 WICHTIG:
WICHTIG:
 Dieses Lab sollte nur auf einem Computer oder Laptop durchgeführt werden.
Dieses Lab sollte nur auf einem Computer oder Laptop durchgeführt werden.
 Pro Lab sind nur 5 Versuche zulässig.
Pro Lab sind nur 5 Versuche zulässig.
 Zur Erinnerung: Es ist ganz normal, beim ersten Versuch nicht alle Fragen richtig zu beantworten oder eine Aufgabe wiederholen zu müssen – das gehört zum Lernprozess.
Zur Erinnerung: Es ist ganz normal, beim ersten Versuch nicht alle Fragen richtig zu beantworten oder eine Aufgabe wiederholen zu müssen – das gehört zum Lernprozess.
 Sobald ein Lab gestartet wurde, kann der Timer nicht mehr pausiert werden. Nach 1 Stunde und 30 Minuten wird das Lab beendet und Sie müssen von vorne beginnen.
Sobald ein Lab gestartet wurde, kann der Timer nicht mehr pausiert werden. Nach 1 Stunde und 30 Minuten wird das Lab beendet und Sie müssen von vorne beginnen.
 Weitere Informationen finden Sie in den technischen Tipps zum Lab.
Weitere Informationen finden Sie in den technischen Tipps zum Lab.
Aktivitätsübersicht
Die Cloud-Datenanalyse ist ein sich schnell weiterentwickelndes Feld. Fachkräfte für Cloud-Datenanalyse müssen sich kontinuierlich über neue Plattformen und Technologien informieren, um effektiv arbeiten zu können. Ein guter Ansatz hierfür ist der Vergleich verschiedener Plattformen wie BigQuery und Dataproc.
BigQuery und Dataproc sind beides Plattformen für die Cloud-Datenverarbeitung, aber sie verwenden unterschiedliche Datenverarbeitungs-Engines, SQL-Dialekte und Entwicklungsumgebungen zum Analysieren der Daten.
BigQuery ist ein Data Warehouse, das sich gut für interaktive Abfragen großer Datasets eignet. Es ist einfach zu bedienen und kann eine Vielzahl von Datenanalyseaufgaben bewältigen.
Dataproc ist ein verwalteter Hadoop- und Spark-Dienst, der sich gut für Batchverarbeitungsjobs für große Datasets eignet. Es ist flexibler als BigQuery, die Einrichtung und Verwendung können aber komplexer sein.
Sowohl BigQuery als auch Dataproc sind in andere Google Cloud-Dienste eingebunden. So lassen sich Daten ganz einfach zwischen den Diensten verschieben und Data Lake-Quellen erkennen.
In diesem Lab führen Sie Daten aus zwei CSV-Dateien in einer Parquet-Datei zusammen. Anschließend vergleichen Sie die mit BigQuery ausgeführte Analyse mit einer Analyse, bei der dieselben Daten mit Dataproc und Spark untersucht werden.
Szenario
TheLook eCommerce testet ein Programm, bei dem Retouren für Onlinebestellungen in allen Geschäften des Unternehmens angenommen werden. Dieses Programm soll die Rückgabe von Artikeln erleichtern, was wiederum zu einer höheren Kundenzufriedenheit und mehr Umsatz führen soll.
Um den Erfolg dieses Programms zu verfolgen, hat Meredith, die Leiterin des Merchandise-Bereichs, Sie gebeten, einen Bericht zu erstellen, in dem die Adressen der Geschäfte und Retourendaten für jedes Geschäft kombiniert werden. Mit diesem Bericht werden die Retouren nach Standort und Region erfasst. Anhand dieser Informationen kann auch der Erfolg des Pilotprogramms in verschiedenen Märkten bestimmt werden.
Zuerst untersuchen Sie die bisher gesammelten Daten für jeden Standort. Sie stellen jedoch schnell fest, dass die Datenmenge riesig ist. Sie wenden sich an Artem, den Datenarchitekten, um Hilfe bei der Verarbeitung der großen Datenmengen zu erhalten, die erfasst, verarbeitet und analysiert werden müssen.
Artem schlägt vor, Dataproc zu verwenden, um die beiden CSV-Dateien, mit denen Sie arbeiten, in einer Parquet-Datei zusammenzuführen. Parquet ist ein spaltenorientiertes Datenformat, das für schnelle Analyseabfragen optimiert ist. Artem weist darauf hin, dass TheLook eCommerce gerade ein Unternehmen übernommen hat, das Analysen mit Spark durchführt. Das ist eine gute Gelegenheit, sich genauer mit Dataproc und Spark zu beschäftigen.
