GSP1320

Visão geral
Este laboratório é voltado à implementação e à implantação de um serviço de
agente cliente com o
Kit de Desenvolvimento de Agente
(ADK) para criar um agente de IA que usa ferramentas remotas, como um servidor
MCP. O princípio arquitetônico central deste laboratório é a separação de
responsabilidades: a camada de raciocínio (agente) comunica-se com a camada de
ferramentas (servidor MCP) por uma API segura.
Neste laboratório, já foi implantado um servidor MCP que contém dados sobre os
animais de um zoológico fictício para LLMs, por exemplo, ao usar a CLI do
Gemini. Você vai criar um agente de guia turístico, na forma de um aplicativo
Python, para o zoológico fictício. O agente usa o servidor MCP para acessar
detalhes sobre os animais do zoológico e usa a Wikipédia para criar a melhor
experiência de turimo possível.

Por fim, você vai implantar o agente de guia turístico no Google Cloud Run
para que todos os visitantes do zoológico possam acessá-lo, em vez de só na
sua máquina.
Pré-requisitos
-
Um servidor MCP em execução no Cloud Run ou o URL do serviço associado.
- Ter um projeto do Google Cloud com o faturamento ativado.
O que você vai aprender
Neste laboratório, você vai aprender a fazer o seguinte:
- Estruturar um projeto Python para implantação com ADK.
- Implementar um agente que usa ferramentas com o google-adk.
-
Conectar um agente a um servidor MCP remoto para o conjunto de ferramentas
dele.
-
Implantar um aplicativo Python como um contêiner sem servidor no Cloud Run.
-
Configurar a autenticação segura de serviço para serviço usando papéis do
IAM.
- Excluir recursos do Cloud para evitar custos futuros.
Você vai precisar de
- Uma conta do Google Cloud e um projeto do Google Cloud
-
Um navegador da web, como o
Chrome
Por que implantar no Cloud Run?
O Cloud Run é uma ótima opção para hospedar agentes do ADK porque é uma
plataforma sem servidor, ou seja, você pode dedicar todo seu tempo ao código
em vez de cuidar da infraestrutura. O Cloud Run cuida do trabalho operacional
para você.
Pense nele como uma loja pop-up: ela só abre e usa recursos quando há clientes
(solicitações). Se nenhum cliente aparece, ela fecha completamente. Assim,
você não paga por uma loja vazia.
Principais recursos do Cloud Run
Executa contêineres em qualquer lugar
-
É possível usar contêineres (imagens do Docker) que têm seu app dentro.
- O Cloud Run executa todos na infraestrutura do Google.
-
Sem você ter a dor de cabeça de lidar com a aplicação de patches no SO,
fazer escalonamentos ou configurar VMs.
Escalonamento automático
-
Se 0 pessoas estiverem usando seu app → 0 instâncias serão executadas
(quando o app está inativo, você não tem custos financeiros).
-
Se o serviço receber 1.000 solicitações, ele vai gerar quantas cópias forem
necessárias.
Sem estado por padrão
- Cada solicitação pode ser encaminhada a uma instância diferente.
-
Caso você precise armazenar estado, use um serviço externo como Cloud SQL,
Firestore ou Redis.
Funciona com qualquer linguagem ou framework
-
Desde que possa ser executado em um contêiner Linux, o Cloud Run não se
importa se você usa Python, Go, Node.js, Java ou .Net.
Pague só pelos que você usar
- Cobrança por solicitação + tempo de computação (até 100 ms).
- Você não paga por recursos ociosos como em uma VM tradicional.
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
Clique em Ativar o Cloud Shell  na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.
-
Clique nas seguintes janelas:
- Continue na janela de informações do Cloud Shell.
- Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
- Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Tarefa 1: baixe e instale o ADK e crie uma pasta de projeto
Nesta tarefa, você vai ativar as APIs relevantes e criar uma pasta de projeto
para armazenar o código-fonte da implantação do seu projeto Python.
