GSP812

Visão geral
Neste laboratório, você vai aprender a usar o Cloud Data Fusion para analisar a linhagem de dados, ou seja, as origens dos dados e o movimento deles ao longo do tempo.
A linhagem de dados do Cloud Data Fusion ajuda você a:
- detectar a causa raíz de eventos de dados inválidos;
- realizar uma análise de impacto antes de alterar os dados.
O Cloud Data Fusion oferece linhagem no nível do conjunto de dados e do campo, além de mostrar a linhagem ao longo do tempo.
- A linhagem no nível do conjunto de dados mostra a relação entre conjuntos de dados e pipelines em um intervalo de tempo selecionado.
- A linhagem no nível de campo mostra as operações realizadas em um conjunto de campos no conjunto de dados de origem para produzir um conjunto diferente de campos no conjunto de dados de destino.
Neste laboratório, você vai usar dois pipelines que demonstram um cenário típico em que os dados brutos são limpos e enviados para processamento downstream. Essa trilha de dados brutos para os dados de frete limpos até os resultados da análise pode ser explorada usando o recurso de linhagem do Cloud Data Fusion.
Observação: no momento, o recurso Cloud Data Fusion Linux está disponível apenas na edição Enterprise do Cloud Data Fusion.
Objetivos
Neste laboratório, você vai aprender a:
- Executar pipelines de amostra para produzir linhagem
- Analisar o conjunto de dados e a linhagem no nível do campo
- Descobrir como transmitir informações de handshake do pipeline upstream para o pipeline downstream
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Faça login no Google Skills usando uma janela anônima.
-
Verifique o tempo de acesso do laboratório (por exemplo, 02:00:00) para conseguir finalizar todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
-
Quando tudo estiver pronto, clique em Começar o laboratório.
Observação: depois de clicar em Começar o laboratório, o tempo para provisionar os recursos necessários e criar uma instância do Data Fusion é de 15 a 20 minutos.
Enquanto isso, você pode conferir as etapas abaixo para conhecer as metas do laboratório.
Quando as credenciais do laboratório (nome de usuário e senha) aparecem no painel esquerdo, isso significa que a instância foi criada, e você pode continuar o login no console.
-
Anote as credenciais (nome de usuário e senha). É com elas que você vai fazer login no console do Google Cloud.
-
Clique em Abrir console do Google.
-
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Aceite os termos e pule a página de recursos de recuperação.
Observação: não clique em Terminar o laboratório a menos que você tenha concluído as atividades ou queira refazer tudo. Essa opção limpa as ações que você realizou e remove o projeto.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
-
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ( ).
).
-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:

Exemplo de comandos
gcloud auth list
(Saída)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemplo de saída)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Saída)
[core]
project = <project_ID>
(Exemplo de saída)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
-
No Console do Google Cloud, acesse o menu de navegação ( ) e clique em IAM e administrador > IAM.
) e clique em IAM e administrador > IAM.
-
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.

Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
-
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
-
No card Informações do projeto, copie o Número do projeto.
-
No Menu de navegação, clique em IAM e administrador > IAM.
-
Na parte superior da página IAM, clique em Adicionar.
-
Para Novos principais, digite:
{project-number}-compute@developer.gserviceaccount.com
Substitua {project-number} pelo número do seu projeto.
-
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
-
Clique em Salvar.
Pré-requisitos
Neste laboratório, você vai trabalhar com dois pipelines:
- O pipeline de limpeza de dados de frete, que lê dados brutos de frete de um pequeno conjunto de dados de exemplo e aplica transformações para limpá-los.
- O pipeline de fretes atrasados nos EUA, que lê os dados de frete limpos, analisa-os e encontra os fretes nos EUA que atrasaram além de um limite estabelecido.
Use os links Limpeza de dados de frete e Fretes atrasados nos EUA para baixar esses conjuntos de dados de exemplo para sua máquina local.
Tarefa 1: adicionar as permissões necessárias para a instância do Cloud Data Fusion
- Na barra de título do console do Google Cloud, digite Data Fusion no campo Pesquisar e clique em Data Fusion nos resultados da pesquisa. Clique em Instâncias.
Observação: a criação da instância leva cerca de 20 minutos. Aguarde até que ela fique pronta.
Em seguida, conceda permissões à conta de serviço associada à instância seguindo estas etapas:
-
No console do Google Cloud, acesse IAM e admin > IAM.
