





准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Add Cloud Data Fusion API Service Agent role to service account
/ 30
Import, Deploy and Run Shipment Data Cleansing pipeline
/ 35
Import, Deploy, and Run the Delayed Shipments data pipeline
/ 35
Add Cloud Data Fusion API Service Agent role to service account
/ 30
Import, Deploy and Run Shipment Data Cleansing pipeline
/ 35
Import, Deploy, and Run the Delayed Shipments data pipeline
/ 35
本实验向您展示如何使用 Cloud Data Fusion 探索数据沿袭:数据的来源及其随时间推移的移动情况。
Cloud Data Fusion 数据沿袭可帮助您:
Cloud Data Fusion 提供数据集级和字段级沿袭,且具有时限性,以显示随时间推移的沿袭情况。
在本实验中,您将使用两条流水线来演示一个典型场景:清理原始数据,然后将其发送以进行下游处理。您可以使用 Cloud Data Fusion 沿袭功能来探索以下数据跟踪:从原始数据到经过清理的发货数据再到分析输出。
在本实验中,您将探索如何:
对于每个实验,您都会免费获得一个新的 Google Cloud 项目及一组资源,它们都有固定的使用时限。
使用无痕式窗口登录 Google Skills。
留意实验的访问时限(例如 02:00:00)并确保能在此时限内完成实验。