Ative as APIs e defina as variáveis de ambiente
-
Para abrir o editor no Cloud Shell no seu diretório principal, clique em
Abrir editor.
-
Na barra de ações do editor do Cloud Shell, clique em
Visualizar > Terminal.
Observação: talvez você tenha que aumentar a altura da janela do navegador para acessar a opção "Visualizar" no menu.
Use esta janela como seu ambiente de desenvolvimento integrado (IDE) com o
editor do Cloud Shell (acima) e o terminal do Cloud Shell (abaixo) ao longo de
todo o laboratório.
Feche qualquer outro tutorial ou painel do Gemini que aparecer no lado direito
da tela. Assim você terá mais espaço na janela do editor de código.
-
No terminal, insira este comando para configurar seu projeto:
gcloud config set project {{{project_0.project_id | filled in at lab start}}}
Saída esperada: você vai receber uma mensagem de saída
confirmando a propriedade atualizada.
Observação: caso o Cloud Shell atinja o tempo limite ou seja reiniciado, você terá que configurar o projeto outra vez.
-
Execute este comando para ativar todos os serviços necessários:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
Saída esperada: você vai receber uma mensagem de saída
confirmando que a operação foi concluída.
Clique em Verificar meu progresso para conferir o objetivo.
Ativar as APIs
Crie os diretórios do projeto
-
Execute o comando abaixo, que cria uma pasta principal no laboratório para
o código-fonte do agente:
mkdir zoo_guide_agent && cd zoo_guide_agent
-
Em seguida, execute este comando para criar um ambiente virtual:
uv venv
-
Execute este comando para ativar o ambiente virtual:
source .venv/bin/activate
Agora já é possível criar o arquivo requirements.txt. Ele lista
as bibliotecas Python que o agente do zoológico precisa.
-
Execute o comando a seguir para criar o arquivo no diretório
zoo_guide_agent e abrir no editor do Cloud Shell para
fazer edições nele:
cloudshell edit requirements.txt
-
Adicione o texto abaixo ao arquivo requirements.txt e
pressione CTRL+S para salvar as alterações:
google-adk==1.12.0
langchain-community
wikipedia
-
Execute o comando a seguir no terminal para o gerenciador de pacotes
uv instalar seus pacotes Python:
uv pip install -r requirements.txt
-
Defina variáveis para seu projeto, região e usuário atuais com estes
comandos:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=$(gcloud compute project-info describe \
--format="value(commonInstanceMetadata.items[google-compute-default-region])")
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SERVICE_ACCOUNT="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Observação: se o Cloud Shell expirar ou reiniciar, você terá que inicializar as variáveis acima de novo.
-
Crie e abra um arquivo .env para autenticar o agente no
diretório zoo_guide_agent com este comando:
cloudshell edit .env
O diretório contendo o arquivo .env é aberto no editor do Cloud
Shell.
-
Adicione o conteúdo abaixo ao arquivo .env e salve as
alterações:
MODEL="{{{ project_0.startup_script.gemini_flash_model_id | filled in at lab start }}}"
SERVICE_ACCOUNT="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Conecte-se ao endpoint do servidor MCP seguro
Nesta seção, você estabelece uma conexão com o servidor MCP remoto.
-
Volte ao terminal do Cloud Shell e execute o comando abaixo para dar
permissão à identidade do serviço do Cloud Run para chamar o servidor MCP
remoto:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
-
Execute o comando abaixo para salvar o URL do servidor MCP em uma variável
de ambiente:
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.${REGION}.run.app/mcp/" >> .env
-
Agora, você vai criar o arquivo __init__.py. Esse arquivo
informa ao Python que o diretório zoo_guide_agent é um
pacote:
cloudshell edit __init__.py
-
No editor do Cloud Shell que será aberto, adicione o código a seguir ao
arquivo __init__.py e salve as alterações:
from . import agent
Tarefa 2: crie o fluxo de trabalho do agente
Nesta tarefa, você vai configurar o fluxo de trabalho do agente de guia
turístico do zoológico. Para começar, as bibliotecas relevantes têm que ser
importadas para a configuração inicial. Depois, é preciso estabelecer os
agentes especialistas e as ferramentas que o agente do zoológico vai usar. Em
seguida, é hora de definir o agente do fluxo de trabalho e montar o fluxo de
trabalho principal.