-
Confirme se a conta de serviço padrão do Compute Engine {project-number}-compute@developer.gserviceaccount.com está presente. Copie a conta de serviço para a área de transferência.
-
Na página de permissões do IAM, clique em +Conceder acesso.
-
No campo "Novos principais", cole a conta de serviço.
-
Clique no campo Selecionar um papel, comece a digitar Agente de serviço da API Cloud Data Fusion e selecione essa opção.
-
Clique em ADICIONAR OUTRO PAPEL.
-
Adicione o papel Administrador do Managed Service for Spark.
-
Clique em Salvar.
Clique em Verificar meu progresso para conferir o objetivo.
Adicionar um papel de agente de serviço da API Cloud Data Fusion à conta de serviço
Conceder permissão do usuário para a conta de serviço
-
No console, acesse o Menu de navegação e clique em IAM e admin > IAM.
-
Marque a caixa de seleção Incluir concessões do papel fornecidas pelo Google.
-
Role a lista para baixo até encontrar a conta de serviço do Cloud Data Fusion gerenciada pelo Google com esta estrutura: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com e copie o nome da conta de serviço para a área de transferência.

-
Em seguida, acesse IAM e admin > Contas de serviço.
-
Clique na conta padrão do Compute Engine com esta estrutura: {project-number}-compute@developer.gserviceaccount.com. Depois disso, selecione a guia Principais com acesso na parte de cima do menu de navegação.
-
Clique no botão Permitir acesso.
-
No campo Novos principais, cole a conta de serviço que você copiou mais cedo.
-
No menu suspenso Papel, selecione Usuário da conta de serviço.
-
Clique em Salvar.
Tarefa 2: abrir a interface do Cloud Data Fusion
-
Acesse o Data Fusion, clique em Instâncias e depois no link Ver instância ao lado da sua instância do Data Fusion. Selecione suas credenciais do laboratório para fazer login. Se o serviço oferecer um tour, clique em Agora não. Agora você está usando a interface do Cloud Data Fusion.
-
Clique em Studio no painel de navegação à esquerda para abrir a página do Cloud Data Fusion Studio.
Tarefa 3: importar, implantar e executar o pipeline de limpeza de dados de envio