Er schlägt vor, mit den kombinierten Daten für den Bericht von Meredith zwei Arten der Analyse zu vergleichen: eine mit BigQuery, einem Produkt, mit dem Sie vertraut sind, und eine mit Dataproc und Spark. So können Sie mehr über Dataproc und Spark erfahren und die beiden Plattformen vergleichen, um herauszufinden, welche besser für die Anforderungen des Pilotprogramms geeignet ist.
Sie bedanken sich bei Artem für den Rat. Bevor Sie BigQuery mit Dataproc und Spark vergleichen können, müssen Sie festlegen, wie Sie die Daten erfassen und verarbeiten, die für den Vergleich verwendet werden.
Sie erstellen ein Diagramm, um besser planen zu können, wie Sie die beiden verschiedenen CSV-Dateien kombinieren. Sie möchten die Dateien mit Dataproc Spark SQL zusammenführen, um eine kombinierte Datei zu den Retouren im Parquet-Format zu rendern.
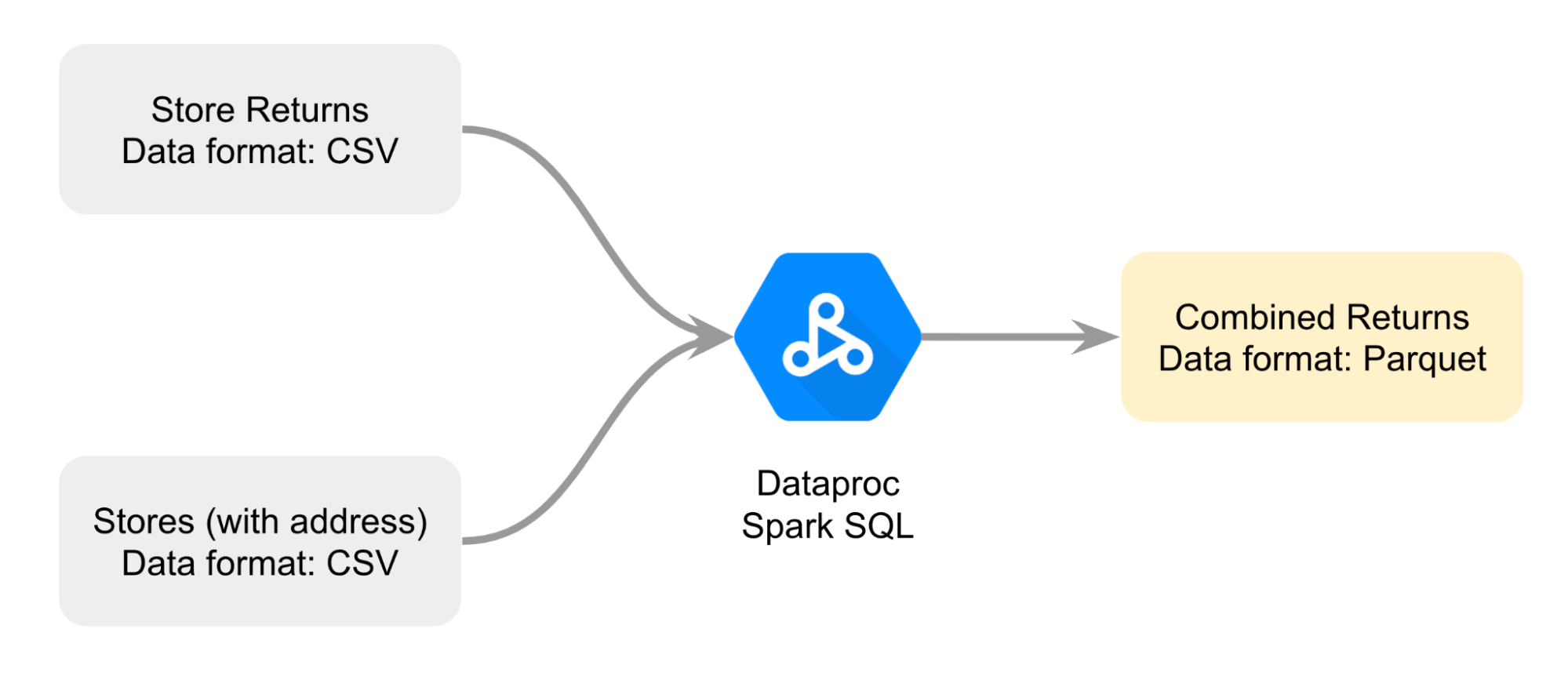
Diese Daten dienen als Grundlage für Ihren Vergleich.
