GSP1350

Übersicht
In diesem Lab geht es um die Implementierung und Bereitstellung eines
Client-KI-Agentendienstes mit dem
Agent Development Kit (ADK),
um einen KI-Agenten zu erstellen, der Remote-Tools wie einen MCP-Server
verwendet. Das wichtigste architektonische Prinzip, das in diesem Lab gezeigt
wird, ist die Trennung von Zuständigkeiten. Eine separate Problemlösungsebene
(der KI-Agent) kommuniziert über eine sichere API mit einer separaten
Toolebene (dem MCP-Server).
In diesem Lab ist für Sie bereits ein MCP-Server bereitgestellt, der LLMs
Daten zu den Tieren in einem fiktiven Zoo zur Verfügung stellt, z. B. bei der
Verwendung der Gemini CLI. In diesem Lab erstellen Sie dann einen
Zooführungs-KI-Agenten, der aus einer Python-Anwendung für den fiktiven Zoo
besteht. Der KI-Agent nutzt den MCP-Server, um Details zu den Zootieren
abzurufen, und Wikipedia, um die bestmögliche Führung zu bieten.

Zum Schluss stellen Sie den Zooführungs-KI-Agenten in Google Cloud Run bereit,
damit alle Zoobesucherinnen und -besucher darauf zugreifen können und er nicht
nur lokal ausgeführt wird.
Voraussetzungen
- Ein laufender MCP-Server in Cloud Run oder die zugehörige Dienst-URL
- Ein Google Cloud-Projekt mit aktivierter Abrechnungsfunktion
Lerninhalte
Aufgaben in diesem Lab:
- Python-Projekt für die ADK-Bereitstellung strukturieren
- Mit google-adk einen KI-Agenten implementieren, der Tools verwendet
-
KI-Agenten mit einem Remote-MCP-Server verbinden, um das Toolset darauf zu
verwenden
- Python-Anwendung als serverlosen Container in Cloud Run bereitstellen
-
Sichere Dienst-zu-Dienst-Authentifizierung mit IAM-Rollen konfigurieren
- Cloud-Ressourcen löschen, um zukünftige Kosten zu vermeiden
Weitere Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
-
Ein Webbrowser wie Chrome
Warum in Cloud Run bereitstellen?
Cloud Run ist eine hervorragende Wahl für das Hosting von ADK-KI-Agenten, da
es sich um eine serverlose Plattform handelt. Sie können sich also auf Ihren
Code konzentrieren und müssen sich nicht um die Verwaltung der zugrunde
liegenden Infrastruktur kümmern. Cloud Run übernimmt die operative Arbeit für
Sie.
Stellen Sie sich das wie einen Pop-up-Store vor: Er öffnet nur, wenn Kundinnen
und Kunden (Anfragen) kommen, und nutzt dann Ressourcen. Wenn keine Kundinnen
und Kunden da sind, schließt er komplett und Sie zahlen nicht für ein leeres
Geschäft.
Wichtige Funktionen von Cloud Run
Container überall ausführen
-
Sie stellen einen Container (Docker-Image) mit Ihrer Anwendung darin bereit.
- Cloud Run führt sie in der Infrastruktur von Google aus.
-
Es sind kein Patching des Betriebssystems und keine VM-Einrichtung nötig und
es gibt keine Skalierungsprobleme.
Autoscaling
-
Wenn niemand Ihre Anwendung verwendet, werden 0 Instanzen ausgeführt (Sie
zahlen 0 $, wenn sie inaktiv ist).
-
Wenn 1.000 Anfragen eingehen, werden so viele Kopien wie nötig erstellt.
Standardmäßig zustandslos
- Jede Anfrage kann an eine andere Instanz gehen.
-
Wenn Sie einen Zustand speichern müssen, verwenden Sie einen externen Dienst
wie Cloud SQL, Firestore oder Redis.
