GSP812

Übersicht
In diesem Lab wird gezeigt, wie Sie Cloud Data Fusion zum Untersuchen der Data Lineage verwenden, d. h. zum Ermitteln der Herkunft und Abstammung von Daten sowie deren Bewegung im Zeitverlauf.
Mit der Data Lineage in Cloud Data Fusion haben Sie folgende Möglichkeiten:
- Ursache fehlerhafter Datenereignisse feststellen
- Wirkungsanalysen durchführen, bevor Sie Daten ändern
Cloud Data Fusion stellt die Data Lineage auf Dataset- und Feldebene bereit. Außerdem sind die Informationen zeitgebunden, um die Data Lineage im Zeitverlauf zu zeigen.
- Die Lineage auf Dataset-Ebene gibt die Beziehung zwischen Datasets und Pipelines in einem ausgewählten Zeitintervall an.
- Die Lineage auf Feldebene zeigt die Vorgänge, die für einen Satz von Feldern im Quell-Dataset ausgeführt wurden, um einen anderen Satz von Feldern im Ziel-Dataset zu erzeugen.
Für dieses Lab verwenden Sie zwei Pipelines, die ein typisches Szenario zeigen, in dem Rohdaten bereinigt und dann zur Downstream-Verarbeitung gesendet werden. Dieser Datentrail von den Rohdaten über die bereinigten Daten zu Lieferungen bis hin zur Ausgabe analysierter Daten kann mit der Lineage-Funktion von Cloud Data Fusion untersucht werden.
Hinweis: Derzeit ist die Funktion „Cloud Data Fusion Lineage“ nur mit Cloud Data Fusion Enterprise Edition verfügbar.
Ziele
In diesem Lab lernen Sie Folgendes:
- Beispielpipelines ausführen, um danach die Lineage von Daten verfolgen zu können
- Lineage auf Dataset- und Feldebene untersuchen
- Handshake-Informationen aus der Upstream-Pipeline an die Downstream-Pipeline übergeben
Einrichtung und Anforderungen
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
-
Melden Sie sich über ein Inkognitofenster bei Google Skills an.
-
Beachten Sie die Zugriffszeit (z. B. 02:00:00) und achten Sie darauf, dass Sie das Lab innerhalb dieser Zeit abschließen.
Es gibt keine Pausenfunktion. Sie können bei Bedarf neu starten, müssen dann aber von vorn beginnen.
-
Wenn Sie bereit sind, klicken Sie auf Lab starten.
Hinweis: Nachdem Sie auf Lab starten geklickt haben, dauert es etwa 15 bis 20 Minuten, bis die erforderlichen Ressourcen für das Lab bereitgestellt und eine Data Fusion-Instanz erstellt wurden.
In der Zwischenzeit können Sie sich anhand der unten aufgeführten Schritte mit den Zielen des Labs vertraut machen.
Wenn im linken Bereich Lab-Anmeldedaten (Nutzername und Passwort) angezeigt werden, ist die Instanz erstellt und Sie können sich in der Console anmelden.
-
Notieren Sie sich Ihre Anmeldedaten (Nutzername und Passwort). Mit diesen Daten melden Sie sich in der Google Cloud Console an.
-
Klicken Sie auf Google Console öffnen.
-
Klicken Sie auf Anderes Konto verwenden. Kopieren Sie den Nutzernamen und das Passwort für dieses Lab und fügen Sie beides in die entsprechenden Felder ein.
Wenn Sie andere Anmeldedaten verwenden, tritt ein Fehler auf oder es fallen Kosten an.
-
Akzeptieren Sie die Nutzungsbedingungen und überspringen Sie die Seite zur Wiederherstellung der Ressourcen.
Hinweis: Über den Button Lab beenden wird Ihre Arbeit gelöscht und das Projekt entfernt. Sie sollten daher nur darauf klicken, wenn Sie das Lab abgeschlossen haben oder es neu starten möchten.
Bei der Google Cloud Console anmelden
- Kopieren Sie im Browsertab oder Fenster für diese Lab-Sitzung im Bereich Verbindungsdetails den Nutzernamen und klicken Sie auf den Button Google Console öffnen.
Hinweis: Wenn die Eingabeaufforderung „Konto auswählen“ angezeigt wird, klicken Sie auf Anderes Konto verwenden.
- Fügen Sie den Nutzernamen und das Passwort ein, wenn Sie dazu aufgefordert werden.
- Klicken Sie auf Weiter.
- Akzeptieren Sie die Nutzungsbedingungen.
Da es sich um ein temporäres Konto handelt, das nur für die Dauer dieses Labs verfügbar ist, beachten Sie bitte Folgendes:
- Fügen Sie keine Wiederherstellungsoptionen hinzu.
