 PENTING:
PENTING:
 Pastikan untuk menyelesaikan lab praktik ini hanya di desktop/laptop.
Pastikan untuk menyelesaikan lab praktik ini hanya di desktop/laptop.
 Hanya ada 5 percobaan yang diizinkan per lab.
Hanya ada 5 percobaan yang diizinkan per lab.
 Sebagai pengingat – wajar jika Anda tidak dapat menjawab semua pertanyaan dengan benar pada percobaan pertama, dan bahkan perlu mengulang suatu tugas. Hal ini merupakan bagian dari proses pembelajaran.
Sebagai pengingat – wajar jika Anda tidak dapat menjawab semua pertanyaan dengan benar pada percobaan pertama, dan bahkan perlu mengulang suatu tugas. Hal ini merupakan bagian dari proses pembelajaran.
 Setelah lab dimulai, timer tidak dapat dijeda. Setelah 1 jam 30 menit, lab akan berakhir dan Anda harus memulainya lagi.
Setelah lab dimulai, timer tidak dapat dijeda. Setelah 1 jam 30 menit, lab akan berakhir dan Anda harus memulainya lagi.
 Untuk informasi selengkapnya, tinjau bacaan Tips teknis lab.
Untuk informasi selengkapnya, tinjau bacaan Tips teknis lab.
Ringkasan aktivitas
Analisis data cloud adalah bidang yang berkembang pesat, dan analis data cloud harus terus mempelajari platform dan teknologi baru agar efektif dalam pekerjaan mereka. Membandingkan berbagai platform, seperti BigQuery dan Dataproc, adalah cara yang baik untuk melakukannya.
BigQuery dan Dataproc adalah platform pemrosesan data cloud, tetapi keduanya menggunakan mesin pemrosesan data, dialek SQL, dan lingkungan pengembangan yang berbeda untuk menganalisis data.
BigQuery adalah data warehouse yang cocok untuk kueri interaktif pada set data besar. Alat ini mudah digunakan dan dapat menangani berbagai tugas analisis data.
Dataproc adalah layanan Hadoop dan Spark terkelola yang cocok untuk tugas batch processing pada set data besar. Dataproc lebih fleksibel daripada BigQuery, tetapi penyiapan dan penggunaannya bisa lebih rumit.
BigQuery dan Dataproc terintegrasi dengan layanan Google Cloud lainnya, sehingga memudahkan pemindahan data di antara keduanya dan penemuan sumber data lake.
Di lab ini, Anda akan menggabungkan data dari dua file CSV ke dalam file Parquet. Kemudian, Anda akan menggunakan data hasil penggabungannya untuk membandingkan analisis yang dilakukan dengan BigQuery dan analisis menggunakan data yang sama dengan Dataproc dan Spark.
Skenario
TheLook eCommerce sedang menjalankan program uji coba untuk menerima pengembalian pesanan online di semua toko fisiknya. Program ini akan mempermudah pelanggan mengembalikan item, yang diharapkan akan meningkatkan kepuasan pelanggan dan penjualan.
Untuk membantu melacak keberhasilan program ini, Meredith, kepala tim merchandising, telah meminta Anda menyiapkan laporan yang menggabungkan alamat toko dan data pengembalian untuk setiap toko. Laporan ini akan digunakan untuk melacak pengembalian menurut lokasi dan wilayah; informasi ini juga akan membantu menentukan keberhasilan program uji coba di berbagai pasar.
Untuk memulai, Anda menjelajahi data yang telah dikumpulkan dari setiap lokasi. Namun, Anda segera menyadari bahwa jumlah datanya sangat besar. Anda menghubungi Artem, arsitek data, untuk meminta bantuan dalam menangani data bervolume tinggi yang perlu dikumpulkan, diproses, dan dianalisis.
Artem menyarankan penggunaan Dataproc untuk menggabungkan dua file CSV yang sedang Anda kerjakan menjadi satu file Parquet. Parquet adalah format data berbasis kolom yang dioptimalkan untuk kueri analisis cepat. Artem menambahkan bahwa karena TheLook eCommerce baru saja mengakuisisi perusahaan yang melakukan analisis dengan Spark, ini adalah peluang yang bagus untuk mempelajari lebih lanjut Dataproc dan Spark.