系统不提供暂停功能。如有需要,您可以重新开始实验,不过必须从头开始。
准备就绪时,点击开始实验。
请记好您的实验凭据(用户名和密码)。您需要使用这组凭据来登录 Google Cloud 控制台。
点击打开 Google 控制台。
点击使用其他账号,然后将此实验的凭据复制并粘贴到相应提示框中。
如果您使用其他凭据,将会收到错误消息或产生费用。
接受条款并跳过恢复资源页面。
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

Cloud Shell 是一种包含开发工具的虚拟机。它提供了一个 5 GB 的永久性主目录,并且在 Google Cloud 上运行。Cloud Shell 可让您通过命令行访问 Google Cloud 资源。gcloud 是 Google Cloud 的命令行工具。它会预先安装在 Cloud Shell 上,且支持 Tab 键自动补全功能。
在 Google Cloud Console 的导航窗格中,点击激活 Cloud Shell (
点击继续。
预配和连接到环境需要一些时间。若连接成功,也就表明您已通过身份验证,且相关项目的 ID 会被设为您的 PROJECT_ID。例如:
列出有效的帐号名称:
(输出)
(输出示例)
列出项目 ID:
(输出)
(输出示例)
在开始在 Google Cloud 中工作之前,您必须确保您的项目在 Identity and Access Management (IAM) 中拥有正确的权限。
在 Google Cloud 控制台的导航菜单 (
确认默认计算服务账号 {project-number}-compute@developer.gserviceaccount.com 已存在且被授予了 editor 角色。账号前缀是项目编号,您可以在导航菜单 > Cloud 概览中找到此编号。
如果该账号在 IAM 中不存在或不具有 editor 角色,请按照以下步骤向其分配所需的角色。