- Em seguida, você precisa importar os dados de envio brutos. Clique em Importar no canto superior direito da página do Studio e selecione e importe o pipeline Limpeza de dados de frete que você baixou no passo anterior.
Observação:
Se um pop-up solicitar que você atualize os plug-ins do pipeline, clique em Corrigir todos para atualizar os plug-ins para as versões mais recentes.
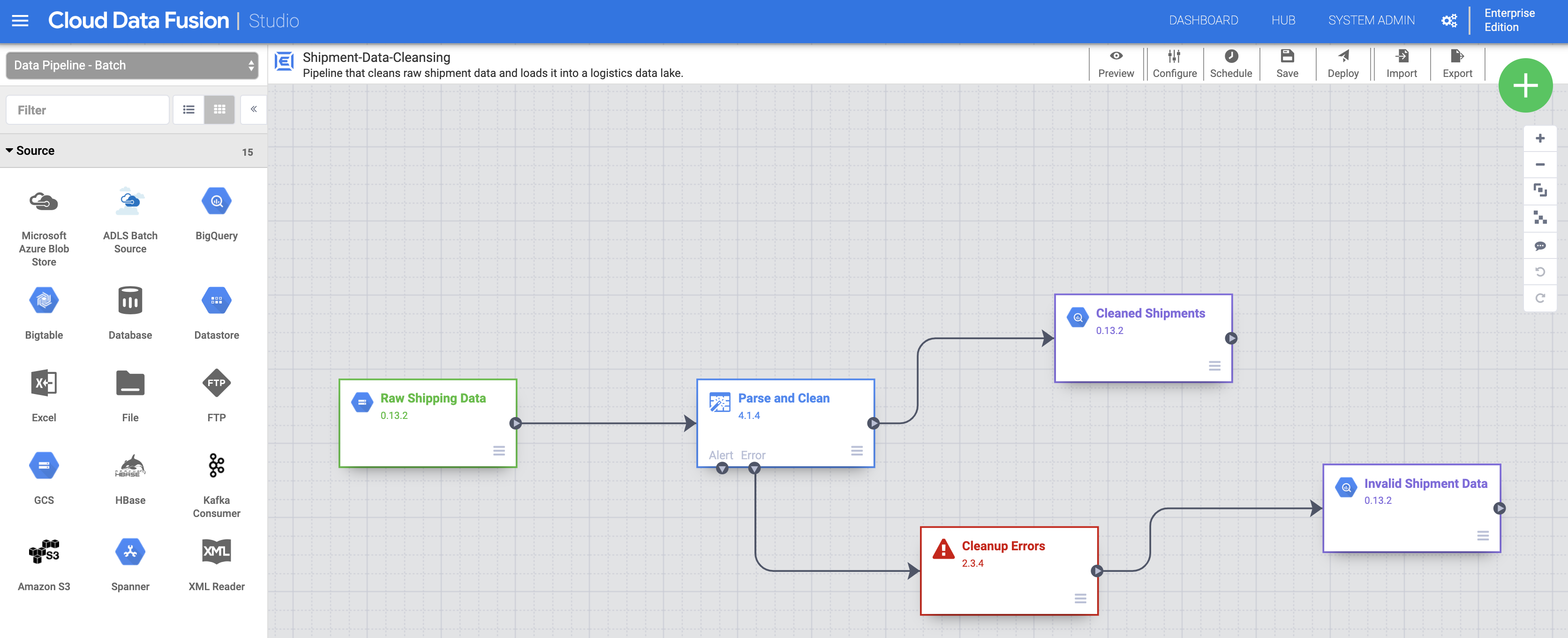
-
Agora, implante o pipeline. Clique em Implantar no canto superior direito da página Studio. Após a implantação, a página Pipeline será aberta.
-
Clique em Executar na parte superior central da página "Pipeline" para executar o pipeline.
Observação: se o pipeline falhar, execute-o novamente.
Clique em Verificar meu progresso para conferir o objetivo.
Importar, implantar e executar o pipeline de limpeza de dados de frete
Tarefa 4: importar, implantar e executar o pipeline de dados de fretes atrasados.
Depois que o status da limpeza de dados de frete mostrar Concluído, você precisará importar e implantar o pipeline de dados de fretes atrasados nos EUA que baixou anteriormente.
-
Clique em Studio no painel de navegação à esquerda para retornar à página do Cloud Data Fusion Studio.
-
Clique em Importar no canto superior direito da página do Studio e selecione e importe o pipeline de dados Fretes atrasados nos EUA que baixou anteriormente.
Observação:
Se um pop-up solicitar que você atualize os plug-ins do pipeline, clique em Corrigir todos para atualizar os plug-ins para as versões mais recentes.
-
Clique em Implantar no canto superior direito da página Studio para implantar o pipeline. Após a implantação, a página Pipeline será aberta.
-
Clique em Executar na parte superior central da página "Pipeline" para executar o pipeline.
Observação: se o pipeline falhar, execute-o novamente.
Depois de concluir o segundo pipeline, siga para as etapas restantes abaixo.
Clique em Verificar meu progresso para conferir o objetivo.
Importar, implantar e executar o pipeline de dados de fretes atrasados
Tarefa 5: descobrir conjuntos de dados
Você precisa descobrir um conjunto de dados antes de explorar a linhagem.
- Selecione Metadados no painel de navegação à esquerda da IU do Cloud Data Fusion para abrir a página Pesquisar para metadados.