So gehen Sie vor: Zuerst öffnen Sie ein Jupyter-Notebook in einem Dataproc-Cluster. Als Nächstes folgen Sie der Anleitung im Notebook, um die beiden CSV-Dateien zusammenzuführen und eine Parquet-Datei zu erstellen. Anschließend laden Sie die Daten aus der Parquet-Datei, die in einem Cloud Storage-Bucket gespeichert ist, in eine BigQuery-Standardtabelle, um die Daten zu analysieren. Zum Schluss verweisen Sie auf dieselbe Parquet-Datei in einem Jupyter-Notebook in einem Dataproc-Cluster, um die Datenanalyse mit BigQuery mit der Datenanalyse mit Dataproc und Spark zu vergleichen.
Einrichtung
Bevor Sie auf „Lab starten“ klicken
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab führen Sie die Aktivitäten eigenständig in einer echten Cloud-Umgebung durch, nicht in einer Simulation oder einer Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
Hinweis: Nutzen Sie den privaten oder Inkognitomodus, um dieses Lab durchzuführen. So wird verhindert, dass es zu Konflikten zwischen Ihrem persönlichen Konto und dem Teilnehmerkonto kommt und zusätzliche Gebühren für Ihr persönliches Konto erhoben werden.
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Hinweis: Wenn Sie über ein persönliches Google Cloud-Konto oder -Projekt verfügen, verwenden Sie es nicht für dieses Lab. So werden zusätzliche Kosten für Ihr Konto vermieden.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Restzeit
- Schaltfläche Google Cloud Console öffnen
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
Hinweis: Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden). Die Anmeldeseite wird in einem neuen Browsertab geöffnet.
Tipp: Sie können die Tabs in getrennten Fenstern nebeneinander anordnen, um bequem zwischen ihnen zu wechseln.
Hinweis: Wenn das Dialogfeld Konto auswählen angezeigt wird, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Google Cloud-Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein. Klicken Sie dann auf Weiter.
{{{user_0.username | "Google Cloud username"}}}
Sie finden den Google Cloud-Nutzernamen auch im Bereich Details zum Lab.
- Kopieren Sie das folgende Google Cloud-Passwort und fügen Sie es in das Dialogfeld Willkommen ein. Klicken Sie dann auf Weiter.
{{{user_0.password | "Google Cloud password"}}}
Sie finden das Google Cloud-Passwort auch im Bereich Details zum Lab.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
- Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder 2-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testzeiträume an.
Nach wenigen Augenblicken wird die Console in diesem Tab geöffnet.
Hinweis: Wenn Sie sich eine Liste der Google Cloud-Produkte und ‑Dienste ansehen möchten, klicken Sie oben links auf das Navigationsmenü.
 Hinweis: Nachdem Sie auf Lab starten geklickt haben, wird die Zeit für die Bereitstellung der Lab-Ressourcen angezeigt. Es kann jedoch etwas länger dauern als angegeben.
Hinweis: Nachdem Sie auf Lab starten geklickt haben, wird die Zeit für die Bereitstellung der Lab-Ressourcen angezeigt. Es kann jedoch etwas länger dauern als angegeben.
Aufgabe 1: JupyterLab in einem Dataproc-Cluster öffnen
Mit JupyterLab können Sie Jupyter-Notebooks in einem Dataproc-Cluster erstellen, öffnen und bearbeiten. So können Sie die Ressourcen des Clusters nutzen, z. B. seine hohe Leistung und Skalierbarkeit, und Ihre Notebooks schneller und mit größeren Datasets ausführen. Sie können JupyterLab auch verwenden, um mit anderen an Projekten zusammenzuarbeiten.
In dieser Aufgabe öffnen Sie einen vorhandenen Dataproc-Cluster in Dataproc und rufen JupyterLab auf, um die Jupyter-Notebooks zu finden, die Sie für die verbleibenden Aufgaben in diesem Lab benötigen.
- Geben Sie in der Titelleiste der Google Cloud Console „Dataproc“ in das Suchfeld ein und drücken Sie die EINGABETASTE.
- Wählen Sie in den Suchergebnissen Dataproc aus.
- Klicken Sie auf der Seite Cluster in der Liste auf den Clusternamen mycluster.
