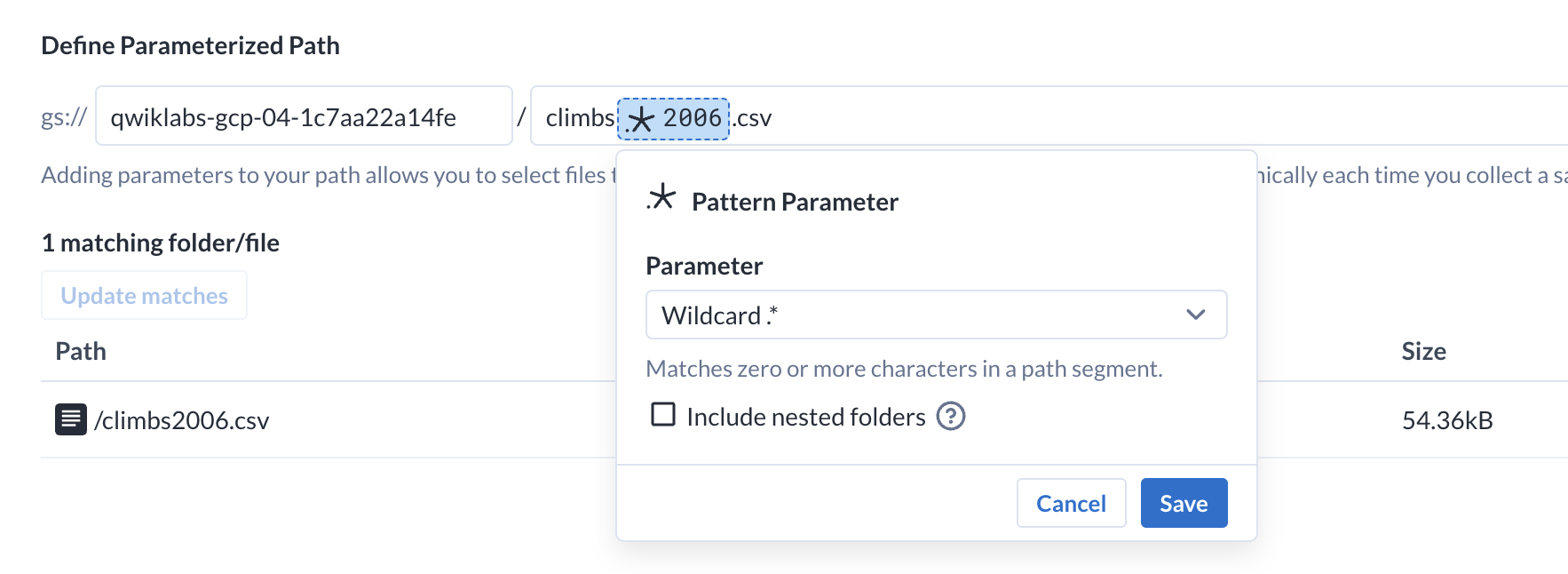
-
Escolha o caractere curinga .* no menu suspenso
"Parâmetro" e clique em Salvar.
-
Esse parâmetro vai corresponder a qualquer arquivo que comece com "climbs"
e termine com ".csv". Na parte inferior da tela, você pode conferir a
atualização do Dataprep que vai refletir todos os arquivos que
correspondem ao parâmetro.
-
Clique em Criar no canto inferior direito para criar um
conjunto de dados com ele. Todos os arquivos correspondentes serão
concatenados em um grande conjunto de dados como entrada para o roteiro.
-
Clique em Importar e adicionar ao fluxo para adicionar as
fontes.
Um novo conjunto de dados chamado
Conjunto de dados com parâmetros é criado e colocado na
Visualização de fluxo. Um roteiro e uma saída também são criados
automaticamente para esse conjunto de dados.
Tarefa 3: coletar novas amostras
-
Clique duas vezes no nó do roteiro para editar o
Conjunto de dados com parâmetros.
-
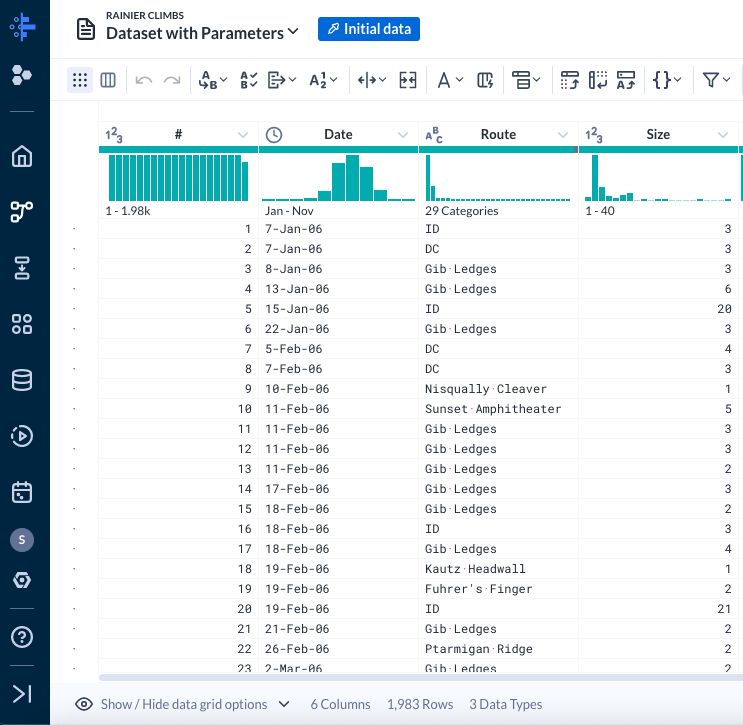
Quando o conjunto de dados é carregado pela primeira vez, perceba que ele
tem 6 colunas e apenas 1.983 linhas.
-
Essa contagem de linhas parece baixa para um período de 9 anos. Na coluna
Date, você vai perceber que ela contém apenas valores de 2006 no
histograma. Por quê?
Você também pode ter notado a notificação que apareceu no canto superior
direito.
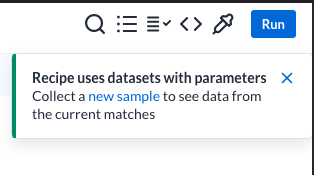
Lembre-se de que, no Dataprep, você cria transformações em uma amostra do
conjunto de dados. Nesse caso, ele carregou só o primeiro conjunto de dados da
entrada parametrizada para mostrar uma prévia deles.
-
Clique na caixa Dados iniciais na parte de cima. Isso vai
abrir o painel Amostras.
Aqui você pode ver as amostras visíveis no momento, bem como outras
disponíveis. Também pode coletar uma nova amostra a qualquer momento.
-
Em Coletar nova amostra, selecione
Aleatória.
-
Escolha Rápido e clique em Coletar para
coletar uma nova amostra aleatória. Uma amostra aleatória é uma técnica de
amostragem em que cada linha tem a mesma probabilidade de ser escolhida.
O Dataprep está preparando a nova amostra em segundo plano. O progresso pode
ser visto no painel.
Dependendo do tamanho e da complexidade da amostra, pode levar alguns minutos
para coletar. Você pode continuar analisando e manipulando os dados com a
amostra atual enquanto a nova é coletada.
