
准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Combine the data and export Parquet files
/ 35
Query data in BigQuery
/ 30
Query data in Dataproc and Spark
/ 35

 重要提示:
重要提示: 请务必仅在桌面设备/笔记本电脑上完成此实操实验。
请务必仅在桌面设备/笔记本电脑上完成此实操实验。 每个实验仅允许尝试 5 次。
每个实验仅允许尝试 5 次。 温馨提示:第一次尝试时,您可能无法答对所有问题,甚至可能需要重做任务,请不必担心,这都是学习过程的一部分。
温馨提示:第一次尝试时,您可能无法答对所有问题,甚至可能需要重做任务,请不必担心,这都是学习过程的一部分。 实验一旦开始,计时器就无法暂停。1 小时 30 分钟后,实验将结束,您需要重新开始。
实验一旦开始,计时器就无法暂停。1 小时 30 分钟后,实验将结束,您需要重新开始。 如需了解详情,请阅读实验技术提示。
如需了解详情,请阅读实验技术提示。
云数据分析领域发展日新月异,云数据分析师必须不断钻研新平台、新技术,才能切实胜任本职工作。对比 BigQuery 与 Dataproc 等不同平台,便是提升自身能力的有效途径。
BigQuery 和 Dataproc 都是云数据处理平台,但二者采用不同的数据处理引擎、SQL 方言和开发环境进行数据分析。
BigQuery 是一个数据仓库,非常适合对大型数据集进行交互式查询。它操作简便,能应对各类数据分析任务。
Dataproc 是一项托管式 Hadoop 和 Spark 服务,非常适合对大型数据集执行批处理作业。它比 BigQuery 更灵活,但配置和使用流程相对复杂。
BigQuery 和 Dataproc 均与其他 Google Cloud 服务集成,因此您可以轻松地在它们之间传输数据,以及探索数据湖的数据源。
在本实验中,您将把两个 CSV 文件中的数据联接到一个 Parquet 文件中。然后,您将使用合并后的数据,对比基于 BigQuery 的分析结果与基于 Dataproc 和 Spark 的分析结果。
TheLook eCommerce 正在试点一项计划,允许客户在任意实体店退回线上订单商品。该计划将为客户退货提供便利,有望提升客户满意度并促进销售额增长。
为了帮助跟踪此计划的成效,商品部负责人 Meredith 委托您制作一份报告,整合各个实体店的地址和退货数据。此报告将用于按实体店和地区统计退货情况,同时助力判断试点计划在不同市场的实施效果。
着手之初,您先梳理了各实体店截至目前收集到的数据。但很快发现,数据量极为庞大!于是,您向数据架构师 Artem 寻求帮助,希望解决海量数据的收集、处理与分析问题。
Artem 建议使用 Dataproc 将您正在处理的两个 CSV 文件合并为一个 Parquet 文件。Parquet 是一种列式数据格式,专为快速执行分析查询而优化。Artem 补充道,由于 TheLook eCommerce 刚刚收购了一家使用 Spark 进行数据分析的公司,这正是深入了解 Dataproc 和 Spark 的绝佳契机。