Unterstützt jede Sprache und jedes Framework
-
Solange die Anwendung in einem Linux-Container ausgeführt wird, ist es Cloud
Run egal, ob sie in Python, Go, Node.js, Java oder .NET geschrieben ist.
Sie zahlen nur für die tatsächliche Nutzung
-
Die Abrechnung erfolgt pro Anfrage und Rechenzeit (bis auf 100 ms genau).
-
Sie zahlen nicht für inaktive Ressourcen wie bei einer herkömmlichen VM.
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange Google Cloud-Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus (empfohlen), um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Verwenden Sie für dieses Lab nur das Teilnehmerkonto. Wenn Sie ein anderes Google Cloud-Konto verwenden, fallen dafür möglicherweise Kosten an.
Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
-
Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren  .
.
-
Klicken Sie sich durch die folgenden Fenster:
- Fahren Sie mit dem Informationsfenster zu Cloud Shell fort.
- Autorisieren Sie Cloud Shell, Ihre Anmeldedaten für Google Cloud API-Aufrufe zu verwenden.
Wenn eine Verbindung besteht, sind Sie bereits authentifiziert und das Projekt ist auf Project_ID, eingestellt. Die Ausgabe enthält eine Zeile, in der die Project_ID für diese Sitzung angegeben ist:
Ihr Cloud-Projekt in dieser Sitzung ist festgelegt als {{{project_0.project_id | "PROJECT_ID"}}}
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
- Klicken Sie auf Autorisieren.
Ausgabe:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
Um das aktive Konto festzulegen, führen Sie diesen Befehl aus:
$ gcloud config set account `ACCOUNT`
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Hinweis: Die vollständige Dokumentation für gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Aufgabe 1: ADK herunterladen und installieren und Projektordner erstellen
In dieser Aufgabe aktivieren Sie die relevanten APIs und erstellen einen
Projektordner, in dem der Quellcode für die Bereitstellung Ihres
Python-Projekts gespeichert wird.
APIs aktivieren und Umgebungsvariablen festlegen
-
Klicken Sie in der Cloud Shell auf Editor öffnen, um den
Cloud Shell-Editor in Ihrem Basisverzeichnis zu öffnen.
-
Klicken Sie in der Aktionsleiste des Cloud Shell-Editors auf
Ansehen > Terminal.
Hinweis: Möglicherweise müssen Sie das Browserfenster verlängern, um die Menüoption „Ansehen“ zu sehen.
Verwenden Sie dieses Fenster als IDE mit dem Cloud Shell-Editor (oben) und dem
Cloud Shell-Terminal (unten) für den Rest dieses Labs.
Schließen Sie alle zusätzlichen Tutorials oder Gemini-Felder, die auf der
rechten Seite des Bildschirms angezeigt werden, damit mehr Platz für den
Code-Editor bleibt.
-
Geben Sie im Terminal den folgenden Befehl ein, um Ihr Projekt
einzurichten:
gcloud config set project {{{project_0.project_id | filled in at lab start}}}
Erwartete Ausgabe: Sie sollten eine Ausgabemeldung
erhalten, die das aktualisierte Attribut bestätigt.
Hinweis: Wenn die Cloud Shell ein Zeitlimit überschreitet oder neu gestartet wird, müssen Sie das Projekt neu einrichten.
-
Führen Sie zur Aktivierung aller erforderlichen Dienste den folgenden
Befehl aus:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com \
compute.googleapis.com
Erwartete Ausgabe: Sie sollten eine Ausgabemeldung
erhalten, die bestätigt, dass der Vorgang erfolgreich war.
Klicken Sie auf Fortschritt prüfen.
APIs aktivieren
Projektverzeichnisse erstellen
-
Führen Sie den folgenden Befehl aus, um im Lab einen Hauptordner für den
Quellcode des KI-Agenten zu erstellen:
mkdir zoo_guide_agent && cd zoo_guide_agent
-
Führen Sie als Nächstes den folgenden Befehl aus, um eine virtuelle
Umgebung zu erstellen:
uv venv
-
Führen Sie den folgenden Befehl aus, um die virtuelle Umgebung zu
aktivieren:
source .venv/bin/activate
Jetzt können Sie die Datei requirements.txt erstellen. In dieser
Datei sind die Python-Bibliotheken aufgeführt, die Ihr Zoo-KI-Agent benötigt.