- Melden Sie sich nicht für kostenlose Testversionen an.
- Wenn die Console geöffnet wurde, klicken Sie oben links auf das Navigationsmenü (
 ), um die Liste der Dienste aufzurufen.
), um die Liste der Dienste aufzurufen.

Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Cloud Shell bietet Ihnen Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen. gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
-
Klicken Sie in der Google Cloud Console im Navigationsbereich auf Cloud Shell aktivieren ( ).
).
-
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:

Beispielbefehle
gcloud auth list
(Ausgabe)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Beispielausgabe)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Ausgabe)
[core]
project = <project_ID>
(Beispielausgabe)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Projektberechtigungen prüfen
Bevor Sie mit der Arbeit in Google Cloud beginnen, müssen Sie sicherstellen, dass für Ihr Projekt im Rahmen von Identity and Access Management (IAM) die nötigen Berechtigungen vorliegen.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf IAM und Verwaltung > IAM.
-
Prüfen Sie, ob das standardmäßige Compute-Dienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden und ihm die Rolle Bearbeiter zugewiesen ist. Das Kontopräfix ist die Projektnummer. Sie finden sie im Navigationsmenü unter Cloud-Übersicht.

Wenn das Konto nicht in IAM vorhanden ist oder nicht über die Bearbeiter-Rolle verfügt, weisen Sie die erforderliche Rolle so zu:
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf Cloud-Übersicht.
-
Kopieren Sie auf der Karte Projektinformationen die Projektnummer.
-
Klicken Sie im Navigationsmenü auf IAM und Verwaltung > IAM.
-
Klicken Sie oben auf der Seite IAM auf Hinzufügen.
-
Geben Sie unter Neue Hauptkonten ein:
{project-number}-compute@developer.gserviceaccount.com
Ersetzen Sie {project-number} durch die entsprechende Projektnummer.
-
Wählen Sie unter Rolle auswählen die Option Basic (oder „Projekt“) > Editor aus.
-
Klicken Sie auf Speichern.
Vorbereitung
In diesem Lab arbeiten Sie mit zwei Pipelines:
- Die Pipeline Shipment Data Cleansing liest Rohdaten zu Lieferungen aus einem kleinen Beispiel-Dataset und wendet Transformationen an, um die Daten zu bereinigen.
- Die Pipeline Delayed Shipments USA liest die bereinigten Lieferdaten, analysiert sie und sucht Lieferungen innerhalb der USA, deren Verspätung über einem Schwellenwert liegt.
Laden Sie die Beispiel-Datasets über die Links auf Ihren Computer herunter: Shipment Data Cleansing und Delayed Shipments USA.
Aufgabe 1: Erforderliche Berechtigungen für Ihre Cloud Data Fusion-Instanz hinzufügen
- Geben Sie in der Titelleiste der Google Cloud Console Data Fusion in das Suchfeld ein und klicken Sie dann in den Suchergebnissen auf Data Fusion. Klicken Sie auf Instanzen.
Hinweis: Das Erstellen der Instanz kann bis zu 20 Minuten dauern. Bitte warten Sie, bis der Vorgang abgeschlossen ist.
Als Nächstes gewähren Sie dem Dienstkonto, das der Instanz zugeordnet ist, Berechtigungen. Gehen Sie dazu so vor:
-
Rufen Sie in der Google Cloud Console IAM und Verwaltung > IAM auf.
-
Prüfen Sie, ob das Compute Engine-Standarddienstkonto {project-number}-compute@developer.gserviceaccount.com vorhanden ist, und kopieren Sie das Dienstkonto in die Zwischenablage.
-
Klicken Sie auf der Seite „IAM-Berechtigungen“ auf Zugriff erlauben.
-
Fügen Sie im Feld „Neue Hauptkonten“ das Dienstkonto ein.
-
Klicken Sie in das Feld Rolle auswählen und geben Sie Cloud Data Fusion API-Dienst-Agent ein. Wählen Sie dann die Rolle aus.
-
Klicken Sie auf + Weitere Rolle hinzufügen.
-
Fügen Sie die Rolle Dataproc-Administrator hinzu.
-
Klicken Sie auf Speichern.
Klicken Sie auf Fortschritt prüfen.
Rolle „Cloud Data Fusion API-Dienst-Agent“ zum Dienstkonto hinzufügen
Dienstkontonutzerin/Dienstkontonutzer die Berechtigung erteilen
-
Klicken Sie in der Console im Navigationsmenü auf IAM & Verwaltung > IAM.
-
Klicken Sie auf das Kästchen Von Google bereitgestellte Rollenzuweisungen einschließen.