Artem 提议利用这份为 Meredith 制作报告而合并的数据,对比两种数据分析方式:一种基于您熟悉的 BigQuery 产品,另一种基于 Dataproc 和 Spark。这不仅能帮助您进一步了解 Dataproc 和 Spark,还能通过对比两个平台,明确哪个平台更契合试点计划的需求。
您感谢了 Artem 的建议。但是,在开始比较 BigQuery 与 Dataproc 和 Spark 之前,您需要规划如何收集和处理将用于比较的数据。
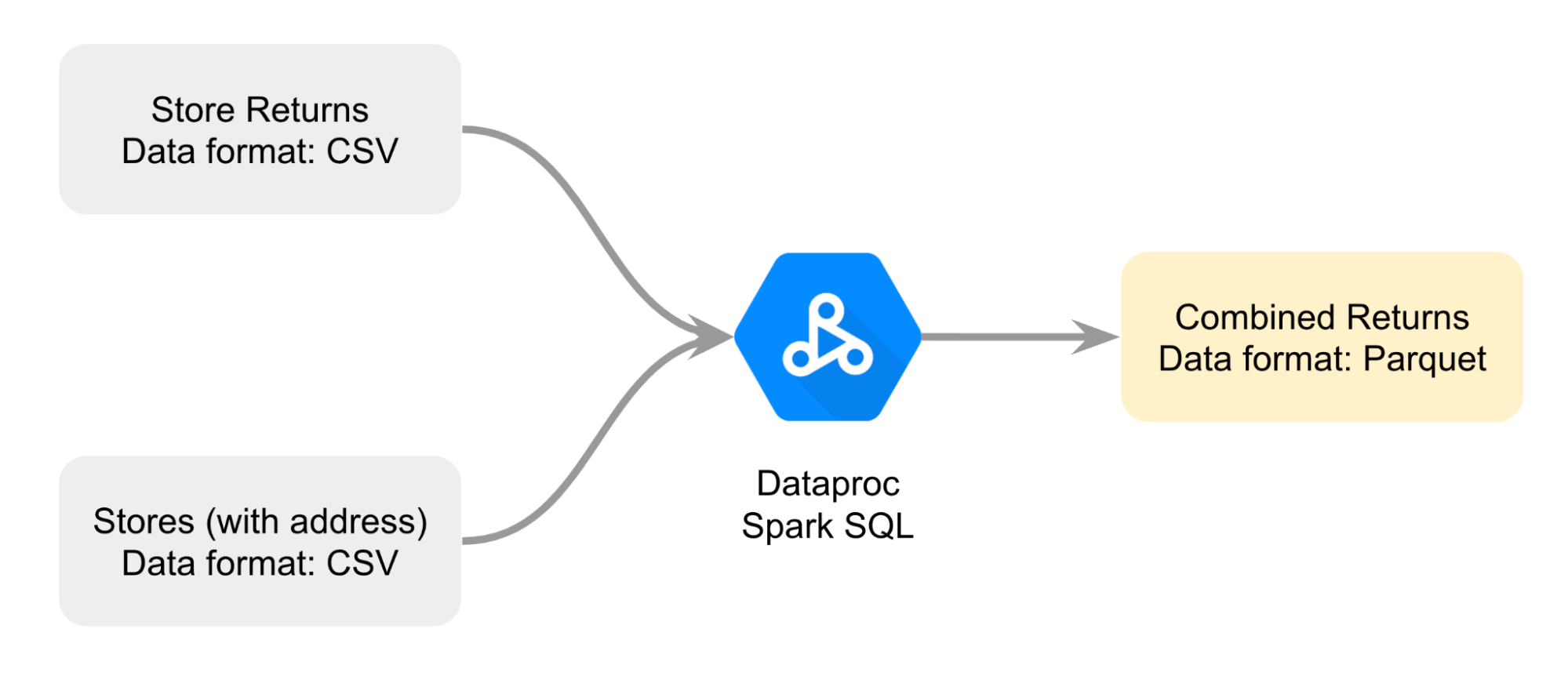
您绘制了一张示意图,以便更好地规划两个 CSV 文件的合并方案:通过 Dataproc Spark SQL 联接两个文件,以生成 Parquet 格式的合并退货文件。
这份合并后的数据将作为您对比分析的基础。
下面是任务的具体步骤:首先,您将在 Dataproc 集群上打开一个 Jupyter 笔记本。接着,您将按照笔记本中的说明,联接两个 CSV 文件,以创建 Parquet 文件。然后,您需要将存储在 Cloud Storage 存储桶中的 Parquet 文件的数据加载到 BigQuery 标准表中,进行分析。最后,您将在 Dataproc 集群上的 Jupyter 笔记本中引用同一 Parquet 文件,对比 BigQuery 与 Dataproc 搭配 Spark 的数据分析效果。
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展活动,免受模拟或演示环境的限制。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。左侧是实验详细信息面板,其中包含以下各项:
如果您使用的是 Chrome 浏览器,点击打开 Google Cloud 控制台(或右键点击并选择在无痕式窗口中打开链接)。系统会在新的浏览器标签页中打开登录页面。
提示:您可以将这些标签页分别放在不同的窗口中,并排显示,以便轻松切换。
如有必要,请复制下方的 Google Cloud 用户名,然后将其粘贴到登录对话框中。点击下一步。
您也可以在实验详细信息面板中找到 Google Cloud 用户名。
您也可以在实验详细信息面板中找到 Google Cloud 密码。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

您可以使用 JupyterLab 在 Dataproc 集群上创建、打开和修改 Jupyter 笔记本。这样,您便能借助集群的高性能、高伸缩性等资源优势,更快地运行笔记本,处理更大规模的数据集;同时,您还能通过 JupyterLab 与他人协作开展项目。
在此任务中,您将在 Dataproc 中打开现有的 Dataproc 集群,然后前往 JupyterLab,找到将用于完成本实验后续任务的 Jupyter 笔记本。
JupyterLab 环境会在新的浏览器标签页中打开。
C2M4-1 Combine and Export.ipynb 文件。为帮助 Meredith 确定退货地点和对应市场,需要获取每笔退货的相关信息以及退货实体店的实际地址。但这些信息分散在两个独立的 CSV 文件中。