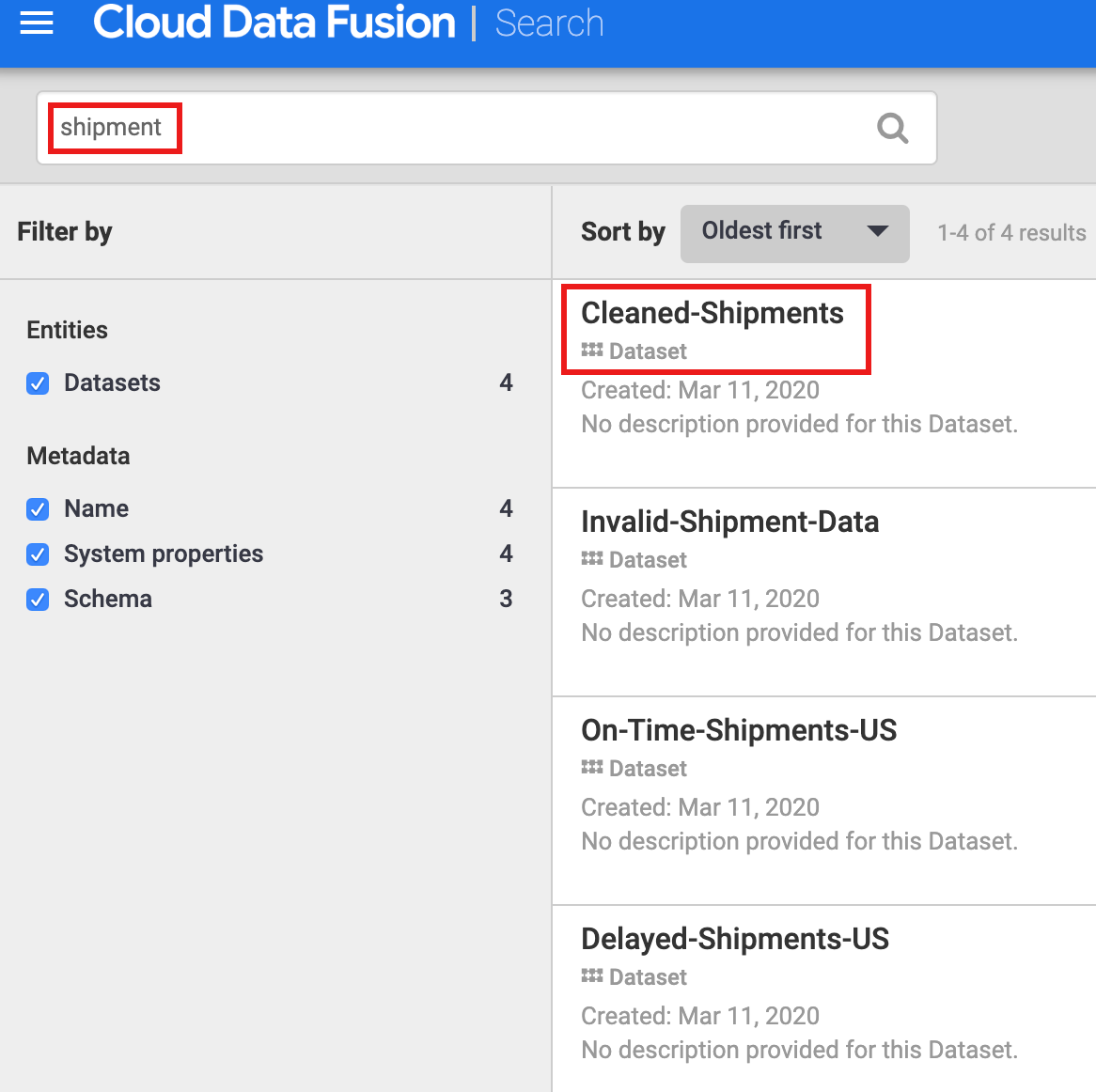
- Como o conjunto de dados de limpeza de dados de frete especificou "Cleaned-Shipments" como o conjunto de dados de referência, insira
shipment na caixa de pesquisa. Os resultados da pesquisa incluem esse conjunto de dados.
Tarefa 6: usar tags para descobrir conjuntos de dados
Uma pesquisa de metadados descobre conjuntos de dados que foram consumidos, processados ou gerados por pipelines do Cloud Data Fusion. Os pipelines são executados em um sistema estruturado que gera e coleta metadados técnicos e operacionais. Os metadados técnicos incluem nome, tipo, esquema, campos, hora de criação e processamento do conjunto de dados. Essas informações técnicas são usadas pelos recursos de pesquisa e metadados do Cloud Data Fusion.
Embora o Nome de referência de origens e coletores seja um identificador exclusivo do conjunto de dados e um excelente termo de pesquisa, você pode usar outros metadados técnicos como critérios de pesquisa, descrição, esquema, nome de campo ou prefixo de metadados.
O Cloud Data Fusion também é compatível com a anotação de conjuntos de dados com metadados empresariais, como tags e propriedades de chave-valor, que podem ser usados como critérios de pesquisa. Por exemplo, para adicionar e pesquisar uma anotação de tag empresarial no conjunto de dados de frete brutos:
-
Selecione Metadados no painel de navegação à esquerda da IU do Cloud Data Fusion para abrir a página Pesquisar para metadados.
-
Digite Raw shipping data na página de pesquisa da opção de metadados.