-
Führen Sie den folgenden Befehl aus, um die Datei im Verzeichnis
zoo_guide_agent zu erstellen und im Cloud Shell-Editor zu
öffnen, damit Sie sie bearbeiten können:
cloudshell edit requirements.txt
-
Fügen Sie der Datei requirements.txt Folgendes hinzu und
drücken Sie STRG + S, um die Änderungen zu speichern:
google-adk==1.12.0
langchain-community
wikipedia
-
Führen Sie den folgenden Befehl im Terminal aus, damit der Paketmanager
uv Ihre Python-Pakete installiert:
uv pip install -r requirements.txt
-
Legen Sie mit diesen Befehlen Variablen für Ihr aktuelles Projekt, Ihre
Region und Ihr Nutzerkonto fest:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=$(gcloud compute project-info describe \
--format="value(commonInstanceMetadata.items[google-compute-default-region])")
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SERVICE_ACCOUNT="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Hinweis: Wenn die Cloud Shell ein Zeitlimit überschreitet oder neu gestartet wird, müssen Sie die oben genannten Variablen neu initialisieren.
-
Erstellen und öffnen Sie mit dem folgenden Befehl eine
.env-Datei, um den KI-Agenten im Verzeichnis
zoo_guide_agent zu authentifizieren:
cloudshell edit .env
Das Verzeichnis mit der Datei .env wird im Cloud Shell-Editor
geöffnet.
-
Fügen Sie der Datei .env Folgendes hinzu und speichern Sie
die Änderungen:
MODEL="{{{ project_0.startup_script.gemini_flash_model_id | filled in at lab start }}}"
SERVICE_ACCOUNT="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Verbindung zum sicheren MCP-Serverendpunkt herstellen
In diesem Abschnitt stellen Sie eine Verbindung zu Ihrem Remote-MCP-Server
her.
-
Kehren Sie zum Cloud Shell-Terminal zurück und führen Sie den folgenden
Befehl aus, um der Cloud Run-Dienstidentität die Berechtigung zum Aufrufen
des Remote-MCP-Servers zu erteilen:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
-
Führen Sie den folgenden Befehl aus, um die MCP-Server-URL in einer
Umgebungsvariablen zu speichern:
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.${REGION}.run.app/mcp/" >> .env
-
Als Nächstes erstellen Sie die Datei __init__.py. Diese Datei
teilt Python mit, dass das Verzeichnis zoo_guide_agent ein
Paket ist:
cloudshell edit __init__.py
-
Fügen Sie im Cloud Shell-Editor, der sich öffnet, den folgenden Code zu
__init__.py hinzu und speichern Sie die Änderungen:
from . import agent
Aufgabe 2: KI-Agentenworkflow erstellen
In dieser Aufgabe konfigurieren Sie den Workflow des Zooführungs-KI-Agenten.
Zuerst importieren Sie die relevanten Bibliotheken für die anfängliche
Einrichtung. Dann definieren Sie die Fähigkeiten des Zoo-KI-Agenten (welche
Tools er verwendet) und die Spezial-KI-Agenten. Danach definieren Sie den
Workflowagenten und stellen schließlich den Hauptworkflow zusammen.
Hauptdatei agent.py erstellen
-
Kehren Sie zum Cloud Shell-Terminal zurück und führen Sie den folgenden
Befehl aus, um die Hauptdatei agent.py zu erstellen. Dadurch
wird sie im Cloud Shell-Editor geöffnet, sodass Sie in den folgenden
Schritten den vollständigen Code für Ihr Multi-KI-Agentensystem einfügen
können:
cloudshell edit agent.py
1. Schritt: Bibliotheken importieren und erste Einrichtung vornehmen
Dieser erste Block ruft alle erforderlichen Bibliotheken aus dem ADK und
Google Cloud ab. Außerdem werden das Logging eingerichtet und die
Umgebungsvariablen werden aus der Datei .env geladen, was für den
Zugriff auf das Modell und die Server-URL entscheidend ist.