-
Suchen Sie in der Liste nach dem von Google verwalteten Cloud Data Fusion-Dienstkonto, das so aussieht: service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Kopieren Sie dann den Namen des Dienstkontos in die Zwischenablage.

-
Rufen Sie als Nächstes IAM & Verwaltung > Dienstkonten auf.
-
Klicken Sie auf das Compute Engine-Standardkonto, das so aussieht: {project-number}-compute@developer.gserviceaccount.com, und wählen Sie in der oberen Navigationsleiste den Tab Hauptkonten mit Zugriff aus.
-
Klicken Sie auf den Button Zugriff gewähren.
-
Fügen Sie im Feld Neue Hauptkonten das zuvor kopierte Dienstkonto ein.
-
Wählen Sie im Drop‑down-Menü Rolle die Option Dienstkontonutzer aus.
-
Klicken Sie auf Speichern.
Aufgabe 2: Benutzeroberfläche von Cloud Data Fusion öffnen
-
Rufen Sie Data Fusion auf, klicken Sie auf Instanzen und dann auf den Link Instanz ansehen neben Ihrer Data Fusion-Instanz. Wählen Sie die Anmeldedaten des Labs aus, um sich anzumelden. Wenn Ihnen eine Tour zum Dienst angeboten wird, klicken Sie auf Nein danke. Sie sollten sich jetzt in der Cloud Data Fusion-Benutzeroberfläche befinden.
-
Klicken Sie im linken Navigationsbereich auf Studio, um die Cloud Data Fusion Studio-Seite zu öffnen.
Aufgabe 3: Pipeline „Shipment Data Cleansing“ importieren, bereitstellen und ausführen
- Als Nächstes müssen Sie die Rohdaten zu den Lieferungen importieren. Klicken Sie rechts oben auf der Studio-Seite auf Import. Wählen Sie dann die Pipeline Shipment Data Cleansing aus, die Sie zuvor heruntergeladen haben, und importieren Sie sie.
Hinweis:
Wenn Sie in einem Pop-up-Fenster aufgefordert werden, ein Upgrade der Pipeline-Plug-ins durchzuführen, klicken Sie auf Fix all, um die Plug-ins auf die aktuelle Version zu aktualisieren.
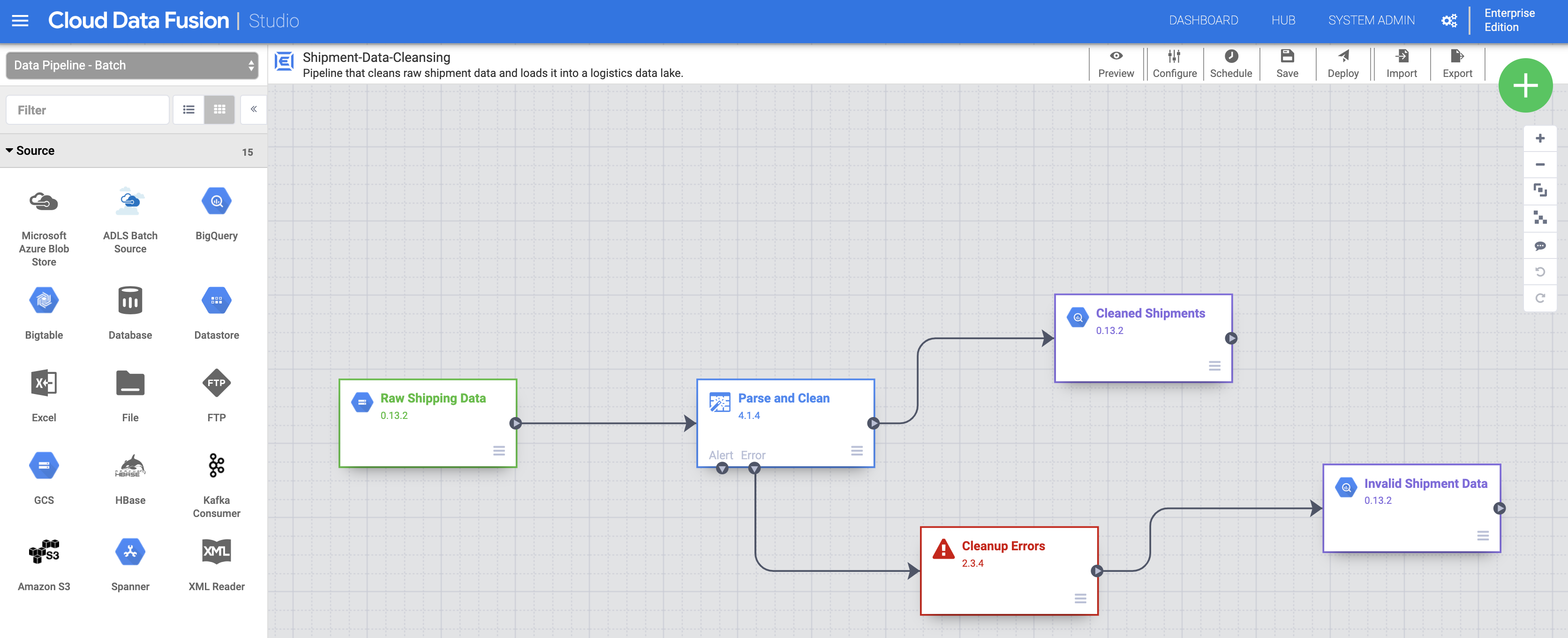
-
Stellen Sie nun die Pipeline bereit. Klicken Sie rechts oben auf der Seite Studio auf Deploy. Nach der Bereitstellung wird die Seite Pipeline geöffnet.