在 Google Cloud 控制台的导航菜单中,点击 Cloud 概览。
从项目信息卡片中复制项目编号。
在导航菜单中,点击 IAM 和管理 > IAM。
在 IAM 页面顶部,点击添加。
在新的主账号字段中,输入:
将 {project-number} 替换为您的项目编号。
在选择角色部分,依次选择基本(或“项目”)> Editor。
点击保存。
在本实验中,您将使用两条流水线:
点击 Shipment Data Cleansing(发货数据清理)和 Delayed Shipments USA(美国延迟发货)链接,将这些示例数据集下载到您的本地机器。
接下来,您将按照以下步骤,向与实例关联的服务账号授予权限。
在 Google Cloud 控制台中,找到 IAM 和管理 > IAM。
确认 Compute Engine 默认服务账号 {project-number}-compute@developer.gserviceaccount.com 已存在,并将服务账号复制到剪贴板。
在 IAM 权限页面,点击 +授予访问权限。
在“新的主账号”字段中,粘贴该服务账号。
点击选择角色字段,开始输入 Cloud Data Fusion API Service Agent,然后选择该角色。
点击添加其他角色
添加 Managed Service for Spark Administrator 角色。
点击保存。
点击“检查我的进度”以验证是否完成了以下目标:
在控制台中,点击导航菜单下的 IAM 和管理 > IAM。
选中包括 Google 提供的角色授权复选框。
在列表中向下滚动,找到由 Google 管理的 Cloud Data Fusion 服务账号(其形式类似于 service-{项目编号}@gcp-sa-datafusion.iam.gserviceaccount.com),随后将该服务账号名称复制到剪贴板。