-
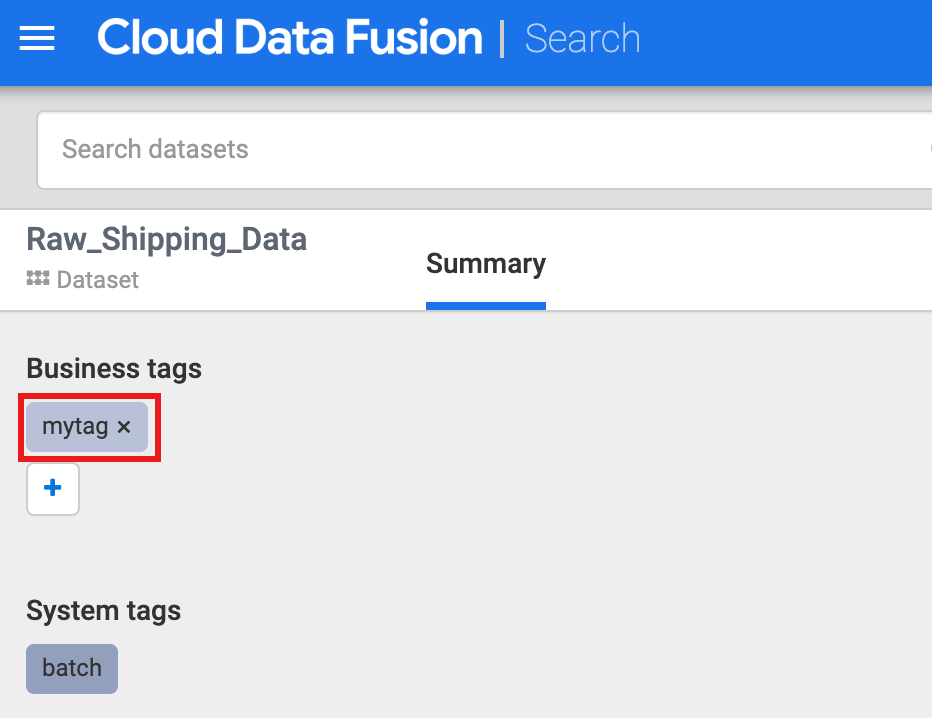
Clique em Raw_Shipping_Data.
-
Em Tags empresariais, clique em +, insira um nome de tag (caracteres alfanuméricos e sublinhados são permitidos) e pressione Enter.
Você pode pesquisar uma tag clicando no nome dela ou inserindo outras: tag_name na caixa de pesquisa na página de pesquisa Metadados.
Tarefa 7: analisar a linhagem de dados
Linhagem no nível do conjunto de dados
-
Selecione Metadados no painel de navegação à esquerda da interface do Cloud Data Fusion para abrir a página de pesquisa de metadados e digite shipment na caixa de pesquisa.
-
Clique no nome do conjunto de dados Cleaned-Shipments listado na página de pesquisa.
-
Em seguida, clique na guia Linhagem. O gráfico de linhagem mostra que esse conjunto de dados foi gerado pelo pipeline Shipments-Data-Cleansing (Limpeza de dados de frete), que consumiu o conjunto de dados brutos.