Crie o arquivo principal agent.py
Etapa 1: importe as bibliotecas e faça a configuração inicial
O primeiro bloco importa todas as bibliotecas necessárias do ADK e do Google
Cloud. Ele também configura a criação de registros em log e carrega as
variáveis de ambiente do arquivo .env, o que é essencial para
acessar o modelo e o URL do servidor.
Etapa 2: defina as ferramentas (recursos) do agente

A qualidade de um agente é limitada às ferramentas que ele pode usar. Nesta
seção, você vai definir todos os recursos do seu agente, inclusive uma função
personalizada para salvar dados, uma ferramenta MCP que se conecta ao seu
servidor MCP seguro e uma ferramenta da Wikipédia.
Explicação das três ferramentas
-
add_prompt_to_state: 📝ferramenta que lembra
as perguntas dos visitantes do zoológico. Quando um visitante pergunta
"Onde estão os leões?", a ferramenta salva essa pergunta específica na
memória para que os outros agentes no fluxo de trabalho saibam o que
pesquisar.
Como: é uma função Python que grava o comando do
visitante no dicionário compartilhado tool_context.state. O
contexto da ferramenta representa a memória de curto prazo do agente para
uma única conversa. Os dados salvos no estado por um agente podem ser
lidos pelo próximo no fluxo de trabalho.
-
MCPToolset: 🦁usado para conectar o agente
do guia turístico ao servidor MCP do zoológico pré-implantado neste
laboratório. Esse servidor tem ferramentas especiais para pesquisar
informações específicas sobre os animais do zoológico, como nome, idade e
localização.
Como: o servidor estabelece uma conexão segura com o URL
do servidor particular do zoológico. Ele usa
get_id_token para receber automaticamente um "cartão de
acesso" seguro (um token de ID da conta de serviço) para comprovar a
identidade e ganhar acesso.
-
LangchainTool: 🌍dá ao agente de guia
turístico conhecimento geral do mundo. Quando um visitante faz uma
pergunta que não está no banco de dados do zoológico, como "O que leões
comem na natureza?", a ferramenta permite que o agente procure a resposta
na Wikipédia.
Como: a ferramenta age como um adaptador, permitindo que
o agente use a ferramenta pré-criada WikipediaQueryRun da biblioteca
LangChain.
Recursos:
Etapa 3: defina os agentes especialistas

Nesta seção, você vai definir dois agentes especialistas: o de pesquisa e o de
formatação de respostas. O agente de pesquisa é o "cérebro" da sua
operação. Ele recebe o comando do usuário do
Estado compartilhado, examina as ferramentas avançadas do
servidor MCP do zoológico e da Wikipédia e decide as que serão usadas para
encontrar a resposta.
O papel do agente de formatação de respostas é a apresentação. Ele
não usa ferramentas para encontrar informações novas. Em vez disso, ele pega
os dados brutos do agente de pesquisa que foram passados pelo Estado e usa a
habilidade de linguagem do LLM para criar uma resposta natural e
conversacional.
Etapa 4: defina o agente de fluxo de trabalho
O agente de fluxo de trabalho age como o gerente dos "bastidores" do passeio
pelo zoológico. Ele recebe um comando de pesquisa e garante que os dois
agentes definidos na etapa 3 façam os trabalhos na ordem certa: primeiro a
pesquisa, depois a formatação. Isso cria um processo previsível e confiável
para responder às perguntas dos visitantes do zoológico.