然后前往 IAM 和管理 > 服务账号。
点击默认 Compute Engine 账号(其形式类似于 {项目编号}-compute@developer.gserviceaccount.com),然后选择顶部导航栏中的具有访问权限的主账号标签页。
点击授予访问权限按钮。
将您先前复制的服务账号粘贴到新的主账号字段中。
在角色下拉菜单中,选择 Service Account User。
点击保存。
进入 Data Fusion 界面,点击实例,然后点击 Data Fusion 实例旁边的查看实例链接。选择您的实验凭证进行登录。如果系统提示您浏览该服务,请点击不用了。现在,您应该已进入 Cloud Data Fusion 界面。
点击左侧导航面板中的 Studio,打开 Cloud Data Fusion Studio 页面。
现在部署流水线。在 Studio 页面右上角,点击部署。部署完成后,系统会打开流水线页面。
点击“流水线”页面顶部中央的运行来运行该流水线。
点击“检查我的进度”以验证是否完成了以下目标:
在“Shipping Data Cleansing”(发货数据清理)的状态显示为成功之后,您将继续导入并部署之前下载的“Delayed Shipments USA”(美国延迟发货)数据流水线。
点击左侧导航面板中的 Studio,返回 Cloud Data Fusion Studio 页面。
点击 Studio 页面右上角的导入,然后选择并导入之前下载的 Delayed Shipments USA(美国延迟发货)数据流水线。
点击 Studio 页面右上角的部署来部署流水线。部署完成后,系统会打开流水线页面。
点击“流水线”页面顶部中央的运行来运行流水线。
成功运行完第二条流水线后,您可以继续执行下面的剩余步骤。
点击“检查我的进度”以验证是否完成了以下目标:
您必须先发现一个数据集,然后才能探索其沿袭。