Ia mengusulkan penggunaan data gabungan untuk laporan Meredith guna membandingkan dua cara menjalankan analisis: yang satu berpusat di BigQuery yang sudah Anda kenal, dan satu lagi berpusat di Dataproc dan Spark. Cara ini akan menjadi cara yang baik bagi Anda untuk mempelajari lebih lanjut Dataproc dan Spark, serta membandingkan kedua platform tersebut dan melihat mana yang lebih sesuai dengan kebutuhan program uji coba.
Anda berterima kasih kepada Artem atas sarannya. Namun, sebelum mulai membandingkan BigQuery dengan Dataproc dan Spark, Anda perlu memetakan cara mengumpulkan dan memproses data yang akan digunakan untuk perbandingan.
Anda membuat diagram untuk membantu Anda merencanakan dengan lebih baik cara menggabungkan dua file CSV yang berbeda; pendekatannya adalah menggabungkan file dengan Dataproc Spark SQL untuk merender file pengembalian gabungan dalam format Parquet.
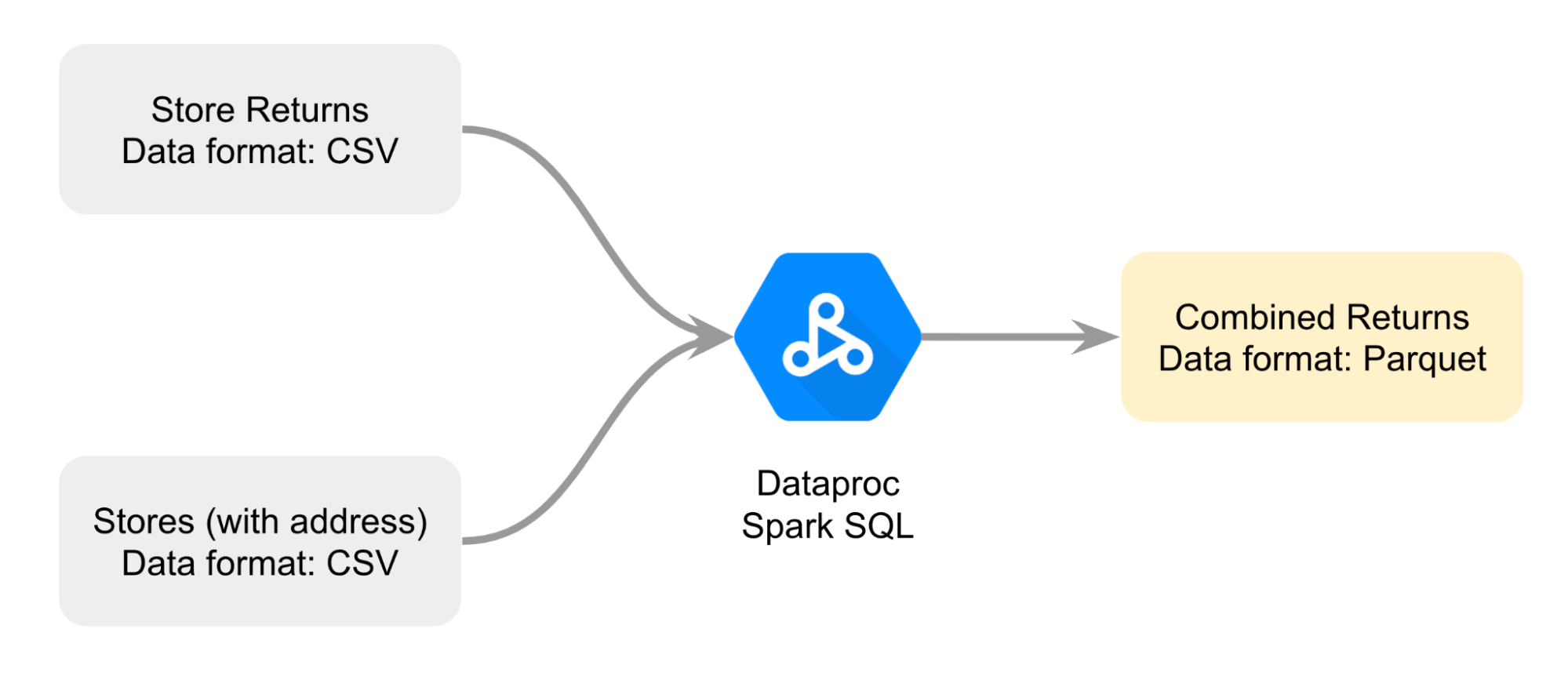
Inilah data yang akan Anda gunakan sebagai dasar perbandingan.