-
Klicken Sie oben in der Mitte der Seite „Pipeline“ auf Run, um die Pipeline auszuführen.
Hinweis: Wenn die Pipeline fehlschlägt, führen Sie sie noch einmal aus.
Klicken Sie auf Fortschritt prüfen.
Pipeline „Shipment Data Cleansing“ importieren, bereitstellen und ausführen
Aufgabe 4: Datenpipeline „Delayed Shipments USA“ importieren, bereitstellen und ausführen.
Wenn der Status der Bereinigung der Daten zu den Lieferungen Succeeded lautet, importieren Sie die Datenpipeline „Delayed Shipments USA“, die Sie zuvor heruntergeladen haben, und stellen sie bereit.
-
Klicken Sie im linken Navigationsbereich auf Studio, um zur Cloud Data Fusion Studio-Seite zurückzukehren.
-
Klicken Sie rechts oben auf der Studio-Seite auf Import. Wählen Sie dann die Datenpipeline Delayed Shipments USA aus, die Sie zuvor heruntergeladen haben, und importieren Sie sie.
Hinweis:
Wenn Sie in einem Pop-up-Fenster aufgefordert werden, ein Upgrade der Pipeline-Plug-ins durchzuführen, klicken Sie auf Fix all, um die Plug-ins auf die aktuelle Version zu aktualisieren.
-
Klicken Sie rechts oben auf der Seite Studio auf Deploy, um die Pipeline bereitzustellen. Nach der Bereitstellung wird die Seite Pipeline geöffnet.
-
Klicken Sie oben in der Mitte der Seite „Pipeline“ auf Run, um die Pipeline auszuführen.
Hinweis: Wenn die Pipeline fehlschlägt, führen Sie sie noch einmal aus.
Nachdem die Ausführung der zweiten Pipeline erfolgreich abgeschlossen wurde, können Sie die verbleibenden Schritte unten ausführen.
Klicken Sie auf Fortschritt prüfen.
Datenpipeline „Delayed Shipments USA“ importieren, bereitstellen und ausführen
Aufgabe 5: Datasets erkennen
Sie müssen ein Dataset erst erkennen, bevor Sie seine Lineage untersuchen.
- Wählen Sie im linken Navigationsbereich der Cloud Data Fusion-Benutzeroberfläche die Option Metadata aus, um die Seite Search für Metadaten zu öffnen.