Como: ele é um SequentialAgent, um tipo especial
de agente que não pensa por conta própria. Seu único trabalho é executar uma
lista de sub_agents (o pesquisador e o formatador) em uma
sequência fixa, transmitindo automaticamente a memória compartilhada de um
para o outro.
Etapa 5: monte o fluxo de trabalho principal

O fluxo de trabalho principal é designado pelo root_agent, o que
é usado pela estrutura do ADK como ponto de partida para todas as novas
conversas. A função principal desse agente é orquestrar o processo geral. Ele
age como o controlador inicial, cuidando do primeiro turno da conversa.
Seu arquivo agent.py está concluído.
Criando desse jeito, você entende como cada componente (ferramentas, agentes
de worker e agentes de gerenciamento) tem um papel específico para entregar o
sistema inteligente final. Próxima parada: implantação!
Tarefa 3: prepare o aplicativo para implantação
Com o ambiente local pronto, a próxima etapa é preparar o projeto do Google
Cloud para a implantação do agente de guia turístico do zoológico.
Essa etapa envolve uma verificação final da estrutura de arquivos do agente
para garantir que ela seja compatível com o comando de implantação. Pra fechar
com chave de ouro, configure uma permissão essencial do IAM pra que o serviço
do Cloud Run possa agir por você e chamar os modelos da Agent Platform. Com
essa etapa concluída, você garante que o ambiente de nuvem está pronto para
executar o agente.
-
Volte ao terminal do Cloud Shell e execute este comando para carregar as
variáveis na sua sessão do shell:
source .env
-
Execute o comando a seguir para conceder à conta de serviço o papel de
usuário da Agent Platform com permissão para fazer previsões e chamar
modelos do Google:
# Grant the "Agent Platform User" role to your service account
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
Tarefa 4: implante o agente usando a CLI do ADK
Com o código local pronto e o projeto do Google Cloud preparado, é hora de
implantar o agente.
Nesta tarefa, você vai usar o comando adk deploy cloud_run, uma
ferramenta conveniente que automatiza todo o fluxo de trabalho de implantação.
Esse comando único empacota seu código, cria uma imagem de contêiner, envia
para o Artifact Registry e executa o serviço no Cloud Run para que ele fique
acessível na web.
Implante o agente
-
Execute este comando para implantar o agente:
# Run the deployment command
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=zoo-tour-guide \
--with_ui \
.
-
Se você receber uma mensagem perguntando se quer continuar e/ou permitir
invocações não autenticadas em [zoo-tour-guide], digite
Y em cada caso e aperte ENTER.
Observação: a execução do comando de implantação pode levar de 5 a 10 minutos.
-
Execute o comando abaixo para mudar as configurações do serviço do Cloud
Run atual:
gcloud run services update zoo-tour-guide \
--region=$REGION \
--update-labels=dev-tutorial=codelab-adk
Acesse o link de implantação
-
Depois que o agente for implantado no Cloud Run, segure CTRL e clique no
URL do serviço gerado para abrir o conteúdo em uma nova
guia do navegador.
O URL provavelmente terá o formato a seguir.
Saída de URL do serviço:
https://zoo-tour-guide-{{{project_0.startup_script.project_number | filled in at lab start}}}.{{{project_0.default_region | filled in at lab start}}}.run.app
Como você usou a flag --with_ui na hora de implantar no Cloud
Run, a interface de desenvolvedor do ADK vai aparecer.
Observação: qualquer pessoa com o URL pode acessar esse agente. Por isso, essa abordagem é mais adequada para fins de teste.
Clique em Verificar meu progresso para conferir o objetivo.
Implantar o agente
Tarefa 5: teste o agente implantado
Com o agente ativo no Cloud Run, chegou a hora de fazer um teste para
confirmar se tudo correu bem na implantação e se o agente está funcionando
como esperado. Você precisa usar o URL do serviço público para acessar a
interface da web do ADK e interagir com o agente.