Berikut cara melakukan tugas ini: Pertama, Anda akan membuka notebook Jupyter di cluster Dataproc. Berikutnya, Anda akan mengikuti petunjuk dalam notebook untuk menggabungkan dua file CSV guna membuat file Parquet. Kemudian , Anda akan memuat data dari file Parquet yang disimpan ke dalam bucket Cloud Storage ke tabel standar BigQuery untuk menganalisis data. Terakhir, Anda akan mereferensikan Parquet yang sama ke notebook Jupyter di cluster Dataproc untuk membandingkan analisis data menggunakan BigQuery dengan analisis data menggunakan Dataproc dan Spark.
Penyiapan
Sebelum Anda mengklik Start Lab
Baca petunjuk ini. Lab memiliki timer yang tidak dapat dijeda. Timer, yang dimulai saat Anda mengklik Start Lab, akan menampilkan durasi ketersediaan resource Google Cloud untuk Anda.
Lab praktis ini dapat Anda gunakan untuk melakukan sendiri aktivitas di lingkungan cloud sungguhan, bukan di lingkungan demo atau simulasi. Untuk mengakses lab ini, Anda akan diberi kredensial baru yang bersifat sementara dan dapat digunakan untuk login serta mengakses Google Cloud selama durasi lab.
Untuk menyelesaikan lab ini, Anda memerlukan:
- Akses ke browser internet standar (disarankan browser Chrome).
Catatan: Gunakan jendela Samaran atau browser pribadi untuk menjalankan lab ini. Hal ini akan mencegah konflik antara akun pribadi Anda dan akun siswa yang dapat menyebabkan tagihan ekstra pada akun pribadi Anda.
- Waktu untuk menyelesaikan lab. Ingat, setelah dimulai, lab tidak dapat dijeda.
Catatan: Jika Anda sudah memiliki project atau akun pribadi Google Cloud, jangan menggunakannya untuk lab ini agar terhindar dari tagihan ekstra pada akun Anda.
Cara memulai lab dan login ke Konsol Google Cloud
-
Klik tombol Start Lab. Di sebelah kiri adalah panel Lab Details dengan informasi berikut ini:
- Waktu tersisa
- Tombol Open Google Cloud console
- Kredensial sementara yang harus Anda gunakan untuk lab ini
- Informasi lain, jika diperlukan, untuk menyelesaikan lab ini
Catatan: Jika Anda perlu membayar lab, jendela pop-up akan terbuka untuk memilih metode pembayaran.
-
Klik Open Google Cloud console (atau klik kanan dan pilih Open Link in Incognito Window) jika Anda menjalankan browser Chrome. Halaman Sign in akan terbuka di tab browser baru.
Tips: Anda dapat mengatur tab di jendela terpisah secara berdampingan untuk memudahkan Anda berpindah-pindah tab.
Catatan: Jika dialog Choose an account ditampilkan, klik Use Another Account.
-
Jika perlu, salin Username Google Cloud di bawah dan tempel ke dialog Sign in. Klik Next.
{{{user_0.username | "Google Cloud username"}}}
Anda juga dapat menemukan nama pengguna Google Cloud di panel Lab Details.
- Salin Google Cloud password di bawah dan tempel ke dialog Welcome. Klik Next.
{{{user_0.password | "Google Cloud password"}}}
Anda juga dapat menemukan password Google Cloud di panel Lab Details.
Penting: Anda harus menggunakan kredensial yang diberikan lab. Jangan menggunakan kredensial akun Google Cloud Anda.
Catatan: Menggunakan akun Google Cloud sendiri untuk lab ini dapat dikenai biaya tambahan.
- Klik halaman berikutnya:
- Setujui persyaratan dan ketentuan.
- Jangan tambahkan opsi pemulihan atau autentikasi 2 langkah (karena ini akun sementara).