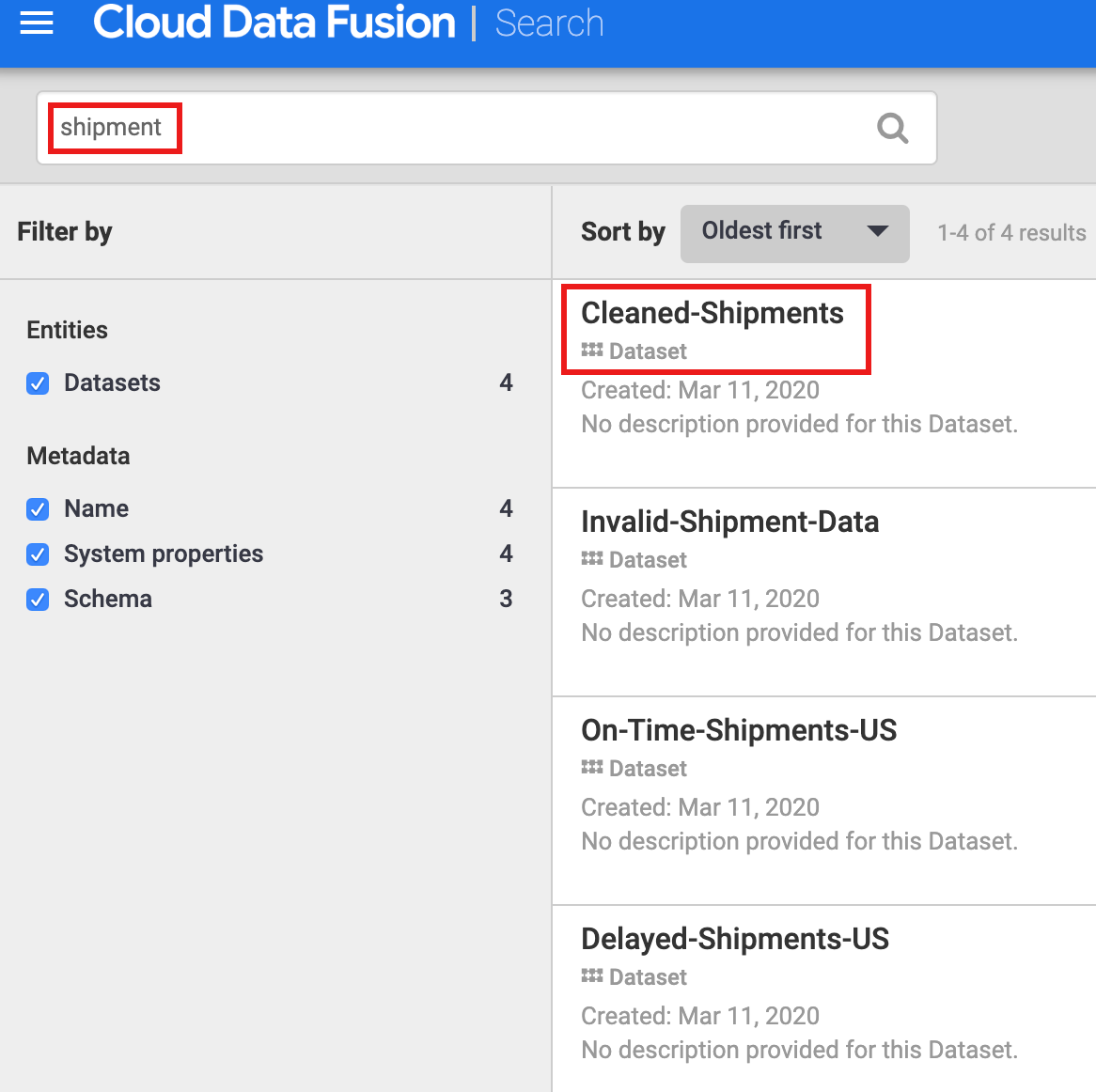
- Da im Dataset „Shipping Data Cleansing“ der bereinigte Dataset „Cleaned-Shipments“ als Referenz-Dataset angegeben wurde, geben Sie
shipment in das Suchfeld ein. Die Suchergebnisse enthalten dieses Dataset.
Aufgabe 6: Datasets mithilfe von Tags erkennen
Eine Metadatensuche findet Datasets, die von Cloud Data Fusion-Pipelines verwendet, verarbeitet oder generiert wurden. Pipelines werden in einem strukturierten Framework ausgeführt, das technische und Betriebsmetadaten generiert und sammelt. Die technischen Metadaten umfassen Name, Typ, Schema, Felder und Erstellungszeit des Datasets sowie Verarbeitungsinformationen. Diese technischen Informationen werden von den Metadaten- und Lineage-Funktionen von Cloud Data Fusion verwendet.
Der Reference Name von Quellen und Senken ist zwar eine eindeutige Dataset-ID und ein gut geeigneter Suchbegriff, Sie können aber auch andere technische Metadaten als Suchkriterien verwenden, z. B. eine Dataset-Beschreibung, ein Schema, einen Feldnamen oder ein Metadatenpräfix.
Cloud Data Fusion unterstützt auch die Annotation von Datasets mit Geschäftsmetadaten wie Tags und Schlüssel/Wert-Attributen, die als Suchkriterien verwendet werden können. So fügen Sie beispielsweise eine Annotation mit einem Unternehmens-Tag-zum Dataset „Raw Shipping Data“ hinzu und suchen nach einer solchen Annotation:
-
Wählen Sie im linken Navigationsbereich der Cloud Data Fusion-Benutzeroberfläche die Option Metadata aus, um die Suchseite für Metadaten zu öffnen.
-
Geben Sie Raw shipping data in das Suchfeld der Metadatenoption ein.
-
Klicken Sie auf Raw_Shipping_Data.