shipment(发货)。搜索结果包含此数据集。元数据搜索会发现已由 Cloud Data Fusion 流水线使用、处理或生成的数据集。流水线在结构化框架上执行,该框架会生成并收集技术元数据和操作元数据。技术元数据包括数据集名称、类型、架构、字段、创建时间和处理信息。Cloud Data Fusion 元数据搜索和沿袭功能会使用此技术信息。
虽然来源和接收器的参考名称是唯一的数据集标识符和极佳的搜索字词,但您也可以使用其他技术元数据作为搜索条件,例如数据集说明、架构、字段名称或元数据前缀。
Cloud Data Fusion 还支持使用业务元数据(例如标记和键值对属性)为数据集添加注解,这些元数据也可用作搜索条件。例如,要在“Raw Shipping Data”(原始发货数据)数据集上添加并搜索业务标记注解,请执行以下操作:
从 Cloud Data Fusion 界面的左侧导航面板中选择元数据,以打开元数据搜索页。
在元数据选项的搜索页面中输入 Raw shipping data(原始发货数据)
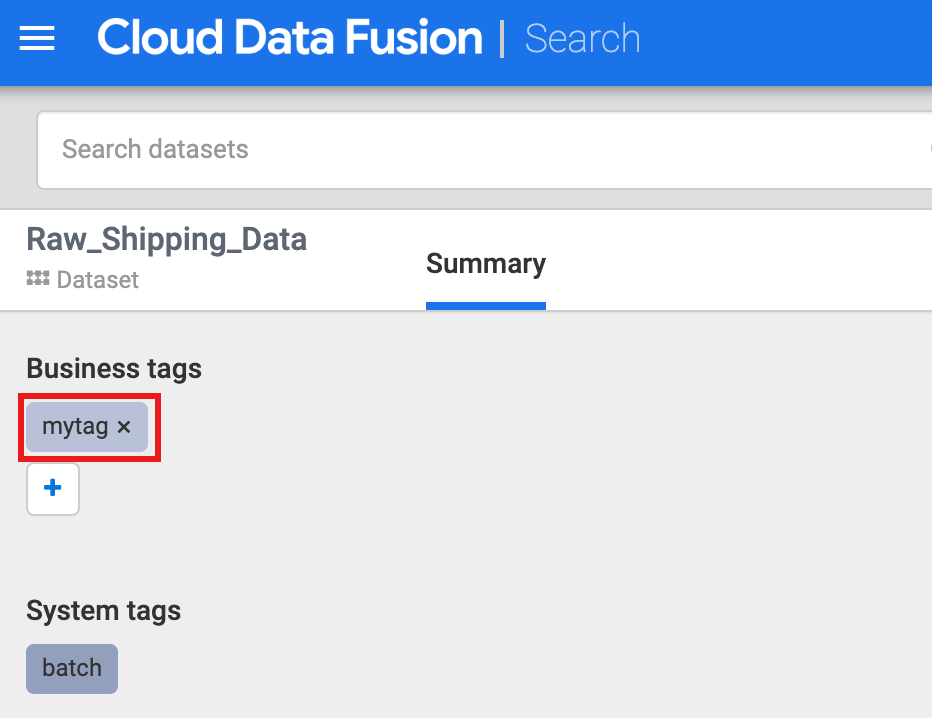
点击 Raw_Shipping_Data(原始发货数据)。
在 Business tags(业务标记)下,点击 +,然后插入标记名称(允许使用字母数字字符和下划线字符),然后按 Enter 键。
您可以通过点击标记名称,或在元数据搜索页的搜索框中输入“tags: tag_name”来搜索标记。
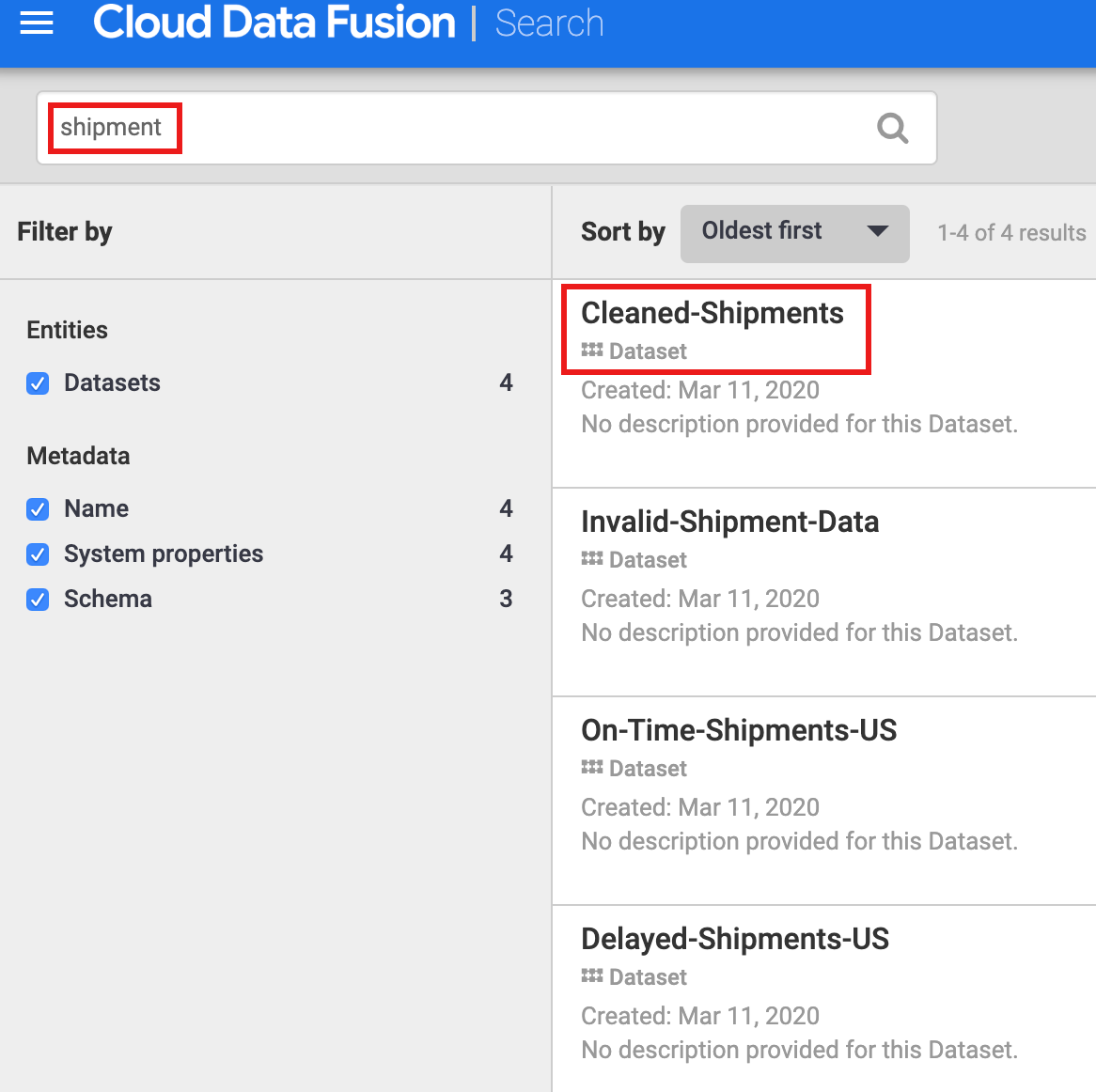
从 Cloud Data Fusion 界面的左侧导航面板中选择元数据,以打开元数据搜索页,然后在搜索框中输入 shipment(发货)。
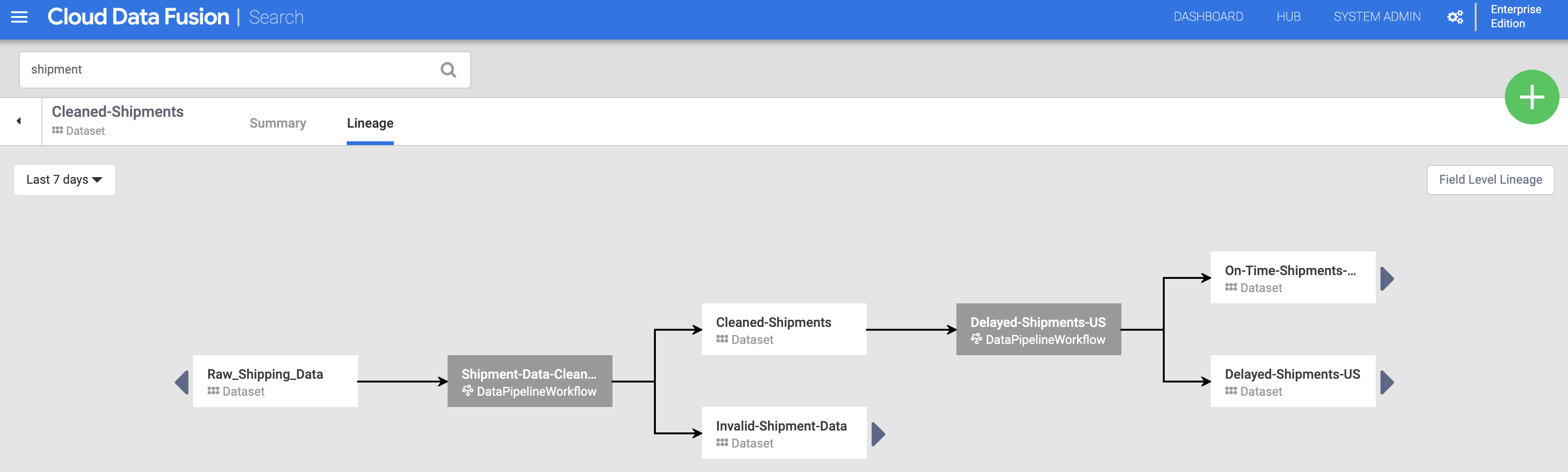
点击搜索页上列出的 Cleaned-Shipments(清理后的发货)数据集名称。