Tarefa 4: Limpeza de dados
Enquanto a amostra é coletada em segundo plano, você pode dar uma olhada
rápida nos seus dados. Os dados de escalada contêm 6 colunas:
-
#: um ID de subida crescente
-
Date: a data da escalada
-
Route: o trajeto feito
-
Size: o tamanho do grupo de escalada
-
Summit: o número de pessoas que chegam ao cume
-
Leader Zip Code: o CEP do líder do grupo de escalada
-
Observe o formato da coluna Date (7-Jan-06).
-
Anote a distribuição da coluna Date. Há várias equipes de
escalada por dia.
Manipulação de datas
O formato padrão de data e hora do BigQuery é
yyyy-MM-ddTHH:mm:ss. Como o objetivo final é publicar esses dados
no BigQuery, é melhor seguir o formato. O Dataprep permite a fácil manipulação
das colunas de data e hora.
-
Clique no menu suspenso ao lado da coluna Data e
selecione Formato >
Mudar formato de data e hora >
Data.
-
Isso vai abrir o criador de transformações de formato de data. Em "Formato
de saída", selecione o formato, neste caso, aaaa-MM-dd.
Confira a visualização e clique em Adicionar.
Preparar dados de junção
Para analisar como o clima afeta a taxa de sucesso da escalada, os dados
climáticos precisam ser incluídos. Esses dados meteorológicos estão em outro
conjunto de dados. Enquanto o Dataprep coleta a amostra de dados da escalada,
você pode analisar o conjunto de dados do clima.
-
Volte para a visualização Fluxo clicando no nome do fluxo
RAINIER CLIMBS.

-
No canto superior direito da página "Visualização de fluxo", clique no
botão Adicionar conjuntos de dados para adicionar um novo
conjunto de dados a este fluxo.
-
Clique em Importar conjuntos de dados no canto inferior
esquerdo da caixa de diálogo.
-
Volte para a mesma pasta no Cloud Storage e adicione o conjunto de dados
rainier_weather.csv.
- Clique em Importar e Adicionar ao fluxo.
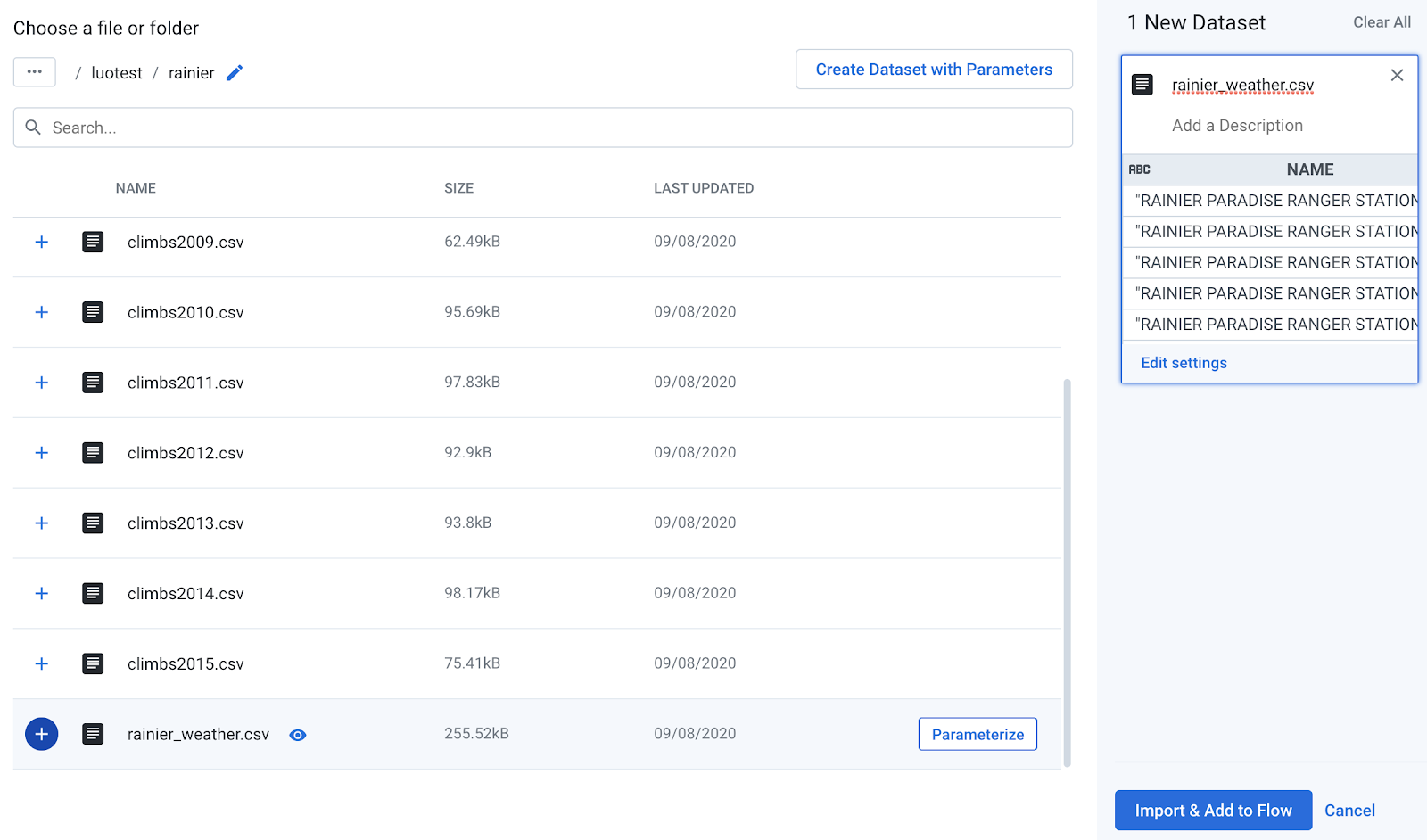
-
Um novo nó aparece na tela de fluxo para os dados meteorológicos. Clique
no sinal de adição (+) ao lado dele e selecione
Adicionar novo roteiro.
-
Renomeie o roteiro sem título como
rainier weather e clique duas vezes no novo
nó de roteiro para editá-lo.
-
Os dados têm as seguintes colunas:
-
NAME: o nome da estação meteorológica que fez as medições
-
ELEVATION: a elevação da estação meteorológica
-
DATE: a data da previsão
-
Multiday_precipitation_total: o total de chuva durante
vários dias, em polegadas
-
Multiday_snowfall_total: o total de neve durante vários
dias, em polegadas
-
Precipitation_inches: a quantidade de chuva em polegadas
naquele dia específico
-
Snowfall_inches: a quantidade de neve em polegadas naquele
dia específico
-
Snow_depth: a profundidade da neve ao redor da estação, em
polegadas
-
Temp_max: a temperatura máxima prevista
-
Temp_min: a temperatura mínima prevista
-
Temp_observed: a temperatura observada ao meio-dia
-
Fog: (booleano) para clima com neblina
Observe o formato das datas neste conjunto de dados: 2/22/06.
- Analise o conjunto de dados e se familiarize com a estrutura geral.
Limpeza de dados
Ao analisar todas as colunas, é possível perceber que o Dataprep tentou
inferir os tipos de dados com base nos valores mais comuns nas colunas. No
entanto, alguns dos tipos de dados inferidos não são o que se espera. Por
exemplo, a maioria dos valores em Snowfall_inches são números
inteiros. Por isso, a ferramenta inferiu que o tipo de coluna é inteiro e
marcou todos os decimais como incompatíveis. Com dados sujos, muitas vezes
você terá que fazer uma análise adicional para entender realmente qual tipo de
dados é apropriado para cada coluna.