-
Klicken Sie unter Business tags auf +, fügen Sie einen Tag-Namen ein (alphanumerische Zeichen und Unterstriche sind zulässig) und drücken Sie die Eingabetaste.
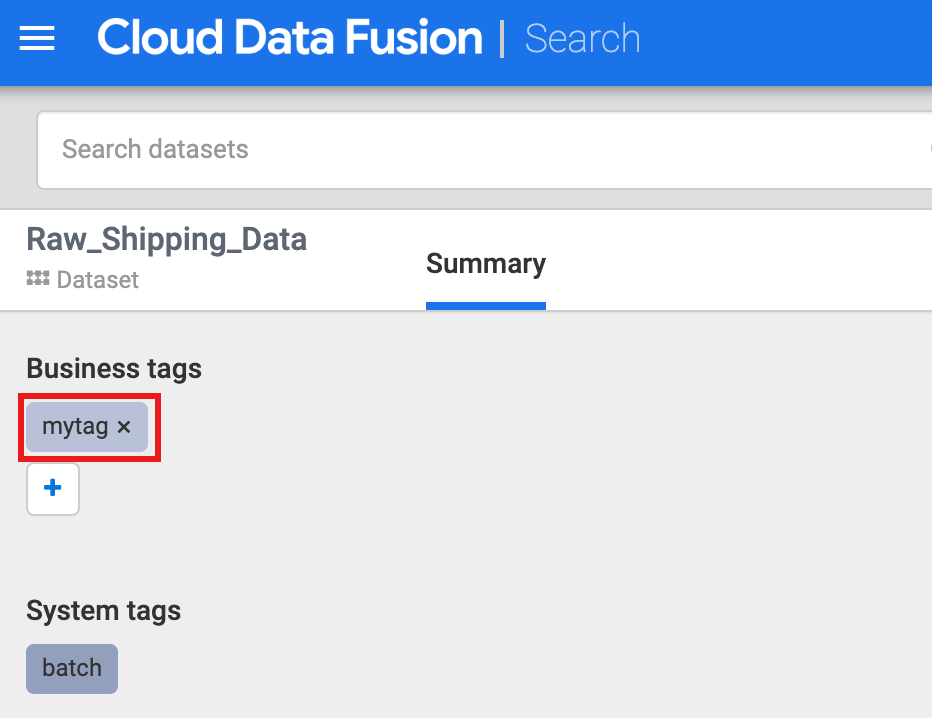
Wenn Sie nach einem Tag suchen möchten, klicken Sie auf den Tag-Namen oder geben Sie „tags: tag_name“ in das Suchfeld auf der Suchseite Metadaten ein.
Aufgabe 7: Data Lineage untersuchen
Lineage auf Dataset-Ebene
-
Wählen Sie im linken Navigationsbereich der Cloud Data Fusion-Benutzeroberfläche die Option Metadata aus, um die Suchseite für Metadaten zu öffnen. Geben Sie shipment in das Suchfeld ein.
-
Klicken Sie auf der Suchseite auf den Dataset-Namen Cleaned-Shipments.
-
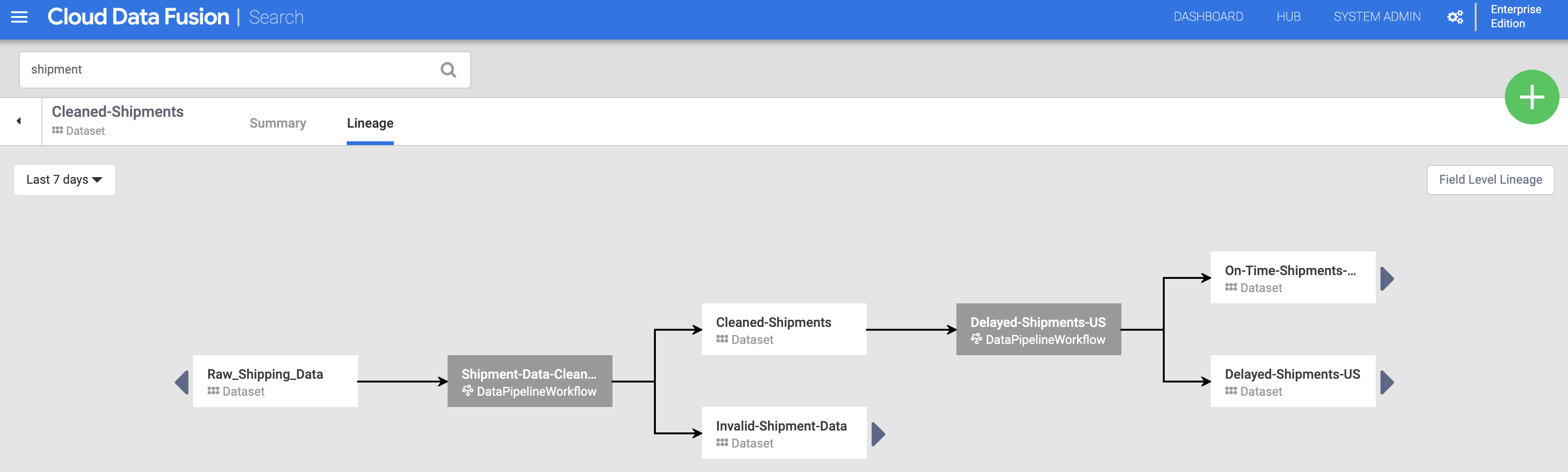
Klicken Sie dann auf den Tab Lineage. Die Lineage-Diagramm zeigt, dass dieses Dataset von der Pipeline „Shipments-Data-Cleansing“ generiert wurde, die das Dataset „Raw_Shipping_Data“ verwendet hat.