-
Abra o URL público do serviço do Cloud Run gerado na tarefa anterior no
seu navegador da web ou clique no URL da saída para abrir uma nova guia do
navegador. Assim, você abre a interface de desenvolvedor do ADK.
-
Deixe a opção Streaming de token
Ligada no canto superior direito da barra de ferramentas
do ADK.
Pronto! Você já pode interagir com o agente do zoológico.
-
Digite Hello na caixa de comando e aperte ENTER para começar
uma nova conversa.
Observe o resultado. O agente deve responder rapidamente com a saudação
padrão:
"Olá! Sou o guia turístico do zoológico. Estou pronto para ensinar tudo sobre os animais fantásticos que temos aqui. O que você quer aprender hoje?"
-
Fale com o agente de guia do zoológico. Digite a consulta a seguir para
começar uma nova conversa:
Onde estão os pinguins?
Uma resposta parecida com esta vai aparecer:
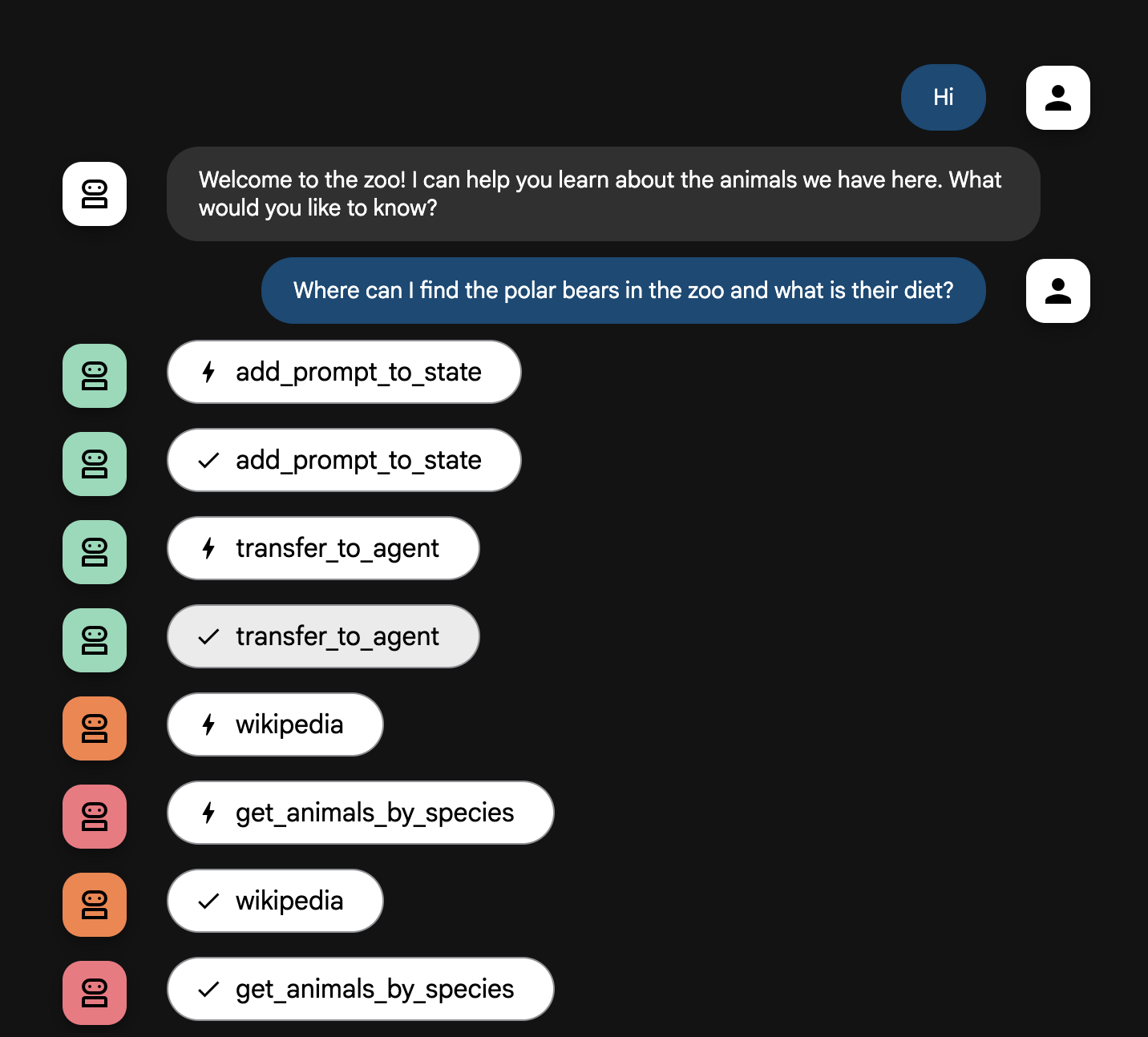

Explicação do fluxo do agente
Seu sistema opera como uma equipe inteligente com vários agentes. O processo é
guiado por uma sequência clara para garantir um fluxo tranquilo e eficiente,
da pergunta do usuário à resposta final detalhada.