Schritt 2: Tools definieren (die Fähigkeiten des KI-Agenten)

Ein KI-Agent ist nur so gut wie die Tools, die er nutzen kann. In diesem
Abschnitt definieren Sie alle Fähigkeiten Ihres KI-Agenten, einschließlich
einer benutzerdefinierten Funktion zum Speichern von Daten, eines MCP-Tools,
das eine Verbindung zu Ihrem sicheren MCP-Server herstellt, sowie eines
Wikipedia-Tools.
Erläuterung der drei Tools
-
add_prompt_to_state: 📝 Dieses Tool merkt sich die Fragen der Zoobesucherinnen und
-besucher. Wenn eine Besucherin oder ein Besucher fragt: „Wo sind die
Löwen?“, speichert dieses Tool die Frage im Gedächtnis des KI-Agenten,
sodass die anderen KI-Agenten im Workflow wissen, wonach sie suchen
müssen.
Funktionsweise: Es handelt sich um eine Python-Funktion,
die den Prompt der Besucherin bzw. des Besuchers in das gemeinsame
Wörterbuch tool_context.state schreibt. Dieser Toolkontext
stellt das Kurzzeitgedächtnis des KI-Agenten für eine einzelne
Unterhaltung dar. Daten, die von einem KI-Agenten im Zustand gespeichert
wurden, können vom nächsten KI-Agenten im Workflow gelesen werden.
-
MCPToolset: 🦁 Damit wird der Zooführungs-KI-Agent mit dem MCP-Server des Zoos
verbunden, der in diesem Lab vorab bereitgestellt wurde. Dieser Server hat
spezielle Tools, um bestimmte Informationen über Zootiere abzurufen, wie
ihren Namen, ihr Alter und ihr Gehege.
Funktionsweise: Es wird eine sichere Verbindung zur
privaten Server-URL des Zoos hergestellt. Es wird
get_id_token verwendet, um automatisch eine sichere
„Schlüsselkarte“ (ein Dienstkonto-ID-Token) zu erhalten, mit der die
Identität nachgewiesen und Zugriff erlangt werden kann.
-
LangchainTool: 🌍 Damit erhält der Zooführungs-KI-Agent allgemeines Weltwissen. Wenn
eine Besucherin oder ein Besucher eine Frage stellt, die nicht in der
Datenbank des Zoos enthalten ist, wie z. B.: „Was fressen Löwen in freier
Wildbahn?“, kann der KI-Agent mit diesem Tool die Antwort bei Wikipedia
nachschlagen.
Funktionsweise: Das Tool fungiert als Adapter, sodass Ihr
KI-Agent das vorhandene Tool „WikipediaQueryRun“ aus der
LangChain-Bibliothek verwenden kann.
Ressourcen:
Schritt 3: Spezial-KI-Agenten definieren

In diesem Abschnitt definieren Sie zwei Spezial-KI-Agenten: den
Recherche-KI-Agenten und den Antwortformatierungs-KI-Agenten. Der
Recherche-KI-Agent ist das „Gehirn“ Ihres Dienstes. Dieser KI-Agent
nimmt den Prompt der Nutzerin bzw. des Nutzers aus dem gemeinsamen
Zustand, prüft seine leistungsfähigen Tools (das MCP-Servertool
des Zoos und das Wikipedia-Tool) und entscheidet, welche verwendet werden
sollen, um die Antwort zu finden.
Die Aufgabe des Antwortformatierungs-KI-Agenten ist die Präsentation.