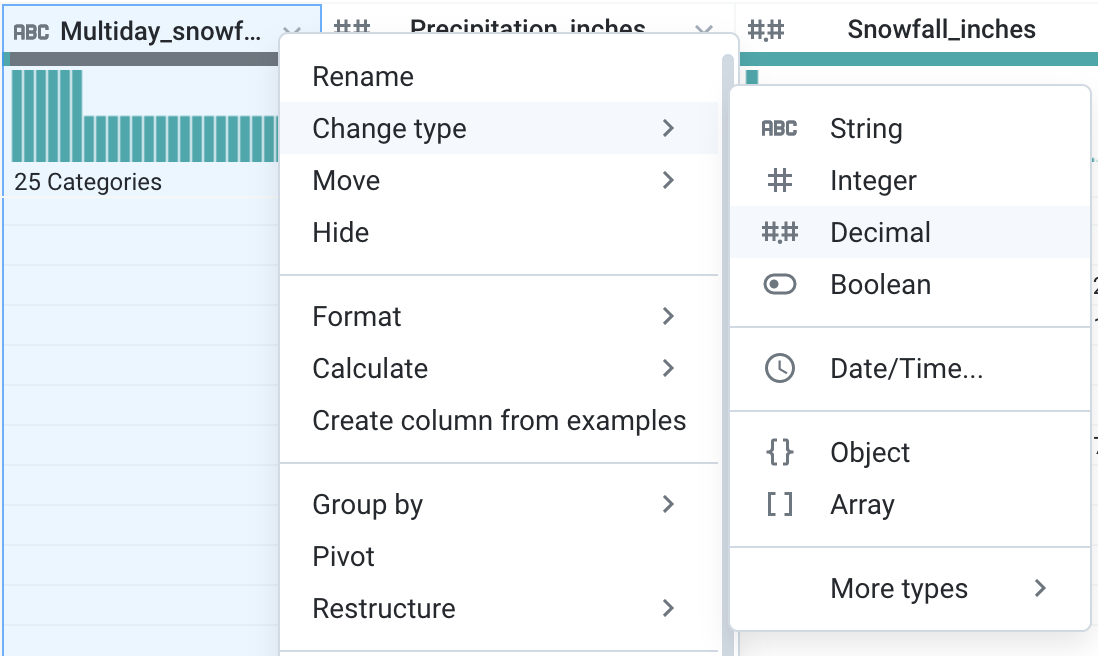
-
Para as colunas a seguir, mude o tipo de dados para
decimal. Use o menu suspenso ao lado da coluna e
selecione Mudar tipo >
Decimal.
Multiday_precipitation_totalMultiday_snowfall_totalSnowfall_inches
-
Agora, vamos conferir alguns dos valores ausentes neste conjunto de dados.
Clique na área cinza da barra de qualidade de dados para
Precipitation_inches. Ao fazer isso, o Dataprep vai sugerir
transformações para a área selecionada. Além disso, ele destaca as linhas
vazias. Role o conjunto de dados para as linhas destacadas.
-
Ao rolar para baixo, vai notar que muitas das linhas vazias em
Precipitation_inches têm valores válidos na coluna
Multiday_precipitation_total.
Nem todas as linhas seguem esse padrão, mas para aquelas que seguem, também é
muito provável que haja uma lacuna na data.
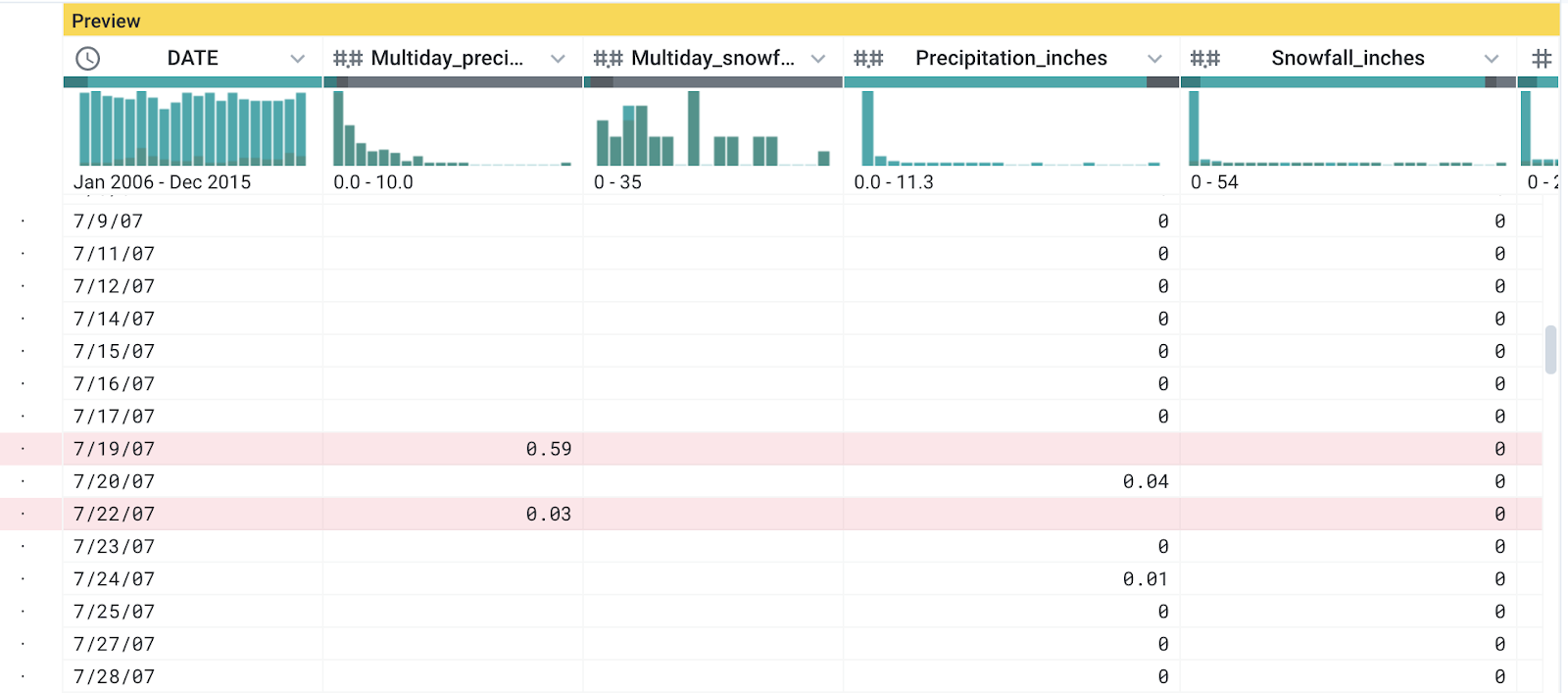
Por exemplo, nesta captura de tela, os dados das datas 7/18/07 e
7/21/07 estão faltando. Parece que, em dias de precipitação
constante, os dados não são registrados com granularidade diária.
-
É possível preencher essas datas e valores usando uma lógica mais
complicada, mas, por enquanto, podemos mesclar os valores nas colunas de
precipitação de vários dias e de um dia para organizar melhor o conjunto
de dados e mesclá-lo com os dados das escaladas.
-
Clique no cabeçalho da coluna
Multiday_precipitation_total para selecionar a coluna.
-
Mantenha pressionada a tecla CTRL ou
CMD e clique no cabeçalho de
Precipitation_inches para selecionar as duas colunas.
-
Nas sugestões, em Criar uma nova coluna, escolha a opção
COALESCE([Multiday_precipitation_total,Precipitation_inches])
e clique em Adicionar.