- Wählen Sie auf der Tab-Seite Clusterdetails den Tab Weboberflächen aus.
- Klicken Sie im Abschnitt Component Gateway auf den Link JupyterLab.
Hinweis: Achten Sie darauf, den JupyterLab-Link nicht mit dem Jupyter-Link zu verwechseln.
Die JupyterLab-Umgebung wird in einem neuen Browsertab geöffnet.
- Suchen Sie in der linken Seitenleiste im Ordner GCS nach der Datei
C2M4-1 Combine and Export.ipynb.
Aufgabe 2: Daten kombinieren und Parquet-Dateien exportieren
Damit Meredith die Standorte und Märkte identifizieren kann, benötigt sie Informationen zu jeder Retoure und die physische Adresse, an der sie abgegeben wurde. Diese Daten sind jedoch in zwei separaten CSV-Dateien enthalten.
Die Daten zu Retouren im Geschäft wurden aus den Geschäften im CSV-Format exportiert und in einen Cloud Storage-Bucket kopiert. Diese Daten umfassen Folgendes: order_id, rma_id, return_status, status_date, product_id, quantity_returned, store_id.
Die ersten 10 Zeilen der CSV-Datei für Retouren im Geschäft enthalten Folgendes:
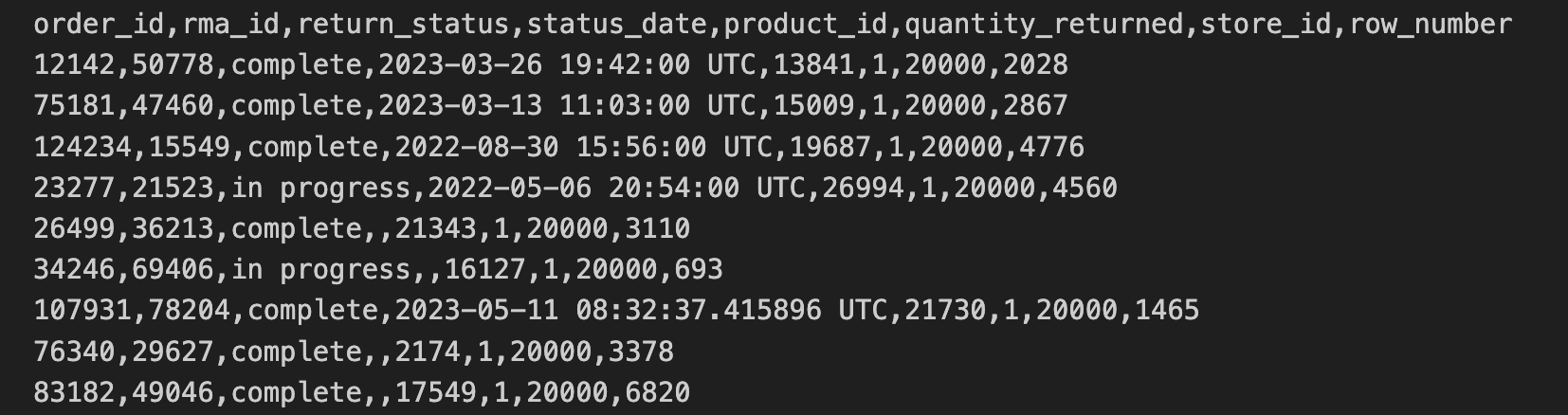
Die Daten zur Geschäftsadresse sind in einer separaten CSV-Datei enthalten. Diese Daten enthalten „store_id“ und „street_address“.