Er verwendet keine Tools, um neue Informationen zu finden. Stattdessen werden
die vom Recherche-KI-Agenten gesammelten Rohdaten (über den Zustand übergeben)
übernommen und mithilfe der Sprachkenntnisse des LLM in eine freundliche
Antwort wie bei einer normalen Unterhaltung umwandelt.
Schritt 4: Workflow-KI-Agenten definieren
Der Workflow-KI-Agent fungiert als Koordinator für die Zootour. Er nimmt eine
Rechercheanforderung entgegen und sorgt dafür, dass die beiden in Schritt 3
definierten KI-Agenten ihre Aufgaben in der richtigen Reihenfolge erledigen:
zuerst die Recherche, dann die Formatierung. So entsteht ein vorhersehbarer,
zuverlässiger Prozess, um die Fragen von Zoobesucherinnen und -besuchern zu
beantworten.
Funktionsweise: Es ist ein SequentialAgent, eine
spezielle Art von KI-Agent, der nicht selbstständig denkt. Seine einzige
Aufgabe ist es, eine Liste von sub_agents (für Recherche und
Formatierung) in einer festen Reihenfolge auszuführen und die gemerkten
Informationen automatisch von einem zum nächsten zu übergeben.
Schritt 5: Hauptworkflow zusammenstellen

Der Hauptworkflow wird über den root_agent festgelegt, den das
ADK-Framework als Ausgangspunkt für alle neuen Unterhaltungen verwendet. Die
Hauptaufgabe dieses KI-Agenten ist die Orchestrierung des gesamten Prozesses.
Er fungiert als anfänglicher Controller und verwaltet die erste Runde der
Unterhaltung.
Die Datei agent.py ist jetzt fertig.
So können Sie sehen, wie jede Komponente – Tools, Worker-KI-Agenten und
Manager-KI-Agenten – eine bestimmte Rolle bei der Erstellung des endgültigen,
intelligenten Systems spielt. Als Nächstes erfolgt die Bereitstellung.
Aufgabe 3: Anwendung auf die Bereitstellung vorbereiten
Nachdem Sie Ihre lokale Umgebung eingerichtet haben, müssen Sie Ihr Google
Cloud-Projekt für die Bereitstellung des Zooführungs-KI-Agenten vorbereiten.
Dabei wird die Dateistruktur des KI-Agenten noch einmal geprüft, um
sicherzugehen, dass sie mit dem Bereitstellungsbefehl kompatibel ist. Noch
wichtiger ist, dass Sie eine kritische IAM-Berechtigung konfigurieren, die es
Ihrem bereitgestellten Cloud Run-Dienst ermöglicht, in Ihrem Namen zu handeln
und die Agent Platform-Modelle aufzurufen. Wenn Sie diesen Schritt
abgeschlossen haben, ist die Cloud-Umgebung bereit, Ihren KI-Agenten
erfolgreich auszuführen.
-
Kehren Sie zum Cloud Shell-Terminal zurück und führen Sie den folgenden
Befehl aus, um die Variablen in Ihre Shell-Sitzung zu laden:
source .env
-
Führen Sie den folgenden Befehl aus, um dem Dienstkonto die Rolle „Agent
Platform-Nutzer“ zu gewähren. Damit hat es die Berechtigung, Vorhersagen
zu treffen und Modelle von Google aufzurufen:
# Grant the "Agent Platform User" role to your service account
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
Aufgabe 4: KI-Agenten mit der ADK-CLI bereitstellen
Ihr lokaler Code ist fertig und Ihr Google Cloud-Projekt ist vorbereitet.
Jetzt können Sie den KI-Agenten bereitstellen.
In dieser Aufgabe verwenden Sie den Befehl adk deploy cloud_run.
Dieses praktische Tool automatisiert den gesamten Bereitstellungsworkflow. Mit
diesem einen Befehl wird Ihr Code verpackt, ein Container-Image erstellt und
in Artifact Registry gepusht und der Dienst in Cloud Run gestartet, sodass er
im Web zugänglich ist.