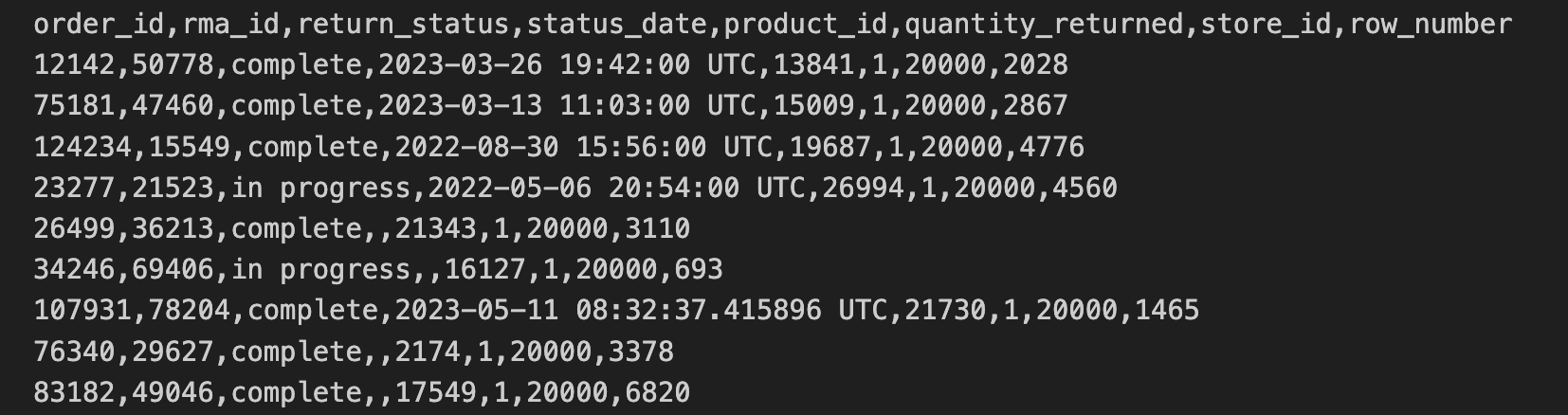
实体店退货数据已以 CSV 格式从实体店导出,并复制到 Cloud Storage 存储桶中。这些数据包括 order_id、rma_id、return_status、status_date、product_id、quantity_returned、store_id。
实体店退货 CSV 文件的前 10 行内容如下:
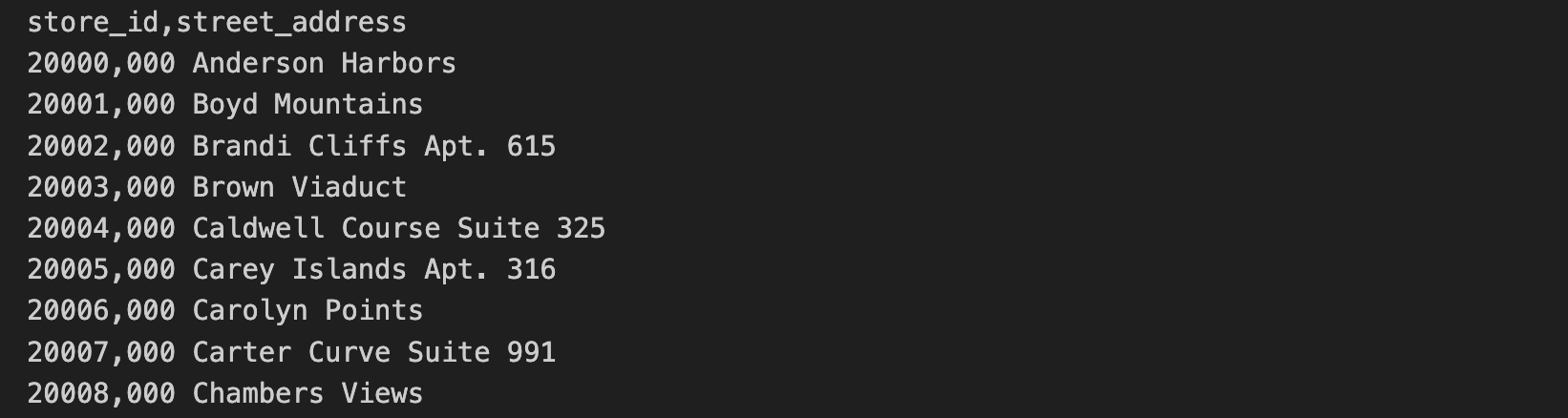
实体店地址数据存储在另一个 CSV 文件中,包括 store_id 和 street_address。
实体店地址 CSV 文件的前 10 行内容如下:
在此任务中,您将运行 C2M4-1 Combine and Export.ipynb 文件中包含的 SQL 查询和 Python 命令,以联接这两个 CSV 文件。合并后的数据将以 Parquet 文件格式存储。
在左侧边栏中,双击 C2M4-1 Combine and Export.ipynb 文件,在 JupyterLab 环境中将其打开。
在 JupyterLab 菜单栏中,依次点击内核 > 更改内核,选择 PySpark,然后点击选择。
接着,按照笔记本中的说明操作,执行每个单元中的代码。
 ) 以执行每个单元。或者,您也可以按 Shift + Enter 键来运行代码。依赖于前一个单元输出结果的单元必须按顺序运行。如果操作失误导致单元未按顺序运行,请点击笔记本工具栏中的刷新按钮 (
) 以执行每个单元。或者,您也可以按 Shift + Enter 键来运行代码。依赖于前一个单元输出结果的单元必须按顺序运行。如果操作失误导致单元未按顺序运行,请点击笔记本工具栏中的刷新按钮 ( ) 重启内核。
) 重启内核。通过 Dataproc 中的 Spark 会话,您可以连接到 Dataproc 集群,并运行 Spark 应用。这是启动 Spark 应用和创建 DataFrame 的主要方式。DataFrame 是 Spark 可以处理和运行查询的表。借助 Spark,您还可以读取数据并将其写入不同的存储系统,例如 Google Cloud Storage 或 BigQuery。
在此笔记本中,您创建了一个 Spark 会话,并将实体店退货数据从 CSV 文件加载到 DataFrame(Spark 中使用的表)。接着,您从第二个 CSV 文件加载了实体店地址,联接这两个 DataFrame,并将联接后的单个表导出为 Parquet 文件。最后,您使用查询修改了其中一列的名称。
提示:在回答以下问题时,请确保包含输出的笔记本处于打开状态。
点击检查我的进度,验证您是否已正确完成此任务。
现在,合并后的 Parquet 文件已创建并存储在 Cloud Storage 存储桶中,您可以开始比较两种运行分析的方法:一种基于 BigQuery,另一种基于 Dataproc 和 Spark。
先从 BigQuery 开始,这是一个数据仓库,使用 BigQuery 引擎执行查询和分析数据。