- Jangan daftar uji coba gratis.
Setelah beberapa saat, konsol akan terbuka di tab ini.
Catatan: Anda dapat melihat menu berisi daftar Produk dan Layanan Google Cloud dengan mengklik Navigation menu di kiri atas.
 Catatan: Setelah Anda mengklik Start Lab, waktu untuk menyediakan resource lab akan ditampilkan. Namun, prosesnya mungkin memerlukan waktu lebih lama dari yang ditunjukkan.
Catatan: Setelah Anda mengklik Start Lab, waktu untuk menyediakan resource lab akan ditampilkan. Namun, prosesnya mungkin memerlukan waktu lebih lama dari yang ditunjukkan.
Tugas 1. Membuka JupyterLab di cluster Dataproc
JupyterLab dapat digunakan untuk membuat, membuka, dan mengedit notebook Jupyter di cluster Dataproc. Hal ini memungkinkan Anda memanfaatkan resource cluster, seperti performa dan skalabilitasnya yang tinggi, serta menjalankan notebook dengan lebih cepat dan pada set data yang lebih besar. Anda juga dapat menggunakan JupyterLab untuk berkolaborasi dengan orang lain dalam project.
Dalam tugas ini, Anda akan membuka cluster Dataproc yang ada di Dataproc dan membuka JupyterLab untuk menemukan notebook Jupyter yang akan Anda gunakan untuk menyelesaikan tugas lainnya dalam lab ini.
- Di kolom judul Konsol Google Cloud, ketik "Dataproc" di kolom Search, lalu tekan ENTER.
- Dari hasil penelusuran, pilih Dataproc.
- Di halaman Clusters, klik nama cluster yang tercantum, mycluster.
- Di halaman bertab Cluster details, pilih tab Web Interfaces.
- Di bagian Component gateway, klik link JupyterLab.
Catatan: Berhati-hatilah agar tidak salah mengira link JupyterLab dengan link Jupyter.
Lingkungan JupyterLab akan terbuka di tab browser baru.
- Temukan file
C2M4-1 Combine and Export.ipynb di folder GCS yang tercantum di sidebar kiri.
Tugas 2. Menggabungkan data dan mengekspor file Parquet
Untuk membantu Meredith mengidentifikasi lokasi dan pasar, Meredith memerlukan informasi tentang setiap pengembalian dan alamat fisik tempat pengembalian dilakukan. Namun, informasi ini ada dalam dua file CSV terpisah.
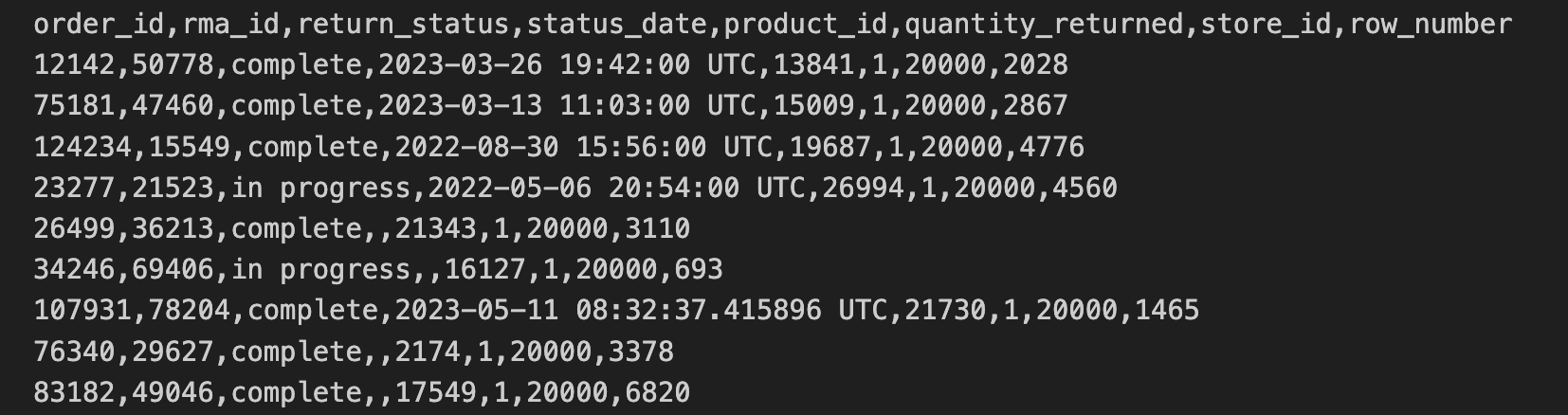
Data pengembalian barang dari toko telah diekspor dari toko dalam format CSV dan disalin ke bucket Cloud Storage. Data ini mencakup order_id, rma_id, return_status, status_date, product_ied, quantity_returned, store_id.