KI-Agenten bereitstellen
-
Führen Sie den folgenden Befehl aus, um den Agenten bereitzustellen:
# Run the deployment command
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=zoo-tour-guide \
--with_ui \
.
-
Wenn Sie gefragt werden, ob Sie fortfahren möchten und/oder ob Sie nicht
authentifizierte Aufrufe von [zoo-tour-guide] zulassen
möchten, geben Sie jeweils Y ein und drücken
Sie die Eingabetaste.
Hinweis: Die Ausführung dieses Befehls kann 5 bis 10 Minuten dauern.
-
Führen Sie den folgenden Befehl aus, um die Konfigurationseinstellungen
des vorhandenen Cloud Run-Dienstes zu ändern:
gcloud run services update zoo-tour-guide \
--region=$REGION \
--update-labels=dev-tutorial=codelab-adk
Link zur Bereitstellung abrufen
-
Sobald der KI-Agent erfolgreich in Cloud Run bereitgestellt wurde, klicken
Sie bei gedrückter STRG-Taste in der Ausgabe auf die
Dienst-URL, um sie in einem neuen Browsertab zu öffnen.
Sie sollte in etwa so aussehen: Dienst-URL-Ausgabe:
https://zoo-tour-guide-{{{project_0.startup_script.project_number | filled in at lab start}}}.{{{project_0.default_region | filled in at lab start}}}.run.app
Da Sie beim Bereitstellen in Cloud Run das Flag
--with_ui verwendet haben, sollte die ADK-Entwickler-UI angezeigt
werden.
Hinweis: Wer die URL hat, kann auf diesen KI-Agenten zugreifen. Daher eignet sich dieser Ansatz am besten für Testzwecke.
Klicken Sie auf Fortschritt prüfen.
KI-Agenten bereitstellen
Aufgabe 5: Bereitgestellten KI-Agenten testen
Ihr KI-Agent ist jetzt in Cloud Run aktiv. In dieser Aufgabe führen Sie einen
Test durch, um zu bestätigen, dass die Bereitstellung erfolgreich war und der
KI-Agent wie erwartet funktioniert. Sie benötigen die öffentliche Dienst-URL,
um auf die Weboberfläche des ADK zuzugreifen und mit dem KI-Agenten zu
interagieren.
-
Rufen Sie die öffentliche Cloud Run-Dienst-URL, die in der vorherigen
Aufgabe ausgegeben wurde, in Ihrem Webbrowser auf oder klicken Sie auf die
URL in der Ausgabe (sie sollte in einem neuen Browsertab geöffnet werden).
Dadurch wird die ADK-Entwickler-UI geöffnet.
-
Stellen Sie Tokenstreaming rechts oben in der
ADK-Symbolleiste auf Ein.
Sie können jetzt mit dem Zoo-KI-Agenten interagieren.
-
Geben Sie Hallo in das Prompt-Feld ein und drücken Sie die
Eingabetaste, um eine neue Unterhaltung zu beginnen.
Sehen Sie sich das Ergebnis an. Der KI-Agent sollte schnell mit seiner
Standardbegrüßung antworten:
"Hallo! Ich bin die Zooführung. Ich kann dir mehr über die faszinierenden Tiere hier erzählen. Was möchtest du wissen oder entdecken?"
-
Interagieren Sie jetzt mit dem Zooführungs-KI-Agenten. Geben Sie die
folgende Frage ein, um eine neue Unterhaltung zu beginnen:
Wo finde ich die Pinguine?
