
准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Configure a Service Account & IAM permissions
/ 20
Configure credential file for a Service Account
/ 20
Modify the application to save text from images to Cloud Storage
/ 20
Modify the application to translate text using the Language API
/ 20
Query the BigQuery table
/ 20
Configure a Service Account & IAM permissions
/ 20
Configure credential file for a Service Account
/ 20
Modify the application to save text from images to Cloud Storage
/ 20
Modify the application to translate text using the Language API
/ 20
Query the BigQuery table
/ 20

在实验室挑战赛中,我们会为您提供一个场景和一系列任务。您将使用从课程的各个实验中学到的技能自行确定如何完成这些任务,而不是按照分步说明进行操作。自动评分系统(显示在本页面中)会提供有关您是否已正确完成任务的反馈。
在您参加实验室挑战赛期间,我们不会再教授新的 Google Cloud 概念知识。您需要拓展所学的技能,例如通过更改默认值和查看并研究错误消息来更正您自己所犯的错误。
要想获得满分,您必须在该时间段内成功完成所有任务!
我们建议已报名参加在 Google Cloud 上使用 Machine Learning API 课程的学员参与本实验。准备好接受挑战了吗?
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。右侧是实验设置和访问权限面板,其中包含以下内容:
请注意,实验计时器位于页面顶部附近,将显示剩余时间。
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:可以将这些标签页分别放在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在实验设置和访问权限面板中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在实验设置和访问权限面板中找到“密码”。
点击下一步。
依次点击进入后续页面:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

您刚刚走上新岗位,成为 Jooli Inc. 分析团队的一员。您的职责包括协助公司机器学习项目的数据集开发与评估。常见任务包括准备、清理和分析多种类型的数据集。
您应该已经掌握了完成这些任务所需的技能和知识,所以我们不会提供分步指南。
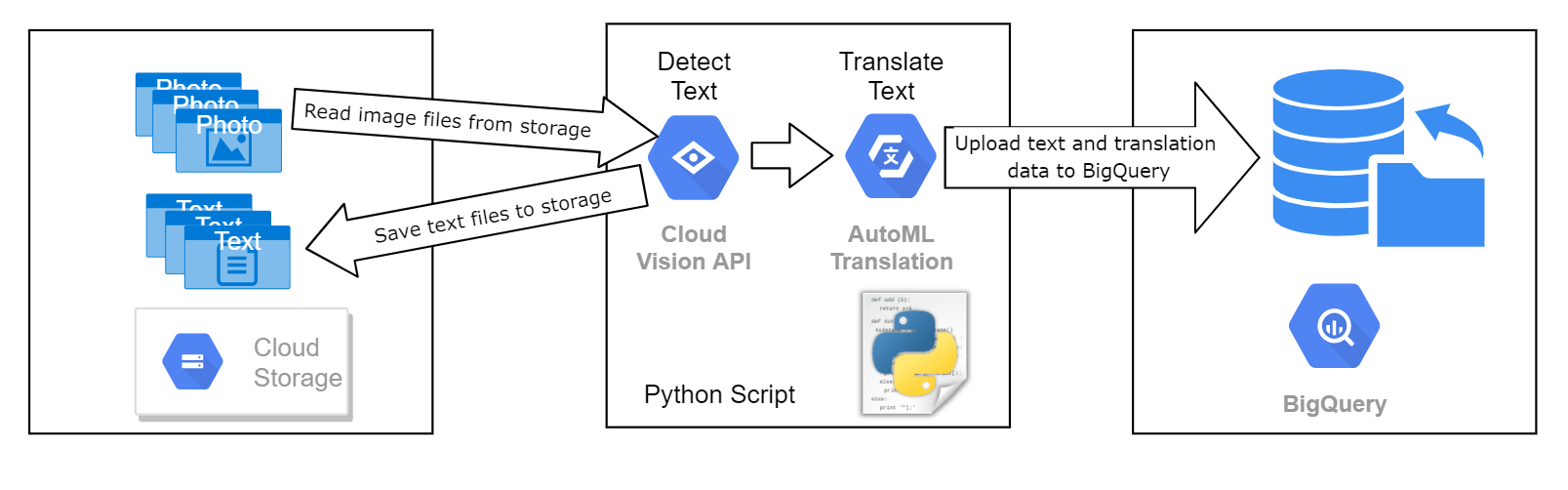
您需要开发一个流程,用于分析多组标牌图像,提取其中的文本并执行翻译。提取的文本信息将用于图像分类,这是机器学习项目的一部分,该项目将使用这一图像数据集进行模型训练和评估。所有图像都包含文本,但文本的语言可能各不相同。这些图片存储在预先为您准备的 Cloud Storage 存储桶中。
您必须使用 Python 脚本处理每个图像文件,将起发送到 Google Vision API,以识别图像中的文本。从每个图像中提取出的文本都必须重新保存到 Cloud Storage,每个图像对应一个独立的文本文件。如果文本语言区域不是