10 baris pertama CSV pengembalian di toko berisi hal berikut:
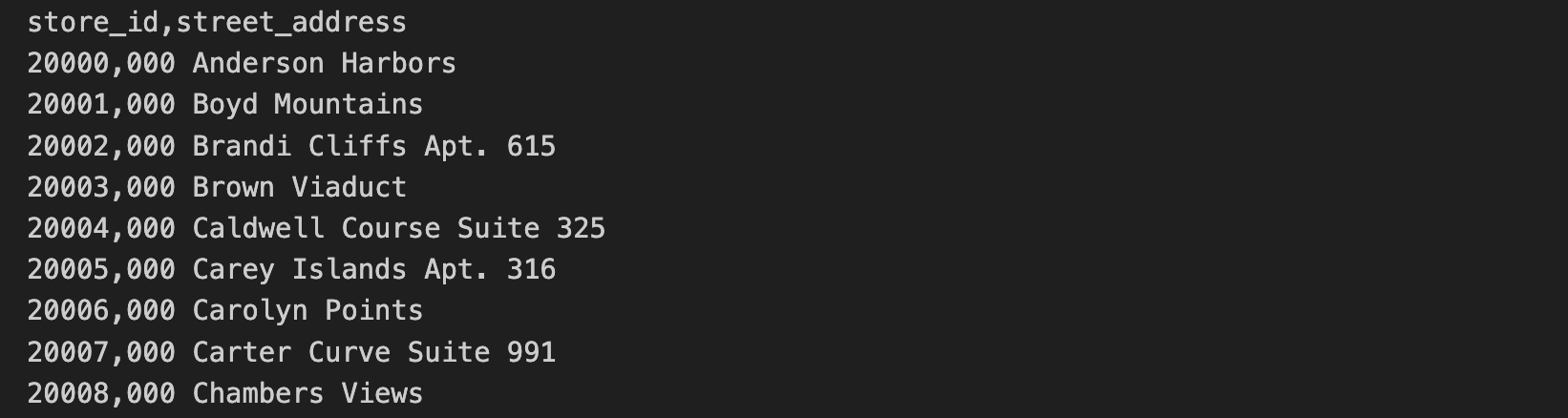
Data alamat toko disertakan dalam file CSV terpisah. Data ini mencakup store_id dan street_address.
10 baris pertama CSV alamat toko berisi hal berikut:
Dalam tugas ini, Anda akan menjalankan kueri SQL dan perintah Python yang ada dalam file C2M4-1 Combine and Export.ipynb, untuk menggabungkan dua file CSV. File gabungan akan disimpan sebagai file Parquet.
-
Di sidebar kiri, klik dua kali file C2M4-1 Combine and Export.ipynb untuk membukanya di lingkungan JupyterLab.
-
Di panel menu JupyterLab, klik Kernel > Change Kernel, pilih PySpark, lalu klik Select.
Berikutnya, ikuti petunjuk dalam notebook dan jalankan kode di setiap sel.
- Klik setiap sel di notebook, lalu klik ikon Run the selected cells and advance (
 ) untuk menjalankan setiap sel. Atau, tekan SHIFT+ENTER untuk menjalankan kode. Sel yang bergantung pada output sel sebelumnya HARUS dijalankan secara berurutan. Jika Anda membuat kesalahan dan menjalankan sel secara tidak berurutan, klik tombol Refresh (
) untuk menjalankan setiap sel. Atau, tekan SHIFT+ENTER untuk menjalankan kode. Sel yang bergantung pada output sel sebelumnya HARUS dijalankan secara berurutan. Jika Anda membuat kesalahan dan menjalankan sel secara tidak berurutan, klik tombol Refresh ( ) di toolbar notebook untuk memulai ulang kernel.