在上一个任务中,您创建了一个 Parquet 文件,并将其存储在 Cloud Storage 存储桶中。若要在 BigQuery 中访问这些数据,您有两种选择:外部表或标准表。外部表引用存储在 BigQuery 外部(例如 Google Cloud Storage 中)的数据。标准表直接在 BigQuery 中存储数据副本。
Artem 曾告诉您,处理大数据时,标准表往往是更高效的选择,因为可以快速查询和处理数据。因此,您决定使用标准表来完成此任务。
在此任务中,您会将 Parquet 文件加载到 BigQuery 中的标准表,并使用 GoogleSQL(BigQuery 环境中使用的 SQL 方言)运行查询。然后,您将回答一些问题,确保拥有必要信息,以便在下一个任务中比较 BigQuery 与 Dataproc 和 Spark。
返回 Google Cloud 控制台浏览器标签页(Dataproc 页面应该仍处于打开状态),同时确保 JupyterLab 浏览器标签页处于打开状态。
在 Google Cloud 控制台的导航菜单 (
在查询编辑器中,点击 +(SQL 查询)图标,以打开新的未命名的查询标签页。
将以下查询复制到未命名的查询标签页中:
此查询会将 Parquet 文件导入 BigQuery。
URI(统一资源标识符)是指 Cloud Storage 存储桶中文件的路径。可以通过将一组 URI 置于方括号 [] 内,将其作为 LOAD DATA 命令的输入。这表示相应值是一个 URI 数组。
URI 始终以 gs:// 开头,表示它是 Cloud Storage 中的资源。上述示例中提供的 URI 会过滤出扩展名为 .parquet 的文件,因为它以 *.parquet 结尾。星号 (*) 是一个通配符,表示任何字符串。
此查询会返回路径 gs://
此查询会返回“thelook_gcda.product_returns_to_store”表中的行数。
默认情况下,在 BigQuery Studio 中运行查询时,系统会使用 GoogleSQL 方言执行查询。GoogleSQL 是标准 SQL 方言的超集,这意味着它不仅包含所有标准 SQL 查询,还提供了额外扩展功能,可让您更轻松地在 BigQuery 中处理大量数据和复杂数据类型。
此查询会按月和按状态显示收到的退货数量。
点击检查我的进度,验证您是否已正确完成此任务。
现在您已在 BigQuery 中完成分析,可以开始探索基于 Dataproc 和 Spark 的分析。
Spark 是使用 Dataproc 分析数据的主要数据处理引擎。Dataproc 会自动管理 Spark 集群,并预安装了 Spark,因此是便捷而强大的数据分析选择。
Spark 还使用自己的 SQL 方言,即 Spark SQL。与 GoogleSQL 一样,Spark SQL 是一种 SQL 方言。Spark SQL 是一种分布式 SQL 方言,这意味着它可以查询和分析分布在 Spark 集群中多台机器上的数据。
为了使用 Dataproc 和 Spark 运行 Spark SQL 查询,您将使用 Jupyter 笔记本。借助此交互式环境,您可以编写代码并轻松显示其输出。
在此任务中,您将对从 Cloud Storage 存储桶中引用的 Parquet 文件运行 Spark SQL 查询。然后,您将回答一些问题,以便完成对两种分析运行方法的比较:一种基于 BigQuery,另一种基于 Dataproc 和 Spark。