该示意图大致描述了整个流程。
处理后的文本数据必须写入项目中名为 image_classification_dataset 的数据集下的现有 BigQuery 表 image_text_detail。
您团队的一位同事此前基于一份用于调用 Natural Language API 处理文本文件的 Python 脚本,已经开始编写此次用于处理图像的代码。这位同事已转入另一个项目,现在由您接手完成这项任务。
脚本的大部分工作已经完成,您拿到的版本能够访问存储桶,并遍历其中找到的每个图像文件。但用于从每个图像中提取文本、并将该文本发送给 Translation API 的具体 API 调用尚未实现。
在以您的实验项目 ID 命名的 Cloud Storage 存储桶中,您会获得这一正在开发的 Python 脚本副本以及一组示例图像。
您的同事已在脚本中标注出了尚未完成的部分,并对需要补充的 API 调用进行了注释。脚本中有三个尚未完成的部分,您必须将其补充完整,才能正确调用 Machine Learning API。这些代码行前都带有注释标签 # TBD:。
脚本的最后一行代码用于将结果数据上传到 BigQuery。当前脚本中,这一行被注释符禁用了。当您确认脚本其余部分运行正常后,移除该注释符即可启用最后一行。
在开始修改脚本前,您需要先完成环境准备:创建一个具备正确权限的服务账号,并下载该账号的凭证文件。获得服务账号凭证后,您即可修改 Python 脚本并使用它来处理图像文件。
要完成本次挑战,您必须将所有图像的原始提取文本、语言区域以及翻译后的文本加载到名为 image_text_detail 的 BigQuery 表中。脚本中已包含执行此操作的代码,但您需要移除注释符,才能启用脚本末尾的那行代码。
使用更新后的 Python 脚本成功处理图像文件并将数据上传到 BigQuery 后,您必须在 BigQuery 中运行以下查询,以确认图像数据已成功处理:
该查询将返回在样本图像集中检测到的各语言类型的标牌数量。
将为您创建的 Cloud Storage 存储桶中的 analyze-images-v2.py 文件复制到 Cloud Shell 中。
您必须修改该 Python 脚本,以从存储在项目存储桶中的图像文件中提取文本,并将每个图像提取到的文本数据保存为单独的文本文件,再写回同一存储桶。请注意,脚本中需要补充 API 调用代码的部分均以 # TBD 注释标记。
在完成脚本第一部分的修改、使其能够调用 Cloud Vision API 从图像文件中提取文本后,您应当运行已部分完成的脚本检查进度,确保实现方向正确。
现在修改 Python 脚本的第二部分,使其能够识别 Vision API 检测到的任何
提示 1:您必须设置一个环境变量,提供 Python 脚本访问 Google Cloud API 时所需凭证文件的详细信息。
提示 2:您可以在 Vision API 客户端的 Python API 文档参考页面中找到有关 Vision API 客户端 document_text_detection API 调用的详细信息,也可以在 Vision API 对象的 Python API 文档参考页面中找到有关 Vision API 注解响应对象的详细信息。
提示 3:如需了解 Translation API 客户端的 translate API 调用的详细信息,请参阅 Translation V2 API 客户端的 Python API 文档。
您已成功开发出一个用于分析标牌图像、并从中提取和翻译文本的流程。
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2025 年 9 月 2 日
上次测试实验的时间:2025 年 9 月 2 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验
完成此快速步骤即可开始实验。