1. Agente de boas-vindas do zoológico (a recepção)
Todo o processo começa com o agente recepcionista.
Função: começar a conversa. A instrução é cumprimentar o
usuário e perguntar sobre qual animal ele quer saber mais.
Ferramenta: quando o usuário responde, o Recepcionista usa
add_prompt_to_state para capturar as palavras exatas, por exemplo, "fale sobre
os leões" e salvar na memória do sistema.
Transferência: depois de salvar o comando, o controle passa
imediatamente para o subagente tour_guide_workflow.
2. Pesquisador Geral (o mestre das pesquisas)
Essa é a primeira etapa do fluxo de trabalho principal, o "cérebro" da
operação. Em vez de uma equipe, você passa a interagir com um único agente
altamente qualificado que tem acesso a todas as informações disponíveis.
Função: analisar a pergunta do usuário e criar um plano
inteligente. Com o recurso avançado de uso de ferramentas do modelo de
linguagem, o agente decide se precisa de:
- Dados internos dos registros do zoológico (pelo servidor MCP).
- Conhecimento geral da web (pela API Wikipedia).
- Ou dos dois, em caso de perguntas mais complexas.
Ação: o agente executa as ferramentas necessárias para
coletar todos os dados brutos exigidos. Por exemplo, se perguntarem "Quantos
anos os leões têm e o que eles comem na natureza?", ele vai chamar o servidor
MCP para saber as idades e a ferramenta Wikipedia para encontrar informações
sobre a dieta.
3. Formatador de respostas (o apresentador)
Depois que o Pesquisador Geral reúne todos os fatos, esse é o último agente a
ser executado.
Função: ser nosso guia amigável do zoológico. Ele pega dados
brutos de uma ou das duas fontes e melhora a qualidade deles.
Ação: resumir todas as informações em uma resposta
individual, coerente e interessante. Seguindo as instruções, ele começa
apresentando as informações específicas do zoológico e depois conta fatos
gerais interessantes.
O resultado final: o texto gerado por esse agente é a
resposta completa e detalhada que aparece na tela da conversa para o usuário.
Próximas etapas / Saiba mais
Para mais informações sobre como criar agentes, confira estes recursos:
Tarefa 6: limpe o ambiente
Para evitar custos futuros, você vai excluir os recursos do Cloud criados
neste laboratório.
Parabéns!
Neste laboratório, você aprendeu a estruturar projetos Python para implantar
com a interface de linha de comando do ADK, implementou um fluxo de trabalho
multiagente, se conectou a um servidor MCP remoto para acessar ferramentas,
melhorou dados internos integrando ferramentas externas como a API Wikipedia e
implantou o agente como um contêiner sem servidor no Cloud Run.
Manual atualizado em 13 de outubro de 2025
Laboratório testado em 13 de outubro de 2025
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