Sie sollten eine Antwort ähnlich der folgenden erhalten:
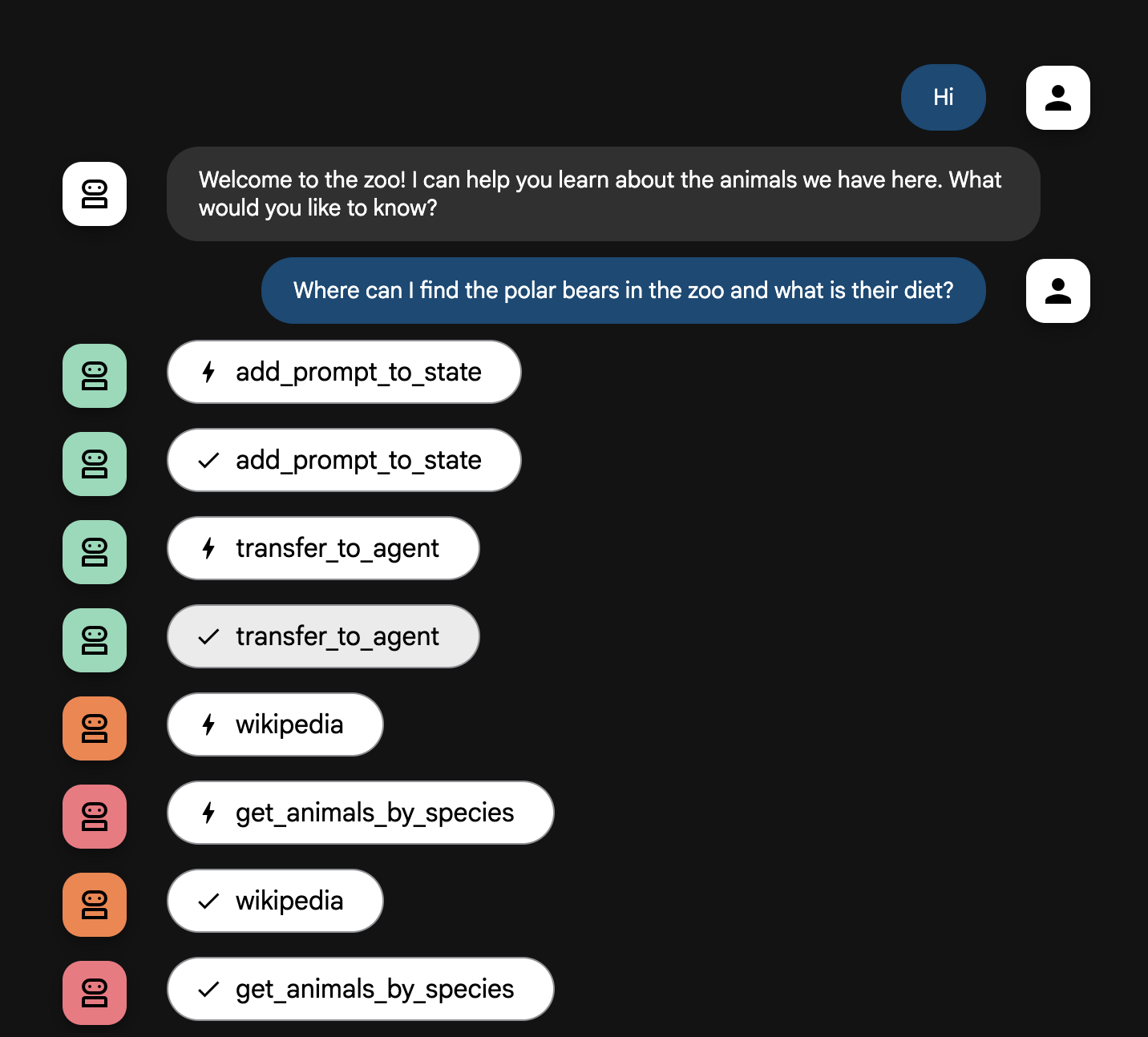

Der KI-Agentenablauf
Ihr System funktioniert wie ein intelligentes Multi-KI-Agententeam. Der
Prozess wird durch eine klare Abfolge gesteuert, um einen reibungslosen und
effizienten Ablauf von der Frage einer Nutzerin oder eines Nutzers bis zur
detaillierten Antwort zu gewährleisten.