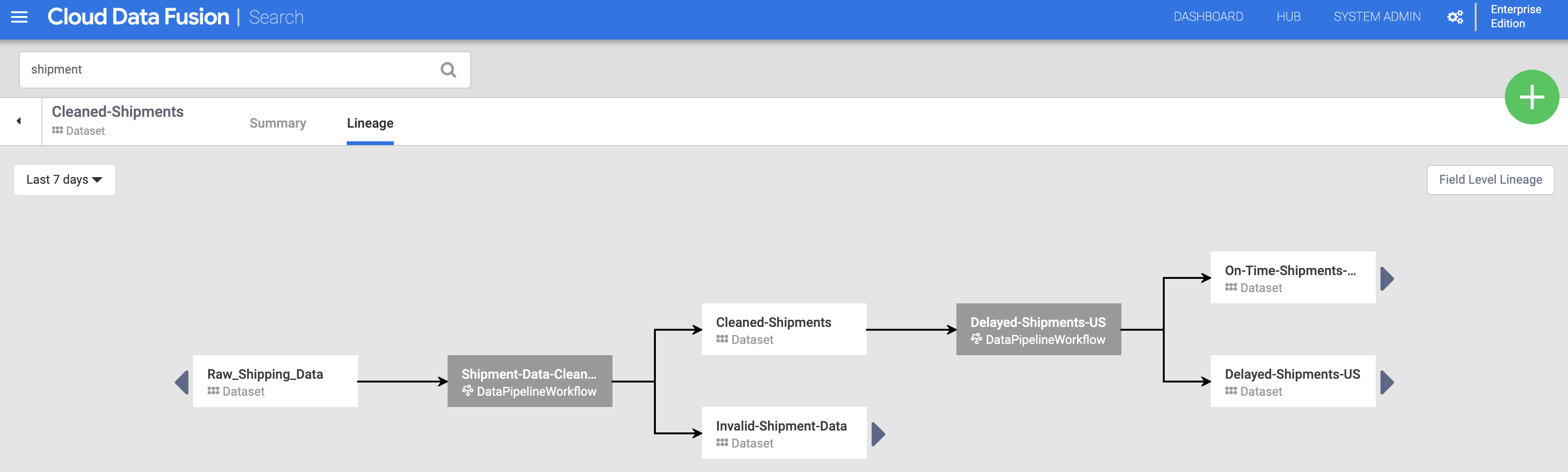
Linhagem no nível do campo
A linhagem no nível do campo do Cloud Data Fusion mostra a relação entre os campos de um conjunto de dados e as transformações que foram realizadas em um conjunto de campos para produzir um conjunto diferente de campos. Assim como a linhagem no nível do conjunto de dados, a linhagem no nível do campo é vinculada tempo, e os resultados mudam com o tempo.
- Continuando da etapa Linhagem no nível do conjunto de dados, clique no botão Linhagem no nível do campo no canto superior direito do gráfico de linhagem no nível do conjunto de dados para exibir o gráfico de linhagem no nível do campo.
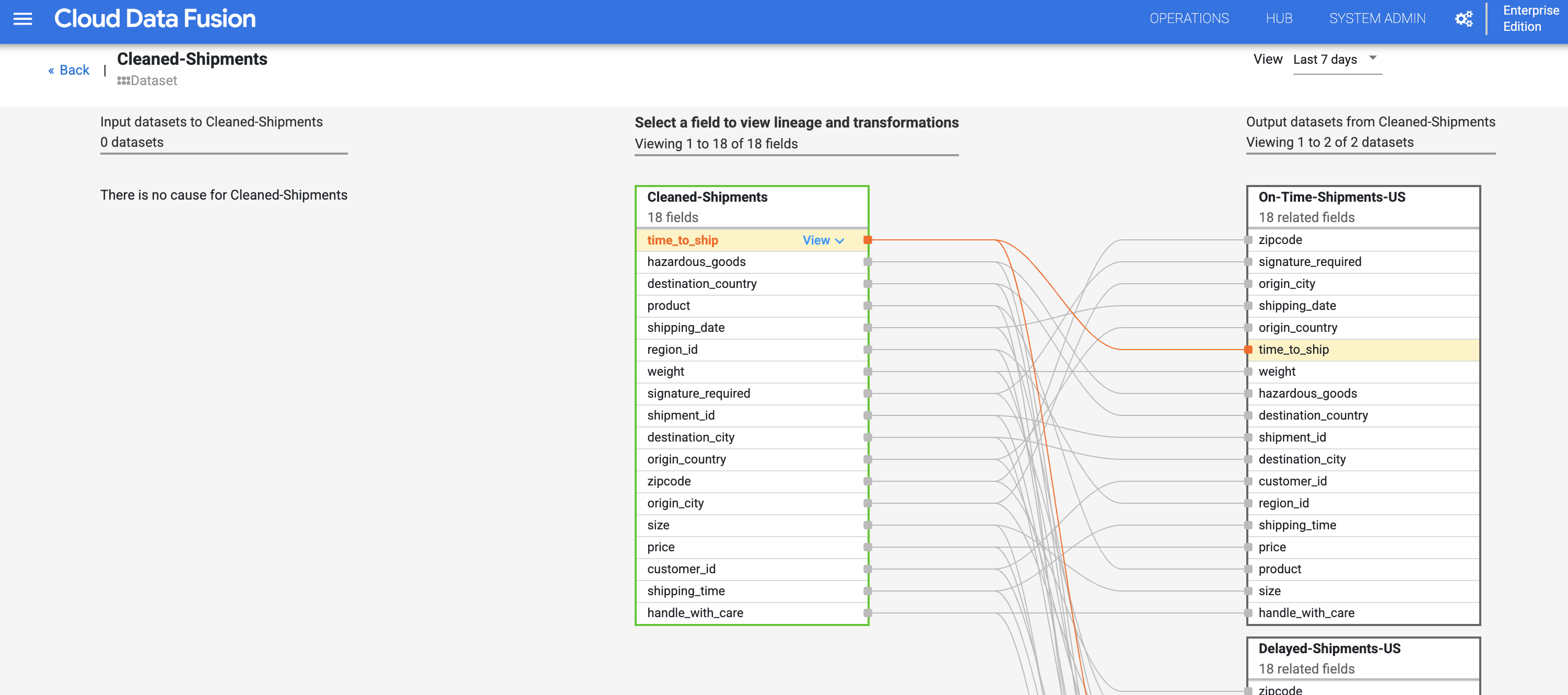
- O gráfico de linhagem no nível do campo mostra as conexões entre os campos. Selecione um campo para visualizar a respectiva linhagem. Selecione Visualizar e, em seguida, Fixar campo para visualizar somente a linhagem desse campo.