Die ersten 10 Zeilen der CSV-Datei mit den Geschäftsadressen enthalten Folgendes:
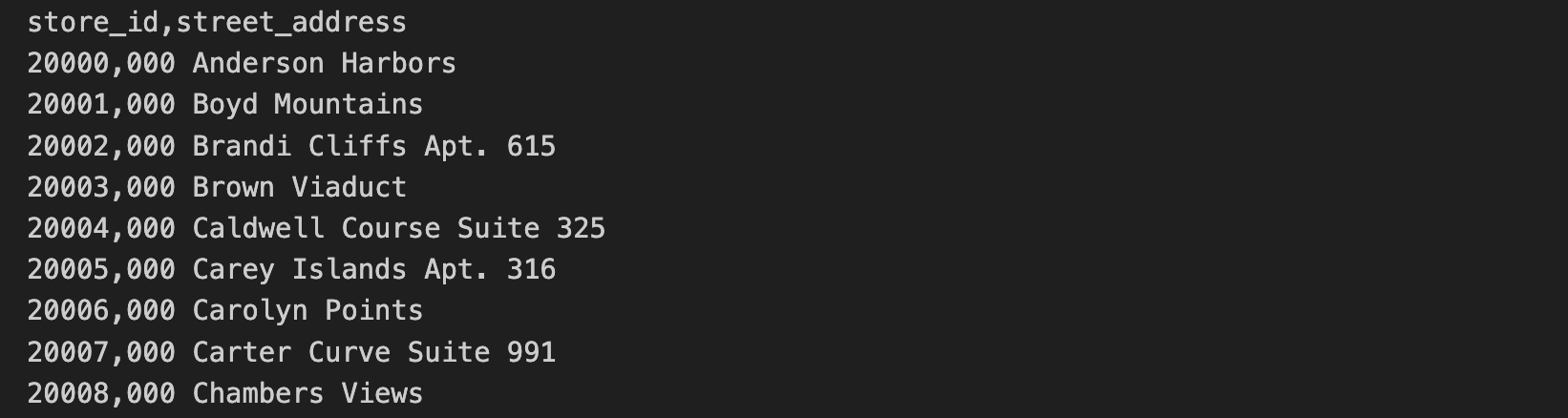
In dieser Aufgabe führen Sie die in der Datei C2M4-1 Combine and Export.ipynb enthaltenen SQL-Abfragen und Python-Befehle aus, um die beiden CSV-Dateien zusammenzuführen. Die zusammengeführten Dateien werden als Parquet-Datei gespeichert.
-
Doppelklicken Sie in der linken Seitenleiste auf die Datei C2M4-1 Combine and Export.ipynb, um sie in der JupyterLab-Umgebung zu öffnen.
-
Klicken Sie in der JupyterLab-Menüleiste auf Kernel > Change Kernel (Kernel ändern), wählen Sie PySpark aus und klicken Sie dann auf Select (Auswählen).
Folgen Sie als Nächstes der Anleitung im Notebook und führen Sie den Code in den einzelnen Zellen aus.
- Klicken Sie auf jede Zelle im Notebook und dann auf das Symbol zum Ausführen der ausgewählten Zellen und Fortfahren (
 ), um jede Zelle auszuführen. Alternativ können Sie den Code auch mit UMSCHALTTASTE + EINGABETASTE ausführen. Zellen, die von der Ausgabe einer vorherigen Zelle abhängen, MÜSSEN in der richtigen Reihenfolge ausgeführt werden. Wenn Sie einen Fehler machen und Zellen in der falschen Reihenfolge ausführen, klicken Sie in der Notebook-Symbolleiste auf den Button Aktualisieren (
), um jede Zelle auszuführen. Alternativ können Sie den Code auch mit UMSCHALTTASTE + EINGABETASTE ausführen. Zellen, die von der Ausgabe einer vorherigen Zelle abhängen, MÜSSEN in der richtigen Reihenfolge ausgeführt werden. Wenn Sie einen Fehler machen und Zellen in der falschen Reihenfolge ausführen, klicken Sie in der Notebook-Symbolleiste auf den Button Aktualisieren ( ), um den Kernel neu zu starten.
), um den Kernel neu zu starten.
Hinweis: Die Zellen im Notebook müssen in der korrekten Reihenfolge ausgeführt werden, damit das Notebook richtig funktioniert. Wenn beim Ausführen einer Zelle im Notebook eine Fehlermeldung angezeigt wird, prüfen Sie, ob jede Zelle ausgeführt wurde, und versuchen Sie, das gesamte Notebook noch einmal auszuführen, um den Fehler zu beheben.
- Sehen Sie sich die Ausgaben der einzelnen Zellen im Notebook an. Die beiden CSV-Dateien wurden zusammengeführt und die Parquet-Datei, die Sie in der nächsten Aufgabe verwenden, wurde automatisch erstellt.
Eine Spark-Sitzung in Dataproc ist eine Möglichkeit, eine Verbindung zu einem Dataproc-Cluster herzustellen und Spark-Anwendungen auszuführen. Sie ist die wichtigste Methode zum Starten von Spark-Anwendungen und zum Erstellen von DataFrames. DataFrames sind Tabellen, die von Spark verarbeitet und abgefragt werden können. Mit Spark können Sie auch Daten in verschiedenen Speichersystemen wie Google Cloud Storage oder BigQuery lesen und schreiben.