1. Die Zoobegrüßung (der Empfangstresen)
Der gesamte Prozess beginnt mit dem Begrüßungs-KI-Agenten.
Aufgabe: Die Unterhaltung beginnen. Die Anweisung lautet, die
Nutzerin bzw. den Nutzer zu begrüßen und zu fragen, über welches Tier die
Person mehr erfahren möchte.
Tool: Wenn die Nutzerin bzw. der Nutzer antwortet, verwendet
der Begrüßungs-KI-Agent das Tool „add_prompt_to_state“, um die genauen Worte
der Person zu erfassen (z. B. „Erzähl mir etwas über Löwen“), und speichert
sie im Arbeitsspeicher des Systems.
Übergabe: Nachdem der Prompt gespeichert wurde, übergibt er
die Steuerung sofort an seinen Unter-KI-Agenten, den tour_guide_workflow.
2. Der gründliche Rechercheur (der Superrechercheur)
Dies ist der erste Schritt im Hauptworkflow und das „Gehirn“ des Dienstes.
Statt eines großen Teams haben Sie jetzt einen einzigen, hochqualifizierten
KI-Agenten, der auf alle verfügbaren Informationen zugreifen kann.
Aufgabe: Die Frage der Nutzerin bzw. des Nutzers analysieren
und einen intelligenten Plan erstellen. Der Recherche-KI-Agent nutzt die
Fähigkeit des Sprachmodells zur Toolnutzung, um zu entscheiden, ob er
Folgendes benötigt:
- Interne Daten aus den Aufzeichnungen des Zoos (über den MCP-Server)
- Allgemeinwissen aus dem Web (über die Wikipedia API)
- Beides im Fall komplexer Fragen
Aktion: Es werden die erforderlichen Tools ausgeführt, um
alle benötigten Rohdaten zu erheben. Wenn beispielsweise gefragt wird: „Wie
alt sind unsere Löwen und was fressen sie in freier Wildbahn?“, ruft Gemini
den MCP-Server für das Alter und das Wikipedia-Tool für die Informationen zur
Nahrung auf.
3. Der Antwortformatierer (der Präsentator)
Sobald der gründliche Rechercheur alle Fakten zusammengetragen hat, ist dies
der letzte KI-Agent, der ausgeführt wird.
Aufgabe: Als freundliche Stimme der Zooführung fungieren.
Dieser KI-Agent nimmt die Rohdaten (die aus einer oder aus beiden Quellen
stammen können) und bereitet sie auf.
Aktion: Die Informationen werden in einer einzigen,
zusammenhängenden und ansprechenden Antwort zusammengefasst. Gemäß den
Anweisungen werden zuerst die spezifischen Zoo-Informationen und dann die
interessanten allgemeinen Fakten präsentiert.
Endergebnis: Der von diesem KI-Agenten generierte Text ist
die vollständige, detaillierte Antwort, die im Chatfenster zu sehen ist.
Weitere Informationen
Wenn Sie mehr über das Erstellen von KI-Agenten erfahren möchten, finden Sie
hier einige Ressourcen:
Aufgabe 6: Umgebung bereinigen
In dieser Aufgabe löschen Sie die Cloud-Ressourcen, die Sie in diesem Lab
erstellt haben, um zukünftige Kosten zu vermeiden.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
In diesem Lab haben Sie gelernt, wie Sie ein Python-Projekt für die
Bereitstellung mit der ADK-Befehlszeile strukturieren, einen Workflow mit
mehreren KI-Agenten implementieren, eine Verbindung zu einem Remote-MCP-Server
herstellen, um dessen Tools zu nutzen, interne Daten durch die Einbindung
externer Tools wie der Wikipedia API anreichern und den KI-Agenten als
serverlosen Container in Cloud Run bereitstellen.
Anleitung zuletzt am 13. Oktober 2025 aktualisiert
Lab zuletzt am 13. Oktober 2025 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