A função COALESCE retorna o primeiro valor não vazio encontrado
nas duas colunas, mesclando-as em uma única coluna.
-
Edite a etapa anterior do roteiro ou adicione uma nova etapa para renomear
a coluna para Merged Precipitation.
-
Repita a etapa para as colunas Snowfall_inches e
Multiday_snowfall_total. Nomeie a nova coluna como
Merged Snowfall. Por fim, mude o tipo de dados no menu
suspenso da nova coluna para decimal.
Adicionar comentários
Embora o Dataprep mostre as transformações em linguagem natural de fácil
leitura, se você não trabalhar em um roteiro por muito tempo ou compartilhá-lo
com outras pessoas, pode ser necessário decifrar o que as etapas fazem. Para
ajudar na reutilização, faça comentários nos roteiros para anotar e descrever
as etapas.
-
Clique nos três pontos para Mais ações e clique no ícone de
Comentário para inserir um comentário como uma nova etapa
do roteiro.
-
Descreva as etapas anteriores, ou seja, "As etapas combinam as polegadas
de neve com valores de vários dias".
-
Clique em Adicionar. Os comentários vão aparecer em azul
com duas barras na frente. As etapas de comentários não alteram os dados e
não são executadas durante as execuções de jobs.
Mover a linha de visualização do roteiro (RVL) e inserir etapas
Agora que você já sabe como inserir comentários, é hora de voltar e fazer um
comentário semelhante ao lado da etapa que produziu a coluna de precipitação
mesclada.
-
Para inserir uma etapa no roteiro em um local específico, você precisa mudar
a linha de visualização do roteiro (RVL, na sigla em inglês).
A linha de visualização da roteiro tem duas finalidades:
- Define o ponto em que novas etapas são adicionadas.
- Permite visualizar os dados em qualquer etapa específica.
Para definir a RVL, basta passar o cursor no espaço entre duas etapas. Uma
linha pontilhada cinza vai aparecer para indicar que você está passando o
mouse sobre uma RVL. Clique para definir a RVL nessa etapa. A
RVL ativa é indicada por uma linha pontilhada azul.
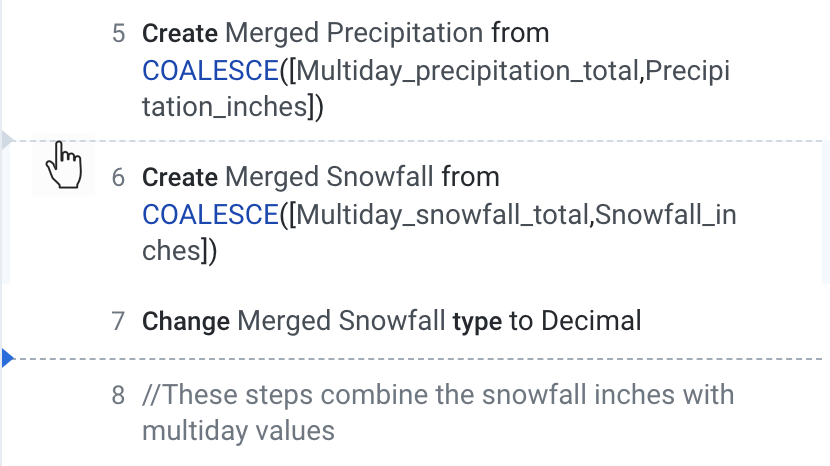
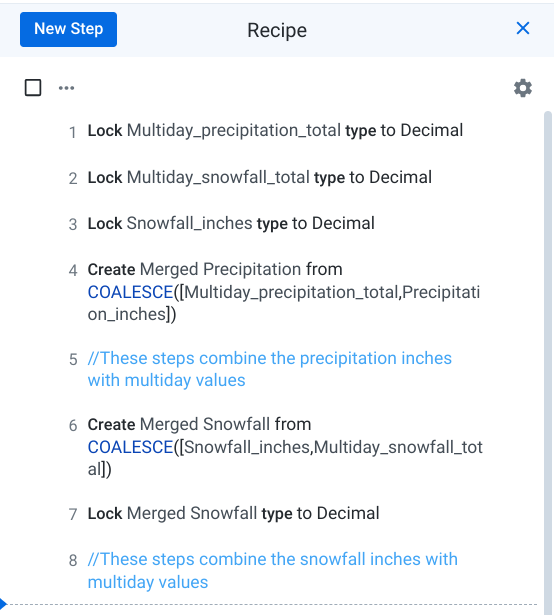
Nesta captura de tela, a RVL está entre as etapas 7 e 8.
-
Clique entre as etapas 5 e 6 para definir a RVL após a linha 5. Ao adicionar
o comentário, a etapa será inserida aqui.
Observe que, depois de definir a RVL na etapa 5, a coluna "Merged Snowfall"
não aparece mais na grade. Isso acontece porque as etapas após a RVL não são
exibidas na grade de dados, o que permite revisar rapidamente os dados após
diferentes transformações.
Observação: você também pode definir a RVL acima da etapa 1
para visualizar os dados de origem originais.
Observação: quando você executa o job em escala, todas as
etapas do roteiro ainda são calculadas, mesmo as que estão abaixo da RVL. A
RVL só controla o que você vê na grade de dados durante o design. Para evitar
que as etapas sejam calculadas na execução, você precisa desativá-las.
-
Adicione o comentário "Estas etapas combinam as polegadas de precipitação
com valores de vários dias" ao roteiro.
-
Defina a RVL de volta na parte inferior do roteiro. A página será parecida
com esta:
Dados agregados
A coleta de amostras aleatórias nos dados de escalada já deve ter terminado.
-
Mude rapidamente para os dados de escalada clicando na lista suspensa ao
lado do nome do roteiro na parte de cima.
-
Clique em Conjunto de dados com parâmetros para mudar
rapidamente para outro roteiro no fluxo.
-
Depois que o roteiro for trocado, clique novamente em
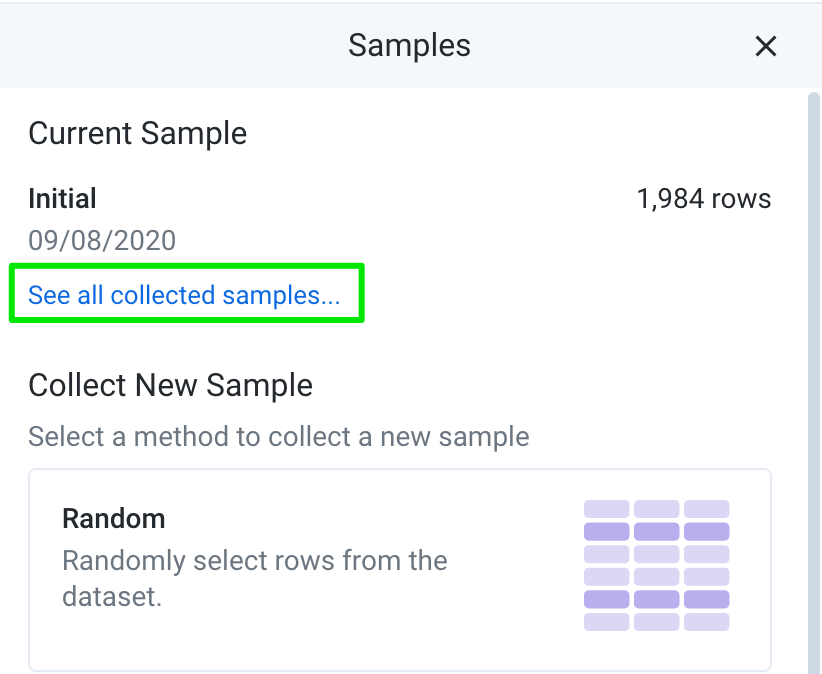
Dados iniciais para abrir o painel "Amostras".