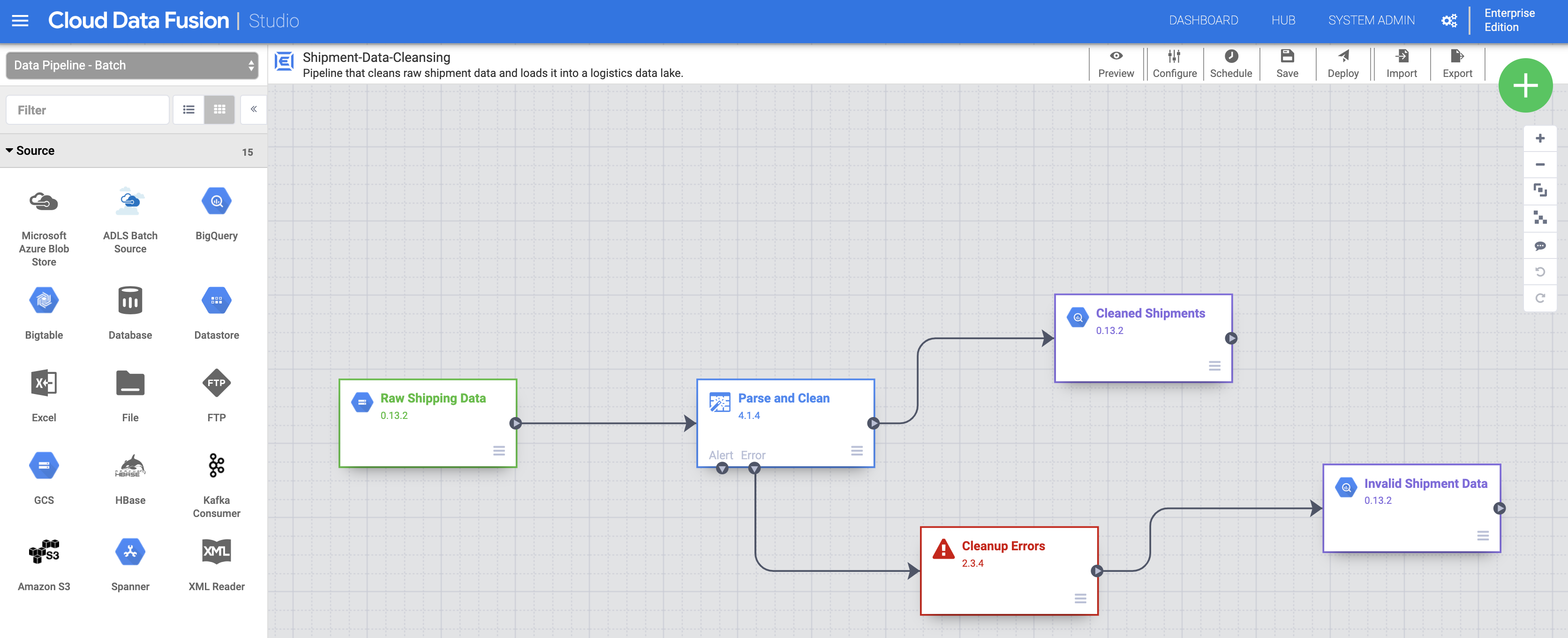
然后点击沿袭标签页。沿袭图表显示,此数据集是由“Shipments-Data-Cleansing”(发货数据清理)流水线生成的,该流水线使用了“Raw_Shipping_Data”(原始发货数据)数据集。
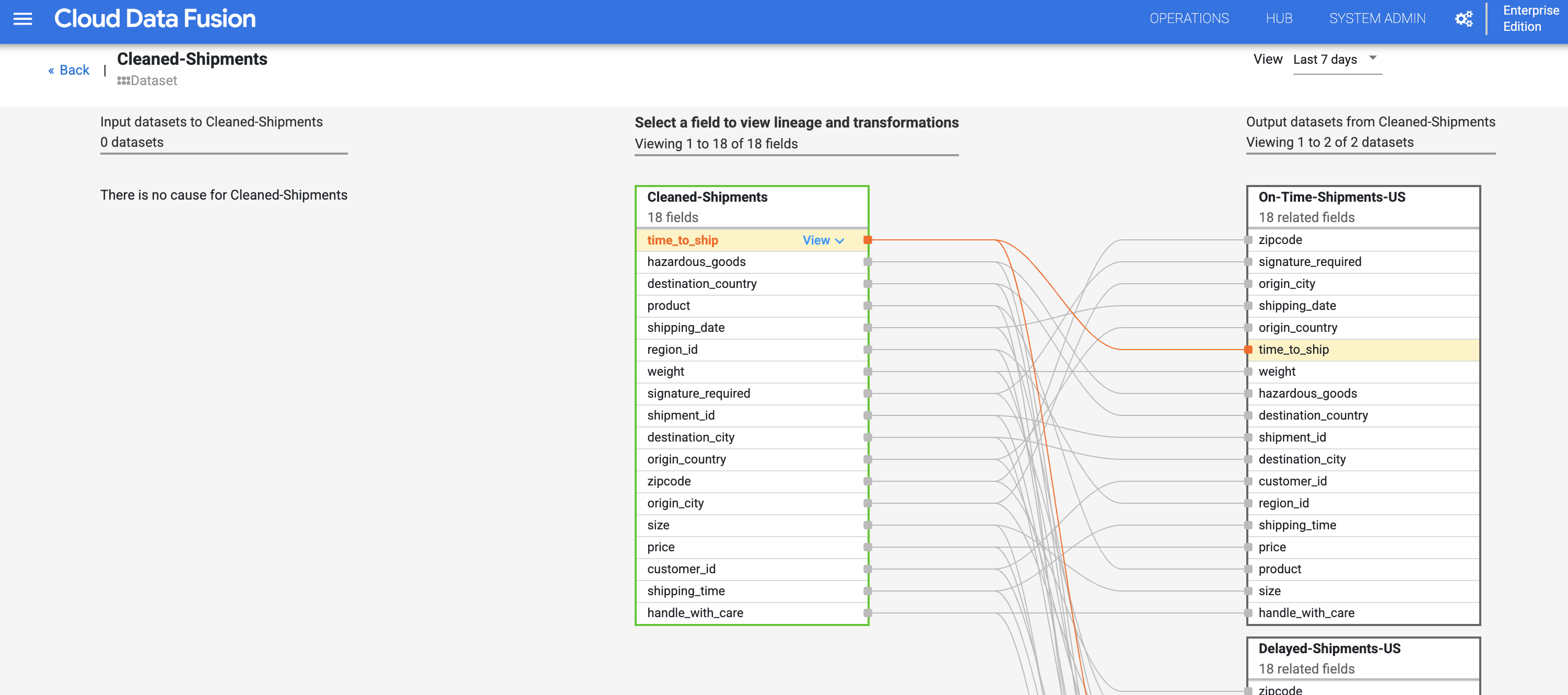
Cloud Data Fusion 字段级沿袭显示了数据集各字段之间的关系,以及为生成一组不同字段而对原有一组字段执行的转换操作。与数据集级沿袭一样,字段级沿袭具有时限性,其结果会随时间而变化。
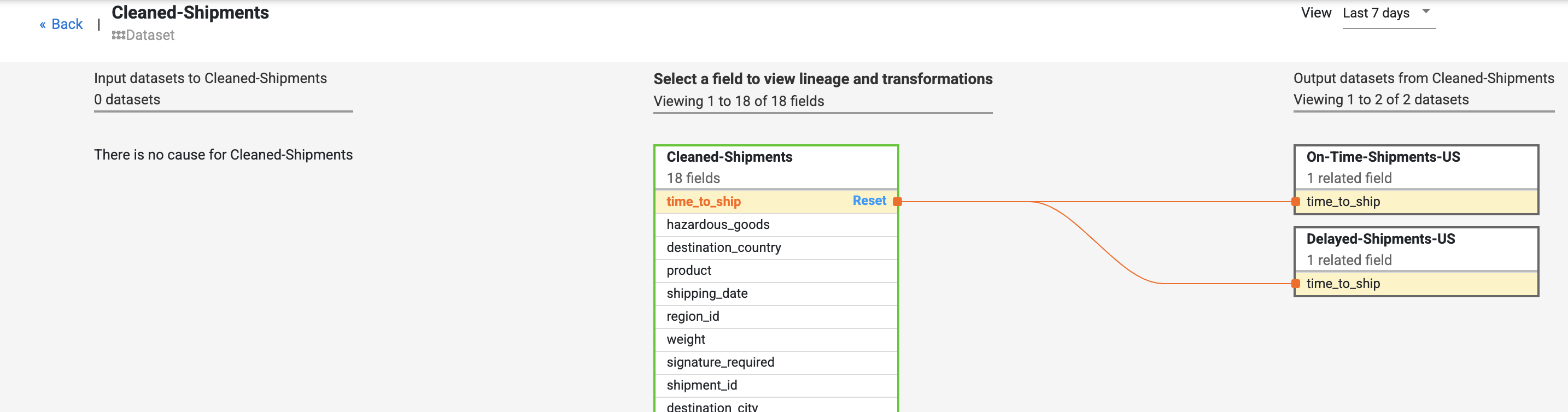
字段级沿袭显示了此字段如何随时间发生转换。请注意 time_to_ship(发货用时)字段的转换:(i) 将其转换为“float”(浮点)类型列,(ii) 确定是将该值重定向到下一个节点,还是沿错误路径向下传递。
沿袭会展示特定字段经历的更改历史记录。其他示例包括将几个字段串联起来以组成一个新字段(例如将“名字”和“姓氏”组合以生成“姓名”),或者对字段执行计算(例如将“数字”转换为相对于总数的“百分比”)。
“原因”和“影响”链接以人类可读的账本格式显示对字段两侧执行的转换。
在本实验中,您学习了如何探索数据的沿袭。此信息对于报告和治理至关重要。它可以帮助不同的受众群体了解数据是如何演变成当前状态的。
上次更新手册的时间:2022 年 11 月 14 日
上次测试实验的时间:2023 年 8 月 8 日
版权所有 2026 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名称和产品名称可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验
完成此快速步骤即可开始实验。