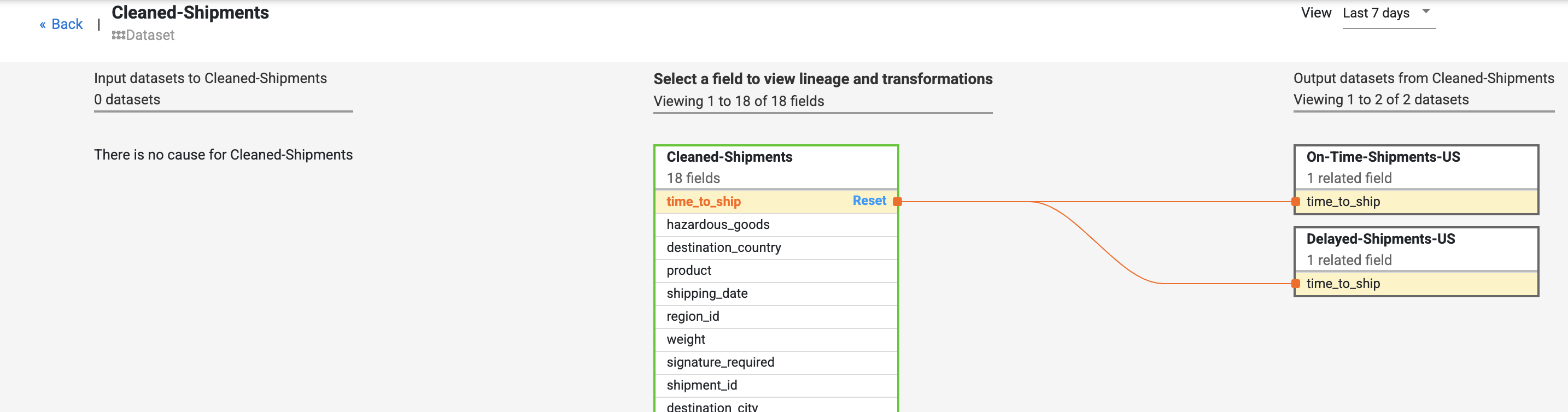
- Localize o campo time_to_ship no conjunto de dados Cleaned-Shipments, selecione Visualizar e, em seguida, Visualizar impacto para realizar uma análise de impacto.

A linhagem no nível do campo mostra como o campo mudou ao longo do tempo. Observe as transformações do campo time_to_ship: (i) conversão em uma coluna do tipo float e (ii) determinação se o valor será redirecionado para o próximo nó ou para o caminho de erro.
A linhagem expõe o histórico de alterações do campo. Outros exemplos são a concatenação de alguns campos para compor um novo campo (como combinar nome e sobrenome para gerar nome completo) ou cálculos feitos em um campo (como converter um número em uma porcentagem em relação à contagem total).
Os links de causa e impacto mostram as transformações realizadas em ambos os lados de um campo em um formato de livro contábil legível por humanos.
Parabéns!
Neste laboratório, você aprendeu a analisar a linhagem dos dados. Essas informações podem ser essenciais para geração de relatórios e governança. Ela pode ajudar diferentes públicos a entender como os dados chegaram ao estado em que estão.
Manual atualizado em 14 de novembro de 2022
Laboratório testado em 8 de agosto de 2023
Copyright 2026 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.