-
No painel "Amostras", clique em
Ver todas as amostras coletadas.
-
Em "Amostras disponíveis", temos duas opções: Inicial, que
está selecionada no momento, e Aleatória. Clique em
Aleatória para mudar para essa amostra.
-
Clique em Carregar. Depois que a amostra for carregada,
você verá:
- Mais linhas
- Uma distribuição maior de datas na coluna correspondente.
Observação: como as linhas são selecionadas aleatoriamente,
os dados que aparecem na sua tela serão diferentes das capturas de tela do
laboratório.
Agora que tem mais linhas de dados, é possível resumir os dados para facilitar
a análise downstream. Como viu ao abrir o conjunto de dados pela primeira vez,
ele tem vários grupos por dia.
-
Clique no ícone Tabela dinâmica para criar uma tabela
dinâmica.
-
Uma tabela dinâmica é uma tabela de estatísticas que resume os
dados de uma tabela mais extensa. O Dataprep permite criar tabelas com
facilidade mostrando uma prévia da tabela resultante.
Na seção Rótulos de linha, selecione a coluna
Data.
Observe como a grade muda para mostrar a aparência da tabela.
-
Na seção Valores, insira estes dois:
SUM(Size) e SUM(Summit).
As outras colunas (#* e *Leader Zip Code) serão descartadas porque não são
necessárias para a análise.
-
Clique em Adicionar para aceitar a agregação. A tabela
dinâmica resume o número total de alpinistas que partiram e chegaram ao
topo em cada dia.
-
Agora você pode calcular a taxa de sucesso geral para qualquer dia
dividindo sum_Summit por sum_Size. Na barra de
ferramentas, clique no ícone Functions e selecione
Math > DIVIDE.
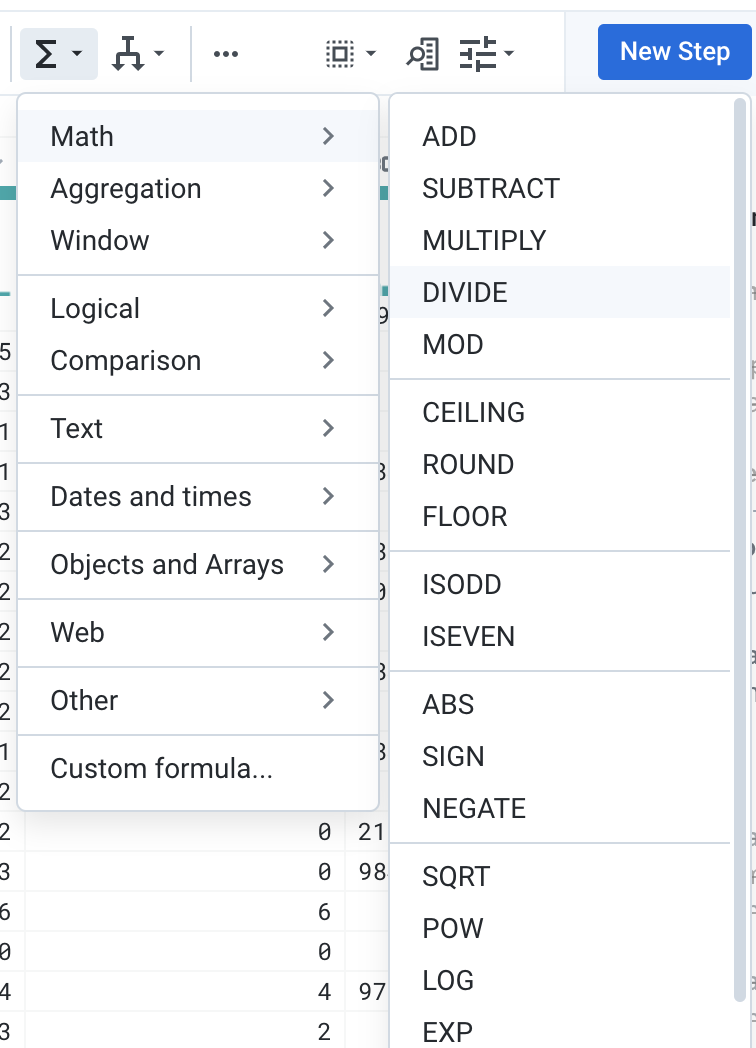
-
Para a fórmula, use
DIVIDE(sum_Summit, sum_Size) e nomeie a
nova coluna como Summit rate. Clique em
Adicionar.
Condicionais e casos
Dependendo da amostra, talvez você veja que o histograma da da taxa "summit"
mostra valores acima de 1.
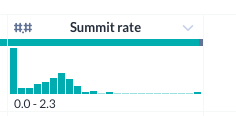
Isso é estranho, porque um valor acima de 1 significaria que mais pessoas
chegaram ao cume do que subiram a montanha em um determinado dia. Isso talvez
indique que as pessoas estão acampando na montanha por vários dias ou mudando
de grupo de expedição, mas pode distorcer algumas análises se a taxa de
sucesso for superior a 100%. Em seguida, vamos criar uma condição para
corrigir alguns dos problemas.
-
Na barra de ferramentas, escolha
Condições > Caso em condições personalizadas.
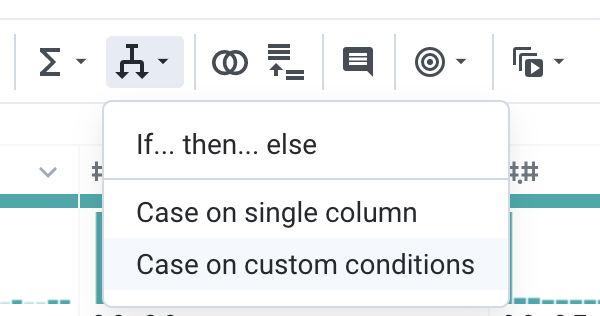
-
Em Condições, a primeira caixa é a condição a ser avaliada e a segunda é o
valor se o caso for verdadeiro. Insira
1 < {Summit rate} na primeira caixa e 1 na
segunda. Isso significa que, se a taxa for maior que 1, basta defini-la
como 1. As chaves { } em torno do nome da coluna são usadas para indicar
colunas com espaços em branco.
-
Você pode adicionar mais casos clicando em Adicionar ao
lado do argumento "Condições".
Novas caixas de condição vão aparecer. Insira
ISNULL({Summit rate}) na primeira caixa e 0 na
segunda. Para algumas linhas com sum_Size igual a 0, o cálculo
anterior de Summit rate teria sido dividido por 0 e produzido um
valor nulo. Por isso, defina esse valor como 0.
-
Em "Valor padrão", insira {Summit rate}. Para as linhas que
não forem avaliadas como verdadeiras nas condições anteriores, o valor
atual é preenchido por Summit rate.