Lineage auf Feldebene
Die Lineage auf Feldebene in Cloud Data Fusion zeigt die Beziehung zwischen den Feldern eines Datasets und den Transformationen, die für einen Satz von Feldern durchgeführt wurden, um einen anderen Satz von Feldern zu erzeugen. Wie die Lineage auf Dataset-Ebene ist die Lineage auf Feldebene zeitgebunden und die Ergebnisse ändern sich mit der Zeit.
- Klicken Sie nach dem Anzeigen der Lineage auf Dataset-Ebene rechts oben im Dataset-Lineage-Diagramm für „Cleaned Shipments“ auf den Button Field Level Lineage, um das Diagramm für die Lineage auf Feldebene anzuzeigen.
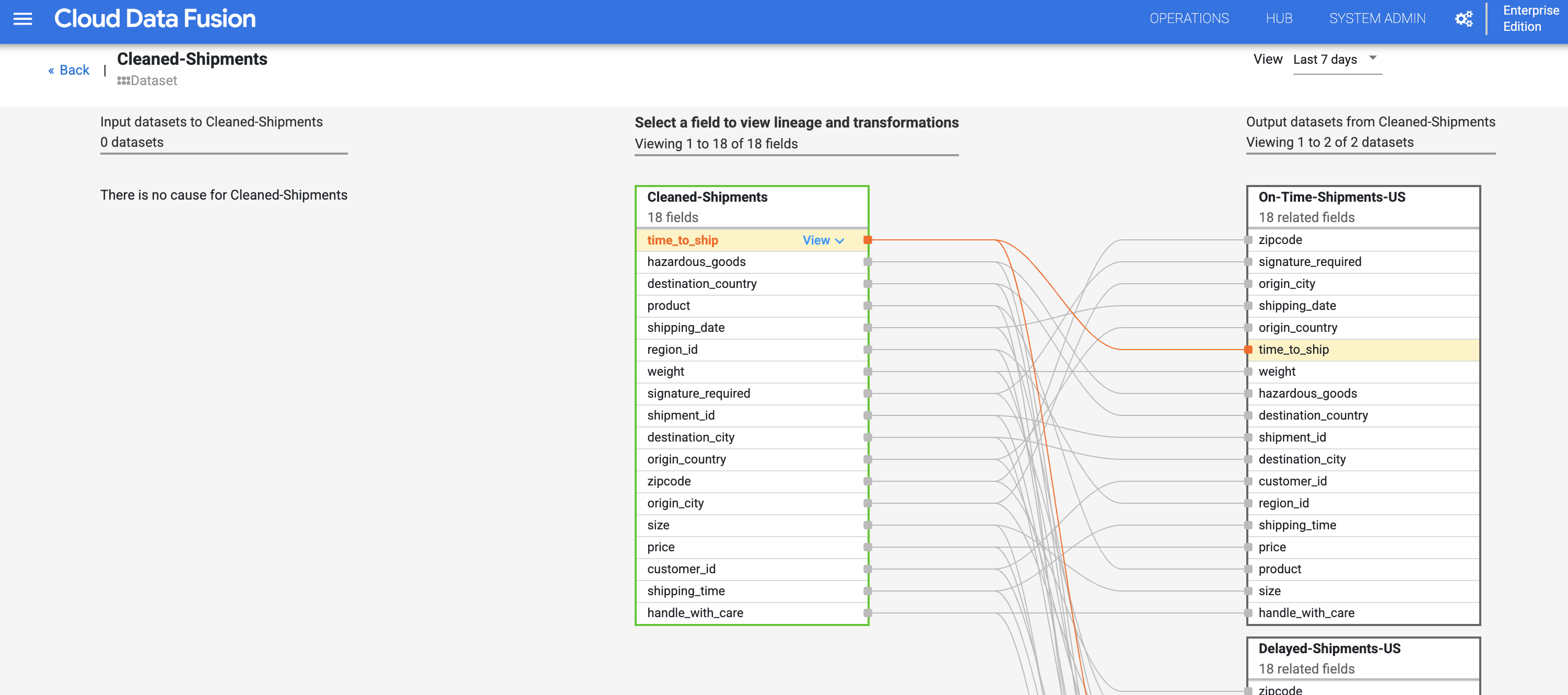
- Das Lineage-Diagramm auf Feldebene zeigt die Verbindungen zwischen Feldern. Sie können ein Feld auswählen, um die Lineage anzuzeigen. Klicken Sie auf View und dann auf Pin field, um nur die Lineage des Felds anzuzeigen.