Hinweis: Dataproc kann auch in Textdateien gespeicherte Abfragen verarbeiten. Das ist die typische Lösung für automatisierte Prozesse. Die Verwendung eines Notebooks ist ein Standardansatz bei der Entwicklung und der explorativen Datenanalyse.
In diesem Notebook haben Sie eine Spark-Sitzung erstellt und die Daten zu Retouren im Geschäft aus einer CSV-Datei in einen DataFrame, d. h. eine in Spark verwendete Tabelle, geladen. Als Nächstes haben Sie die Geschäftsadressen aus einer zweiten CSV-Datei geladen, die beiden DataFrames zusammengeführt und die zusammengeführte Tabelle als Parquet-Datei exportiert. Schließlich haben Sie eine Abfrage verwendet, um den Namen einer der Spalten zu ändern.
Tipp: Lassen Sie das Notebook mit den Ausgaben geöffnet, während Sie die folgenden Fragen beantworten.
Klicken Sie auf Fortschritt prüfen, um zu sehen, ob Sie die Aufgabe richtig ausgeführt haben.
Daten kombinieren und Parquet-Dateien exportieren
Aufgabe 3: Daten in BigQuery abfragen
Nachdem die kombinierte Parquet-Datei erstellt und in einem Cloud Storage-Bucket gespeichert wurde, können Sie die beiden Analysemethoden (BigQuery und Dataproc mit Spark) vergleichen.
Beginnen Sie mit BigQuery, einem Data Warehouse, bei dem die BigQuery-Engine zum Ausführen von Abfragen und Analysieren von Daten verwendet wird.
In der letzten Aufgabe haben Sie eine Parquet-Datei erstellt und in einem Cloud Storage-Bucket gespeichert. Für den Zugriff auf diese Daten in BigQuery haben Sie zwei Möglichkeiten: eine externe Tabelle oder eine Standardtabelle. Externe Tabellen verweisen auf Daten, die außerhalb von BigQuery gespeichert sind, z. B. in Google Cloud Storage. In Standardtabellen wird eine Kopie der Daten direkt in BigQuery gespeichert.
Artem hat Ihnen gesagt, dass Standardtabellen oft die effizientere Wahl für die Arbeit mit Big Data sind, da die Daten schnell abgefragt und verarbeitet werden können. Sie entscheiden sich daher bei dieser Aufgabe für eine Standardtabelle.
In dieser Aufgabe laden Sie die Parquet-Datei in eine Standardtabelle in BigQuery und führen eine Abfrage mit GoogleSQL aus, dem SQL-Dialekt, der in der BigQuery-Umgebung verwendet wird. Anschließend beantworten Sie Fragen, um sicherzugehen, dass Ihnen die benötigten Informationen vorliegen, um BigQuery mit Dataproc und Spark in der nächsten Aufgabe zu vergleichen.
-
Kehren Sie zum Browsertab der Google Cloud Console zurück (die Dataproc-Seite sollte noch geöffnet sein) und lassen Sie den JupyterLab-Browsertab geöffnet.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü ( ) auf BigQuery > Studio. BigQuery Studio ist die primäre Methode zum Schreiben und Ausführen von Abfragen in BigQuery.
) auf BigQuery > Studio. BigQuery Studio ist die primäre Methode zum Schreiben und Ausführen von Abfragen in BigQuery.
Hinweis: Möglicherweise wird das Fenster Willkommen bei BigQuery in der Cloud Console angezeigt. Es enthält Links zur Kurzanleitung und zu den Versionshinweisen für Aktualisierungen der Benutzeroberfläche. Klicken Sie auf Fertig, um fortzufahren.
-
Klicken Sie im Abfrageeditor auf das Symbol + (SQL-Abfrage), um den neuen Tab Unbenannte Abfrage zu öffnen.
-
Kopieren Sie die folgende Abfrage auf den Tab Unbenannte Abfrage:
LOAD DATA OVERWRITE thelook_gcda.product_returns_to_store
FROM FILES (
format="PARQUET",
uris=["gs://{{{project_0.project_id | "PROJECT_ID"}}}/store_returns_output/store_returns.parquet/*.parquet"]
) ;
Mit dieser Abfrage wird die Parquet-Datei in BigQuery importiert.
- Klicken Sie auf Ausführen.