-
Nomeie a nova coluna como "Taxa de sucesso" e adicione a etapa ao
roteiro. Clique em Adicionar. A condição deve ser
parecida com esta:
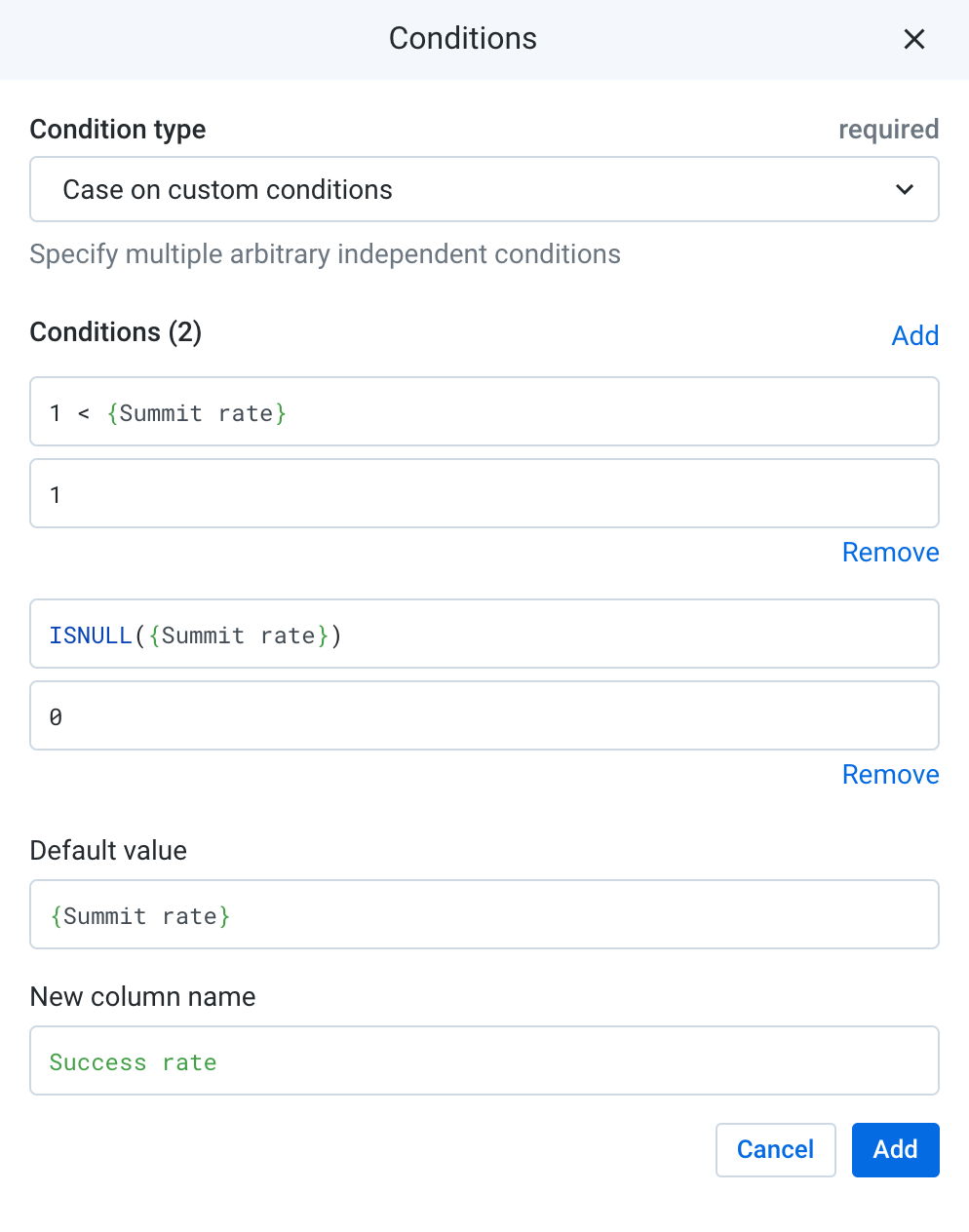
Mesclar conjuntos de dados
Agora que você tem os dados de escalada resumidos no nível do dia, está tudo
pronto para mesclar os dados meteorológicos.
-
Crie uma nova etapa de mesclagem clicando no ícone Mesclar.
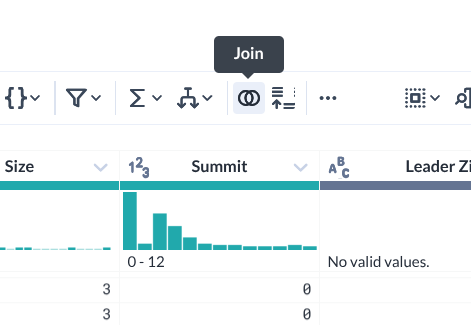
-
Selecione o conjunto de dados climáticos que deseja mesclar e clique em
Aceitar.
-
Mude o tipo de mesclagem para Esquerda.
-
Edite a chave de mesclagem para corresponder à coluna
Data = coluna DATE.
Na pré-visualização, observe que o Dataprep consegue fazer a junção em uma
coluna de data e hora que não está no mesmo formato.
Como uma mesclagem à esquerda foi selecionada, algumas linhas não têm
correspondências. (Dependendo da amostra, a porcentagem de linhas não
correspondentes vai variar.)
-
Clique em Próxima para selecionar as colunas de saída.
Mantenha as colunas a seguir. O restante será descartado automaticamente
após a mesclagem.
DateDATEsum_Sizesum_SummitSuccess rateMerged PrecipitationMerged SnowfallSnow_depthTemp_observedFog
-
Clique em Revisar. A mesclagem vai ficar assim:
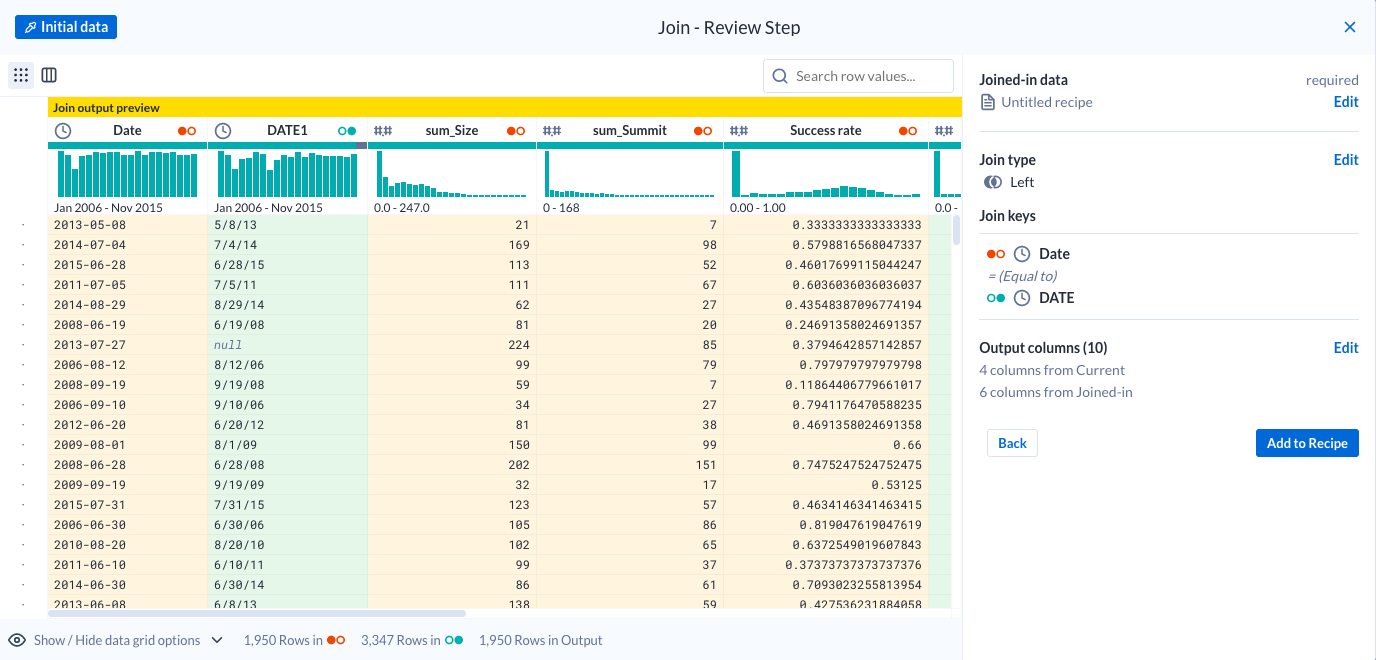
-
Clique em Adicionar ao roteiro.