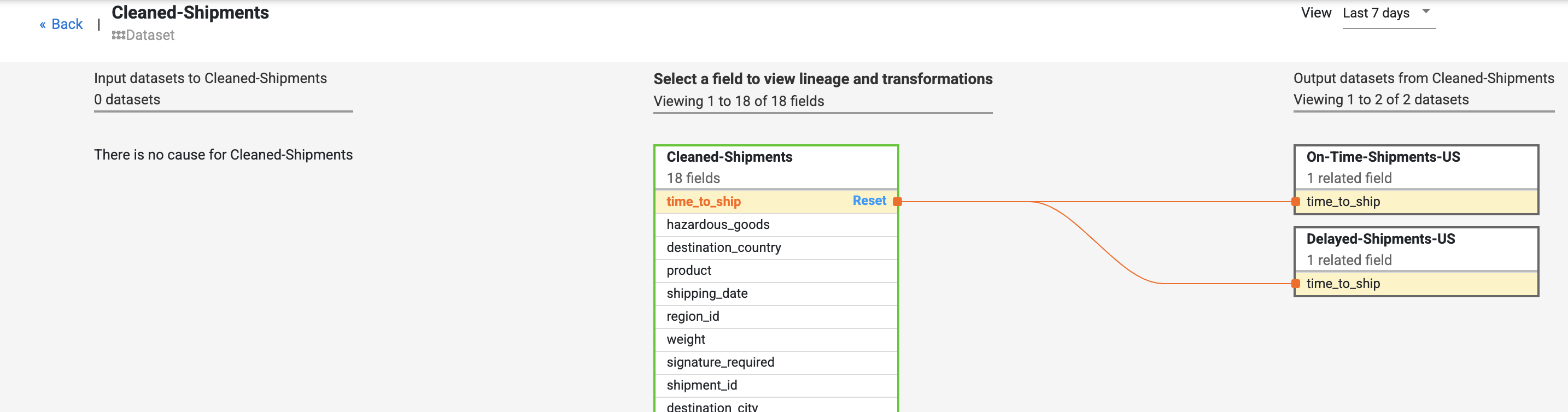
- Suchen Sie im Dataset Cleaned-Shipments nach dem Feld time_to_ship. Wählen Sie View und dann View impact aus, um eine Wirkungsanalyse durchzuführen.

Die Lineage auf Feldebene zeigt, wie sich dieses Feld im Laufe der Zeit verändert hat. Beachten Sie die Transformationen für das Feld time_to_ship: (i) Umwandlung in eine Spalte vom Typ float, (ii) Bestimmung, ob der Wert zum nächsten Knoten oder zum Fehlerpfad umgeleitet wird.
Die Lineage zeigt den Verlauf der Änderungen, die an einem bestimmten Feld vorgenommen wurden. Weitere Beispiele sind das Verketten mehrerer Felder zu einem neuen Feld (z. B. Vorname und Nachname zu Name) oder Berechnungen in einem Feld (z. B. Umwandlung einer Zahl in einen Prozentsatz im Verhältnis zur Gesamtzahl).
Die Links für Ursache und Wirkung zeigen die Transformationen auf beiden Seiten eines Felds in einem menschenlesbaren Verzeichnisformat.
Glückwunsch!
In diesem Lab haben Sie gelernt, wie Sie die Lineage Ihrer Daten untersuchen. Diese Informationen können für die Berichterstellung und Governance wichtig sein. So können verschiedene Zielgruppen nachvollziehen, wie die Daten in ihren aktuellen Zustand gelangt sind.
Anleitung zuletzt am 14. November 2022 aktualisiert
Lab zuletzt am 8. August 2023 getestet
© 2026 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.