) di toolbar notebook untuk memulai ulang kernel.
Catatan: Sel di notebook harus dijalankan agar dapat dieksekusi dengan benar. Jika Anda menerima pesan error saat menjalankan sel di notebook, pastikan setiap sel telah dijalankan dan coba jalankan ulang seluruh notebook untuk menghapus error.
- Pelajari output dari setiap sel di notebook. Kedua file CSV kini digabungkan, dan file Parquet yang akan Anda gunakan dalam tugas berikutnya telah dibuat secara otomatis.
Sesi Spark di Dataproc adalah cara untuk terhubung ke cluster Dataproc dan menjalankan aplikasi Spark. Ini adalah cara utama untuk memulai aplikasi Spark dan membuat DataFrame. DataFrame adalah tabel yang dapat diproses dan dijalankan kuerinya oleh Spark. Dengan Spark, Anda juga dapat membaca dan menulis data ke sistem penyimpanan yang berbeda, seperti Google Cloud Storage atau BigQuery.
Catatan: Dataproc juga dapat memproses kueri yang disimpan dalam file teks, yang merupakan solusi umum untuk proses otomatis. Penggunaan notebook adalah pendekatan standar selama pengembangan dan eksplorasi data.
Di notebook ini, Anda telah membuat sesi Spark dan memuat data pengembalian barang dari file CSV ke DataFrame, sebuah tabel yang digunakan di Spark. Selanjutnya, Anda memuat alamat toko dari file CSV kedua, menggabungkan kedua Dataframe, dan mengekspor satu tabel gabungan sebagai file Parquet. Terakhir, Anda menggunakan kueri untuk mengubah nama salah satu kolom.
Petunjuk: Biarkan notebook dengan output tetap terbuka saat Anda menjawab pertanyaan di bawah.
Klik Check my progress untuk memastikan Anda telah menyelesaikan tugas ini dengan benar.
Menggabungkan data dan mengekspor file Parquet
Tugas 3. Mengkueri data di BigQuery
Setelah file Parquet gabungan dibuat dan disimpan di bucket Cloud Storage, Anda siap membandingkan dua cara untuk menjalankan analisis: satu berpusat di BigQuery dan satu lagi berpusat di Dataproc dan Spark.
Mulai dengan BigQuery, data warehouse yang menggunakan mesin BigQuery untuk menjalankan kueri dan menganalisis data.
Dalam tugas terakhir, Anda membuat file Parquet dan menyimpannya di bucket Cloud Storage. Untuk mengakses data ini di BigQuery, Anda memiliki dua pilihan: tabel eksternal atau tabel standar. Tabel eksternal mereferensikan data yang disimpan di luar BigQuery, seperti di Google Cloud Storage. Tabel standar menyimpan salinan data langsung di BigQuery.
Artem memberi tahu Anda bahwa tabel standar sering kali merupakan pilihan yang lebih efisien untuk bekerja dengan data besar, karena data dapat dikueri dan diproses dengan cepat. Jadi, Anda memutuskan bahwa tabel standar adalah pilihan terbaik untuk tugas ini.
Dalam tugas ini, Anda akan memuat file Parquet ke dalam tabel standar di BigQuery dan menjalankan kueri menggunakan GoogleSQL, dialek SQL yang digunakan di lingkungan BigQuery. Kemudian, Anda akan menjawab pertanyaan untuk memastikan Anda memiliki informasi yang diperlukan untuk membandingkan BigQuery dengan Dataproc dan Spark dalam tugas berikutnya.
-
Kembali ke tab browser Konsol Google Cloud (tempat Anda seharusnya masih membuka halaman Dataproc), sambil tetap membuka tab browser JupyterLab.
-
Di Menu navigasi ( ) Konsol Google Cloud, klik BigQuery > Studio. BigQuery Studio adalah cara utama untuk menulis dan menjalankan kueri di BigQuery.
) Konsol Google Cloud, klik BigQuery > Studio. BigQuery Studio adalah cara utama untuk menulis dan menjalankan kueri di BigQuery.
Catatan: Kotak pesan Welcome to BigQuery in the Cloud Console dapat muncul, yang menyediakan link ke panduan memulai dan catatan rilis untuk update UI. Klik Done untuk melanjutkan.