-
Agora que a mesclagem foi adicionada, você notará que faltam dados
meteorológicos para alguns dias, então não será possível usá-los na
análise. Você pode excluir as linhas em que DATE1 está faltando
ou mantê-las no conjunto de dados.
Tarefa 5: publicar no BigQuery
Agora que mesclou os dados, você pode publicar os resultados no BigQuery.
-
Clique no botão Executar para criar uma saída.
-
Na seção "Ações de publicação", o Dataprep vai criar um arquivo CSV por
padrão. Passe o cursor sobre a ação e clique no botão
Editar para mudar o destino de publicação para o
BigQuery.
-
Escolha BigQuery na lista de sistemas à esquerda.
-
Escolha o banco de dados Dataprep e clique em
Criar uma nova tabela à direita.
-
Com base nos nomes das colunas que você criou, uma mensagem de erro vai
aparecer na parte de cima.

Isso indica que o BigQuery não pode usar nomes de colunas com espaços e o
conjunto de dados tem alguns.
-
Clique em Cancelar para sair da caixa de diálogo "Ação de
publicação" e em clique em Cancelar novamente para sair
da caixa de diálogo "Executar job". Abra novamente o roteiro
Conjunto de dados com parâmetro.
-
O Dataprep pode corrigir rapidamente problemas com nomes de colunas
removendo todos os caracteres especiais. Clique no chevron ao lado de
qualquer coluna e escolha Renomear.
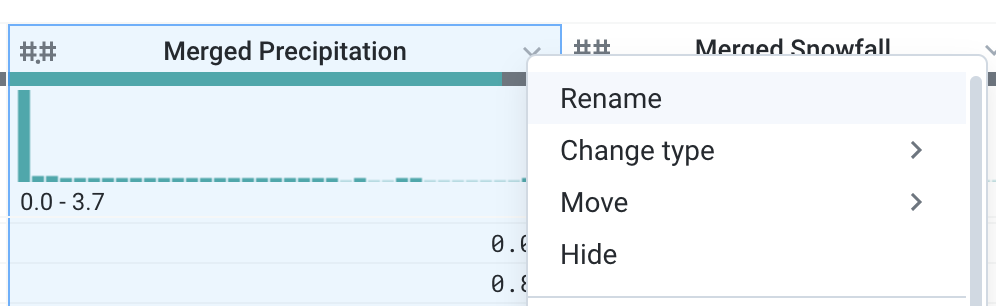
-
Por padrão, a transformação "Renomear" pede que você renomeie a coluna
manualmente. No entanto, ele também vem com várias funções pré-criadas,
incluindo uma função de limpeza geral.
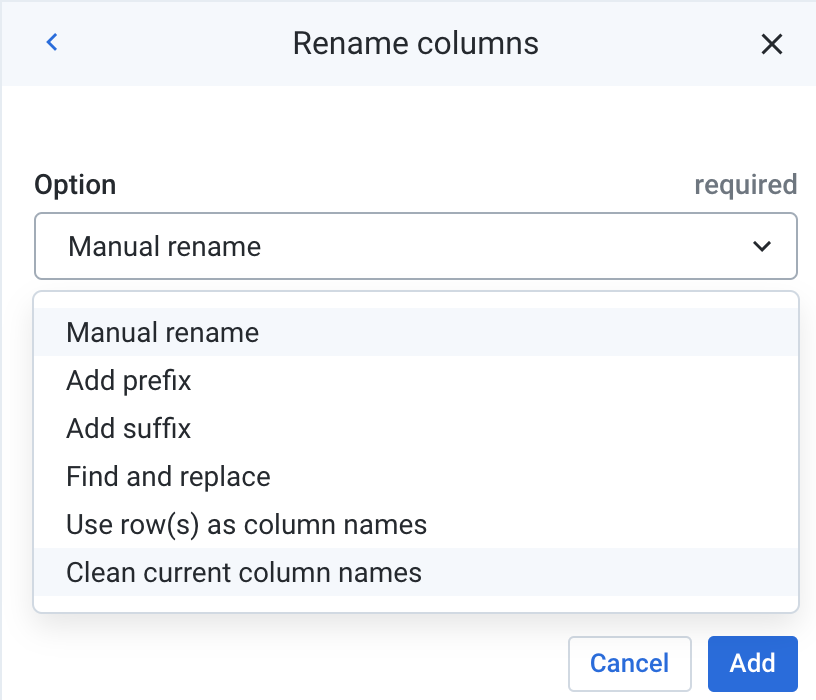
No menu suspenso Opção, escolha
Limpar nomes de colunas atuais. Observe como a
pré-visualização afeta todas as colunas e substituiu todos os espaços por
sublinhados. Clique em Adicionar.
-
Agora que os nomes das colunas estão corrigidos, repita as etapas 1 a 4 e
crie uma nova tabela chamada RainierLab. Escolha
Truncar a tabela em cada execução e
Atualizar.
-
Clique em Executar. Isso pode levar alguns minutos.
Clique em Verificar meu progresso para conferir o objetivo.
Publicar no BigQuery
Visualizar os resultados
Quando o job terminar, crie uma visualização rápida dos dados.
Abrir o console do BigQuery
- No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você verá a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e as notas de lançamento.
- Clique em OK.
O console do BigQuery vai abrir.
- No editor de consultas SQL, execute a seguinte consulta:
select * from Dataprep.RainierLab;
-
Quando os resultados forem retornados, em "Resultados da consulta", clique
no menu suspenso Abrir em e selecione
Data Studio. Isso vai abrir o Data Studio em outra guia.
-
Aceite todos os contratos do Data Studio.
-
Agora é possível criar uma visualização simples. Clique em
Adicionar um gráfico e escolha
Linha > Gráfico de combinações empilhadas.
-
Na guia "Configuração" à direita, mantenha
Dimensão do período como Data (Date) e
Dimensão como Date.
-
Ative as Métricas opcionais. Arraste
Success_rate, Merged_Precipitation e
Merged_Snowfall dos campos disponíveis para a seção
Métrica. Remova as outras métricas e posicione a métrica
Success_rate acima das outras.
-
Por fim, classifique por data e em ordem crescente. Sua configuração será
parecida com o seguinte:
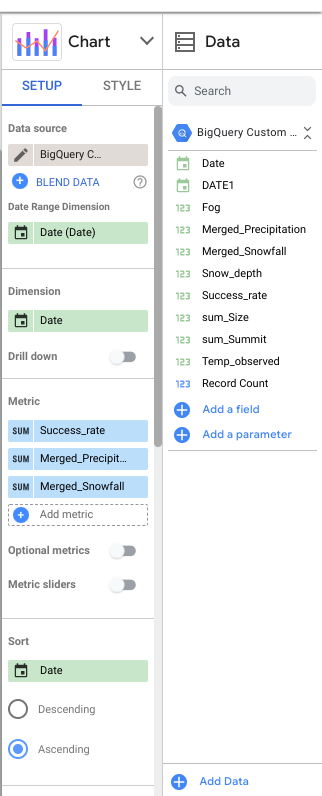
-
Na guia Estilo, defina o eixo da série 1 como
Direita e o restante das séries como
Esquerda.