返回浏览器中的 JupyterLab 标签页。
双击 C2M4-2 Query Store Data with Spark SQL.ipynb 文件,在 JupyterLab 环境中将其打开。
在 JupyterLab 菜单栏中,依次点击内核 > 更改内核,选择 PySpark,然后点击选择。
按照笔记本中的说明操作,并执行每个单元中的代码。
点击笔记本中的每个单元,然后点击运行或按 Shift + Enter 键运行代码。
查看笔记本中 Spark SQL 查询的输出。
在 JupyterLab 菜单栏中,点击文件,然后点击保存笔记本。
如果笔记本未保存,下面的进度检查可能无法检测到您已完成这些步骤。
在此笔记本中,您首先创建了一个 Spark 会话。然后,您使用 iPython 笔记本引用了 Cloud Storage 中 Parquet 文件的数据,并将其填充至 DataFrame。接着,您创建了一个视图,以便将 DataFrame 与 Spark SQL 搭配使用。之后,您运行了一个 Spark SQL 查询,该查询返回了 DataFrame 中的前三行数据。最后,您运行了与上一步在 BigQuery 中执行的查询相同的查询。
点击检查我的进度,验证您是否已正确完成此任务。
最佳实践是,在退出环境之前,务必停止集群。
请查看下表,它总结了本实验中介绍的两种数据分析方法之间的区别:一种基于 BigQuery,另一种基于 Dataproc 和 Spark。
| 任务 3 | 任务 4 | |
|---|---|---|
| 核心产品 | BigQuery | Dataproc |
| 数据处理引擎 | BigQuery | Spark |
| 数据位置 | BigQuery 标准表 | GCS 中的 Parquet 文件 |
| SQL 方言 | GoogleSQL | Spark SQL |
| 开发环境 | BigQuery Studio | Jupyter 笔记本 |
太棒了!
您已成功收集和处理 Meredith 的报告所需的数据,并使用合并后的数据比较了两种分析运行方法:一种基于您熟悉的 BigQuery 产品,另一种基于 Dataproc 和 Spark。
首先,您在现有 Dataproc 集群上打开了一个 Jupyter 笔记本。
然后,您按照该笔记本中的说明,联接了两个分别包含退货数据和地址数据的 CSV 文件,以创建一个合并的 Parquet 文件,并将该 Parquet 文件存储在 Cloud Storage 存储桶中。
根据 Artem 的建议,您随后使用合并的 Parquet 文件比较了基于 BigQuery 与基于 Dataproc 和 Spark 的数据分析方法,详细了解了它们的数据处理引擎、SQL 方言、数据位置以及开发环境。
您已经掌握如何使用 Dataproc 和 Spark 处理大型数据集。
在结束实验之前,请确保您已完成所有任务。准备就绪后,点击结束实验,然后点击提交。
结束实验后,您将无法再访问实验环境,也无法再访问您在其中完成的工作成果。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验