Ein URI (Uniform Resource Identifier) ist der Pfad zu einer Datei in einem Cloud Storage-Bucket. Sie können als Eingabe für den Befehl LOAD DATA eine Sammlung von URIs angeben, indem Sie die URIs in eckige Klammern [] setzen. So wird gekennzeichnet, dass der Wert ein Array von URIs ist.
Der URI beginnt immer mit „gs://“, was darauf hinweist, dass es sich um eine Ressource in Cloud Storage handelt. Der im obigen Beispiel angegebene URI filtert nach Dateien mit der Erweiterung „.parquet“, da er mit „*.parquet“ endet. Das Symbol * ist ein Platzhalter, der für einen beliebigen String steht.
Mit dieser Abfrage werden alle Dateien im Pfad „gs:///store_returns_output/store_returns.parquet/“ zurückgegeben, deren Name mit „.parquet“ endet. Die Daten werden in die Tabelle „store_returns“ geladen.
- Kopieren Sie die folgende Abfrage in den Abfrageeditor:
SELECT count(*)
FROM thelook_gcda.product_returns_to_store;
Diese Abfrage gibt die Anzahl der Zeilen in der Tabelle „thelook_gcda.product_returns_to_store“ zurück.
- Klicken Sie auf Ausführen.
Wenn Sie eine Abfrage in BigQuery Studio ausführen, wird sie standardmäßig mit dem GoogleSQL-Dialekt ausgeführt. GoogleSQL ist eine Obermenge des Standard-SQL-Dialekts. Das bedeutet, dass GoogleSQL alle Standard-SQL-Abfragen und zusätzliche Erweiterungen enthält, die die Arbeit mit großen Datenmengen und komplexen Datentypen in BigQuery erleichtern.
- Kopieren Sie die folgende Abfrage in den Abfrageeditor:
SELECT
substring(CAST(status_date AS STRING), 1, 7) as year_month,
return_status,
count(order_id) as order_count
FROM thelook_gcda.product_returns_to_store
GROUP BY year_month, return_status;
Diese Abfrage zeigt die Anzahl der Retouren nach Monat und Status an.
- Klicken Sie auf Ausführen.
Hinweis: Die Spalte „year_month“ kann in der Ausgabe Nullwerte enthalten.
Klicken Sie auf Fortschritt prüfen, um zu sehen, ob Sie die Aufgabe richtig ausgeführt haben.
Daten in BigQuery abfragen
Aufgabe 4: Daten in Dataproc und Spark abfragen
Nachdem Sie Ihre Analyse in BigQuery abgeschlossen haben, können Sie sich nun mit Analysen in Dataproc und Spark befassen.
Spark ist die wichtigste Datenverarbeitungs-Engine für die Datenanalyse mit Dataproc. Dataproc verwaltet den Spark-Cluster automatisch und Spark ist vorinstalliert. Das macht Dataproc zu einer praktischen und leistungsstarken Lösung für die Datenanalyse.
Spark verwendet ebenfalls einen eigenen SQL-Dialekt, Spark SQL. Wie GoogleSQL ist Spark SQL ein SQL-Dialekt. Spark SQL ist ein verteilter SQL-Dialekt. Dies bedeutet, dass damit Daten abgefragt und analysiert werden können, die auf mehrere Computer im Spark-Cluster verteilt sind.
Wenn Sie Spark SQL-Abfragen mit Dataproc und Spark ausführen, verwenden Sie ein Jupyter-Notebook. In dieser interaktiven Umgebung können Sie Code schreiben und die Ausgabe einfach anzeigen lassen.
In dieser Aufgabe führen Sie Spark SQL-Abfragen für die Parquet-Datei aus, auf die im Cloud Storage-Bucket verwiesen wird. Anschließend beantworten Sie Fragen, mit denen Sie den Vergleich der beiden Analyseansätze abschließen können: den mit BigQuery und den mit Dataproc und Spark.
-
Kehren Sie zum Tab JupyterLab in Ihrem Browser zurück.
-
Doppelklicken Sie auf die Datei C2M4-2 Query Store Data with Spark SQL.ipynb, um sie in der JupyterLab-Umgebung zu öffnen.
-
Klicken Sie in der JupyterLab-Menüleiste auf Kernel > Change Kernel (Kernel ändern), wählen Sie PySpark aus und klicken Sie dann auf Select (Auswählen).
Folgen Sie der Anleitung im Notebook und führen Sie den Code in jeder Zelle aus.
-
Klicken Sie auf jede Zelle im Notebook und dann auf Run (Ausführen) oder drücken Sie UMSCHALTTASTE + EINGABETASTE, um den Code auszuführen.