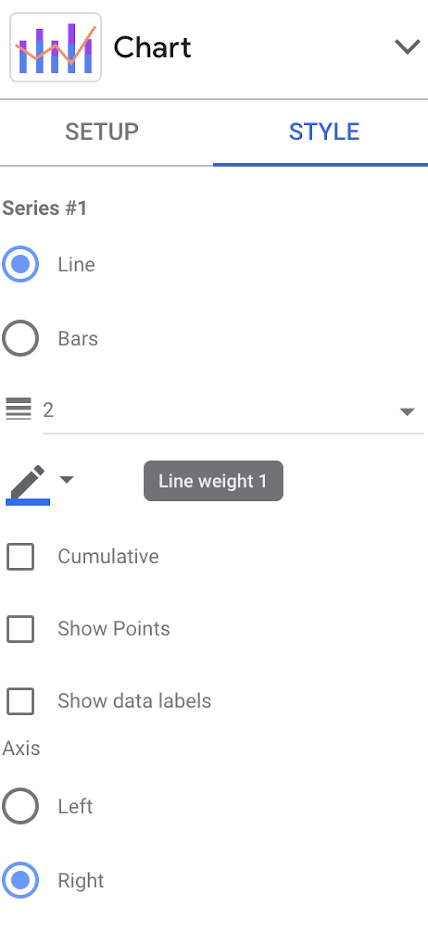
Você pode testar as outras configurações de estilo para ver o que fica melhor.
- O gráfico vai ficar parecido com isso.
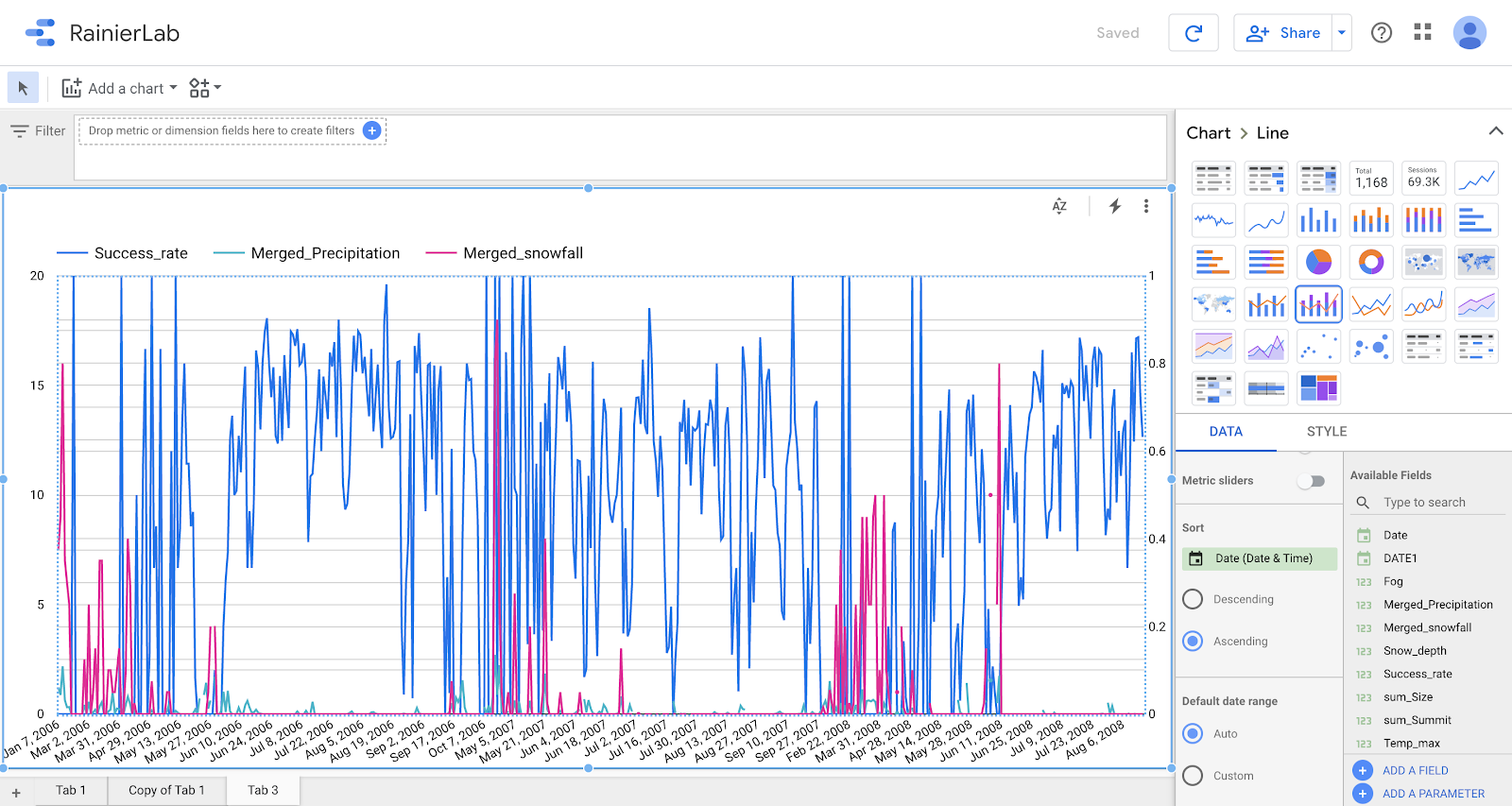
Com base no gráfico, o que você pode concluir sobre a relação entre o sucesso
da escalada e a precipitação e a queda de neve?
-
Teste os outros recursos arrastando-os de "Campos disponíveis" para
"Métricas". Existe um melhor indicador de sucesso para chegar ao cume?
Tarefa 6: exportar o fluxo (opcional)
No seu projeto do Dataprep, todos os fluxos são salvos e podem ser
reutilizados. No entanto, no Qwiklabs, esses projetos são temporários e
excluídos após o laboratório. Com o Dataprep, é possível exportar os fluxos
para usar com sistemas de controle de versões, importar para outro ambiente ou
compartilhar com colegas. Para salvar o trabalho para o próximo laboratório,
você pode exportar o fluxo criado.
-
Volte para a visualização do fluxo Rainier Climb.
-
No canto superior direito, abra o menu Mais (...) e
selecione Exportar.
-
Salve o arquivo zip na sua área de trabalho local como
flow_Rainier_Climbs.zip. Você pode usar esse arquivo no próximo
laboratório, se quiser.
Parabéns!
Neste laboratório, você teve experiência prática com o Dataprep ao criar
conjuntos de dados parametrizados, além de usar novas amostras e criar casos
condicionais e agregações. Você também manipulou datas e horas, limpou os
cabeçalhos para publicar no BigQuery e visualizou os resultados no Data
Studio.
Próximas etapas / Saiba mais
-
Leia os
guias de instruções
para saber como descobrir, limpar e melhorar os dados com o Google Dataprep.
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 10 de outubro de 2025
Laboratório testado em 10 de outubro de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