-
Di Editor Kueri, klik ikon + (SQL query) untuk membuka tab Untitled query baru.
-
Salin kueri berikut ke tab Untitled query:
LOAD DATA OVERWRITE thelook_gcda.product_returns_to_store
FROM FILES (
format="PARQUET",
uris=["gs://{{{project_0.project_id | "PROJECT_ID"}}}/store_returns_output/store_returns.parquet/*.parquet"]
) ;
Kueri ini mengimpor file Parquet ke BigQuery.
- Klik Run.
URI (Uniform Resource Identifier) adalah jalur ke file di bucket Cloud Storage. Kumpulan URI dapat diberikan sebagai input ke perintah LOAD DATA dengan menyertakan URI dalam tanda kurung siku []. Hal ini menunjukkan bahwa nilai tersebut adalah array URI.
URI selalu dimulai dengan gs://, yang menunjukkan bahwa URI tersebut adalah resource di Cloud Storage. URI yang diberikan dalam contoh di atas memfilter file dengan ekstensi .parquet, karena diakhiri dengan *.parquet. Simbol * adalah karakter pengganti, yang berarti string apa pun.
Kueri ini menampilkan semua file di jalur gs:///store_returns_output/store_returns.parquet/ yang memiliki nama yang diakhiri dengan .parquet, dan memuat data ke dalam tabel store_returns.
- Tempel kueri berikut ke dalam Editor Kueri:
SELECT count(*)
FROM thelook_gcda.product_returns_to_store;
Kueri ini menampilkan jumlah baris dalam tabel 'thelook_gcda.product_returns_to_store'.
- Klik Run.
Secara default, saat Anda menjalankan kueri di BigQuery Studio, kueri tersebut akan dieksekusi menggunakan dialek GoogleSQL. GoogleSQL adalah superset dialek SQL standar, yang berarti mencakup semua kueri SQL standar dan ekstensi tambahan yang mempermudah penanganan data dalam jumlah besar dan jenis data yang kompleks di BigQuery.
- Tempel kueri berikut ke dalam Editor Kueri:
SELECT
substring(CAST(status_date AS STRING), 1, 7) as year_month,
return_status,
count(order_id) as order_count
FROM thelook_gcda.product_returns_to_store
GROUP BY year_month, return_status;
Kueri ini menampilkan jumlah pengembalian yang diterima menurut bulan dan status.
- Klik Run.
Catatan: Kolom year_month mungkin memiliki nilai null dalam output.
Klik Check my progress untuk memastikan Anda telah menyelesaikan tugas ini dengan benar.
Mengkueri data di BigQuery
Tugas 4. Mengkueri data di Dataproc dan Spark
Setelah menyelesaikan analisis di BigQuery, Anda siap menjelajahi analisis yang berpusat di Dataproc dan Spark.
Spark adalah mesin pemrosesan data utama untuk menganalisis data dengan Dataproc. Dataproc secara otomatis mengelola cluster Spark dan telah diinstal sebelumnya dengan Spark, sehingga menjadikannya pilihan yang mudah dan efektif untuk analisis data.
Spark juga menggunakan dialek SQL-nya sendiri, yaitu Spark SQL. Seperti GoogleSQL, Spark SQL adalah dialek SQL. Spark SQL adalah dialek SQL terdistribusi, yang berarti dapat mengkueri dan menganalisis data yang didistribusikan di beberapa mesin dalam cluster Spark.
Untuk menjalankan kueri Spark SQL dengan Dataproc dan Spark, Anda akan menggunakan Notebook Jupyter. Lingkungan interaktif ini memungkinkan Anda menulis kode dan menampilkan outputnya dengan mudah.
Dalam tugas ini, Anda akan menjalankan kueri Spark SQL pada file Parquet yang dirujuk dari bucket Cloud Storage. Kemudian, Anda akan menjawab pertanyaan yang akan membantu Anda menyelesaikan perbandingan dua cara untuk menjalankan analisis: satu berpusat di BigQuery dan satu berpusat di Dataproc dan Spark.
-
Kembali ke tab JupyterLab di browser Anda.