-
Sehen Sie sich die Ausgaben der Spark SQL-Abfragen im Notebook an.
-
Klicken Sie in der JupyterLab-Menüleiste auf File (Datei) und dann auf Save Notebook (Notebook speichern).
Wenn das Notebook nicht gespeichert wurde, kann die Fortschrittsprüfung unten möglicherweise nicht erkennen, dass Sie diese Schritte ausgeführt haben.
In diesem Notebook haben Sie zuerst eine Spark-Sitzung erstellt. Anschließend haben Sie mit dem iPython-Notebook auf die Daten aus den Parquet-Dateien in Cloud Storage verwiesen und ein DataFrame erstellt. Als Nächstes haben Sie eine Ansicht erstellt, damit das DataFrame mit Spark SQL verwendet werden konnte. Anschließend haben Sie eine Spark SQL-Abfrage ausgeführt, die die drei obersten Zeilen aus dem DataFrame zurückgegeben hat. Schließlich haben Sie dieselbe Abfrage wie im vorherigen Schritt in BigQuery ausgeführt.
Klicken Sie auf Fortschritt prüfen, um zu sehen, ob Sie die Aufgabe richtig ausgeführt haben.
Daten in Dataproc und Spark abfragen
Aufgabe 5: Cluster beenden
Als Best Practice sollten Sie den Cluster beenden, bevor Sie die Umgebung verlassen.
Hinweis: Wenn Sie Cluster weiter ausführen, werden Ressourcen verwendet und es können zusätzliche Kosten anfallen.
- Kehren Sie zum Tab BigQuery in Ihrem Browser zurück.
- Geben Sie in der Titelleiste der Google Cloud Console Dataproc in das Suchfeld ein.
- Wählen Sie in den Suchergebnissen Dataproc aus. Klicken Sie im Menü auf der linken Seite auf Cluster.
- Klicken Sie in der Clusterliste das Kästchen neben mycluster an.
- Klicken Sie in der Leiste Aktion auf Beenden und Bestätigen.
Zusammenfassung
In der folgenden Tabelle sind die Unterschiede zwischen der Datenanalyse mit BigQuery und der Datenanalyse mit Dataproc und Spark zusammengefasst, die in diesem Lab behandelt wurden.
|
Aufgabe 3 |
Aufgabe 4 |
| Zentrales Produkt |
BigQuery |
Dataproc |
| Engine für die Datenverarbeitung |
BigQuery |
Spark |
| Speicherort der Daten |
BigQuery-Standardtabelle |
Parquet-Datei in GCS |
| SQL-Dialekt |
GoogleSQL |
Spark SQL |
| Entwicklungsumgebung |
BigQuery Studio |
Jupyter Notebooks |
Fazit
Gut gemacht!
Sie haben die für den Bericht von Meredith erforderlichen Daten erfolgreich erfasst und verarbeitet. Dann haben Sie die kombinierten Daten verwendet, um zwei Ansätze für die Analyse zu vergleichen: einen, der auf BigQuery basiert, einem Produkt, mit dem Sie vertraut sind, und einen, der auf Dataproc und Spark basiert.
Zuerst haben Sie ein Jupyter-Notebook in einem vorhandenen Dataproc-Cluster geöffnet.
Anschließend haben Sie die Anleitung im Notebook befolgt, um zwei CSV-Dateien mit Retouren- und Adressdaten zusammenzuführen, eine kombinierte Parquet-Datei zu erstellen und die Parquet-Datei in einem Cloud Storage-Bucket zu speichern.
Sie haben Artems Ratschlag befolgt und die kombinierte Parquet-Datei verwendet, um die Analyse von Daten mit BigQuery und mit der Datenanalyse mit Dataproc und Spark zu vergleichen. So konnten Sie mehr über die Datenverarbeitungs-Engines, SQL-Dialekte, Datenspeicherorte und Entwicklungsumgebungen erfahren.
Sie sind auf dem besten Weg, zu verstehen, wie Sie mit Dataproc und Spark große Datasets verarbeiten können.
Lab beenden
Bevor Sie das Lab beenden, sehen Sie nach, ob Sie alle Aufgaben erledigt haben. Wenn Sie soweit sind, klicken Sie auf Lab beenden und dann auf Senden.
Wenn Sie das Lab beenden, haben Sie keinen Zugriff mehr auf die Lab-Umgebung und können auch nicht mehr auf die darin ausgeführten Aufgaben zugreifen.