-
Klik dua kali file C2M4-2 Query Store Data with Spark SQL.ipynb untuk membukanya di lingkungan JupyterLab.
-
Di panel menu JupyterLab, klik Kernel > Change Kernel, pilih PySpark, lalu klik Select.
Ikuti petunjuk dalam notebook dan jalankan kode di setiap sel.
-
Klik setiap sel di notebook, lalu klik Run atau tekan SHIFT+ENTER untuk menjalankan kode.
-
Jelajahi output dari kueri Spark SQL di notebook.
-
Di panel menu JupyterLab, klik File, lalu klik Save Notebook.
Jika notebook belum disimpan, pemeriksaan progres di bawah mungkin tidak dapat mendeteksi bahwa Anda telah menyelesaikan langkah-langkah ini.
Dalam notebook ini, Anda pertama-tama membuat sesi Spark. Kemudian, Anda mereferensikan data dari file Parquet di Cloud Storage menggunakan notebook iPython dan mengisi DataFrame. Selanjutnya, Anda membuat tampilan sehingga DataFrame dapat digunakan dengan Spark SQL. Kemudian, Anda menjalankan kueri Spark SQL yang menampilkan tiga baris teratas dari DataFrame. Terakhir, Anda menjalankan kueri yang sama seperti yang Anda jalankan di BigQuery pada langkah sebelumnya.
Klik Check my progress untuk memastikan Anda telah menyelesaikan tugas ini dengan benar.
Mengkueri data di Dataproc dan Spark
Tugas 5. Menghentikan cluster
Sebagai praktik terbaik, sebelum keluar dari lingkungan, pastikan untuk menghentikan cluster.
Catatan: Membiarkan cluster tetap berjalan akan menggunakan resource dan dapat menyebabkan Anda dikenai biaya tambahan.
- Kembali ke tab BigQuery di browser Anda.
- Di kolom judul Konsol Google Cloud, ketik Dataproc di kolom Search.
- Pilih Dataproc dari hasil penelusuran. Klik Clusters dari menu sebelah kiri.
- Dalam daftar cluster, centang kotak di samping mycluster.
- Di panel Action, klik Stop dan Confirm.
Ringkasan
Tinjau tabel berikut yang merangkum perbedaan antara analisis data dengan BigQuery dan analisis data dengan Dataproc dan Spark yang dibahas dalam lab ini.
|
Tugas 3 |
Tugas 4 |
| Produk utama |
BigQuery |
Dataproc |
| Mesin Pemrosesan Data |
BigQuery |
Spark |
| Lokasi data |
Tabel Standar BigQuery |
File Parquet di GCS |
| Dialek SQL |
GoogleSQL |
Spark SQL |
| Lingkungan Pengembangan |
BigQuery Studio |
Notebook Jupyter |
Kesimpulan
Kerja bagus!
Anda telah berhasil mengumpulkan dan memproses data yang diperlukan untuk laporan Meredith serta menggunakan data gabungan untuk membandingkan dua pendekatan dalam menjalankan analisis: satu berpusat di BigQuery, produk yang sudah Anda kenal, dan satu lagi berpusat di Dataproc dan Spark.
Pertama, Anda membuka notebook Jupyter di cluster Dataproc yang ada.
Kemudian, Anda mengikuti petunjuk dalam notebook untuk menggabungkan dua file CSV yang berisi data pengembalian dan alamat untuk membuat file Parquet gabungan dan menyimpan file Parquet di bucket Cloud Storage.
Mengikuti saran Artem, Anda kemudian menggunakan file Parquet gabungan untuk membandingkan analisis data menggunakan BigQuery dan Dataproc serta Spark untuk mempelajari lebih lanjut mesin pemrosesan data, dialek SQL, lokasi data, dan lingkungan pengembangan.
Anda sudah hampir memahami cara menggunakan Dataproc dan Spark untuk memproses set data besar.
Mengakhiri lab Anda
Sebelum mengakhiri lab, pastikan Anda puas telah menyelesaikan semua tugas. Jika sudah siap, klik Akhiri Lab, lalu klik Kirim.
Dengan mengakhiri lab, Anda akan menghapus akses ke lingkungan lab, dan Anda tidak akan dapat mengakses kembali pekerjaan yang telah Anda selesaikan di dalamnya.






